Traffic signs provide reliable safety precautions and guiding information to road users on highways, motorways, urban surroundings, and the sort. In the wake of building smart cities and self-driving vehicles, traffic sign recognition has become a very necessary sub-field of study under object recognition with several applications being developed. Although, many methods have been proposed, still there are issues such as variations in view points, distortion in color of signs especially at night under street lights, blurring from motion, a degradation in contrast, varied poses, and either less or more exposed signs, as depicted in
Figure 1, making it difficult to obtain high classification and recognition accuracy. Most methods that have been deployed for traffic sign recognition, be it traditional computer vision methods or advanced ones, have used a supervised learning approach. Classical supervised learning demands all samples to be well annotated before a good model can be built, which is a major drawback when factors such as labeling cost, time, and demand for expertise knowledge are considered. To reduce the labeling cost and make use of both labeled and unlabeled data, a semi-supervised learning technique is used. Semi-supervised learning is an approach that automatically assigns a class to unlabeled samples by relying on its capabilities of predicting labels correctly and through training, extending its knowledge on the predictions learned and/or its competence in classifying [
1].
To this end, there is the assumption that less traffic signs that have been well labeled are available together with a chunk of unlabeled ones. Several works [
3,
4,
5,
6,
7,
8] have been done in the past to address the traffic sign recognition task. However, the availability of unlabeled datasets has been less considered and less exploited in terms of traffic sign recognition tasks. With the little literature existing on the topic of Traffic Sign Recognition (TSR) [
2,
4,
6,
7,
8], it is generally difficult to decide which Convolutional Neural Network (CNN)-based method gives the best result due to the performances that have been reported on benchmark datasets. Some studies [
9,
10,
11] have evaluated their methods on self-gathered private datasets, whereas in other studies [
12], the benchmark datasets were combined with self-collated traffic signs, to enrich the dataset for detection and recognition tasks. However, one common thing that is observed among these methods is that they focus on using classical supervised learning to either detect or classify only well-annotated data samples, which results in underperformance when implemented in a real-world scenario. Some of these methods were implemented via traditional hand-crafted features, such as the histogram of oriented gradients (HOG) [
11,
13,
14,
15], local binary patterns (LBP) [
11], and integral channel features or scale-invariant feature transform (SIFT) [
11,
16], together with a wide range of machine learning and statistical learning algorithms [
9,
11,
12,
14,
15,
16,
17]. Just like in the computer vision world, CNN-based models have been implemented and evaluated in traffic sign recognition tasks. Deep CNNs have achieved huge success in computer vision tasks, cutting across object detection [
18,
19,
20], clustering and association [
21], classification [
22,
23,
24], and segmentation [
18,
25,
26]. CNNs have been deployed in many studies [
6,
7,
11,
27,
28] to learn representations and classifiers automatically. Domen et al. [
28] proposed a deep learning framework with end-to-end full feature learning. Their approach was based on Mask R-CNN, which used a region proposal network to employ deeper network architectures in detecting and classifying traffic signs. In the study [
29] conducted by Alvaro et al., a single CNN for automatic recognition of traffic signs that alternated convolutional and spatial transformer modules was utilized. Extensive experiments were conducted on the German Traffic-Sign Recognition Benchmark (GTSRB) and the Belgium Traffic Sign for Classification (BTSC) dataset to find the best CNN architecture, as well as to investigate the impact of multiple spatial transform network configurations within the CNN, together with the effectiveness of four stochastic gradient decent optimization algorithms. A recognition accuracy of 99.71% was obtained for precision, recall, and F1-score for the GTSRB and the BTSC; 98.95%, 98.87%, and 98.86% were obtained for the precision, recall, and F1-score, respectively. The recognition rate was improved by the study conducted by Mahmoud et al. [
30]. Mahmoud et al. combined features learned by deep convolutional generative adversarial networks (DCGAN) and pseudoinverse learning autoencoder (PILAE) supplemented with the softmax classifier method to obtain excellent performance with a recognition rate of 99.80% on the GTSRB and 99.72% on the BTSC, as compared to handcrafted features and other methods that were DNN based. DCGAN was utilized to extract the informative features in an unsupervised way without needing an expert analysis of the learning process and PILAE to train the model faster. Furthermore, Sermanet et al. applied the convolutional network architecture to achieve a better result on the GTSRB dataset after experimenting with the Energy-based learning (EBLearn) open-source library [
31]. However, their result of 99.17% was later improved by the work of Mahmoud et al. [
30]. Another study proposed Balancing GAN (BAGAN) [
32] as an augmentation tool to restore balance in imbalanced datasets. The method generates images for the less represented classes from the majority classes, and during the adversarial training, all available images of the majority and minority classes are included in the training process. The generative model learns useful features from majority classes and uses these to generate images for the minority classes. The study further used class conditioning in the latent space to drive the generation process towards a target class. Competitive and decent results were achieved. However, all these methods, as mentioned previously, are classical fully-supervised learning techniques. In the sub-field of weakly-supervised learning (WSL), object detection and segmentation involve locating and segmenting with image labels [
24,
26,
33]. Object detection problems are solved with weakly-supervised learning as a classification problem by pooling layers in CNN models. In the work [
24] conducted by Durand et al., they used a weakly-supervised learning model to learn and localize visual parts that were related to class modalities. They were able to classify images, as well as supervise weakly the pointwise localization of objects and segmentation. Existing weakly-supervised learning methods were improved at three levels, where they made use of fully-convolutional networks (FCNs) as baseline models in their method. They aggregated spatial scores into a global prediction. Wang et al. [
34] improved on [
24] by using an iterative top-down and bottom-up architecture to expand object regions and also optimize the network. The method was further improved by [
35] to mine object locations and pixel labels via filtering and fusion of multiple pieces of evidence. They proposed an algorithm for filtering, fusing, and categorizing object instances collected from multiple solution mechanisms. The method achieved great success and challenged state-of-the-art algorithms. Ge et al. [
36] then combined the algorithms proposed in [
34,
35] using a bottom-up approach weakly-supervised learning to classify fine-grained images. They performed weakly-supervised instance detection and segmentation and proposed regions for Mask R-CNN [
37] by using Class Activation Maps (CAM) [
13]. They rectified the object regions and masks iteratively with Conditional Random Fields (CRF) [
38] as a way to prevent losing significant parts for object’s parts modeling. Given these successes, we adopted weakly-supervised learning to generate attention maps and selected the most important parts from multiple proposed parts in each image in an annotation-free scenario using attention cropping [
39]. In this way, we enhanced discriminative feature representation and at the same time captured wide feature parts.
However, one challenge in recent computer vision tasks is how to obtain a large amount of well-annotated data. The labeling challenge originates from two perspectives: First, a large number of labeled samples are required to be able to create a model that will easily generalize and precisely depict a real-world situation for a whole dataset. Secondly, different annotators have semantic gaps. There is no universal standard for the annotation of these samples, so different annotators give different positions for the same data samples. Furthermore, collecting images that capture all possible instances of objects in an ever-changing world is not feasible. Moreover, the burden of annotating is amplified more when we have to consider traffic sign recognition. In this setting, only experts will be able to provide well-labeled data for the recognition model.
Fortunately, through semi-supervised and weakly-supervised learning, a robust semi-supervised traffic sign recognition can to some extent alleviate the costly and laboriousannotations by utilizing unlabeled images. Techniques such as those in [
40,
41,
42,
43,
44] use self-training or similar concepts to utilize unlabeled samples for semi-supervised learning. A greedy unsupervised criterion has been used to generate and select the pseudo-labeled data for the retraining process of models. Most of the time, this criterion is the loss of the pseudo-labeled data, where its predicted approximate label is considered as the true label to calculate the loss [
41,
45]. Since no supervision is required during the retraining procedure and training the criterion function, the loss criterion has a high tendency of producing incorrect pseudo-labels and selecting incorrect pseudo-labeled data for the retraining process. This way, these incorrect pseudo-labeled data mislead the optimization of the classifier and detector with the consequence of reinforcing the wrong data in the unsupervised retraining phase. When it comes to the application of semi-supervised learning methods for the traffic sign recognition task, a few literature works can be found. He et al. proposed a novel semi-supervised learning method that combined global and local features for traffic sign recognition in an Internet of Things-based transport system [
46]. In that research, different feature spaces were built utilizing approaches such as the histogram of oriented gradients (HOG), color histograms (CH), and edge features (EF) for the labeled aspect and for the unlabeled data samples. He et al. used the fusion of the feature space to alleviate the differences between the varying feature spaces. By employing a semi-supervised tri-training, a classifier was trained to obtain a 98.7% recognition rate and also to solve a small sample problem. However, the authors failed to tackle the issue of class imbalance, which led to reinforcing incorrectly generated pseudo-labels as a result of the model holding on to the well-represented categories, causing the performance of some classifiers to decline eventually. Hillebrand et al. proposed applying semi-supervised co-training to classify German traffic signs [
1] prior to the study by He et al. In that research, Hillebrand et al. deployed an iterative co-training process where the most informative samples from a given pool of unlabeled traffic signs were automatically selected and then classified by two classifiers, which generated labels for each other [
1]. Extensive experiments were conducted on 14 classes of German traffic signs to obtain an accuracy of 98.0%, which would later be improved by the work of He et al. [
46].

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
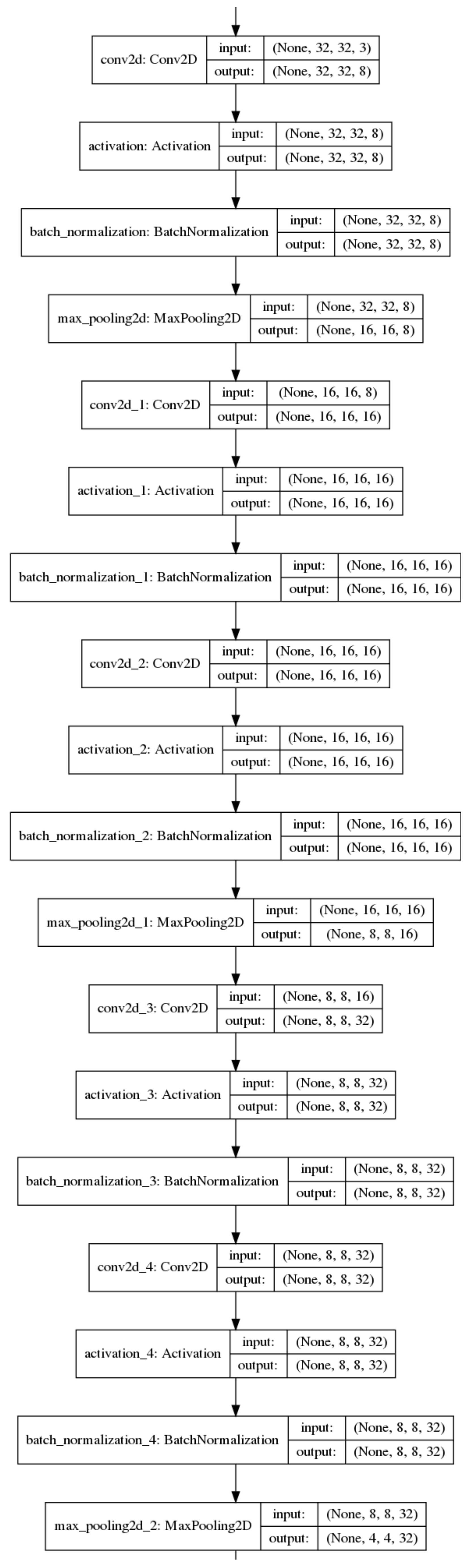{kind=link}
{kind=link}