Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
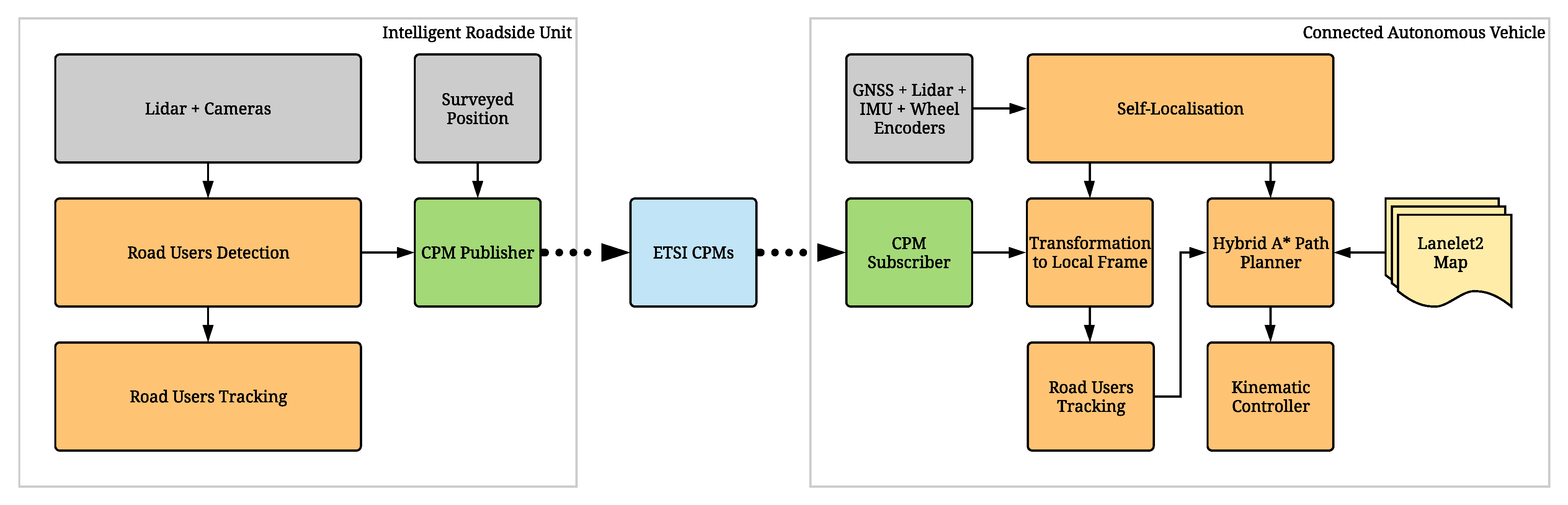
3. Platforms
3.1. Intelligent Roadside Unit
3.2. Connected and Automated Vehicle
3.3. Handling of ETSI CPMs on IRSU and CAV Platforms
- A CPM Management Container, which indicates station type, such as a vehicle or an IRSU, and reference position of the transmitting ITS-S.
- An optional Station Data Container, which provides additional information about the originating station. This includes the heading, speed, and dimensions when the originating station is a vehicle.
- Optional Sensor Information Containers, which describe the type and specifications of the equipped sensors of the transmitting ITS-S, including sensor IDs, types, and detection areas.
- Optional Perceived Object Containers, each of which describes the dynamics and properties of a perceived object, such as type, position, speed, heading, and dimensions. These perceived object descriptions are registered in the coordinate system of the originating station.
- Optional Free Space Addendum Containers, which describe different confidence levels for certain areas within the sensor detection areas.
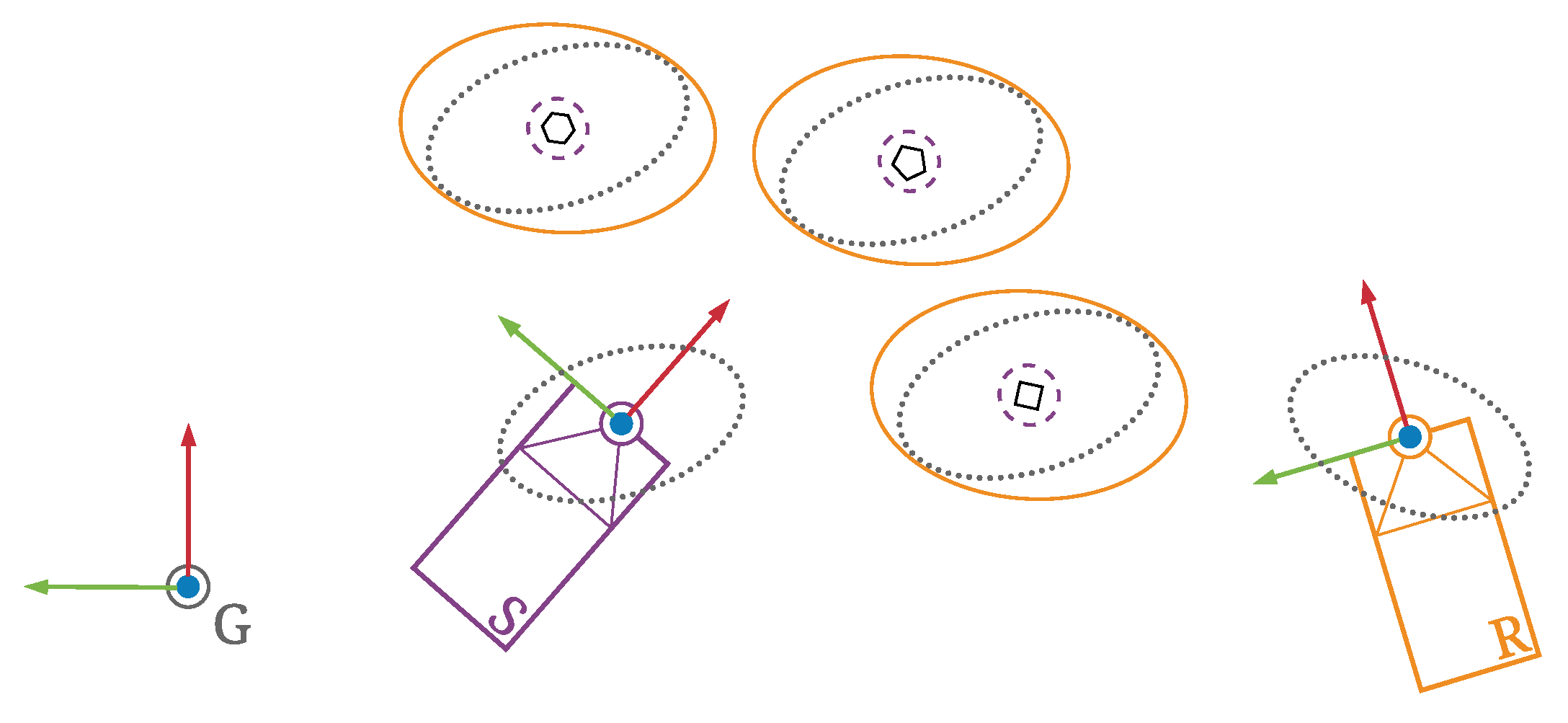
4. Coordinate Transformation of Perceived Objects with Uncertainty
- Perception uncertainty in the sensing ITS-S. Every commonly used perception sensor in ITS area has its own strengths and limitations. For instance, RGB images are useful in detecting object instances and classification of road users with an estimated confidence level using a visual classifier algorithm. Doppler RADARs produce both position and velocity measurements but are prone to noise and interference from the environment. Lidars have a high range resolution to observe physical extent and shape of objects. Nevertheless, the point density decreases dramatically along with range. These sensors all produce measurements corrupted by noise, and thus should be modelled with uncertainty. Combining multi-modal sensory information not only improves robustness of the perception system, but also increases accuracy, which means a lower level of uncertainty. The produced estimates of perceived objects with uncertainty have been represented in Perceived Object Containers of the CPM specification.
- Self-localisation uncertainty of sensing and receiving ITS-Ss. A vehicle ITS-S has to constantly localise itself within a global frame of reference such as a map or UTM frame for navigation and safety reasons. However, accurate self-localisation for a moving platform is known to be one of the existing challenges in ITS applications such as urban navigation. Using GNSS as the only source for localisation often cannot achieve satisfactory accuracy, in particular in GNSS-degraded or even GNSS-denied environments. There are various existing solutions that can provide higher localisation accuracy such as RTK, GNSS and inertial/encoder data fusion, feature based localisation based on existing map, etc. Nevertheless, even with the same localisation approach, the uncertainty magnitude in the localisation can vary significantly depending on certain external conditions, such as GNSS satellite visibility in the sky, and the quantity of observable features and their qualities in the surroundings. The location of an IRSU, although deployed static in a traffic environment, is not immune from localisation error either when set either by GNSS or through a surveying process. The localisation uncertainties of both sensing and receiving ITS-Ss therefore have to be considered in the perceived objects coordinate transformation since it cannot be completely eliminated regardless of the self-localisation means employed. The originating ITS-S information including its pose with associated uncertainty has been contained within the CPM Management Container and Station Data Container in the CPM definition.
4.1. Problem Formulation
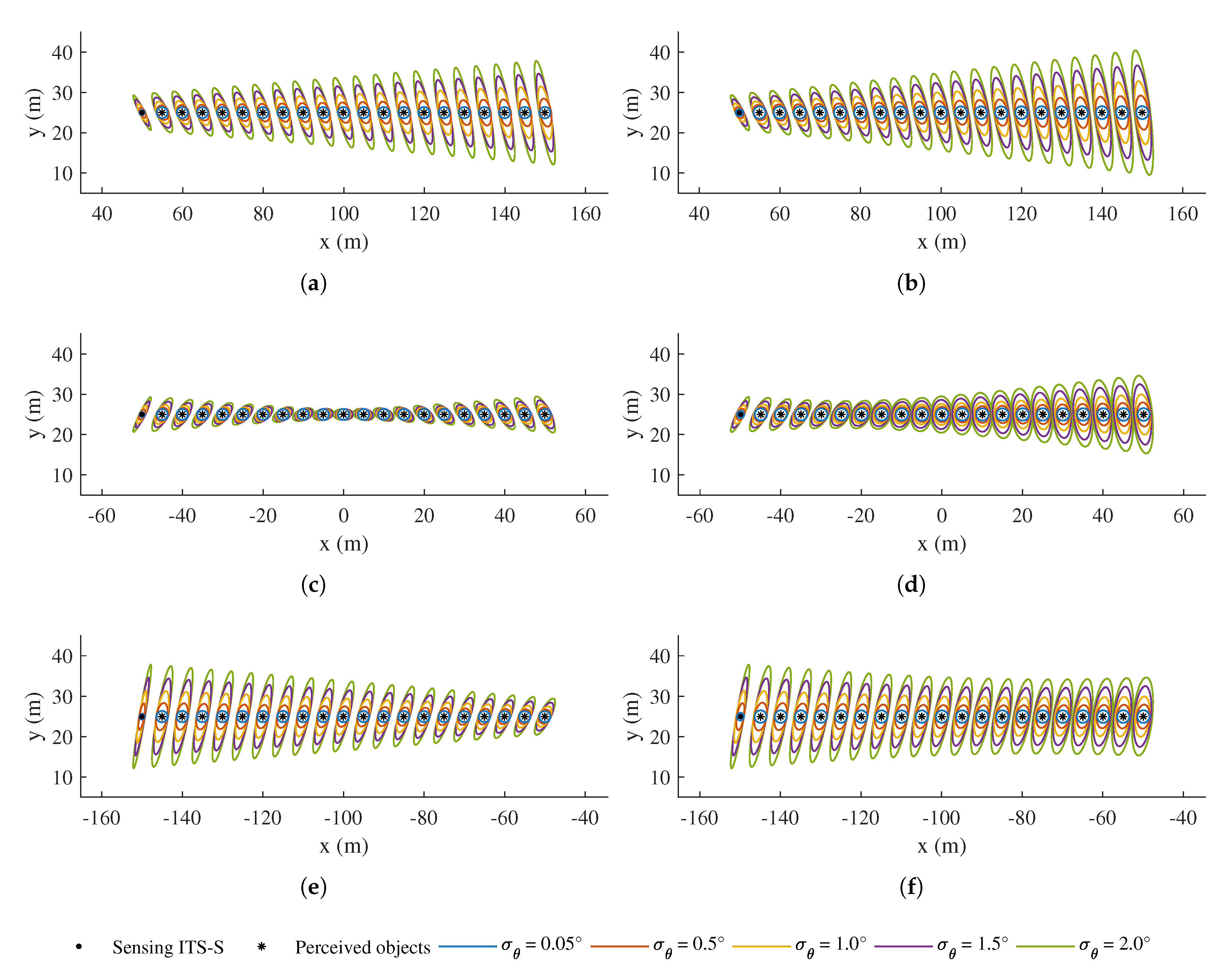
4.2. Numerical Simulation
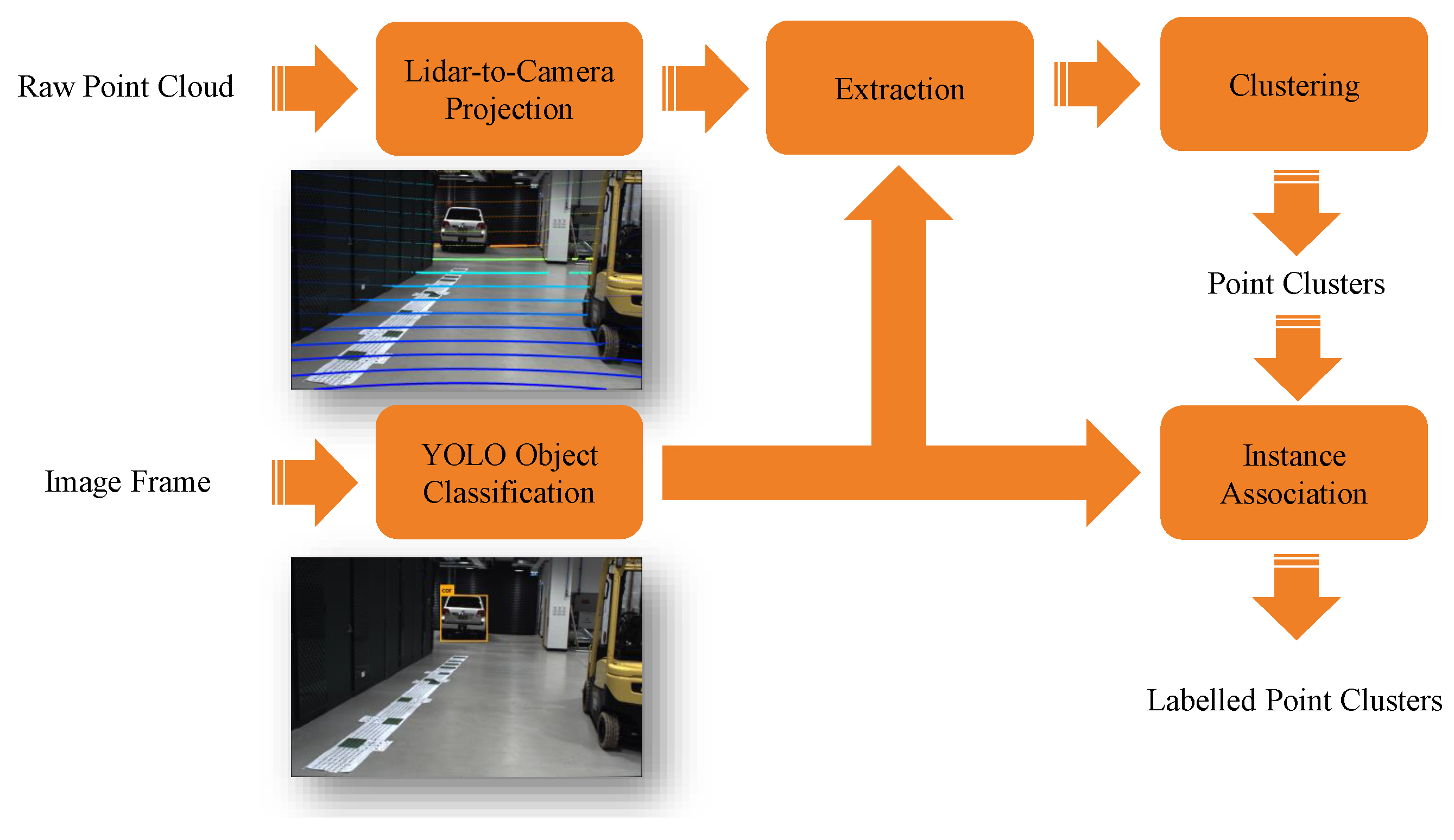
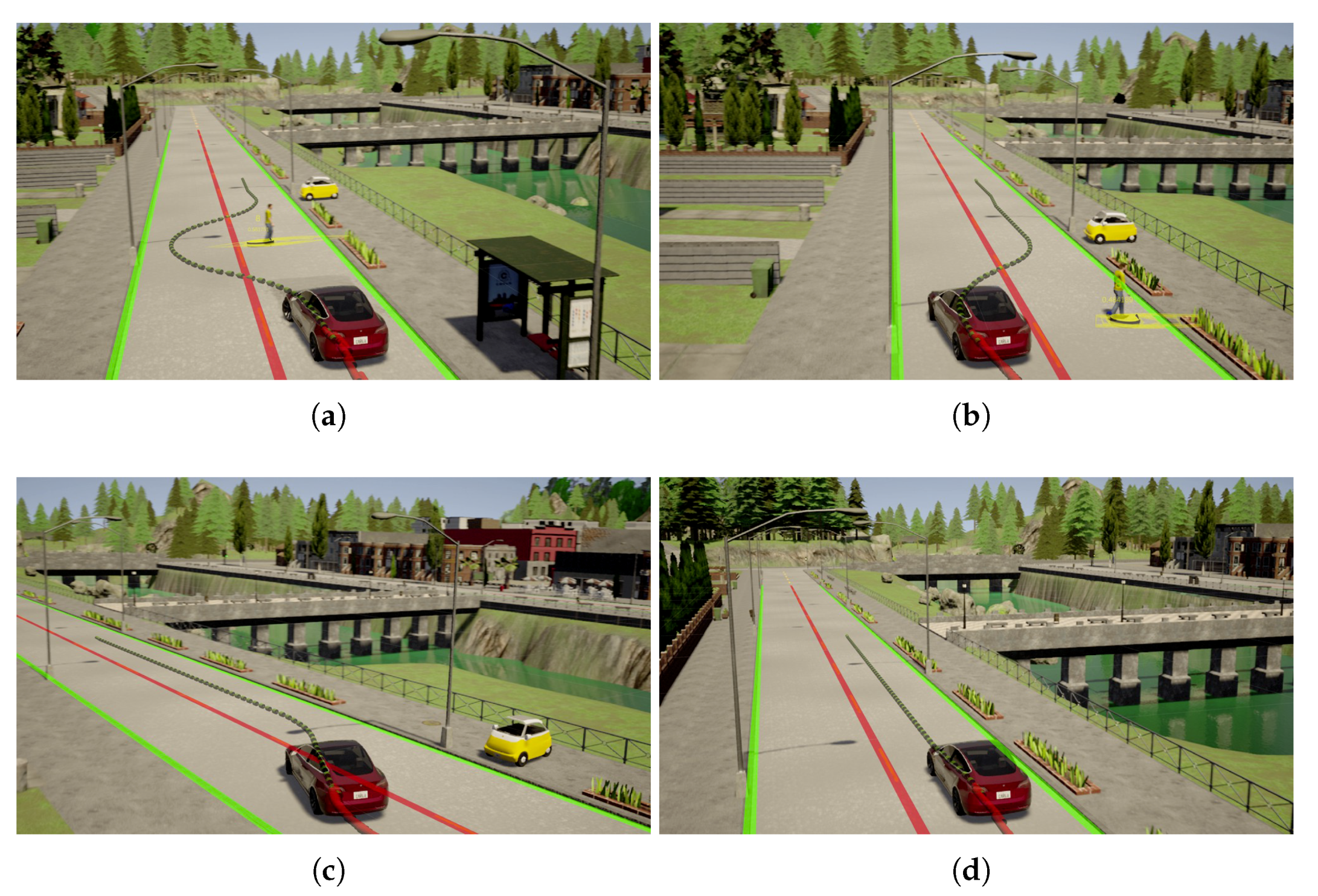
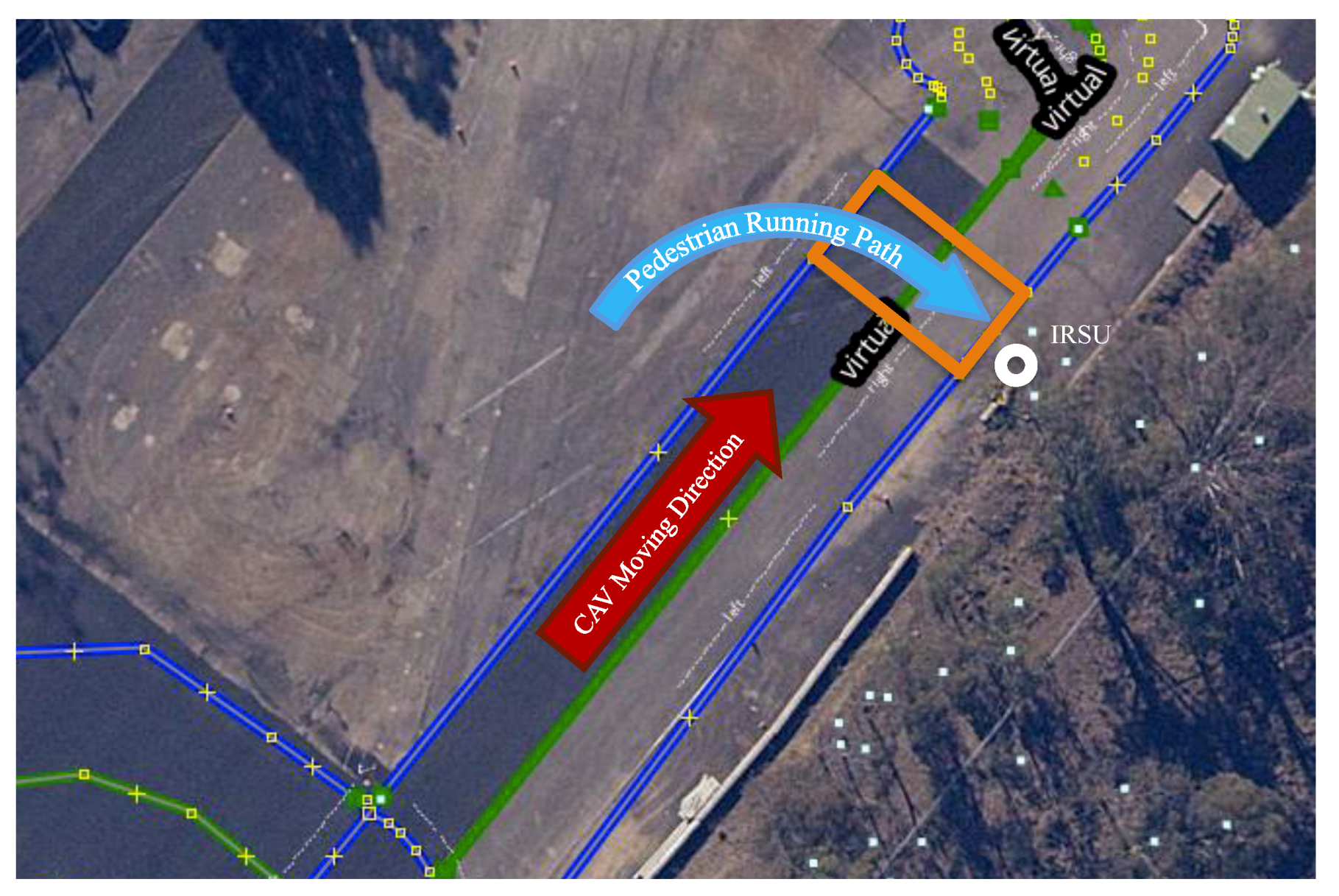
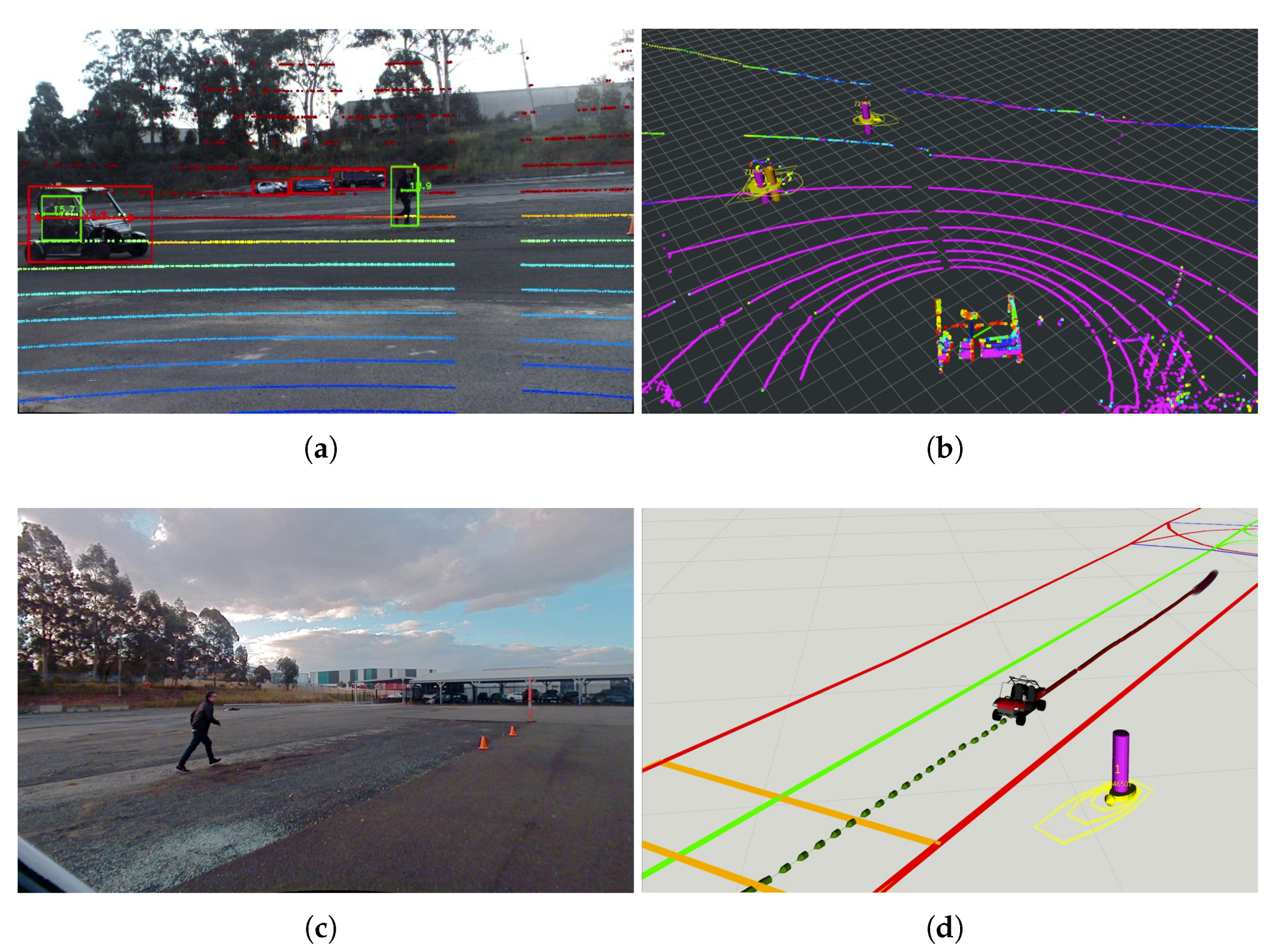
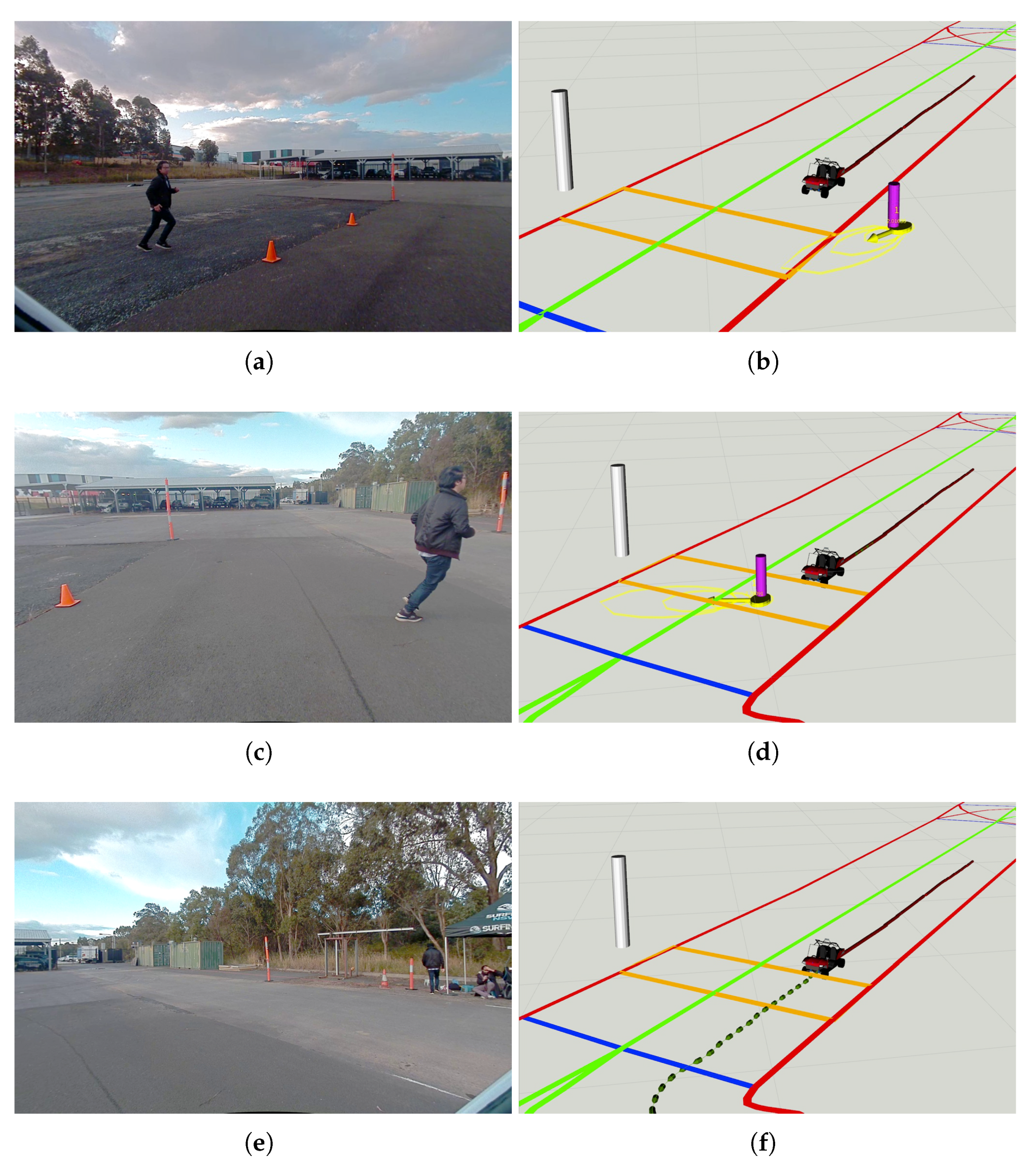
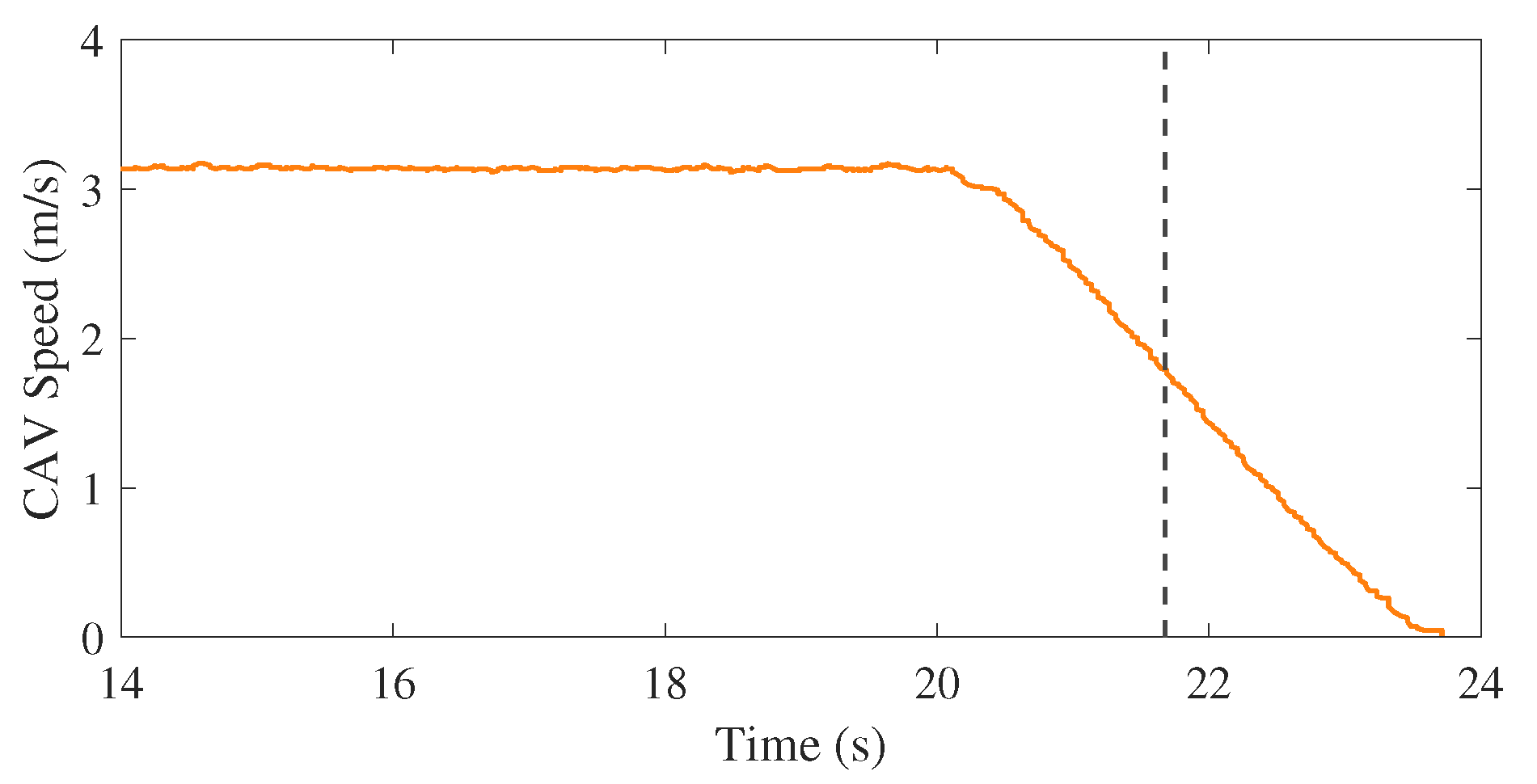
5. Demonstrations
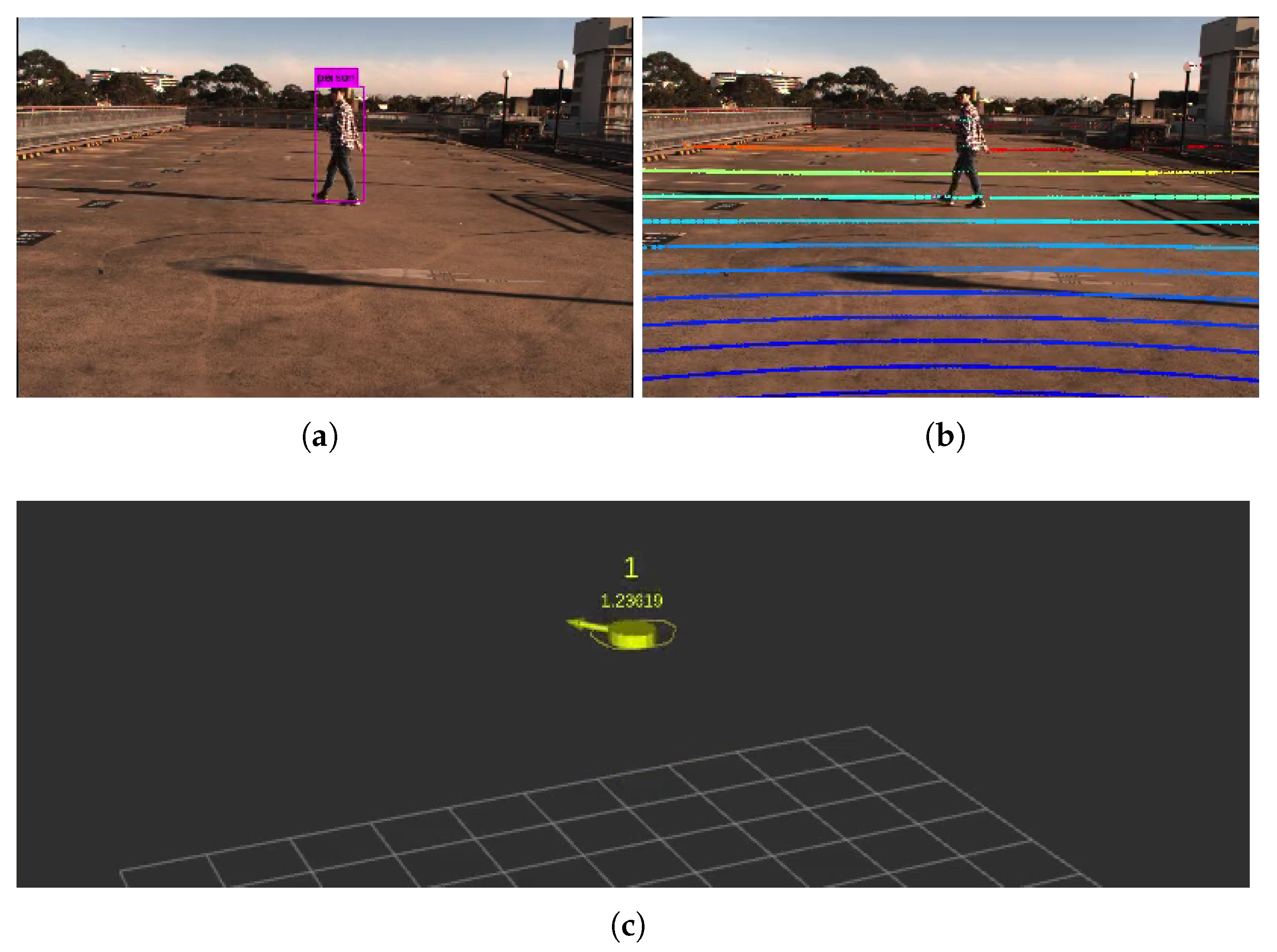
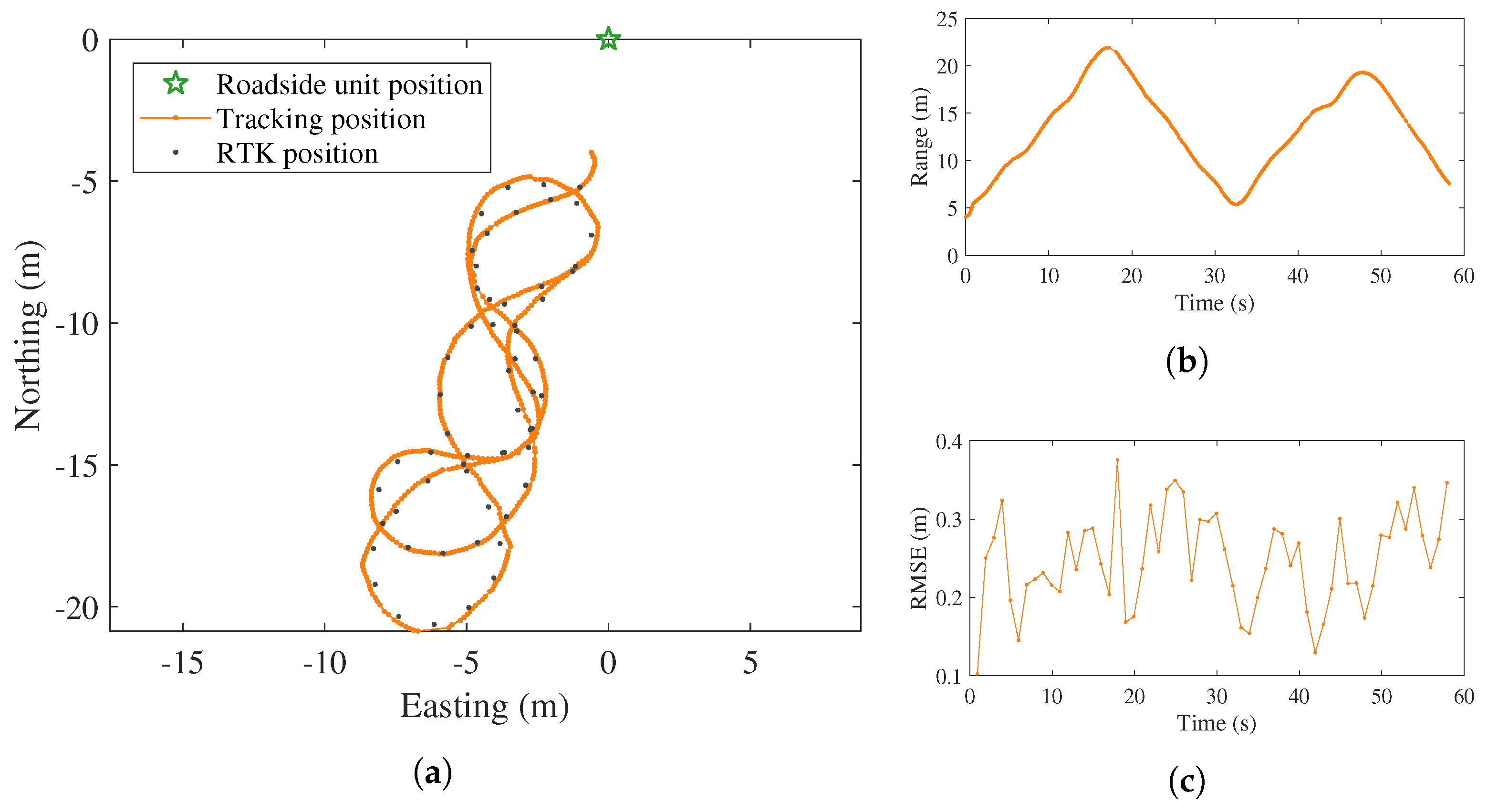
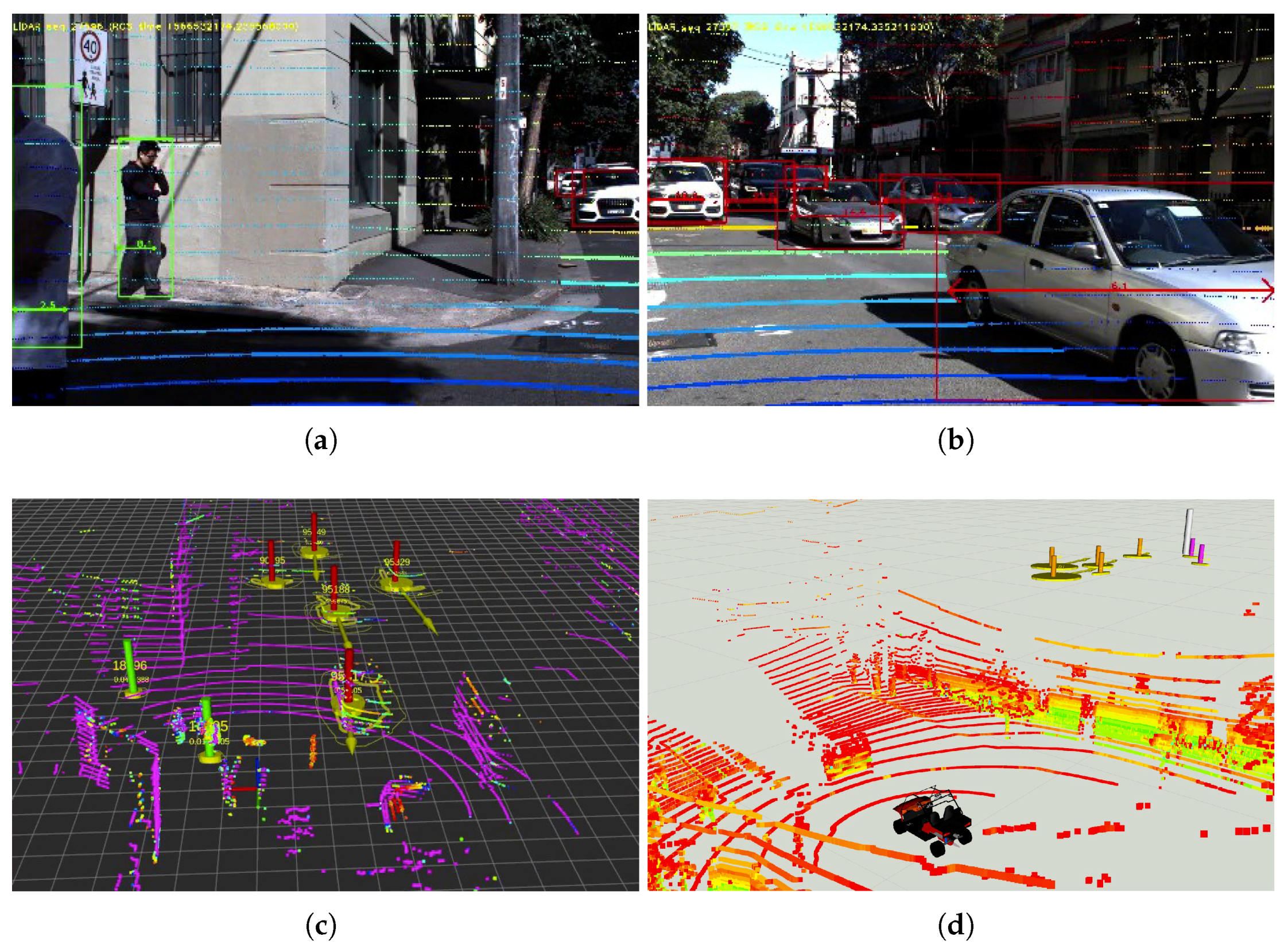
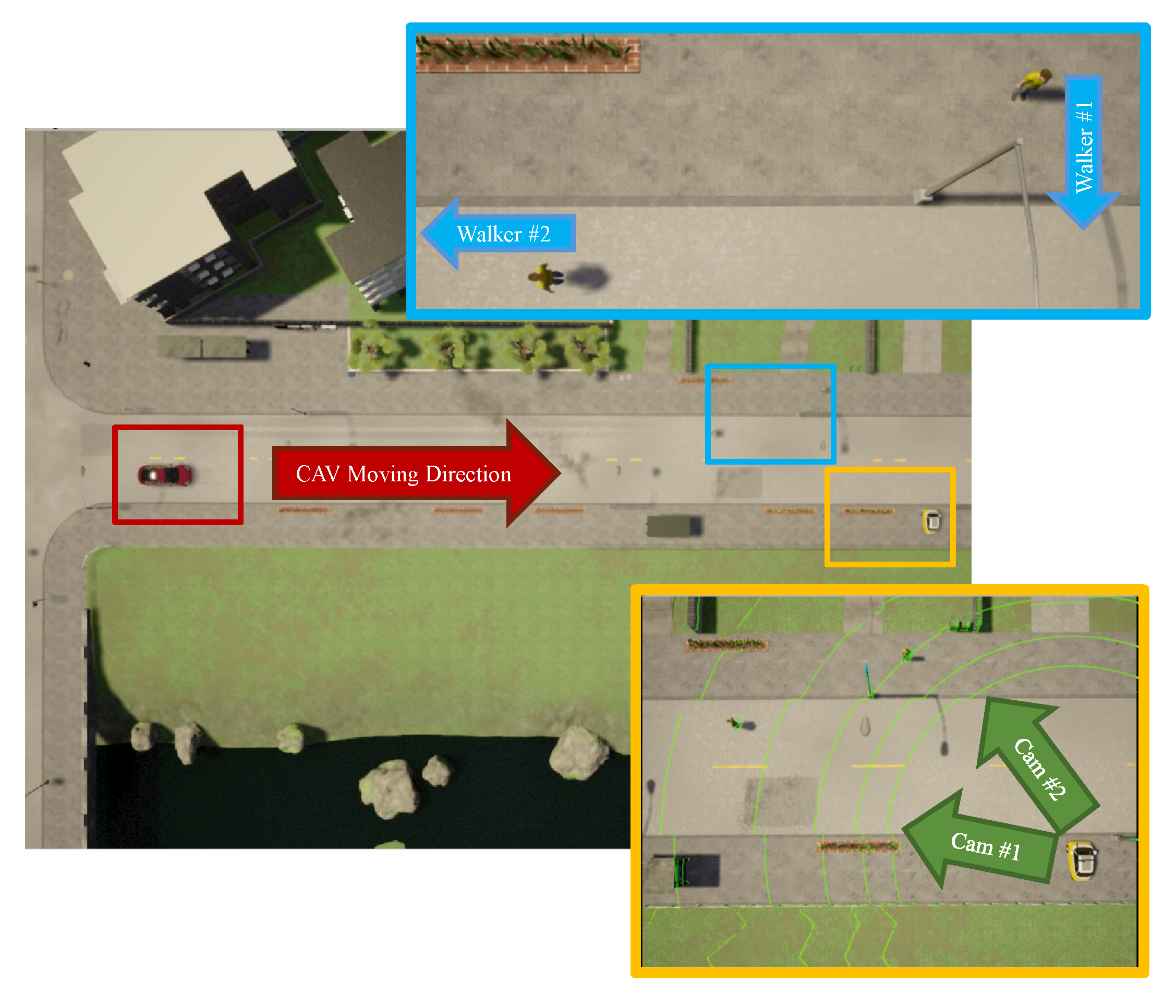
5.1. Experiment in an Urban Traffic Environment
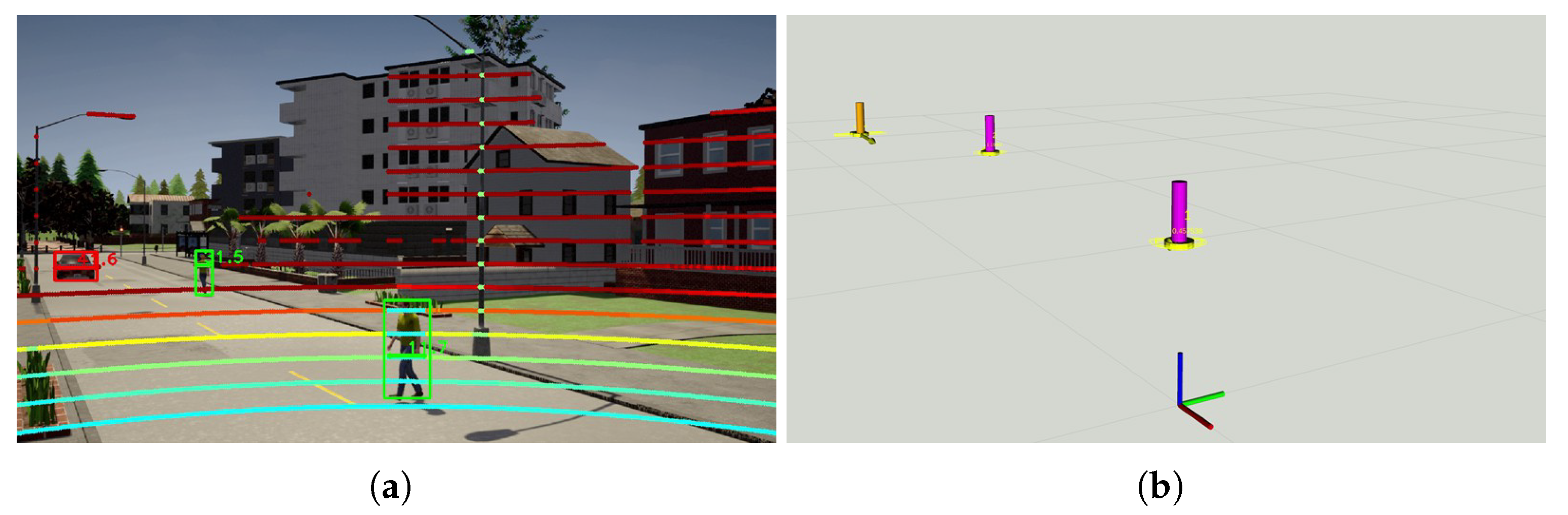
5.2. Experiment in the CARLA Simulator
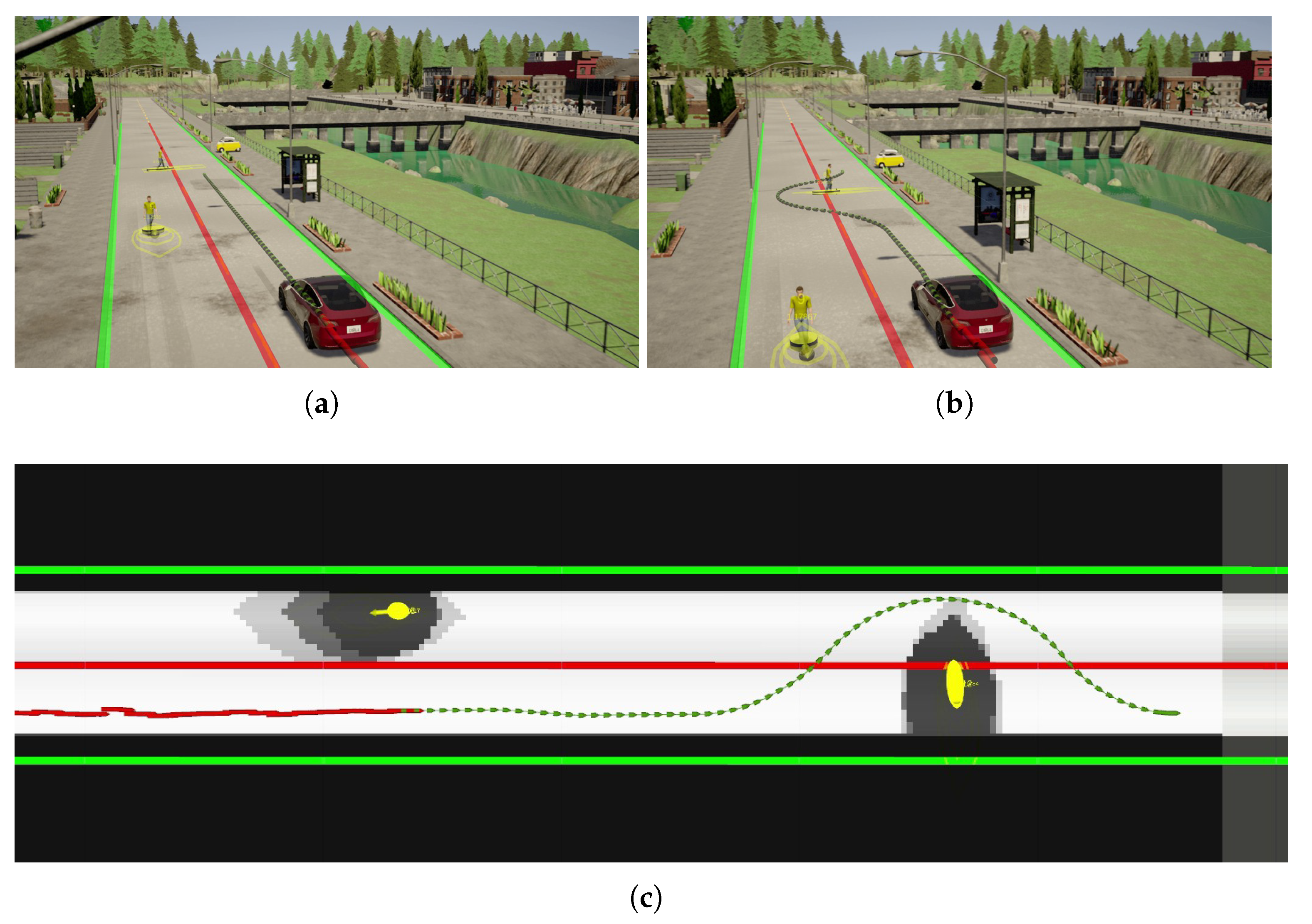
5.3. Experiment in a Lab Environment
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ACFR | Australian Centre for Field Robotics |
| ADAS | Advanced Driving Assistance System |
| AV | Autonomous Vehicle |
| CAM | Cooperative Awareness Message |
| CAV | Connected and Automated Vehicle |
| C-ITS | Cooperative Intelligent Transportation System |
| CP | Cooperative/Collective Perception |
| CPM | Collective Perception Message or Cooperative Perception Message |
| CSM | Cooperative Sensing Message |
| CV | Connected Vehicle |
| DE | Data Element |
| DF | Data Frames |
| EPM | Environmental Perception Message |
| ETSI | European Telecommunications Standard Institute |
| FOV | Field of View |
| GMPHD | Gaussian Mixture Probability Hypothesis Density |
| GMSL | Gigabit Multimedia Serial Link |
| GNSS | Global Navigation Satellite System |
| IMU | Inertial Measurement Unit |
| IRSU | Intelligent Roadside Unit |
| ITS | Intelligent Transportation System |
| ITS-S | Intelligent Transportation System Station |
| LTS | Long-Term Support |
| MAVEN | Managing Automated Vehicles Enhances Network |
| NUC | Next Unit of Computing |
| OMNeT++ | Open Modular Network Testbed in C++ |
| RMSE | Root Mean Squared Error |
| ROS | Robot Operation System |
| RSU | Roadside Unit |
| RTK | Real-Time Kinematic |
| SUMO | Simulation of Urban Mobility |
| UT | Unscented Transform |
| UTM | Universal Transverse Mercator |
| V2I | Vehicle-to-Infrastructure |
| V2V | Vehicle-to-Vehicle |
| V2X | Vehicle-to-X |
| Veins | Vehicles in Network Simulation |
| VRU | Vulnerable Road Users |
References
- Li, H.; Nashashibi, F. Multi-vehicle Cooperative Perception and Augmented Reality for Driver Assistance: A Possibility to ‘See’ Through Front Vehicle. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 242–247. [Google Scholar]
- Kumar, S.; Shi, L.; Ahmed, N.; Gil, S.; Katabi, D.; Rus, D. CarSpeak: A Content-Centric Network for Autonomous Driving. ACM SIGCOMM Comput. Commun. Rev. 2012, 42, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Mourllion, B.; Lambert, A.; Gruyer, D.; Aubert, D. Collaborative Perception for Collision Avoidance. In Proceedings of the IEEE International Conference on Networking, Sensing & Control, Taipei, Taiwan, 21–23 March 2004; pp. 880–885. [Google Scholar]
- Kim, S.W.; Chong, Z.J.; Qin, B.; Shen, X.; Cheng, Z.; Liu, W.; An, M.H., Jr. Cooperative Perception for Autonomous Vehicle Control on the Road: Motivation and Experimental Results. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 5059–5066. [Google Scholar]
- Kim, S.W.; Qin, B.; Chong, Z.J.; Shen, X.; Liu, W.; Ang, M.H., Jr.; Frazzoli, E.; Rus, D. Multivehicle Cooperative Driving Using Cooperative Perception: Design and Experimental Validation. IEEE Trans. Intell. Transp. Syst. 2015, 16, 663–680. [Google Scholar] [CrossRef]
- Karam, N.; Chaussel, F.; Aufrère, R.; Chapuis, R. Cooperative Multi-Vehicle Localization. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Tokyo, Japan, 13–15 June 2006; pp. 564–570. [Google Scholar]
- Shan, M.; Worrall, S.; Nebot, E. Nonparametric cooperative tracking in mobile Ad-Hoc networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 423–430. [Google Scholar]
- Ko-FAS. Available online: http://www.ko-fas.de (accessed on 23 October 2020).
- Rauch, A.; Klanner, F.; Dietmayer, K. Analysis of V2X Communication Parameters for the Development of a Fusion Architecture for Cooperative Perception Systems. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 685–690. [Google Scholar]
- Rauch, A.; Klanner, F.; Rasshofer, R.; Dietmayer, K. Car2X-Based Perception in a High-Level Fusion Architecture for Cooperative Perception Systems. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Alcalá de Henares, Spain, 3–7 June 2012; pp. 270–275. [Google Scholar]
- Rauch, A.; Maier, S.; Klanner, F.; Dietmayer, K. Inter-Vehicle Object Association for Cooperative Perception Systems. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), The Hague, The Netherlands, 6–9 October 2013; pp. 893–898. [Google Scholar]
- Allig, C.; Wanielik, G. Dynamic Dissemination Method for Collective Perception. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3756–3762. [Google Scholar]
- Günther, H.J.; Mennenga, B.; Trauer, O.; Riebl, R.; Wolf, L. Realizing Collective Perception in a Vehicle. In Proceedings of the IEEE Vehicular Networking Conference (VNC), Columbus, OH, USA, 8–10 December 2016. [Google Scholar]
- AutoNet2030. Available online: http://www.autonet2030.eu (accessed on 23 October 2020).
- Hobert, L. AutoNet2030—Specifications for the Enhancement to Existing LDM and Cooperative Communication Protocol Standards. In AutoNet2030 Deliverable D3.2. 2015. Available online: https://docplayer.net/32233291-Specifications-for-the-enhancement-to-existing-ldm-and-cooperative-communication-protocol-standards.html (accessed on 29 November 2020).
- Hobert, L.; Festag, A.; Llatser, I.; Altomare, L.; Visintainer, F.; Kovacs, A. Enhancements of V2X Communication in Support of Cooperative Autonomous Driving. IEEE Commun. Mag. 2015, 53, 64–70. [Google Scholar] [CrossRef]
- Kitazato, T.; Tsukada, M.; Ochiai, H.; Esaki, H. Proxy Cooperative Awareness Message: An Infrastructure-Assisted V2V Messaging. In Proceedings of the Ninth International Conference on Mobile Computing and Ubiquitous Networking (ICMU), Kaiserslautern, Germany, 4–6 October 2016. [Google Scholar]
- Tsukada, M. Roadside-Assisted V2V Messaging for Connected Autonomous Vehicle. In Proceedings of the Thirteenth International Conference on Wireless and Mobile Communications (ICWMC), Nice, France, 23–27 July 2017. [Google Scholar]
- Tsukada, M.; Oi, T.; Kitazawa, M.; Esaki, H. Networked Roadside Perception Units for Autonomous Driving. Sensors 2020, 20, 5320. [Google Scholar] [CrossRef] [PubMed]
- Burgstahler, D.M. Collaborative Sensing in Automotive Scenarios: Enhancement of the Vehicular Electronic Horizon through Collaboratively Sensed Knowledge. Ph.D. Thesis, Technical University of Darmstadt, Darmstadt, Germany, 2017. [Google Scholar]
- Günther, H.J.; Riebl, R.; Wolf, L.; Facchi, C. Collective Perception and Decentralized Congestion Control in Vehicular Ad-hoc Networks. In Proceedings of the IEEE Vehicular Networking Conference (VNC), Columbus, OH, USA, 8–10 December 2016. [Google Scholar]
- Günther, H.J.; Riebl, R.; Wolf, L.; Facchi, C. The Effect of Decentralized Congestion Control on Collective Perception in Dense Traffic Scenarios. Comput. Commun. 2018, 122, 76–83. [Google Scholar] [CrossRef]
- ETSI ITS. Technical Report: Intelligent Transport System (ITS); Vehicular Communications; Basic Set of Applications; Analysis of the Collective Perception Service (CPS); Release 2. ETSI TR. 103 562 V2.1.1; 2019; Available online: https://www.etsi.org/deliver/etsi_tr/103500_103599/103562/02.01.01_60/tr_103562v020101p.pdf (accessed on 29 November 2020).
- SAE Advanced Applications Technical Committee. V2X Sensor-Sharing for Cooperative & Automated Driving. SAE J3224. Available online: https://www.sae.org/servlets/works/committeeHome.do?comtID=TEVCSC3 (accessed on 23 October 2020).
- Garlichs, K.; Günther, H.J.; Wolf, L.C. Generation Rules for the Collective Perception Service. In Proceedings of the IEEE Vehicular Networking Conference (VNC), Los Angeles, CA, USA, 4–6 December 2019. [Google Scholar]
- Thandavarayan, G.; Sepulcre, M.; Gozalvez, J. Analysis of Message Generation Rules for Collective Perception in Connected and Automated Driving. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019. [Google Scholar]
- Huang, H.; Fang, W.; Li, H. Performance Modelling of V2V based Collective Perceptions in Connected and Autonomous Vehicles. In Proceedings of the IEEE 44th Conference on Local Computer Networks (LCN), Osnabrueck, Germany, 14–17 October 2019; pp. 356–363. [Google Scholar]
- Huang, H.; Li, H.; Shao, C.; Sun, T.; Fang, W.; Dang, S. Data Redundancy Mitigation in V2X Based Collective Perceptions. IEEE Access 2020, 8, 13405–13418. [Google Scholar] [CrossRef]
- Thandavarayan, G.; Sepulcre, M.; Gozalvez, J. Generation of Cooperative Perception Messages for Connected and Automated Vehicles. arXiv 2019, arXiv:cs.NI/1908.11151. [Google Scholar] [CrossRef]
- Delooz, Q.; Festag, A. Network Load Adaptation for Collective Perception in V2X Communications. In Proceedings of the IEEE International Conference on Connected Vehicles and Expo (ICCVE), Graz, Austria, 4–8 November 2019. [Google Scholar]
- Aoki, S.; Higuchi, T.; Altintas, O. Cooperative Perception with Deep Reinforcement Learning for Connected Vehicles. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 20–23 October 2020. [Google Scholar]
- Günther, H.J.; Trauer, O.; Wolf, L. The Potential of Collective Perception in Vehicular Ad-hoc Networks. In Proceedings of the 14th International Conference on ITS Telecommunications (ITST), Copenhagen, Denmark, 2–4 December 2015; pp. 1–5. [Google Scholar]
- Schiegg, F.A.; Brahmi, N.; Llatser, I. Analytical Performance Evaluation of the Collective Perception Service in IEEE 802.11p Networks. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 181–188. [Google Scholar]
- Schiegg, F.A.; Bischoff, D.; Krost, J.R.; Llatser, I. Analytical Performance Evaluation of the Collective Perception Service in C-V2X Mode 4 Networks. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Korea, 25–28 May 2020. [Google Scholar]
- Bian, K.; Zhang, G.; Song, L. Toward Secure Crowd Sensing in Vehicle-to-Everything Networks. IEEE Netw. 2018, 32, 126–131. [Google Scholar] [CrossRef]
- Ambrosin, M.; Yang, L.L.; Liu, X.; Sastry, M.R.; Alvarez, I.J. Design of a Misbehavior Detection System for Objects Based Shared Perception V2X Applications. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1165–1172. [Google Scholar]
- Seeliger, F.; Weidl, G.; Petrich, D.; Naujoks, F.; Breuel, G.; Neukum, A.; Dietmayer, K. Advisory Warnings Based on Cooperative Perception. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Dearborn, MI, USA, 8–11 June 2014; pp. 246–252. [Google Scholar]
- Naujoks, F.; Grattenthaler, H.; Neukum, A.; Weidl, G.; Petrich, D. Effectiveness of advisory warnings based on cooperative perception. IET Intell. Transp. Syst. 2015, 9, 606–617. [Google Scholar] [CrossRef] [Green Version]
- Deng, R.; Di, B.; Song, L. Cooperative Collision Avoidance Scheme Design and Analysis in V2X-based Driving Systems. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018. [Google Scholar]
- Rondinone, M.; Walter, T.; Blokpoel, R.; Schindler, J. V2X communications for infrastructure-assisted automated driving. In Proceedings of the IEEE 19th International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Chania, Greece, 12–15 June 2018. [Google Scholar]
- Kamel, J.; Ansari, M.R.; Petit, J.; Kaiser, A.; Jemaa, I.B.; Urien, P. Simulation Framework for Misbehavior Detection in Vehicular Networks. IEEE Trans. Veh. Technol. 2020, 69, 6631–6643. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; de Veciana, G.; Shimizu, T.; Lu, H. Performance and Scaling of Collaborative Sensing and Networking for Automated Driving Applications. In Proceedings of the IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Merdrignac, P.; Shagdar, O.; Tohmé, S.; Franchineau, J.L. Augmented Perception by V2X Communication for Safety of Autonomous and Non-Autonomous Vehicles. In Proceedings of the 7th Transport Research Arena TRA 2018, Vienna, Austria, 16–19 April 2018. [Google Scholar]
- Jandial, A.; Merdrignac, P.; Shagdar, O.; Fevrier, L. Implementation and Evaluation of Intelligent Roadside Infrastructure for Automated Vehicle with I2V Communication. In Vehicular Ad-hoc Networks for Smart Cities: Third International Workshop, 2019 (Advances in Intelligent Systems and Computing 1144); Springer: Singapore, 2019; pp. 3–18. ISBN 978-981-15-3749-3. [Google Scholar]
- Managing Automated Vehicles Enhances Network (MAVEN). Available online: http://www.maven-its.eu (accessed on 23 October 2020).
- Khan, S.; Andert, F.; Wojke, N.; Schindler, J.; Correa, A.; Wijbenga, A. Towards Collaborative Perception for Automated Vehicles in Heterogeneous Traffic. In Advanced Microsystems for Automotive Applications 2018; Springer: Cham, Switzerland, 2019; pp. 31–42. ISBN 978-3-319-99762-9. [Google Scholar]
- Llatser, I.; Michalke, T.; Dolgov, M.; Wildschütte, F.; Fuchs, H. Cooperative Automated Driving Use Cases for 5G V2X Communication. In Proceedings of the IEEE 2nd 5G World Forum (5GWF), Dresden, Germany, 30 September–2 October 2019; pp. 120–125. [Google Scholar]
- Simulation of Urban MObility (SUMO). Available online: https://www.eclipse.org/sumo (accessed on 23 October 2020).
- Vehicles in Network Simulation (VEINS): The Open Source Vehicular Network Simulation Framework. Available online: https://veins.car2x.org (accessed on 23 October 2020).
- Sommer, C.; German, R.; Dressler, F. Bidirectionally Coupled Network and Road Traffic Simulation for Improved IVC Analysis. IEEE Trans. Mob. Comput. 2011, 10, 3–15. [Google Scholar] [CrossRef] [Green Version]
- OMNet++: Discrete Event Simulator. Available online: https://omnetpp.org (accessed on 23 October 2020).
- Garlichs, K.; Wegner, M.; Wolf, L.C. Realizing Collective Perception in the Artery Simulation Framework. In Proceedings of the IEEE Vehicular Networking Conference (VNC), Taipei, Taiwan, 5–7 December 2018. [Google Scholar]
- Artery: V2X Simulation Framework. Available online: http://artery.v2x-research.eu (accessed on 23 October 2020).
- Riebl, R.; Günther, H.J.; Facchi, C.; Wolf, L. Artery: Extending Veins for VANET applications. In Proceedings of the International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Budapest, Hungary, 3–5 June 2015; pp. 450–456. [Google Scholar]
- CARLA: Open-Source Simulator for Autonomous Driving Research. Available online: https://carla.org (accessed on 23 October 2020).
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; López, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning (CoRL), Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Vo, B.N.; Ma, W.K. The Gaussian Mixture Probability Hypothesis Density Filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Verma, S.; Berrio, J.S.; Worrall, S.; Nebot, E. Automatic extrinsic calibration between a camera and a 3D Lidar using 3D point and plane correspondences. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3906–3912. [Google Scholar]
- Zhou, W.; Berrio, J.S.; De Alvis, C.; Shan, M.; Worrall, S.; Ward, J.; Nebot, E. Developing and Testing Robust Autonomy: The University of Sydney Campus Data Set. IEEE Intell. Transp. Syst. Mag. 2020, 12, 23–40. [Google Scholar] [CrossRef]
- Yi, S.; Worrall, S.; Nebot, E. Geographical Map Registration and Fusion of Lidar-Aerial Orthoimagery in GIS. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 128–134. [Google Scholar]
- Narula, K.; Worrall, S.; Nebot, E. Two-Level Hierarchical Planning in a Known Semi-Structured Environment. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Rhodes, Greece, 20–23 September 2019; pp. 1344–1349. [Google Scholar]
- Allig, C.; Wanielik, G. Alignment of Perception Information for Cooperative Perception. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1849–1854. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
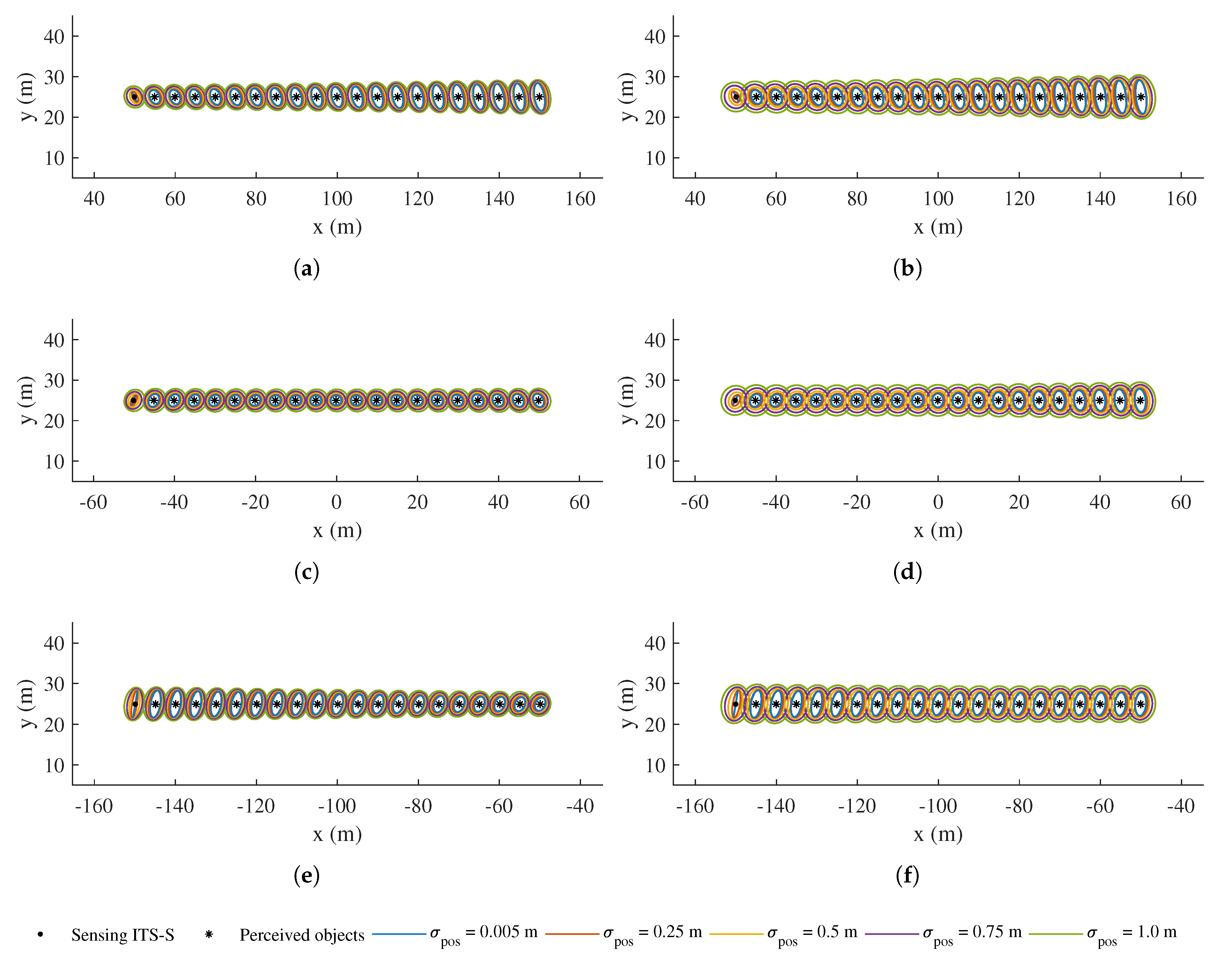{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standard Deviation in State Estimate | |||
|---|---|---|---|
| Position | Heading | ||
| Perceived Objects | 0.5 m | ||
| Sensing ITS-S | IRSU | 0.005 m | |
| CAV | Same as Receiving CAV | ||
| Receiving CAV | Test 1 | 0.25 m | |
| Test 2 | 0.005 m, 0.25 m, 0.5 m, 0.75 m, 1.0 m | ||
| Configuration | Experiment No. | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| Environment | Real Urban Traffic Env. | CARLA Simulator | Real Lab Traffic Env. |
| IRSU Perception Sensors | Real Lidar + Cameras | Simulated Lidar + Cameras | Real Lidar + Cameras |
| Pedestrian(s) Activity | Walking + Standing | Walking | Running |
| V2I Communication | Cohda Wireless MK5 | Simulated | Cohda Wireless MK5 |
| CAV Driving Mode | Manual | Autonomous | Autonomous |
| CAV Perception Sensors | Disabled | Disabled | Real Lidar 1 |
| CAV Self-Localisation 2 | Lidar Features + GNSS | Simulated GNSS | Lidar Features + GNSS |
| Multi-Target Tracking 3 | GMPHD Tracker | GMPHD Tracker | GMPHD Tracker |
| CAV Navigation | N.A. | Hybrid A* Path Planning on Lanelet2 Map | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, M.; Narula, K.; Wong, Y.F.; Worrall, S.; Khan, M.; Alexander, P.; Nebot, E. Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations. Sensors 2021, 21, 200. https://doi.org/10.3390/s21010200
Shan M, Narula K, Wong YF, Worrall S, Khan M, Alexander P, Nebot E. Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations. Sensors. 2021; 21(1):200. https://doi.org/10.3390/s21010200
Chicago/Turabian StyleShan, Mao, Karan Narula, Yung Fei Wong, Stewart Worrall, Malik Khan, Paul Alexander, and Eduardo Nebot. 2021. "Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations" Sensors 21, no. 1: 200. https://doi.org/10.3390/s21010200
APA StyleShan, M., Narula, K., Wong, Y. F., Worrall, S., Khan, M., Alexander, P., & Nebot, E. (2021). Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations. Sensors, 21(1), 200. https://doi.org/10.3390/s21010200