
A Fully Convolutional Network-Based Tube Contour Detection Method Using Multi-Exposure Images


Abstract
:1. Introduction
1.1. Related Work
1.1.1. Gradient-Based Methods

1.1.2. Multiple Feature-Based Methods
1.1.3. Deep Learning-Based Methods
- Poor tube image quality. For metallic tubes, some areas in the scene may exceed the dynamic range of camera sensor due to problems such as reflections, shadows and uneven lighting, which also means over-saturated or under-saturated regions may appear in tube images. One single low dynamic range (LDR) image cannot provide complete and absolute tube contour information in the process of detection;
- Low contour label accuracy. It is difficult to accurately label the tube contours by manual, and the binary labels naturally have jagged morphology instead of ideal smooth contours. These factors will directly affect the performance of networks.
1.2. Contributions
- We propose to use high-resolution multi-exposure (ME) images as the input of an FCN model. These ME images of different dynamic ranges can guarantee the integrity of tube contour information;
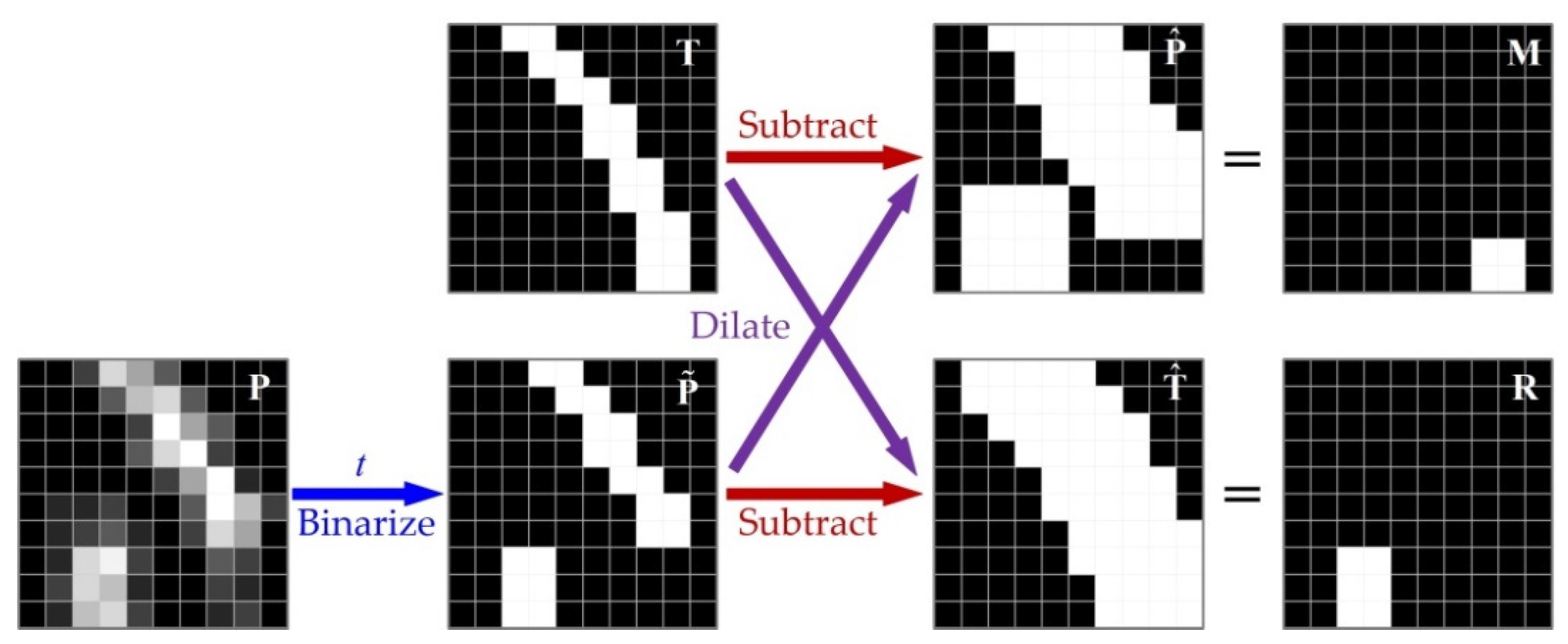
- A new loss function, which is calculated based on dilated contours, is introduced and used in the training of FCN. Minimizing this loss function will help to eliminate the adverse effects caused by positional deviation and jagged morphology of tube contour labels;
- We present a new dataset and a new evaluation metric to verify the effectiveness of our proposed method in the tube contour detection task.
2. Method
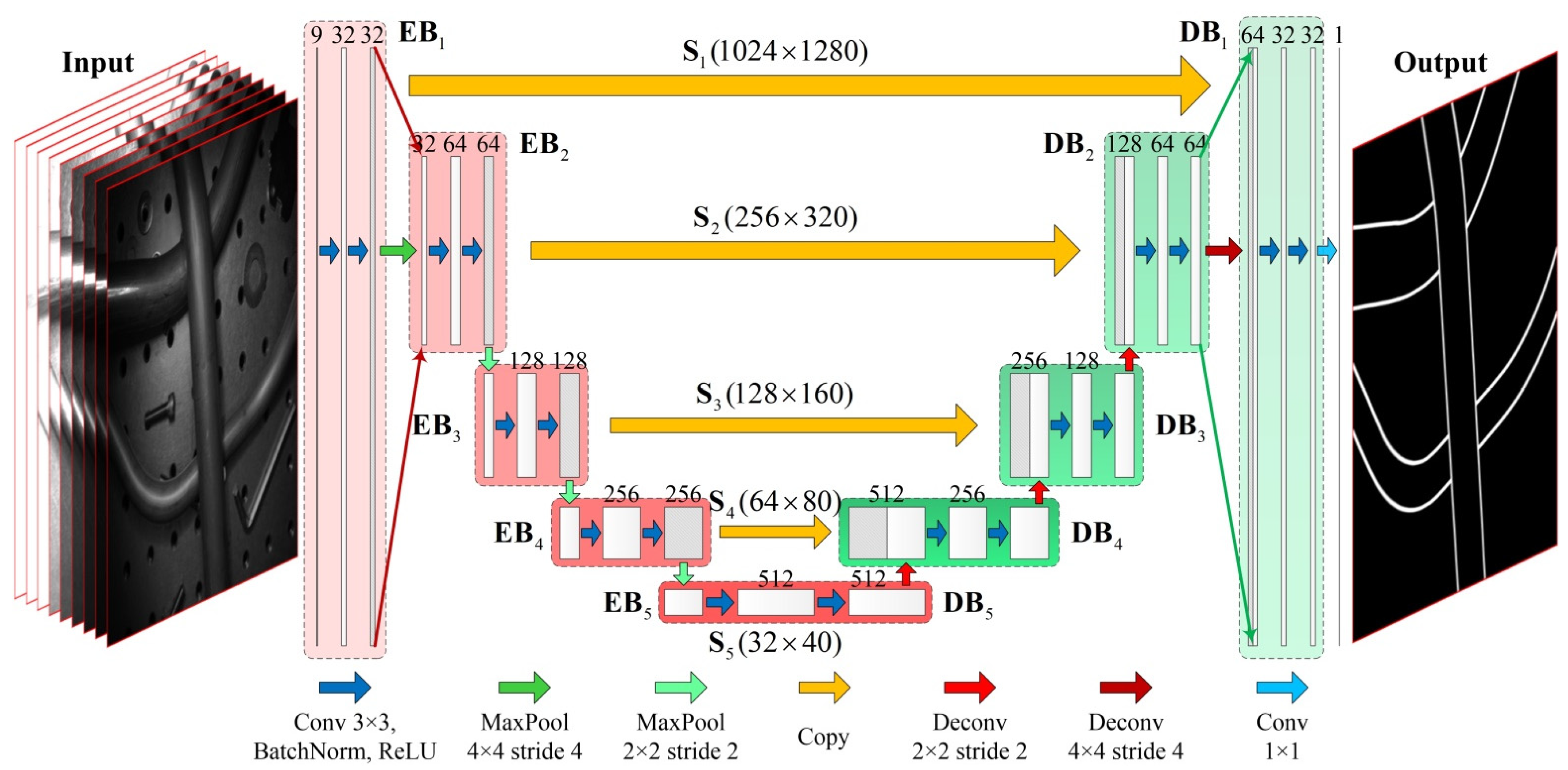
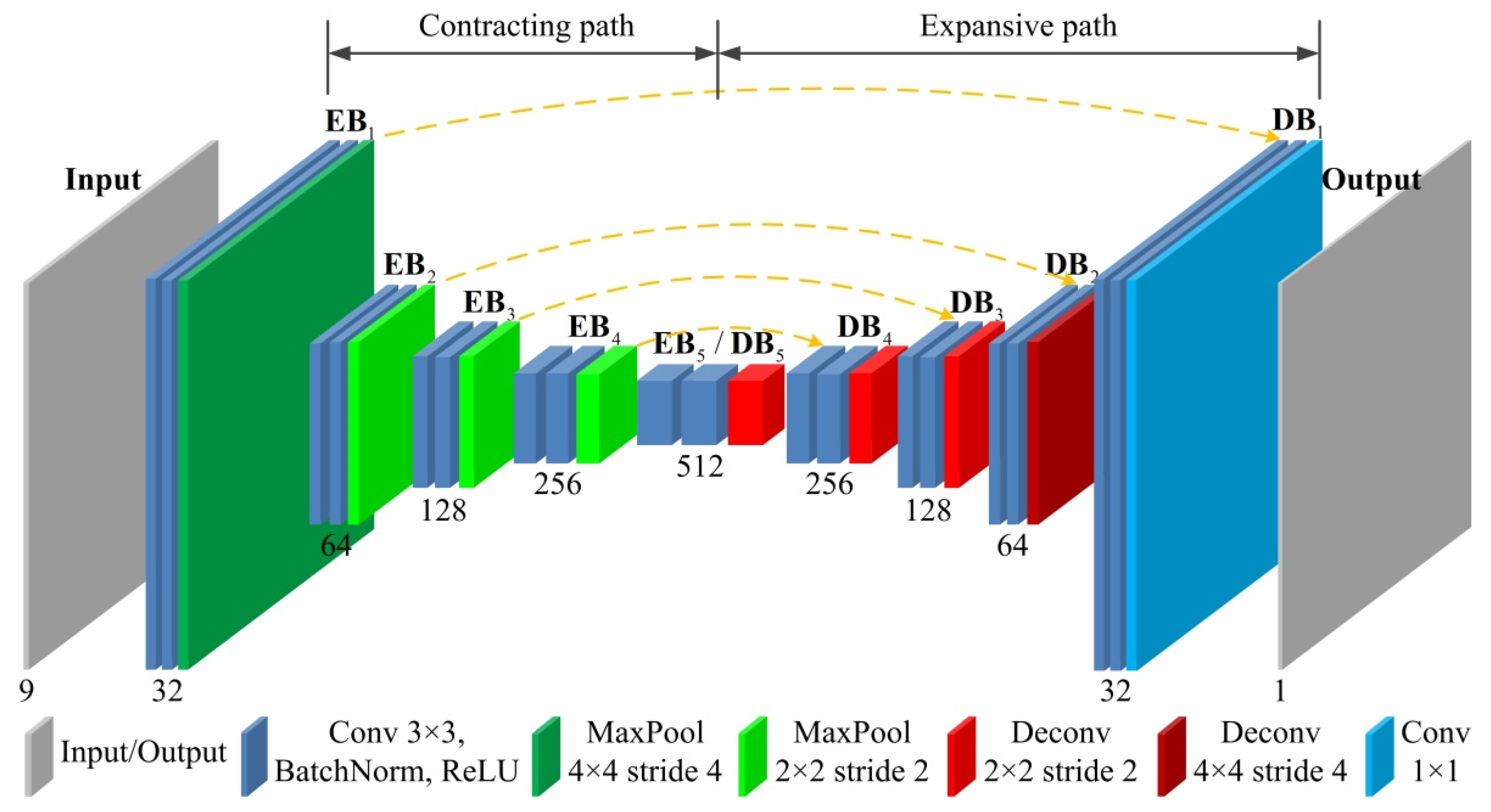
2.1. Network Architecture
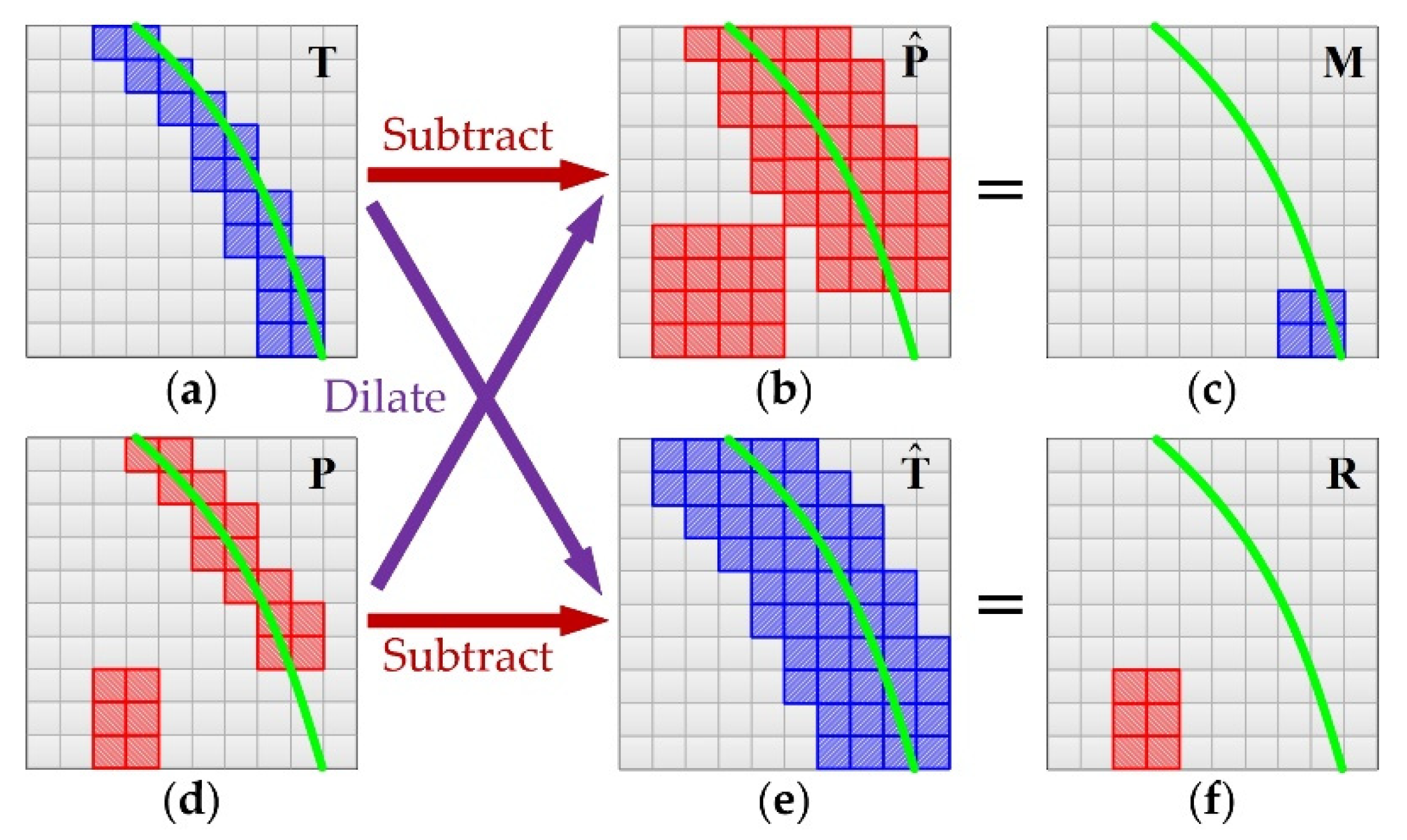
2.2. Loss Function
3. Multi-Exposure Tube Contour Dataset
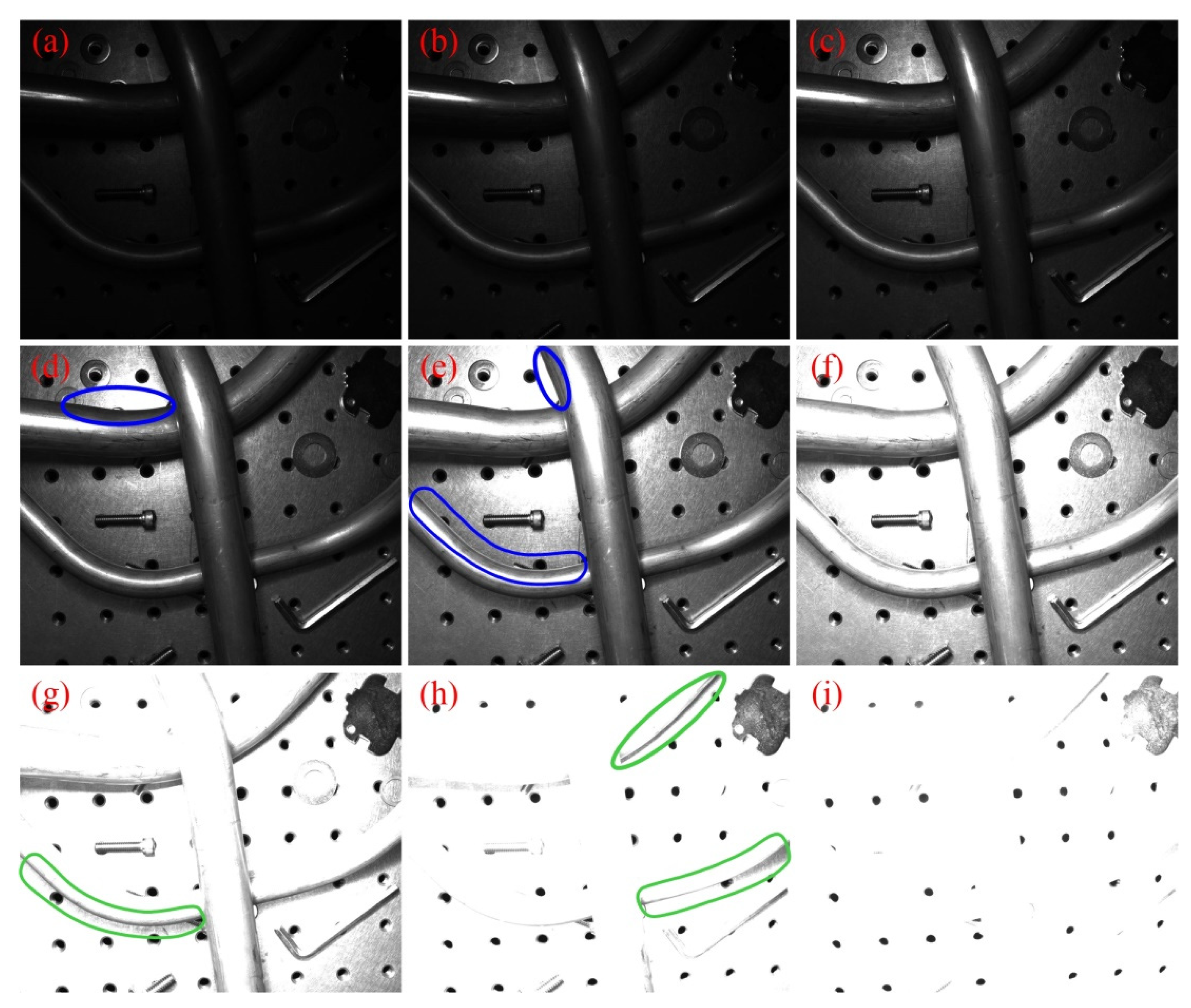
3.1. Multi-Exposure Image Acquisition
3.2. Labeling Process
3.3. Evaluation Metrics
4. Experiments
4.1. Experimental Framework
- Data Augmentation: Due to the small number of training samples in the METCD, data augmentation was performed to improve the generalization ability of the network and avoid overfitting. We augmented the training data with the following ways: (1) random horizontal and vertical flipping with probability 0.5; (2) random rotation between (−45°, +45°); (3) random horizontal and vertical translation in the scale of (−0.2, +0.2); and (4) random scaling in the range of (1, 1.2).
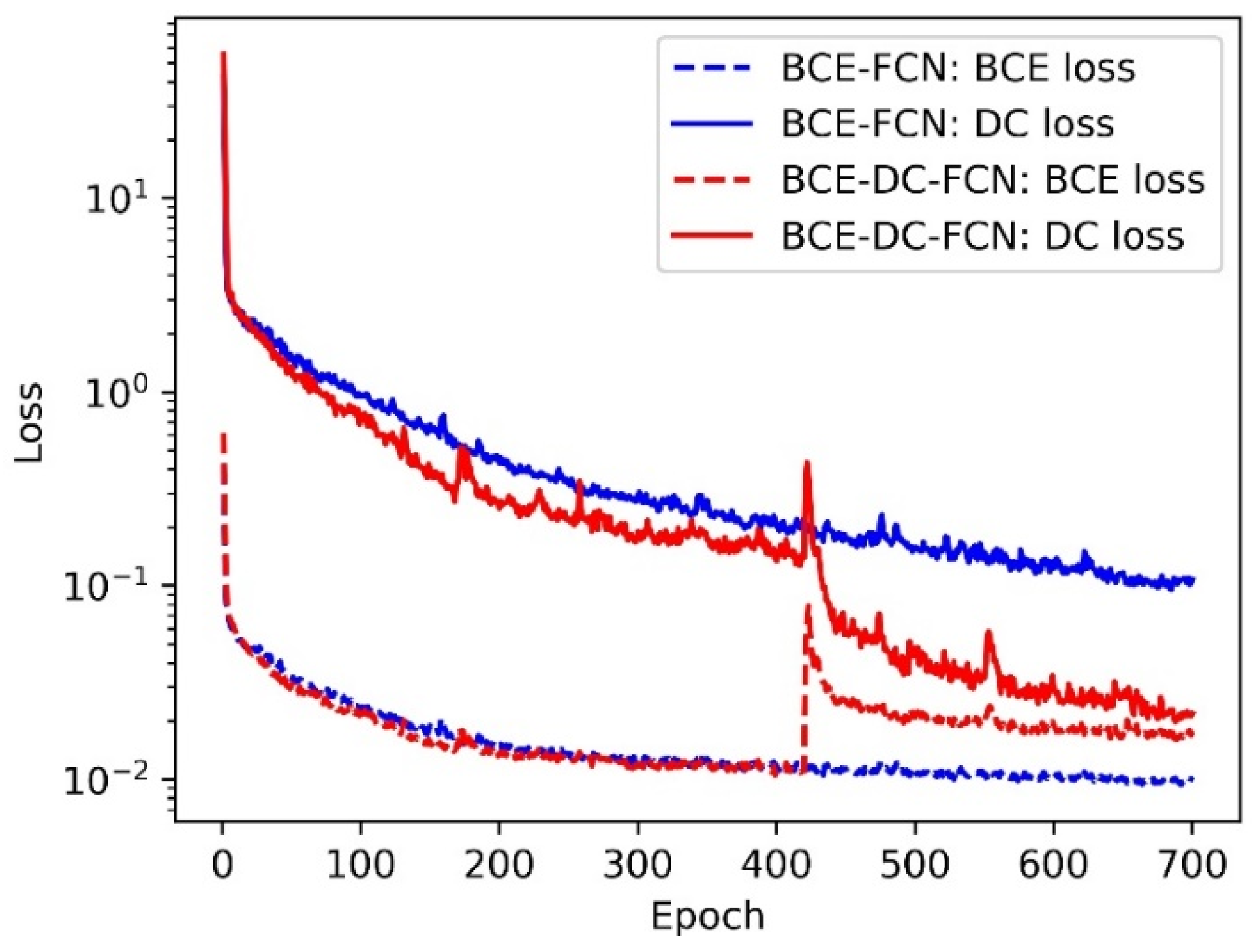
- Optimization: The Adam optimizer was used as the optimization algorithm. The size of mini-batches was set to 3. The learning rate was initialized to 0.01 and decayed by a factor of 0.9 every 70 epochs. We ran all experiments for 700 epochs. The joint loss function adopted in the training process was combined by BCE loss and DC loss, as follows:
- Implementation: All experiments were conducted on a machine equipped with an Intel Core i9-9900X CPU, 32GB RAM and a NVIDIA GTX 2080Ti GPU.
4.2. Experimental Results
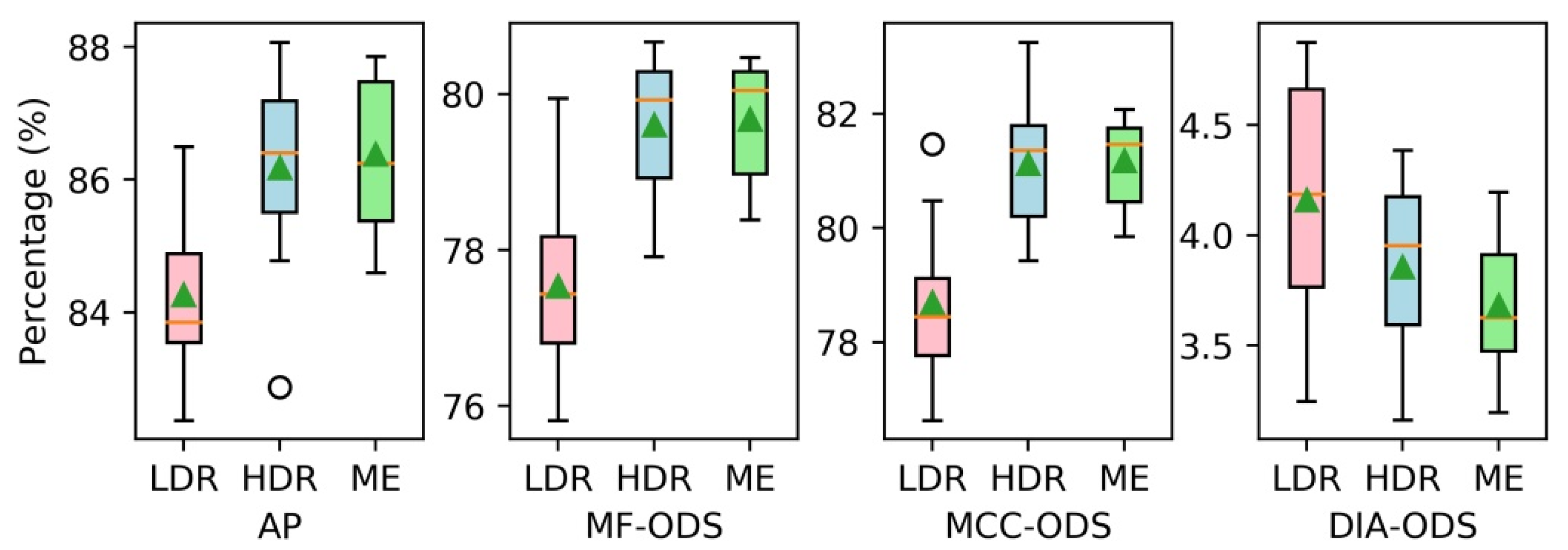
4.2.1. Data Input
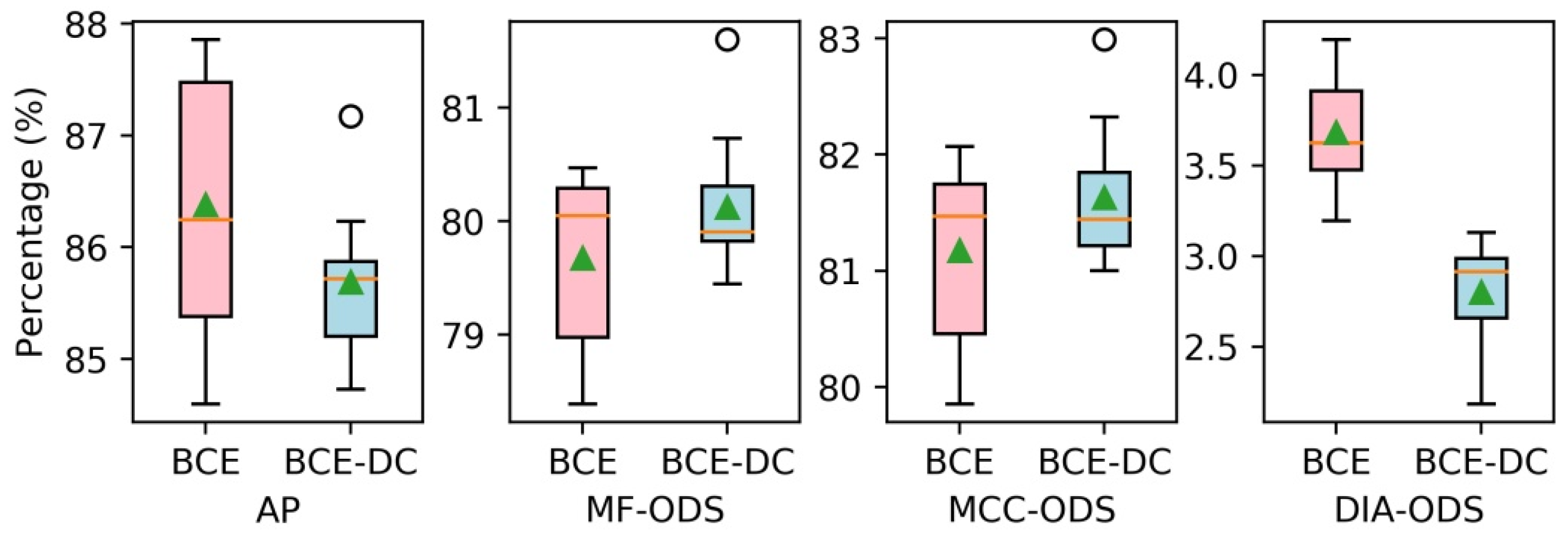
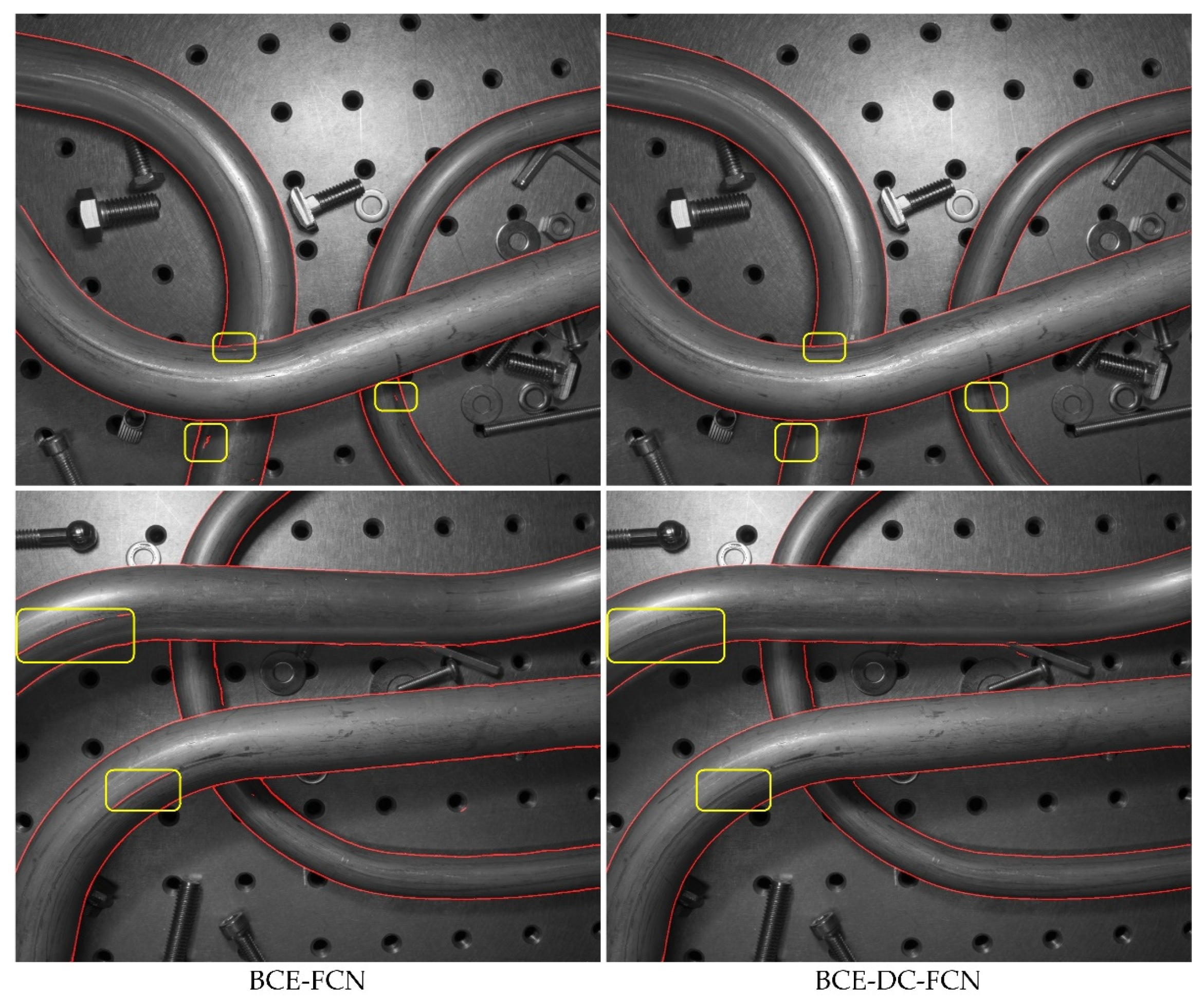
4.2.2. Loss Function
4.2.3. Contour Width
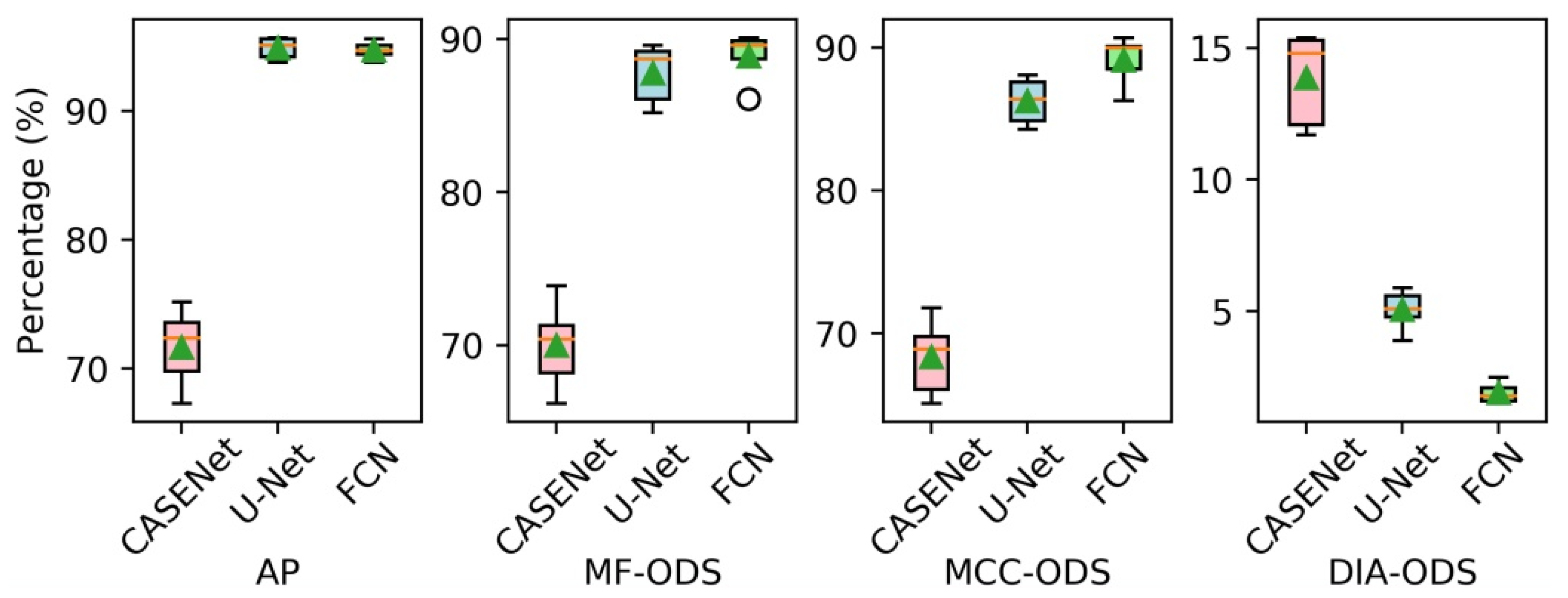
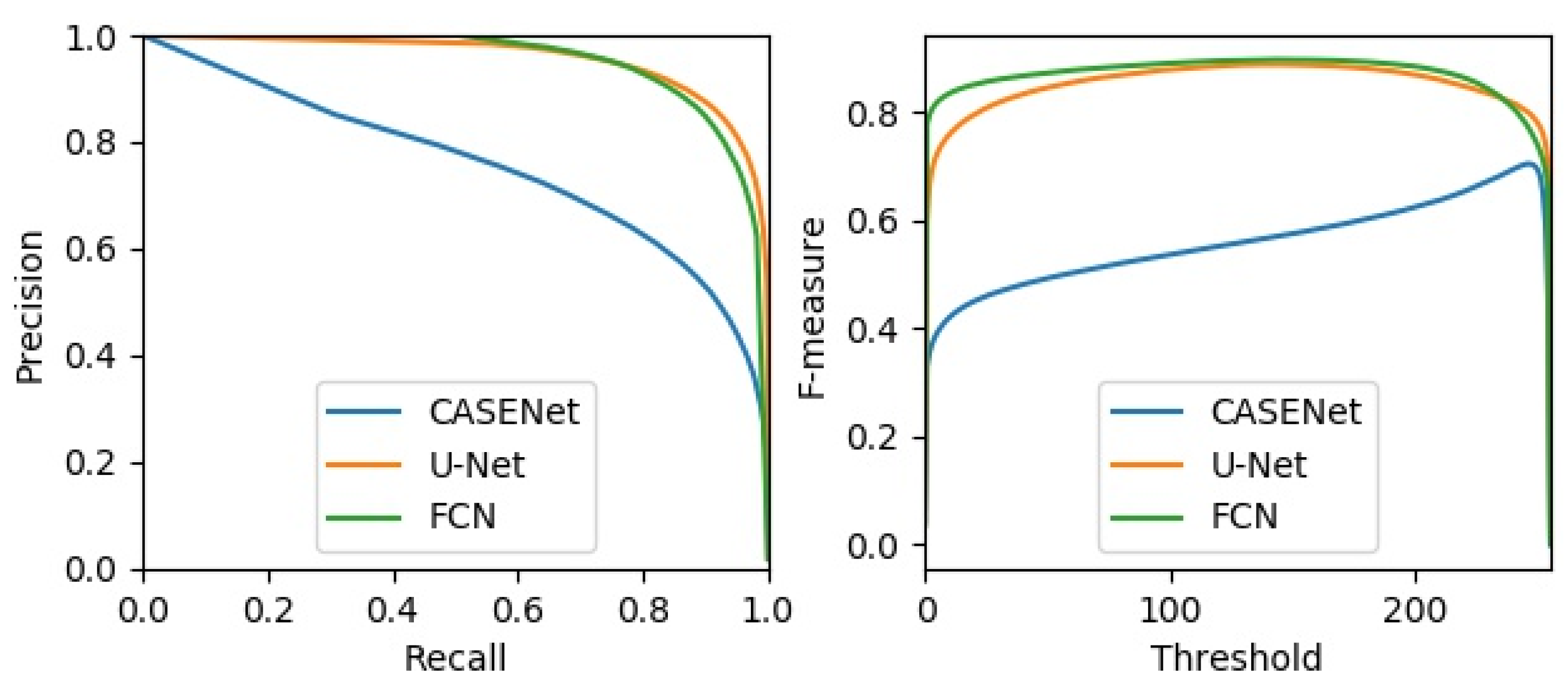
4.2.4. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Caglioti, V.; Giusti, A. Reconstruction of canal surfaces from single images under exact perspective. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 289–300. [Google Scholar] [CrossRef]
- Liu, S.; Liu, J.; Jin, P.; Wang, X. Tube measurement based on stereo-vision: A review. Int. J. Adv. Manuf. Technol. 2017, 92, 2017–2032. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, Y.; Cheng, X. A high precision 3D reconstruction method for bend tube axis based on binocular stereo vision. Opt. Express 2019, 27, 2292–2304. [Google Scholar] [CrossRef] [PubMed]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Trujillo-Pino, A.; Krissian, K.; Alemán-Flores, M.; Santana-Cedrés, D. Accurate subpixel edge location based on partial area effect. Image Vis. Comput. 2013, 31, 72–90. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, J.; Liu, S.; Tang, C.; Jin, P. A 3D reconstruction method for pipeline inspection based on multi-vision. Measurement 2017, 98, 35–48. [Google Scholar] [CrossRef]
- Thirion, B.; Bascle, B.; Ramesh, V.; Navab, N. Fusion of color, shading and boundary information for factory pipe segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 13–15 June 2000; pp. 349–356. [Google Scholar] [CrossRef]
- Aubry, N.; Kerautret, B.; Debled-Rennesson, I.; Even, P. Parallel strip segment recognition and application to metallic tubular object measure. In Proceedings of the International Workshop on Combinatorial Image Analysis, Kolkata, India, 24–27 November 2015; pp. 311–322. [Google Scholar] [CrossRef]
- Ghosh, S.; Pal, A.; Jaiswal, S.; Santosh, K.C. SegFast-V2: Semantic image segmentation with less parameters in deep learning for autonomous driving. Int. J. Mach. Learn. Cybern. 2019, 10, 3145–3154. [Google Scholar] [CrossRef]
- Liu, L.; Chen, S.; Zhang, F.; Wu, F.; Pan, Y.; Wang, J. Deep convolutional neural network for automatically segmenting acute ischemic stroke lesion in multi-modality MRI. Neural Comput. Appl. 2020, 32, 6545–6558. [Google Scholar] [CrossRef]
- Hu, X.; Liu, Y.; Wang, K.; Ren, B. Learning hybrid convolutional features for edge detection. Neurocomputing 2018, 313, 337–385. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Tu, Z. Holistically-nested edge detection. Int. J. Comput. Vis. 2017, 125, 3–18. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Bardis, M.; Houshyar, R.; Chantaduly, C.; Ushinsky, A.; Glavis-Bloom, J.; Shaver, M.; Chow, D.; Uchio, E.; Chang, P. Deep learning with limited data: Organ segmentation performance by U-Net. Electronics 2020, 9, 1199. [Google Scholar] [CrossRef]
- Wang, W.; Li, Q.; Xiao, C.; Zhang, D.; Miao, L.; Wang, L. An improved boundary-aware U-Net for ore image semantic segmentation. Sensors 2021, 21, 2615. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef] [Green Version]
- Lou, L.; Zang, S. Research on edge detection method based on improved HED network. J. Phys. Conf. Ser. 2020, 1607, 012068. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, Z.; Feng, C.; Liu, M.Y.; Ramalingam, S. CASENet: Deep category-aware semantic edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1761–1770. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Acuna, D.; Kar, A.; Fidler, S. Devil is in the edges: Learning semantic boundaries from noisy annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11075–11083. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Chen, Y.; Li, X.; Feng, J. Dynamic feature fusion for semantic edge detection. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 782–788. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Jiang, G.; Yu, M.; Zhang, Y.; Shao, F.; Peng, Z. Naturalness index for a tone-mapped high dynamic range image. Appl. Opt. 2016, 55, 10084–10091. [Google Scholar] [CrossRef] [PubMed]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In Proceedings of the Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 3–8 August 1997; pp. 369–378. [Google Scholar] [CrossRef]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial Scale | Contracting Path | Expansive Path | ||||
|---|---|---|---|---|---|---|
| Block | Input | Output | Block | Input | Output | |
| 1028 × 1280 × 9 | 1028 × 1280 × 32 | 1028 × 1280 × 64 | 1028 × 1280 × 32 | |||
| 256 × 320 × 32 | 256 × 320 × 64 | 256 × 320 × 128 | 256 × 320 × 64 | |||
| 128 × 160 × 64 | 128 × 160 × 128 | 128 × 160 × 256 | 128 × 160 × 128 | |||
| 64 × 80 × 128 | 64 × 80 × 256 | 64 × 80 × 512 | 64 × 80 × 256 | |||
| Block | Input | Output | ||||
| 32 × 40 × 256 | 32 × 40 × 512 | |||||
| Models | AP (%) | MF-ODS (%) | MCC-ODS (%) | DIA-ODS (%) |
|---|---|---|---|---|
| LDR-FCN | 84.3 | 77.5 | 78.7 | 4.2 |
| HDR-FCN | 86.2 | 79.6 | 81.1 | 3.9 |
| ME-FCN | 86.4 | 79.7 | 81.2 | 3.7 |
| Models | AP (%) | MF-ODS (%) | MCC-ODS (%) | DIA-ODS (%) |
|---|---|---|---|---|
| BCE-FCN | 86.4 | 79.7 | 81.2 | 3.7 |
| BCE-DC-FCN | 85.7 | 80.1 | 81.6 | 2.8 |
| Models | AP (%) | MF-ODS (%) | MCC-ODS (%) | DIA-ODS (%) |
|---|---|---|---|---|
| Width1-FCN | 58.6 | 62.7 | 66.3 | 4.9 |
| Width2-FCN | 85.7 | 80.1 | 81.6 | 2.8 |
| Width4-FCN | 94.8 | 87.7 | 87.8 | 2.5 |
| Width8-FCN | 98.0 | 92.2 | 91.5 | 2.6 |
| Models | AP (%) | MF-ODS (%) | MCC-ODS (%) | DIA-ODS (%) |
|---|---|---|---|---|
| CASENet | 71.7 | 70.0 | 68.3 | 13.9 |
| U-Net | 94.9 | 87.8 | 86.3 | 5.1 |
| FCN | 94.7 | 88.9 | 89.1 | 1.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Sun, J.; Zhou, F. A Fully Convolutional Network-Based Tube Contour Detection Method Using Multi-Exposure Images. Sensors 2021, 21, 4095. https://doi.org/10.3390/s21124095
Cheng X, Sun J, Zhou F. A Fully Convolutional Network-Based Tube Contour Detection Method Using Multi-Exposure Images. Sensors. 2021; 21(12):4095. https://doi.org/10.3390/s21124095
Chicago/Turabian StyleCheng, Xiaoqi, Junhua Sun, and Fuqiang Zhou. 2021. "A Fully Convolutional Network-Based Tube Contour Detection Method Using Multi-Exposure Images" Sensors 21, no. 12: 4095. https://doi.org/10.3390/s21124095
APA StyleCheng, X., Sun, J., & Zhou, F. (2021). A Fully Convolutional Network-Based Tube Contour Detection Method Using Multi-Exposure Images. Sensors, 21(12), 4095. https://doi.org/10.3390/s21124095