
MEG Source Localization via Deep Learning

Abstract
:1. Introduction
2. Background on MEG Source Localization
3. Background on Deep Learning
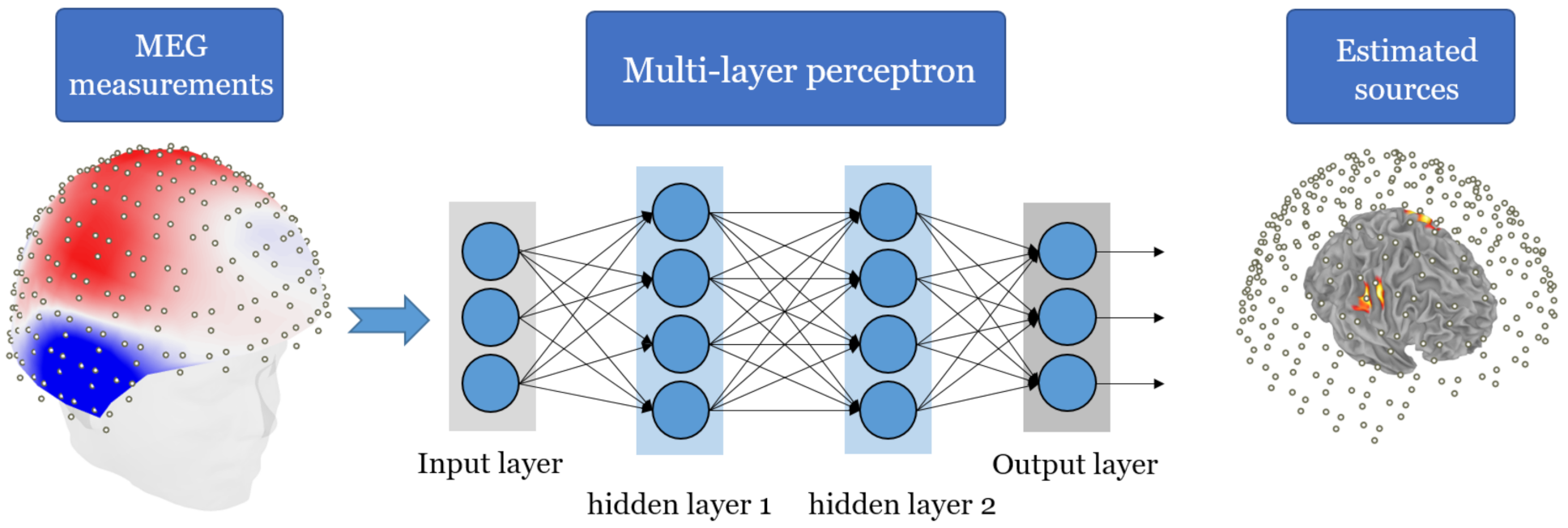
3.1. Multi-Layer Perceptron (MLP)
3.2. Convolutional Neural Networks
4. Deep Learning for MEG Source Localization
4.1. MLP for Single-Snapshot Source Localization
4.2. CNN for Multiple-Snapshot Source Localization
4.3. Data Generation Workflow
5. Performance Evaluation
5.1. Deep Network Training
5.2. Localization Experiments
5.2.1. Experiment 1: Performance of the DeepMEG-MLP Model with Single-Snapshot Data
5.2.2. Experiment 2: Performance of the DeepMEG-CNN Model with Multiple-Snapshot Data
5.2.3. Experiment 3: Robustness of DeepMEG to Forward Model Errors
5.3. Real-Time Source Localization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Valero-Cabré, A.; Amengual, J.L.; Stengel, C.; Pascual-Leone, A.; Coubard, O.A. Transcranial magnetic stimulation in basic and clinical neuroscience: A comprehensive review of fundamental principles and novel insights. Neurosci. Biobehav. Rev. 2017, 83, 381–404. [Google Scholar] [CrossRef]
- Kohl, S.; Hannah, R.; Rocchi, L.; Nord, C.L.; Rothwell, J.; Voon, V. Cortical Paired Associative Stimulation Influences Response Inhibition: Cortico-cortical and Cortico-subcortical Networks. Biol. Psychiatry 2019, 85, 355–363. [Google Scholar] [CrossRef]
- Folloni, D.; Verhagen, L.; Mars, R.B.; Fouragnan, E.; Constans, C.; Aubry, J.F.; Rushworth, M.F.; Sallet, J. Manipulation of Subcortical and Deep Cortical Activity in the Primate Brain Using Transcranial Focused Ultrasound Stimulation. Neuron 2019, 101, 1109–1116.e5. [Google Scholar] [CrossRef] [Green Version]
- Darrow, D. Focused Ultrasound for Neuromodulation. Neurotherapeutics 2019, 16, 88–99. [Google Scholar] [CrossRef] [Green Version]
- Min, B.K.; Chavarriaga, R.; del Millán, R.J. Harnessing Prefrontal Cognitive Signals for Brain–Machine Interfaces. Trends Biotechnol. 2017, 35, 585–597. [Google Scholar] [CrossRef] [PubMed]
- Pichiorri, F.; Mattia, D. Brain-computer interfaces in neurologic rehabilitation practice. In Handbook of Clinical Neurology; Elsevier: Amsterdam, The Netherlands, 2020; Volume 168, pp. 101–116. [Google Scholar] [CrossRef]
- Ilmoniemi, R.; Sarvas, J. Brain Signals: Physics and Mathematics of MEG and EEG; MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Niedermeyer, E.; Schomer, D.L.; Lopes da Silva, F.H. Niedermeyer’s Electroencephalography: Basic Principles, Clinical Applications, and Related Fields; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2012. [Google Scholar]
- Hämäläinen, M.; Hari, R.; Ilmoniemi, R.J.; Knuutila, J.; Lounasmaa, O.V. Magnetoencephalography—Theory, instrumentation, and applications to noninvasive studies of the working human brain. Rev. Mod. Phys. 1993, 65, 413–497. [Google Scholar] [CrossRef] [Green Version]
- Baillet, S. Magnetoencephalography for brain electrophysiology and imaging. Nat. Neurosci. 2017, 20, 327–339. [Google Scholar] [CrossRef] [PubMed]
- Darvas, F.; Pantazis, D.; Kucukaltun-Yildirim, E.; Leahy, R. Mapping human brain function with MEG and EEG: Methods and validation. NeuroImage 2004, 23, S289–S299. [Google Scholar] [CrossRef] [PubMed]
- Kleiner, R.; Koelle, D.; Ludwig, F.; Clarke, J. Superconducting quantum interference devices: State of the art and applications. Proc. IEEE 2004, 92, 1534–1548. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Gupta, H.; Jin, K.H.; Nguyen, H.Q.; McCann, M.T.; Unser, M. CNN-Based Projected Gradient Descent for Consistent CT Image Reconstruction. IEEE Trans. Med Imaging 2018, 37, 1440–1453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep Convolutional Neural Network for Inverse Problems in Imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gjesteby, L.; Yang, Q.; Xi, Y.; Zhou, Y.; Zhang, J.; Wang, G. Deep Learning Methods to Guide CT Image Reconstruction and Reduce Metal Artifacts. In Proceedings of the SPIE Medical Imaging, Orlando, FL, USA, 11–16 February 2017. [Google Scholar] [CrossRef]
- Liang, D.; Cheng, J.; Ke, Z.; Ying, L. Deep Magnetic Resonance Image Reconstruction: Inverse Problems Meet Neural Networks. IEEE Signal Process. Mag. 2020, 37, 141–151. [Google Scholar] [CrossRef]
- Wang, S.; Su, Z.; Ying, L.; Peng, X.; Zhu, S.; Liang, F.; Feng, D.; Liang, D. Accelerating magnetic resonance imaging via deep learning. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016. [Google Scholar]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.N.; Rueckert, D. A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans. Med Imaging 2018, 37, 491–503. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gong, K.; Catana, C.; Qi, J.; Li, Q. PET Image Reconstruction Using Deep Image Prior. IEEE Trans. Med. Imaging 2019, 38, 1655–1665. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Wu, D.; Gong, K.; Dutta, J.; Kim, J.H.; Son, Y.D.; Kim, H.K.; El Fakhri, G.; Li, Q. Penalized PET Reconstruction Using Deep Learning Prior and Local Linear Fitting. IEEE Trans. Med Imaging 2018, 37, 1478–1487. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar] [CrossRef] [Green Version]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef] [Green Version]
- Hauptmann, A.; Lucka, F.; Betcke, M.; Huynh, N.; Adler, J.; Cox, B.; Beard, P.; Ourselin, S.; Arridge, S. Model-Based Learning for Accelerated, Limited-View 3-D Photoacoustic Tomography. IEEE Trans. Med Imaging 2018, 37, 1382–1393. [Google Scholar] [CrossRef] [Green Version]
- Yonel, B.; Mason, E.; Yazici, B. Deep Learning for Passive Synthetic Aperture Radar. IEEE J. Sel. Top. Signal Process. 2018, 12, 90–103. [Google Scholar] [CrossRef] [Green Version]
- Budillon, A.; Johnsy, A.C.; Schirinzi, G.; Vitale, S. Sar Tomography Based on Deep Learning. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3625–3628. [Google Scholar] [CrossRef]
- Araya-Polo, M.; Jennings, J.; Adler, A.; Dahlke, T. Deep-learning tomography. Lead. Edge 2018, 37, 58–66. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuasa, M.; Nagashino, H.; Kinouchi, Y. Single dipole source localization from conventional EEG using BP neural networks. In Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Hong Kong, China, 1 November 1998; Volume 4, pp. 2163–2166. [Google Scholar] [CrossRef]
- Abeyratne, U.R.; Zhang, G.; Saratchandran, P. EEG source localization: A comparative study of classical and neural network methods. Int. J. Neural Syst. 2001, 11, 349–359. [Google Scholar] [CrossRef]
- Sclabassi, R.J.; Sonmez, M.; Sun, M. EEG source localization: a neural network approach. Neurol. Res. 2001, 23, 457–464. [Google Scholar] [CrossRef] [PubMed]
- Yuasa, M.; Zhang, Q.; Nagashino, H.; Kinouchi, Y. EEG source localization for two dipoles by neural networks. In Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Hong Kong, China, 1 November 1998; Volume 4, pp. 2190–2192. [Google Scholar]
- Cui, S.; Duan, L.; Gong, B.; Qiao, Y.; Xu, F.; Chen, J.; Wang, C. EEG source localization using spatio-temporal neural network. China Commun. 2019, 16, 131–143. [Google Scholar] [CrossRef]
- Dinh, C.; Samuelsson, J.G.; Hunold, A.; Hämäläinen, M.S.; Khan, S. Contextual Minimum-Norm Estimates (CMNE): A Deep Learning Method for Source Estimation in Neuronal Networks. arXiv 2019, arXiv:1909.02636. [Google Scholar]
- Hecker, L.; Rupprecht, R.; Tebartz van Elst, L.; Kornmeier, J. ConvDip: A convolutional neural network for better M/EEG Source Imaging. Front. Neurosci. 2021, 15, 533. [Google Scholar] [CrossRef]
- Mosher, J.; Lewis, P.; Leahy, R. Multiple dipole modeling and localization from spatio-temporal MEG data. IEEE Trans. Biomed. Eng. 1992, 39, 541–557. [Google Scholar] [CrossRef]
- Huang, M.; Aine, C.; Supek, S.; Best, E.; Ranken, D.; Flynn, E. Multi-start downhill simplex method for spatio-temporal source localization in magnetoencephalography. Electroencephalogr. Clin. Neurophysiol. Potentials Sect. 1998, 108, 32–44. [Google Scholar] [CrossRef]
- Uutela, K.; Hamalainen, M.; Salmelin, R. Global optimization in the localization of neuromagnetic sources. IEEE Trans. Biomed. Eng. 1998, 45, 716–723. [Google Scholar] [CrossRef]
- Khosla, D.; Singh, M.; Don, M. Spatio-temporal EEG source localization using simulated annealing. IEEE Trans. Biomed. Eng. 1997, 44, 1075–1091. [Google Scholar] [CrossRef]
- Jiang, T.; Luo, A.; Li, X.; Kruggel, F. A Comparative Study Of Global Optimization Approaches To Meg Source Localization. Int. J. Comput. Math. 2003, 80, 305–324. [Google Scholar] [CrossRef] [Green Version]
- van Veen, B.D.; Drongelen, W.v.; Yuchtman, M.; Suzuki, A. Localization of brain electrical activity via linearly constrained minimum variance spatial filtering. IEEE Trans. Biomed. Eng. 1997, 44, 867–880. [Google Scholar] [CrossRef]
- Vrba, J.; Robinson, S.E. Signal Processing in Magnetoencephalography. Methods 2001, 25, 249–271. [Google Scholar] [CrossRef] [Green Version]
- Dalal, S.S.; Sekihara, K.; Nagarajan, S.S. Modified beamformers for coherent source region suppression. IEEE Trans. Biomed. Eng. 2006, 53, 1357–1363. [Google Scholar] [CrossRef] [Green Version]
- Brookes, M.J.; Stevenson, C.M.; Barnes, G.R.; Hillebrand, A.; Simpson, M.I.; Francis, S.T.; Morris, P.G. Beamformer reconstruction of correlated sources using a modified source. NeuroImage 2007, 34, 1454–1465. [Google Scholar] [CrossRef]
- Hui, H.B.; Pantazis, D.; Bressler, S.L.; Leahy, R.M. Identifying true cortical interactions in MEG using the nulling beamformer. NeuroImage 2010, 49, 3161–3174. [Google Scholar] [CrossRef] [Green Version]
- Diwakar, M.; Huang, M.X.; Srinivasan, R.; Harrington, D.L.; Robb, A.; Angeles, A.; Muzzatti, L.; Pakdaman, R.; Song, T.; Theilmann, R.J.; et al. Dual-Core Beamformer for obtaining highly correlated neuronal networks in MEG. NeuroImage 2011, 54, 253–263. [Google Scholar] [CrossRef]
- Diwakar, M.; Tal, O.; Liu, T.; Harrington, D.; Srinivasan, R.; Muzzatti, L.; Song, T.; Theilmann, R.; Lee, R.; Huang, M. Accurate reconstruction of temporal correlation for neuronal sources using the enhanced dual-core MEG beamformer. NeuroImage 2011, 56, 1918–1928. [Google Scholar] [CrossRef] [PubMed]
- Moiseev, A.; Gaspar, J.M.; Schneider, J.A.; Herdman, A.T. Application of multi-source minimum variance beamformers for reconstruction of correlated neural activity. NeuroImage 2011, 58, 481–496. [Google Scholar] [CrossRef] [PubMed]
- Moiseev, A.; Herdman, A.T. Multi-core beamformers: Derivation, limitations and improvements. NeuroImage 2013, 71, 135–146. [Google Scholar] [CrossRef]
- Hesheng, L.; Schimpf, P.H. Efficient localization of synchronous EEG source activities using a modified RAP-MUSIC algorithm. IEEE Trans. Biomed. Eng. 2006, 53, 652–661. [Google Scholar]
- Ewald, A.; Avarvand, F.S.; Nolte, G. Wedge MUSIC: A novel approach to examine experimental differences of brain source connectivity patterns from EEG/MEG data. NeuroImage 2014, 101, 610–624. [Google Scholar] [CrossRef] [PubMed]
- Mosher, J.C.; Leahy, R.M. Source localization using recursively applied and projected (RAP) MUSIC. IEEE Trans. Signal Process. 1999, 47, 332–340. [Google Scholar] [CrossRef] [Green Version]
- Mäkelä, N.; Stenroos, M.; Sarvas, J.; Ilmoniemi, R.J. Truncated RAP-MUSIC (TRAP-MUSIC) for MEG and EEG source localization. NeuroImage 2018, 167, 73–83. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mäkelä, N.; Stenroos, M.; Sarvas, J.; Ilmoniemi, R.J. Locating highly correlated sources from MEG with (recursive) (R)DS-MUSIC. Neuroscience 2017, preprint. [Google Scholar] [CrossRef] [Green Version]
- Lucas, A.; Iliadis, M.; Molina, R.; Katsaggelos, A.K. Using Deep Neural Networks for Inverse Problems in Imaging: Beyond Analytical Methods. IEEE Signal Process. Mag. 2018, 35, 20–36. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Sainath, T.N.; Weiss, R.J.; Wilson, K.W.; Li, B.; Narayanan, A.; Variani, E.; Bacchiani, M.; Shafran, I.; Senior, A.; Chin, K.; et al. Multichannel Signal Processing With Deep Neural Networks for Automatic Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 965–979. [Google Scholar] [CrossRef]
- Fischl, B.; Salat, D.H.; van der Kouwe, A.J.; Makris, N.; Ségonne, F.; Quinn, B.T.; Dale, A.M. Sequence-independent segmentation of magnetic resonance images. NeuroImage 2004, 23, S69–S84. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tadel, F.; Baillet, S.; Mosher, J.C.; Pantazis, D.; Leahy, R.M. Brainstorm: a user-friendly application for MEG/EEG analysis. Comput. Intell. Neurosci. 2011, 2011, 1–13. [Google Scholar] [CrossRef]
- Huang, M.X.; Mosher, J.C.; Leahy, R.M. A sensor-weighted overlapping-sphere head model and exhaustive head model comparison for MEG. Phys. Med. Biol. 1999, 44, 423–440. [Google Scholar] [CrossRef]
- Sekihara, K.; Nagarajan, S.S.; Poeppel, D.; Marantz, A.; Miyashita, Y. Reconstructing spatio-temporal activities of neural sources using an MEG vector beamformer technique. IEEE Trans. Biomed. Eng. 2001, 48, 760–771. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Rey Dean, J.; Hieu Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, 2015. Available online: tensorflow.org (accessed on 22 June 2021).
- Cho, J.H.; Vorwerk, J.; Wolters, C.H.; Knösche, T.R. Influence of the head model on EEG and MEG source connectivity analyses. Neuroimage 2015, 110, 60–77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gençer, N.G.; Acar, C.E. Sensitivity of EEG and MEG measurements to tissue conductivity. Phys. Med. Biol. 2004, 49, 701. [Google Scholar] [CrossRef] [PubMed]
- Wax, M.; Adler, A. Detection of the Number of Signals by Signal Subspace Matching. IEEE Trans. Signal Process. 2021, 69, 973–985. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Network | 1st Layer | 2nd Layer | 3rd Layer | 4th Layer | 5th Layer | Parameters |
|---|---|---|---|---|---|---|---|
| Single MEG | MLP-1 | FC (3000,’sigmoid’) | FC (2500,’sigmoid’) | FC (1200,’sigmoid’) | FC (3,’none’) | - | 11,428,303 |
| Snapshot | MLP-2 | FC (3000,’sigmoid’) | FC (2500,’sigmoid’) | FC (1200,’sigmoid’) | FC (6,’none’) | - | 11,431,906 |
| MLP-3 | FC (3000,’sigmoid’) | FC (2500,’sigmoid’) | FC (1200,’sigmoid’) | FC (9,’none’) | - | 11,435,509 | |
| MEG | CNN-1 | Conv1D (, ) | FC (3000,’sigmoid’) | FC (2500,’sigmoid’) | FC (1200,’sigmoid’) | FC (3,’none’) | 11,711,295 |
| Time-Series | CNN-2 | Conv1D (, ) | FC (3000,’sigmoid’) | FC (2500,’sigmoid’) | FC (1200,’sigmoid’) | FC (6,’none’) | 11,714,898 |
| CNN-3 | Conv1D (, ) | FC (3000,’sigmoid’) | FC (2500,’sigmoid’) | FC (1200,’sigmoid’) | FC (9,’none’) | 11,718,501 |
| Sources | Time Samples | Algorithm | Time [ms] |
|---|---|---|---|
| 1 | 1 | RAP-MUSIC | 135.47 |
| 1 | 1 | DeepMEG MLP-1 | 0.19 |
| 2 | 1 | RAP-MUSIC | 452.17 |
| 2 | 1 | DeepMEG MLP-2 | 0.19 |
| 3 | 1 | RAP-MUSIC | 736.76 |
| 3 | 1 | DeepMEG MLP-3 | 0.19 |
| 1 | 16 | RAP-MUSIC | 136.59 |
| 1 | 16 | DeepMEG CNN-1 | 0.25 |
| 2 | 16 | RAP-MUSIC | 478.23 |
| 2 | 16 | DeepMEG CNN-2 | 0.27 |
| 3 | 16 | RAP-MUSIC | 741.51 |
| 3 | 16 | DeepMEG CNN-3 | 0.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pantazis, D.; Adler, A. MEG Source Localization via Deep Learning. Sensors 2021, 21, 4278. https://doi.org/10.3390/s21134278
Pantazis D, Adler A. MEG Source Localization via Deep Learning. Sensors. 2021; 21(13):4278. https://doi.org/10.3390/s21134278
Chicago/Turabian StylePantazis, Dimitrios, and Amir Adler. 2021. "MEG Source Localization via Deep Learning" Sensors 21, no. 13: 4278. https://doi.org/10.3390/s21134278
APA StylePantazis, D., & Adler, A. (2021). MEG Source Localization via Deep Learning. Sensors, 21(13), 4278. https://doi.org/10.3390/s21134278