
Confidence Score: The Forgotten Dimension of Object Detection Performance Evaluation


Abstract
:1. Introduction
- (benchmark) performance metrics (e.g., COCO evaluation results),
- object size or class-specific performance metrics,
- inference speed (e.g., FPS as a function of batch size),
- computational cost/power consumption (e.g., for edge devices),
- source code license.
2. Experimental Setup
2.1. Dataset Selection
2.2. Model Selection
2.2.1. COCO
- state-of-the-art results promised in accompanying publications
- deployed commonly in industry and academia
- small models suitable for deployment on edge device
- large models with highest scores despite high hardware requirements
2.2.2. Models for Selected for Evaluation on TTPLA
2.3. Evaluation Metrics
2.4. Evaluation Process
3. Results
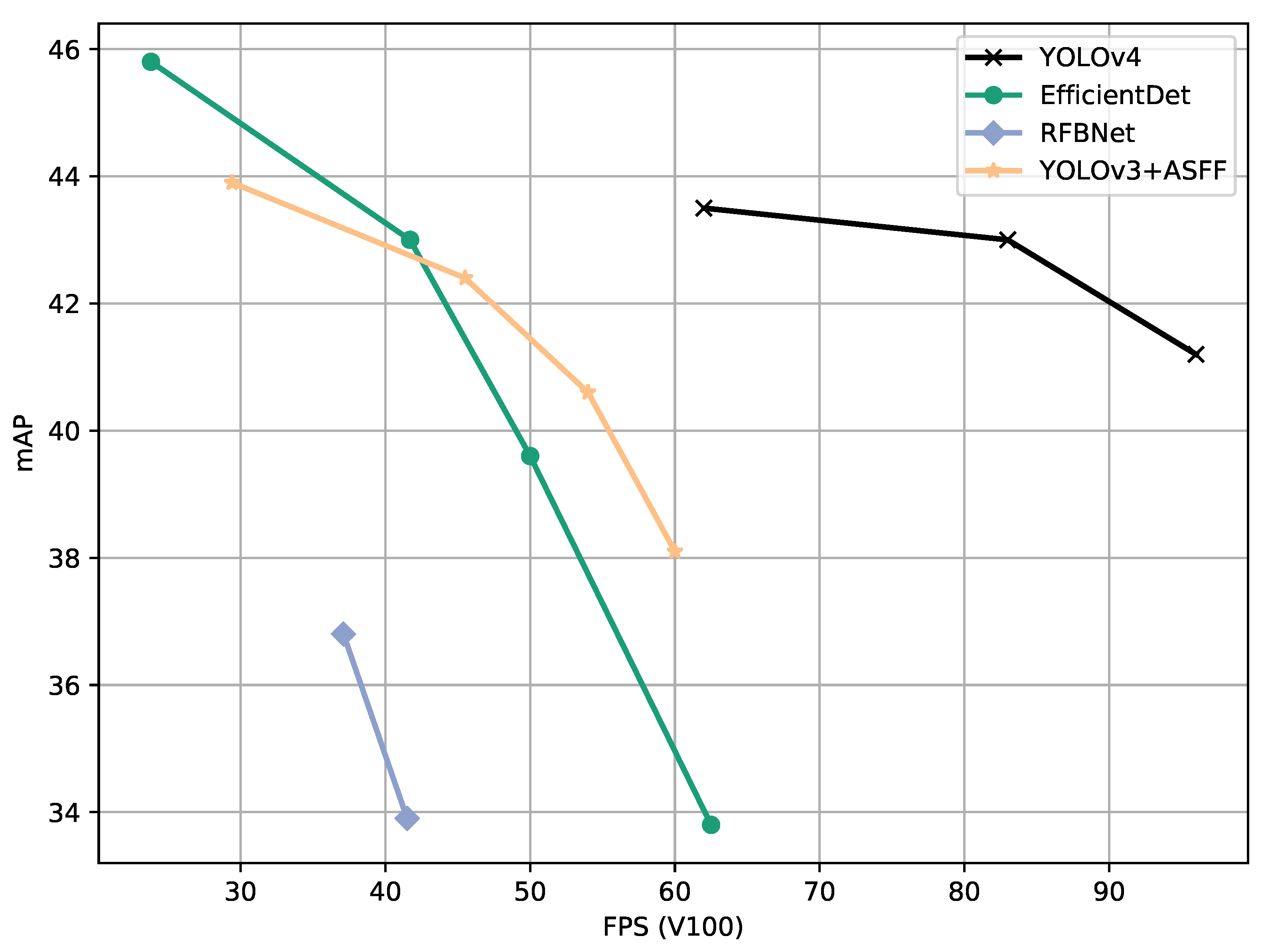
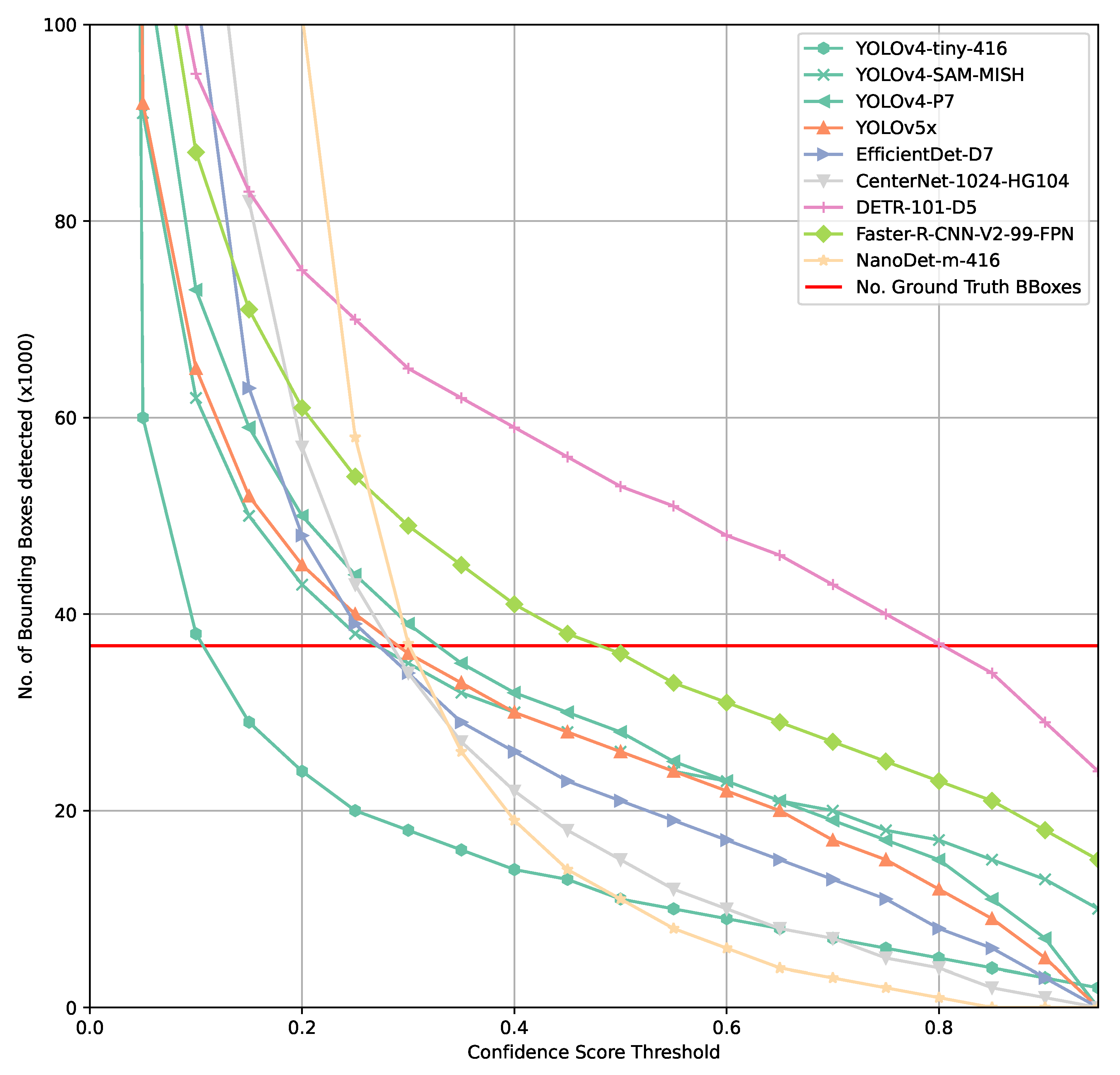
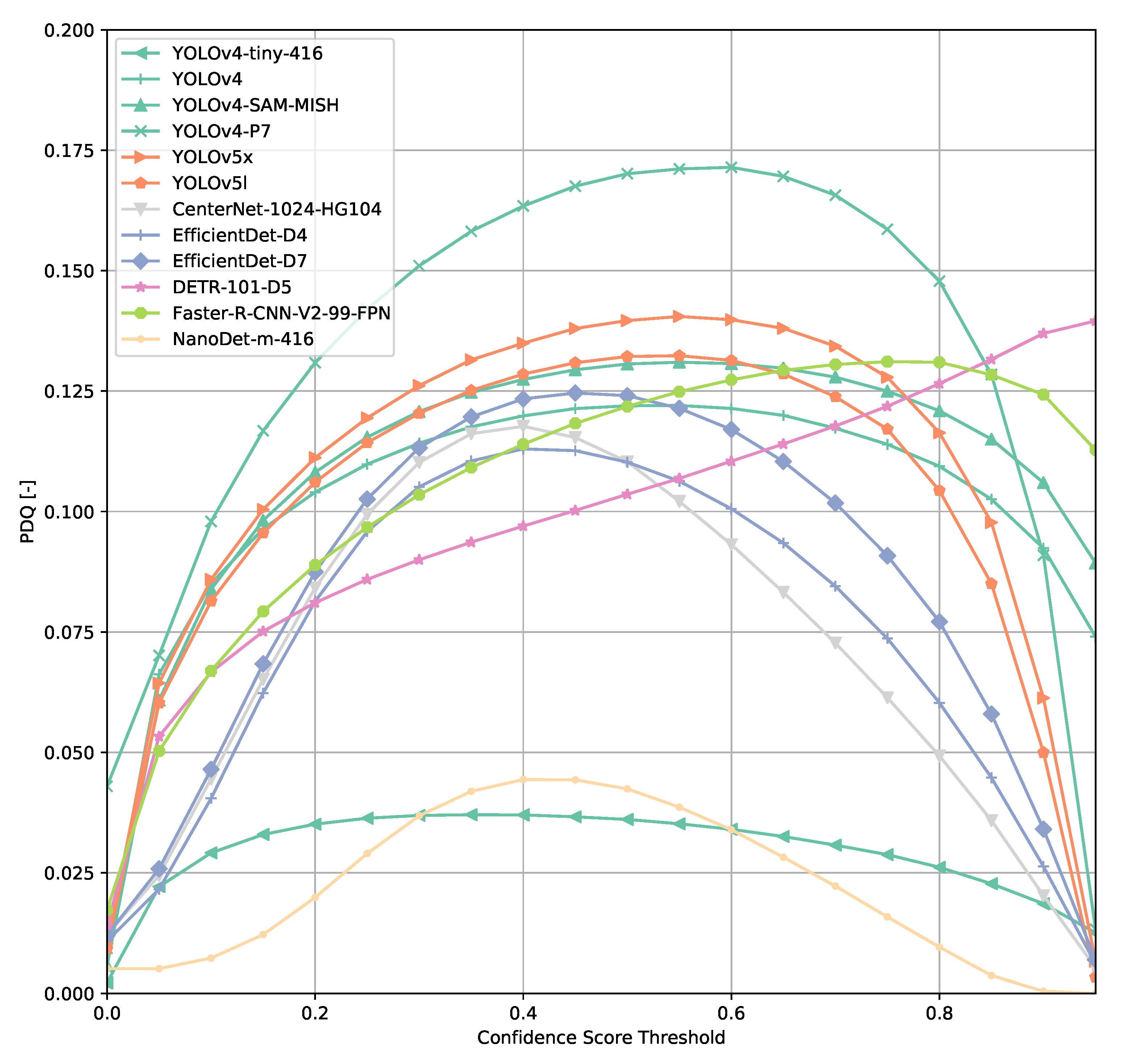
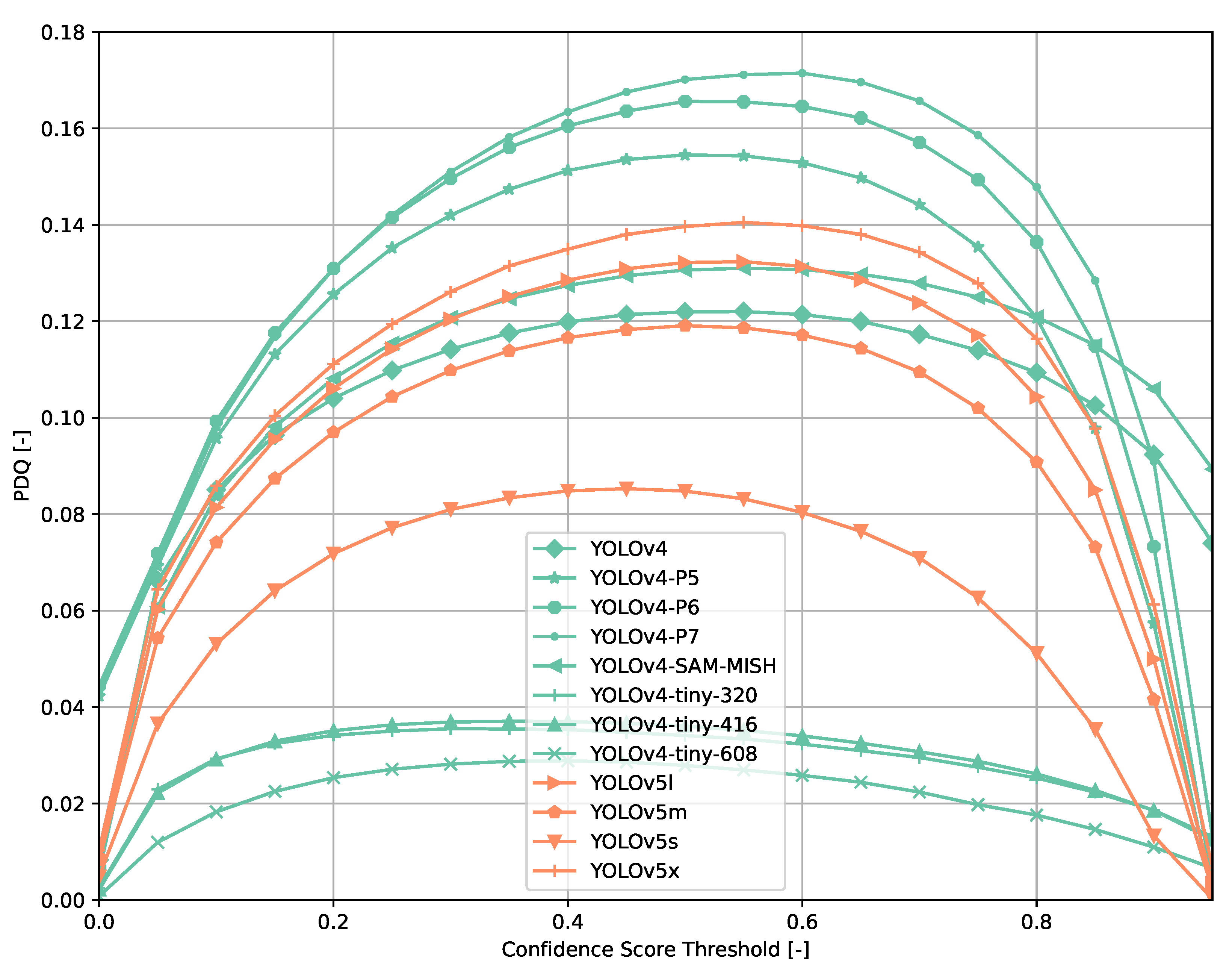
3.1. COCO Dataset
3.2. TTPLA Dataset
4. Discussion
5. Related Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lal, B.; de la Rosa Blanco, E.; Behrens, J.R.; Corbin, B.A.; Green, E.K.; Picard, A.J.; Balakrishnan, A. Global Trends in Small Satellites; Analysis P-3-23; The IDA Science and Technology Policy Institute: Washington, DC, USA, 2017. [Google Scholar]
- Kothari, V.; Liberis, E.; Lane, N.D. The final frontier: Deep learning in space. In Proceedings of the 21st International Workshop on Mobile Computing Systems and Applications, Austin, TX, USA, 3 March 2020; pp. 45–49. [Google Scholar]
- You, Y.; Wang, S.; Ma, Y.; Chen, G.; Wang, B.; Shen, M.; Liu, W. Building Detection from VHR Remote SensingImagery Based on the Morphological Building Index. Remote Sens. 2018, 10, 1287. [Google Scholar] [CrossRef] [Green Version]
- Ahlborn, T.M.; Shuchman, R.A.; Sutter, L.L.; Harris, D.K.; Brooks, C.N.; Burns, J.W. Bridge Condition Assessment Using Remote Sensors; Final Report DT0S59-10-H-00001, USDOT/RITA; Michigan Technological University: Houghton, MI, USA, 2013. [Google Scholar]
- Liu, W.; Chen, S.-E.; Hauser, E. Remote sensing for bridge health monitoring. Proc. SPIE Int. Soc. Opt. Eng. 2009. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the The AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–8 February 2020. [Google Scholar]
- Welleck, S.; Yao, Z.; Gai, Y.; Mao, J.; Zhang, Z.; Cho, K. Loss Functions for Multiset Prediction. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Walder, C.; Nock, R. All your loss are belong to Bayes. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 18505–18517. [Google Scholar]
- Lv, Y.; Gu, Y.; Xinggao, L. The Dilemma of TriHard Loss and an Element-Weighted TriHard Loss for Person Re-Identification. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 17391–17402. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 21002–21012. [Google Scholar]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8430–8439. [Google Scholar]
- Abdelfattah, R.; Wang, X.; Wang, S. TTPLA: An Aerial-Image Dataset for Detection and Segmentation of Transmission Towers and Power Lines. In Computer Vision—ACCV 2020; Ishikawa, H., Liu, C.L., Pajdla, T., Shi, J., Eds.; Springer International Publishing: Cham, Swizerland, 2021; pp. 601–618. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 28–37. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S.; et al. A2d2: Audi autonomous driving dataset. arXiv 2020, arXiv:2004.06320. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2446–2454. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 12–18 June 2018; pp. 954–960. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In International Conference on Pattern Recognition Applications and Methods; SCITEPRESS: Porto, Portugal, 2017; Volume 2, pp. 324–331. [Google Scholar]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. Xview: Objects in context in overhead imagery. arXiv 2018, arXiv:1802.07856. [Google Scholar]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2019, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Swizerland, 2014; pp. 740–755. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete Problems in AI Safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Sünderhauf, N.; Brock, O.; Scheirer, W.; Hadsell, R.; Fox, D.; Leitner, J.; Upcroft, B.; Abbeel, P.; Burgard, W.; Milford, M.; et al. The limits and potentials of deep learning for robotics. Int. J. Robot. Res. 2018, 37, 405–420. [Google Scholar] [CrossRef] [Green Version]
- Hall, D.; Dayoub, F.; Skinner, J.; Zhang, H.; Miller, D.; Corke, P.; Carneiro, G.; Angelova, A.; Sünderhauf, N. Probabilistic Object Detection: Definition and Evaluation. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1031–1040. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Shivappriya, S.N.; Priyadarsini, M.J.P.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B.D. Cascade Object Detection and Remote Sensing Object Detection Method Based on Trainable Activation Function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS — Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision – ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Swizerland, 2016; pp. 21–37. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 14–17 June 2019. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. arXiv 2020, arXiv:2011.08036. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. ultralytics/yolov5: v3.1—Bug Fixes and Performance Improvements. Zenodo 2020. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231v1. [Google Scholar]
- Zhang, R. Making Convolutional Networks Shift-Invariant Again. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 7324–7334. [Google Scholar]
- Wiyatno, R.R.; Xu, A. Physical adversarial textures that fool visual object tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4822–4831. [Google Scholar]
- Yang, C.; Kortylewski, A.; Xie, C.; Cao, Y.; Yuille, A. Patchattack: A black-box texture-based attack with reinforcement learning. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 681–698. [Google Scholar]
- Wu, Z.; Lim, S.N.; Davis, L.S.; Goldstein, T. Making an invisibility cloak: Real world adversarial attacks on object detectors. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–17. [Google Scholar]
- Ammirato, P.; Berg, A.C. A Mask-RCNN Baseline for Probabilistic Object Detection. arXiv 2019, arXiv:1908.03621. [Google Scholar]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A Cascaded R-CNN With Multiscale Attention and Imbalanced Samples for Traffic Sign Detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
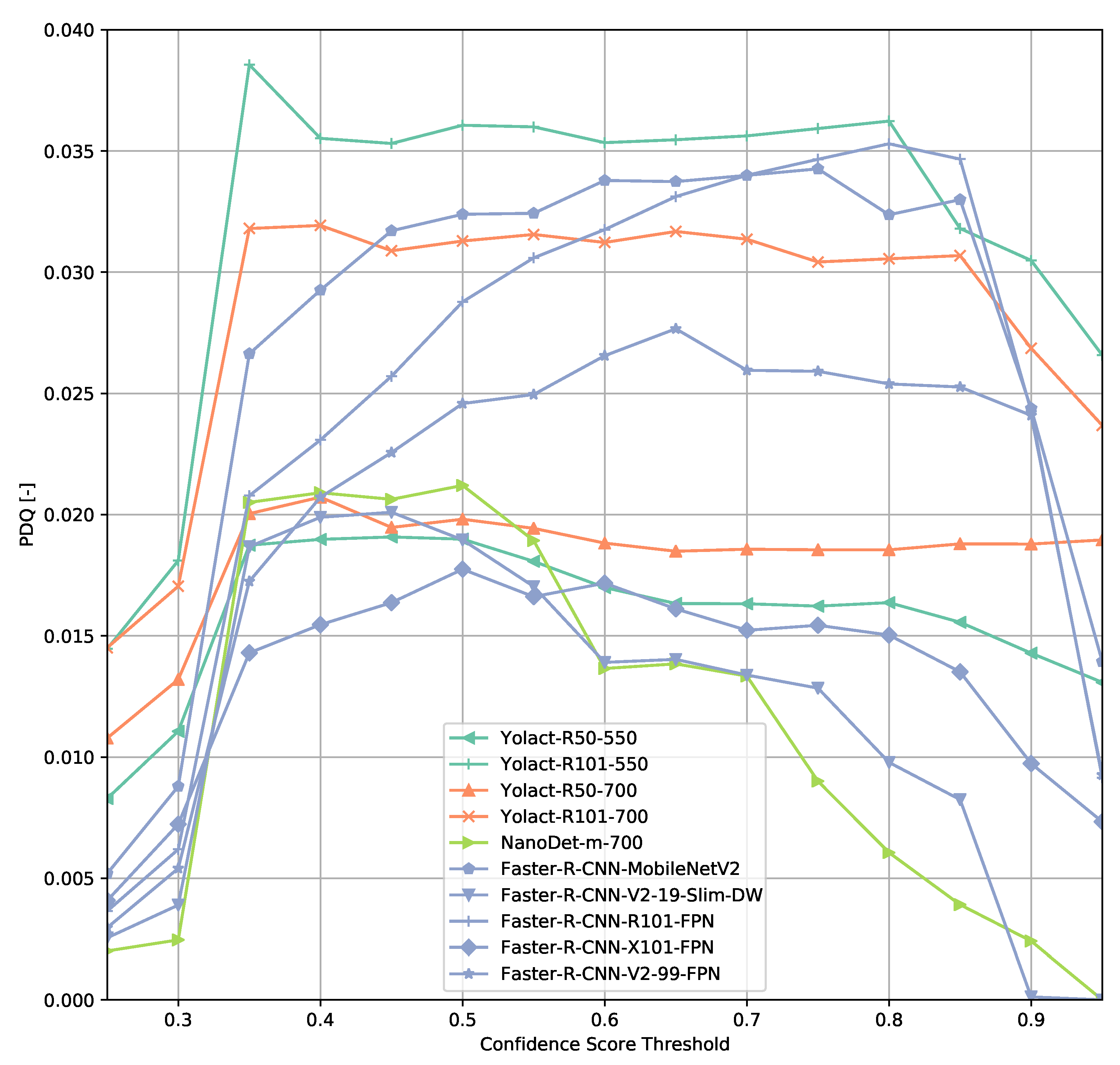{kind=link}
| Model | Confidence | PDQ(max) | Spatial | Label | mAP(max) | mAP | ∆mAP | mAP50 | mAP75 | mAPs | mAPm | mAPl | TP | FP | FN |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Threshold | (PDQ) | (PDQ) | |||||||||||||
| [%] | [%] | [%] | [%] | [%] | [%] | [p.p.] | [%] | [%] | [%] | [%] | [%] | ||||
| CenterNet-1024-HG104 | 40 | 11.77 | 21.18 | 64.03 | 44.47 | 34.33 | 10.14 | 44.61 | 38.29 | 19.80 | 36.08 | 44.60 | 17,590. | 4611 | 19,191 |
| CenterNet-512-R101 | 45 | 9.26 | 17.75 | 69.31 | 34.23 | 27.28 | 6.96 | 37.81 | 29.74 | 8.10 | 29.58 | 44.49 | 14,781 | 4169 | 22,000 |
| CenterNet-512-R50v1 | 40 | 7.60 | 14.72 | 62.74 | 31.29 | 25.35 | 5.94 | 36.62 | 27.87 | 8.67 | 27.46 | 40.44 | 15,257 | 6563 | 21,524 |
| CenterNet-512-R50v2 | 40 | 7.11 | 14.64 | 62.84 | 29.53 | 23.94 | 5.60 | 34.39 | 26.17 | 7.10 | 26.07 | 39.46 | 13,840 | 5287 | 22,941 |
| DETR-R101 | 95 | 12.30 | 17.07 | 97.41 | 43.49 | 35.62 | 7.87 | 49.74 | 38.69 | 15.14 | 39.11 | 53.25 | 18,136 | 5194 | 18,645 |
| DETR-R101-DC5 | 95 | 13.96 | 19.54 | 97.58 | 44.90 | 37.01 | 7.89 | 50.81 | 40.13 | 16.52 | 40.74 | 54.52 | 18,791 | 5374 | 17,990 |
| DETR-R50 | 95 | 12.83 | 18.86 | 97.44 | 42.01 | 33.97 | 8.04 | 47.63 | 36.65 | 14.18 | 36.76 | 52.36 | 17,387 | 4553 | 19,394 |
| DETR-R50-DC5 | 95 | 14.07 | 20.50 | 97.34 | 43.27 | 35.01 | 8.27 | 48.59 | 37.92 | 15.61 | 38.65 | 51.38 | 18,179 | 5062 | 18,602 |
| EfficientDet-D0 | 40 | 7.20 | 13.38 | 66.97 | 33.48 | 27.58 | 5.91 | 39.02 | 30.90 | 6.00 | 31.04 | 47.84 | 14,249 | 4567 | 22,532 |
| EfficientDet-D1 | 45 | 8.47 | 15.03 | 70.46 | 39.18 | 30.92 | 8.26 | 41.75 | 34.64 | 8.08 | 35.40 | 50.42 | 14,720 | 3538 | 22,061 |
| EfficientDet-D2 | 45 | 9.54 | 15.92 | 70.31 | 42.52 | 33.51 | 9.01 | 44.65 | 37.20 | 12.71 | 37.71 | 52.97 | 16,034 | 3586 | 20,747 |
| EfficientDet-D3 | 45 | 10.82 | 16.60 | 71.75 | 45.87 | 36.75 | 9.12 | 48.14 | 40.75 | 16.15 | 40.65 | 55.66 | 17,634 | 4065 | 19,147 |
| EfficientDet-D4 | 40 | 11.30 | 16.65 | 68.44 | 49.13 | 40.64 | 8.49 | 53.35 | 45.07 | 20.22 | 45.33 | 58.99 | 19,239 | 4897 | 17,542 |
| EfficientDet-D5 | 45 | 12.01 | 17.56 | 71.36 | 50.45 | 40.47 | 9.99 | 52.52 | 44.76 | 21.42 | 44.67 | 57.60 | 18,921 | 4178 | 17,860 |
| EfficientDet-D6 | 45 | 12.13 | 17.05 | 71.67 | 51.10 | 41.26 | 9.85 | 53.27 | 45.74 | 21.98 | 45.12 | 59.22 | 19,631 | 4415 | 17,150 |
| EfficientDet-D7 | 45 | 12.46 | 17.37 | 72.67 | 53.07 | 43.05 | 10.01 | 55.37 | 47.32 | 23.77 | 47.07 | 60.67 | 19,762 | 4521 | 17,019 |
| Faster-R-CNN-MobileNetV2 | 70 | 8.42 | 12.63 | 89.85 | 33.18 | 25.98 | 7.20 | 39.08 | 28.90 | 11.97 | 27.15 | 36.25 | 16,379 | 6658 | 20,402 |
| Faster-R-CNN-R101-FPN | 75 | 12.36 | 16.67 | 92.84 | 42.42 | 34.86 | 7.55 | 49.06 | 39.04 | 17.06 | 38.59 | 48.15 | 19,174 | 6048 | 17,607 |
| Faster-R-CNN-R50-FPN | 75 | 11.51 | 15.81 | 92.61 | 40.52 | 33.09 | 7.42 | 47.39 | 37.27 | 15.32 | 36.52 | 46.14 | 18,523 | 6168 | 18,258 |
| Faster-R-CNN-V2-19-DW-FPNLite | 75 | 10.01 | 14.14 | 91.95 | 37.08 | 29.10 | 7.98 | 42.89 | 32.73 | 14.71 | 31.54 | 39.32 | 17,233 | 5423 | 19,548 |
| Faster-R-CNN-V2-19-FPN | 75 | 10.53 | 14.30 | 92.20 | 39.20 | 31.32 | 7.88 | 45.60 | 34.98 | 16.34 | 33.77 | 42.13 | 18,209 | 6011 | 18,572 |
| Faster-R-CNN-V2-19-FPNLite | 75 | 10.74 | 14.76 | 92.41 | 39.13 | 31.34 | 7.79 | 45.69 | 34.98 | 16.39 | 33.99 | 42.66 | 18,132 | 5900 | 18,649 |
| Faster-R-CNN-V2-19-Slim-DW | 70 | 8.52 | 12.50 | 89.81 | 32.57 | 25.52 | 7.05 | 39.01 | 28.46 | 11.73 | 26.88 | 35.16 | 16,518 | 6380 | 20,263 |
| Faster-R-CNN-V2-19-Slim-FPNLite | 75 | 9.40 | 13.67 | 91.61 | 35.40 | 27.22 | 8.18 | 40.51 | 30.36 | 13.71 | 28.41 | 37.40 | 16,732 | 5594 | 20,049 |
| Faster-R-CNN-V2-39-FPN | 75 | 12.31 | 16.29 | 93.06 | 43.09 | 35.41 | 7.69 | 50.12 | 39.65 | 18.61 | 38.85 | 47.75 | 19,408 | 5916 | 17,373 |
| Faster-R-CNN-V2-57-FPN | 75 | 12.72 | 16.64 | 93.16 | 43.70 | 35.97 | 7.73 | 50.74 | 40.10 | 18.97 | 39.61 | 49.25 | 19,689 | 6010 | 17,092 |
| Faster-R-CNN-V2-99-FPN | 75 | 13.11 | 17.02 | 93.45 | 44.59 | 36.78 | 7.81 | 51.50 | 41.09 | 18.85 | 39.97 | 50.98 | 19,808 | 5781 | 16,973 |
| Faster-R-CNN-X101-FPN | 80 | 12.91 | 17.20 | 94.55 | 43.58 | 35.78 | 7.80 | 49.87 | 40.13 | 18.26 | 38.89 | 49.07 | 19,171 | 5485 | 17,610 |
| NanoDet-m-320 | 40 | 4.25 | 11.75 | 57.35 | 20.57 | 16.45 | 4.12 | 25.70 | 17.47 | 2.21 | 14.40 | 30.02 | 10,322 | 5150 | 26,459 |
| NanoDet-m-416 | 40 | 4.44 | 10.76 | 57.34 | 21.65 | 17.66 | 3.99 | 28.12 | 18.70 | 4.08 | 17.47 | 28.52 | 11,974 | 7035 | 24,807 |
| NanoDet-m-608 | 45 | 4.25 | 10.60 | 59.03 | 18.75 | 14.29 | 4.47 | 23.72 | 14.79 | 5.32 | 17.00 | 19.42 | 11,542 | 6058 | 25,239 |
| RetinaNet-R101-FPN | 55 | 11.57 | 19.38 | 78.03 | 40.41 | 32.03 | 8.38 | 44.15 | 35.67 | 13.92 | 35.88 | 44.42 | 16,700 | 4287 | 20,081 |
| RetinaNet-R50-FPN | 50 | 10.67 | 17.83 | 75.03 | 38.69 | 31.61 | 7.08 | 44.32 | 35.20 | 14.11 | 34.80 | 44.27 | 17,285 | 5899 | 19,496 |
| SSD-MobileNetV2-320 | 55 | 3.83 | 9.79 | 66.54 | 20.24 | 16.35 | 3.89 | 25.98 | 17.43 | 1.13 | 11.26 | 36.49 | 10,357 | 7059 | 26,424 |
| SSD-MobileNetV2-320-FPN | 40 | 3.90 | 9.55 | 58.11 | 22.25 | 18.49 | 3.76 | 29.07 | 20.22 | 1.39 | 17.91 | 35.03 | 10,793 | 5683 | 25,988 |
| SSD-R101-640 | 45 | 7.50 | 14.61 | 64.01 | 35.60 | 28.28 | 7.32 | 39.60 | 31.83 | 8.28 | 30.93 | 45.02 | 14,440 | 4553 | 22,341 |
| SSD-R152-640 | 45 | 7.40 | 14.39 | 64.11 | 35.40 | 27.99 | 7.42 | 39.10 | 31.36 | 8.16 | 30.22 | 45.63 | 14,302 | 4587 | 22,479 |
| SSD-R50-640 | 45 | 6.94 | 13.82 | 63.35 | 34.19 | 26.79 | 7.40 | 37.92 | 30.25 | 8.22 | 28.63 | 43.29 | 13,961 | 4613 | 22,820 |
| YOLOv2 | 45 | 4.45 | 6.63 | 68.93 | 29.39 | 24.41 | 4.98 | 42.13 | 25.69 | 6.44 | 28.16 | 40.53 | 14,358 | 5053 | 22,423 |
| YOLOv2-tiny-320 | 45 | 0.88 | 2.81 | 67.46 | 9.54 | 6.96 | 2.57 | 15.69 | 5.16 | 0.33 | 4.64 | 15.40 | 5957 | 8631 | 30,824 |
| YOLOv2-tiny-416 | 45 | 0.90 | 2.47 | 66.90 | 10.53 | 7.71 | 2.82 | 17.75 | 5.52 | 0.67 | 6.75 | 15.55 | 6774 | 9287 | 30,007 |
| YOLOv2-tiny-608 | 45 | 0.86 | 2.20 | 64.86 | 9.59 | 6.84 | 2.74 | 16.93 | 4.18 | 1.66 | 9.16 | 10.04 | 7263 | 9127 | 29,518 |
| YOLOv3 | 55 | 7.18 | 9.01 | 88.61 | 38.84 | 30.16 | 8.68 | 48.99 | 33.48 | 16.69 | 33.11 | 42.04 | 17,811 | 6670 | 18,970 |
| YOLOv3-spp | 40 | 8.16 | 10.68 | 78.20 | 42.59 | 33.20 | 9.39 | 49.47 | 38.02 | 16.96 | 34.60 | 48.09 | 18,121 | 5426 | 18,660 |
| YOLOv3-tiny-320 | 30 | 1.21 | 3.85 | 62.36 | 8.56 | 6.23 | 2.33 | 11.27 | 6.46 | 0.02 | 1.98 | 19.19 | 6513 | 6668 | 30,268 |
| YOLOv3-tiny-416 | 30 | 1.26 | 3.57 | 60.18 | 9.65 | 6.68 | 2.97 | 12.35 | 6.49 | 0.04 | 4.75 | 18.52 | 7423 | 7047 | 29,358 |
| YOLOv3-tiny-608 | 30 | 1.27 | 3.59 | 58.37 | 9.46 | 6.20 | 3.26 | 11.95 | 5.67 | 0.24 | 9.48 | 11.93 | 7811 | 7261 | 28,970 |
| YOLOv4 | 55 | 12.20 | 15.72 | 86.27 | 50.50 | 40.13 | 10.38 | 54.63 | 46.24 | 23.10 | 46.01 | 53.27 | 19,103 | 3896 | 17,678 |
| YOLOv4-P5 | 50 | 15.45 | 22.74 | 77.57 | 50.75 | 41.55 | 9.20 | 53.43 | 46.13 | 21.68 | 47.06 | 56.69 | 20,163 | 4926 | 16,618 |
| YOLOv4-P6 | 50 | 16.56 | 23.34 | 78.62 | 53.41 | 44.91 | 8.49 | 57.42 | 49.51 | 25.83 | 50.12 | 60.84 | 21,455 | 5451 | 15,326 |
| YOLOv4-P7 | 60 | 17.15 | 24.58 | 82.58 | 54.63 | 44.25 | 10.38 | 55.55 | 48.65 | 22.50 | 50.34 | 62.37 | 20,053 | 3862 | 16,728 |
| YOLOv4-SAM-MISH | 55 | 13.10 | 15.42 | 88.02 | 55.26 | 45.23 | 10.02 | 61.09 | 52.34 | 29.02 | 51.41 | 59.89 | 20673 | 4097 | 16,108 |
| YOLOv4-tiny-320 | 30 | 3.55 | 7.45 | 68.66 | 20.55 | 16.03 | 4.52 | 27.78 | 16.73 | 2.70 | 17.48 | 28.83 | 10,706 | 5263 | 26,075 |
| YOLOv4-tiny-416 | 35 | 3.70 | 7.10 | 70.73 | 21.97 | 16.53 | 5.44 | 28.64 | 17.23 | 4.80 | 19.91 | 24.84 | 11,366 | 4961 | 25,415 |
| YOLOv4-tiny-608 | 40 | 2.89 | 6.38 | 67.50 | 17.28 | 12.06 | 5.22 | 22.28 | 11.76 | 5.86 | 17.89 | 11.92 | 10,486 | 6737 | 26,295 |
| YOLOv5l | 55 | 13.24 | 20.22 | 78.53 | 47.34 | 38.04 | 9.29 | 49.62 | 42.26 | 18.11 | 44.25 | 52.79 | 18,470 | 4283 | 18,311 |
| YOLOv5m | 50 | 11.91 | 18.51 | 76.45 | 43.88 | 35.66 | 8.22 | 47.87 | 39.45 | 17.07 | 41.59 | 49.02 | 18,166 | 4882 | 18,615 |
| YOLOv5s | 45 | 8.53 | 14.67 | 71.02 | 36.71 | 28.49 | 8.23 | 40.43 | 31.97 | 12.44 | 33.75 | 38.64 | 15,788 | 4614 | 20,993 |
| YOLOv5x | 55 | 14.05 | 20.71 | 79.32 | 48.66 | 40.35 | 8.31 | 52.55 | 44.51 | 20.59 | 46.16 | 56.40 | 19,463 | 4770 | 17,318 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wenkel, S.; Alhazmi, K.; Liiv, T.; Alrshoud, S.; Simon, M. Confidence Score: The Forgotten Dimension of Object Detection Performance Evaluation. Sensors 2021, 21, 4350. https://doi.org/10.3390/s21134350
Wenkel S, Alhazmi K, Liiv T, Alrshoud S, Simon M. Confidence Score: The Forgotten Dimension of Object Detection Performance Evaluation. Sensors. 2021; 21(13):4350. https://doi.org/10.3390/s21134350
Chicago/Turabian StyleWenkel, Simon, Khaled Alhazmi, Tanel Liiv, Saud Alrshoud, and Martin Simon. 2021. "Confidence Score: The Forgotten Dimension of Object Detection Performance Evaluation" Sensors 21, no. 13: 4350. https://doi.org/10.3390/s21134350
APA StyleWenkel, S., Alhazmi, K., Liiv, T., Alrshoud, S., & Simon, M. (2021). Confidence Score: The Forgotten Dimension of Object Detection Performance Evaluation. Sensors, 21(13), 4350. https://doi.org/10.3390/s21134350