
Novel Feature-Extraction Methods for the Estimation of Above-Ground Biomass in Rice Crops

 ,
,  ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
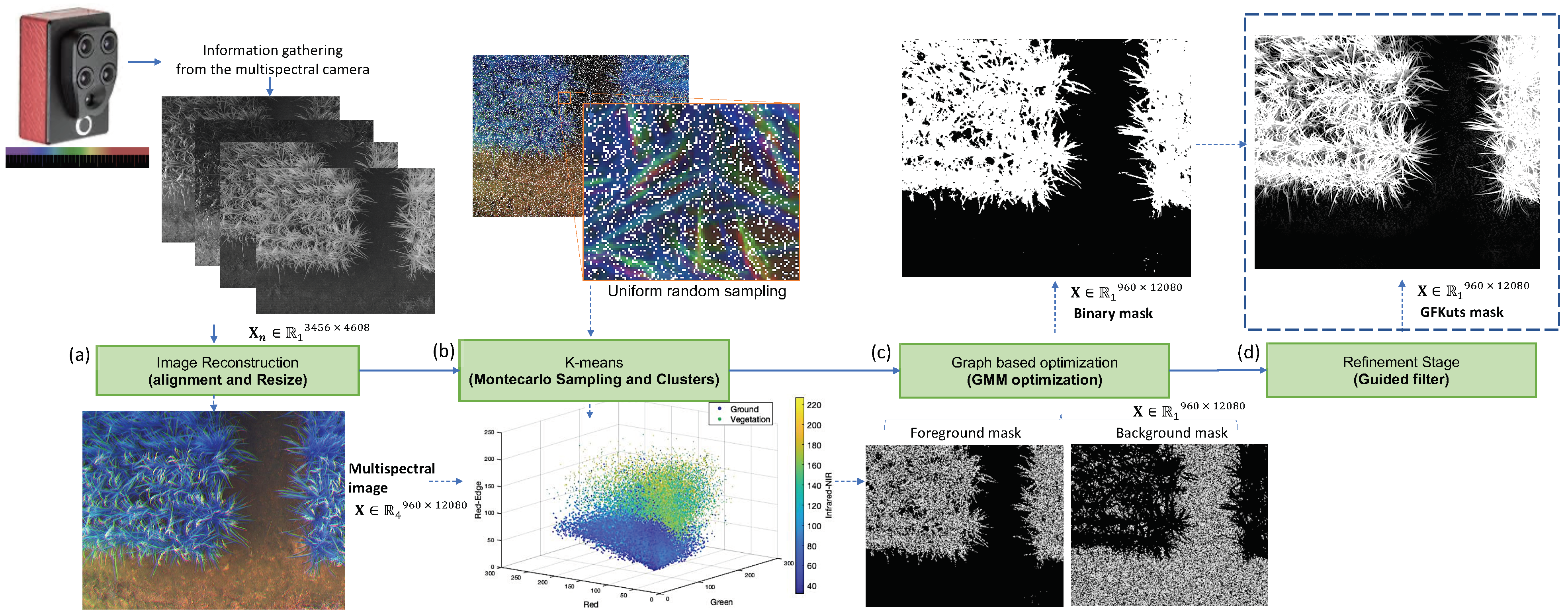
3.1. GFKuts
| Algorithm 1: Montecarlo Sampled K-means. |
| Input: the image , the number of samples N, and two heuristic values associated with the mean expected |
| radiance of the canopy: , and the ground: . |
| for Each pixel in range (1 … n) do |
| Random (x, y) pixel selection from to P |
| Store sRGB value from P to |
| Store pixel coordinates |
| end for |
| Run K-means over to get labeling and |
| calculate the Euclidean distance between C1 and the centroid of the group K = 1 to ; |
| calculate the Euclidean distance between C1 and the centroid of the group K = 2 to ; |
| if < then |
| group K = 1 to |
| group K = 2 to |
| else |
| group K = 1 to |
| group K = 2 to |
| end if |
| Create a mask and set the coordinates in of each pixel in as the foreground. |
| Create a mask and set the coordinates in of each pixel in as the background. |
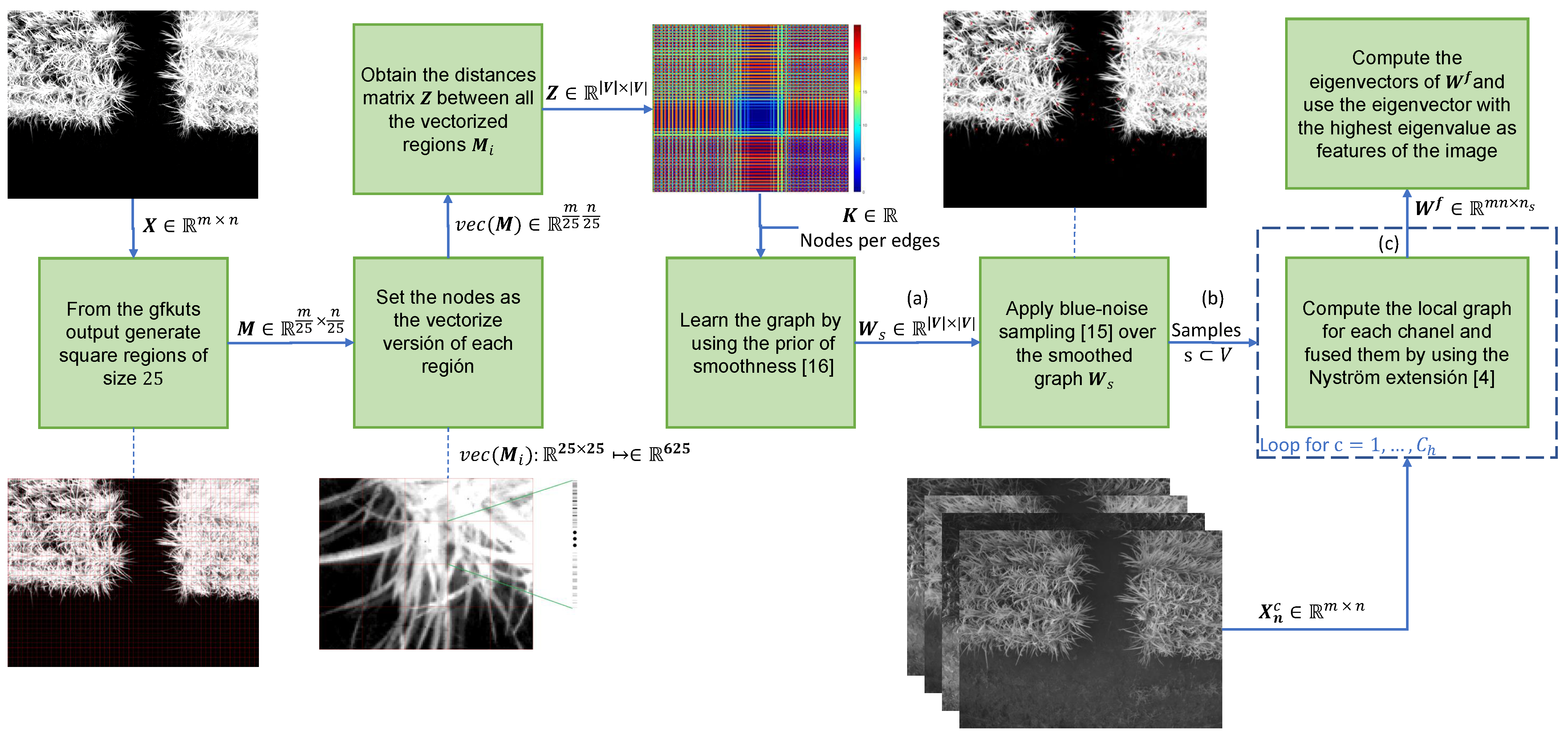
3.2. Graph-Based Data Fusion
3.2.1. Nyström Extension
3.2.2. Graph Signal Processing: Smoothness Prior
| Algorithm 2: Graph learning with prior smoothness [24]. |
| Input: Matrix of distances Z, K edges per node (sparsity level) |
| Output: Graph learned with prior smoothness |
| Step to compute |
| Compute bounds of with Equation (12). |
| Compute as a geometric mean between the bounds and . |
| Step to compute adjacency matrix . |
| Compute from Equation (11) with |
3.2.3. Blue-Noise Sampling
3.3. Non-Linear Regression Models
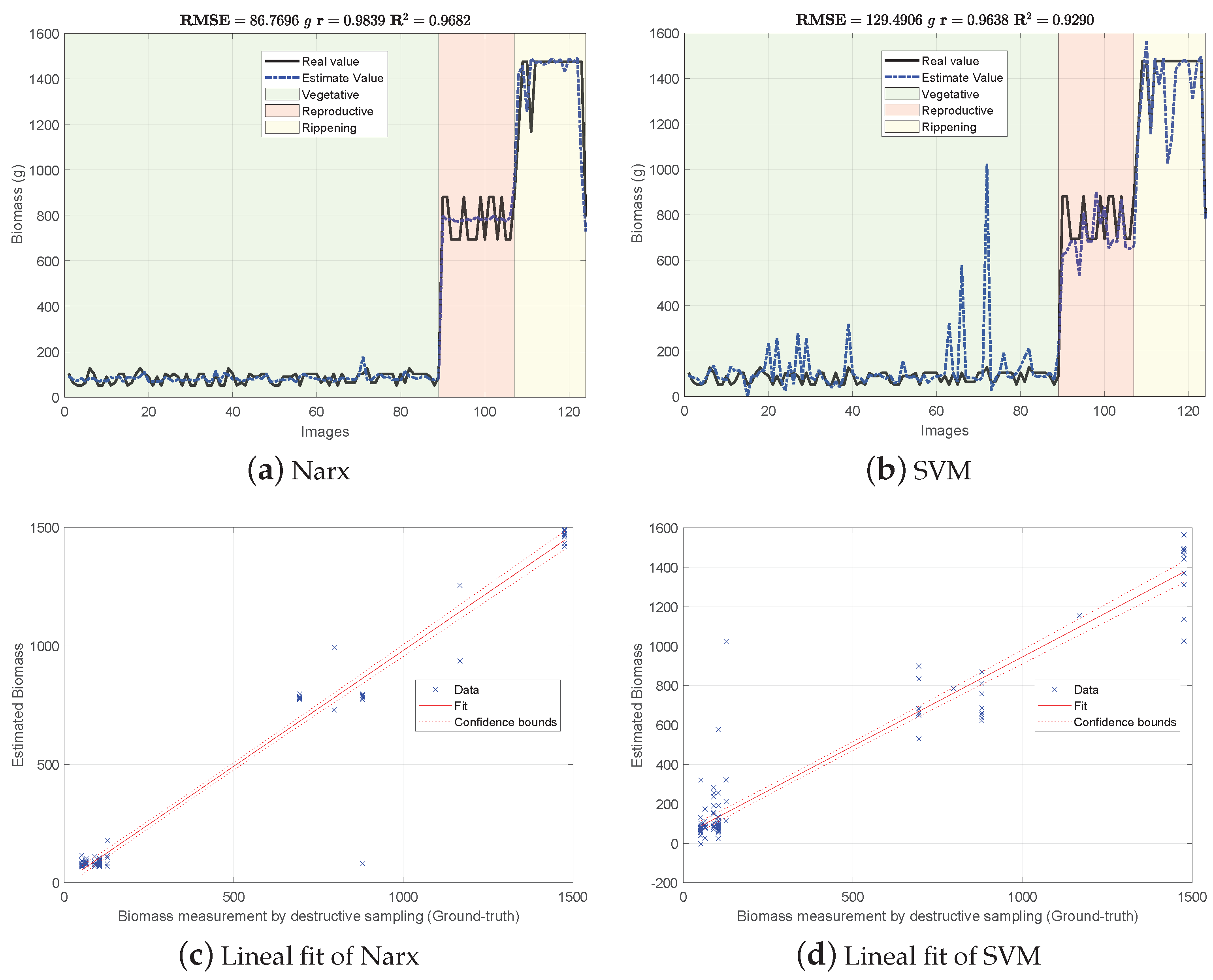
3.3.1. Support Vector Machine Regression (SVM-R)
3.3.2. A Nonlinear Autoregressive Exogenous (NARX)
4. Results and Discussion
4.1. Experimental Setup
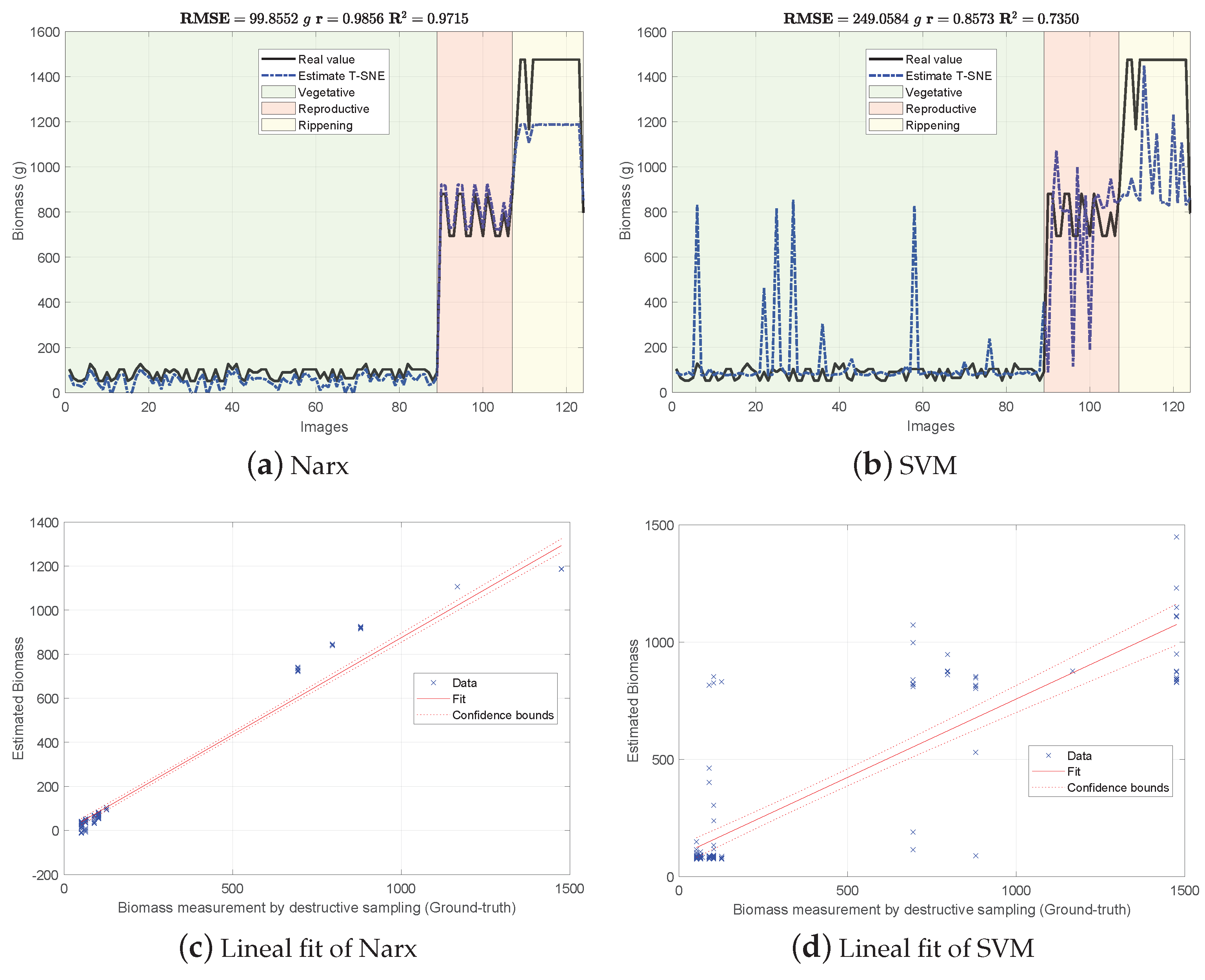
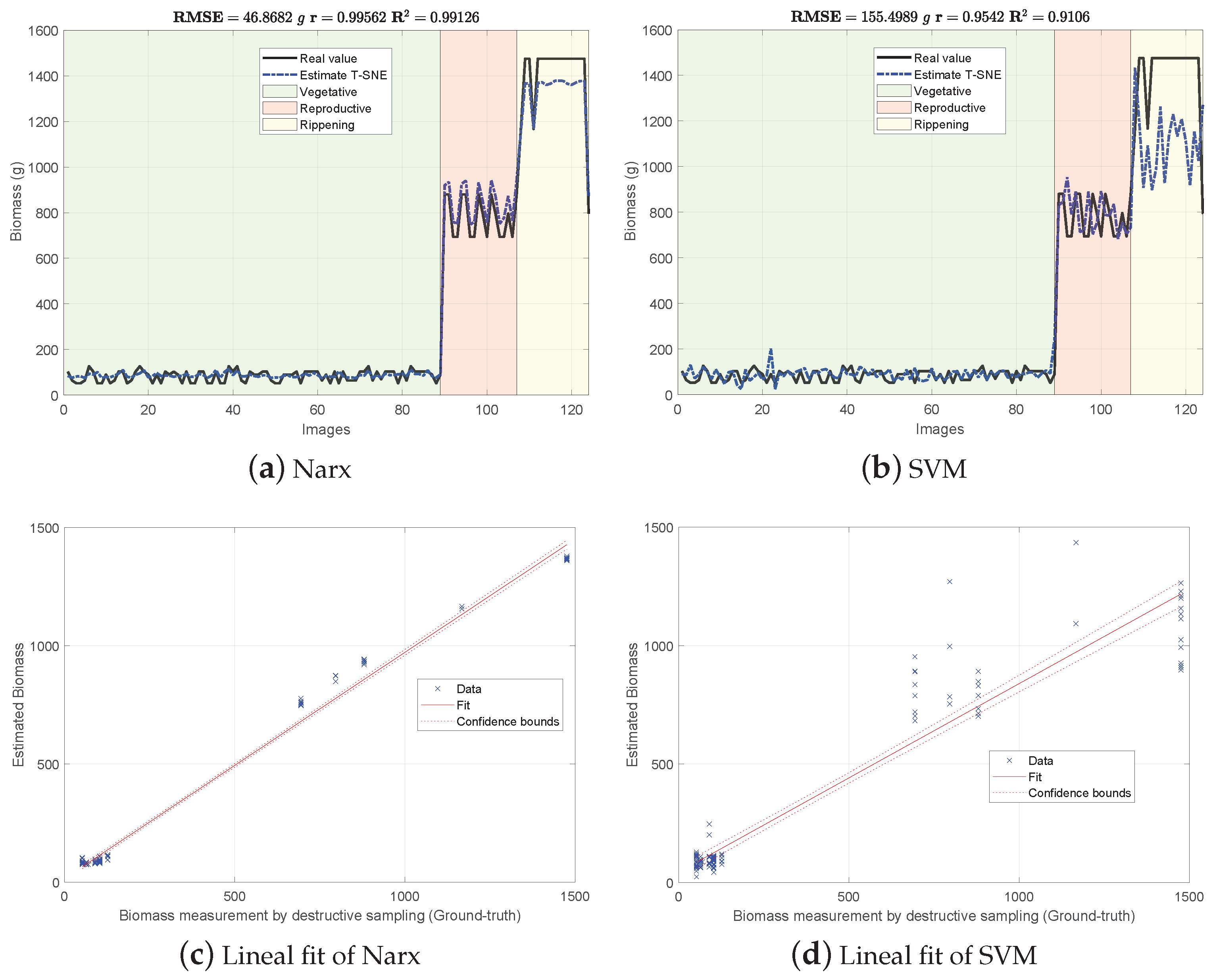
4.2. Biomass Estimation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahmed, M.; Ahmad, S.; Ahmad, S. Climate Variability Impact on Rice Production: Adaptation and Mitigation Strategies. In Quantification of Climate Variability, Adaptation and Mitigation for Agricultural Sustainability; Springer: Cham, Switzerland, 2017; pp. 91–111. [Google Scholar]
- Alebele, Y.; Zhang, X.; Wang, W.; Yang, G.; Yao, X.; Zheng, H.; Zhu, Y.; Cao, W.; Cheng, T. Estimation of Canopy Biomass Components in Paddy Rice from Combined Optical and SAR Data Using Multi-Target Gaussian Regressor Stacking. Remote Sens. 2020, 12, 2564. [Google Scholar] [CrossRef]
- Colorado, J.D.; Calderon, F.; Mendez, D.; Petro, E.; Rojas, J.P.; Correa, E.S.; Mondragon, I.F.; Rebolledo, M.C.; Jaramillo-Botero, A. A novel NIR-image segmentation method for the precise estimation of above-ground biomass in rice crops. PLoS ONE 2020, 15, e0239591. [Google Scholar] [CrossRef]
- Jimenez-Sierra, D.A.; Benítez-Restrepo, H.D.; Vargas-Cardona, H.D.; Chanussot, J. Graph-Based Data Fusion Applied to: Change Detection and Biomass Estimation in Rice Crops. Remote Sens. 2020, 12, 2683. [Google Scholar] [CrossRef]
- Yue, J.; Feng, H.; Jin, X.; Yuan, H.; Li, Z.; Zhou, C.; Yang, G.; Tian, Q. A comparison of crop parameters estimation using images from UAV-mounted snapshot hyperspectral sensor and high-definition digital camera. Remote Sens. 2018, 10, 1138. [Google Scholar] [CrossRef] [Green Version]
- Yue, J.; Feng, H.; Yang, G.; Li, Z. A comparison of regression techniques for estimation of above-ground winter wheat biomass using near-surface spectroscopy. Remote Sens. 2018, 10, 66. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Z.; Bao, Y.-X.; Lin, W.; Du, Z.-Z.; Qian, T.; Can, C. Hyperspectral Features of Rice Canopy and SPAD Values Estimation under the Stress of Rice Leaf Folder. Chin. J. Agrometeorol. 2020, 41, 173. [Google Scholar]
- Cheng, T.; Song, R.; Li, D.; Zhou, K.; Zheng, H.; Yao, X.; Tian, Y.; Cao, W.; Zhu, Y. Spectroscopic estimation of biomass in canopy components of paddy rice using dry matter and chlorophyll indices. Remote Sens. 2017, 9, 319. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Jia, Z.; Yang, J.; Kasabov, N. Change Detection of Optical Remote Sensing Image Disturbed by Thin Cloud Using Wavelet Coefficient Substitution Algorithm. Sensors 2019, 19, 1972. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Wu, Z.; Hu, Z.; Li, Z.; Wang, Y.; Molinier, M. Deep Learning Based Thin Cloud Removal Fusing Vegetation Red Edge and Short Wave Infrared Spectral Information for Sentinel-2A Imagery. Remote Sens. 2021, 13, 157. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Stark, R.; Rundquist, D. Novel algorithms for remote estimation of vegetation fraction. Remote Sens. Environ. 2002, 80, 76–87. [Google Scholar] [CrossRef] [Green Version]
- Lin, F.; Guo, S.; Tan, C.; Zhou, X.; Zhang, D. Identification of Rice Sheath Blight through Spectral Responses Using Hyperspectral Images. Sensors 2020, 20, 6243. [Google Scholar] [CrossRef]
- Harrell, D.; Tubana, B.; Walker, T.; Phillips, S. Estimating rice grain yield potential using normalized difference vegetation index. Agron. J. 2011, 103, 1717–1723. [Google Scholar] [CrossRef]
- Campos, J.; García-Ruíz, F.; Gil, E. Assessment of Vineyard Canopy Characteristics from Vigour Maps Obtained Using UAV and Satellite Imagery. Sensors 2021, 21, 2363. [Google Scholar] [CrossRef] [PubMed]
- Devia, C.A.; Rojas, J.P.; Petro, E.; Martinez, C.; Mondragon, I.F.; Patino, D.; Rebolledo, M.C.; Colorado, J. High-throughput biomass estimation in rice crops using UAV multispectral imagery. J. Intell. Robot. Syst. 2019, 96, 573–589. [Google Scholar] [CrossRef]
- Colorado, J.D.; Cera-Bornacelli, N.; Caldas, J.S.; Petro, E.; Rebolledo, M.C.; Cuellar, D.; Calderon, F.; Mondragon, I.F.; Jaramillo-Botero, A. Estimation of Nitrogen in Rice Crops from UAV-Captured Images. Remote Sens. 2020, 12, 3396. [Google Scholar] [CrossRef]
- Hernández-Vela, A.; Reyes, M.; Ponce, V.; Escalera, S. Grabcut-based human segmentation in video sequences. Sensors 2012, 12, 15376–15393. [Google Scholar] [CrossRef] [PubMed]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Mortensen, E.N.; Barrett, W.A. Intelligent scissors for image composition. In Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 6–11 August 1995; pp. 191–198. [Google Scholar]
- Xiong, J.; Po, L.M.; Cheung, K.W.; Xian, P.; Zhao, Y.; Rehman, Y.A.U.; Zhang, Y. Edge-Sensitive Left Ventricle Segmentation Using Deep Reinforcement Learning. Sensors 2021, 21, 2375. [Google Scholar] [CrossRef]
- Liu, B.; Liu, Z.; Li, Y.; Zhang, T.; Zhang, Z. Iterative Min Cut Clustering Based on Graph Cuts. Sensors 2021, 21, 474. [Google Scholar] [CrossRef]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 105–112. [Google Scholar]
- Castro, W.; Marcato Junior, J.; Polidoro, C.; Osco, L.P.; Gonçalves, W.; Rodrigues, L.; Santos, M.; Jank, L.; Barrios, S.; Valle, C.; et al. Deep learning applied to phenotyping of biomass in forages with UAV-based RGB imagery. Sensors 2020, 20, 4802. [Google Scholar] [CrossRef]
- Kalofolias, V.; Perraudin, N. Large Scale Graph Learning From Smooth Signals. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Parada-Mayorga, A.; Lau, D.L.; Giraldo, J.H.; Arce, G.R. Blue-noise sampling on graphs. IEEE Trans. Signal Inf. Process. Netw. 2019, 5, 554–569. [Google Scholar] [CrossRef] [Green Version]
- Shapiro, A. Monte Carlo sampling methods. In Handbooks in Operations Research and Management Science; Elsevier: Amsterdam, The Netherlands, 2003; Volume 10, pp. 353–425. [Google Scholar]
- Petschnigg, G.; Szeliski, R.; Agrawala, M.; Cohen, M.; Hoppe, H.; Toyama, K. Digital photography with flash and no-flash image pairs. ACM Trans. Graph. (TOG) 2004, 23, 664–672. [Google Scholar] [CrossRef]
- Correa, E.S.; Francisco Calderon, J.D.C. GFkuts: A novel multispectral image segmentation method applied to precision agriculture. In Proceedings of the Virtual Symposium in Plant Omics Sciences (OMICAS), Cali, Colombia, 23–27 November 2020. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–14. [Google Scholar]
- Fowlkes, C.; Belongie, S.; Chung, F.; Malik, J. Spectral grouping using the Nystrom method. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 214–225. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, S.; Mohri, M.; Talwalkar, A. Sampling methods for the Nyström method. J. Mach. Learn. Res. 2012, 13, 981–1006. [Google Scholar]
- Dong, X.; Thanou, D.; Rabbat, M.; Frossard, P. Learning graphs from data: A signal representation perspective. IEEE Signal Process. Mag. 2019, 36, 44–63. [Google Scholar] [CrossRef] [Green Version]
- Tanaka, Y.; Eldar, Y.C.; Ortega, A.; Cheung, G. Sampling Signals on Graphs: From Theory to Applications. IEEE Signal Process. Mag. 2020, 37, 14–30. [Google Scholar] [CrossRef]
- Iyer, G.; Chanussot, J.; Bertozzi, A.L. A Graph-Based Approach for Data Fusion and Segmentation of Multimodal Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4419–4429. [Google Scholar] [CrossRef]
- Lau, D.L.; Arce, G.R. Modern Digital Halftoning; CRC Press: Boca Raton, FL, USA, 2018; Volume 1. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Laref, R.; Losson, E.; Sava, A.; Siadat, M. On the optimization of the support vector machine regression hyperparameters setting for gas sensors array applications. Chemom. Intell. Lab. Syst. 2019, 184, 22–27. [Google Scholar] [CrossRef]
- Huo, F.; Poo, A.N. Nonlinear autoregressive network with exogenous inputs based contour error reduction in CNC machines. Int. J. Mach. Tools Manuf. 2013, 67, 45–52. [Google Scholar] [CrossRef]
- Men, Z.; Yee, E.; Lien, F.S.; Yang, Z.; Liu, Y. Ensemble nonlinear autoregressive exogenous artificial neural networks for short-term wind speed and power forecasting. Int. Sch. Res. Not. 2014, 2014, 972580. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haviluddin; Alfred, R. Performance of modeling time series using nonlinear autoregressive with eXogenous input (NARX) in the network traffic forecasting. In Proceedings of the 2015 International Conference on Science in Information Technology (ICSITech), Yogyakarta, Indonesia, 27–28 October 2015; pp. 164–168. [Google Scholar]
- Boussaada, Z.; Curea, O.; Remaci, A.; Camblong, H.; Mrabet Bellaaj, N. A nonlinear autoregressive exogenous (NARX) neural network model for the prediction of the daily direct solar radiation. Energies 2018, 11, 620. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters | |||
|---|---|---|---|---|
| GFKuts [3] | k-neighbors | window radius | - | |
| GBF [4] | - | - | t-SNE | |
| GBF-Sm-Bs | edges/node | window size | t-SNE | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jimenez-Sierra, D.A.; Correa, E.S.; Benítez-Restrepo, H.D.; Calderon, F.C.; Mondragon, I.F.; Colorado, J.D. Novel Feature-Extraction Methods for the Estimation of Above-Ground Biomass in Rice Crops. Sensors 2021, 21, 4369. https://doi.org/10.3390/s21134369
Jimenez-Sierra DA, Correa ES, Benítez-Restrepo HD, Calderon FC, Mondragon IF, Colorado JD. Novel Feature-Extraction Methods for the Estimation of Above-Ground Biomass in Rice Crops. Sensors. 2021; 21(13):4369. https://doi.org/10.3390/s21134369
Chicago/Turabian StyleJimenez-Sierra, David Alejandro, Edgar Steven Correa, Hernán Darío Benítez-Restrepo, Francisco Carlos Calderon, Ivan Fernando Mondragon, and Julian D. Colorado. 2021. "Novel Feature-Extraction Methods for the Estimation of Above-Ground Biomass in Rice Crops" Sensors 21, no. 13: 4369. https://doi.org/10.3390/s21134369
APA StyleJimenez-Sierra, D. A., Correa, E. S., Benítez-Restrepo, H. D., Calderon, F. C., Mondragon, I. F., & Colorado, J. D. (2021). Novel Feature-Extraction Methods for the Estimation of Above-Ground Biomass in Rice Crops. Sensors, 21(13), 4369. https://doi.org/10.3390/s21134369