
Optimally-Weighted Image-Pose Approach (OWIPA) for Distracted Driver Detection and Classification

 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
- Using pose estimation (hand and body pose) classification to classify the distraction.
- Propose Optimally-weighted Image-Pose Approach (OWIPA) to classify distraction through original and pose estimation images.
- Using grid-search algorithm to deduce the weight for maximum prediction accuracy.
2. Literature Review
2.1. Distraction Detection
2.2. Pose Estimation
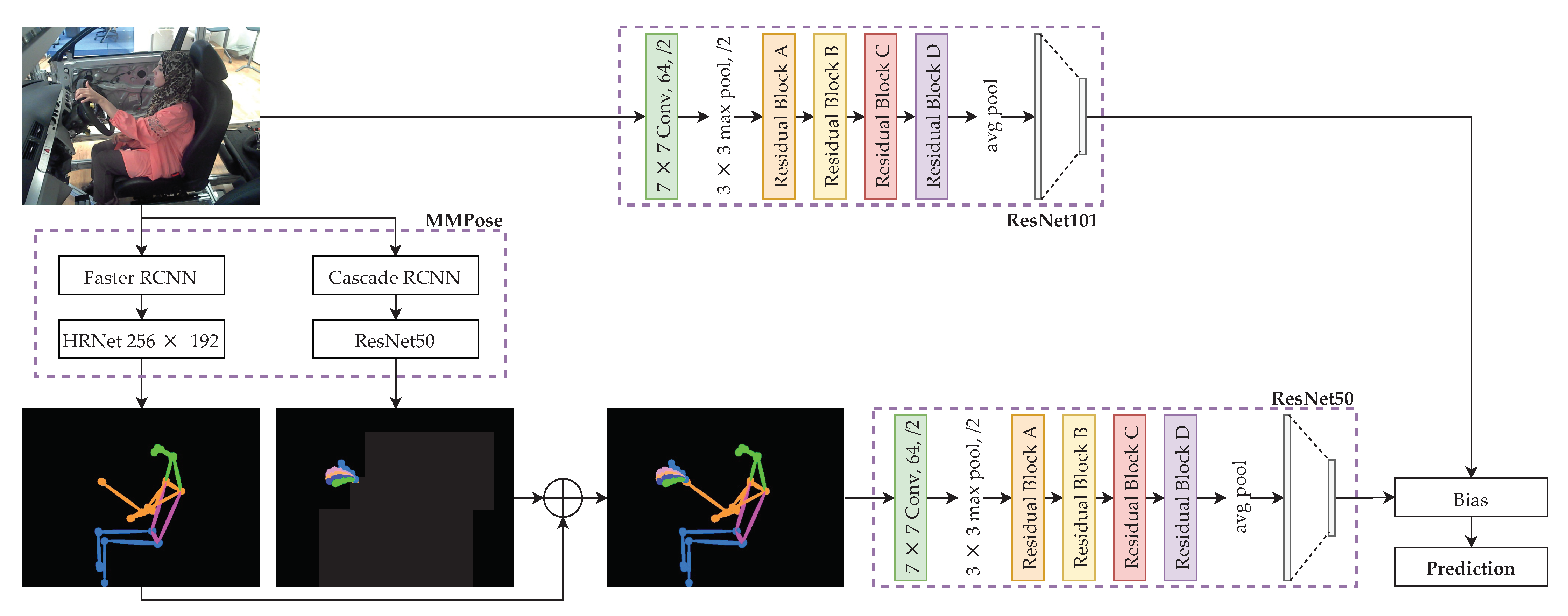
3. Optimally-Weighted Image-Pose Approach (OWIPA)
4. Experiments
4.1. Evaluation Metrics
- Accuracy. It is the proportion of correct predictions among the total number of input samples. Accuracy is considered to be a valid evaluation metric only if the dataset is balanced. High accuracy in an almost equal dataset represents a good model.
- F1 Score. It provides a better measure to predicted result. It is the weighted average of precision and recall, as given in Equation (2).F1 score is commonly used when the balance between precision and recall is required. It is a better measure for uneven class distributions, such as a large number of true negative. Therefore, it is preferable for this study since the dataset is uneven.
- Area Under the ROC Curve (AUC). It measures the area underneath the entire ROC curve. It is used to measure the ability of a classifier to distinguish between classes. High AUC represents a perfect model, where it can distinguish between positive and negative classes.
- Cross-entropy loss or negative log-likelihood (NLL) loss. It is used to measure the performance of a classification model, with output of class probability between 0 and 1. This measures the difference between the actual label using the log of the predicted probability. The cross-entropy loss is to produce higher accuracy. The categorical cross-entropy loss is calculated as given in Equation (3).where N is the number of instances, M is the number of classes, is 1 when i belongs to class j and is the prediction probability of instance i belonging to class j.
4.2. Dataset Description
4.3. Experiment Environment
4.3.1. Pose Estimation
4.3.2. Transfer Learning Procedure
- The newly added head of the network is trained while preserving the ImageNet [25] weights for the rest of the body. The newly added head is trained for 10 epochs with discriminative learning rate [53] described in Section 4.3.4.
- The whole network, including body and head of model, is fined-tuned for 20 epochs using discriminative learning rate described in Section 4.3.4.
4.3.3. Optimizer
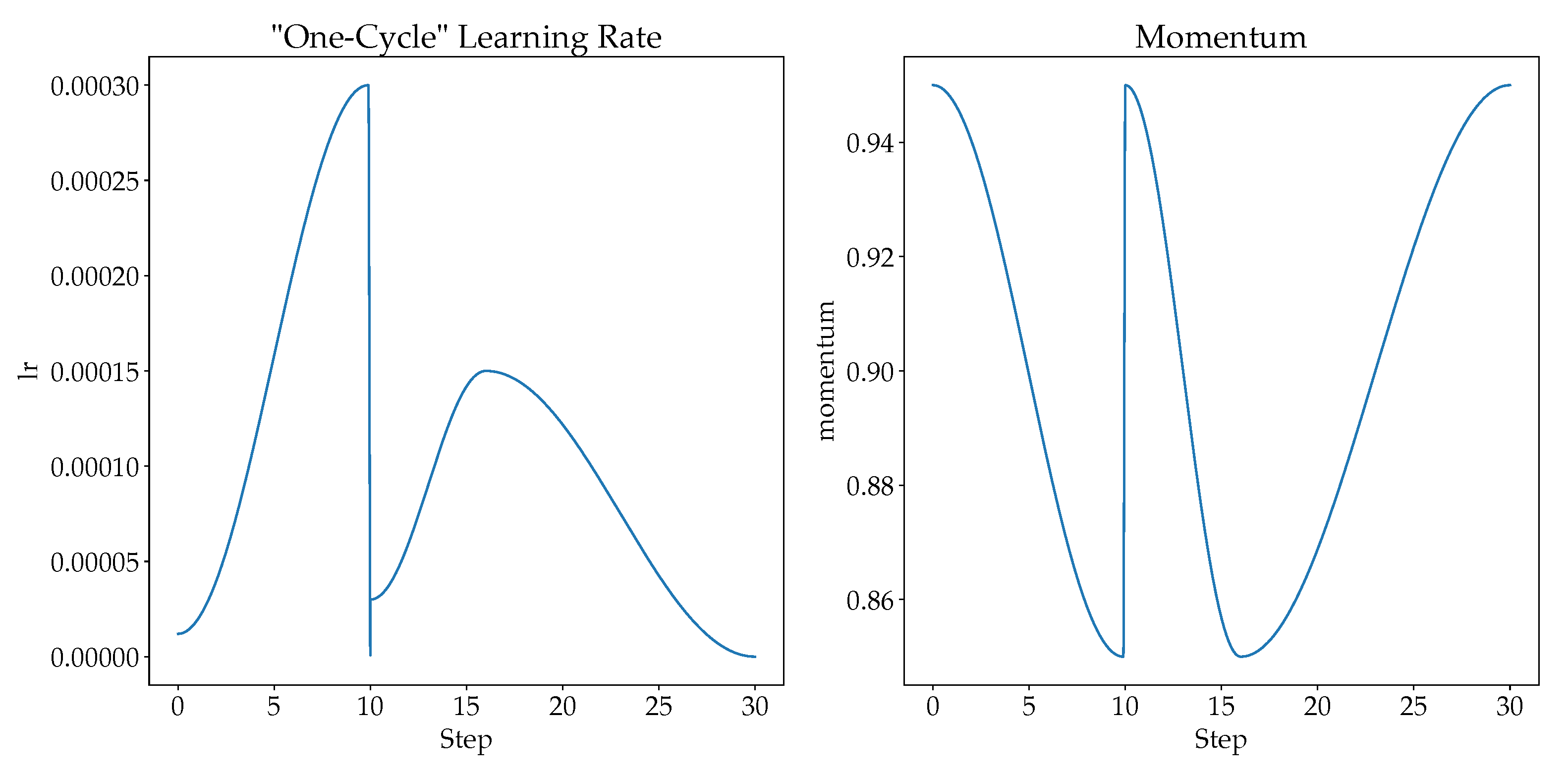
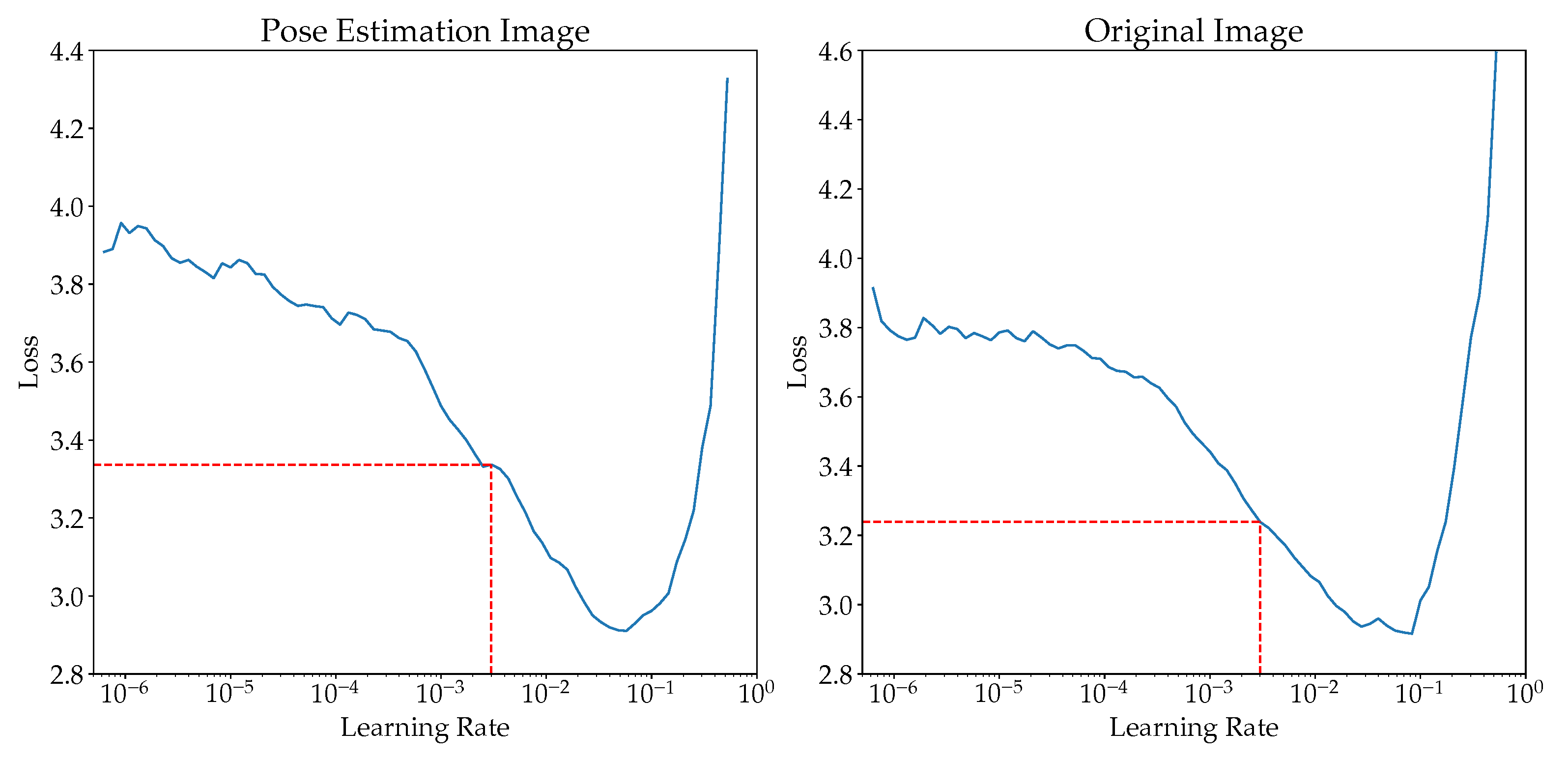
4.3.4. Learning Rates
5. Results and Discussion
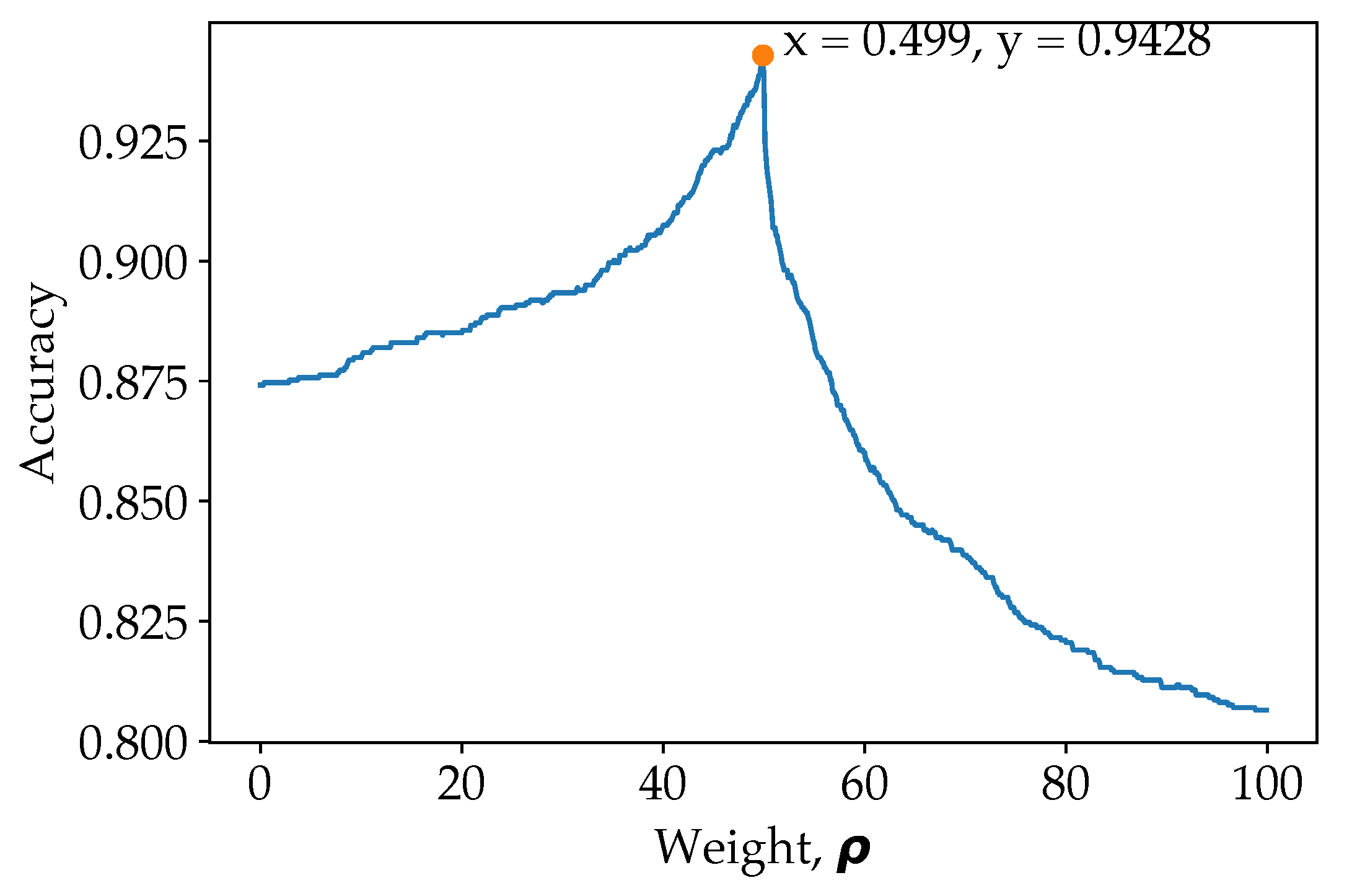
5.1. Selection of Hyperparameter
5.2. Fusion of Multiple Models
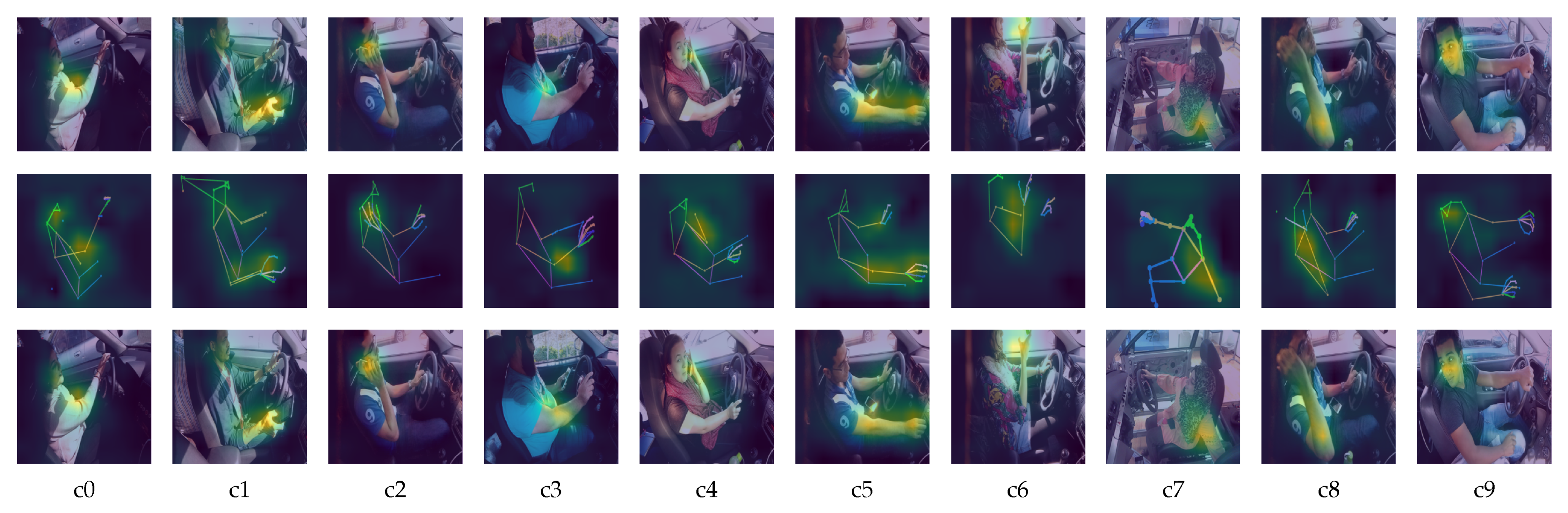
5.3. Performance of OWIPA
- The usage of "one-cycle" learning rate increases the accuracy and reduces the training loss.
- More epochs are needed to train the newly-added head classifier when performing transfer learning.
- Higher resolution images can increase total accuracy and reduce loss, with minimal increase in total training time.
- The usage of pose estimation images in classifying the class of distraction is useful when coupled with the original image classification model. It is observed that there is about 2% increase in the accuracy as compared to using the original image to perform classification.
- The introduction of weight can increase the accuracy of the model further. Pose estimation images classification should be weighed more to increase the overall classification accuracy.
6. Conclusions
- Using keypoint from pose estimation method to classify the action and fuse with the original image classification model.
- Using a dynamic weight for every class. As shown in this work, a fixed weight for overall classification can increase accuracy, but it is observed that some class perform worse than before. Therefore, every class should have its own weight to produce higher accuracy for each class.
- Acquiring video stream of the distracted driving and learning the video’s temporal features, coupled with our proposed model, to produce a better classification.
- Implementing other pre-trained CNNs and applying our proposed techniques to achieve higher accuracy and shorter training time.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Additional Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Learning Rate | ResNet18 | ResNet34 | ResNet50 | ResNet101 | ||||
|---|---|---|---|---|---|---|---|---|
| Epoch: 5/10 | ||||||||
| 0.3587 | 0.3033 | 0.2582 | 0.3025 | 0.2465 | 0.3033 | 0.3344 | 0.2477 | |
| “one-cycle” | 0.7658 | 0.8205 | 0.8442 | 0.8191 | 0.8115 | 0.8243 | 0.8499 | 0.7603 |
| Epoch: 5/20 | ||||||||
| 0.4315 | 0.4355 | 0.3013 | 0.2704 | 0.3356 | 0.2324 | 0.2183 | 0.2255 | |
| “one-cycle” | 0.8473 | 0.7801 | 0.8518 | 0.8603 | 0.7801 | 0.8541 | 0.7764 | 0.8910 |
| Epoch: 10/20 | ||||||||
| 0.4437 | 0.3598 | 0.2487 | 0.2959 | 0.2069 | 0.2589 | 0.2599 | 0.2673 | |
| “one-cycle” | 0.7717 | 0.8444 | 0.8372 | 0.8577 | 0.7682 | 0.8870 | 0.8021 | 0.8874 |
| Learning Rate | ResNet18 | ResNet34 | ResNet50 | ResNet101 | ||||
|---|---|---|---|---|---|---|---|---|
| Epoch: 5/10 | ||||||||
| 0.6543 | 0.7305 | 0.6676 | 0.7030 | 0.6984 | 0.6713 | 0.5890 | 0.5598 | |
| “one-cycle” | 0.7300 | 0.7480 | 0.7660 | 0.7737 | 0.7694 | 0.8012 | 0.7493 | 0.7510 |
| Epoch: 5/20 | ||||||||
| 0.6858 | 0.6841 | 0.6809 | 0.6595 | 0.6778 | 0.7053 | 0.6165 | 0.6962 | |
| “one-cycle” | 0.8005 | 0.7437 | 0.8007 | 0.7416 | 0.7350 | 0.7257 | 0.7437 | 0.7545 |
| Epoch: 10/20 | ||||||||
| 0.6673 | 0.6862 | 0.6681 | 0.7490 | 0.6582 | 0.6307 | 0.6293 | 0.5912 | |
| “one-cycle” | 0.7583 | 0.7985 | 0.7624 | 0.7693 | 0.7135 | 0.8063 | 0.7334 | 0.7655 |
Appendix A.1. Selection of Learning Rate

Appendix A.2. Effects of Learning Rates
Appendix A.3. Effects of Image Size
Appendix A.4. Effect of Training Epochs
- Usage of “one-cycle” learning rate will help the model to regularize well, even with less training epochs.
- Higher resolution of images will help the model to capture more features. However, more training epochs are needed.
- Selection of training epochs should be balanced between training of newly added head and the whole models. Early stopping could be deployed as well.
References
- National Center for Statistics and Analysis. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/812926 (accessed on 13 July 2021).
- World Health Organization. Road Traffic Injuries. 2020. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 13 July 2021).
- Strayer, D.L.; Cooper, J.M.; Turrill, J.; Coleman, J.; Medeiros-Ward, N.; Biondi, F. Measuring Cognitive Distraction in the Automobile. 2013. Available online: https://aaafoundation.org/measuring-cognitive-distraction-automobile/ (accessed on 13 July 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 770–778. [Google Scholar]
- Mafeni Mase, J.; Chapman, P.; Figueredo, G.P.; Torres Torres, M. A Hybrid Deep Learning Approach for Driver Distraction Detection. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, South Korea, 21–23 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mase, J.M.; Chapman, P.; Figueredo, G.P.; Torres, M.T. Benchmarking deep learning models for driver distraction detection. In Proceedings of the International Conference on Machine Learning, Optimization, and Data Science, Siena, Italy, 19–23 July 2020; pp. 103–117. [Google Scholar]
- Alotaibi, M.; Alotaibi, B. Distracted driver classification using deep learning. Signal Image Video Process 2019, 14, 1–8. [Google Scholar] [CrossRef]
- Eraqi, H.M.; Abouelnaga, Y.; Saad, M.H.; Moustafa, M.N. Driver distraction identification with an ensemble of convolutional neural networks. J. Adv. Transp. 2019. [Google Scholar] [CrossRef]
- Abouelnaga, Y.; Eraqi, H.M.; Moustafa, M.N. Real-time distracted driver posture classification. arXiv 2017, arXiv:1706.09498. Available online: https://arxiv.org/pdf/1706.09498.pdf (accessed on 13 July 2021).
- Berri, R.A.; Silva, A.G.; Parpinelli, R.S.; Girardi, E.; Arthur, R. A pattern recognition system for detecting use of mobile phones while driving. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; pp. 411–418. [Google Scholar]
- Craye, C.; Karray, F. Driver distraction detection and recognition using RGB-D sensor. arXiv 2015, arXiv:1502.00250. Available online: https://arxiv.org/pdf/1502.00250.pdf (accessed on 13 July 2021).
- Artan, Y.; Bulan, O.; Loce, R.P.; Paul, P. Driver cell phone usage detection from HOV/HOT NIR images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, San Juan, PR, USA, 17–19 June 1997; pp. 225–230. [Google Scholar]
- Zhang, X.; Zheng, N.; Wang, F.; He, Y. Visual recognition of driver hand-held cell phone use based on hidden CRF. In Proceedings of the 2011 IEEE International Conference on Vehicular Electronics and Safety, Beijing, China, 10–12 July 2011; pp. 248–251. [Google Scholar]
- Seshadri, K.; Juefei-Xu, F.; Pal, D.K.; Savvides, M.; Thor, C.P. Driver cell phone usage detection on strategic highway research program (SHRP2) face view videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–15 June 2015; pp. 35–43. [Google Scholar]
- StateFarm Distracted Driver Detection Dataset. 2016. Available online: https://www.kaggle.com/c/state-farm-distracted-driver-detection (accessed on 13 July 2021).
- Weng, C.H.; Lai, Y.H.; Lai, S.H. Driver drowsiness detection via a hierarchical temporal deep belief network. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 117–133. [Google Scholar]
- Ortega, J.D.; Kose, N.; Cañas, P.; Chao, M.A.; Unnervik, A.; Nieto, M.; Otaegui, O.; Salgado, L. Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis. arXiv 2020, arXiv:2008.12085. Available online: https://arxiv.org/pdf/2008.12085.pdf (accessed on 13 July 2021).
- Ohn-Bar, E.; Martin, S.; Trivedi, M. Driver hand activity analysis in naturalistic driving studies: Challenges, algorithms, and experimental studies. J. Electron. Imaging 2013, 22, 041119. [Google Scholar] [CrossRef]
- Ohn-Bar, E.; Martin, S.; Tawari, A.; Trivedi, M.M. Head, eye, and hand patterns for driver activity recognition. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 660–665. [Google Scholar]
- Martin, S.; Ohn-Bar, E.; Tawari, A.; Trivedi, M.M. Understanding head and hand activities and coordination in naturalistic driving videos. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 884–889. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. In-vehicle hand activity recognition using integration of regions. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, Australia, 23–26 June 2013; pp. 1034–1039. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. The power is in your hands: 3D analysis of hand gestures in naturalistic video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 912–917. [Google Scholar]
- Ihab, S. Academic Purposes? 2021. Available online: https://www.kaggle.com/c/state-farm-distracted-driver-detection/discussion/20043 (accessed on 13 July 2021).
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23–28 June 2018; pp. 8697–8710. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. Available online: https://arxiv.org/pdf/1704.04861.pdf (accessed on 13 July 2021).
- Chung, J.; Ahn, S.; Bengio, Y. Hierarchical multiscale recurrent neural networks. arXiv 2016, arXiv:1609.01704. Available online: https://arxiv.org/pdf/1609.0170.pdf (accessed on 13 July 2021).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 23–28 June 2016; pp. 2818–2826. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/pdf/1409.1556.pdf (accessed on 13 July 2021).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Kim, W.; Choi, H.K.; Jang, B.T.; Lim, J. Driver distraction detection using single convolutional neural network. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 18–20 October 2017; pp. 1203–1205. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Majdi, M.S.; Ram, S.; Gill, J.T.; Rodríguez, J.J. Drive-net: Convolutional network for driver distraction detection. In Proceedings of the 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Las Vegas, NV, USA, 8–10 April 2018; pp. 1–4. [Google Scholar]
- Yan, C.; Coenen, F.; Zhang, B. Driving posture recognition by convolutional neural networks. IET Comput. Vis. 2016, 10, 103–114. [Google Scholar] [CrossRef]
- Elings, J.W. Driver Handheld Cell Phone Usage Detection. Master’s Thesis. 2018. Available online: http://dspace.library.uu.nl/handle/1874/371744 (accessed on 13 July 2021).
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.V.; Schiele, B. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 7291–7299. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Martin, M.; Stuehmer, S.; Voit, M.; Stiefelhagen, R. Real time driver body pose estimation for novel assistance systems. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–7. [Google Scholar]
- Zhao, Z.; Xia, S.; Xu, X.; Zhang, L.; Yan, H.; Xu, Y.; Zhang, Z. Driver Distraction Detection Method Based on Continuous Head Pose Estimation. Comput. Intell. Neurosci. 2020, 2020. [Google Scholar] [CrossRef]
- Hu, T.; Jha, S.; Busso, C. Robust driver head pose estimation in naturalistic conditions from point-cloud data. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 23–30 June 2020; pp. 1176–1182. [Google Scholar]
- Ercolano, G.; Rossi, S. Combining CNN and LSTM for activity of daily living recognition with a 3D matrix skeleton representation. Intell. Serv. Robot. 2021, 14, 175–185. [Google Scholar] [CrossRef]
- Solongontuya, B.; Cheoi, K.J.; Kim, M.H. Novel side pose classification model of stretching gestures using three-layer LSTM. J. Supercomput. 2021, 1–17. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Peng, C.; Liu, Y. Mask-pose cascaded cnn for 2d hand pose estimation from single color image. IEEE Trans. Circuits. Syst. Video Technol. 2018, 29, 3258–3268. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Howard, J.; Gugger, S. Fastai: A layered API for deep learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- MMPose Contributors. OpenMMLab Pose Estimation Toolbox and Benchmark. Available online: https://github.com/open-mmlab/mmpose (accessed on 13 July 2021).
- Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1–learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:1803.09820. Available online: https://arxiv.org/pdf/1803.09820.pdf (accessed on 13 July 2021).
- Schmidt, R.M.; Schneider, F.; Hennig, P. Descending through a Crowded Valley–Benchmarking Deep Learning Optimizers. arXiv 2020, arXiv:2007.01547. Available online: https://arxiv.org/pdf/2007.01547.pdf (accessed on 13 July 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Wightman, R. PyTorch Image Models. Available online: https://github.com/rwightman/pytorch-image-models (accessed on 13 July 2021). [CrossRef]








| Layer | Output size | ResNet50 | ResNet101 |
|---|---|---|---|
| Input | Input image | ||
| Convolution | , 64, stride 2 | ||
| Max pool | max pool, stride 2 | ||
| Residual Block | |||
| Residual Block | |||
| Residual Block | |||
| Residual Block | |||
| Avg pool | Average poll, Fully connected | ||
| Flatten | 4096 | Flatten, BatchNorm | |
| Dropout | 512 | Dropout, , ReLU, BatchNorm | |
| Output | 10 | Dropout, , Linear | |
| Class | Description | Training Size (Images) | Validation Size (Images) | Testing Size (Images) |
|---|---|---|---|---|
| c0 | Safe driving | 2107 | 533 | 346 |
| c1 | Text right | 1207 | 298 | 213 |
| c2 | Right phone usage | 836 | 226 | 194 |
| c3 | Text left | 762 | 182 | 180 |
| c4 | Left phone usage | 914 | 236 | 170 |
| c5 | Adjusting radio | 745 | 208 | 170 |
| c6 | Drinking | 753 | 180 | 143 |
| c7 | Reaching behind | 716 | 175 | 143 |
| c8 | Hair or makeup | 724 | 174 | 146 |
| c9 | Talking to passenger | 1280 | 299 | 218 |
| Total | 10,044 | 2511 | 1923 | |
| Model | ResNet18 | ResNet34 | ResNet50 | ResNet101 | ResNet50+ ResNet101 | ResNet50 (O)+ ResNet50 (P) | ResNet101 (O)+ ResNet50 (P) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data | Ori | Pose | Ori | Pose | Ori | Pose | Ori | Pose | Ori | Ori + Pose | Ori + Pose | ||
| - | - | - | - | - | - | - | - | - | - | 0.498 | - | 0.499 | |
| TT (min) | 175 | 210 | 186 | 213 | 209 | 244 | 355 | 388 | 433 | 453 | 453 | 599 | 599 |
| CL | 0.0356 | 0.0875 | 0.0284 | 0.1162 | 0.0292 | 0.0613 | 0.0300 | 0.0876 | 0.0296 | 0.0453 | 0.0366 | 0.0457 | 0.0455 |
| Acc | 0.8487 | 0.8003 | 0.8544 | 0.7629 | 0.8851 | 0.8066 | 0.8846 | 0.7686 | 0.9012 | 0.9215 | 0.9262 | 0.9376 | 0.9428 |
| F1 | 0.8444 | 0.7985 | 0.8577 | 0.7693 | 0.8870 | 0.8063 | 0.8874 | 0.7655 | 0.9033 | 0.9210 | 0.9259 | 0.9375 | 0.9427 |
| AUC | 0.9948 | 0.9873 | 0.9936 | 0.9837 | 0.9964 | 0.9857 | 0.9948 | 0.9821 | 0.9956 | 0.9911 | 0.9932 | 0.9940 | 0.9937 |
| c0 | 0.7010 | 0.7463 | 0.8108 | 0.7458 | 0.8594 | 0.8043 | 0.8650 | 0.7012 | 0.8896 | 0.9240 | 0.9208 | 0.9231 | 0.9149 |
| c1 | 0.9187 | 0.9057 | 0.9330 | 0.7657 | 0.9067 | 0.8377 | 0.8354 | 0.7100 | 0.8773 | 0.9647 | 0.9697 | 0.9456 | 0.9531 |
| c2 | 0.8600 | 0.7753 | 0.8496 | 0.7907 | 0.9022 | 0.7650 | 0.9370 | 0.8376 | 0.9430 | 0.9227 | 0.9391 | 0.9242 | 0.9291 |
| c3 | 0.9422 | 0.8116 | 0.8035 | 0.8042 | 0.8774 | 0.8199 | 0.9003 | 0.7321 | 0.9053 | 0.9330 | 0.9358 | 0.9489 | 0.9518 |
| c4 | 0.8883 | 0.9471 | 0.9708 | 0.9172 | 0.9426 | 0.9499 | 0.9441 | 0.8951 | 0.9444 | 0.9677 | 0.9676 | 0.9853 | 0.9853 |
| c5 | 1 | 0.9412 | 0.9971 | 0.9226 | 0.9851 | 0.9499 | 1 | 0.9046 | 1 | 0.9827 | 0.9913 | 0.9884 | 0.9942 |
| c6 | 0.8947 | 0.6570 | 0.9104 | 0.6240 | 0.9023 | 0.6644 | 0.9254 | 0.6745 | 0.9294 | 0.8603 | 0.8800 | 0.9084 | 0.9242 |
| c7 | 0.8624 | 0.8034 | 0.7760 | 0.6272 | 0.8239 | 0.7922 | 0.8299 | 0.8103 | 0.8309 | 0.8800 | 0.8800 | 0.9108 | 0.9256 |
| c8 | 0.7148 | 0.6300 | 0.7213 | 0.6567 | 0.7569 | 0.6412 | 0.7538 | 0.6145 | 0.8050 | 0.8266 | 0.8375 | 0.8809 | 0.9014 |
| c9 | 0.7915 | 0.7621 | 0.8238 | 0.7629 | 0.9051 | 0.7931 | 0.8894 | 0.8074 | 0.9024 | 0.9074 | 0.9074 | 0.9522 | 0.9593 |
| Ref | CNN Model | PT | BS | LR | Optimizer | Epochs | ACL | AA | AF | IT |
|---|---|---|---|---|---|---|---|---|---|---|
| [6] | AlexNet | ✓ | 32 | 0.0001 | Adam | 50 (5) | 1.024 | 0.738 | 0.741 | 2.61 |
| [8] | GWE-Resnet50 | ✗ | 50 | 0.01 | GD | 30 | 0.6615 | 0.8169 | NA | NA |
| [6] | VGG-19 | ✓ | 32 | 0.0001 | Adam | 50 (5) | 0.531 | 0.833 | 0.835 | 20.46 |
| [7] | HRNN | ✓ | 80 | 0.001 | Adam | 30 | NA | 0.8485 | NA | 71 |
| [6] | ResNet50 | ✓ | 32 | 0.0001 | Adam | 50 (5) | 0.442 | 0.877 | 0.882 | 14.26 |
| [6] | InceptionV3 | ✓ | 32 | 0.0001 | Adam | 50 (5) | 0.442 | 0.884 | 0.890 | 22.85 |
| [5] | InceptionV3 | ✓ | NA | NA | NA | NA | 0.5723 | 0.8841 | NA | 22.85 |
| [6] | InceptionV3-RNN | ✓ | 16 | 0.0001 | Adam | 50 (5) | 0.418 | 0.884 | 0.899 | 23.42 |
| [7] | ResNet152 | ✓ | 80 | 0.001 | Adam | 30 | NA | 0.8852 | NA | 62 |
| [6] | Densenet-201 | ✓ | 32 | 0.0001 | Adam | 50 (5) | 0.395 | 0.890 | 0.895 | 46.05 |
| [5] | InceptionV3-LSTM | ✓ | 16 | 0.0001 | Adam | 50 (5) | 0.4445 | 0.8982 | NA | 23.24 |
| [8] | GWE-InceptionV3 | ✗ | 50 | 0.01 | GD | 30 | 0.6400 | 0.9006 | NA | NA |
| [6] | InceptionV3-LSTM | ✓ | 16 | 0.0001 | Adam | 50 (5) | 0.375 | 0.902 | 0.906 | 23.24 |
| [6] | InceptionV3-GRU | ✓ | 16 | 0.0001 | Adam | 50 (5) | 0.348 | 0.903 | 0.909 | 23.18 |
| [6] | InceptionV3-BiLSTM | ✓ | 8 | 0.0001 | Adam | 50 (5) | 0.292 | 0.917 | 0.931 | 23.30 |
| [6] | InceptionV3-BiGRU | ✓ | 8 | 0.0001 | Adam | 50 (5) | 0.336 | 0.917 | 0.922 | 23.24 |
| [7] | ResNet+HRNN+Inception | ✓ | 80 | 0.001 | Adam | 30 | NA | 0.9236 | NA | 114 |
| [5] | InceptionV3-BiLSTM | ✗ | 32 | 0.0001 | Adam | 50 | 0.2793 | 0.9270 | NA | 23.30 |
| Ours | ResNet101 (O) + ResNet50 (P) (with weight) | ✓ | 32 | 1-cycle | Adam | 10/20 | 0.0455 | 0.9428 | 0.9427 | 668.20 |
| Hyperparamer Setting | Original Image | Pose Estimation Image | |||
|---|---|---|---|---|---|
| Model | Learning Rate | Epochs | Image Size | ||
| ResNet18 | 0.003 | 5/10 | 0.3587 | 0.6543 | |
| ResNet18 | “one-cycle” | 5/10 | 0.7658 | 0.7300 | |
| ResNet18 | “one-cycle” | 5/10 | 0.8205 | 0.7480 | |
| ResNet101 | “one-cycle” | 5/10 | 0.7603 | 0.7510 | |
| ResNet101 | “one-cycle” | 5/20 | 0.8910 | 0.7545 | |
| ResNet50 | “one-cycle” | 10/20 | 0.8870 | 0.8063 | |
| ResNet101 | “one-cycle” | 10/20 | 0.8874 | 0.7655 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koay, H.V.; Chuah, J.H.; Chow, C.-O.; Chang, Y.-L.; Rudrusamy, B. Optimally-Weighted Image-Pose Approach (OWIPA) for Distracted Driver Detection and Classification. Sensors 2021, 21, 4837. https://doi.org/10.3390/s21144837
Koay HV, Chuah JH, Chow C-O, Chang Y-L, Rudrusamy B. Optimally-Weighted Image-Pose Approach (OWIPA) for Distracted Driver Detection and Classification. Sensors. 2021; 21(14):4837. https://doi.org/10.3390/s21144837
Chicago/Turabian StyleKoay, Hong Vin, Joon Huang Chuah, Chee-Onn Chow, Yang-Lang Chang, and Bhuvendhraa Rudrusamy. 2021. "Optimally-Weighted Image-Pose Approach (OWIPA) for Distracted Driver Detection and Classification" Sensors 21, no. 14: 4837. https://doi.org/10.3390/s21144837
APA StyleKoay, H. V., Chuah, J. H., Chow, C. -O., Chang, Y. -L., & Rudrusamy, B. (2021). Optimally-Weighted Image-Pose Approach (OWIPA) for Distracted Driver Detection and Classification. Sensors, 21(14), 4837. https://doi.org/10.3390/s21144837