
Pupil Size Prediction Techniques Based on Convolution Neural Network

 , , , ,
, , , ,
Abstract
:1. Introduction
- We have proposed pupil size detection based on a convolution neural network that allows real-time calculation in a low-cost mobile embedded system.
- We have evaluated the performance of the proposed approach with multiple realistic datasets for optimizing the structure.
2. Materials and Methods
2.1. Dataset
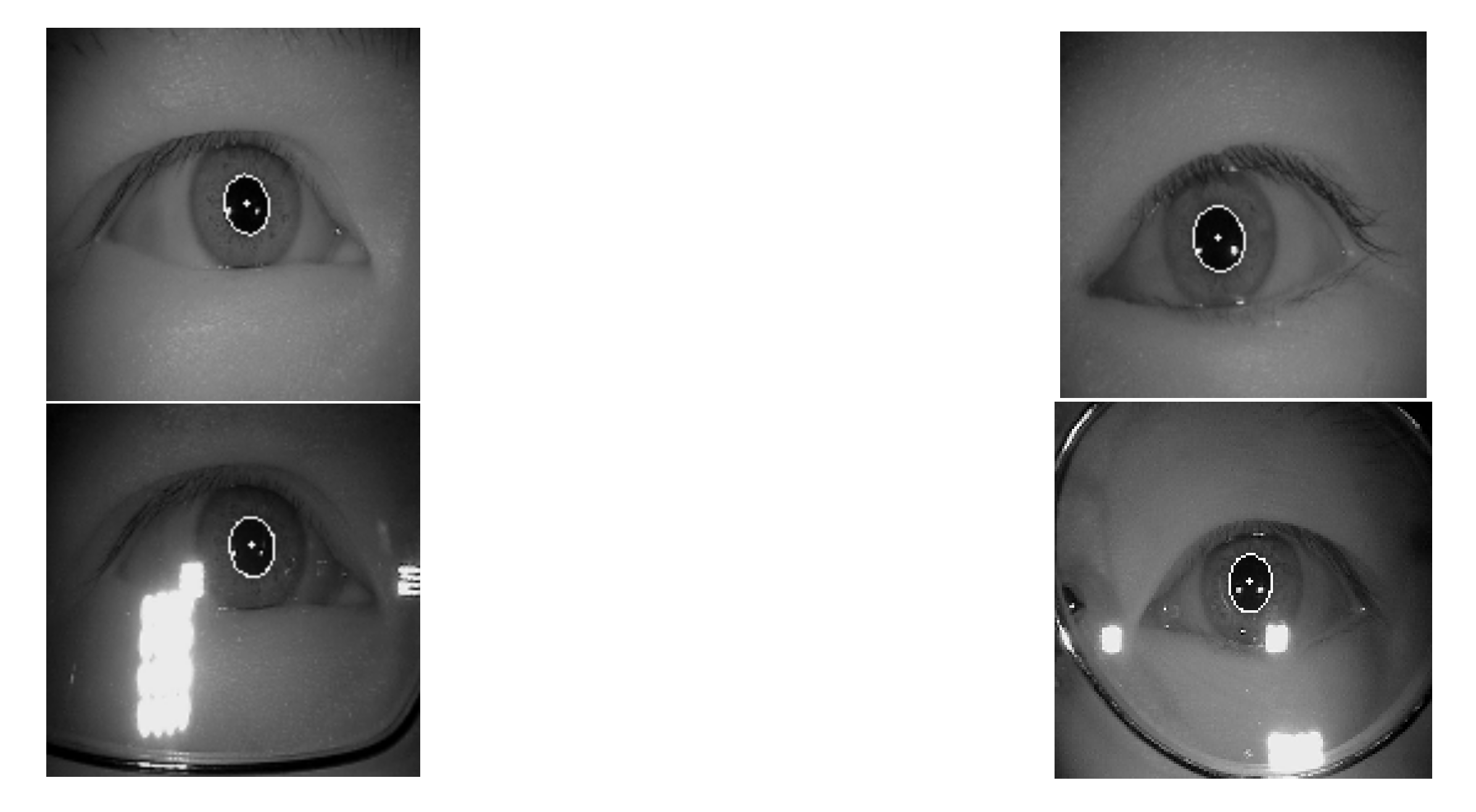
2.1.1. Labeled Pupils in the Wild Dataset
2.1.2. CASIA-IrisV4-Thousand Dataset
2.1.3. ŚWirski Dataset
2.1.4. Preprocess Details
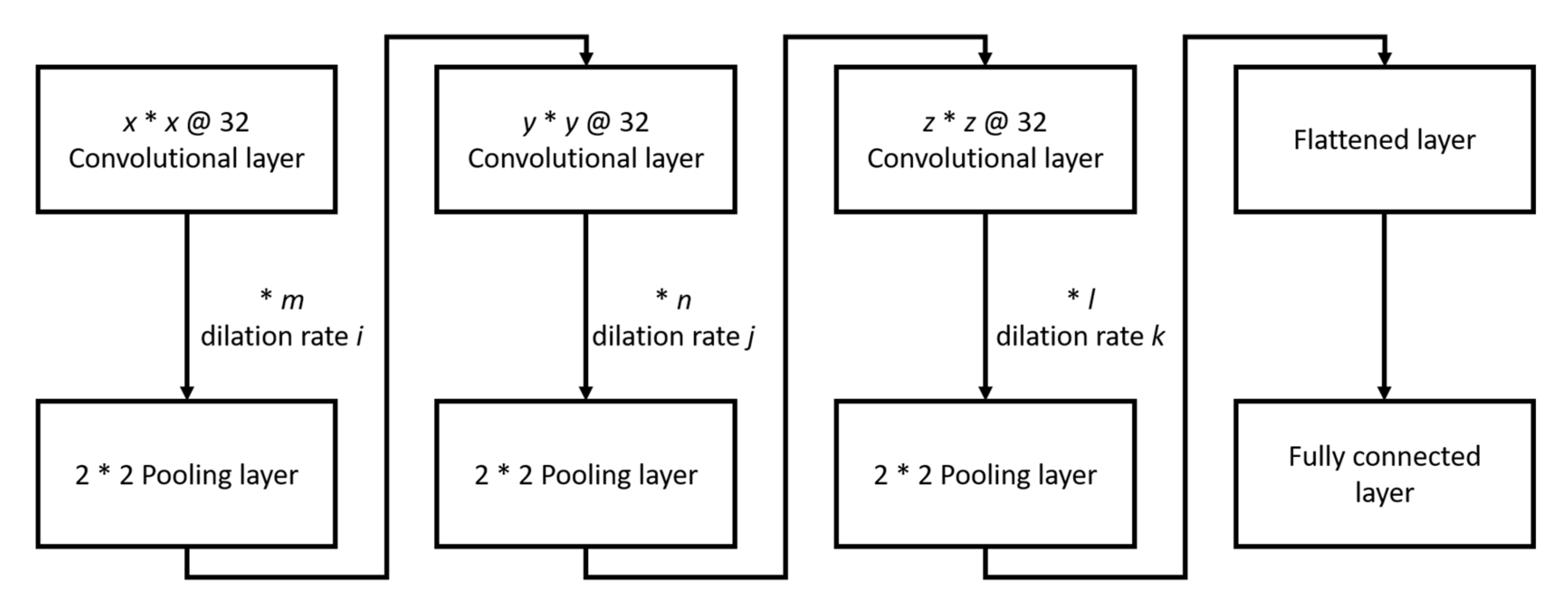
2.2. Method and Network Structure
3. Results
4. Discussion
4.1. Model Evaluation
4.2. Feature Map Visualization
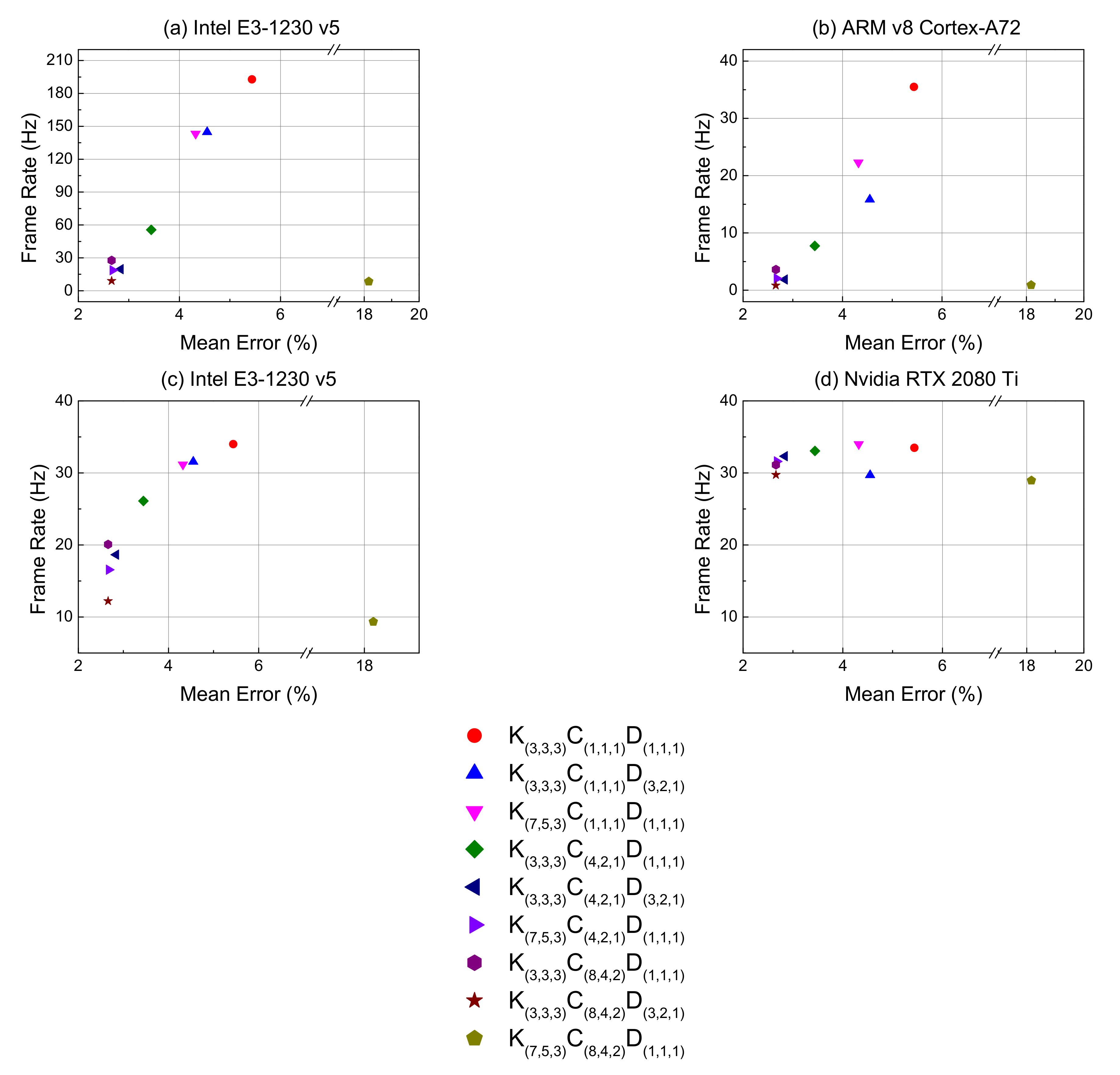
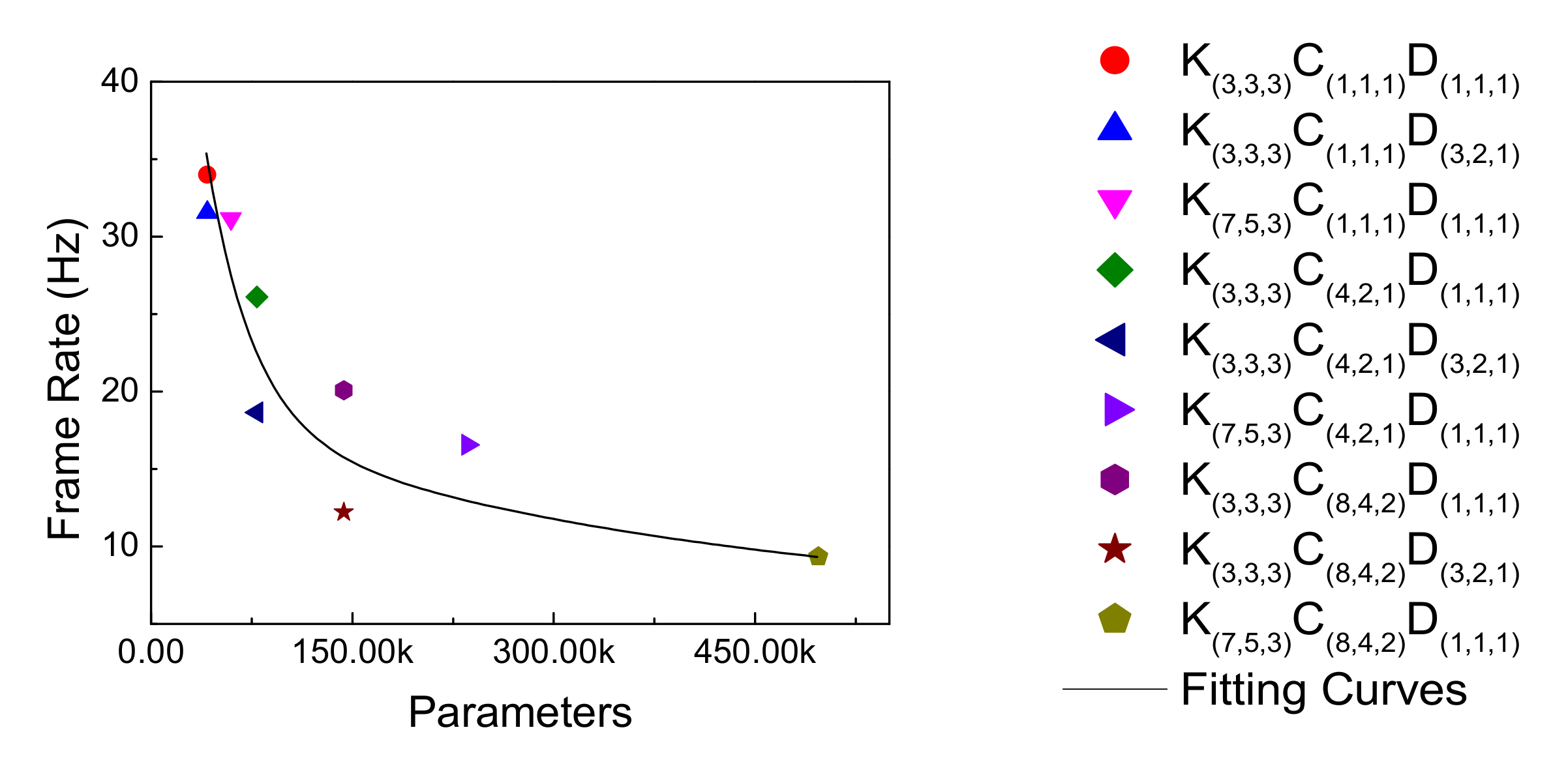
4.3. Model Speed Trend
4.4. Model Comparison
4.5. Model Revision
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xue, T.; Do, M.T.H.; Riccio, A.; Jiang, Z.; Hsieh, J.; Wang, H.C.; Merbs, S.L.; Welsbie, D.S.; Yoshioka, T.; Weissgerber, P.; et al. Melanopsin signalling in mammalian iris and retina. Nat. Cell Biol. 2011, 479, 67–73. [Google Scholar] [CrossRef]
- Kret, M.E.; Sjak-Shie, E.E. Preprocessing pupil size data: Guidelines and code. Behav. Res. Methods 2019, 51, 1336–1342. [Google Scholar] [CrossRef] [PubMed]
- Bitsios, P.; Prettyman, R.; Szabadi, E. Changes in Autonomic Function with Age: A Study of Pupillary Kinetics in Healthy Young and Old People. Age Ageing 1996, 25, 432–438. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Canver, M.C.; Canver, A.C.; Revere, K.E.; Amado, D.; Bennett, J.; Chung, D.C. Novel mathematical algorithm for pupillometric data analysis. Comput. Methods Programs Biomed. 2014, 113, 221–225. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Tan, J.; Zhang, K.; Lei, B. Computerized mouse pupil size measurement for pupillary light reflex analysis. Comput. Methods Programs Biomed. 2008, 90, 202–209. [Google Scholar] [CrossRef] [PubMed]
- Jain, M.; Devan, S.; Jaisankar, D.; Swaminathan, G.; Pardhan, S.; Raman, R. Pupillary Abnormalities with Varying Severity of Diabetic Retinopathy. Sci. Rep. 2018, 8, 5363. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rukmini, A.V.; Milea, D.; Baskaran, M.; How, A.C.; Perera, S.A.; Aung, T.; Gooley, J.J. Pupillary Responses to High-Irradiance Blue Light Correlate with Glaucoma Severity. Ophthalmology 2015, 122, 1777–1785. [Google Scholar] [CrossRef] [Green Version]
- Chang, D.S.; Boland, M.V.; Arora, K.S.; Supakontanasan, W.; Chen, B.B.; Friedman, D.S. Symmetry of the Pupillary Light Reflex and Its Relationship to Retinal Nerve Fiber Layer Thickness and Visual Field Defect. Investig. Opthalmol. Vis. Sci. 2013, 54, 5596–5601. [Google Scholar] [CrossRef] [Green Version]
- Reutrakul, S.; Crowley, S.J.; Park, J.C.; Chau, F.Y.; Priyadarshini, M.; Hanlon, E.C.; Danielson, K.K.; Gerber, B.S.; Baynard, T.; Yeh, J.J.; et al. Relationship between Intrinsically Photosensitive Ganglion Cell Function and Circadian Regulation in Diabetic Retinopathy. Sci. Rep. 2020, 10, 1560. [Google Scholar] [CrossRef]
- Larson, M.D.; Behrends, M. Behrends, and Analgesia, Portable infrared pupillometry: A review. Anesth. Analg. 2015, 120, 1242–1253. [Google Scholar] [CrossRef]
- O’Neill, W.; Trick, K. The narcoleptic cognitive pupillary response. IEEE Trans. Biomed. Eng. 2001, 48, 963–968. [Google Scholar] [CrossRef] [PubMed]
- Yoo, Y.J.; Yang, H.K.; Hwang, J.-M. Efficacy of digital pupillometry for diagnosis of Horner syndrome. PLoS ONE 2017, 12, e0178361. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adhikari, P.; Zele, A.J.; Feigl, B. The Post-Illumination Pupil Response (PIPR). Investig. Opthalmol. Vis. Sci. 2015, 56, 3838–3849. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitz, A.R.; Chacko, R.V.; Putnam, P.T.; Rudebeck, P.H.; Murray, E.A. Using pupil size and heart rate to infer affective states during behavioral neurophysiology and neuropsychology experiments. J. Neurosci. Methods 2017, 279, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.-A.; Baird, T.; Huang, J.; Coutinho, J.D.; Brien, D.C.; Munoz, D.P. Arousal Effects on Pupil Size, Heart Rate, and Skin Conductance in an Emotional Face Task. Front. Neurol. 2018, 9, 1029. [Google Scholar] [CrossRef] [PubMed]
- Garcia, R.G.; Avendano, G.O.; Agdeppa, D.B.F.; Castillo, K.J.; Go, N.R.S.; Mesina, M.A. Automated Pupillometer Using Edge Detection in OpenCV for Pupil Size and Reactivity Assessment. In Proceedings of the 2019 3rd International Conference on Imaging, Signal Processing and Communication (ICISPC), Singapore, 27–29 July 2019; pp. 143–149. [Google Scholar]
- Fuhl, W.; Rosenstiel, W.; Kasneci, E. 500,000 Images Closer to Eyelid and Pupil Segmentation. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer Science and Business Media LLC.: Berlin, Germany, 2019; pp. 336–347. [Google Scholar]
- Miron, C.; Pasarica, A.; Bozomitu, R.G.; Manta, V.; Timofte, R.; Ciucu, R. Efficient Pupil Detection with a Convolutional Neural Network. In Proceedings of the 2019 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 21–23 November 2019; pp. 1–4. [Google Scholar]
- Vera-Olmos, F.; Pardo, E.; Melero, H.; Malpica, N. DeepEye: Deep convolutional network for pupil detection in real environments. Integr. Comput. Eng. 2018, 26, 85–95. [Google Scholar] [CrossRef]
- Yiu, Y.-H.; Aboulatta, M.; Raiser, T.; Ophey, L.; Flanagin, V.L.; zu Eulenburg, P.; Ahmadi, S.-A. DeepVOG: Open-source pupil segmentation and gaze estimation in neuroscience using deep learning. J. Neurosci. Methods 2019, 324, 108307. [Google Scholar] [CrossRef] [PubMed]
- Fuhl, W.; Santini, T.; Kasneci, G.; Rosenstiel, W.; Kasneci, E. Pupilnet v2.0: Convolutional neural networks for cpu based real time robust pupil detection. arXiv 2017, arXiv:1711.00112. [Google Scholar]
- Vera-Olmos, F.J.; Malpica, N. Deconvolutional Neural Network for Pupil Detection in Real-World Environments. In Transactions on Petri Nets and Other Models of Concurrency XV; Springer Science and Business Media LLC.: Berlin, Germany, 2017; pp. 223–231. [Google Scholar]
- Fuhl, W.; Santini, T.C.; Kübler, T.; Kasneci, E. Else: Ellipse selection for robust pupil detection in real-world environments. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications; Association for Computing Machinery: New York, NY, USA, 2016; pp. 123–130. [Google Scholar]
- De Souza, J.K.S.; Pinto, M.A.D.S.; Vieira, P.G.; Baron, J.; Tierra-Criollo, C.J. An open-source, FireWire camera-based, Labview-controlled image acquisition system for automated, dynamic pupillometry and blink detection. Comput. Methods Programs Biomed. 2013, 112, 607–623. [Google Scholar] [CrossRef] [Green Version]
- De Santis, A.; Iacoviello, D. Optimal segmentation of pupillometric images for estimating pupil shape parameters. Comput. Methods Programs Biomed. 2006, 84, 174–187. [Google Scholar] [CrossRef] [PubMed]
- Tabashum, T.; Zaffer, A.; Yousefzai, R.; Colletta, K.; Jost, M.B.; Park, Y.; Chawla, J.; Gaynes, B.; Albert, M.V.; Xiao, T. Detection of Parkinson’s Disease Through Automated Pupil Tracking of the Post-illumination Pupillary Response. Front. Med. 2021, 8, 645293. [Google Scholar] [CrossRef] [PubMed]
- Navaneethan, S.; Nandhagopal, N. RE-PUPIL: Resource efficient pupil detection system using the technique of average black pixel density. Sādhanā 2021, 46, 114. [Google Scholar] [CrossRef]
- Kim, T.; Lee, E.C. Experimental Verification of Objective Visual Fatigue Measurement Based on Accurate Pupil Detection of Infrared Eye Image and Multi-Feature Analysis. Sensors 2020, 20, 4814. [Google Scholar] [CrossRef] [PubMed]
- Xiang, Y.; Zhao, L.; Liu, Z.; Wu, X.; Chen, J.; Long, E.; Lin, D.; Zhu, Y.; Chen, C.; Lin, Z.; et al. Implementation of artificial intelligence in medicine: Status analysis and development suggestions. Artif. Intell. Med. 2020, 102. [Google Scholar] [CrossRef]
- Tonsen, M.; Zhang, X.; Sugano, Y.; Bulling, A. Labelled pupils in the wild: A dataset for studying pupil detection in unconstrained environments. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications; Association for Computing Machinery: New York, NY, USA, 2016; pp. 139–142. [Google Scholar]
- Zhang, J.; Liang, X.; Wang, M.; Yang, L.; Zhuo, L. Coarse-to-fine object detection in unmanned aerial vehicle imagery using lightweight convolutional neural network and deep motion saliency. Neurocomputing 2020, 398, 555–565. [Google Scholar] [CrossRef]
- Portions of the Research in This Paper Use the CASIA-IrisV3 Collected by the Chinese Academy of Sciences’ Institute of Automation (CASIA) and a Reference to CASIA Iris Image Database. Available online: http://biometrics.idealtest.org/ (accessed on 25 November 2020).
- Świrski, L.; Bulling, A.; Dodgson, N. Robust real-time pupil tracking in highly off-axis images. In Proceedings of the Symposium on Applied Computing; Association for Computing Machinery: New York, NY, USA, 2012; p. 173. [Google Scholar]
- Wyatt, H.J. The form of the human pupil. Vis. Res. 1995, 35, 2021–2036. [Google Scholar] [CrossRef] [Green Version]
- FitzGibbon, A.; Pilu, M.; Fisher, R. Direct least square fitting of ellipses. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 476–480. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Rickmann, A.; Waizel, M.; Kazerounian, S.; Szurman, P.; Wilhelm, H.; Boden, K.T. Digital Pupillometry in Normal Subjects. Neuro Ophthalmol. 2016, 41, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interval of Sampling | Average Value |
|---|---|
| 10 | 0.8406 |
| 15 | 0.8090 |
| 20 | 0.7781 |
| Comparison Type | ||||
|---|---|---|---|---|
| Type I | Type II | Type III | ||
| Network depth | Shallow | K(3,3,3)C(1,1,1)D(1,1,1) | K(3,3,3)C(1,1,1)D(3,2,1) | K(7,5,3)C(1,1,1)D(1,1,1) |
| Middle | K(3,3,3)C(4,2,1)D(1,1,1) | K(3,3,3)C(4,2,1)D(3,2,1) | K(7,5,3)C(4,2,1)D(1,1,1) | |
| Deep | K(3,3,3)C(8,4,2)D(1,1,1) | K(3,3,3)C(8,4,2)D(3,2,1) | K(7,5,3)C(8,4,2)D(1,1,1) | |
| Comparison Type | ||||
|---|---|---|---|---|
| Type I | Type II | Type III | ||
| Network depth | Shallow | 5.437% | 4.549% | 4.321% |
| Middle | 3.442% | 2.838% | 2.677% | |
| Deep | 2.662% | 2.660% | 18.165% | |
| The Recommended Model | The Previous Research | |
|---|---|---|
| Mean Error | 5.437% | 6.587% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Whang, A.J.-W.; Chen, Y.-Y.; Tseng, W.-C.; Tsai, C.-H.; Chao, Y.-P.; Yen, C.-H.; Liu, C.-H.; Zhang, X. Pupil Size Prediction Techniques Based on Convolution Neural Network. Sensors 2021, 21, 4965. https://doi.org/10.3390/s21154965
Whang AJ-W, Chen Y-Y, Tseng W-C, Tsai C-H, Chao Y-P, Yen C-H, Liu C-H, Zhang X. Pupil Size Prediction Techniques Based on Convolution Neural Network. Sensors. 2021; 21(15):4965. https://doi.org/10.3390/s21154965
Chicago/Turabian StyleWhang, Allen Jong-Woei, Yi-Yung Chen, Wei-Chieh Tseng, Chih-Hsien Tsai, Yi-Ping Chao, Chieh-Hung Yen, Chun-Hsiu Liu, and Xin Zhang. 2021. "Pupil Size Prediction Techniques Based on Convolution Neural Network" Sensors 21, no. 15: 4965. https://doi.org/10.3390/s21154965
APA StyleWhang, A. J. -W., Chen, Y. -Y., Tseng, W. -C., Tsai, C. -H., Chao, Y. -P., Yen, C. -H., Liu, C. -H., & Zhang, X. (2021). Pupil Size Prediction Techniques Based on Convolution Neural Network. Sensors, 21(15), 4965. https://doi.org/10.3390/s21154965