1. Introduction
A prefix code, a
P-code, is a code where no codeword is a prefix of another codeword [
1].
P-codes have been used in symmetric cryptography for a long time [
2,
3].
The oldest known example of a
P-code is the Argenti code [
2] (16th century).
P-codes were also used by Peter the Great, where the plaintext was the Cyrillic alphabet [
2]. Furthermore, the Soviet cipher known as VIC [
3], used
P-codes as one of the rounds during the encryption. Finally, in the mid of the 20th century, the properties of
P-codes were studied by the leading scholars in the area, including Shannon, Fano, Huffman, etc. Nowadays, one area of cryptography which employs prefix codes is the DNA cryptography [
4], in which many cryptosystems utilize binary prefix codes as the plaintext space [
5,
6,
7,
8].
Example 1. To illustrate the usage of P-codes for encryption, let us consider Table 1, where each lowercase letter is mapped to a codeword of a binary prefix code; each codeword is of length four or five. It is readily seen that no codeword is a prefix of any other codeword. The plaintext, written as a sequence of lowercase letters, is encrypted by substituting each letter with the corresponding binary string and concatenating the strings into the resulting ciphertext. Let the message be . Substituting each letter by its corresponding binary codeword, the encrypted form is 11101111100111010010010110110001. The table is secret and known only to the sender and receiver, therefore only they are able to uniquely decipher the encrypted message, by using the property of prefix codes that no codeword is a prefix of any other codeword. The attacker, having observed the ciphertext, must solve two things to find the secret key, i.e., the used mapping: first of all, he/she must divide the message correctly into the variable-length segments and then he/she must find the correct substitution.
The plaintext alphabet may contain special symbols called null-ciphers, which are inserted into the plaintext during encryption and when decrypted are represented by the empty string. The usage of null-ciphers makes the frequency analysis of the ciphertext more difficult.
The memory complexity of the cipher depends on the size of the table, i.e., on the size of the plaintext alphabet and the corresponding codewords. For example, let the plaintext alphabet be the ASCII alphabet (128 symbols) and each variable-length codeword be approximately 10-bit long. Then the size of the table would be roughly 1280 bits, e.g., 160 bytes.
Due to the simplistic design of the cryptosystem and its low memory requirements, it is usable as a symmetric cipher for IoT applications. Securing the communication of IoT devices is currently extensively studied [
9,
10,
11], with one notable proposal of an encryption algorithm using prefix codes as its plaintext alphabet [
12]. The corresponding key-exchange of the symmetric key can be performed by algorithms dedicated for IoT, e.g., the Merkle-tree authenticated KEM [
13].
The paper is organized as follows. The proposal of a cryptosystem based on
P-codes is presented in
Section 2. In
Section 3, we collect fundamental properties of
P-codes.
Section 4 provides an algorithm for finding the set of all minimal dictionaries of
P-codes with respect to a given string
x. Statistical data obtained by running this algorithm for all strings of length up to 26 are presented in
Section 5. Finally, the preliminary cryptanalysis of the cryptosystem is described in
Section 6.
2. The Proposal of a Cryptosystem Based on -Codes
To be able to propose a cipher based on prefix codes, we first recall the definition of a prefix code.
Definition 1. Let be an alphabet and P be a set, . Then a code is a bijection ; elements of P are called codewords and P is also called a dictionary of the code. Specifically, a prefix code, for short a P-code, is a code where no codeword is a prefix of another codeword. A message x is a concatenation of finitely many words from the dictionary P.
In what follows, the dictionary P will consist of binary words, while the alphabet is the English A-Z alphabet, the ASCII alphabet, etc. For a set of binary words P, stands for the set of all finite concatenations of elements of P.
We now state the definition of the cryptosystem based on P-codes.
Definition 2. Let be a plaintext alphabet, let be a set of prefix codes P. Then a symmetric substitution cryptosystem based on P-codes is a five-tuple where:
The plaintext alphabet .
The ciphertext alphabet .
The keyspace consists of two-tuples , where and κ is a bijection .
For each , the encryption rule , .
For each , the decryption rule , .
The property follows directly from 4 and 5. If m is a string of plaintext symbols, , , then as usual, its encryption is the sequence . Decryption is done in the same manner. We note that this algorithm is a substitution cipher, in which it is difficult to distinguish respective encrypted plaintext symbols in the ciphertext.
The encryption can be performed as a simple look-up in the look-up table of the used P-code. Since each plaintext character is mapped independently of the other symbols, the encryption resembles the so-called ECB-mode of block ciphers. However, to further enhance the security of the cipher, special symbols called null-ciphers can be employed. These special symbols are also part of the plaintext alphabet and have their corresponding images under the mapping . They are randomly inserted into the plaintext and thus get encrypted as some binary strings. However, during the decryption, they are represented as empty strings and therefore do not change the meaning of the original plaintext.
The decryption is performed by identifying codewords in the ciphertext and mapping them to their preimages under the mapping . The recognition of codewords can be easily implemented with the usage of a finite state automaton, which would process the input ciphertext on a bit-by-bit basis and have separate accepting states for each codeword. On reaching one of these accepting states, the automaton would recognize the corresponding codeword, return to the initial state and process the ciphertext further.
Key Generation
The generation of a random key consists of two steps:
If we want to generate a random set of codewords
P for an alphabet, say with 128 characters, we have several possibilities. One is to generate a random string
x such that there is a huge number of dictionaries having cardinality
, where
x is the concatenation of all codewords of the dictionary, in some order. Then, one would try to find one of the dictionaries by using Algorithm 1 presented in
Section 2. The shortest possible length of such a string
x which would have a dictionary with 128 codewords is
. Unfortunately, such a string cannot be effectively processed by this algorithm, since the algorithm exhaustively searches all possible partitions of the string, which takes an exponential time in the length of
x.
Another approach is to generate a random binary string x of a sufficient length, e.g., in the case , and then try to generate a random partition of x and test, whether the resulting partition of x forms a P-code. If not, one may try to generate another random partition of x and test it again. However, this approach might also take a lot of time if the length of x is not sufficiently large. For example, if we want to find a P-code V such that , the least possible length of x is 896. In this case, the only suitable partition is the partition of x into 128 7-bit substrings. However, the number of all partitions of a 896-bit string into 128 substrings is . Another disadvantage of this method is the fact that some of the substrings might be the same, therefore the resulting P-code would be of a smaller cardinality than 128.
A more efficient way is to directly generate a set of random integers
and test if these numbers satisfy the well-known Kraft inequality ([
14,
15]):
If so, then there exists a
P-code with codewords of lengths
, and there are many ways how to construct it. For example, one may construct a binary tree with 128 leaves, where
i-th leaf is at
level under the root. Then, each leaf directly represents a codeword of length
of some
P-code with 128 codewords. This process can further be randomised during the binary tree’s construction, which leads to a randomized algorithm that generates different
P-codes even for the same sequence of lengths
. Straightforward implementation of this approach on a portable computer is able to generate a random
P-code with 128 codewords in approx. 20–30 ms.
| Algorithm 1: Algorithm FindVx() for finding all minimal P-codes that decode x |
![Sensors 21 06236 i001]() |
Once such a set of codewords P has been generated, the generation of the mapping can be done by generating a random bijection . Due to implementational simplicity, this mapping may be also fixed in a sense that the first symbol of alphabet will always be mapped to the first codeword of P, the second symbol of will be mapped to the second codeword of P, etc. Thus, the certification authority (CA) distributing the keys among the IoT devices needs to only distribute the set of codewords P and not the mapping itself.
The efficiency of the cipher can be measured, as is common, by a transmission rate. Suppose that the alphabet comprises all 8-bit characters, i.e., . Generally, the average codeword length is , where is the probability of occurrence of character , is the length of the corresponding codeword of . Then, is expected to be more than that given by some efficient (e.g., Huffman) coding. Thus, in this case, the efficiency can be measured as the fraction , i.e., the average number of bits of ciphertext per one encrypted character. Further, and the higher this fraction is, the more P-codes are available for this string. For security reasons, our coding does not adhere to the obvious rule used in efficient coding, where implies , since we do not want to give the attacker any additional information about the used P-code.
3. Set of Minimal Dictionaries with Respect to a Given String
If the dictionary P is known, the decision whether the string x was written using this dictionary is trivial. However, if the dictionary is not known, which represents the attacker’s situation, the attacker must consider all possible dictionaries, which could have been used to create x. The key ingredient in the study of all possible dictionaries is the notion of a minimal dictionary with respect to the known x.
Definition 3. Let x be a binary string. Then a set V such that is called minimal with respect to x, if for any , . The collection of all minimal sets V, , is denoted by .
Example 2. Given a string x of length , there are at least two minimal sets containing x, , say and with an exception when x consists of only zeroes or ones, then or , respectively.
Theorem 1. Let x be a string. Then a set is minimal with respect to x if and only if V is a partition of x into substrings.
As V is a set, then each substring occurs in V once; V is not a multiset, repetitions do not count. Since V is a partition of x, we have that .
Proof. (⇐). Let elements of V form a partition of x into substrings; say , where ’s are not necessarily different. Assume, by contradiction, that V is not minimal. Then there would be such that . This in turn implies that . If or , then would be a prefix of or vice versa. Therefore, which implies . The rest of the proof is done by induction on the length of x.
(⇒) If V is minimal with respect to x, then . Therefore, V has to contain elements whose concatenation is x; these elements form a partition of x into substrings. Because of minimality of V, there is no other element there. □
In order to show that it is computationally infeasible to break our cipher by brute-force, we will investigate the number of P-codes containing a piece of ciphertext x. In fact, it suffices to show that the number of minimal P-codes containing x, the subset of all P-codes, is large.
All minimal P-codes can be obtained by partitioning x into substrings (Theorem 1) and then checking, whether this partitioning satisfies the prefix property.
For a given string x of length , the number of different partitions into substrings is , as each delimiter is placed in between two consecutive symbols.
The following example illustrates this procedure.
Example 3. If , then there exist 8 partitions. For each partition, we will verify whether the obtained set satisfies the prefix property. We will have following dictionaries:
if there is no delimiter, then the corresponding P-code is
one delimiter:
partition leads to , which does not satisfy the prefix property,
partition results in a P-code ,
implies a P-code .
two delimiters:
, leads to a P-code ,
does not satisfy the prefix property,
we get a P-code
3 delimiters: leads a P-code .
Thus, for , the procedure leads to 6 minimal P-codes, i.e., . Later, we will see that for x long enough, .
The structure of dictionaries from , is presented in the following theorem.
Theorem 2. Let x be a binary string of length ν and C, D be two dictionaries in . Then:
- (1)
There are no dictionaries , where C is a proper subset of D.
- (3)
There are no dictionaries such that is a dictionary.
- (3)
There are no dictionaries such that is a dictionary.
Proof. (1). Let
x be a binary string
. Suppose that
C and
D are two dictionaries such that
and
, say
. Without loss of generality, let
. According to Theorem 1,
D comprises substrings of
x, therefore there is an element
such that
Similarly, there is
such that
By assumption, , which in turn implies that the codeword is a prefix of , a contradiction. Analogously, , which means that is a prefix of .
Therefore, . If we remove the prefix from the string x, the above procedure can be repeated on the shorter string . Now, the induction on finishes the proof.
Item (2) follows directly from (1). If there were two different dictionaries C and D of P-codes such that is a dictionary as well, then it would be true that there are two different dictionaries, and C, for which , contradicting (1).
Item (3) follows from (1) as well. If were a P-code, then , contradicting (1). □
Now we turn our attention to the cardinality of
. The following theorem and corollary deal with the lower bound. The upper bound will be estimated statistically in
Section 5.
We recall that the function
counting the number of divisors of
n, including 1 and
n, can be easily computed from the prime factorization of
n: If
, then
[
16].
In the following, we use the common notation and . We also use the notation to represent the binary complement of x.
Theorem 3. Let and be the function which counts number of divisors of ν. Then . Similarly, for , .
Proof. It is readily seen that a dictionary contains only one element. Otherwise, for any two elements in V one would be a prefix of the other, a contradiction. Hence and because , and vice versa. The proof follows. The case of is analogous. □
Proposition 1. Let x be a string and be its binary complement. is a dictionary of the string x, if and only if, is a dictionary of the string , i.e., .
Proof. Let , . Then , and vice versa. The proof follows. □
Corollary 1. For each string x of length ν, . The equality is attained only for , , and also for all strings with . For all other strings .
Proof. The first part of the statement follows from Theorem 3 and from for all strings of length 2. To finish the proof we show that for all other strings . We recall that now .
- 1.
Let d be a divisor of . If we partition , where , then the set is a dictionary of the string x, since the words are of the same length and therefore cannot be prefixes of each other. In this way, we can find different dictionaries of the string x. Therefore . We note that the above argument works also in the case is a prime.
- 2a.
Let , , where the leftmost digit of w is 0, with the exception of the string . Then is also a dictionary of the string x. Moreover, , therefore we have found a dictionary with codewords of different lengths, i.e., a dictionary not included in the previous case. In the case we can consider a dictionary and have once again found a dictionary with codewords of different lengths, as . Therefore .
- 2b.
Let , where the leftmost digit of w is 1. Due to Proposition 1 and we can consider the complement of x and continue as in the previous case.
This proves our corollary. □
4. Algorithm for Finding the Set
In this section, we describe an algorithm for finding the set . This algorithm was employed for all strings of lengths up to 26.
For a given binary string x of length , the algorithm finds all such minimal P-codes V that . Since each P-code can be viewed as a binary tree T whose leaves represent the codewords of the P-code, the algorithm recursively searches all divisions of the string x into partitions and checks whether these substrings may form the leaves of some binary tree T. If so, then the algorithm outputs the tree T that also represents such P-code V, where .
The input of the recursive algorithm is a binary string x, whose prefixes are potential codewords and a binary tree T with already-found codewords. In the beginning, the algorithm is used with the original string x and a binary tree T with only one node—its root.
Steps 5–20 take a prefix P of x of lengths 1 up to and check whether it may be a codeword of some P-code by keeping up a binary tree T of already identified codewords. The following situations might arise for a prefix P of the string x and a binary tree T (its working copy):
Steps 12–14 If one of the leaves of is a prefix of P, then it is also a prefix of x. Therefore the current call of the algorithm terminates, since it is not possible to create another codeword from the current string x.
Steps 15–17 If the string P is a prefix of some leaf of , i.e., a prefix of some codeword, then this prefix is ignored and a prefix of length +1 is considered (i.e., the jump to the step 21).
Steps 18–20 The string P might be a codeword of some P-code. Therefore, it is inserted to the tree as a new leaf and the algorithm is recursively called with the rest of x after removal of P (i.e., the string in the step 19) and with the tree .
For example, if we apply Algorithm 1 to a string , we find the following P-codes:
The trees represent the following
P-codes, respectively:
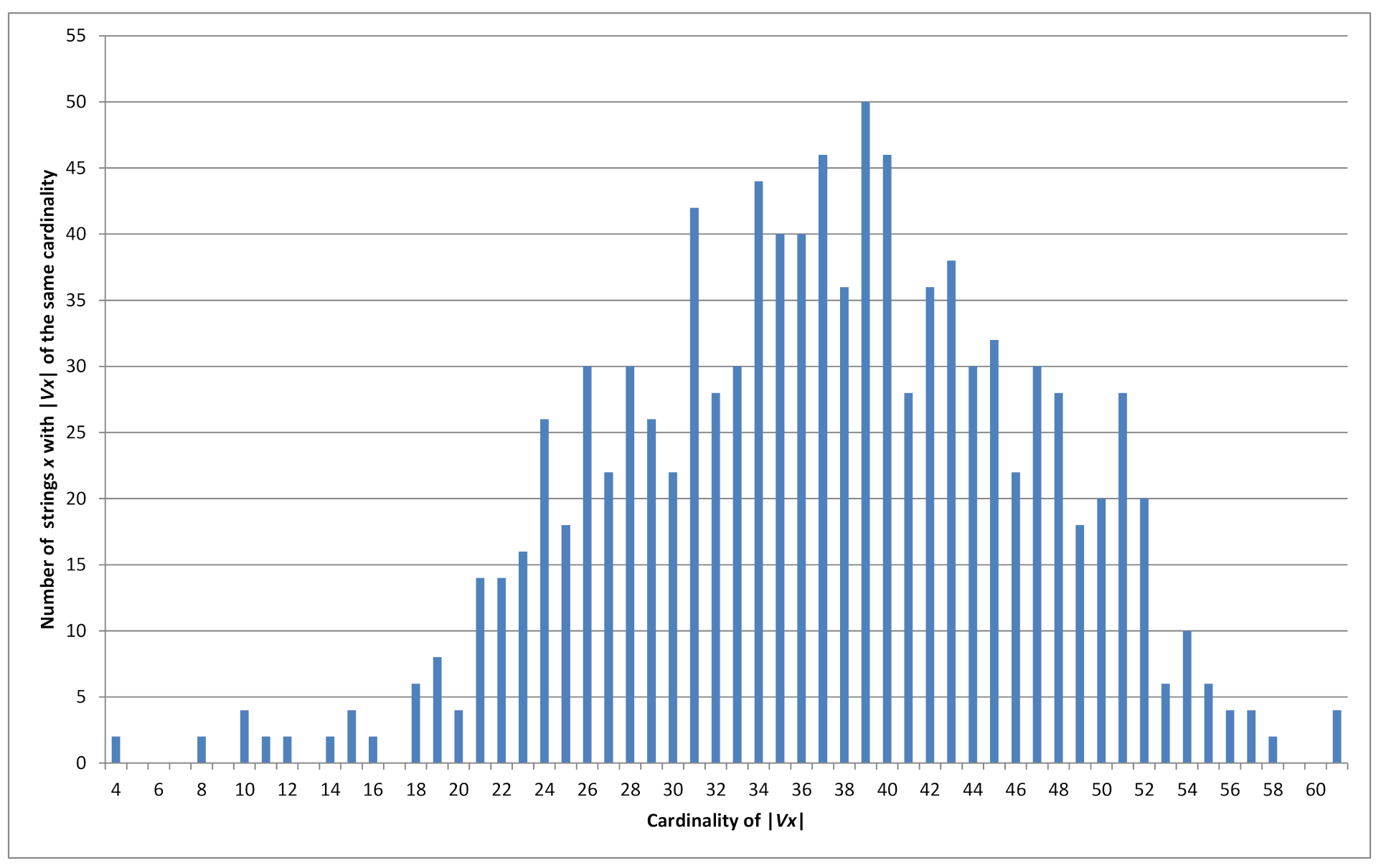
5. Statistical Approach for Cardinality of the Set
Consider all
binary strings of length
. For each string, we find the set
and its cardinality. Cardinality distribution histogram of
is in
Figure 1. For example, 50 strings of length
have the property that 39
P-codes can be constructed from them, i.e., for 50 strings
it is true that
. Maximum cardinality
is reached by four strings
x (last value of the histogram).
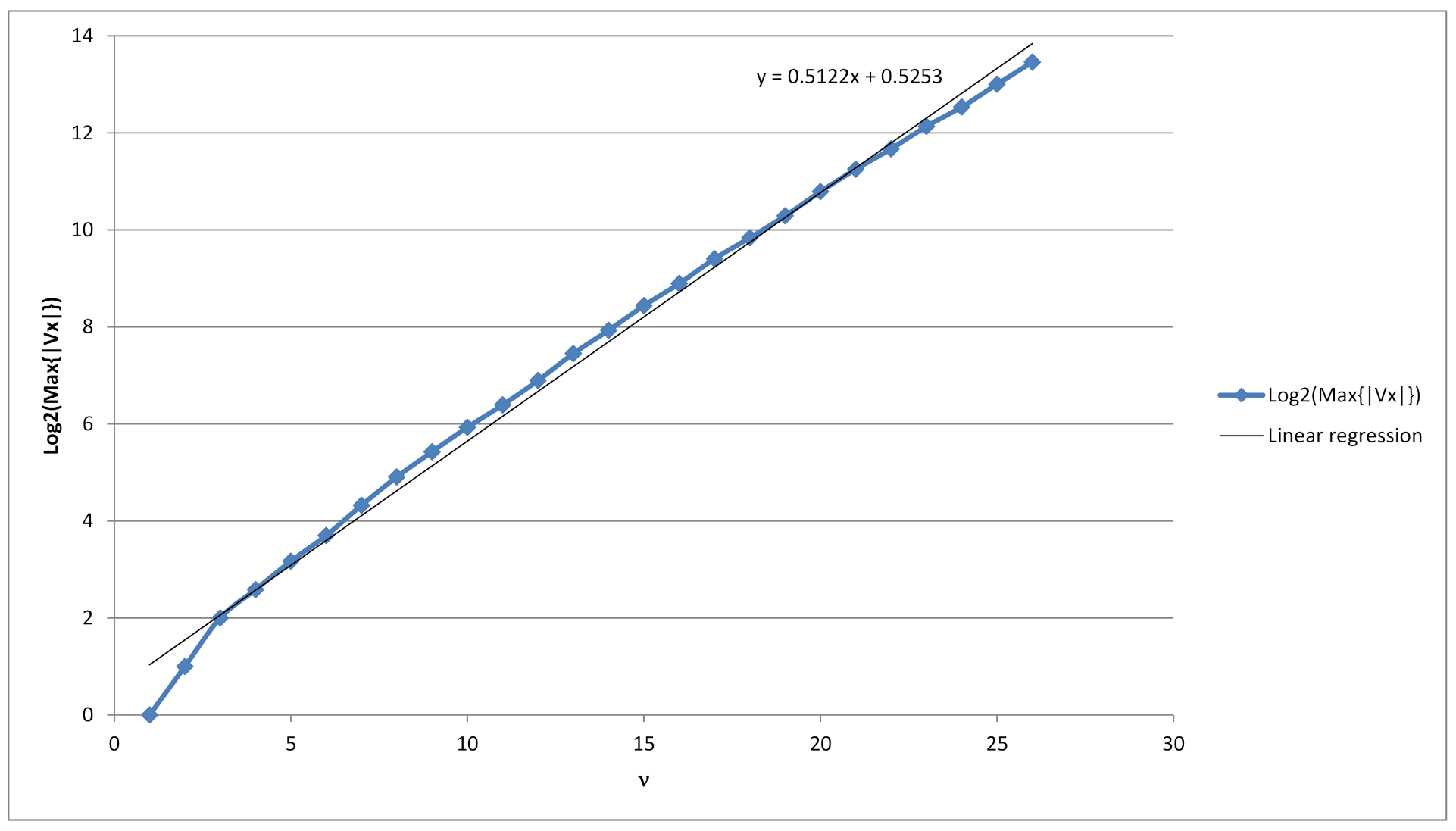
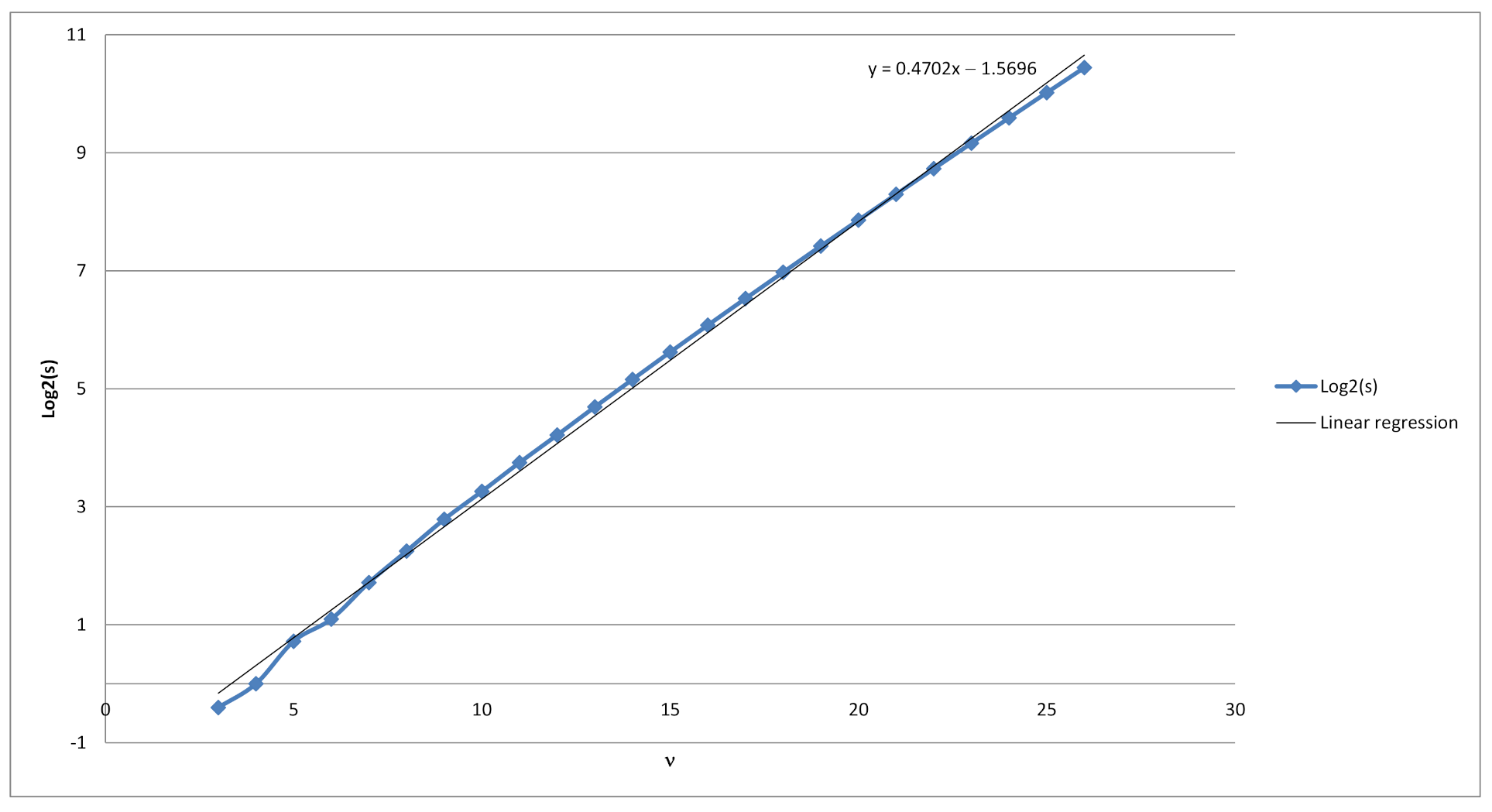
We have estimated the upper bound for
experimentally by using the log-linear regression to be
. As mentioned above, this number is less than
. To do this, we collected the data which are included in
Table 2. Description of its columns are in the next subsection.
Results of Our Exhaustive Search
We implemented Algorithm 1 in programming language C++ and used it to calculate the cardinalities of sets
for all possible binary strings
x of lengths
. For each value of
, we generated all
strings
x of length
and determined all possible
P-codes, i.e., the set
, and
for each possible string
x. Our algorithm checked
instances for each
. As a consequence we were able to generate histograms for distribution of cardinalities of
. One such example is presented in
Figure 1.
We used computational resources available at the HPC center at the Slovak University of Technology in Bratislava, where the computation used 72 computational nodes and took 1 day 20 h and 53 min, i.e., it performed at a rate approx. 416 x strings of length 26 per second.
At this rate, the calculation would take approx. 3 days for , one week for , two weeks for and approx. one year and three months for . However, in reality the periods would be even longer, since the rate would slow down, because of longer strings x.
We present the results in
Table 2, with the following columns:
—The length of the binary string x,
k—Upper bound on
—Estimated mean for
s—Estimated standard deviation s for
5—Estimated maximum of the function , where is the Gaussian density function , i.e., . In other words, the theoretical number of strings with their value of equal to the estimated mean value .
6—The measured number of strings with their value of equal to the most probable value of .
—The smallest number of P-codes for a string , i.e., the smallest . Due to Corollary 1 it is equal .
—The largest number of P-codes for a string , i.e., the largest .
h—The estimated upper bound using log-linear regression from the collected data.
Comparing columns 5 and 6 one can see how sharp is our estimation for the most probable value. From this it follows that this estimation is acceptable. Comparing the last two columns it follows that the discrepancy between our estimation for
and the true value is also acceptable. These columns also display the range of occurrences for
. (see also
Figure 2).
Let
x be a binary string of the length
and
be the set of all
P-codes that can be obtained from the string
x by Algorithm 1. Moreover, let
. Then for each
and
, we define the characteristic function
Let
be a random variable
defined on the sample space
For instance, if
we have
(see graph in
Figure 1). Moreover, because of the complement property mentioned above we have
, and
is an even number for
.
Next, we need a variant of the Central limit theorem [
17].
Lemma 1. Let a density functions of independent random variables be bounded by a constant h and their characteristic function is non negative. Then densities of random variables converge to the density of Gaussian random variable.
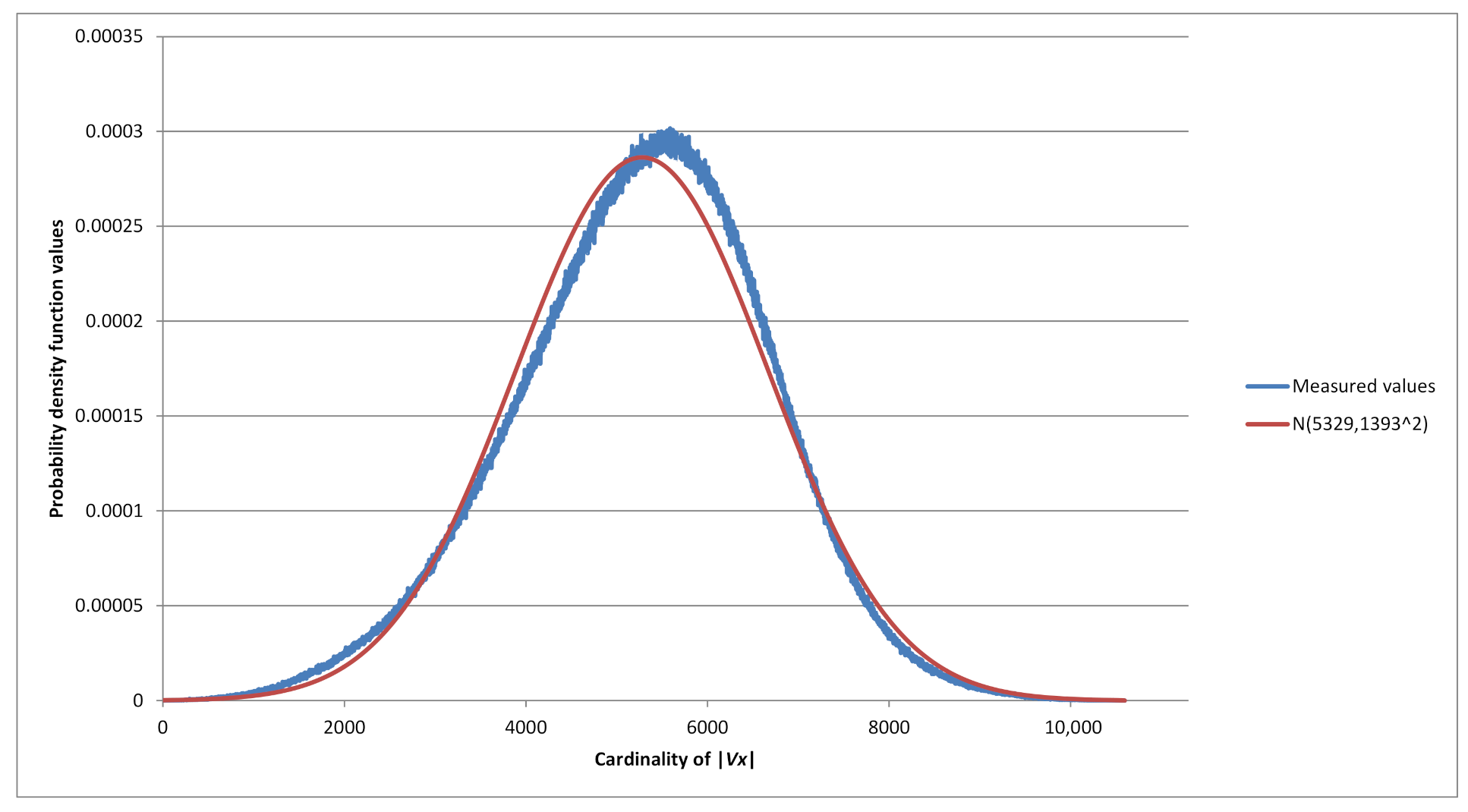
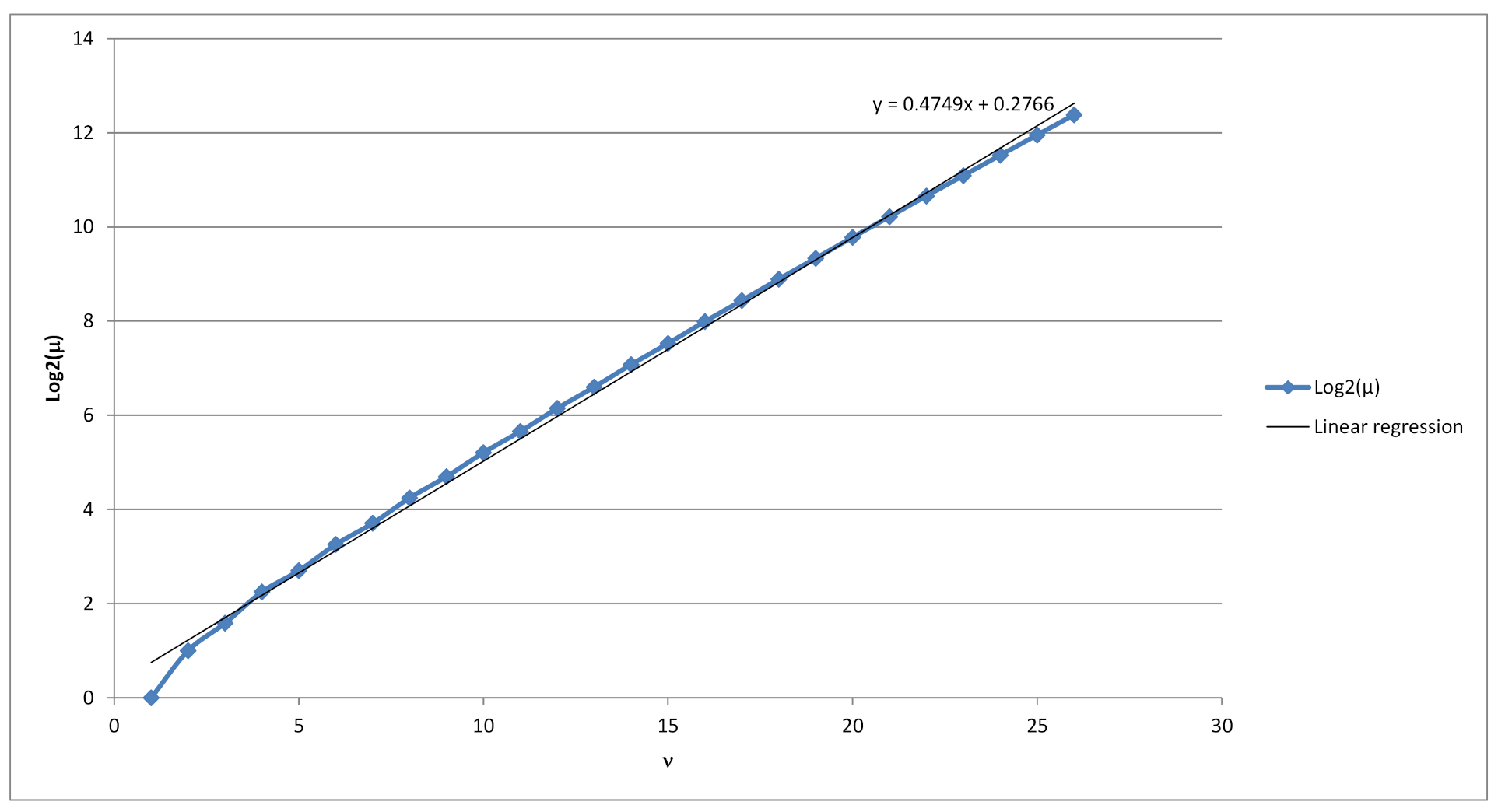
Hence our random variable
possesses Gaussian probability distribution with a density function
. Using exhaustive search for values
subsequent linear regression revealed that the random variable
has a slightly biased normal distribution (see
Figure 3) with the mean value of
(see
Figure 4) and a standard deviation of
(see
Figure 5). From there we get an estimate on the number of strings
x of length
for which
is equal to the most probable value, i.e., the mean of random variable
:
6. Preliminary Cryptanalysis of the Proposed Cipher Based on -Codes
The security of the proposed cryptosystem is based on the fact that there exist a rather large (potentially infinite if the length of codewords is not upper-bounded) number of dictionaries for plaintext alphabets. As mentioned earlier, the cryptanalysis can be further made more complicated by employing null-ciphers into encryption, i.e., the code P may contain several codewords that will be decoded as an empty string. We recommend to insert a random number of these null-ciphers into the beginning and end of the ciphertext and also to randomly insert them into ciphertext during the encryption as well. In our opinion, this security measure substitutes the usage of encryption modes, since the encryption without null-ciphers behaves similarly to ECB-mode, where two equal sequences of plaintext characters would be encrypted as two equal binary sequences. With the addition of randomly inserted null-ciphers, this is no longer true.
We also suppose that each message has its own encryption key, i.e., the used P-code.
Let us consider the ciphertext-only attack, i.e., the attacker has observed a ciphertext x. The brute-force attack on the cryptosystem would consist of the exhaustive search for the used key . To investigate the security of the system under this attack, in this paper we study the properties of P-codes to show that the keyspace is too large to mount such an attack.
The size of keyspace depends on both the size of alphabet and on the size of which is determined by fundamental properties of P-codes.
As can be seen on
Figure 4, the average number of minimal dictionaries with respect to a given string grows exponentially with regards to the length of the binary string. Therefore, one approach to have a complexity of
of finding the correct minimal dictionary, is to let the length of the ciphertext to be at least
, i.e.,
. In this case, if the ciphertext has at least 269 bits, then there exist on average at least
possible dictionaries, which could have been used to generate such a ciphertext. Thus, even if the attacker tries to find the correct dictionary by searching through all possible minimal dictionaries with respect to the ciphertext, he/she has to search through
dictionaries.
7. Conclusions
In this paper, a symmetric cipher based on prefix codes has been proposed. Our main goal was to investigate the security of the cipher regarding the amount of information about the key, i.e., the used random
P-code, that is available to the attacker by observing a ciphertext, i.e., a string of concatenated codewords of the
P-code. The encryption algorithm and methods how to generate such random
P-code are presented in
Section 2. In
Section 3 we defined a notion of a minimal dictionary of a
P-code with respect to a given string and we identified the minimal bound on the number of all dictionaries with respect to a given string. An exponential algorithm which finds all minimal dictionaries with respect to a given string is proposed in
Section 4. Statistical approach for finding the upper bound on the number of all minimal dictionaries with respect to a given string is presented in
Section 5. Our analysis shows that the number of possible
P-codes derived from a string increases exponentially with the length of the corresponding string, therefore the keyspace of the cipher increases exponentially as well, making the brute-force attack difficult. In
Section 6, we present a preliminary cryptanalysis of the proposed cipher. In order to retain the simplicity of the cipher and to prevent some basic attacks, e.g., the statistical analysis of the ciphertext, we suggest to use the null-ciphers during the encryption.
Some technicalities about possible coders and decoders for
P-codes can be further found in [
18]. Information on effective decoding algorithms can be found in [
19,
20] and on memory-efficient representation of prefix codes can be found in [
21].
Future plans include finding the sharp lower bound of the cardinality of a dictionary with respect to a given string x.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}