1. Introduction
The sorting scenes in current daily life, such as family services, garbage sorting and logistics distribution, are often unstructured scenes [
1]. In the face of these environments, the robot system not only needs to identify and locate the target object but also needs to understand the whole environment. Many existing methods generally only identify and locate objects in the scene by target detection or template matching, which cannot play a stable sorting effect in the face of a variety of unknown object sorting scenarios with stacking. Because of the lack of understanding of the spatial relationship of objects in the scene, the target object is damaged in the process of grasping. Therefore, it is of great significance to study how to use robots for safe, stable and accurate sorting of complex multi-object scenes.
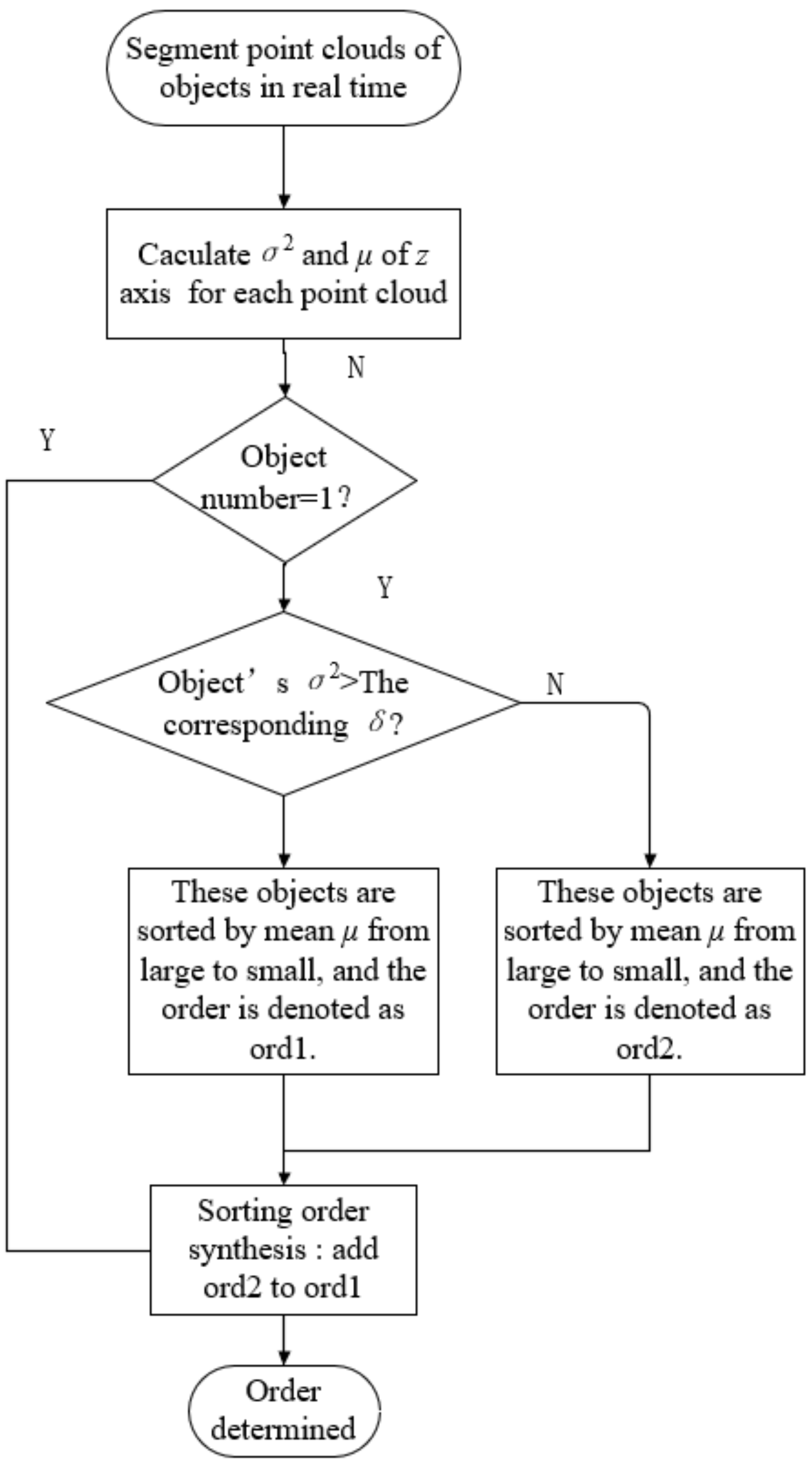
To solve the above problems, this paper proposes a multi-objective sorting system based on fusion neural network. In this system, we mainly proposed: (1) The attitude information of the object is obtained by two different networks so as to make full use of the advantages of the two networks. (2) Normal vector estimation based on point cloud processing and grasping sequence reasoning based on average depth calculation are proposed. The rotating target detection network is responsible for the position of the target object and the rotation angle on the horizontal plane. The instance segmentation network is responsible for obtaining the point cloud of the object surface. The point cloud data are used to calculate the normal vector of the upper surface and the average depth of each upper surface to calculate the grasping order. The normal vector is estimated by principal component analysis. In sorting order reasoning, we propose a new method. Firstly, each kind of object is placed on the experimental platform, and the variance of its average depth is recorded as a priori knowledge. Then, the mean value of the obtained point cloud data is sorted in the sorting process, and the grasping sequence is obtained by synthesizing the variance information of the prior knowledge. The system enables the robot to sort multiple unknown objects in the scene independently, stably and safely.
2. Rated Work
The sorting system is originally based on shallow learning. For example, K. Rahardja [
2] and Ata AA [
3] implement object recognition and pose estimation through edge detection technology, simple features of complex objects, color attributes and structural light principles, respectively. In addition, in the field of machine learning and robot system integration, D. Kragic and H. I. Christensen [
4] use view-based support vector machine to realize the recognition and detection of daily household goods. In 2006, Ashutosh Saxena et al. [
5] first used machine learning to predict the grasping position of daily necessities and realized the effective grasping of unknown objects. Wang [
6] realized the classification prediction and location determination of sorting objects through SVM and circle projection features. The saliency detection algorithm is used to remove the background of the image, and the upper and lower relations of the stacked objects are judged by combining the depth information.
In recent years, compared with shallow learning, deep learning has great advantages in extracting and learning image features. Levine [
7] et al. predicted a given action instruction by grasping the prediction network to calculate the possibility of grasping and then combined the servo mechanism with the neural network to continuously select the best path to achieve successful grasping. D. Hossain [
8] et al. constructed a system that can identify and select targets in different positions, directions and illuminations by combining DBNN network with evolutionary algorithm. In addition, Ulrich Viereck et al. [
9] built a stacked object sorting system based on convolutional neural network with learning distance function. Zhang Xinyi [
10] realized the automatic sorting system of stacked multi-objects by combining semantic segmentation, three-dimensional reconstruction and support relationship reasoning. Li [
11] realized the recognition of the position and category of multi-objects with uncertain positions in the environment and drove the robot to grab and sort. On this basis, Wang Bin [
12] added the method of visual and force fusion to complete the compliant control of the robot in the sorting process. However, the above methods are only applicable to the separated multi-object sorting scene. When objects in the scene are randomly stacked, these methods may cause object damage or grab failure during sorting.
At present, the rotating frame detection method is mainly divided into single-stage, two-stage and three-stage network. The single-stage network runs faster, but the accuracy is low. The multi-stage network has good performance, but the speed is slow, and the construction is difficult. The representative of single-stage network is R3Det [
13], while the main representative of dual-stage network is R2CNN [
14]. In the three-stage network, Jian Ding [
15] proposed a three-stage rotating target detection architecture based on ROI Transformer module. ROI Transformer module is a common module, which can be added to other frameworks to improve the detection accuracy. Since the rotation angle of rotating rectangular border is not easy to learn, Yongchao Xu et al. [
16] proposed a Gliding vertex network architecture that can predict quadrilateral borders. The network uses the offset of four corners relative to the horizontal rectangular border to describe the quadrilateral bounding box of the object. RSDet [
17] also uses four corners to represent the rotating frame of the object. For the boundary problem, RSDet solves it by moving the ordered corners forward or backward and then calculating the minimum loss.
As for the case segmentation network, it is mainly divided into three categories: (1) the top-down detection-based model, (2) a bottom-up model based on semantic segmentation, and (3) the direct instance segmentation model. However, for objects with complex or large contours, most networks have rough segmentation of their boundaries.
Yi Li [
18] constructed a highly integrated and efficient end-to-end network FCIS by expanding the FCN [
19] method, which can jointly solve the problem of target classification and instance segmentation. Xiaoke Shen [
20] proposed A 3D convolutional-based system, which generates frustums from 2D detection results, proposes 3D candidate voxelized images for each frustum and uses a 3D convolutional neural network (CNN) based on these candidates voxelized images to perform the 3D instance segmentation and object detection. He Kaiming [
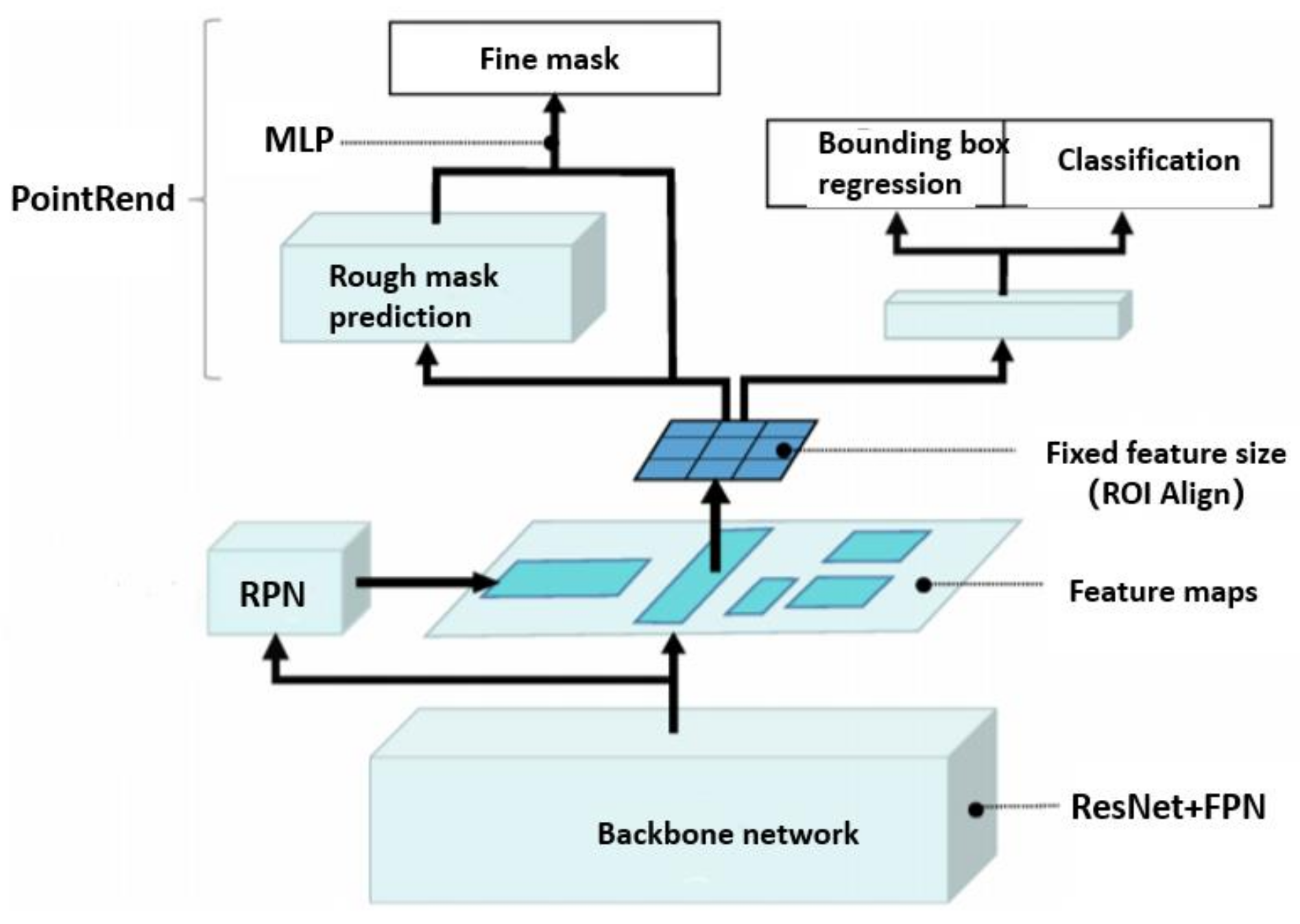
21] et al. proposed the classic instance segmentation network Mask R-CNN in 2017. The algorithm realizes the segmentation of objects in the scene by adding mask head network to the target detection network Faster R-CNN. This method also innovatively changes the original ROI pooling to ROI Align, which ensures the feature alignment from the original image to ROI, thereby improving the performance of the entire network. Daniel Bolya et al. [
22] proposed the real-time instance segmentation network model YOLACT for the first time. YOLACT innovatively changed the original NMS strategy to Fast NMS, thus maintaining the accuracy of the model and improving the speed of non-maximum suppression operation. Sida Peng [
23] improved snake method and proposed a bottom-up DeepSnake network architecture. DeepSnake also has good segmentation speed and accuracy. Wang Xinlong et al. [
24] proposed a network architecture SOLO, which is different from the previous design ideas. The network innovation transforms the instance segmentation problem into the instance type problem of the prediction pixel, and the overall network architecture is very simple. The SOLO network has both high speed and segmentation accuracy. However, since SOLO distinguishes different instances through the location information of objects, the network has poor effect when the objects are stacked.
In terms of the representation method of grasping pose, in recent years,
are mostly used to represent the grasping pose of the object [
25,
26,
27]. For a multi-object sorting scene, when the object is stacked and the stacked object has a certain height, the use of five parameters to guide the robot grasping can easily lead to grasping failure or even damage to the target object. Therefore, this paper uses
to represent the grasping pose. The rotating rectangular frame is defined by the long edge method, where (
represents the center point coordinates, the long edge of the rectangular boundary frame is defined as
, and the other edge is defined as
.
is the angle of the long side
and
axis positive direction, and the increase of
is used to represent the angle between the normal vector of the object surface and the angle perpendicular to the horizontal direction.
and
are obtained by rotating target detection network, and parameter
is obtained by instance segmentation network.
4. Rotating Target Detection Network
4.1. Basic Framework
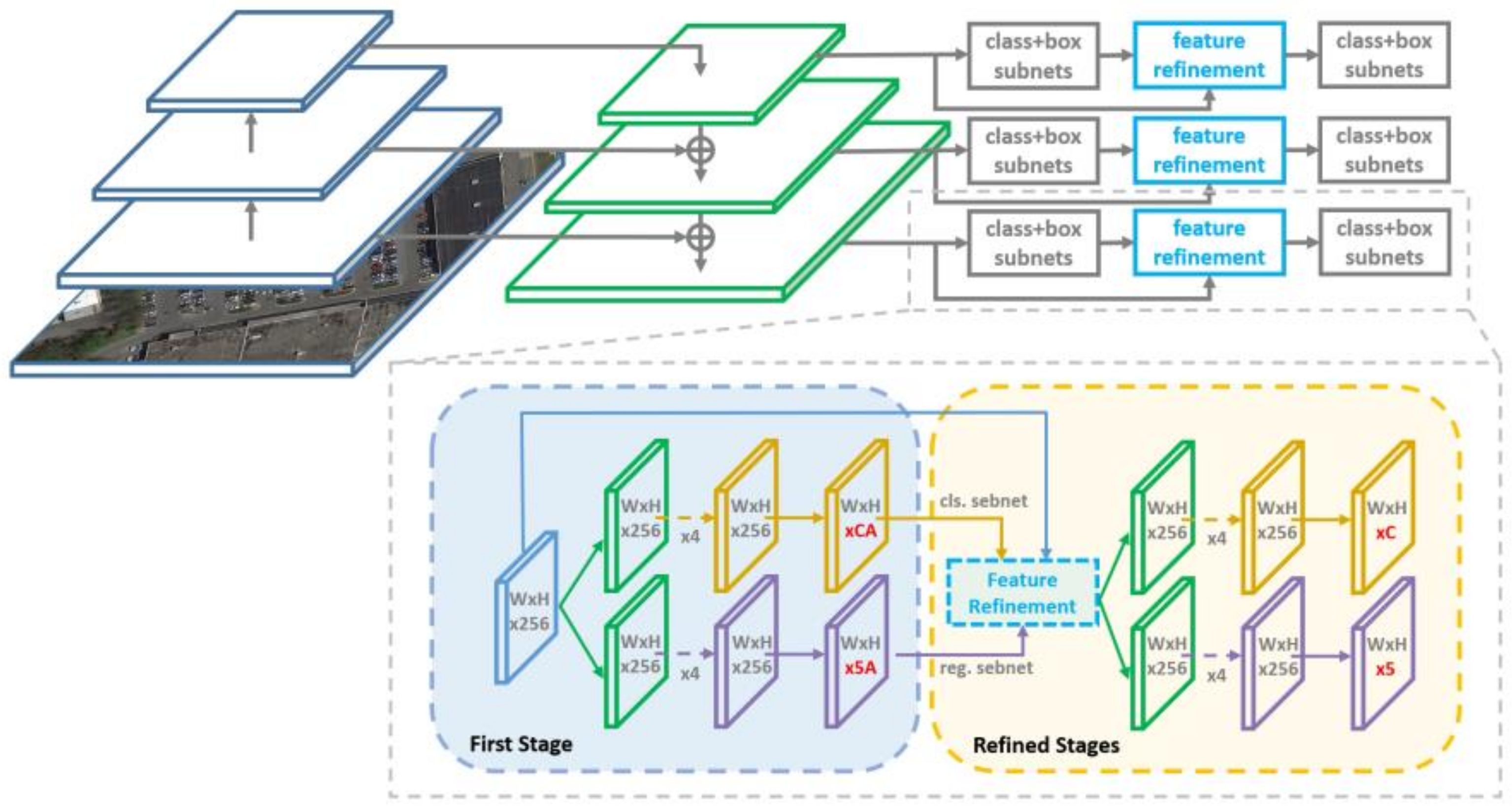
The overall frame of R3Det [
31] network is shown in
Figure 3. R3Det network is divided into three parts:
(1) Basic network RetinaNet: RetinaNet uses ResNet(Residual Network) + FPN (Feature Pyramid Networks) as the backbone network and uses single-stage target detection and Focal Loss. RetinaNet is used to realize the preliminary detection of rotating targets in the first stage.
(2) Feature alignment module: By reconstructing the whole feature map on the feature points, the problem of unalignment of cascade structure features is solved to obtain more accurate boundary position information.
(3) Refining module: cascade optimization is adopted to improve the accuracy of classification and the positioning accuracy of regression boundary by cascading refining modules (multiple can be added) after the first stage.
4.2. Dataset Construction
In this paper, the rotating target detection is applied to the robot grasping task, and the targets in the existing public data set (COCO/DOTA) do not meet the grasping requirements of the robot system. Therefore, the data set needs to be constructed according to the types of robots and manipulator claws.
The constructed dataset needs to meet the following conditions;
(1) In order to ensure that the trained neural network has good effect and good generalization, the type and number of target objects selected to construct the data set should be as many as possible and able to be captured by the existing robot paws.
(2) Image resolution should be consistent with the resolution of the image taken in practical application. In this paper, KinectV2 camera is used to obtain the image of the scene in the sorting process, so when collecting the data set, KinectV2 is also used to collect images with resolution of 1920 × 1080.
(3) In order to achieve the training of the rotating target detection model, not only should the category and position of the object be marked, but the rotation angle of the target should also be marked when labeling the image.
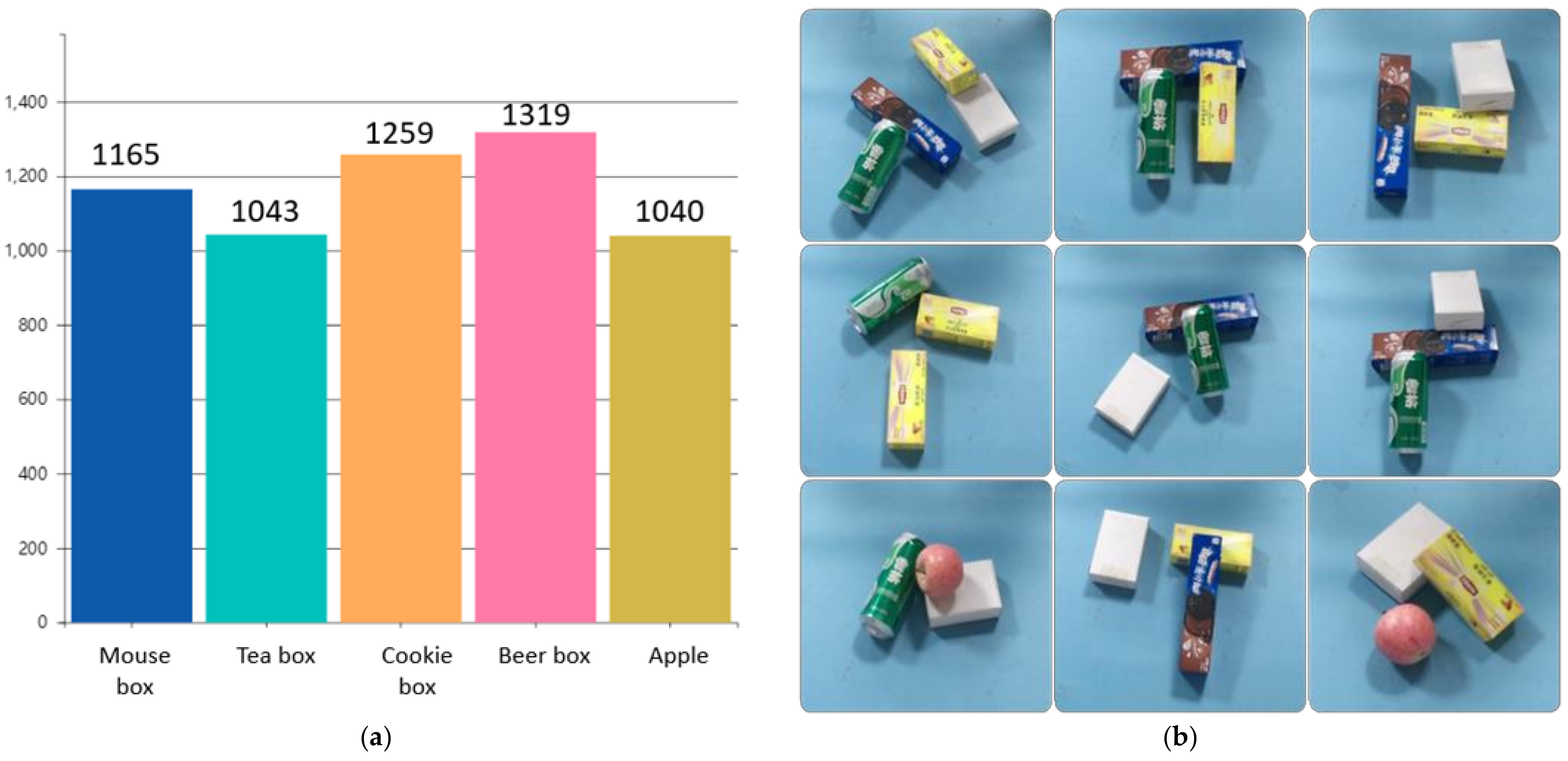
According to the above conditions, five kinds of objects suitable for grasping are selected as the target objects in the construction of data sets. When collecting images, 2~4 target objects are placed on the experimental platform. Due to the random placement of objects in practical application scenarios, objects may be stacked. Therefore, the collected image contains a variety of situations, such as separate objects, multiple objects scattered and multiple objects containing stacking. Finally, a total of 2000 images of target objects in the experimental scene were collected, with a total of 5826 entity instances. The number distribution of dataset objects and dataset images are shown in
Figure 4.
Calibration of data sets refer to PASCAL VOC [
32] including position information of real labels, specifications and posture of objects (rotation angle of marked border
θ). RoLabelImg is the dataset tagging software we use. The specific annotation process is as follows: Firstly, draw the horizontal border, which is similar to the size of the object in the image. Then, rotate the horizontal frame to make its center point and edge coincide with the target object center point and the upper surface contour, respectively. Finally, add the object category label to the rotating border, as shown in
Figure 5. After labeling, the dataset is divided into a training set with 1600 images and a test set with 400 images, and then the Python program is used to change the annotation format to the DOTA dataset format (four corner coordinates of the rotating border) for training the neural network model.
4.3. Model Training and Evaluation
4.3.1. Dataset Augmentation
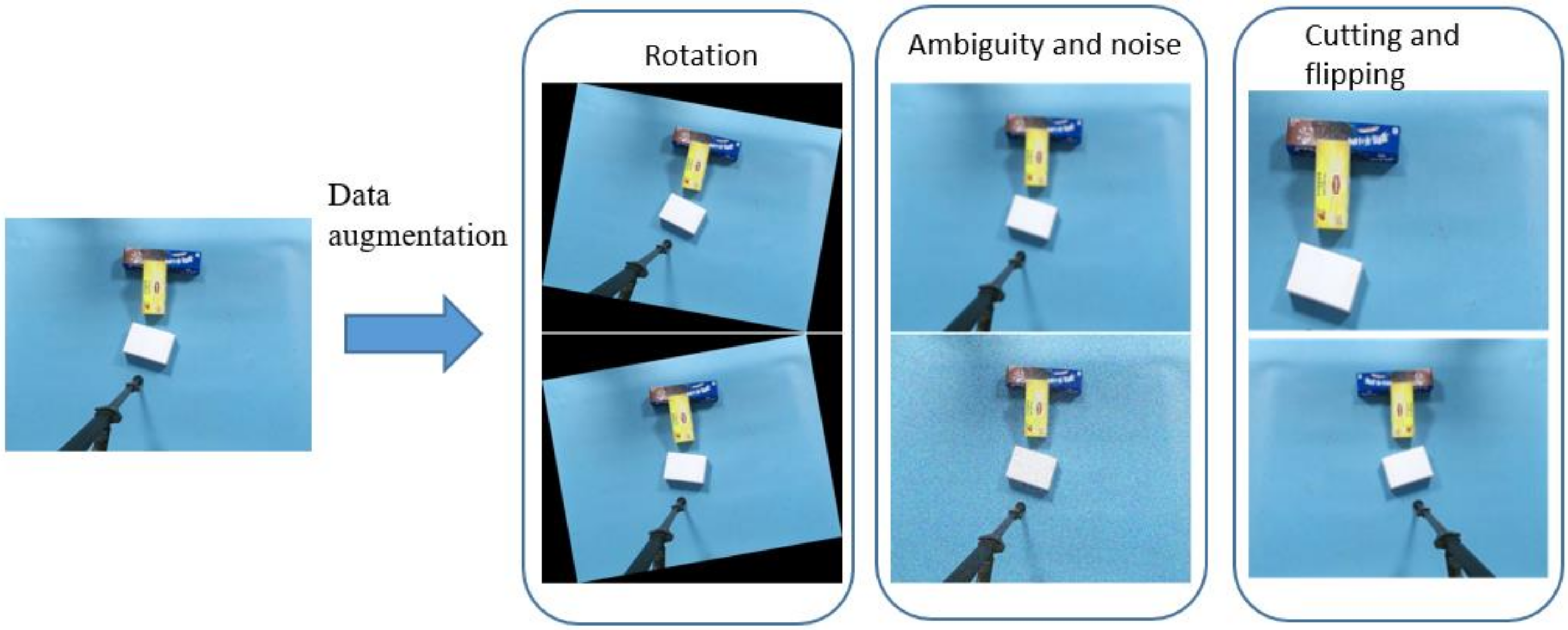
The size of the data set plays a vital role in achieving good performance of neural network model training. Data set enhancement is a method to generate data equivalent to the original data set through a series of transformations. Thus, the target network can be applied in various scenarios, such as different shooting direction, location and illumination when collecting data. In this paper, the original data set is enhanced by horizontal reversal, rotation, clipping, blurring and Gaussian noise, as shown in
Figure 6. For each image, random transformation is carried out according to the probability set by each transformation, and the transformation method can be superimposed. Therefore, the new data generated may contain multiple transformations.
4.3.2. Model Training
This paper constructs a rotating target detection model based on Ubuntu18.04 + tensorflow deep learning framework. The hardware configuration is Intel (R) Core (TM) i7-10700F CPU, 16GB memory and 8GB Nvidia GeForce RTX 2070 SUPER display card.
In model training, momentum optimizer is applied, and momentum is set to 0.9. The number of images sent to the model for each step of training is 1. For each input image, the random data enhancement method described in
Section 4.3.1 is adopted. In this paper, the learning rate adopts the strategy of warming up first and then decaying. The learning rate changes in the process of gradually increasing first, then stabilizing and finally decreasing in segments.
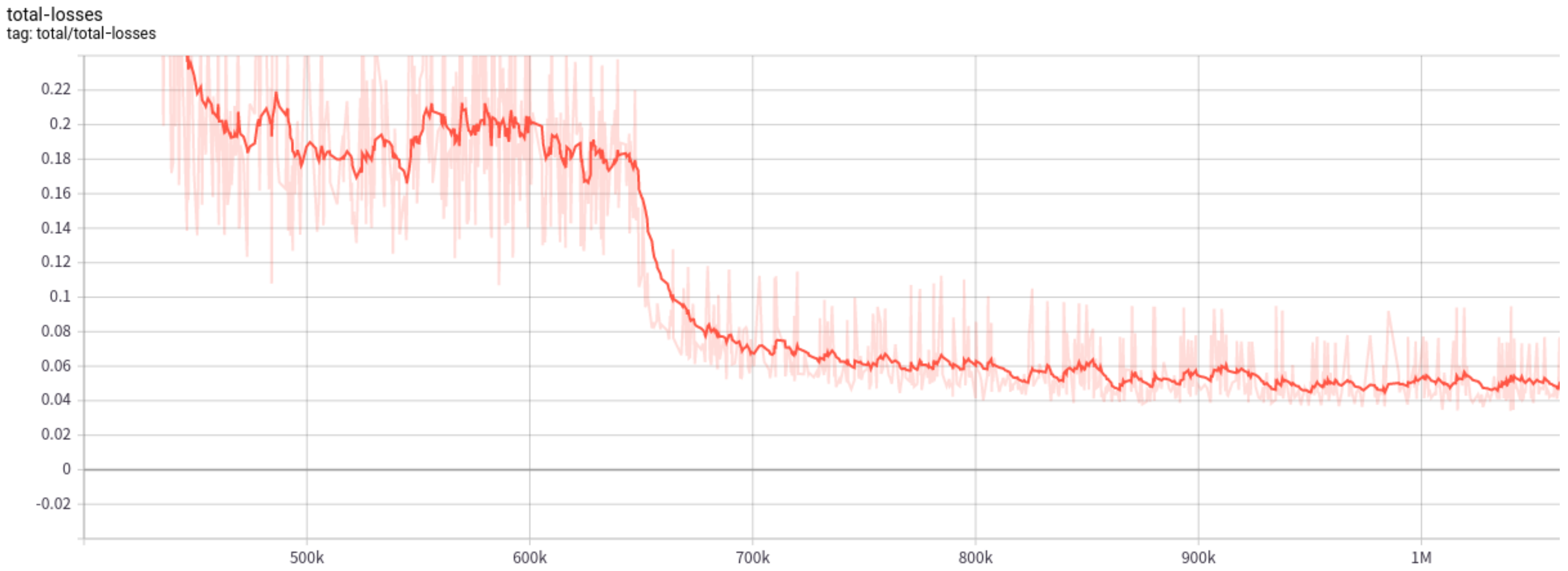
Neural network training is monitored by Tensorboard, and the overall training loss is shown in
Figure 7. It can be seen from the figure that the loss gradually decreases at the initial stage and then tends to be stable, and the ladder-like decline occurs at the global step number of about
steps, which is caused by the segmented decrease of learning rate. In a certain stage of neural network training, if the learning rate is large, it will lead to the model crossing the local optimal solution. When the learning rate decays, the loss continues to decline, and the model finally converges.
4.3.3. Model Evaluation
First, the IoU (Intersection over Union) threshold of the rotating target detection model is set to 0.5.
The prediction results of statistical samples, recall and precision sometimes appear contradictory situation; one of them is very high, and the other is very low. Therefore, it is necessary to adopt the F score for comprehensive consideration, whose expression is
Among them, P represents precision and R represents recall. is a constant, usually take 1. F-Score combines recall and precision: the higher the value, the better the performance of neural network.
Table 1 shows that the F-Score of the rotating target detection network model constructed in this paper is 0.99%. Compared with the conventional rotating target monitoring network [
33], the detection performance of the network model is good, and part of the test set after neural network detection is shown in
Figure 8.
8. Conclusions and Future Work
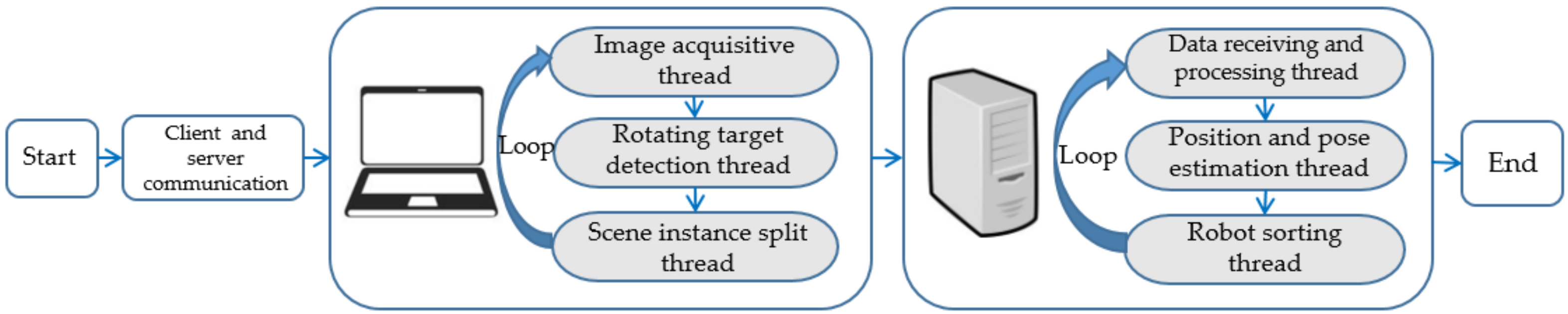
In this paper, a robot multi-objective sorting system based on fusion of rotating target and instance segmentation network is constructed. The first part of the system is the object recognition system. The Kinect camera collects the images of objects in unstructured scenes and sends them into the trained rotation target detection network and the optimized instance segmentation network to obtain the pose and category information of objects. The second part is the robot grasping system. The Windows client sends the pose information of the object to the robot instruction after calculation and processing and drives the robot to grasp. This paper innovatively proposed to use the information of the upper surface of the object to obtain the actual pose of the object and determine the stacking relationship between the upper and lower objects by comparing the mean value of the upper surface point cloud in the z direction, so as to solve the sorting problem of stacked objects in the non-institutional scene. Real experimental results showed that the proposed method had very good performance and good robustness for the sorting of common objects in daily life.
In addition, the method proposed in this paper still has many places that can be further studied. Firstly, in this paper, the way to obtain the pose of the object is to extract the upper surface information. In the future, the recognition of the grab point or the extraction of the overall geometric characteristics of the object can be studied to obtain the pose of the object. In this paper, the method of combining two neural networks is used in object recognition system, and the two networks can be fused into a neural network in the future. In this paper, the obstacle avoidance problem is not considered in the process of robot grasping, and the system can be optimized by integrating obstacle avoidance factors. Finally, this paper does not consider the strength and stiffness of the objects in the grasping process and does not control the grasping forces for different situations. Research improvements in this area could be undertaken in the future.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}