
Modeling Mortality Based on Pollution and Temperature Using a New Birnbaum–Saunders Autoregressive Moving Average Structure with Regressors and Related-Sensors Data




Abstract
:1. Introduction
2. An RBS Regression Model
2.1. The RBS Distribution
2.2. Formulation
2.3. Estimation
3. RBSARMAX Model
3.1. Formulation
3.2. Estimation
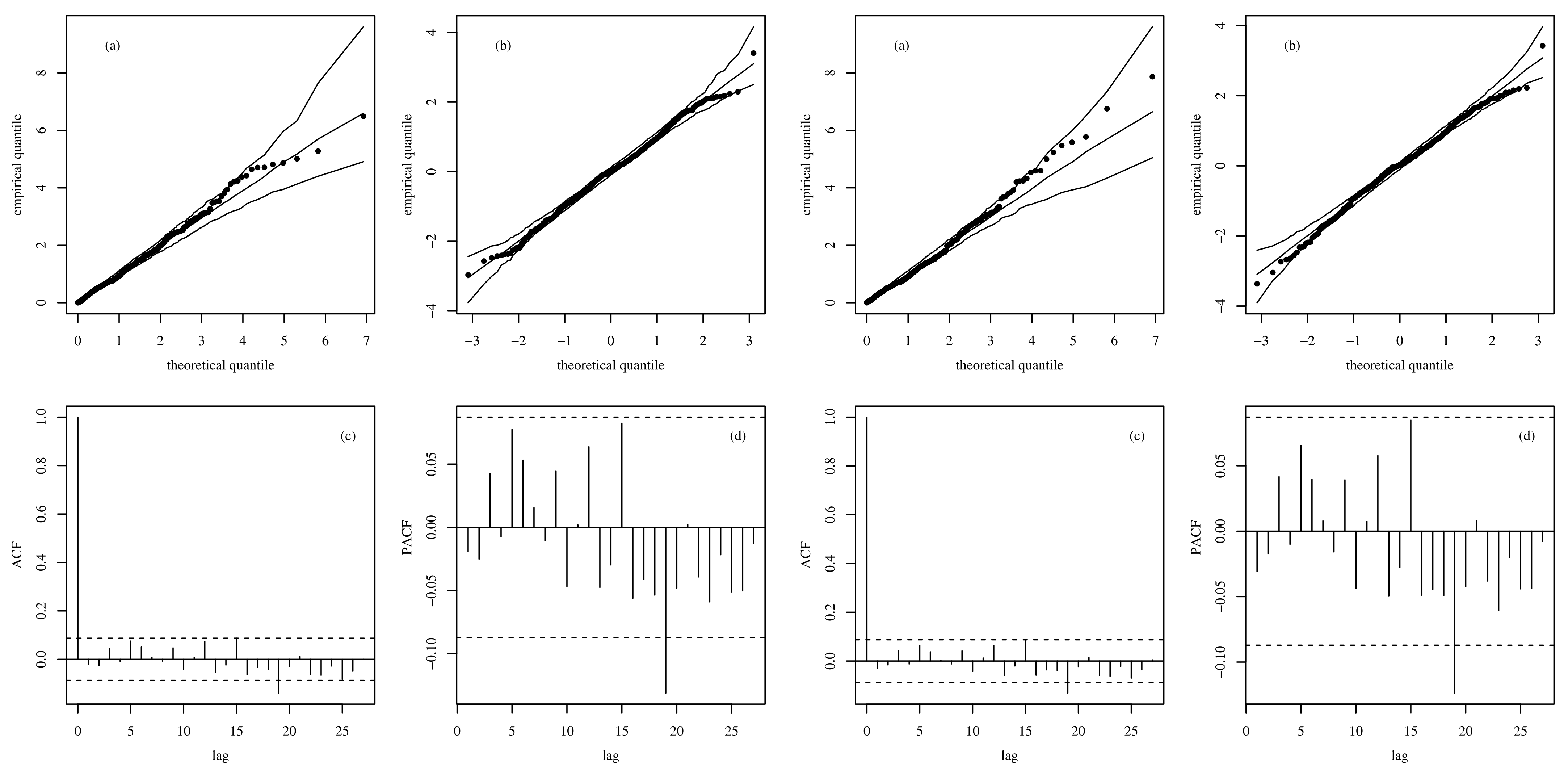
3.3. Residual Analysis
4. Numerical Simulations
4.1. Definitions and Simulation Model
4.2. RBSARMAX(1,1,1) Model
4.3. Performance Measures and Model Selection
4.3.1. Scenario 1
4.3.2. Scenario 2
5. Application to Real-World Data Related to Sensors
5.1. Sensor-Related Data and Definition of the Variables
5.2. Exploratory Data Analysis
5.3. Time-Series Modeling
6. Conclusions, Limitations, and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. The Observed Fisher Information Matrix
References
- Marchant, C.; Leiva, V.; Cavieres, M.F.; Sanhueza, A. Air contaminant statistical distributions with application to PM10 in Santiago, Chile. Rev. Environ. Contam. Toxicol. 2013, 223, 1–31. [Google Scholar] [PubMed]
- Cavieres, M.F.; Leiva, V.; Marchant, C.; Rojas, F. A methodology for data-driven decision making in the monitoring of particulate matter environmental contamination in Santiago of Chile. Rev. Environ. Contam. Toxicol. 2020, 250, 45–67. [Google Scholar] [PubMed]
- Shumway, R.H.; Azari, A.S.; Pawitan, Y. Modeling mortality fluctuations in Los Angeles as functions of pollution and weather effects. Environ. Res. 1988, 45, 224–241. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples; Springer: New York, NY, USA, 2017. [Google Scholar]
- Maior, V.Q.S.; Cysneiros, F.J.A. SYMARMA: A new dynamic model for temporal data on conditional symmetric distribution. Stat. Pap. 2016, 59, 75–97. [Google Scholar] [CrossRef]
- Leiva, V.; Marchant, C.; Ruggeri, F.; Saulo, H. A criterion for environmental assessment using Birnbaum–Saunders attribute control charts. Environmetrics 2015, 26, 463–476. [Google Scholar] [CrossRef]
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. J. Appl. Probab. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Desmond, A. Stochastic models of failure in random environments. Can. J. Stat. 1985, 13, 171–183. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; Wiley: New York, NY, USA, 1995; pp. 651–663. [Google Scholar]
- Leiva, V. The Birnbaum–Saunders Distribution; Academic Press: New York, NY, USA, 2016. [Google Scholar]
- Ferreira, M.; Gomes, M.I.; Leiva, V. On an extreme value version of the Birnbaum–Saunders distribution. REVSTAT 2012, 10, 181–210. [Google Scholar]
- Marchant, C.; Leiva, V.; Cysneiros, F.J.A.; Liu, S. Robust multivariate control charts based on Birnbaum–Saunders distributions. J. Stat. Comput. Simul. 2018, 88, 182–202. [Google Scholar] [CrossRef]
- Marchant, C.; Leiva, V.; Christakos, G.; Cavieres, M.F. Monitoring urban environmental pollution by bivariate control charts: New methodology and case study in Santiago, Chile. Environmetrics 2019, 30, e2551. [Google Scholar] [CrossRef]
- Puentes, R.; Marchant, C.; Leiva, V.; Figueroa-Zúñiga, J.I.; Ruggeri, F. Predicting PM2.5 and PM10 levels during critical episodes management in Santiago, Chile, with a bivariate Birnbaum–Saunders log-linear model. Mathematics 2021, 9, 645. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Ruggeri, F.; Uribe-Opazo, M.A. Kriging with external drift in a Birnbaum-Saunders geostatistical model. Stoch. Environ. Res. Risk Assess. 2018, 32, 1517–1530. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Leiva, V.; Uribe-Opazo, M.A.; Aykroyd, R.G. Birnbaum–Saunders spatial regression models: Diagnostics and application to chemical data. Chemom. Intell. Lab. Syst. 2018, 177, 114–128. [Google Scholar] [CrossRef] [Green Version]
- Leiva, V.; Ferreira, M.; Gomes, M.I.; Lillo, C. Extreme value Birnbaum–Saunders regression models applied to environmental data. Stoch. Environ. Res. Risk Assess. 2016, 30, 1045–1058. [Google Scholar] [CrossRef]
- Lillo, C.; Leiva, V.; Nicolis, O.; Aykroyd, R.G. L-moments of the Birnbaum–Saunders distribution and its extreme value version: Estimation, goodness of fit and application to earthquake data. J. Appl. Stat. 2018, 45, 187–209. [Google Scholar] [CrossRef]
- Saulo, H.; Leiva, V.; Ziegelmann, F.A.; Marchant, C. A nonparametric method for estimating asymmetric densities based on skewed Birnbaum–Saunders distributions applied to environmental data. Stoch. Environ. Res. Risk Assess. 2013, 27, 1479–1491. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Kundu, D. Birnbaum–Saunders distribution: A review of models, analysis, and applications. Appl. Stoch. Model. Bus. Ind. 2019, 35, 4–49. [Google Scholar] [CrossRef] [Green Version]
- Rieck, J.R.; Nedelman, J.R. A log-linear model for the Birnbaum–Saunders distribution. Technometrics 1991, 3, 51–60. [Google Scholar]
- Dasilva, A.; Dias, R.; Leiva, V.; Marchant, C.; Saulo, H. Birnbaum–Saunders regression models: A comparative evaluation of three approaches. J. Stat. Comput. Simul. 2020, 90, 2552–2570. [Google Scholar] [CrossRef]
- Fonseca, R.V.; Nobre, J.S.; Farias, R.B.A. Comparative inference and diagnostic in a reparametrized Birnbaum–Saunders regression model. Chilean J. Stat. 2016, 7, 17–30. [Google Scholar]
- Leão, J.; Leiva, V.; Saulo, H.; Tomazella, V. Incorporation of frailties into a cure rate regression model and its diagnostics and application to melanoma data. Stat. Med. 2018, 37, 4421–4440. [Google Scholar] [CrossRef] [PubMed]
- Desousa, M.; Saulo, H.; Leiva, V.; Santos-Neto, M. On a new mixture-based regression model: Simulation and application to data with high censoring. J. Stat. Comput. Simul. 2020, 90, 2861–2877. [Google Scholar] [CrossRef]
- Mazucheli, M.; Leiva, V.; Alves, B.; Menezes, A.F.B. A new quantile regression for modeling bounded data under a unit Birnbaum–Saunders distribution with applications in medicine and politics. Symmetry 2021, 13, 682. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Dey, S. The unit-Birnbaum–Saunders distribution with applications. Chilean J. Stat. 2018, 9, 47–57. [Google Scholar]
- Reyes, J.; Arrue, J.; Leiva, V.; Martin-Barreiro, C. A new Birnbaum–Saunders distribution and its mathematical features applied to bimodal real-world data from environment and medicine. Mathematics 2021, 9, 1891. [Google Scholar] [CrossRef]
- Sanchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum–Saunders quantile regression and its diagnostics with application to economic data. Appl. Stoch. Model. Bus. Ind. 2021, 37, 53–73. [Google Scholar] [CrossRef]
- Athayde, E.; Azevedo, A.; Barros, M.; Leiva, V. Failure rate of Birnbaum–Saunders distributions: Shape, change-point, estimation and robustness. Braz. J. Probab. Stat. 2019, 33, 301–328. [Google Scholar] [CrossRef] [Green Version]
- Balakrishnan, N.; Gupta, R.; Kundu, D.; Leiva, V.; Sanhueza, A. On some mixture models based on the Birnbaum–Saunders distribution and associated inference. J. Stat. Plan. Inference 2011, 141, 2175–2190. [Google Scholar] [CrossRef]
- Santos-Neto, M.; Cysneiros, F.J.A.; Leiva, V.; Barros, M. On new parameterizations of the Birnbaum–Saunders distribution and its moments, estimation and application. REVSTAT 2014, 12, 247–272. [Google Scholar]
- Leiva, V.; Santos-Neto, M.; Cysneiros, F.J.A.; Barros, M. Birnbaum–Saunders statistical modeling: A new approach. Stat. Model. 2014, 14, 21–48. [Google Scholar] [CrossRef]
- Bhatti, C. The Birnbaum–Saunders autoregressive conditional duration model. Math. Comput. Simul. 2010, 80, 2062–2078. [Google Scholar] [CrossRef]
- Fonseca, R.V.; Cribari-Neto, F. Bimodal Birnbaum–Saunders generalized autoregressive score model. J. Appl. Stat. 2014, 45, 2585–2606. [Google Scholar] [CrossRef]
- Leiva, V.; Saulo, H.; Leão, J.; Marchant, C. A family of autoregressive conditional duration models applied to financial data. Comput. Stat. Data Anal. 2014, 79, 175–191. [Google Scholar] [CrossRef]
- Rahul, T.; Balakrishnan, N.; Balakrishna, N. Time series with Birnbaum–Saunders marginal distributions. Appl. Stoch. Model. Bus. Ind. 2018, 34, 562–581. [Google Scholar] [CrossRef]
- Saulo, H.; Leão, J.; Leiva, V.; Aykroyd, R.G. Birnbaum–Saunders autoregressive conditional duration models applied to high-frequency financial data. Stat. Pap. 2019, 46, 1021–1042. [Google Scholar] [CrossRef] [Green Version]
- Saulo, H.; Leão, J.; Santos-Neto, M. Discussion of “Birnbaum–Saunders distribution: A review of models, analysis, and applications” by N. Balakrishnan and Debasis Kundu. Appl. Stoch. Model. Bus. Ind. 2019, 35, 118–121. [Google Scholar] [CrossRef] [Green Version]
- Leiva, V.; Saulo, H.; Souza, R.; Aykroyd, R.G.; Vila, R. A new BISARMA time series model for forecasting mortality using weather and particulate matter data. J. Forecast. 2021, 40, 346–364. [Google Scholar] [CrossRef]
- Benjamin, M.A.; Rigby, R.A.; Stasinopoulos, D.M. Generalized autoregressive moving average models. J. Am. Stat. Assoc. 2003, 98, 214–223. [Google Scholar] [CrossRef]
- Rocha, A.V.; Cribari-Neto, F. Beta autoregressive moving average models. TEST 2009, 18, 529–545. [Google Scholar] [CrossRef]
- Santos-Neto, M.; Cysneiros, F.J.A.; Leiva, V.; Barros, M. Reparameterized Birnbaum–Saunders regression models with varying precision. Electron. J. Stat. 2016, 2, 2825–2855. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Stasinopoulos, D.; Rigby, R. Generalized additive models for location, scale and shape (GAMLSS). J. Stat. Softw. 2007, 23, 1–46. [Google Scholar] [CrossRef] [Green Version]
- Rinne, H. The Weibull Distribution; Chapman and Hall: London, UK, 2009. [Google Scholar]
- Ventura, M.; Saulo, H.; Leiva, V.; Monsueto, S. Log-symmetric regression models: Information criteria, application to movie business and industry data with economic implications. Appl. Stoch. Model. Bus. Ind. 2019, 35, 963–977. [Google Scholar] [CrossRef]
- Sales-Lérida, D.; Bello, A.J.; Sánchez-Alzola, A.; Martínez-Jiménez, P.M. An approximation for metal-oxide sensor calibration for air quality monitoring using multivariable statistical analysis. Sensors 2021, 21, 4781. [Google Scholar] [CrossRef]
- Velasco, H.; Laniado, H.; Toro, M.; Leiva, V.; Lio, Y. Robust three-step regression based on comedian and its performance in cell-wise and case-wise outliers. Mathematics 2021, 8, 1259. [Google Scholar]
- Aykroyd, R.G.; Leiva, V.; Marchant, C. Multivariate Birnbaum-Saunders distributions: Modelling and applications. Risks 2018, 6, 21. [Google Scholar] [CrossRef] [Green Version]
- Saulo, H.; Dasilva, A.; Leiva, V.; Sanchez, L.; de la Fuente-Mella, H. Log-symmetric quantile regression models. Stat. Neerl. 2022, in press. [Google Scholar] [CrossRef]
- Huerta, M.; Leiva, V.; Liu, S.; Rodriguez, M.; Villegas, D. On a partial least squares regression model for asymmetric data with a chemical application in mining. Chemom. Intell. Lab. Syst. 2019, 190, 55–68. [Google Scholar] [CrossRef]
- Rodriguez, M.; Leiva, V.; Huerta, M.; Lillo, M.; Tapia, A.; Ruggeri, F. An asymmetric area model-based approach for small area estimation applied to survey data. REVSTAT 2021, 19, 399–420. [Google Scholar]
- Costa, E.; Santos-Neto, M.; Leiva, V. Optimal sample size for the Birnbaum–Saunders distribution under decision theory with symmetric and asymmetric loss functions. Symmetry 2021, 13, 926. [Google Scholar] [CrossRef]
- Martin-Barreiro, C.; Ramirez-Figueroa, J.A.; Nieto, A.B.; Leiva, V.; Martin-Casado, A.; Galindo-Villardón, M.P. A new algorithm for computing disjoint orthogonal components in the three-way Tucker model. Mathematics 2021, 9, 203. [Google Scholar]
- Martin-Barreiro, C.; Ramirez-Figueroa, J.A.; Cabezas, X.; Leiva, V.; Galindo-Villardón, M.P. Disjoint and functional principal component analysis for infected cases and deaths due to COVID-19 in South American countries with sensor-related data. Sensors 2021, 21, 4094. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | |||||
|---|---|---|---|---|---|
| Mean | Bias | Variance | MSE | ||
| 100 | 8 | 8.4705 | 0.4705 | 1.5462 | 0.2334 |
| 15 | 15.8429 | 0.8429 | 5.3862 | 0.7171 | |
| 25 | 26.3139 | 1.3139 | 14.8842 | 1.7304 | |
| 50 | 52.2676 | 2.2676 | 59.0348 | 5.1441 | |
| 200 | 8 | 8.2414 | 0.2414 | 0.7216 | 0.0640 |
| 15 | 15.4353 | 0.4353 | 2.5264 | 0.1926 | |
| 25 | 25.6816 | 0.6816 | 7.0042 | 0.4665 | |
| 50 | 51.1722 | 1.1722 | 27.9215 | 1.3750 | |
| 500 | 8 | 8.0720 | 0.0720 | 0.2464 | 0.0072 |
| 15 | 15.1332 | 0.1332 | 0.8625 | 0.0189 | |
| 25 | 25.2044 | 0.2044 | 2.3963 | 0.0425 | |
| 50 | 50.3276 | 0.3276 | 9.5864 | 0.1077 | |
| n | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Bias | Variance | MSE | Mean | Bias | Variance | MSE | |||
| 100 | 0.3 | 0.3 | 0.2957 | −0.0043 | 0.0258 | 0.0258 | 0.2953 | −0.0047 | 0.0285 | 0.0286 |
| 0.5 | 0.3087 | 0.0087 | 0.0190 | 0.0191 | 0.4791 | −0.0209 | 0.0207 | 0.0211 | ||
| 0.7 | 0.3098 | 0.0098 | 0.0139 | 0.0140 | 0.6681 | −0.0319 | 0.0142 | 0.0152 | ||
| 0.5 | 0.3 | 0.4761 | −0.0239 | 0.0149 | 0.0155 | 0.3114 | 0.0114 | 0.0188 | 0.0189 | |
| 0.5 | 0.4863 | −0.0137 | 0.0127 | 0.0129 | 0.4946 | −0.0054 | 0.0151 | 0.0152 | ||
| 0.7 | 0.4855 | −0.0145 | 0.0110 | 0.0112 | 0.6755 | −0.0245 | 0.0122 | 0.0128 | ||
| 0.7 | 0.3 | 0.6664 | −0.0336 | 0.0084 | 0.0096 | 0.3171 | 0.0171 | 0.0136 | 0.0139 | |
| 0.5 | 0.6733 | −0.0267 | 0.0080 | 0.0087 | 0.5005 | 0.0005 | 0.0119 | 0.0119 | ||
| 0.7 | 0.6725 | −0.0275 | 0.0074 | 0.0081 | 0.6717 | −0.0283 | 0.0109 | 0.0117 | ||
| 200 | 0.3 | 0.3 | 0.2954 | −0.0046 | 0.0143 | 0.0143 | 0.2980 | −0.0020 | 0.0151 | 0.0151 |
| 0.5 | 0.3004 | 0.0004 | 0.0083 | 0.0083 | 0.4913 | −0.0087 | 0.0078 | 0.0079 | ||
| 0.7 | 0.3046 | 0.0046 | 0.0066 | 0.0066 | 0.6818 | −0.0182 | 0.0052 | 0.0055 | ||
| 0.5 | 0.3 | 0.4853 | −0.0147 | 0.0079 | 0.0082 | 0.3066 | 0.0066 | 0.0096 | 0.0096 | |
| 0.5 | 0.4897 | −0.0103 | 0.0054 | 0.0055 | 0.4983 | −0.0017 | 0.0060 | 0.0060 | ||
| 0.7 | 0.4920 | −0.0080 | 0.0048 | 0.0049 | 0.6852 | −0.0148 | 0.0045 | 0.0048 | ||
| 0.7 | 0.3 | 0.6811 | −0.0189 | 0.0041 | 0.0045 | 0.3093 | 0.0093 | 0.0067 | 0.0068 | |
| 0.5 | 0.6841 | −0.0159 | 0.0033 | 0.0036 | 0.5006 | 0.0006 | 0.0050 | 0.0050 | ||
| 0.7 | 0.6868 | −0.0132 | 0.0033 | 0.0034 | 0.6817 | −0.0183 | 0.0044 | 0.0047 | ||
| 500 | 0.3 | 0.3 | 0.2958 | −0.0042 | 0.0058 | 0.0058 | 0.3002 | 0.0002 | 0.0063 | 0.0063 |
| 0.5 | 0.2978 | −0.0022 | 0.0036 | 0.0036 | 0.4984 | −0.0016 | 0.0032 | 0.0032 | ||
| 0.7 | 0.3018 | 0.0018 | 0.0025 | 0.0025 | 0.6922 | −0.0078 | 0.0017 | 0.0018 | ||
| 0.5 | 0.3 | 0.4922 | −0.0078 | 0.0030 | 0.0030 | 0.3034 | 0.0034 | 0.0040 | 0.0040 | |
| 0.5 | 0.4936 | −0.0064 | 0.0023 | 0.0024 | 0.5011 | 0.0011 | 0.0024 | 0.0024 | ||
| 0.7 | 0.4966 | −0.0034 | 0.0018 | 0.0019 | 0.6936 | −0.0064 | 0.0015 | 0.0016 | ||
| 0.7 | 0.3 | 0.6916 | −0.0084 | 0.0014 | 0.0015 | 0.3037 | 0.0037 | 0.0029 | 0.0029 | |
| 0.5 | 0.6927 | −0.0073 | 0.0013 | 0.0014 | 0.5013 | 0.0013 | 0.0020 | 0.0020 | ||
| 0.7 | 0.6965 | −0.0035 | 0.0013 | 0.0013 | 0.6905 | −0.0095 | 0.0015 | 0.0015 | ||
| n | AIC | BIC | MAPE | ||
|---|---|---|---|---|---|
| 100 | 0.3 | 0.3 | 365.1127 (424.5509) | 378.1385 (437.5767) | 47.5600 (50.5495) |
| 0.5 | 358.6198 (434.0864) | 371.6457 (447.1122) | 47.4919 (53.2613) | ||
| 0.7 | 353.1928 (450.4833) | 366.2187 (463.5092) | 47.9737 (59.0348) | ||
| 0.5 | 0.3 | 346.8663 (426.9802) | 359.8921 (440.0060) | 47.5695 (53.5615) | |
| 0.5 | 337.8665 (441.0506) | 350.8924 (454.0764) | 47.5570 (58.4819) | ||
| 0.7 | 329.9848 (461.8964) | 343.0103 (474.9222) | 48.2969 (67.8709) | ||
| 0.7 | 0.3 | 304.6918 (427.5490) | 317.7176 (440.5749) | 47.6495 (62.3559) | |
| 0.5 | 290.1231 (448.0035) | 303.1489 (461.0293) | 47.7313 (74.1163) | ||
| 0.7 | 276.5373 (474.0917) | 289.5631 (487.1176) | 48.8350 (94.6032) | ||
| 200 | 0.3 | 0.3 | 730.0360 (850.0534) | 746.5276 (866.5450) | 48.0250 (50.4204) |
| 0.5 | 717.5611 (873.3260) | 734.0527 (889.8176) | 48.0832 (53.3298 | ||
| 0.7 | 708.0656 (915.5029) | 724.5571 (931.9945) | 48.5205 (59.2581) | ||
| 0.5 | 0.3 | 694.7785 (858.7896) | 711.2701 (875.2812) | 48.0156 (53.1801) | |
| 0.5 | 677.0623 (893.5079) | 693.5539 (909.9995) | 48.1152 (58.4859) | ||
| 0.7 | 662.9814 (947.2945) | 679.4730 (963.7861) | 48.6620 (68.0547) | ||
| 0.7 | 0.3 | 612.9718 (873.1339) | 629.4634 (889.6255) | 48.0465 (61.6831) | |
| 0.5 | 583.2384 (924.1664) | 599.7300 (940.6580) | 48.2035 (74.2198) | ||
| 0.7 | 558.8758 (995.1106) | 575.3674 (1011.6021) | 48.9833 (95.2990) | ||
| 500 | 0.3 | 0.3 | 1830.5340 (2144.955) | 1851.6070 (2166.0280) | 48.4820 (50.6497) |
| 0.5 | 1798.2570 (2204.2160) | 1819.3300 (2225.2890) | 48.5240 (53.4874) | ||
| 0.7 | 1768.6360 (2307.8030) | 1789.7090 (2328.8760) | 48.6783 (59.2412) | ||
| 0.5 | 0.3 | 1742.7360 (2176.732) | 1763.8090 (2197.8050) | 48.4793 (53.3932) | |
| 0.5 | 1697.1640 (2265.1910) | 1718.2370 (2286.2640) | 48.5363 (58.5531) | ||
| 0.7 | 1654.8520 (2400.0260) | 1675.9250 (2421.099) | 48.7389 (67.9263) | ||
| 0.7 | 0.3 | 1538.2870 (2238.3820) | 1559.3600 (2259.4550) | 48.4948 (62.0646) | |
| 0.5 | 1462.2430 (2374.6440) | 1483.3160 (2395.7170) | 48.5859 (74.5613) | ||
| 0.7 | 1391.7030 (2559.9320) | 1412.7760 (2581.00500) | 48.9514 (96.0765) |
| n | AIC | BIC | MAPE | |
|---|---|---|---|---|
| 100 | 8 | 290.1231 (448.0035) | 303.1489 (461.02934) | 47.7313 (74.1163) |
| 15 | 282.6548 (386.9450) | 295.6806 (399.9709) | 32.0136 (42.2746) | |
| 25 | 258.3715 (335.5085) | 271.3974 (348.5343) | 23.8601 (29.8148) | |
| 50 | 210.3474 (265.9603) | 223.3732 (278.9862) | 16.4679 (20.0521) | |
| 200 | 8 | 583.2384 (924.1664) | 599.7300 (940.6580) | 48.2035 (74.2198) |
| 15 | 567.9856 (790.4170) | 584.4772 (806.9086) | 32.2836 (42.1439) | |
| 25 | 518.7238 (681.6172) | 535.2154 (698.1088) | 24.0106 (29.5744) | |
| 50 | 421.3633 (537.5253) | 437.8549 (554.0169) | 16.4974 (19.7077) | |
| 500 | 8 | 1462.2430 (2374.6440) | 1483.3160 (2395.7170) | 48.5859 (74.5613) |
| 15 | 1425.7260 (2014.7160) | 1446.7990 (2035.7890) | 32.4906 (42.3578) | |
| 25 | 1302.9140 (1731.6710) | 1323.9870 (1752.7440) | 24.1287 (29.6706) | |
| 50 | 1058.8260 (1363.2620) | 1079.8990 (1384.3350) | 16.5303 (19.6674) |
| n | AIC | BIC | MAPE | RMSE | ||
|---|---|---|---|---|---|---|
| 100 | 0.3 | 0.3 | −22.4756 (−29.8433) | −9.4498 (−16.8175) | 12.8005 (13.5334) | 0.0410 (0.2342) |
| 0.5 | −18.2110 (−24.8238) | −5.1851 (−11.7979) | 13.1341 (13.9234) | 0.0432 (0.2394) | ||
| 0.7 | −5.8601 (−16.3406) | 7.1658 (−3.3148) | 14.1277 (14.5934) | 0.0490 (0.2466) | ||
| 0.5 | 0.3 | −20.0399 (−28.4447) | −7.0140 (−15.4189) | 13.0553 (13.6080) | 0.0428 (0.2355) | |
| 0.5 | −12.5863 (−22.6473) | 0.4396 (−9.6214) | 13.6356 (14.0540) | 0.0465 (0.2416) | ||
| 0.7 | 1.2421 (−2.2657) | 3.2481 (−0.2597) | 2.6458 (2.7110) | 0.0177 (0.0380) | ||
| 0.7 | 0.3 | −6.4925 (−12.5952) | −0.2010 (−6.3037) | 6.6156 (6.6192) | 0.0229 (0.1147) | |
| 0.5 | 0.1071 (−6.6168) | 4.3014 (−2.4224) | 4.9221 (4.6593) | 0.0185 (0.0784) | ||
| 0.7 | 0.0340 (0.0186) | 0.0600 (0.0447) | 0.0447 (0.0311) | 0.0000 (0.0000) | ||
| 200 | 0.3 | 0.3 | −48.0034 (−64.8406) | −31.5119 (−48.3490) | 12.9081 (13.2018) | 0.0416 (0.2191) |
| 0.5 | −40.4854 (−57.5609) | −23.9938 (−41.0693) | 13.2146 (13.4078) | 0.0437 (0.2227) | ||
| 0.7 | −1.7115 (−4.0864) | −0.1943 (−2.5692) | 1.2999 (1.2767) | 0.0045 (0.0211) | ||
| 0.5 | 0.3 | −43.1893 (−62.3776) | −26.6977 (−45.8860) | 13.1516 (13.2349) | 0.0434 (0.2203) | |
| 0.5 | −17.5406 (−33.0697) | −7.4312 (−22.9603) | 8.4065 (8.2611) | 0.0289 (0.1378) | ||
| 0.7 | −0.0234 (−0.0264) | −0.0069 (−0.0099) | 0.0147 (0.0145) | 0.0000 (0.0000) | ||
| 0.7 | 0.3 | −8.0637 (−16.7478) | −3.2482 (−11.9323) | 4.0371 (3.8855) | 0.0140 (0.0652) | |
| 0.5 | 0.1230 (−0.407) | 0.2550 (−0.2751) | 0.1253 (0.1108) | 0.0005 (0.0018) | ||
| 0.7 | −0.0036 (−0.0257) | 0.0129 (−0.0092) | 0.0159 (0.0148) | 0.0000 (0.0000) | ||
| 500 | 0.3 | 0.3 | −119.9713 (−167.4259) | −98.8983 (−146.3529) | 12.9788 (12.9692) | 0.0423 (0.2104) |
| 0.5 | −102.4109 (−156.7271) | −81.3378 (−135.6541) | 13.2702 (13.0616) | 0.0443 (0.2122) | ||
| 0.7 | −667.5407 (−710.4881) | −646.4676 (−689.4151) | 7.2738 (7.1659) | 0.0147 (0.1301) | ||
| 0.5 | 0.3 | −107.7683 (−162.3276) | −162.3276 (−141.2546) | 13.2239 (12.9785) | 0.0441 (0.0448) | |
| 0.5 | −682.3179 (−739.5599) | −661.2449 (−718.4869) | 7.1669 (6.9845) | 0.0143 (0.1270) | ||
| 0.7 | −617.3638 (−704.0180) | −596.2907 (−682.9450) | 7.6447 (7.2001) | 0.0161 (0.1308) | ||
| 0.7 | 0.3 | −680.0527 (−754.0620) | −658.9796 (−732.9890) | 7.1986 (6.8827) | 0.0145 (0.1259) | |
| 0.5 | −623.3151 (−733.1113) | −602.2421 (−712.0383) | 7.6099 (6.9997) | 0.0161 (0.1276) | ||
| 0.7 | −514.9032 (−676.4386) | −494.3992 (−655.9346) | 8.1062 (7.0481) | 0.0183 (0.1283) |
| n | AIC | BIC | MAPE | RMSE | |
|---|---|---|---|---|---|
| 100 | 2.5 | 5.1509 (5.2493) | 5.5156 (5.6140) | 1.6829 (1.6532) | 0.0123 (0.0172) |
| 5 | 34.4187 (29.8729) | 40.9968 (36.4509) | 11.1338 (11.2125) | 0.0530 (0.1691) | |
| 8 | −20.0399 (−28.44447) | −7.0140 (−15,4189) | 13.0553 (13.6080) | 0.0428 (0.2355) | |
| 15 | −139.7903 (−146.6292) | −126.7645 (−133,6034) | 6.9384 (7.6037) | 0.0135 (0.1662) | |
| 25 | −235.5484 (−244.4121) | −222.5225 (−231.3863) | 4.3160 (4.9401) | 0.0056 (0.1416) | |
| 50 | −357.0783 (−379.0394) | −344.0524 (−366.0135) | 2.4303 (2.9598) | 0.0021 (0.1292) | |
| 200 | 2.5 | 1.7186 (1.6450) | 1.7845 (1.7110) | 0.2812 (0.2697) | 0.0021 (0.0027) |
| 5 | 39.4501 (33.3857) | 44.2656 (38.2013) | 6.5062 (6.4046) | 0.0311 (0.0956) | |
| 8 | −43.1893 (−62.3776) | −26.6977 (−45.8860) | 13.1516 (13.2349) | 0.0434 (0.2203) | |
| 15 | −284.7475 (−299.8642) | −268.2559 (−283.3726) | 6.9327 (7.1730) | 0.0134 (0.1418) | |
| 25 | −477.7108 (−495,7330) | −461.2192 (−479.2414) | 4.2670 (4.4941) | 0.0054 (0.1113) | |
| 50 | −720.3836 (−765.6852) | −703.8920 (−749.1936) | 2.3692 (2.4927) | 0.0018 (0.0946) | |
| 500 | 2.5 | 2.0445 (1.9371) | 2.0866 (1.9793 | 0.1368 (0.1246) | 0.0009 (0.0013) |
| 5 | 0.7635 (0.5879) | 0.8057 (0.6301) | 0.0466 (0.0451) | 0.0000 (0.0000) | |
| 8 | −107.7683 (−162.3276) | −86.6952 (−141.2546) | 13.2239 (12.9785) | 0.0441 (0.2114) | |
| 15 | −714.5877 (−758.5032) | −693.5146 (−737.4302) | 6.9309 (6.8751) | 0.0135 (0.1254) | |
| 25 | −1200.435 (−1248.213) | −1179.362 (−1227.139) | 4.2313 (4.1990) | 0.0053 (0.0886) | |
| 50 | −1811.681 (−1922.298) | −1790.608 (−1901.225) | 2.3154 (2.2047) | 0.0017 (0.0659) |
| n | Variables | Minimum | Maximum | Median | Mean | SD | CV | CS | CK |
|---|---|---|---|---|---|---|---|---|---|
| 508 | Mortality, | 68.110 | 132.040 | 87.330 | 88.699 | 9.999 | 0.113 | 0.804 | 0.981 |
| Temperature, | 50.910 | 99.880 | 74.055 | 74.260 | 9.014 | 0.121 | 0.095 | −0.459 | |
| PM, | 20.250 | 97.940 | 44.250 | 47.413 | 15.138 | 0.319 | 0.570 | −0.474 |
| Model | Parameter | Estimate | AIC | BIC | MAPE |
|---|---|---|---|---|---|
| RBSARMAX | 0.3646 | 3078.4330 | 3112.2770 | 4.8128 | |
| 0.4393 | |||||
| 2842.8252 | |||||
| −1.3990 | |||||
| −0.0161 | |||||
| 0.0154 | |||||
| 0.1503 | |||||
| 623.5548 | |||||
| ARMA | 0.3881 | 3100.1290 | 3133.9730 | 4.8151 | |
| 0.4321 | |||||
| 2831.4911 | |||||
| −1.3932 | |||||
| −0.0169 | |||||
| 0.0154 | |||||
| 0.1554 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saulo, H.; Souza, R.; Vila, R.; Leiva, V.; Aykroyd, R.G. Modeling Mortality Based on Pollution and Temperature Using a New Birnbaum–Saunders Autoregressive Moving Average Structure with Regressors and Related-Sensors Data. Sensors 2021, 21, 6518. https://doi.org/10.3390/s21196518
Saulo H, Souza R, Vila R, Leiva V, Aykroyd RG. Modeling Mortality Based on Pollution and Temperature Using a New Birnbaum–Saunders Autoregressive Moving Average Structure with Regressors and Related-Sensors Data. Sensors. 2021; 21(19):6518. https://doi.org/10.3390/s21196518
Chicago/Turabian StyleSaulo, Helton, Rubens Souza, Roberto Vila, Víctor Leiva, and Robert G. Aykroyd. 2021. "Modeling Mortality Based on Pollution and Temperature Using a New Birnbaum–Saunders Autoregressive Moving Average Structure with Regressors and Related-Sensors Data" Sensors 21, no. 19: 6518. https://doi.org/10.3390/s21196518
APA StyleSaulo, H., Souza, R., Vila, R., Leiva, V., & Aykroyd, R. G. (2021). Modeling Mortality Based on Pollution and Temperature Using a New Birnbaum–Saunders Autoregressive Moving Average Structure with Regressors and Related-Sensors Data. Sensors, 21(19), 6518. https://doi.org/10.3390/s21196518