
Building an IoT Platform Based on Service Containerisation

 ,
,  , , ,
, , ,  ,
,  and
and
Abstract
:1. Introduction
2. State of the Art
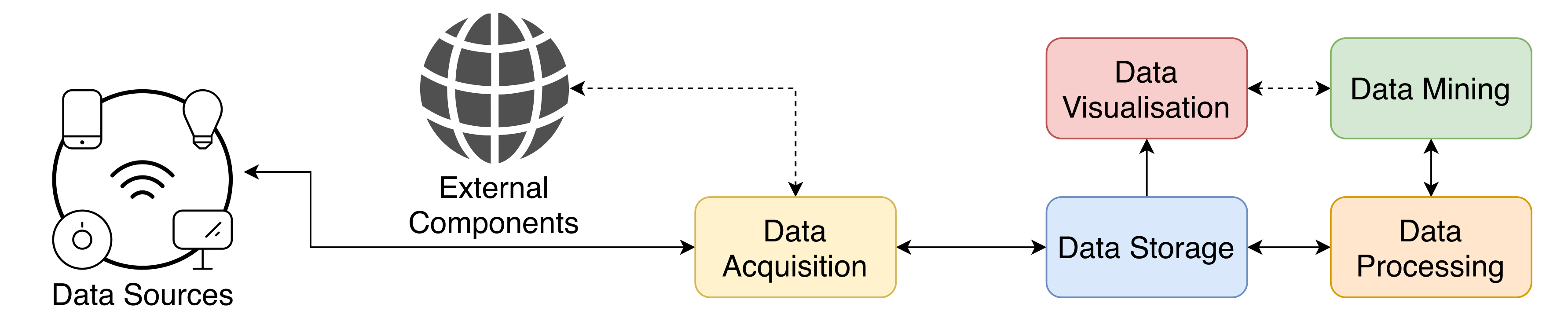
2.1. Data Acquisition
2.2. Data Storage
2.3. Data Processing
2.4. Data Visualisation
2.5. Containerisation
2.6. IoT Platforms
- Monolithic architecture—there was no redundancy available, or the redundancy was limited by the inherent construction centred in service layers with common service functions.
- Difficult to manage—it is challenging to add new services or to debug issues. In particular, scalability and performance issues.
- Under-performing in unexpected high traffic scenarios—infrastructure might not be able to handle a high number of connections or data objects being passed. Objects were duplicated and processed by a large number of service functions, and an error could propagate to further layers without being noticed.
- Difficult to redeploy the same platform—the services were deployed mostly manually and do not allow redeploying the same infrastructure quickly and automatically, which was already cumbersome for telecom operations but impossible to use in other IT operation scenarios.
- Possible conflicts between services in the same machine—One malfunctioning service can affect other services running in the same machine (e.g., a memory leak, data corruption).
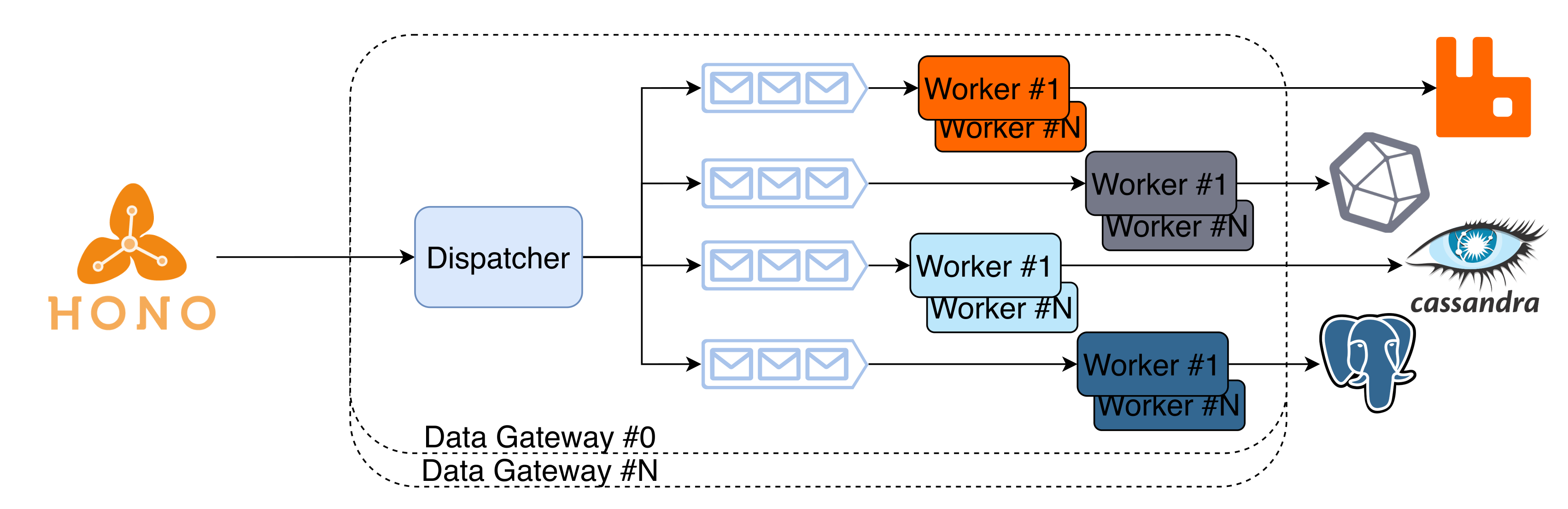
3. Scot Architecture and Implementation
- Distributed architecture—Implemented using a multi-node distributed platform, which allows the distribution of the workload amongst the available workers and making it fault-tolerant by keeping track of the nodes’ health;
- Service replication with load balancing—The proposed implementation allows the replication of any service to improve scalability. Furthermore, the incoming traffic is distributed amongst all replicates to maximise the performance;
- Easier to scale the infrastructure and/or applications—This implementation facilitates the scaling operations of either the cluster or the services of an application, allowing a near-zero downtime;
- Excessive work in updating the platform—The fully custom implementation brought large challenges to code base maintenance as types of software evolve, and multiple security bugs become known. Keeping the whole platform updated requires meaningful proprietary effort.
Listing 1: Pseudocode extract from the ditto incoming mapping
- function mapToDittoProtocolMsg(headers, textPayload,
- bytePayload, contentType) {
- let rv = {};
- try {
- let jsonData;
- if (contentType == “application/json”) {
- jsonData = JSON.parse(textPayload);
- } else {
- let payload = Ditto.asByteBuffer(bytePayload);
- jsonData = JSON.parse(payload.toUTF8());
- }
- let stack = [[jsonData, “”]];
- while (stack.length) {
- let tmp = stack.pop(), root = tmp[0], preffix = tmp[1];
- for (let key in root) {
- let value = root[key];
- if (!!value && value.constructor === Object) {
- let new_preffix;
- if (preffix) {
- new_preffix = preffix.concat(“.”, key);
- } else {
- new_preffix = key;
- }
- stack.push([value, new_preffix]);
- } else {
- let new_preffix;
- if (preffix) {
- new_preffix = preffix.concat(“.”, key);
- } else {
- new_preffix = key;
- }
- rv[new_preffix] = {“properties”:{“value”:value}};
- }
- }
- }
- } catch (e) {
- let byteBuf = Ditto.asByteBuffer(bytePayload);
- rv = {“raw”:{“properties”:{“value”:byteBuf.toBase64()}}}
- }
- return Ditto.buildDittoProtocolMsg(“{}”, headers[“device_id”],
- “things”, “twin”, “commands”, “modify”, “/features”, headers, rv);
- }
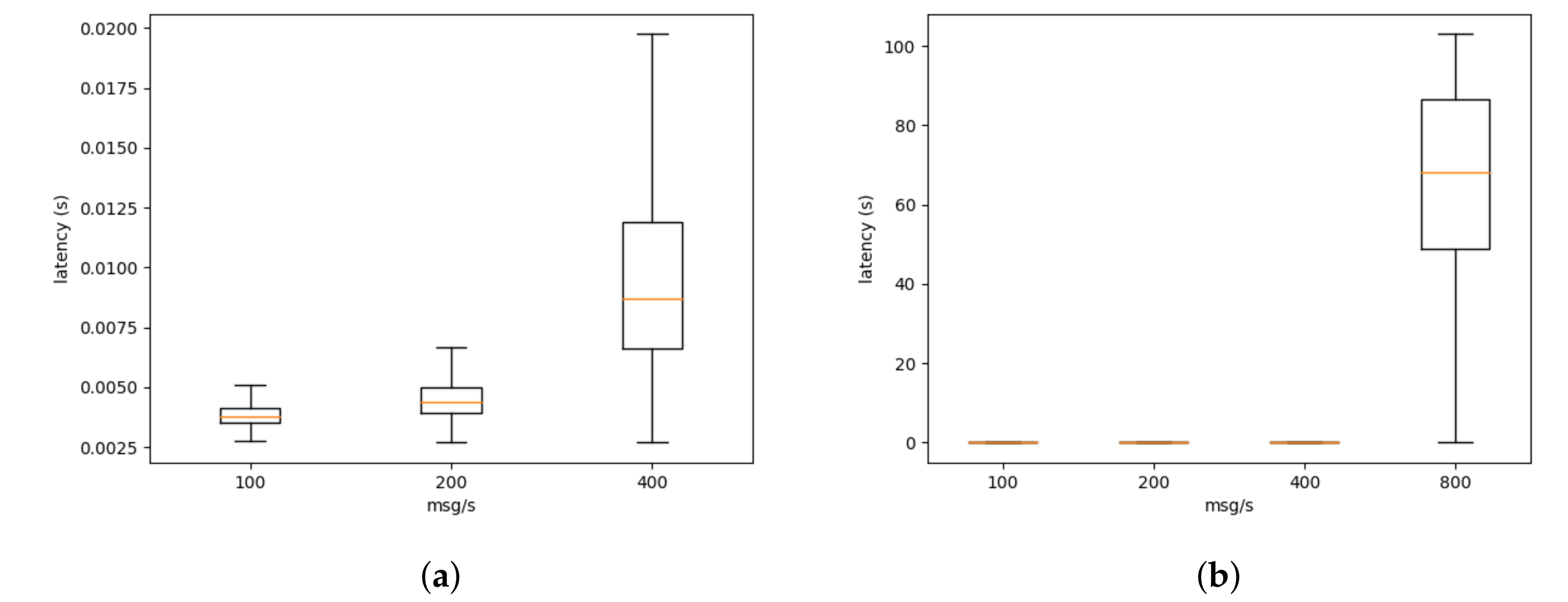
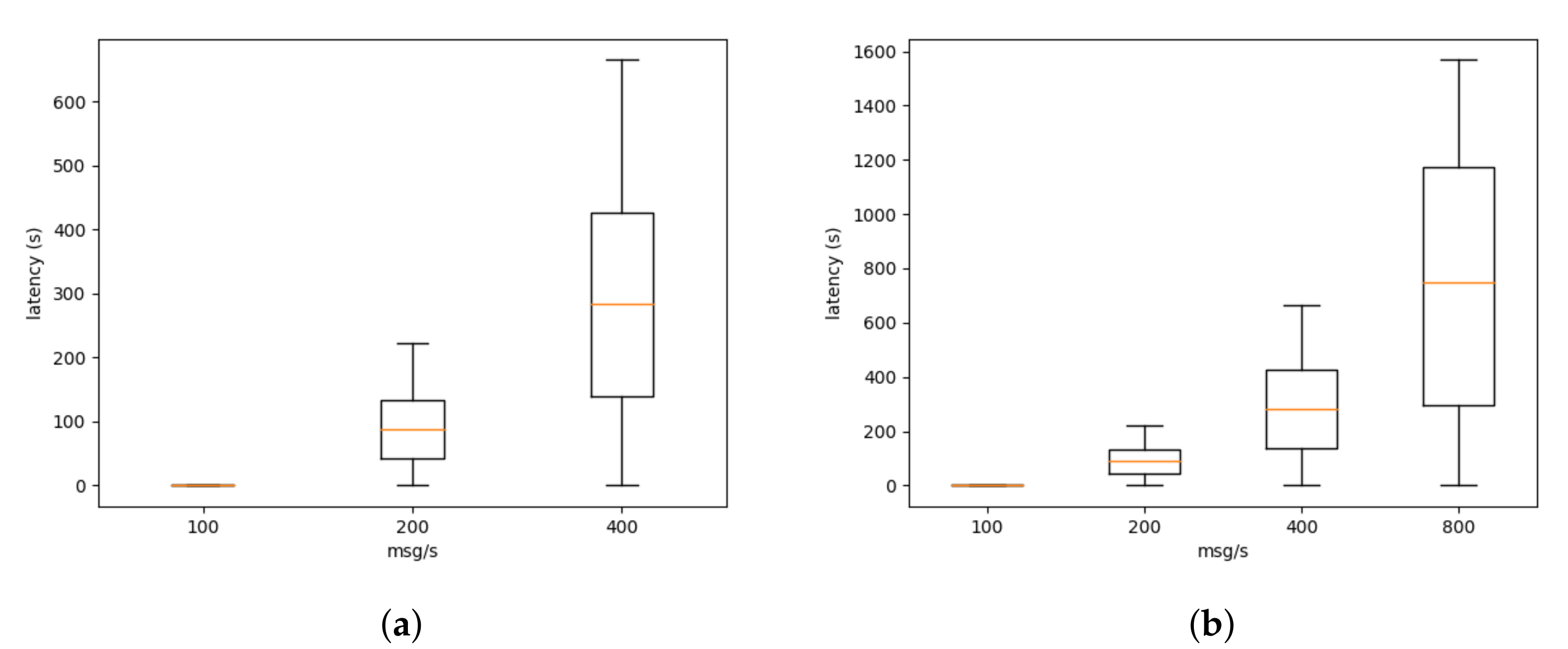
4. IoT Scenarios
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ng, I.C.; Wakenshaw, S.Y. The Internet-of-Things: Review and research directions. Int. J. Res. Mark. 2017, 34, 3–21. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y. Industry 4.0: A survey on technologies, applications and open research issues. J. Ind. Inf. Integr. 2017, 6, 1–10. [Google Scholar] [CrossRef]
- Antunes, M.; Barraca, J.P.; Gomes, D.; Oliveira, P.; Aguiar, R.L. Unified Platform for M2M Telco Providers. In Ubiquitous Computing and Ambient Intelligence. Personalisation and User Adapted Services; Hervás, R., Lee, S., Nugent, C., Bravo, J., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 436–443. [Google Scholar]
- Antunes, M.; Barraca, J.P.; Gomes, D.; Oliveira, P.; Aguiar, R.L. Smart Cloud of Things: An Evolved IoT Platform for Telco Providers. J. Ambient Wirel. Commun. Smart Environ. (AMBIENTCOM) 2016, 1, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Santiago, A.R.; Antunes, M.; Barraca, J.P.; Gomes, D.; Aguiar, R.L. SCoTv2: Large Scale Data Acquisition, Processing, and Visualization Platform. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud (FiCloud), Istanbul, Turkey, 26–28 August 2019; pp. 318–323. [Google Scholar] [CrossRef]
- Fernandes, S.; Antunes, M.; Santiago, A.R.; Barraca, J.P.; Gomes, D.; Aguiar, R.L. Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance. Information 2020, 11, 208. [Google Scholar] [CrossRef] [Green Version]
- Hejazi, H.; Rajab, H.; Cinkler, T.; Lengyel, L. Survey of platforms for massive IoT. In Proceedings of the 2018 IEEE International Conference on Future IoT Technologies (Future IoT), Eger, Hungary, 18–19 January 2018. [Google Scholar] [CrossRef] [Green Version]
- Dhall, R.; Solanki, V.K. An IoT Based Predictive Connected Car Maintenance Approach. Int. J. Interact. Multimed. Artif. Intell. 2017, 4, 16. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef] [Green Version]
- García-Gil, D.; Ramírez-Gallego, S.; García, S.; Herrera, F. A comparison on scalability for batch big data processing on Apache Spark and Apache Flink. Big Data Anal. 2017, 2, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Canizo, M.; Onieva, E.; Conde, A.; Charramendieta, S.; Trujillo, S. Real-time predictive maintenance for wind turbines using Big Data frameworks. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Saadeh, H.; Almobaideen, W.; Sabri, K.E. Internet of Things: A review to support IoT architecture’s design. In Proceedings of the 2017 IEEE 2nd International Conference on the Applications of Information Technology in Developing Renewable Energy Processes & Systems (IT-DREPS), Amman, Jordan, 6–7 December 2017. [Google Scholar] [CrossRef]
- Martín-Lopo, M.M.; Boal, J.; Sánchez-Miralles, Á. A literature review of IoT energy platforms aimed at end users. Comput. Netw. 2020, 171, 107101. [Google Scholar] [CrossRef]
- Hou, L.; Zhao, S.; Xiong, X.; Zheng, K.; Chatzimisios, P.; Hossain, M.S.; Xiang, W. Internet of Things Cloud: Architecture and Implementation. IEEE Commun. Mag. 2016, 54, 32–39. [Google Scholar] [CrossRef] [Green Version]
- Rautmare, S.; Bhalerao, D.M. MySQL and NoSQL database comparison for IoT application. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; pp. 235–238. [Google Scholar] [CrossRef]
- Richardson, D.P.; Lin, A.C.; Pecarina, J.M. Hosting distributed databases on internet of things-scale devices. In Proceedings of the 2017 IEEE Conference on Dependable and Secure Computing, Taipei, Taiwan, 7–10 August 2017; pp. 352–357. [Google Scholar] [CrossRef]
- Jesus, R.; Antunes, M.; Gomes, D.; Aguiar, R.L. Modelling Patterns in Continuous Streams of Data. Open J. Big Data (OJBD) 2018, 4, 1–13. [Google Scholar]
- Chen, F.; Deng, P.; Wan, J.; Zhang, D.; Vasilakos, A.V.; Rong, X. Data Mining for the Internet of Things: Literature Review and Challenges. Int. J. Distrib. Sens. Netw. 2015, 11, 431047. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.; Nkenyereye, L.; Sung, N.; Song, J. Towards a Blockchain-enabled IoT Platform using oneM2M Standards. In Proceedings of the IEEE 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 17–19 October 2018. [Google Scholar] [CrossRef]
- Zivic, N.; Ruland, C.; Sassmannshausen, J. Distributed Ledger Technologies for M2M Communications. In Proceedings of the IEEE 2019 International Conference on Information Networking (ICOIN), Kuala Lumpur, Malaysia, 9–11 January 2019. [Google Scholar] [CrossRef]
- Tseng, L.; Yao, X.; Otoum, S.; Aloqaily, M.; Jararweh, Y. Blockchain-based database in an IoT environment: Challenges, opportunities, and analysis. Clust. Comput. 2020, 23, 2151–2165. [Google Scholar] [CrossRef]
- Gurusamy, V.; Kannan, S.; Nandhini, K. The Real Time Big Data Processing Framework Advantages and Limitations. Int. J. Comput. Sci. Eng. 2017, 5, 305–312. [Google Scholar] [CrossRef]
- Dittrich, J.; Quiané-Ruiz, J.A. Efficient Big Data Processing in Hadoop MapReduce. Proc. VLDB Endow. 2012, 5, 2014–2015. [Google Scholar] [CrossRef] [Green Version]
- Kala Karun, A.; Chitharanjan, K. A review on hadoop—HDFS infrastructure extensions. In Proceedings of the 2013 IEEE Conference on Information Communication Technologies, Thuckalay, India, 11–12 April 2013; pp. 132–137. [Google Scholar] [CrossRef]
- Melnik, S.; Gubarev, A.; Long, J.J.; Romer, G.; Shivakumar, S.; Tolton, M.; Vassilakis, T. Dremel: Interactive Analysis of Web-Scale Datasets. Commun. ACM 2011, 54, 114–123. [Google Scholar] [CrossRef]
- Mishra, S.; Hota, C. A REST Framework on IoT Streams using Apache Spark for Smart Cities. In Proceedings of the 2019 IEEE 16th India Council International Conference (INDICON), Rajkot, India, 13–15 December 2019. [Google Scholar] [CrossRef]
- Vikash; Mishra, L.; Varma, S. Performance evaluation of real-time stream processing systems for Internet of Things applications. Future Gener. Comput. Syst. 2020, 113, 207–217. [Google Scholar] [CrossRef]
- Katsifodimos, A.; Schelter, S. Apache Flink: Stream Analytics at Scale. In Proceedings of the 2016 IEEE International Conference on Cloud Engineering Workshop (IC2EW), Berlin, Germany, 4–8 April 2016; p. 193. [Google Scholar] [CrossRef]
- Noghabi, S.A.; Paramasivam, K.; Pan, Y.; Ramesh, N.; Bringhurst, J.; Gupta, I.; Campbell, R.H. Samza: Stateful Scalable Stream Processing at LinkedIn. Proc. VLDB Endow. 2017, 10, 1634–1645. [Google Scholar] [CrossRef]
- Yang, F.; Tschetter, E.; Léauté, X.; Ray, N.; Merlino, G.; Ganguli, D. Druid: A Real-Time Analytical Data Store. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (SIGMOD ’14), Snowbird, UT, USA, 22–27 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 157–168. [Google Scholar] [CrossRef]
- Szafir, D.A. The good, the bad, and the biased: Five ways visualizations can mislead (and how to fix them). Interactions 2018, 25, 26–33. [Google Scholar] [CrossRef]
- Ali, S.M.; Gupta, N.; Nayak, G.K.; Lenka, R.K. Big data visualization: Tools and challenges. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Noida, India, 14–17 December 2016; pp. 656–660. [Google Scholar] [CrossRef]
- Bentaleb, O.; Belloum, A.S.Z.; Sebaa, A.; El-Maouhab, A. Containerization technologies: Taxonomies, applications and challenges. J. Supercomput. 2021, 1–38. [Google Scholar] [CrossRef]
- Fazio, M.; Celesti, A.; Ranjan, R.; Liu, C.; Chen, L.; Villari, M. Open Issues in Scheduling Microservices in the Cloud. IEEE Cloud Comput. 2016, 3, 81–88. [Google Scholar] [CrossRef]
- Rufino, J.; Alam, M.; Ferreira, J.; Rehman, A.; Tsang, K.F. Orchestration of containerized microservices for IIoT using Docker. In Proceedings of the 2017 IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, 22–25 March 2017; pp. 1532–1536. [Google Scholar] [CrossRef]
- Khazaei, H.; Bannazadeh, H.; Leon-Garcia, A. SAVI-IoT: A Self-Managing Containerized IoT Platform. In Proceedings of the 2017 IEEE 5th International Conference on Future Internet of Things and Cloud (FiCloud), Prague, Czech Republic, 21–23 August 2017; pp. 227–234. [Google Scholar] [CrossRef]
- Hashemipour, S.; Ali, M. Amazon Web Services (AWS)—An Overview of the On-Demand Cloud Computing Platform. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer International Publishing: New York, NY, USA, 2020; pp. 40–47. [Google Scholar] [CrossRef]
- Jukic, O.; Hedi, I.; Cirikovic, E. IoT cloud-based services in network management solutions. In Proceedings of the IEEE 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020. [Google Scholar] [CrossRef]
- Nakhuva, B.; Champaneria, T. Study of Various Internet of Things Platforms. Int. J. Comput. Sci. Eng. Surv. 2015, 6, 61–74. [Google Scholar] [CrossRef]
- Mahmud, M.A.; Bates, K.; Wood, T.; Abdelgawad, A.; Yelamarthi, K. A complete Internet of Things (IoT) platform for Structural Health Monitoring (SHM). In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018. [Google Scholar] [CrossRef]
- Pasha, S. ThingSpeak based sensing and monitoring system for IoT with Matlab Analysis. Int. J. New Technol. Res. 2016, 2, 19–23. [Google Scholar]
- Pierleoni, P.; Concetti, R.; Belli, A.; Palma, L. Amazon, Google and Microsoft Solutions for IoT: Architectures and a Performance Comparison. IEEE Access 2020, 8, 5455–5470. [Google Scholar] [CrossRef]
- Forsström, S.; Jennehag, U. A performance and cost evaluation of combining OPC-UA and Microsoft Azure IoT Hub into an industrial Internet-of-Things system. In Proceedings of the 2017 Global Internet of Things Summit (GIoTS), Geneva, Switzerland, 6–9 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Friedow, C.; Völker, M.; Hewelt, M. Integrating IoT Devices into Business Processes. In Lecture Notes in Business Information Processing; Springer International Publishing: New York, NY, USA, 2018; pp. 265–277. [Google Scholar] [CrossRef]
- De la Bastida, D.; Lin, F.J. OpenStack-Based Highly Scalable IoT/M2M Platforms. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017. [Google Scholar] [CrossRef]
- Chen, H.L.; Lin, F.J. Scalable IoT/M2M Platforms Based on Kubernetes-Enabled NFV MANO Architecture. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019. [Google Scholar] [CrossRef]
- Cai, H.; Xu, B.; Jiang, L.; Vasilakos, A.V. IoT-Based Big Data Storage Systems in Cloud Computing: Perspectives and Challenges. IEEE Internet Things J. 2017, 4, 75–87. [Google Scholar] [CrossRef]
- Antunes, M.; Gomes, D.; Aguiar, R.L. Scalable semantic aware context storage. Future Gener. Comput. Syst. 2015, 56, 675–683. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, J.; Fonseca, J.; Gomes, D.; Barraca, J.; Fernandes, B.; Rufino, J.; Almeida, J.; Aguiar, R. PASMO: An open living lab for cooperative ITS and smart regions. In Proceedings of the 2017 International Smart Cities Conference (ISC2), Wuxi, China, 14–17 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ferreira, J.; Alam, M.; Fernandes, B.; Silva, L.; Almeida, J.; Moura, L.; Costa, R.; Iovino, G.; Cordiviola, E. Cooperative sensing for improved traffic efficiency: The highway field trial. Comput. Netw. 2018, 143, 82–97. [Google Scholar] [CrossRef]
- Almeida, J.; Rufino, J.; Cardoso, F.; Gomes, M.; Ferreira, J. TRUST: Transportation and Road Monitoring System for Ubiquitous Real-Time Information Services. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–7. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Broker | Advantages | Disadvantages |
|---|---|---|
| Mosquitto | Message Queuing Telemetry Transport (MQTT) Message Broker; Lightweight | Protocol limitation |
| RabbitMQ | Multi-protocol broker; Easy to scale | Limited features for IoT |
| Hono | Multi-protocol broker; Queues with different semantic | Computationally heavy |
| TS Database | Advantages | Disadvantages |
|---|---|---|
| InfluxDB | Fast storage; Time-series data retrieval | Limited scalability |
| TimescaleDB | SQL scalability; Easy interpretation | Large time-based queries |
| OpenTSDB | Scalability; Storage as a server | Hadoop knowledge |
| Redis | Wide variety of data types; Open source | No joins operations or conventional queries |
| MongoDB | BSON document as a unit; Horizontal scalability | Non-indexed queries; Hardware requirements |
| Apache Cassandra | Fault-tolerant; Linear scalability | No unanticipated queries |
| MapR Database | High-performance; Analytic capabilities | Non-indexed queries |
| Framework | Main Characteristics | Useful Scenarios |
|---|---|---|
| Hadoop MapReduce [23] | Independent clusters | Large amounts of data |
| Hadoop HDFS [24] | Intermediate results | Shared repository of data |
| Google Dremel [25] | Reduces the CPU overhead | Multiple features |
| Framework | Main Characteristics | Useful Scenarios |
|---|---|---|
| Apache Spark [26] | Supports Lambda architecture | Applications with diverse data sources |
| Apache Storm [27] | Unbounded streams of data | Real time analytics |
| Apache Flink [28] | Unbounded and bounded data | Fault-tolerant applications |
| Apache Samza [29] | Multiple streams | Fault tolerance and buffering |
| Apache Druid [30] | Real-time analytics on large datasets | Clusters with several nodes |
| TS Database | Advantages | Disadvantages |
|---|---|---|
| Grafana | Several time-series data storage; Allow notifications and alerts | Full-text data querying not permitted |
| Kibana | Data querying and analysis; Several data representations | Work only with Elasticsearch |
| Graphite | Highly scalable; Render on demand | Specific database |
| Prometheus | Multi-dimensional data model; Flexible query language | Not viable for anomaly detection |
| CPU | Memory | Disk | ||||
|---|---|---|---|---|---|---|
| Cores | Load (%) | Total (GB) | Load (GB) | Total (GB) | Load (GB) | |
| manager-0 | 4 | 1.86 | 8 | 7.03 | 32 | 3.57 |
| manager-1 | 4 | 1.67 | 8 | 6.04 | 32 | 2.68 |
| manager-2 | 4 | 3.36 | 8 | 6.86 | 32 | 4.35 |
| worker-0 | 4 | 1.87 | 16 | 3.79 | 40 | 3.50 |
| worker-1 | 4 | 1.70 | 16 | 3.03 | 40 | 1.43 |
| worker-2 | 4 | 1.60 | 16 | 3.72 | 40 | 3.82 |
| worker-3 | 4 | 2.28 | 16 | 6.94 | 40 | 3.33 |
| worker-4 | 4 | 1.65 | 16 | 4.07 | 40 | 8.52 |
| nfs-server | 4 | 1.42 | 8 | 2.98 | 32 | 1.56 |
| postgres | 8 | 0.71 | 16 | 1.99 | 160 | 48.70 |
| influxdb | 8 | 1.28 | 16 | 4.12 | 160 | 3.20 |
| cassandra-0 | 4 | 1.63 | 16 | 31.85 | 100 | 9.50 |
| cassandra-1 | 4 | 1.94 | 16 | 32.29 | 100 | 13.16 |
| cassandra-2 | 4 | 1.95 | 16 | 31.49 | 100 | 10.98 |
| cassandra-3 | 4 | 2.18 | 16 | 32.07 | 100 | 13.24 |
| Probe | Latency (Seconds) |
|---|---|
| Bridge | |
| Ditto | |
| Sensor |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Antunes, M.; Santiago, A.R.; Manso, S.; Regateiro, D.; Barraca, J.P.; Gomes, D.; Aguiar, R.L. Building an IoT Platform Based on Service Containerisation. Sensors 2021, 21, 6688. https://doi.org/10.3390/s21196688
Antunes M, Santiago AR, Manso S, Regateiro D, Barraca JP, Gomes D, Aguiar RL. Building an IoT Platform Based on Service Containerisation. Sensors. 2021; 21(19):6688. https://doi.org/10.3390/s21196688
Chicago/Turabian StyleAntunes, Mário, Ana Rita Santiago, Sérgio Manso, Diogo Regateiro, João Paulo Barraca, Diogo Gomes, and Rui L. Aguiar. 2021. "Building an IoT Platform Based on Service Containerisation" Sensors 21, no. 19: 6688. https://doi.org/10.3390/s21196688
APA StyleAntunes, M., Santiago, A. R., Manso, S., Regateiro, D., Barraca, J. P., Gomes, D., & Aguiar, R. L. (2021). Building an IoT Platform Based on Service Containerisation. Sensors, 21(19), 6688. https://doi.org/10.3390/s21196688