1. Introduction
There have been many statistical studies aimed at discovering correlations or relationships between certain factors (i.e., features, variables) and post-operative adverse outcomes (e.g., mortality, respiratory failure). For example, Colin P. Dunn et al. conducted statistical tests to compare risk assessment tools for predicting adverse cardiac events in kidney transplant patients [
1]. James P. Wick et al. proposed an assessment tool for predicting 6-month mortality after dialysis initiation [
2]; they used a logistic regression (LR) model to find potential variables associated with 6-month mortality. In [
3], the surgical complexity score was developed by checking the Area under the ROC Curve (AUC) with various settings of the LR model. Yue Li et al. found risk factors of post-operative cardiopulmonary complications by retrospective analysis of 653 lung-cancer surgery cases [
4]. These studies commonly utilized the LR model, but the LR model was used as a measuring tool, not a predictor; in other words, their major contribution was to discover promising variables (or features) related to adverse outcomes, and the LR model was used as a verification tool. Some studies investigated first-hitting-time models for uncertainty analysis and clinical purposes (e.g., estimated time to infection for burn patients) [
5,
6]. As described in [
7], although these statistical studies uncovered a large amount of useful information, they are still practically limited because they are not suitable for developing real-world applications (e.g., forecasting post-operative outcomes).
End stage renal disease (ESRD) is a loss of renal function for 3 or more months, and is the last stage of chronic kidney disease that requires dialysis or a kidney transplant to survive. Most of these patients have multiple comorbidities including anemia, cardiovascular disease, and diabetes mellitus. Considering their severe comorbidities, patients with ESRD have significantly high perioperative risks. Indeed, the literature consistently demonstrated a higher risk of mortality in ESRD patients compared with patients without ESRD, both in the cardiac and noncardiac perioperative periods [
8,
9,
10,
11,
12,
13,
14]. Across various types of noncardiac surgery, patients with chronic kidney disease had two- to tenfold higher risks of postoperative death and cardiovascular events than those with normal kidney function [
15,
16,
17,
18]. Additionally, these patients have difficulties in terms of management for hemodynamic stability; this is because of their high morbidity and frailty. As such, the prediction of postoperative complications is important regarding perioperative management and reducing these complications. Methods to estimate individual risk are needed to provide individualized care and manage ESRD populations. Many mortality prediction models exist but they have shown deficiencies in model development (e.g., data comprehensiveness, validation) and in practicality. Therefore, we aim to design easy-to-apply prediction models for postoperative complications in ESRD patients. Postoperative adverse cardiac events are a major cause of morbidity and mortality in patients after non-cardiac surgery [
19,
20]. Therefore, predicting the risk is important in reducing these complications. The purpose of this study is to make a proper models for predicting postoperative major cardiac event (MACE) in ESRD patients undergoing general anesthesia.
Data-driven models are used in many fields such as face recognition, intent prediction of dialog systems, and speech recognition. The most widely-used data-driven models are logistic regression (LR), support vector machine (SVM) [
21], decision tree, random forest (RF) [
22], naive Bayes (NB), artificial neural network (ANN), and extreme gradient boosting (XGB) [
23]). These machine learning models learn from data and have shown successful performance in various medical fields. For example, Katiuscha Merath et al. predicted patient risk of post-operative complications (e.g., cardiac, stroke, wound dehiscence, etc.) using a decision tree, and achieved about 0.74∼0.98 C-statistics [
24]. In [
25], ANN and LR models were used to predict post-operative complications (e.g., cardiac, mortality, etc.), and achieved about 0.54∼0.84 AUC with a 95% confidence interval (CI). Paul Thottakkara et al. compared four models (SVM, generalized additive model (GAM), NB, and LR) for risk prediction of some post-operative complications (e.g., acute kidney injury, severe sepsis) [
26], and the SVM had the best results of 77.7∼85.0% accuracy with 95% CI. YiMing Chen et al. compared five models (SVM, RF, rotation forest (RoF), bayesian network (BN), and NB) to predict post-operative complications (e.g., wound infection, free flap infection, etc.), and found that the RF gave the best accuracy of 89.084% [
27]. In [
28], XGB was employed to predict complications after pediatric cardiac surgery and achieved about 0.82 AUC. Christine K. Lee et al. designed a deep neural network (DNN), which is an artificial neural network with many layers for prediction of post-operative mortality [
29]; the proposed DNN consists of 4 layers with 300 nodes followed by ReLU activation functions [
30]. In [
31], to predict complications after bariatric surgery, the authors used three deep learning models: deep neural networks, convolutional neural networks (CNN) [
32], and recurrent neural networks (RNN) [
33]. Their dataset was extremely biased, so the three networks exhibited very poor sensitivities (e.g., 0.06∼0.23). Surprisingly, a recent study reported that using machine learning models were even more accurate than human clinicians [
34]. In this paper, we adopt various promising machine learning models to predict postoperative MACE in ESRD patients undergoing general anesthesia.
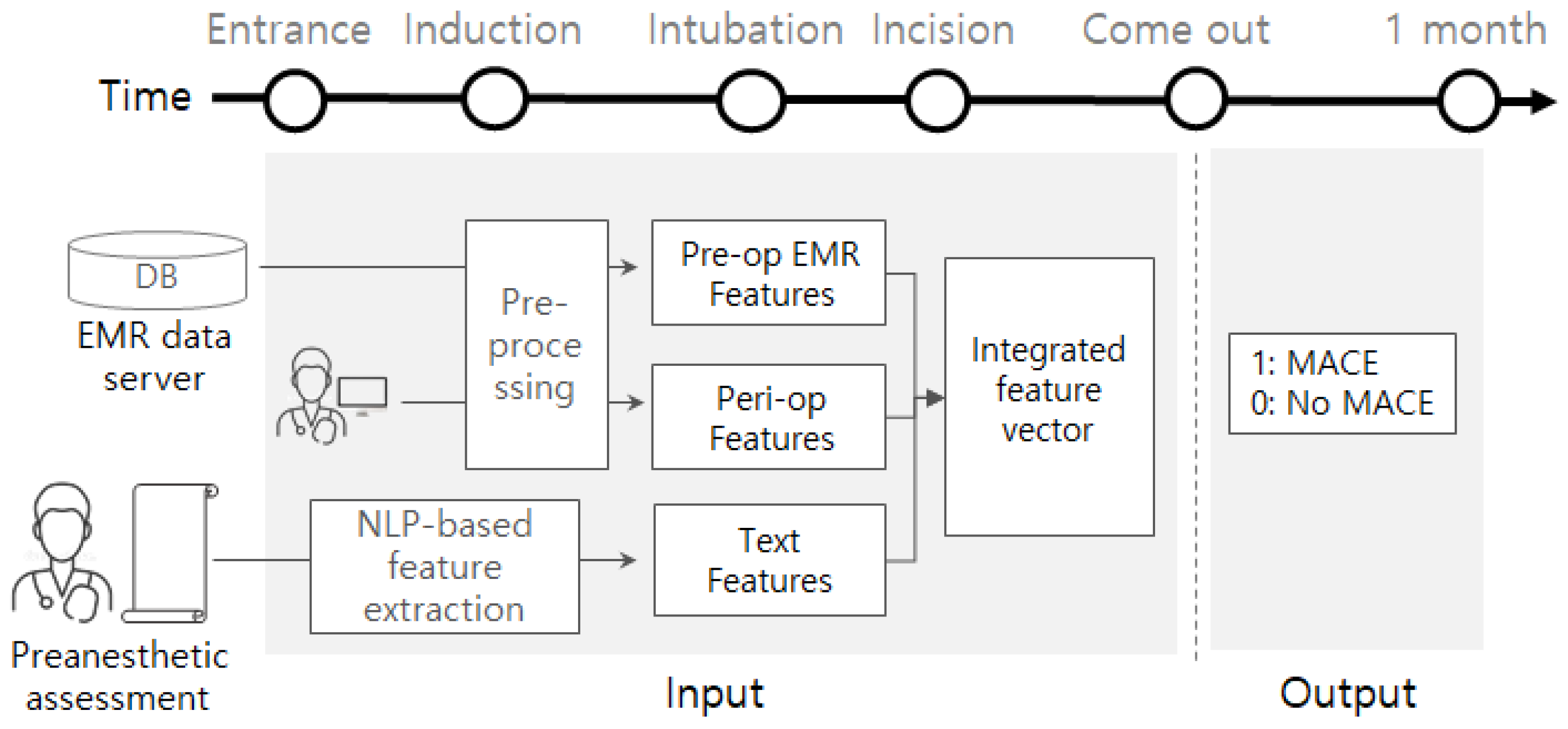
Our contributions can be summarized as follows. First, as far as we know, this is the first study to predict post-operative MACE in patients with ESRD using various machine learning models. The machine learning models used in this paper are the most widely-used models for various tasks (e.g., image analysis, speech recognition, text analysis, and healthcare applications), so we compare the models experimentally and find the most effective one. Second, we suggest carefully designed feature groups, and examine how much impact each has on the performance. We implement a tool of natural language processing (NLP) to extract informative clues from preanesthetic assessment documents written by clinicians before surgery. We also examine combinations of feature groups and try feature selection algorithms. Note that the features are collected from several different sources: devices (or sensors), electronic medical record (EMR), and documents. Therefore, this study aims at applying machine learning techniques to data collected from different sources to develop a medical application. We believe that the results of this study eventually help physicians to make better medical decisions so that the survival rate of patients will be increased.
3. Results
The total amount of data in the original dataset
is 3220. We found that the
is highly imbalanced; the ratio of MACE versus Not-MACE was almost 1:10. To settle this, we generated a balanced dataset by downsampling from
, so we got a label ratio of 1:1 as a result. As the downsampling from
is performed randomly, we prepared three independently downsampled datasets,
,
, and
. Each of the three datasets is further divided into three sets: training, validation, and test sets, while approximately maintaining the balanced label ratio. The statistics of each dataset are summarized in
Table 4.
We compared several machine learning models according to precision, recall, and F1 score. The models are implemented using scikit-learn package (
https://scikit-learn.org/). Every model is trained using the training dataset, and its parameter is tuned using the validation dataset. The parameter settings of
Table 5 are found by grid searching, which generally gave the best F1 score. The numerical attributes are scaled between 0 and 1, where the maximum and minimum values are extracted from the training dataset. We performed three independent experiments using the three downsampled datasets. Some machine learning models (e.g., ANN, RF) may give different results even if the same data are given, because of the parameter initialization method or ensemble process (e.g., random sampling).
Thus, we conducted 10 experiments for each of the sampled datasets (, , and ), and all results are thus a weighted average of 3 × 10 experiments.
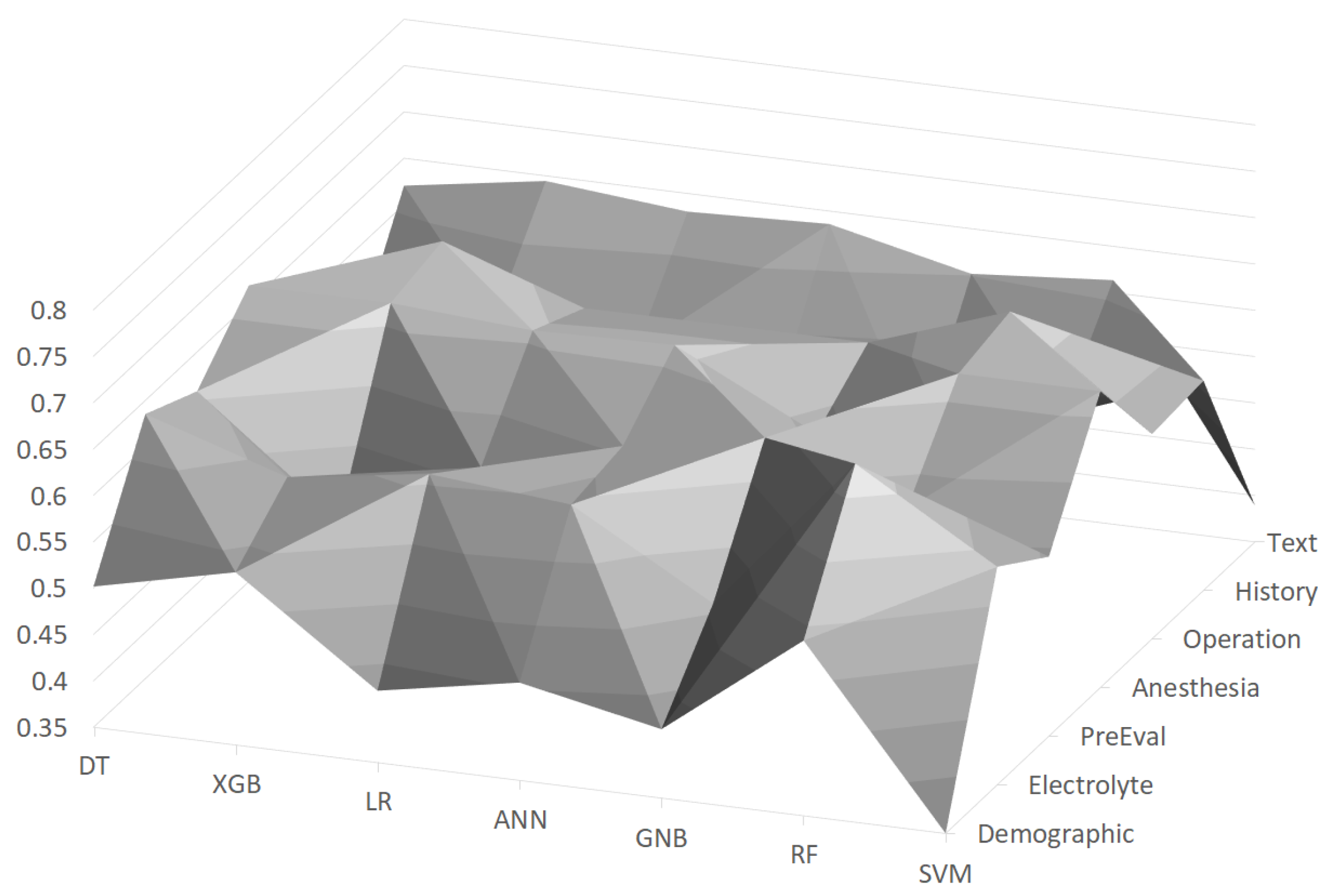
In
Figure 2, F1 scores using the machine learning models with feature groups are depicted as a surface chart, where the scores are distributed between about 0.4∼0.65. It turned out that the
Operation feature group is the most important among the feature groups, and the random forest (RF) achieved the best F1 score of 0.684 with this feature group. On the other hand, the
Demographic feature group generally turned out to be the worst feature group, as about half of the machine learning models gave low scores (e.g., lower than 0.45). The random forest (RF) was generally the best with almost all feature groups, and its F1 score ranged between 0.539 and 0.684.
We tried several combinations of feature groups as shown in
Table 6. We can interpret the results from two perspectives: the perspective of feature combinations and the model-wise perspective. In terms of the feature combination perspective, we found that a combination of feature groups is much better than a single feature group. For example, the
Demographic feature group alone was the worst among the feature groups, but using it with the
Electrolyte feature group improved the F1 score about 0.7. We also found that a combination of more feature groups generally had better performance than that with fewer feature groups; for example,
is better than
. However, using all feature groups did not help to improve the performance, and the most effective combination was
. In the model-wise perspective, the RF model generally gave the best performance with all combinations. The best F1 score of 0.797 was achieved by the RF model with the feature group combination
.
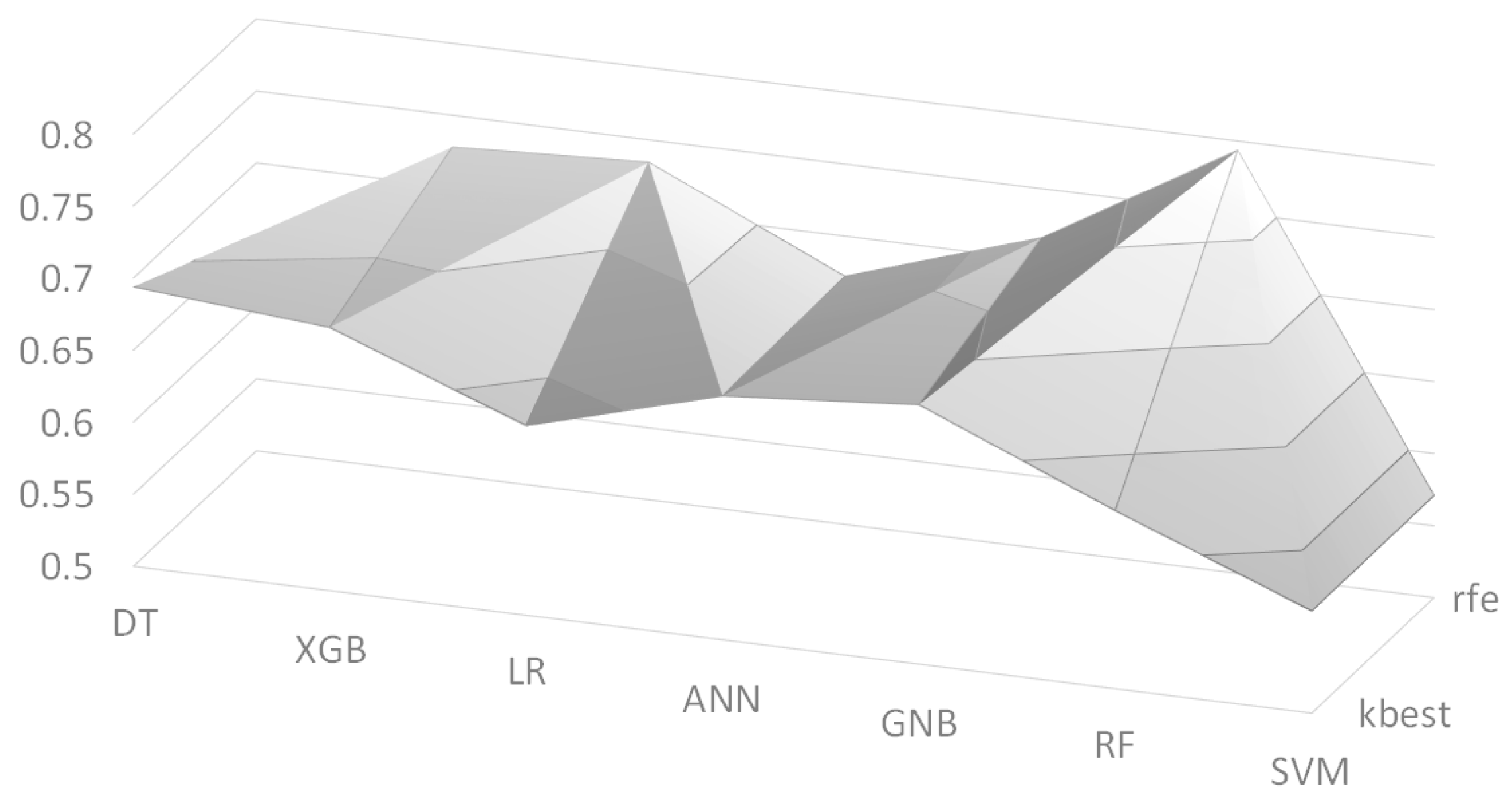
We also employed two feature selection algorithms: Recursive Feature Elimination (RFE) and K-best. We set the number of selected features to K = 30, and its F1 scores are depicted in
Figure 3 as a surface chart, where ‘kbest’ and ‘rfe’ indicate the K-best algorithm and the RFE algorithm, respectively. The RF model with the RFE algorithm had the best F1 score of 0.672 among the models.
Table 7 shows the list of selected features by the two feature selection algorithms. As we performed three independent experiments, the list contains only features that appeared in at least two experiments. The two algorithms selected quite different features, but they commonly picked many features from two feature groups:
Operation and
Anesthesia. It is interesting that from the
Text feature group, the ‘T3’ values of the thyroid gland function test (TFT) were commonly chosen by the two algorithms. This is consistent with the recent work [
37] that found that low ‘T3’ values are associated with poor prognosis; although the target patients of this work are different, we can say that the feature selection algorithms picked reasonable features from the
Text feature group. Another interesting point is that ‘hasText’ feature was picked by the K-best algorithm, where this feature simply indicates whether the preanesthetic assessment document has content or not. This can be explained that the clinicians usually write the preanesthetic assessment when there are any important issues regarding the patients so that ‘hasText’ could be an indicator of important issues.
4. Discussion
We found that the best feature group is
Operation by experimental results. This is consistent with existing studies on predictors of postoperative cardiac events in patients undergoing non-cardiac surgery. For example, Myung Hwan Bae et al. investigated whether surgical parameters have prognostic value with respect to the development of a postoperative cardiac event [
38]. They concluded that the surgical parameters, including surgery time and blood transfusion during surgery, were found to be independent predictors of postoperative MACE in patients undergoing non-cardiac surgery. Although their experiments included only 4.9% of renal insufficiency (defined as serum creatinine ≥2 mg/dL), this is consistent with our study that the
Operation feature group is the most important for prediction of postoperative MACE in ESRD patients.
Regarding the prediction model, one might argue that it is not very useful if it is not sensitive enough to MACE cases.
Figure 4 shows the precision and recall values of the MACE class (i.e., label ‘1’) using the random forest (RF) model. We found that the RF model has a precision of 0.803 and a recall of 0.794, with the best feature combination of
. With this result, we might say that our prediction model is enough to inform physicians of the potential risk so that the patients will be provided with more appropriate therapy. As there is still plenty of room for improvement, we will keep investigating various methods to obtain better performance.
There are two ways of applying the results of this study to operations. First, the best model of this study (i.e., random forest) is installed onto a computer within the surgery room, where the model provides information about potential MACE right after the end of surgery. Physicians are provided with this information so that the patient will have better suited therapy. Of course, the information is just a predicted result (i.e., probability of potential MACE), so the appropriate medical decisions must be made by the physicians. Second, clinicians carefully check the features that we found important. For example, according to the experimental results, we found that Operation features are the most important and other particular features (e.g., anesthesia method, TFT T3) are informative to the prediction of postoperative MACE.
Although we achieved an F1 score of 0.797 and found some important features for the prediction of postoperative MACE, this study is limited because of the small data size. We are continually collecting more data, and plan to gather data from other sources (i.e., other hospitals); we believe that data collected from different sources will help to verify the generalization of our future model. We also expect that more data will improve the performance (i.e., greater F1 score) of data-driven prediction models.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}