
InterNet+: A Light Network for Hand Pose Estimation


Abstract
:1. Introduction
- We redesigned a feature extractor based on deep neural networks to replace the simpler ResNet-50 [14] backbone architecture in the original network and continue to ensure the overall lightweight of the network. We refer to the architecture design of MobileNet v3 [15] and MoGA [16] network and introduce the inverted residual block, Hsigmoid, and Hswish activation functions [15,17]. The latest coordinate attention mechanism [18] is introduced in the bottleneck structure and part of the latest ACON (Activation or Not, can choose the linear or non-linear structure with self-learning) activation function [19];
- We introduced the multi-spectral attention mechanism named FcaNet [20] to process the obtained feature maps before fully connected network in order to retain more frequent domain information to improve the performance;
- We tried to improve the overall training procedure of the network to obtain more information from the available data.
2. Related Work
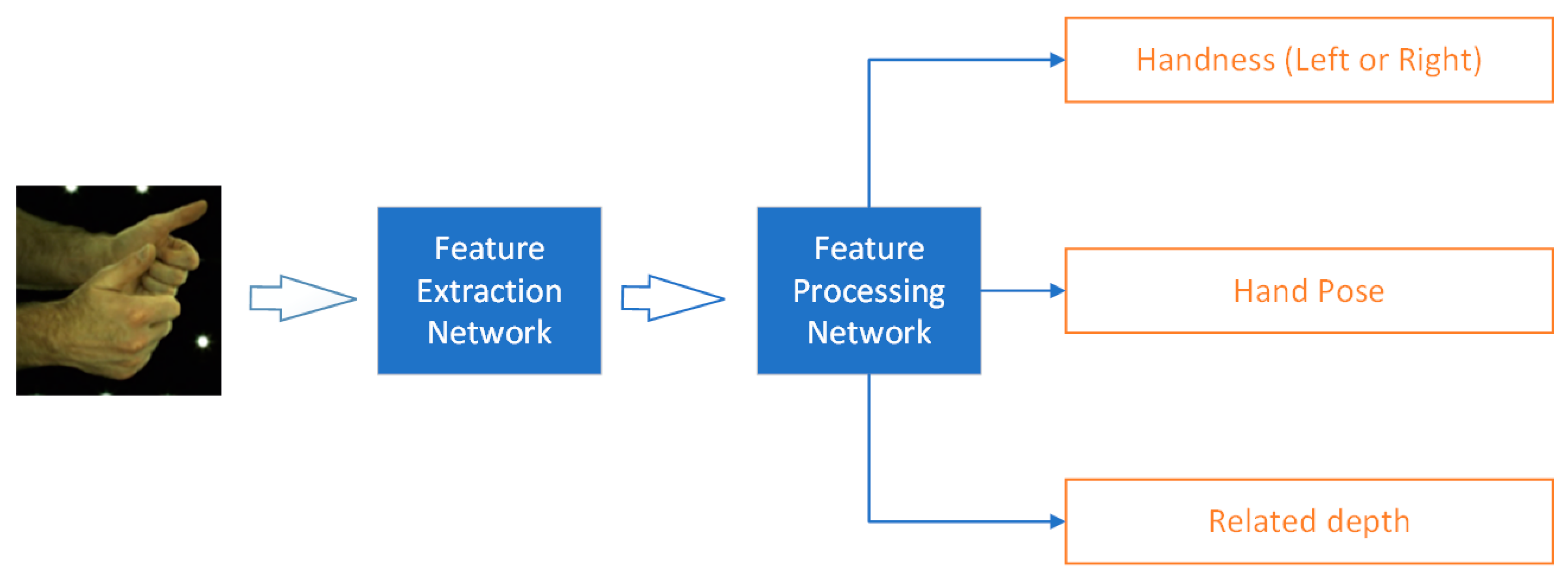
3. Original InterNet
3.1. Network Structure
3.2. Data Annotation
4. InterNet+
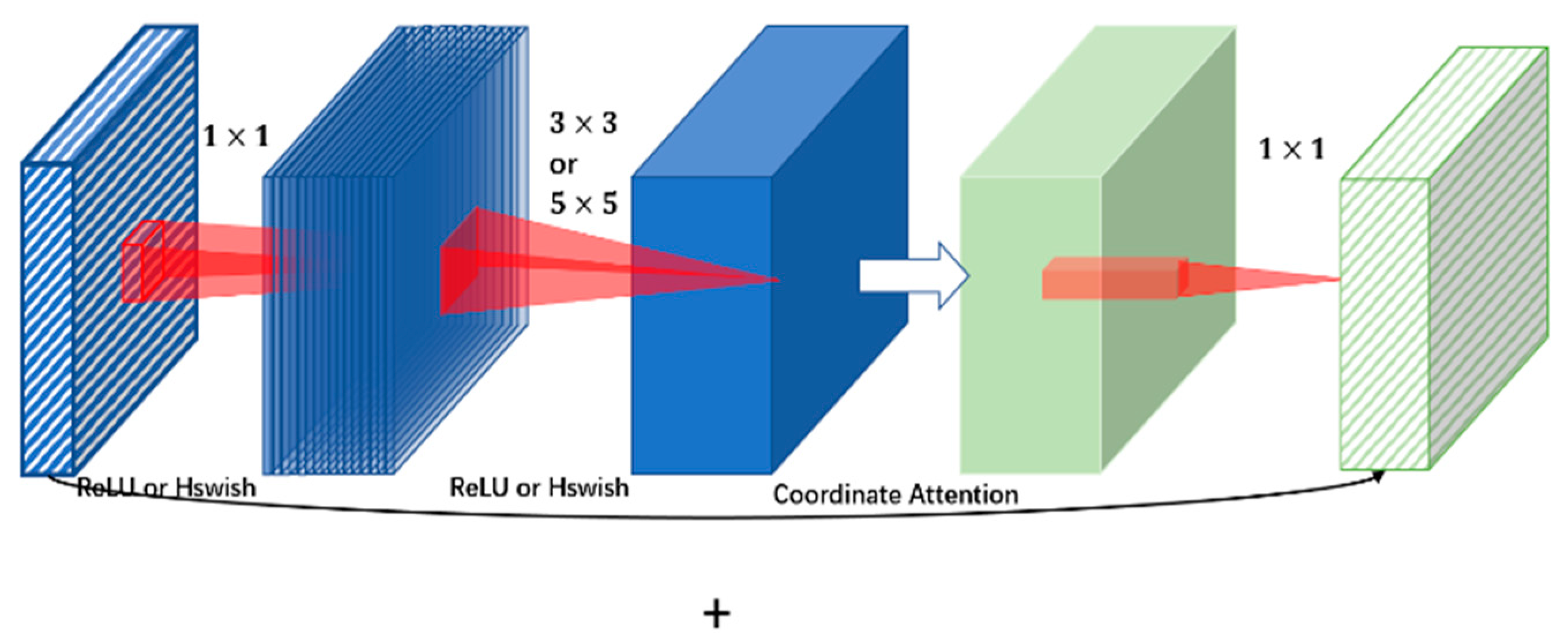
4.1. Redesigned Feature Extraction Network
4.1.1. Inverted Residual Block
4.1.2. Coordinate Attention Mechanism
4.1.3. ACON Activation Function
4.2. Processing of the Feature Maps
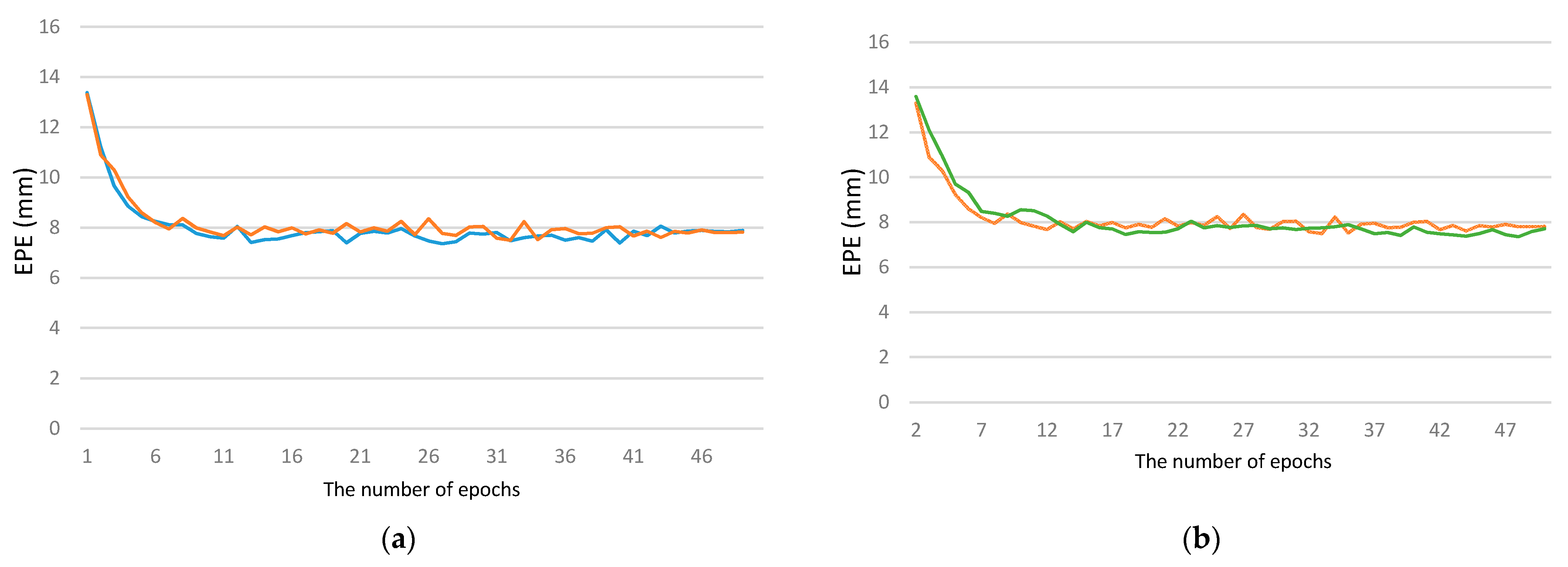
4.3. Effective Way of Network Training
5. Experiment
5.1. Datasets
5.1.1. STB Dataset
5.1.2. RHD Dataset
5.1.3. InterHand2.6M Dataset (5fps/30fps)
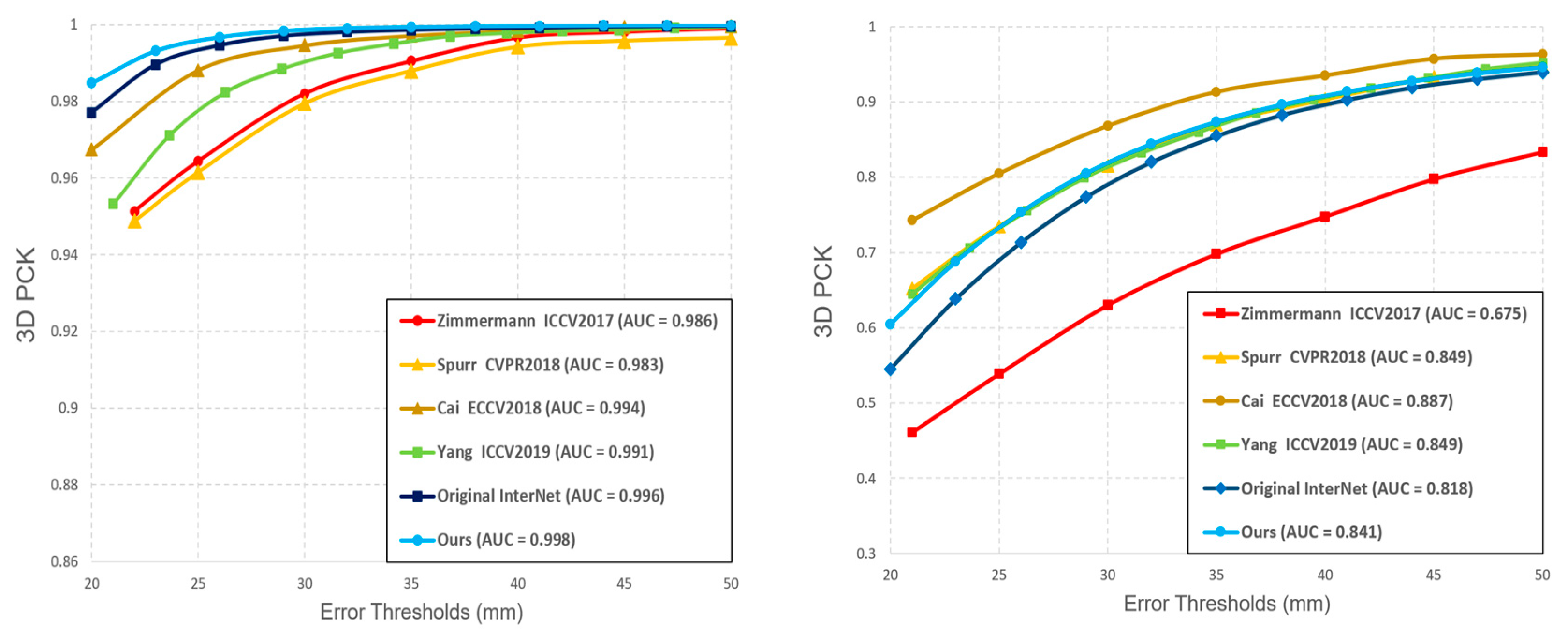
5.2. Experimental Environment and Results
5.3. Ablation Analysis
5.3.1. Coordinate Attention Mechanism Module
5.3.2. Processing of Feature Map by Using the FcaNet Layer
6. Discussion and Outlook
- The development of feature extraction backbone. Recently, scholars have re-examined the widely used convolutional neural network backbones such as ResNet, made new improvements, and targeted adjustments to training strategies [42]. These improvements will help the development of many tasks in the field of computer vision, including hand pose estimation;
- The rise of Transformer in the field of computer vision [43]. Previously, Transformer was mostly used in fields such as natural language processing [44]. Since its introduction into the field of computer vision, it has demonstrated amazing capabilities in a variety of visual tasks, such as segmentation and classification. At present, visual Transformer has been introduced into the field of attitude estimation [45]. Therefore, the modified visual Transformer may bring greater changes in the field of hand posture estimation and overall changes in the network architecture;
- Considering the data acquisition for hand posture estimation, scholars are gradually replacing manual labeling with automatic or semi-automatic methods. Using neural networks and other learning models for more accurate labeling can help reduce the workload caused by manual labeling.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, S.; Zhang, L.; Shen, Y.; Zhao, S.; Zhang, H. Super-resolution for monocular depth estimation with multi-scale sub-pixel convolutions and a smoothness constraint. IEEE Access 2019, 7, 16323–16335. [Google Scholar] [CrossRef]
- Chatzis, T.; Stergioulas, A.; Konstantinidis, D.; Dimitropoulos, K.; Daras, P. A comprehensive study on deep learning-based 3D hand pose estimation methods. Appl. Sci. 2020, 10, 6850. [Google Scholar] [CrossRef]
- Doosti, B. Hand Pose Estimation: A Survey. arXiv 2019, arXiv:1903.01013. [Google Scholar]
- Oberweger, M.; Lepetit, V. DeepPrior++: Improving Fast and Accurate 3D Hand Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, Z.; Xie, S.; Chen, M.; Zhu, H. Hand Augment: A Simple Data Augmentation Method for Depth-Based 3D Hand Pose Estimation. arXiv 2001, arXiv:2001.00702. [Google Scholar]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-time continuous pose recovery of human hands using convolutional networks. ACM Trans. Graph. 2014, 33, 169. [Google Scholar] [CrossRef]
- Rong, Z.; Kong, D.; Wang, S.; Yin, B. RGB-D Hand Pose Estimation Using Fourier Descriptor. In Proceedings of the 2018 7th International Conference on Digital Home (ICDH), Guilin, China, 30 November–1 December 2018. [Google Scholar]
- Moon, G.; Yu, S.-I.; Wen, H.; Shiratori, T.; Lee, K.M. InterHand2.6M: A dataset and baseline for 3D interacting hand pose estimation from a single RGB image. In Computer Vision–ECCV 2020 (Lecture Notes in Computer Science); Springer: Berlin/Heidelberg, Germany, 2020; pp. 548–564. [Google Scholar]
- Ge, L.; Ren, Z.; Li, Y.; Xue, Z.; Wang, Y.; Cai, J.; Yuan, J. 3D Hand Shape and Pose Estimation from a Single RGB Image. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yang, L.; Li, S.; Lee, D.; Yao, A. Aligning Latent Spaces for 3D Hand Pose Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Zimmermann, C.; Brox, T. Learning to Estimate 3D Hand Pose from Single RGB Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. 3D Hand Pose Tracking and Estimation Using Stereo Matching. arXiv 2016, arXiv:1610.07214. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3D hand pose estimation from single depth images using multi-view CNNs. IEEE Trans. Image Process. 2018, 27, 4422–4436. [Google Scholar] [CrossRef] [PubMed]
- Hy, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pan, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Chu, X.; Zhang, B.; Xu, R. MoGA: Searching beyond MobileNetV3. arXiv 2019, arXiv:1908.01314. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Ma, N.; Zhang, X.; Sun, J. Activate or Not: Learning Customized Activation. arXiv 2020, arXiv:2009.04759. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FcaNet: Frequency Channel Attention Networks. arXiv 2020, arXiv:2012.11879. [Google Scholar]
- Liu, Y.; Jiang, J.; Sun, J. Hand Pose Estimation from RGB Images Based on Deep Learning: A Survey. In Proceedings of the 2021 IEEE 7th International Conference on Virtual Reality (ICVR), Foshan, China, 20–22 May 2021. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands Deep in Deep Learning for Hand Pose Estimation. arXiv 2015, arXiv:1502.06807. [Google Scholar]
- Chang, J.Y.; Moon, G.; Lee, K.M. V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhu, T.; Sun, Y.; Ma, X.; Lin, X. Hand Pose Ensemble Learning Based on Grouping Features of Hand Point Sets. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Cai, Y.; Ge, L.; Cai, J.; Yuan, J. Weakly-supervised 3D hand pose estimation from monocular RGB images. In Computer Vision–ECCV 2018 (Lecture Notes in Computer Science); Springer: Berlin/Heidelberg, Germany, 2018; pp. 678–694. [Google Scholar]
- Li, M.; Gao, Y.; Sang, N. Exploiting Learnable Joint Groups for Hand Pose Estimation. arXiv 2020, arXiv:2012.09496. [Google Scholar]
- Chen, X.; Liu, X.; Ma, C.; Chang, J.; Wang, H.; Chen, T.; Guo, X.; Wan, P.; Zheng, W. Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration. arXiv 2021, arXiv:2103.02845. [Google Scholar]
- Chen, Y.; Tu, Z.; Kang, D.; Bao, L.; Zhang, Y.; Zhe, X.; Chen, R.; Yuan, J. Model-based 3D Hand Reconstruction via SELF-Supervised Learning. arXiv 2021, arXiv:2103.11703. [Google Scholar]
- Doosti, B.; Naha, S.; Mirbagheri, M.; Crandall, D.J. HOPE-Net: A Graph-Based Model for Hand-Object Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Chen, Y.; Tu, Z.; Kang, D.; Chen, R.; Bao, L.; Zhang, Z. Joint hand-object 3D reconstruction from a single image with cross-branch feature fusion. IEEE Trans. Image Process. 2021, 30, 4008–4021. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, D.; Blake, C.H.; Nidever, D.; Halverson, S.P. Temporal Variations of Telluric Water Vapor Absorption at Apache Point Observatory; Astronomical Society of the Pacific: San Francisco, CA, USA, 2018; Volume 130, p. 014501. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. A Hand Pose Tracking Benchmark from Stereo Matching. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Yang, L.; Yao, A. Disentangling Latent Hands for Image Synthesis and Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, L.; Lin, S.-Y.; Xie, Y.; Tang, H.; Xue, Y.; Xie, X.; Lin, Y.-Y.; Fan, W. Generating Realistic Training Images Based on Tonality-Alignment Generative Adversarial Networks for Hand Pose Estimation. arXiv 2018, arXiv:1811.09916. [Google Scholar]
- Spurr, A.; Song, J.; Park, S.; Hilliges, O. Cross-Modal Deep Variational Hand Pose Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Bello, I.; Fedus, W.; Du, X.; Cubuk, E.D.; Srinivas, A.; Lin, T.-Y.; Shlens, J.; Zoph, B. Revisiting ResNets: Improved Training and Scaling Strategies. arXiv 2021, arXiv:2103.07579. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; An, X.; Cu, C.; Xu, Y.; et al. A Survey on Visual Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. arXiv 2021, arXiv:2103.10455. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| id | Name | Kernel | Attention | Activation | Dimensionality |
|---|---|---|---|---|---|
| - | Input | - | - | - | 3 × 256 × 256 |
| 1 | First Conv | 3 × 3 | - | Hswish | 16 × 128 × 128 |
| 2 | Separable Conv 1 | 3 × 3 | - | ReLU | 16 × 128 × 128 |
| 3 | Separable Conv 2 | 1 × 1 | - | MetaAconC | 16 × 128 × 128 |
| 4 | Inverted Residual 1 | 5 × 5 | CA 1 | ReLU | 24 × 64 × 64 |
| 5 | Inverted Residual 2 | 3 × 3 | - | ReLU | 24 × 64 × 64 |
| 6 | Inverted Residual 3 | 5 × 5 | CA | ReLU | 40 × 32 × 32 |
| 7 | Inverted Residual 4 | 3 × 3 | - | ReLU | 40 × 32 × 32 |
| 8 | Inverted Residual 5 | 5 × 5 | - | ReLU | 40 × 32 × 32 |
| 9 | Inverted Residual 6 | 5 × 5 | CA | Hswish | 80 × 16 × 16 |
| 10 | Inverted Residual 7 | 5 × 5 | - | Hswish | 80 × 16 × 16 |
| 11 | Inverted Residual 8 | 5 × 5 | - | Hswish | 80 × 16 × 16 |
| 12 | Inverted Residual 9 | 5 × 5 | CA | Hswish | 128 × 16 × 16 |
| 13 | Inverted Residual 10 | 3 × 3 | - | Hswish | 128 × 16 × 16 |
| 14 | Inverted Residual 11 | 3 × 3 | CA | Hswish | 240 × 16 × 16 |
| 15 | Inverted Residual 12 | 3 × 3 | CA | Hswish | 480 × 16 × 16 |
| 16 | Inverted Residual 13 | 3 × 3 | CA | Hswish | 960 × 16 × 16 |
| 17 | Last Conv | 1 × 1 | - | Hswish | 1280 × 8 × 8 |
| 18 | FcaNet Layer | - | FcaNet 2 | - | 1280 × 8 × 8 |
| 19 | Final Conv | 1 × 1 | - | LeakyReLU | 1280 × 8 × 8 |
| Methods | GT S 2 | GT H | EPE (STB) | EPE (RHD) |
|---|---|---|---|---|
| Zimmermann. et al. [11] | √ 1 | √ | 8.68 | 30.42 |
| Yang et.al. [39] | √ | √ | 8.66 | 19.95 |
| Chen et.al. [40] | √ | √ | 10.95 | 24.20 |
| Spurr et.al. [41] | √ | √ | 8.56 | 19.73 |
| Spurr et.al. [41] | × | × | 9.49 | 22.53 |
| InterNet [8] | × | × | 7.95 | 20.89 |
| InterNet+ (ours) | × | × | 7.38 | 19.30 |
| Total Parameters (M) | Parameters Size (MB) | Time Per Iteration (s) 1 | |
|---|---|---|---|
| InterNet | 23.51 | 89.68 | 0.61 |
| InterNet+ (ours) | 11.12 | 42.42 | 0.58 |
| Batch Size | 1 | 4 | 8 | 16 | 32 |
|---|---|---|---|---|---|
| InterNet | 32.46 | 136.35 | 194.79 | 247.52 | 257.26 |
| InterNet+ (ours) | 28.41 | 101.32 | 151.50 | 227.36 | 296.41 |
| Single Hand | Interacting Hands | |
|---|---|---|
| InterNet | 12.16 | 16.02 |
| InterNet+ (ours) | 11.67 1 | 17.63 1 |
| Model | STB | RHD |
|---|---|---|
| InterNet+ (without CA module) | 7.44 | 19.36 |
| InterNet+ (with SE module) | 7.76 | 19.45 |
| InterNet+ (ours) | 7.38 | 19.30 |
| Net Architecture | STB | RHD |
|---|---|---|
| InterNet+ (without FcaNet layer) | 7.52 | 20.01 |
| InterNet+ (ours) | 7.38 | 19.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Jiang, J.; Sun, J.; Wang, X. InterNet+: A Light Network for Hand Pose Estimation. Sensors 2021, 21, 6747. https://doi.org/10.3390/s21206747
Liu Y, Jiang J, Sun J, Wang X. InterNet+: A Light Network for Hand Pose Estimation. Sensors. 2021; 21(20):6747. https://doi.org/10.3390/s21206747
Chicago/Turabian StyleLiu, Yang, Jie Jiang, Jiahao Sun, and Xianghan Wang. 2021. "InterNet+: A Light Network for Hand Pose Estimation" Sensors 21, no. 20: 6747. https://doi.org/10.3390/s21206747
APA StyleLiu, Y., Jiang, J., Sun, J., & Wang, X. (2021). InterNet+: A Light Network for Hand Pose Estimation. Sensors, 21(20), 6747. https://doi.org/10.3390/s21206747