
CNN-Based Spectral Super-Resolution of Panchromatic Night-Time Light Imagery: City-Size-Associated Neighborhood Effects




Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sources
2.2. Data Processing
2.3. CNN Architecture
2.4. Assessing the Quality of the Models
3. Results
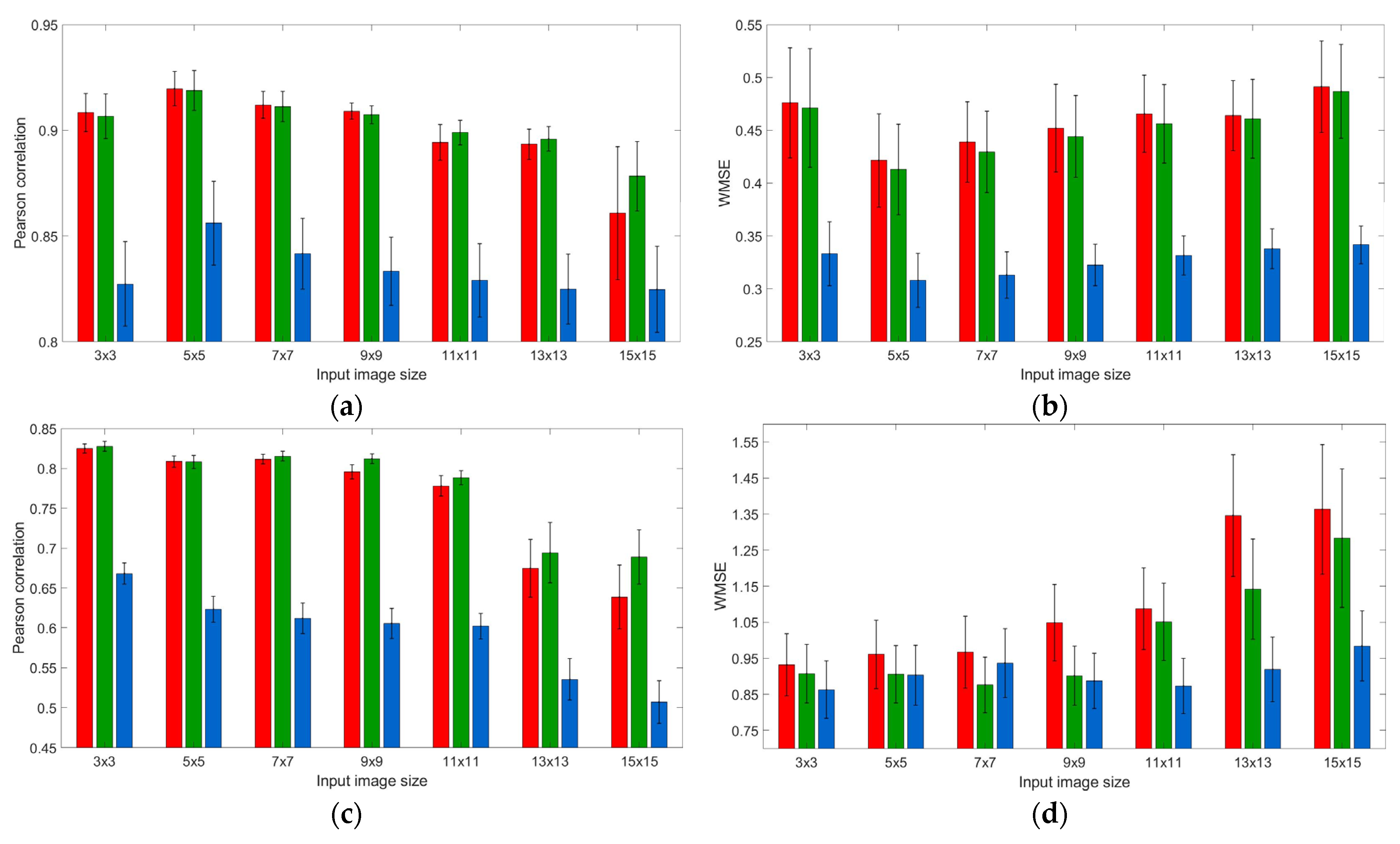
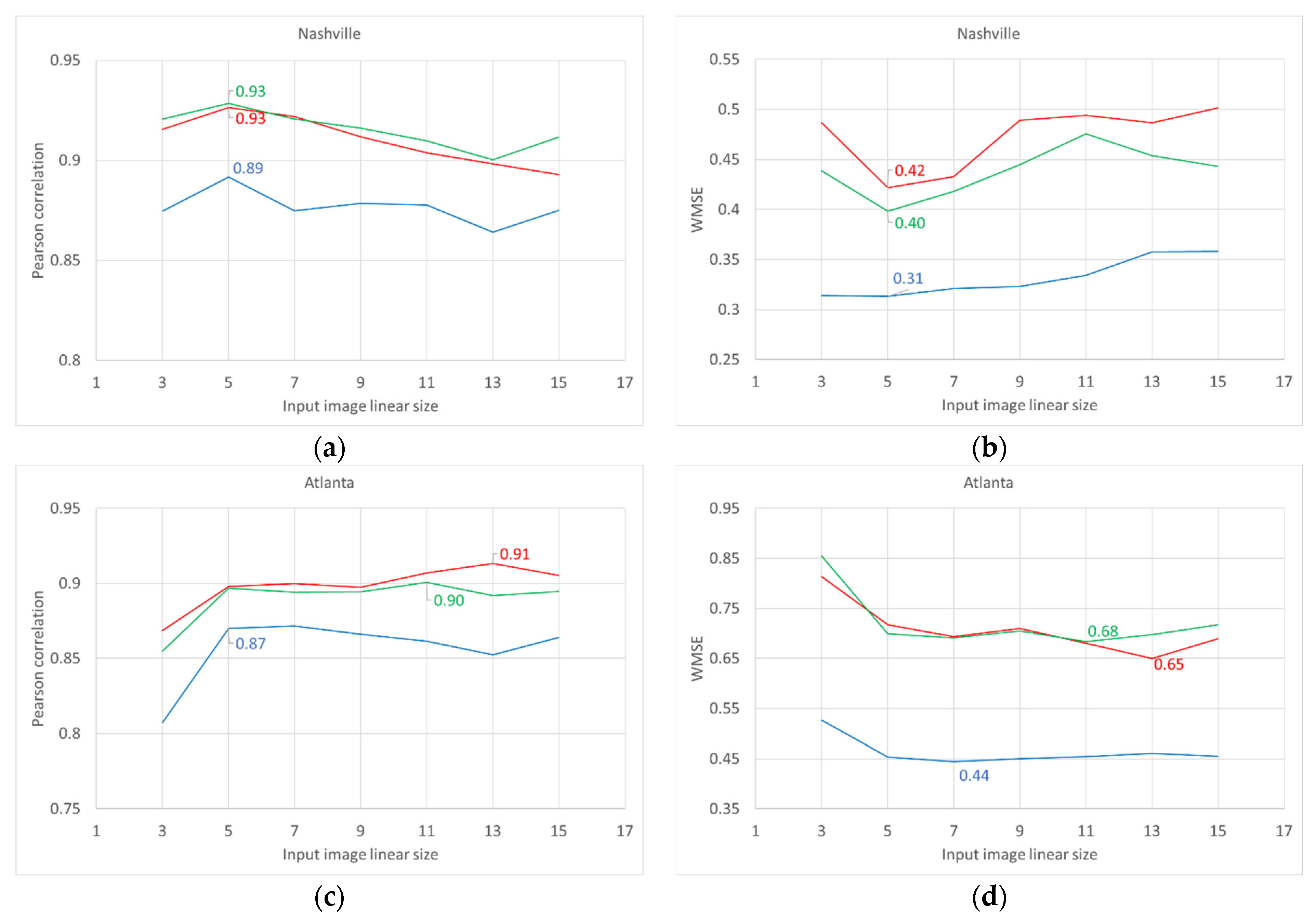
3.1. Neighborhood Effect: Models’ Performance upon Training and Testing Datasets
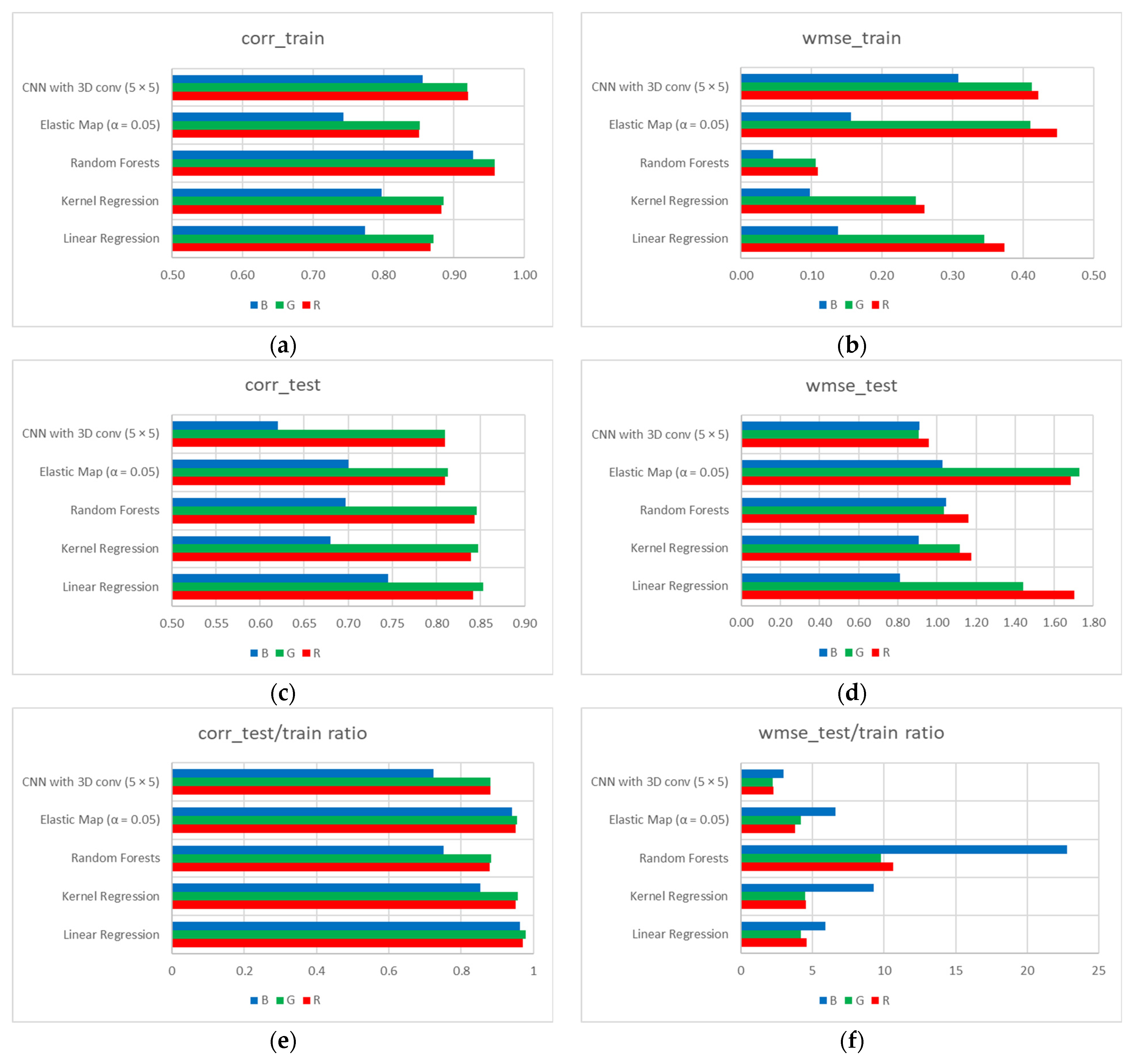
3.2. CNN Models Comparison with Other Machine Learning Techniques
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Elvidge, C.D.; Baugh, K.E.; Kihn, E.A.; Kroehl, H.W.; Davis, E.R.; Davis, C.W. Relation between satellite observed visible-near infrared emissions, population, economic activity and electric power consumption. Int. J. Remote Sens. 1997, 18, 1373–1379. [Google Scholar] [CrossRef]
- Sutton, P.; Roberts, D.; Elvidge, C.; Baugh, K. Census from Heaven: An estimate of the global human population using night-time satellite imagery. Int. J. Remote Sens. 2001, 22, 3061–3076. [Google Scholar] [CrossRef]
- Doll, C.N.H.; Muller, J.P.; Morley, J.G. Mapping regional economic activity from night-time light satellite imagery. Ecol. Econ. 2006, 57, 75–92. [Google Scholar] [CrossRef]
- Ebener, S.; Murray, C.; Tandon, A.; Elvidge, C.C. From wealth to health: Modelling the distribution of income per capita at the sub-national level using night-time light imagery. Int. J. Health Geogr. 2005, 4, 5. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, T.; Powell, R.L.; Elvidge, C.D.; Baugh, K.E.; Sutton, P.C.; Anderson, S. Shedding light on the global distribution of economic activity. Open Geogr. J. 2010, 3, 147–160. [Google Scholar]
- Mellander, C.; Lobo, J.; Stolarick, K.; Matheson, Z. Night-time light data: A good proxy measure for economic activity? PLoS ONE 2015, 10, e0139779. [Google Scholar]
- Hopkins, G.R.; Gaston, K.J.; Visser, M.E.; Elgar, M.A.; Jones, T.M. Artificial light at night as a driver of evolution across urban-rural landscapes. Front. Ecol. Environ. 2018, 16, 472–479. [Google Scholar] [CrossRef] [Green Version]
- Tselios, V.; Stathakis, D. Exploring regional and urban clusters and patterns in Europe using satellite observed lighting. Environ. Plan. B Urban Anal. City Sci. 2018, 47, 553–568. [Google Scholar] [CrossRef]
- Kloog, I.; Haim, A.; Stevens, R.G.; Portnov, B.A. Global co-distribution of light at night (LAN) and cancers of prostate, colon, and lung in men. Chronobiol. Int. 2009, 26, 108–125. [Google Scholar] [CrossRef] [PubMed]
- Kloog, I.; Stevens, R.G.; Haim, A.; Portnov, B.A. Nighttime light level co-distributes with breast cancer incidence worldwide. Cancer Causes Control 2010, 21, 2059–2068. [Google Scholar] [CrossRef]
- Rybnikova, N.A.; Haim, A.; Portnov, B.A. Does artificial light-at-night exposure contribute to the worldwide obesity pandemic? Int. J. Obes. 2016, 40, 815–823. [Google Scholar] [CrossRef]
- Bennie, J.; Duffy, J.; Davies, T.; Correa-Cano, M.; Gaston, K. Global Trends in Exposure to Light Pollution in Natural Terrestrial Ecosystems. Remote Sens. 2015, 7, 2715–2730. [Google Scholar] [CrossRef] [Green Version]
- Hu, Z.; Hu, H.; Huang, Y. Association between nighttime artificial light pollution and sea turtle nest density along Florida coast: A geospatial study using VIIRS remote sensing data. Environ. Pollut. 2018, 239, 30–42. [Google Scholar] [CrossRef]
- Cinzano, P.; Falchi, F.; Elvidge, C.D.; Baugh, K.E. The artificial night sky brightness mapped from DMSP satellite Operational Linescan System measurements. Mon. Not. R. Astron. Soc. 2000, 318, 641–657. [Google Scholar] [CrossRef] [Green Version]
- Falchi, F.; Cinzano, P.; Duriscoe, D.; Kyba, C.C.M.; Elvidge, C.D.; Baugh, K.; Portnov, B.A.; Rybnikova, N.A.; Furgoni, R. The new world atlas of artificial night sky brightness. Sci. Adv. 2016, 2, e1600377. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Falchi, F.; Furgoni, R.; Gallaway, T.A.A.; Rybnikova, N.A.A.; Portnov, B.A.A.; Baugh, K.; Cinzano, P.; Elvidge, C.D.D. Light pollution in USA and Europe: The good, the bad and the ugly. J. Environ. Manag. 2019, 248, 109227. [Google Scholar] [CrossRef]
- Earth Observation Goup. Available online: https://eogdata.mines.edu/products/vnl/ (accessed on 8 August 2021).
- Elvidge, C.D.; Baugh, K.E.; Zhizhin, M.; Hsu, F.-C. Why VIIRS data are superior to DMSP for mapping nighttime lights. Proc. Asia-Pac. Adv. Netw. 2013, 35, 62. [Google Scholar] [CrossRef] [Green Version]
- Rybnikova, N.A.; Portnov, B.A. Remote identification of research and educational activities using spectral properties of nighttime light. ISPRS J. Photogramm. Remote Sens. 2017, 128, 212–222. [Google Scholar] [CrossRef]
- Veitch, J.; Newsham, G.; Boyce, P.; Jones, C. Lighting appraisal, well-being and performance in open-plan offices: A linked mechanisms approach. Light. Res. Technol. 2008, 40, 133–151. [Google Scholar] [CrossRef] [Green Version]
- Guk, E.; Levin, N. Analyzing spatial variability in night-time lights using a high spatial resolution color Jilin-1 image—Jerusalem as a case study. ISPRS J. Photogramm. Remote Sens. 2020, 163, 121–136. [Google Scholar] [CrossRef]
- Cajochen, C.; Münch, M.; Kobialka, S.; Kräuchi, K.; Steiner, R.; Oelhafen, P.; Orgül, S.; Wirz-Justice, A. High Sensitivity of Human Melatonin, Alertness, Thermoregulation, and Heart Rate to Short Wavelength Light. J. Clin. Endocrinol. Metab. 2005, 90, 1311–1316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haim, A.; Portnov, B.A. Light Pollution As a New Risk Factor for Human Breast and Prostate Cancers; Springer: Dordrecht, The Netherlands, 2013; ISBN 9789400762206. [Google Scholar]
- McFadden, E.; Jones, M.E.; Schoemaker, M.J.; Ashworth, A.; Swerdlow, A.J. The relationship between obesity and exposure to light at night: Cross-sectional analyses of over 100,000 women in the Breakthrough Generations Study. Am. J. Epidemiol. 2014, 180, 245–250. [Google Scholar] [CrossRef]
- Search Photos. Available online: https://eol.jsc.nasa.gov/SearchPhotos/ (accessed on 7 April 2020).
- Jilin-1 Optical-A (Jilin-1 Guangxe-A)—Gunter’s Space Page. Available online: https://space.skyrocket.de/doc_sdat/jilin-1-optical-a.htm (accessed on 7 April 2020).
- Rybnikova, N.; Portnov, B.A.; Mirkes, E.M.; Zinovyev, A.; Brook, A.; Gorban, A.N. Coloring Panchromatic Nighttime Satellite Images: Comparing the Performance of Several Machine Learning Methods. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [Green Version]
- Milanfar, P. (Ed.) Super-Resolution Imaging; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Tian, J.; Ma, K.-K. A survey on super-resolution imaging. Signal Image Video Process. 2011, 5, 329–342. [Google Scholar] [CrossRef]
- Nasrollahi, K.; Moeslund, T.B. Super-resolution: A comprehensive survey. Mach. Vis. Appl. 2014, 25, 1423–1468. [Google Scholar] [CrossRef] [Green Version]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheong, J.Y.; Park, I.K. Deep CNN-Based Super-Resolution Using External and Internal Examples. IEEE Signal Process. Lett. 2017, 24, 1252–1256. [Google Scholar] [CrossRef]
- Xiao, A.; Wang, Z.; Wang, L.; Ren, Y. Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network. Sensors 2018, 18, 1194. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Li, C.; Meng, Q.; Liu, S.; Zhang, Y.; Wang, J. Infrared Image Super Resolution by Combining Compressive Sensing and Deep Learning. Sensors 2018, 18, 2587. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Wu, Y.; Ming, Y.; Lv, H. Remote Sensing Imagery Super Resolution Based on Adaptive Multi-Scale Feature Fusion Network. Sensors 2020, 20, 1142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, C.; Xu, Y.; Zuo, W.; Zhang, B.; Fei, L.; Lin, C.W. Coarse-to-Fine CNN for Image Super-Resolution. IEEE Trans. Multimed. 2021, 23, 1489–1502. [Google Scholar] [CrossRef]
- Arun, P.V.; Buddhiraju, K.M.; Porwal, A.; Chanussot, J. CNN based spectral super-resolution of remote sensing images. Signal Process. 2020, 169, 107394. [Google Scholar] [CrossRef]
- Can, Y.B.; Timofte, R. An efficient CNN for spectral reconstruction from RGB images. arXiv 2018, arXiv:1804.04647. [Google Scholar]
- Galliani, S.; Lanaras, C.; Marmanis, D.; Baltsavias, E.; Schindler, K.; Sensing, R.; Zurich, E. Learned Spectral Super-Resolution. arXiv 2017, arXiv:1703.09470. [Google Scholar]
- Aeschbacher, J.; Wu, J.; Timofte CVL, R.; Zurich, E. In Defense of Shallow Learned Spectral Reconstruction from RGB Images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Arad, B.; Ben-Shahar, O. Sparse Recovery of Hyperspectral Signal from Natural RGB Images. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored Neighborhood Regression for Fast Example-Based Super-Resolution. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1920–1927. [Google Scholar]
- Kawakami, R.; Matsushita, Y.; Wright, J.; Ben-Ezra, M.; Tai, Y.W.; Ikeuchi, K. High-resolution hyperspectral imaging via matrix factorization. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2329–2336. [Google Scholar] [CrossRef]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Learning representations for automatic colorization. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016; Volume 9908, pp. 577–593. [Google Scholar]
- Deshpande, A.; Rock, J.; Forsyth, D. Learning large-scale automatic image colorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Morimoto, Y.; Taguchi, Y.; Naemura, T. Automatic colorization of grayscale images using multiple images on the web. In Proceedings of the SIGGRAPH 2009: Talks, New Orleans, LA, USA, 3–7 August 2009. [Google Scholar] [CrossRef]
- Chia, A.Y.S.; Zhuo, S.; Tan, P.; Gupta, R.K.; Cho, S.Y.; Tai, Y.W.; Lin, S. Semantic Colorization with Internet Images. ACM Trans. Graph. 2011, 30, 1–8. [Google Scholar] [CrossRef]
- Gupta, R.K.; Chia, A.Y.S.; Rajan, D.; Ng, E.S.; Zhiyong, H. Image Colorization using Similar Images; ACM Press: New York, NY, USA, 2012; pp. 369–378. [Google Scholar]
- Ironi, R.; Cohen-Or, D.; Lischinski, D. Colorization by Example. Render. Tech. 2005, 29, 201–210. [Google Scholar]
- Bugeau, A.; Ta, V.T.; Papadakis, N. Variational exemplar-based image colorization. IEEE Trans. Image Process. 2014, 23, 298–307. [Google Scholar] [CrossRef] [Green Version]
- Román, M.O.; Wang, Z.; Shrestha, R.; Yao, T.; Kalb, V. Black Marble User Guide Version 1.0; NASA: Washington, DC, USA, 2019.
- Wang, P.; Huang, C.; Brown de Colstoun, E.C.; Tilton, J.C.; Tan, B. Global Human Built-Up And Settlement Extent (HBASE) Dataset From Landsat; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NJ, USA, 2017.
- ArcGIS Desktop|Desktop GIS Software Suite—Esri. Available online: https://www.esri.com/en-us/arcgis/products/arcgis-desktop/overview (accessed on 2 November 2021).
- GitHub. Elastic Map. Available online: https://github.com/Mirkes/ElMap (accessed on 11 April 2020).
- Truong, T.-D.; Nguyen, V.-T.; Tran, M.-T. Lightweight Deep Convolutional Network for Tiny Object Recognition. In Proceedings of the 7th International Conference on Pattern Recognition Applications and Methods 2018, Funchal, Portugal, 16–18 January 2018. [Google Scholar] [CrossRef]
- MATLAB—MathWorks—MATLAB & Simulink. Available online: https://www.mathworks.com/products/matlab.html (accessed on 11 September 2021).
- Train Deep Learning Neural Network—MATLAB Train Network. Available online: https://www.mathworks.com/help/deeplearning/ref/trainnetwork.html (accessed on 11 September 2021).
- JASP. Available online: https://jasp-stats.org/ (accessed on 20 September 2021).
- A New Approach to Identify On-Ground Lamp Types from Night-Time ISS Images. Available online: https://eartharxiv.org/repository/view/2684/ (accessed on 19 September 2021).












{kind=link}
{kind=link}
{kind=link}
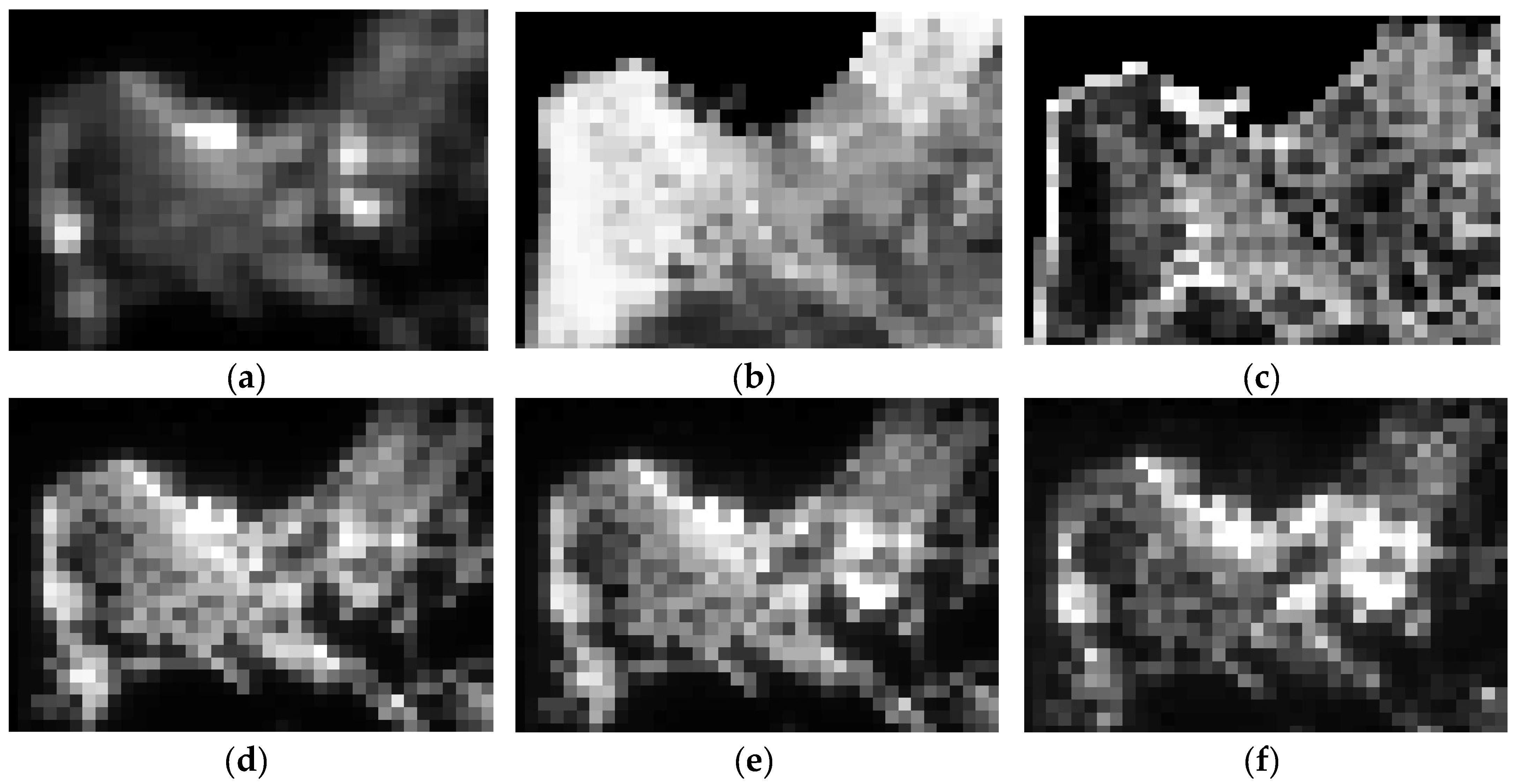{kind=link}
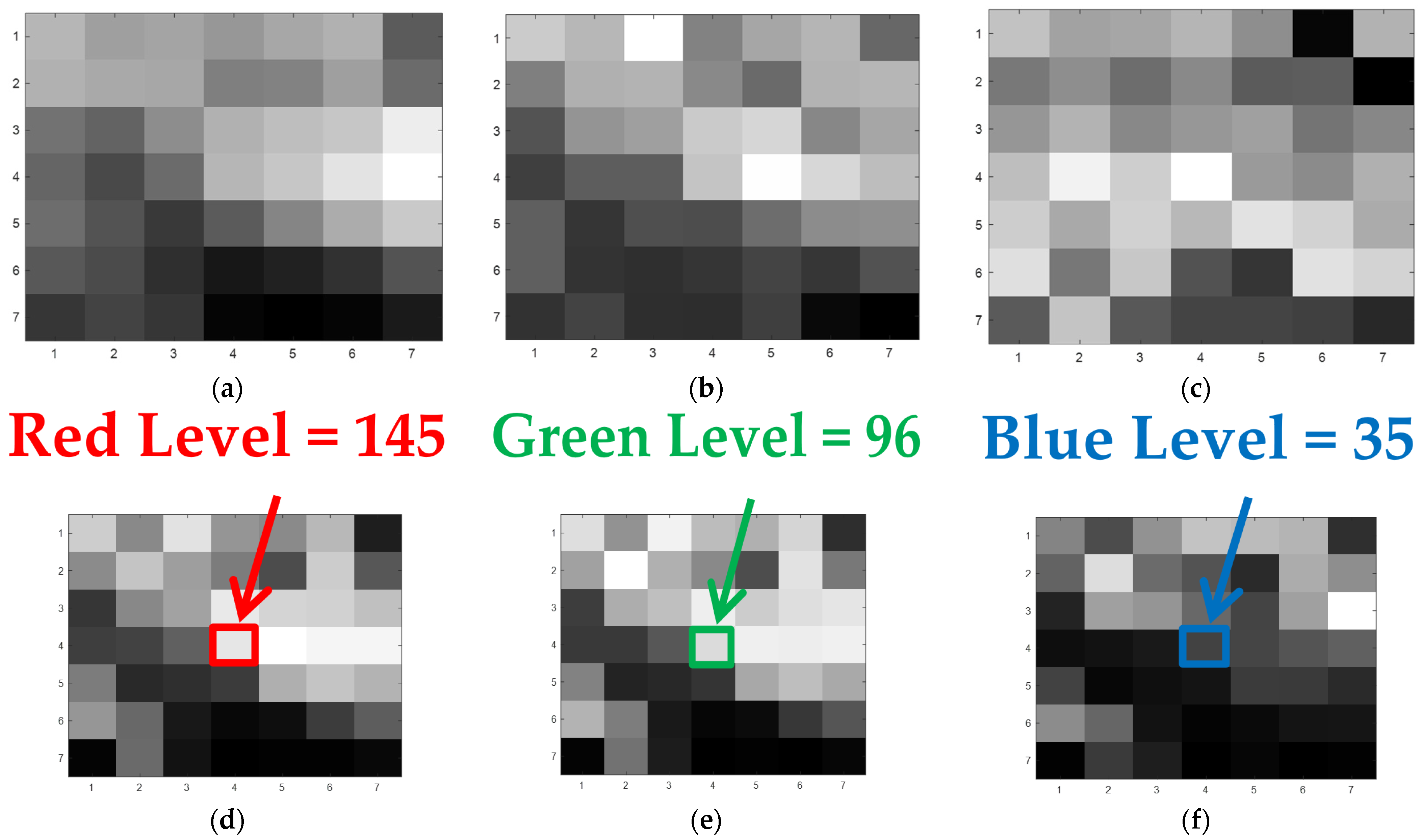{kind=link}
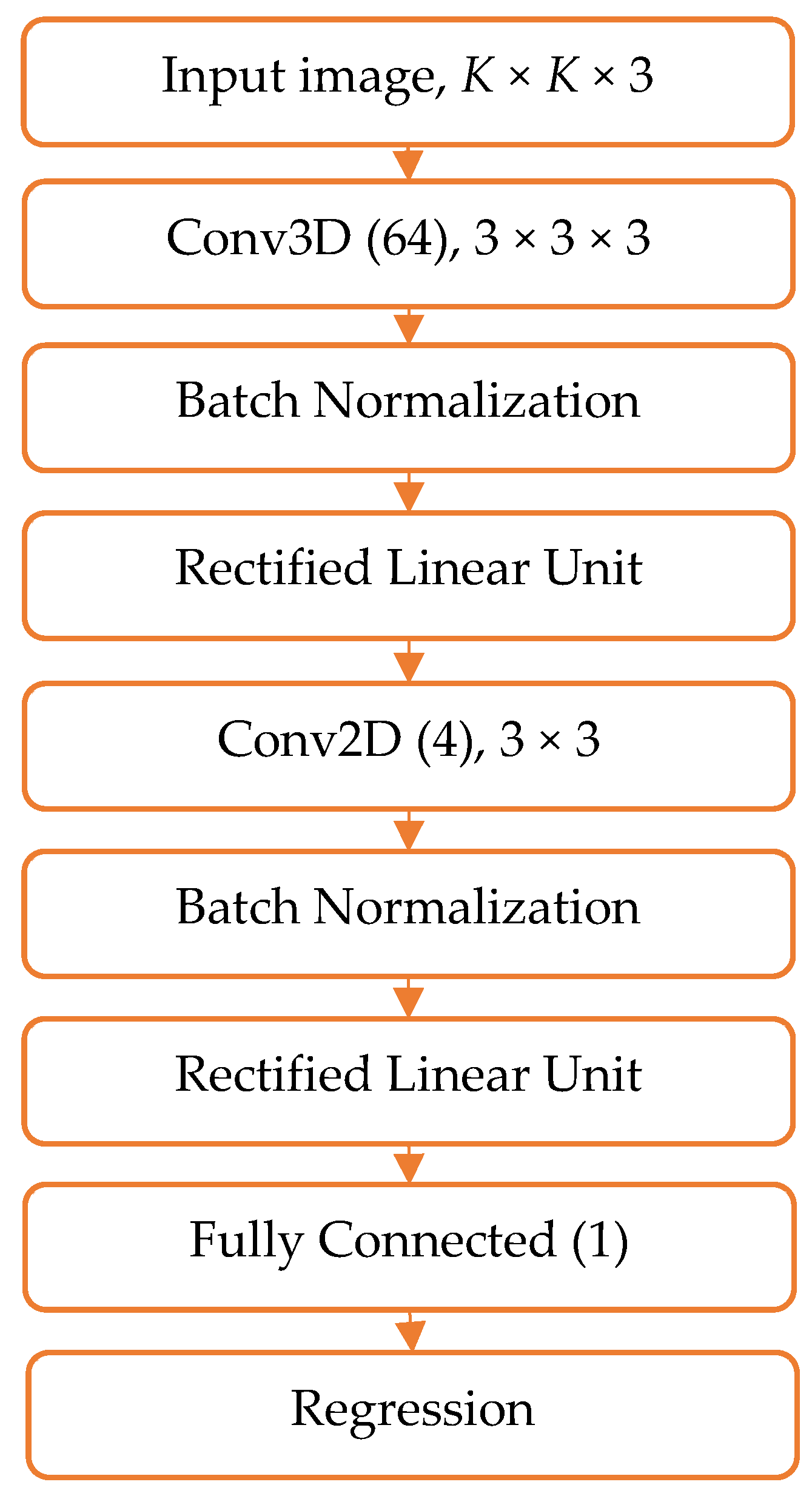{kind=link}
{kind=link}
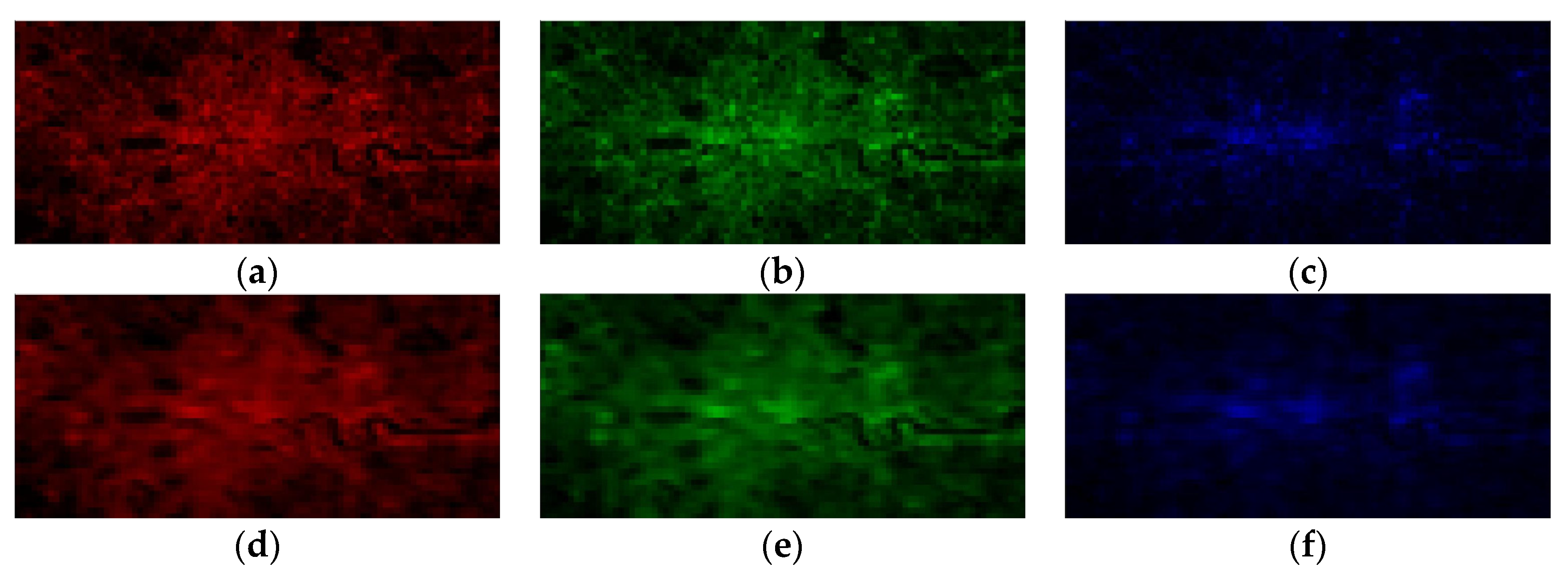{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Input Image Size | ||||||
|---|---|---|---|---|---|---|---|
| 3 × 3 | 5 × 5 | 7 × 7 | 9 × 9 | 11 × 11 | 13 × 13 | 15 × 15 | |
| Atlanta | 5609 | 5313 | 5025 | 4745 | 4473 | 4209 | 3953 |
| Beijing | 5400 | 5088 | 4784 | 4488 | 4200 | 3920 | 3648 |
| Haifa | 900 | 782 | 672 | 570 | 476 | 390 | 312 |
| Khabarovsk | 3550 | 3312 | 3082 | 2860 | 2646 | 2440 | 2242 |
| London | 4850 | 4560 | 4278 | 4004 | 3738 | 3480 | 3230 |
| Naples | 1872 | 1700 | 1536 | 1380 | 1232 | 1092 | 960 |
| Nashville | 2695 | 2491 | 2295 | 2107 | 1927 | 1755 | 1591 |
| Tianjing | 6045 | 5733 | 5429 | 5133 | 4845 | 4565 | 4293 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rybnikova, N.; Mirkes, E.M.; Gorban, A.N. CNN-Based Spectral Super-Resolution of Panchromatic Night-Time Light Imagery: City-Size-Associated Neighborhood Effects. Sensors 2021, 21, 7662. https://doi.org/10.3390/s21227662
Rybnikova N, Mirkes EM, Gorban AN. CNN-Based Spectral Super-Resolution of Panchromatic Night-Time Light Imagery: City-Size-Associated Neighborhood Effects. Sensors. 2021; 21(22):7662. https://doi.org/10.3390/s21227662
Chicago/Turabian StyleRybnikova, Nataliya, Evgeny M. Mirkes, and Alexander N. Gorban. 2021. "CNN-Based Spectral Super-Resolution of Panchromatic Night-Time Light Imagery: City-Size-Associated Neighborhood Effects" Sensors 21, no. 22: 7662. https://doi.org/10.3390/s21227662
APA StyleRybnikova, N., Mirkes, E. M., & Gorban, A. N. (2021). CNN-Based Spectral Super-Resolution of Panchromatic Night-Time Light Imagery: City-Size-Associated Neighborhood Effects. Sensors, 21(22), 7662. https://doi.org/10.3390/s21227662