1. Introduction
The analysis of electrocardiographic signals (ECG) is one of the most important steps in diagnosing cardiac disorders. Research into methods of ECG signal diagnostics has been developed for decades. An electrocardiogram is a commonly employed non-invasive physiological signal used for screening and diagnosing cardiovascular disease. In addition, the signal is used to search for pathological patterns corresponding to diseases. ECG analysis tools require knowledge of the location and morphology of the various segments (P-QRS-T) in the ECG recordings [
1]. The most common reference point for assessing ECG signals is the QRS complex and detection of R-waves [
2,
3,
4,
5,
6]. These studies are complemented by the R–R distance assessment and heart rate analysis as an additional feature of the signal [
7,
8,
9,
10,
11,
12]. It should be noted that these methods usually use databases such as Physionet, PhysioBank, and PhysioToolkit datasets to confirm their performance [
13]. Their main goal is to detect arrhythmia—i.e., an abnormal heartbeat—which is a common symptom of heart disease [
14].
One of the most common ways that clinicians or cardiologists analyze ECG signals is to inspect these records visually. However, visually assessing ECG signals can be difficult and time-consuming. The authors confirm this in numerous works. Most of these algorithms are based on traditional machine learning and digital signal processing techniques, such as wavelet transform, Fourier Transform, low-pass filters, high-pass filters, median filters, and others [
15,
16,
17,
18]. In addition, studies in this area typically involve data preprocessing, feature extraction, and building classifiers using an ECG signal [
19,
20,
21].
Recently, it has been proved that Artificial Intelligence (AI) and Machine Learning (ML) have numerous applications in all engineering fields. The literature includes works in the fields of electrical engineering [
22], civil engineering [
23], and petroleum engineering [
24]. Another group of works includes research based on deep learning (DL) [
25,
26,
27]. The applications of deep learning in biomedical engineering, relevant to this work, have grown exponentially in recent years. Deep learning is the study of information, forecasts, decision making, or the use of a data set, called training data, to identify complex patterns. In particular, DL has been proven to help increase the diagnostic effectiveness of cardiovascular diseases by means of ECG signals. At this time, many researchers have used methods based on deep learning, such as ResNet, InceptionV3, Gated Recurrent Unit (GRU), and Long Short-Term Memory (LSTM) [
28,
29,
30,
31]. The learning capabilities of the Convolutional Neural Network (CNN) are successfully employed in ECG signal classification. For example, in one of the studies, DLs were used to detect R waves, reaching an accuracy at the level of 97.22% [
32], or for ECG arrhythmia classification, reaching an accuracy at the level of 93.53% [
33]. It should be noted here that these tests were conducted on a relatively small number of samples of ECG.
The use of deep learning techniques in ECG signals is a challenge for researchers. A major issue is limited access to the data set. Moreover, deep learning-based methods have high training environments and computing platform requirements, limiting the application scenarios. The solution to the unavailability of data was the PTB-XL database. It is a large, online, publicly available electrocardiography dataset published in April 2020. A large project involving a large number of scientific publications using data from the PTB-XL dataset was PhysioNet/Computing in Cardiology Challenge 2020.
The project PhysioNet/Computing in Cardiology Challenge 2020 was an initiative for authors to research various processes of ECG prediction based on age and gender for the evaluation of signal quality [
34,
35]. Diverse deep learning models [
36] trained on a large dataset of ECG data were used to detect atrial fibrillation. In another study, the authors used the novel convolutional neural network with a non-local convolutional block attention module to solve the problem of detecting arrhythmias in the ECG recording [
37]. The classification of cardiac arrhythmias used a deep neural network based on one-dimensional CNN [
38], obtaining accuracy results of 0.94–0.97. The authors of [
39] undertook the detection and classification of cardiac arrhythmias using long short-term memory. In another study, the authors using DL proposed a Gated Recurrent Unit with the Extreme Learning Machine for ECG signal processing, data sampling, feature extraction, and classification [
27]. The authors of [
40,
41] proposed two SE ResNet models and one rule-based model to improve the classification efficiency of various ECG abnormalities. The use of deep learning techniques in the assessment of the ECG signal was undertaken by the authors of [
42], who presented the possibilities of using convolutional neural networks in the classification of heart diseases by examining ECG signals.
This paper presents a comparison of convolutional neural network architectures using different input data combinations. The varieties included the raw ECG signal, entropy-based features computed from raw ECG signals, extracted QRS complexes, and entropy-based features added from extracted QRS complexes. The enrichment of the neural networks with entropy-based features is related to continuing the research [
42]. Some works link entropy-based features with biomedical signals in combination with machine learning models. The authors of [
43] studied emotional recognition by analyzing the complexity of physiological signals. They assessed the improvement in the efficiency of this process using various characteristics of the entropy domain. They conducted their research based on various physiological signals, including the Electroencephalogram (EEG), Electrocardiogram (ECG), and Galvanic Skin Response (GSR). In their work, they used the XGBoost classifier as a scalable and flexible machine learning method. The authors of [
44] conducted similar research, proposing an entropy-based processing scheme for the structure of emotional recognition. The authors’ activities were based on entropy domain feature extraction and prediction by the XGBoost classifier. The analyzed data included EEG, ECG, and GSR signals. The authors used three types of entropy domain features. The proposed scheme for multi-modal analysis outperforms conventional processing approaches. According to the literature review, the area of the usage of entropy-based features as data vectors for machine learning algorithms such as XGBoost is well-established. However, its utilization during Deep Neural Network inference in ECG signal classification is under-researched, and this article aims to explore this set of methods.
The aim of the study was to find the best neural network architectures for disease entities included in 2, 5, and 20 different heart disease classes. In this work, a neural network architecture is defined as a composition of subnetworks called “modules”. Each “module” uses different types of input data: raw signal, extracted QRS complexes, raw signal entropy, and QRS complex entropies. For this purpose, a convolutional neural network was proposed that uses extracted QRS complexes and entropy-based features. In addition, the new method of R-peak labeling and QRS complex extraction has been used. This method uses a 12-lead signal, for which, using the R wave detection algorithms and the k-mean algorithm, the R-peak position estimate is generated. Entropy-based features are promising additions to data preprocessing that may prove beneficial in other signal-processing-related tasks. Examined models are compositions of modules. Each module interprets the different data types, thus creating a heterogeneous architecture instead of typical homogenous neural network structures. Because of that, the proposed architecture has increased computational complexity to obtain better results. Therefore, research on this topic is required.
2. Materials and Methods
The methodology of the research described in this paper is as follows (
Figure 1): data from the PTB-XL database were used for the research. The data—i.e., ECG signal records—were filtered. Then, in the raw signal, R-peaks were labeled and split into segments such that there was precisely one ECG R-wave peak in each segment (i.e., QRS complex). Then, the entropy features for the raw signal and the QRS complex were calculated. In the next step, the data were divided into training, validation, and test data, using cross validation. Next, the neural network was trained. The last step was evaluation.
2.1. PTB-XL Dataset
In this study, all the ECG data used are derived from the PTB-XL dataset [
13,
45]. The PTB-XL database is a large dataset containing a set of 21,837 clinical 12-lead ECG records. The sampling rate of the data is 500 Hz and 100 Hz with 16-bit resolution. Each ECG signal is 10 s in length and is annotated by cardiologists. The PTB-XL data are derived from 18,885 patients and are balanced in relation to sex, including 52% of male and 48% of female patients. The dataset involves five major classes: NORM—normal ECG, CD—myocardial infarction, STTC—ST/T change, MI—conduction disturbance, HYP—hypertrophy.
2.2. Data Filtering
Initially, the PTB-XL repository contained 21,837 ECG records. However, not all of them are labeled, and not all the labels are assigned 100% certainty. Both cases were filtered out. The remaining records had classes and subclasses assigned to them. In the next step, records with subclasses below 20 were filtered out. This action resulted in the collection of 17,232 ECG records. As a result, each record belonged to one of the 5 classes and one of the 20 subclasses (
Table 1). A sampling frequency of 500 Hz was selected for each record of the ECG signal.
2.3. R Wave Detection
The P wave, QRS complex, and T wave are the main components in the ECG waveform, of which the QRS complex is its dominant feature. The QRS complex detection is essential in many clinical conditions, including measuring and diagnosing numerous heart abnormalities. The first step in the diagnosis of the QRS complex is R-peak detection.
The PTB-XL databases contain 10 s EGC records. This means that they present records with a constant time but not a constant BPM (beat per minute) number. For this work, these records were cut into sections containing precisely one R wave each.
Determining the R waves from the ECG waveform is not trivial. Therefore, the authors decided to use several detectors. The list of used algorithms is presented below:
Two average detector [
47];
Stationary Wavelet Transform detector [
48];
Pan–Tompkins detector [
50];
Engzee detector [
51] with modification [
52].
The methods above return the positions of the R waves in the signal and are designed to work with a single signal (single lead). The PTB-XL database contains 12 lead records. In order to take advantage of the possibilities offered by the base and increase the precision of the algorithm, all 12 signals constituting each record were taken into account. Each of them was processed by all of the detectors.
Figure 2 depicts examples of the I-lead signal for selected records of various classes with R waves marked, using various techniques. The following colors are marked accordingly: red—Hamilton detector, green—two average detector, magenta—Stationary Wavelet Transform detector, cyan—Engzee detector, yellow—Pan–Tompkins detector, Black—Christov detector.
In the next step, the computation of the number of R waves in the record was performed. First, the number of R waves from each detector and for each signal (72 in total) was determined. Then, these numbers were used for median calculation. The median is the assumed number of R waves in record
. Hence, the BPM for the record was calculated. The formula describes this process:
where
is the
i-th ECG signal in the dataset
X;
are the functions processing signals made of 5000 real-value samples into a set of indexes of R-wave centers;
F is the set of functions for R-wave extraction;
is the set of cardinalities of sets of detected R-wave indices extracted by each R-wave detection function for the
i-th ECG signal;
is the median of cardinalities of detected R-waves for the
i-th ECG signal;
n is the number of functions; and
are positive natural numbers.
In the next step, a set of points in the one-dimensional space was created, containing the results of all R-wave detectors for all 12 leads to determine the position of the R waves. Then, the application of the k-mean algorithm on the created set was conducted. The number of R-peak was assumed as k. Finally, the cluster centers of the k-mean algorithm were used to determine the location of the R waves. The evaluation of examined methods was conducted by the computation of the mean absolute error (MAE) of the QRS complex number between the obtained results and ground truth.
Figure 3 and
Figure 4 show a comparison of errors in determining the R-peak number by known detectors and the authors’ detector.
In the next step, a 10 s record was cut with separation points aligned halfway between the R-waves. Finally, the first and last segment were removed. This caused the R wave and QRS to be in the labeled center of the excised section.
Figure 5 shows examples of the I-lead signal for selected records of various classes with designated R waves and points of signal cuts.
In the last step, all sections were resampled to obtain 100 measurements per signal. The resampling ratio was kept for each section forming with BPM constituted additional metadata.
2.4. Entropy-Based Features
The combination of a neural network with entropy-based features has recently been realized in [
42]. In this work, the authors proved that adding entropy-based features to the convolutional neural network ensures the highest accuracy in every classification task. This article examined the utility of measuring ECG and QRS complex information entropies as a feature vector by the deep learning modules specially designed for this task. The entropies listed below have been computed for both raw ECG signals and each individual QRS complex:
According to Granelo-Belinchon et al. [
60], information theory measurements can be straightforwardly used in nonstationary signals as long as short periods are considered during which the signal has not changed its parameters yet. Although ECG signals are not stationary, research conducted on the PTB-XL dataset proved that 10 s measurements of heartbeat provide signals that in 89.5% of cases were classified as stationary by the augmented Dickey–Fuller test [
61], making these signals stationary with regard to these 10 s long time spans.
2.5. Data Splitting
The following data were obtained for each record:
Records were divided into training, validation, and test data at the ratios of 70%, 15%, and 15%. To improve the quality of the research, non-exhaustive cross validation was used. For this purpose, the split function was called with five different seed values. This means that all tests were repeated five times for different data splits.
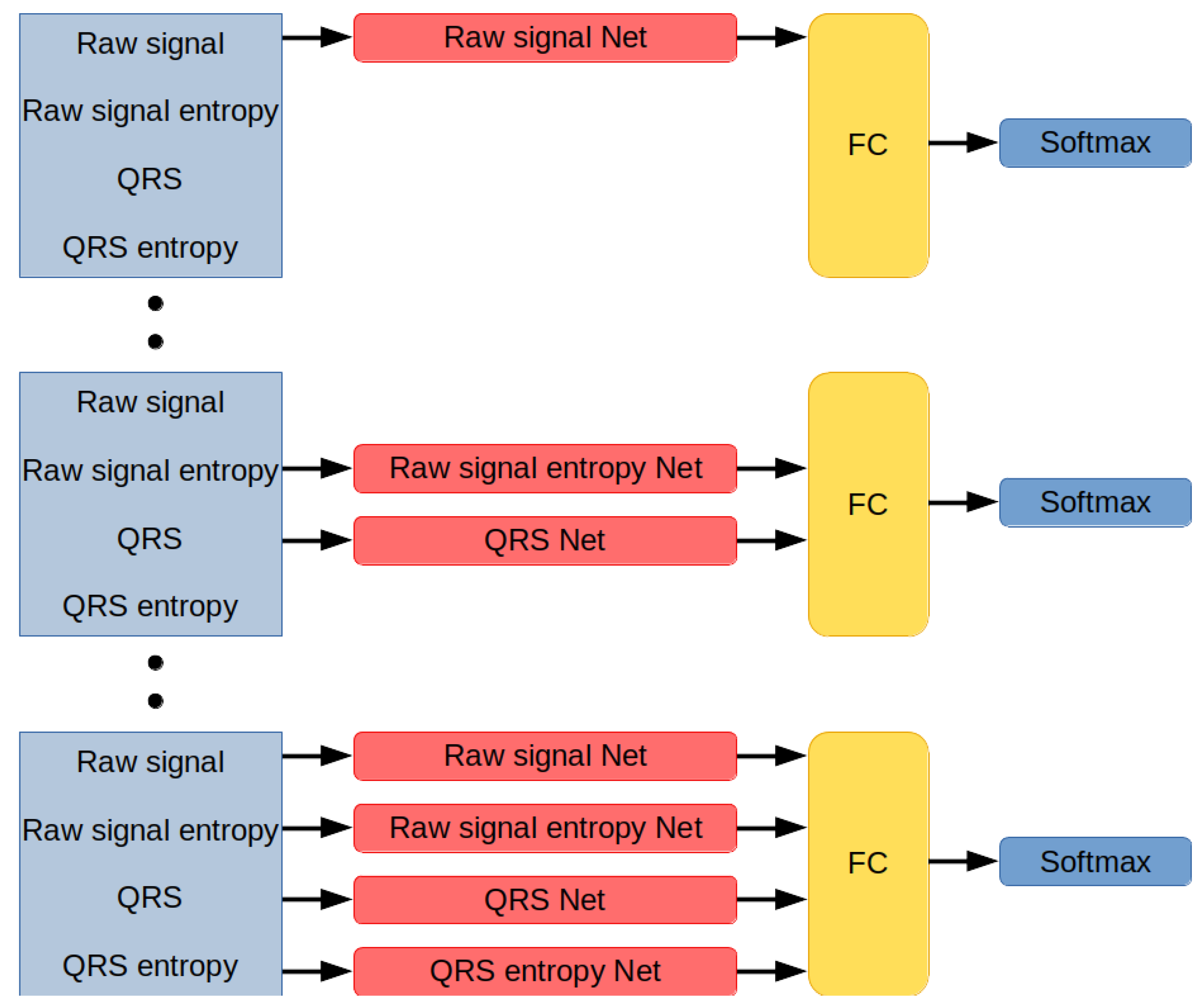
2.6. Designed Network Architectures
Networks developed for this research are modules designed to interpret different types of data (
Figure 6). Each module works in parallel with other modules and encodes incoming information into the 20-dimensional vector. The network distributes data among the modules, concatenates their outputs, applies non-linearity by using the Leaky ReLU activation function, inputs them on a fully-connected layer with a number of neurons equal to the number of classes in the classification set, and returns the index of the label associated with the signal.
2.6.1. Module Interpreting Raw Signal
This subnetwork encodes a raw signal. Its input signal contains 5000 samples in each of its 12 channels. The architecture is described in
Table 2. A leaky ReLU activation function with a negative slope coefficient of 0.01 was used to process the output of every convolutional layer.
The result of the last convolutional layer is flattened to the 40-dimensional vector and processed by the fully-connected layer with 20 neurons. As a result, the output of this module is a 20-dimensional vector.
The last convolutional layer has a kernel of size 1. Its purpose is to perform the dimensionality reduction of map activation to reduce the number of connections in the fully-connected layer. Without dimensionality reduction, the flatten vector would contain 1920 samples, requiring a fully-connected layer with 38,400 weights to process the output. However, due to applied convolution, the final fully-connected layer has only 800 weights. Thus, in addition to 192 weights required to operate an additional convolutional layer, more than 38 times fewer weights were required to perform the last encoding step.
The architecture of this module is simple yet efficient.
2.6.2. Module Interpreting Entropy-Based Features Calculated for a Raw Signal
This subnetwork encodes vectors of entropy-based features calculated for a raw signal. ECG signal contains 12 channels, and for every channel, 13 entropy-based features have been computed, resulting in a 156-dimensional vector. The architecture is described in
Table 3.
2.6.3. Module Interpreting QRS Complex from ECG Signals
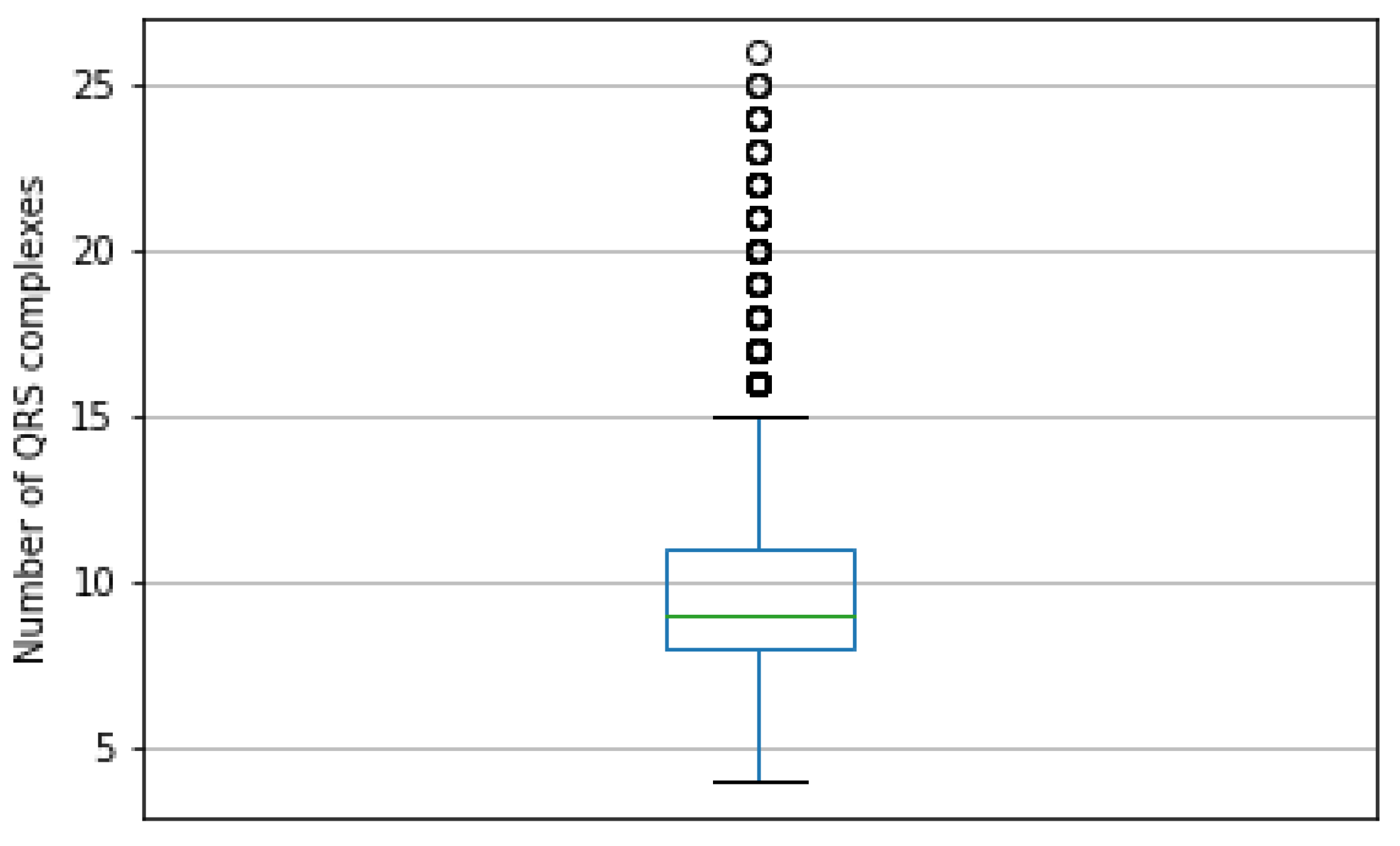
This subnetwork processes QRS complexes, aggregating the results and encoding these to the 20-dimensional vector. Each QRS is a 12-channel signal containing 100 samples, but the amount of QRS is not fixed.
The PTB-XL database contains ECG signals made up of from 4 to 26 QRS signals. The most frequent value of QRS in the ECG signal is 8, with 19.8% occurrence frequency in the dataset. The box plot in
Figure 7 presents the distribution of the QRS count in signals.
The number of QRS complexes in the signal has a significant variance, discouraging the solution of this problem by taking the smallest number of signals due to information loss. To handle varying numbers of QRS complexes, the subnetwork is further divided into submodules:
Single QRS complex encoding function;
Adaptive Maximum Pooling;
Adaptive Average Pooling;
Fully-Connected layer finalizing the computations.
Assume the input data as a set of QRS signals:
We define a wave-encoding function that takes one QRS 12-channel signal containing 100 samples and outputs one 24-dimensional vector:
The function is used to encode each QRS in input data:
As a result,
is a variable-length set of 24-dimensional vectors. This set is now processed by Adaptive Maximum Pooling and Adaptive Average Pooling functions. The Adaptive Maximum Pooling function selects a maximum value for every dimension from vectors in the set:
Adaptive Average Pooling function averages values of every dimension from vectors in the set:
The results of both Adaptive Maximum Pooling and Adaptive Average Pooling are concatenated into one 48-dimensional vector:
In the last step, the result is inputted to a fully-connected layer with 20 neurons turning the 48-dimensional vector of concatenated pooling results into a 20-dimensional final vector:
The function performing the encoding of a single QRS complex is performed by a convolutional neural network of the architecture described in
Table 4. The leaky ReLU activation function with a negative slope coefficient
of 0.01 was used to process the output of every convolutional layer. The output of the last convolutional layer is flattened to the form of a 24-dimensional layer.
2.6.4. Module Interpreting Entropy-Based Features of Every QRS Signal
This submodule encodes information from entropy-based feature vectors computed for every QRS complex. Due to the varying amount of QRS in the ECG signal, the number of entropy-based feature vectors is also unknown. A neural network set of 156-dimensional feature vectors is aggregated using Adaptive Maximum Pooling and Adaptive Average Pooling functions to adjust input data to fixed-size. Each of these functions generates one 156-dimensional vector. Then, these two vectors are concatenated into one 312-dimensional vector, which is then fed to a shallow neural network. The result is a 20-dimensional vector encoding input data.
The architecture of the neural network is described in
Table 5.
2.7. Training
Neural networks are trained using the Adam optimizer [
62]. Each network is optimized on a train dataset and evaluated on a validation dataset. Training lasts for 10,000 epochs unless early stopping [
63] is called. If a network does not improve its best result on the validation dataset in 250 epochs, then training is stopped, and another network is created. The learning rate at the beginning is equal to 0.001, and it is reduced by half if the network does not improve its best result on the training dataset within 50 epochs from the last improvement or learning rate reduction. If the learning rate reaches 0.000001, then no further reduction is applied.
Every epoch consists of 10 batches. Therefore, the batch size is equal to 256. Due to the technical restrictions on the size of Tensors used for GPU computation in PyTorch [
64], batch tensors must be made from same-dimensional data. Therefore, only signals of the same number of QRS complexes can be put into the same batch. Because of that limitation, a particular procedure for creating batch tensors was applied.
Preparation phase:
Evaluate the data;
Find unique numbers of QRS complexes in the dataset;
Determine the distribution of QRS complexes numbers in the dataset;
Divide set into chunks of data with the same number of QRS complexes.
Batch creation phase:
Randomize number of QRS complexes based on distribution established in preparation phase;
Select chunk of data based on result of previous operation;
If chunk contains less than 256 samples:
- (a)
Create tensor from whole chunk;
- (b)
Return tensor.
If chunk contains more than 256 samples:
- (a)
Create tensor from randomly select 256 samples;
- (b)
Return tensor.
The training was conducted using hardware configurations on a dual-Intel Xeon Silver 4210R with 192 GB RAM and a Nvidia Tesla A100 GPU. In this research, PyTorch, Sklearn, Numpy, Pandas, and Jupyter Lab programming solutions were used to implement the neural networks [
42].
2.8. Metrics
Neural networks were evaluated using the metrics described below. For the simplicity of equations, specific acronyms have been created, as follows: TP—true positive, TN—true negative, FP—false positive, FN—false negative. Metrics used for network evaluation are as follows:
Accuracy: ;
;
;
;
AUC: Area under ROC. ROC (Receiver Operating Characteristic) is a curve determined by calculating the true positive rate = and false positive rate = . The false positive rate describes the x-axis and the true positive rate the y-axis of a coordinate system. By changing the threshold value responsible for the classification of an example as belonging to either the positive or negative class, pairs of TFP–FPR are generated, resulting in the creation of the ROC curve. AUC is a measurement of the area below the ROC curve.
4. Discussion
Based on the results, the best model proposed in this article is the composition of modules responsible for interpreting raw signals, QRS complexes, and entropies computed for each QRS wave. This network obtained the best average accuracy on 20 classes, and in other tasks, the accuracy was only around 0.2% on average worse than the best model. The difference is smaller than the standard deviation of the evaluated models. This configuration of modules proved to be the most versatile, scoring an accuracy on average of 90.0% ± 0.4% on 2 classes, 76.2% ± 1.8% on 5 classes, and 68.5% ± 1.3% on 20 classes.
The results prove that adding entropy-based features and extracted QRS complexes to the raw signal is beneficial. In every task, the hybrid network performed the best. The difference between the interpretation of raw signals and other feature supplementation was the highest for predicting 20 classes. The addition of entropy-based features and QRS complexes improved accuracy on average by 6.3%.
Although modules interpreting entropy-based features proved to be, on average, the least accurate models, it is worth noting that these modules were also the simplest, consisting of merely two fully-connected layers. The simplicity of these modules caused by their minimal architecture consisting of only two layers makes their performance impressive, especially for two classes, where QRS entropy achieved on average 86.5% accuracy. Combining this with the fact that the best network in every task used entropy-based features suggests an informational benefit of these metrics.
Their complementation with the base signal may be caused by their different approach to signal interpretation. Convolutional neural networks are designed to extract the information encoded in values of signal samples, their relationship with each other, and the overall shape of the signal. However, entropies are measures of signal predictability, order, and how deterministic they are. These are different ways of extracting information, making them a proper supplementation for signal processing neural networks. The authors plan further research of this phenomenon on other signals.
The entropy-based features extracted from QRS complexes turned out to be better at encoding class-specific information compared to entropy measures of the raw signal. This is a surprising observation. The authors speculated a priori that these entropy-based features would have been less significant than entropy measures conducted on the raw signal due to the structural self-repetitiveness caused by QRS complexes.
R-peak detectors vary in their effectiveness. However, the proposed method of aggregating their results and cross-validating them across signals from several leads simultaneously significantly improves the precision of R-peak detection. In the extracted QRS, the R-peak is not always aligned in the center of the signal’s subsection, which was the authors’ initial goal. This is because the R waves are not at constant distances and the fact that the position of the R wave is determined globally for all 12 leads, which means that for specific leads, especially the extreme ones, a shift may occur.
The methods employed in this research for entropy-based feature calculations and R wave detection have limitations of use due to their computational complexity and non-vectorized code. Therefore, the authors plan to research this subject further to minimize unnecessary computations and vectorize the code, allowing it to use highly optimized computation frameworks such as PyTorch.
The artificial intelligence systems investigated in this article may benefit from feature selection. This procedure may reduce the computational complexity of the networks by calculating only selected entropy metrics (in both raw entropy and QRS complex entropy modules). For example, in [
65], the authors applied the Feature Correlation technique to determine useful features in input data. This technique may reduce the amount of required entropy features computation with minimal loss inaccuracy. The authors plan further research on this topic.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}