
AttendAffectNet–Emotion Prediction of Movie Viewers Using Multimodal Fusion with Self-Attention


Abstract
:1. Introduction
2. Literature Review
2.1. Emotion Representation Models
2.2. Multimodal Representations for Emotion Prediction
2.2.1. Video Modality
2.2.2. Audio Modality
2.2.3. Text Modality
2.3. Multimodal Emotion Prediction Models
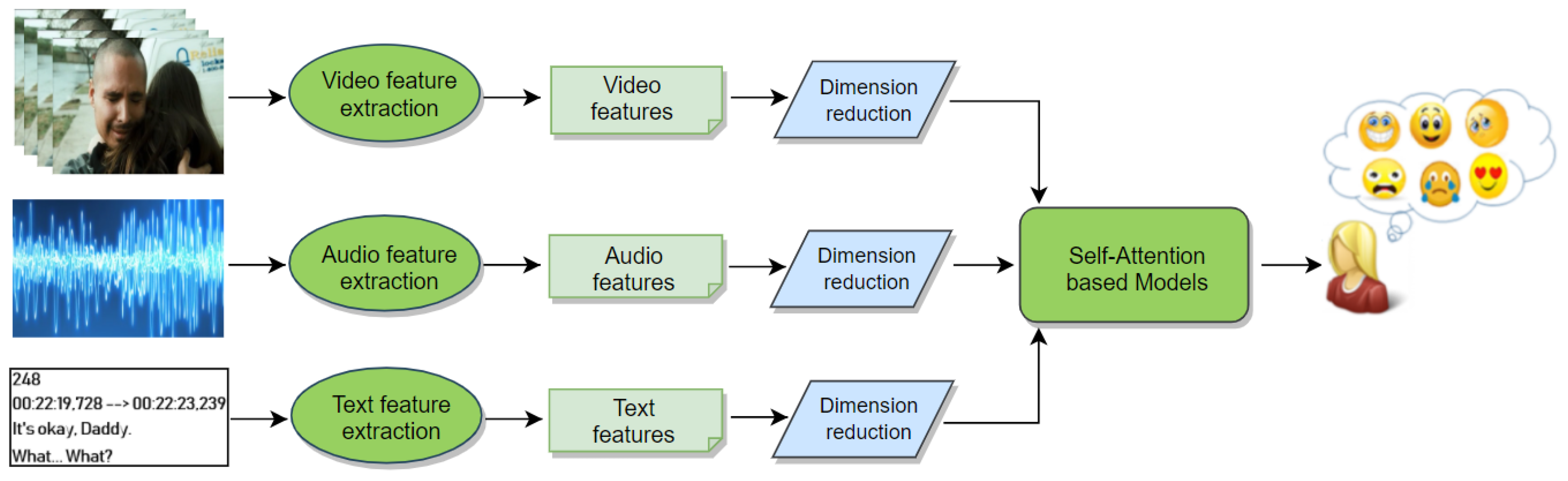
3. Multimodal Feature Extraction
3.1. Visual Features
3.2. Audio Features
3.3. Text Features
4. Proposed AttendAffectNet Model
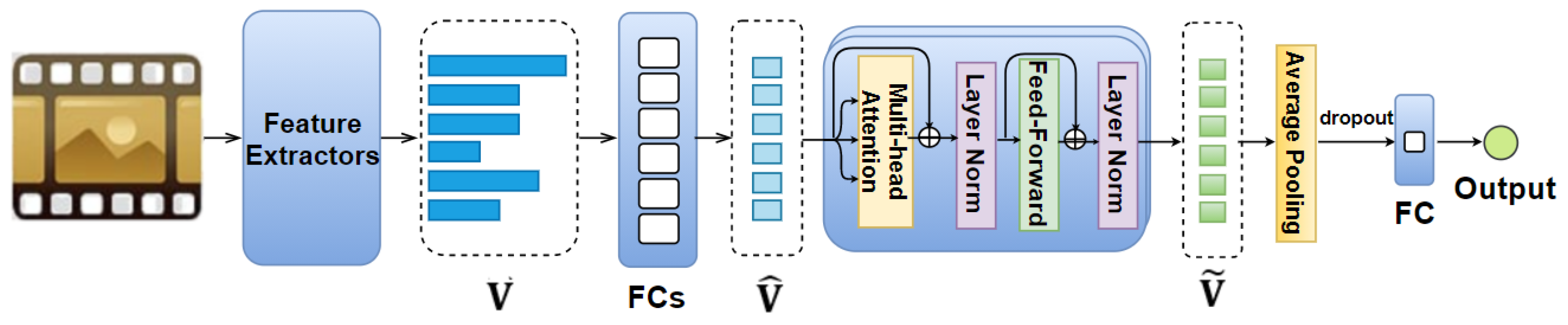
4.1. Feature AttendAffectNet Model
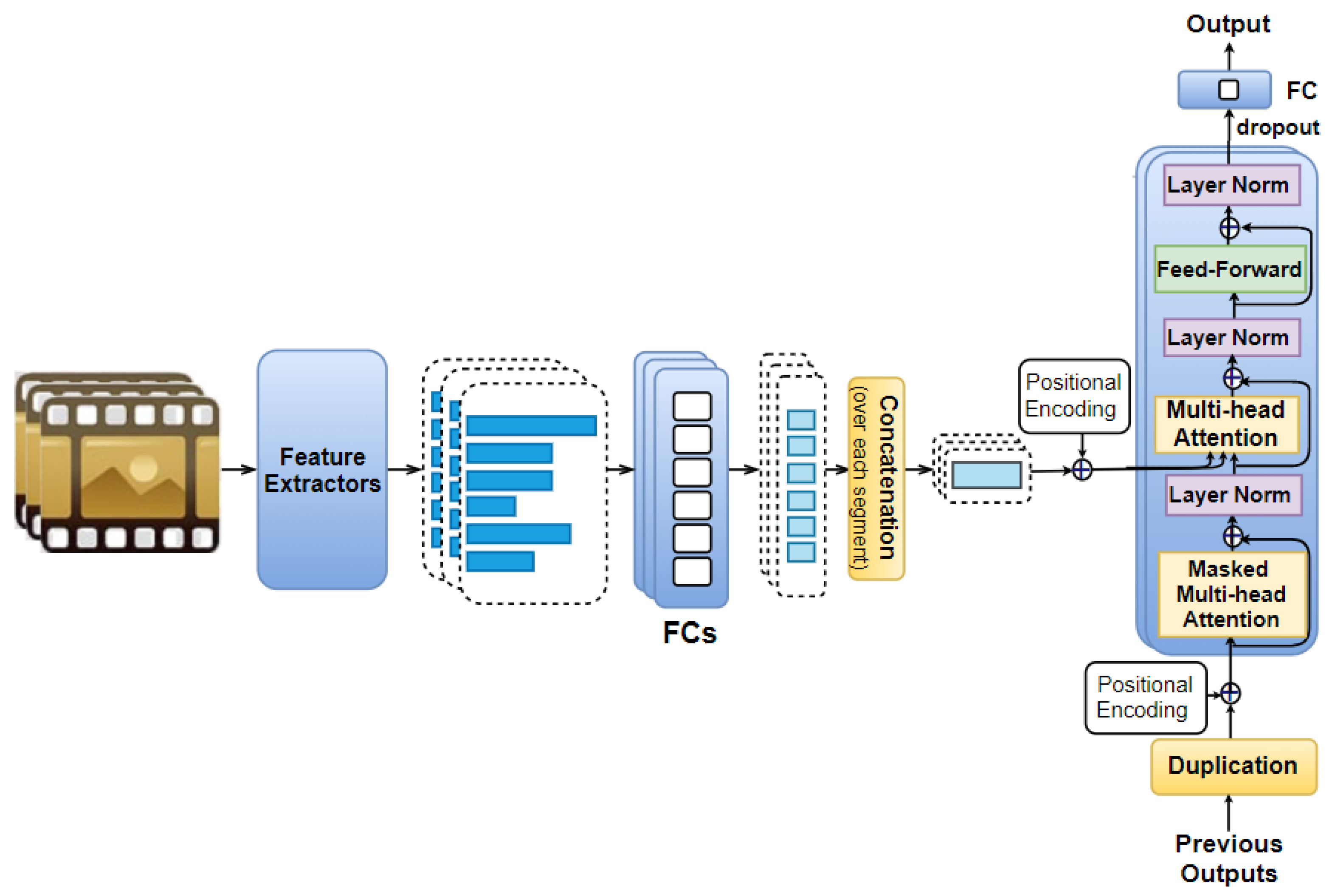
4.2. Temporal AttendAffectNet Model
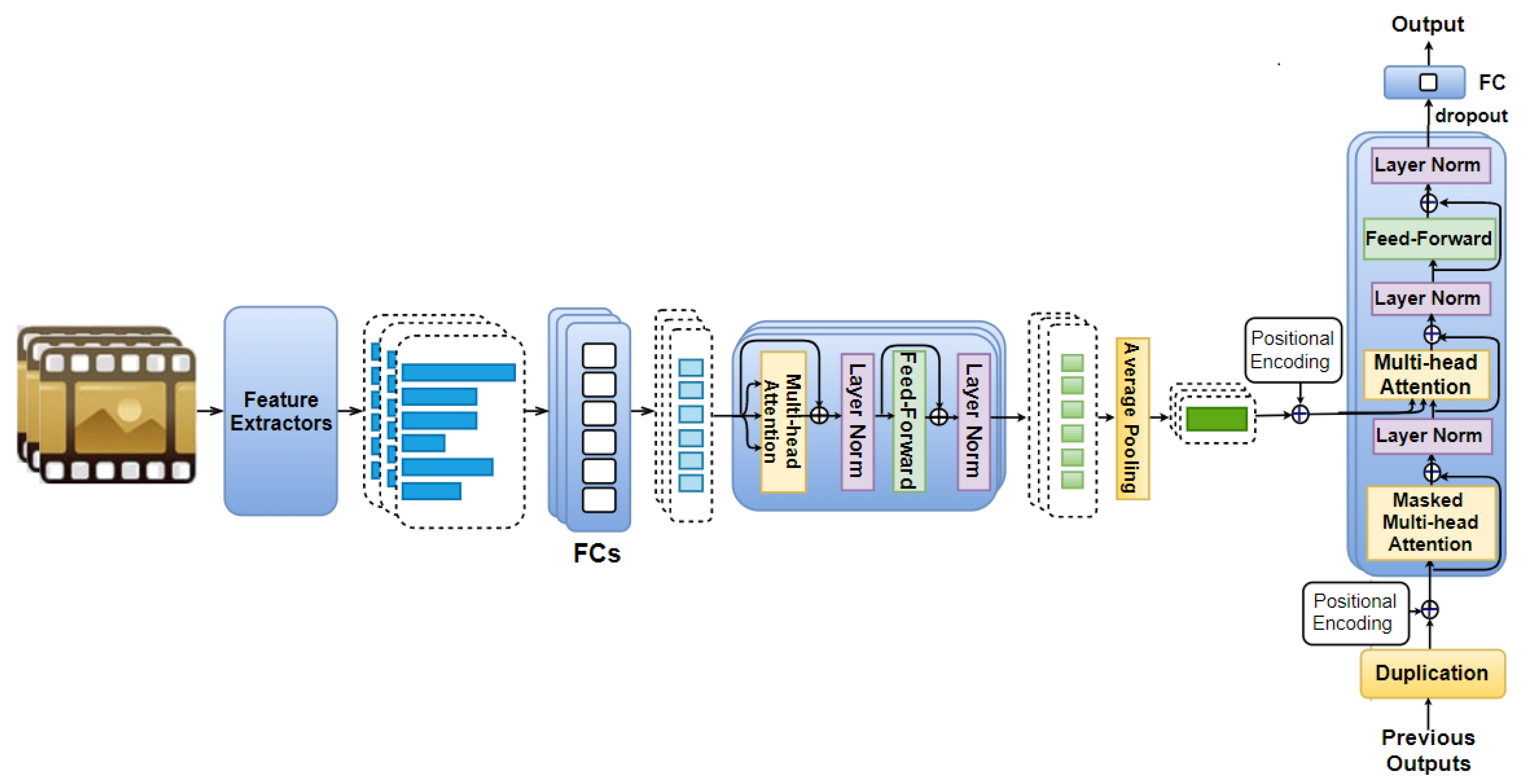
4.3. Mixed AttendAffectNet Model
5. Experimental Set-Up
5.1. Datasets
5.1.1. Extended COGNIMUSE Dataset
5.1.2. EIMT16 Dataset
5.2. Implementation Details
5.2.1. Data Preprocessing
5.2.2. Training Details
6. Experimental Results
6.1. Proposed Model Performance and Influence of Modalities
6.2. Comparison with State-of-the-Art Models
6.2.1. Comparison with Baseline Models
6.2.2. Comparison to Previously Proposed Models
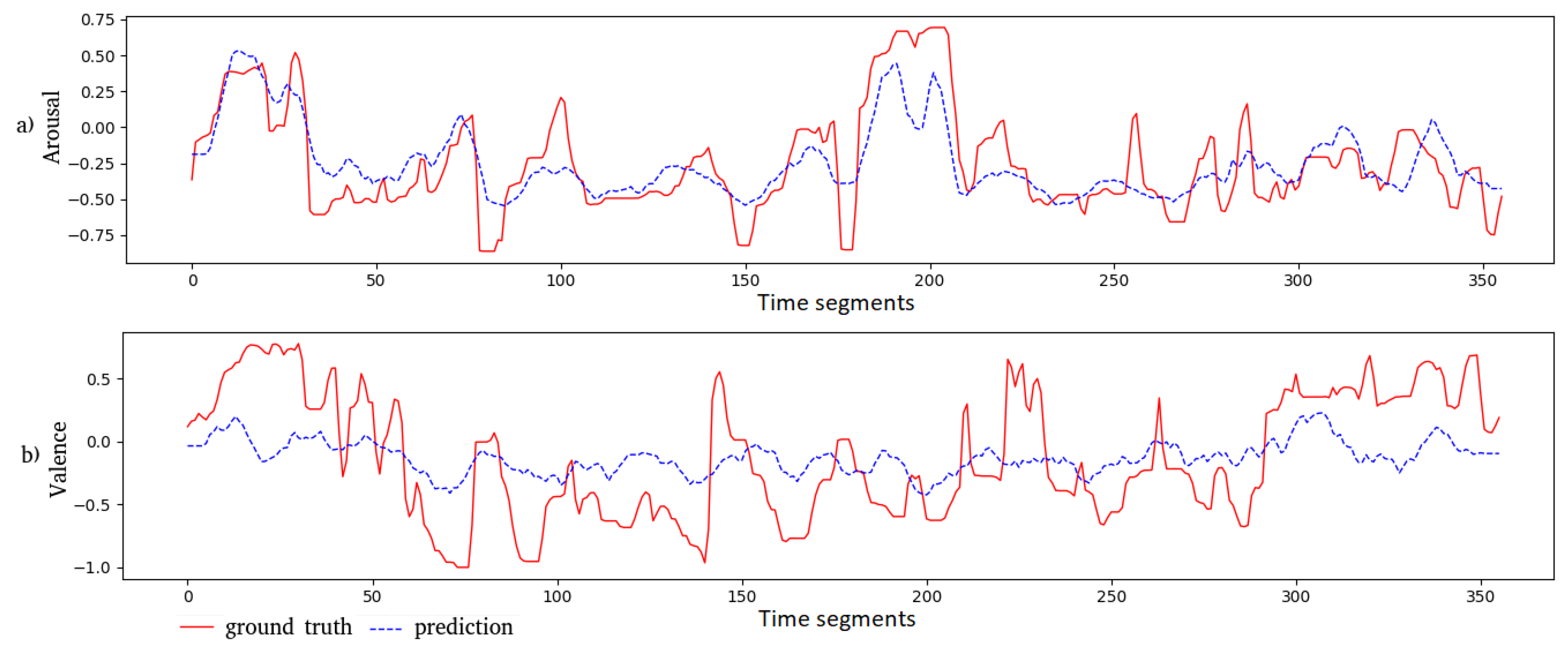
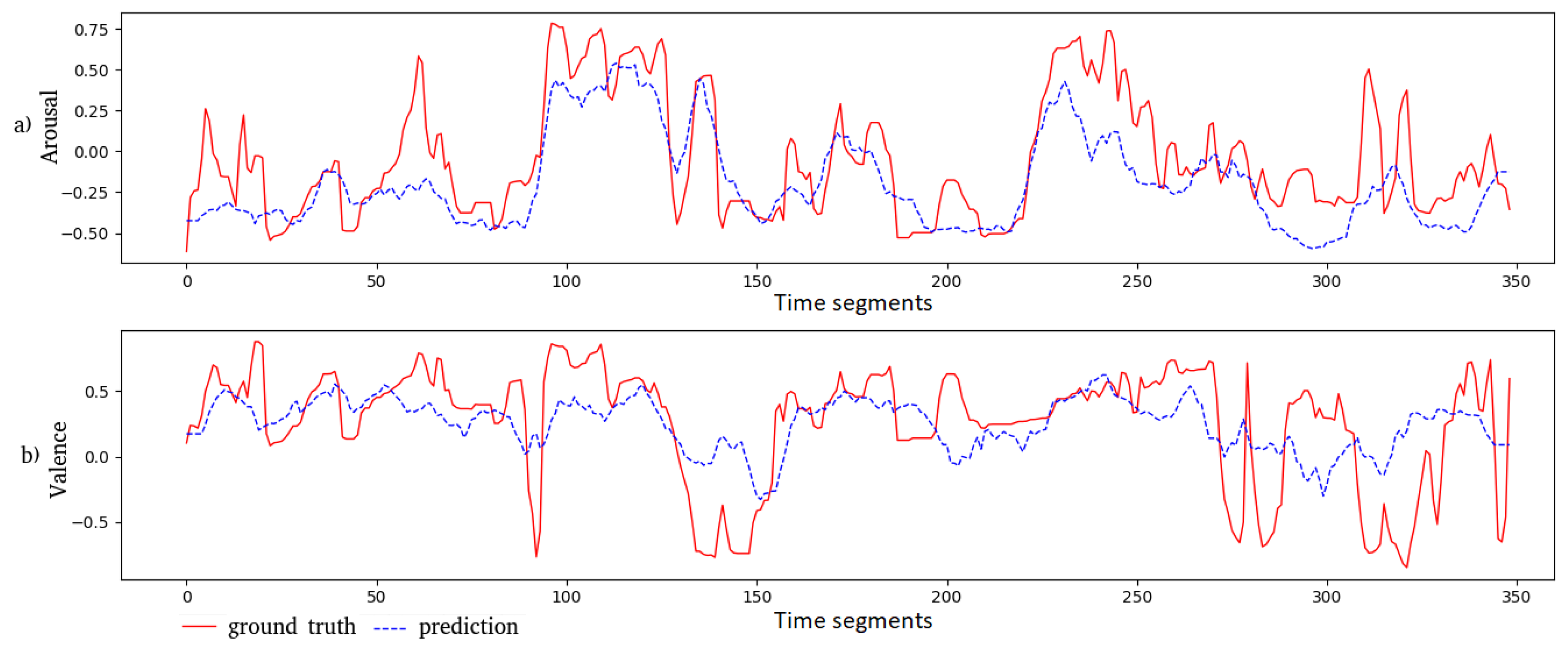
6.3. Illustration of the Predicted Values
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chambel, T.; Oliveira, E.; Martins, P. Being happy, healthy and whole watching movies that affect our emotions. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Memphis, TN, USA, 9–12 October 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 35–45. [Google Scholar]
- Gross, J.J.; Levenson, R.W. Emotion elicitation using films. Cogn. Emot. 1995, 9, 87–108. [Google Scholar] [CrossRef]
- Bartsch, A.; Appel, M.; Storch, D. Predicting emotions and meta-emotions at the movies: The role of the need for affect in audiences’ experience of horror and drama. Commun. Res. 2010, 37, 167–190. [Google Scholar] [CrossRef]
- Visch, V.T.; Tan, E.S.; Molenaar, D. The emotional and cognitive effect of immersion in film viewing. Cogn. Emot. 2010, 24, 1439–1445. [Google Scholar] [CrossRef]
- Fernández-Aguilar, L.; Navarro-Bravo, B.; Ricarte, J.; Ros, L.; Latorre, J.M. How effective are films in inducing positive and negative emotional states? A meta-analysis. PLoS ONE 2019, 14, e0225040. [Google Scholar] [CrossRef]
- Jaquet, L.; Danuser, B.; Gomez, P. Music and felt emotions: How systematic pitch level variations affect the experience of pleasantness and arousal. Psychol. Music 2014, 42, 51–70. [Google Scholar] [CrossRef] [Green Version]
- Hu, P.; Cai, D.; Wang, S.; Yao, A.; Chen, Y. Learning supervised scoring ensemble for emotion recognition in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 553–560. [Google Scholar]
- Ebrahimi Kahou, S.; Michalski, V.; Konda, K.; Memisevic, R.; Pal, C. Recurrent neural networks for emotion recognition in video. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 467–474. [Google Scholar]
- Kahou, S.E.; Bouthillier, X.; Lamblin, P.; Gulcehre, C.; Michalski, V.; Konda, K.; Jean, S.; Froumenty, P.; Dauphin, Y.; Boulanger-Lewandowski, N.; et al. Emonets: Multimodal deep learning approaches for emotion recognition in video. J. Multimodal User Interfaces 2016, 10, 99–111. [Google Scholar] [CrossRef] [Green Version]
- Kahou, S.E.; Pal, C.; Bouthillier, X.; Froumenty, P.; Gülçehre, Ç.; Memisevic, R.; Vincent, P.; Courville, A.; Bengio, Y.; Ferrari, R.C.; et al. Combining modality specific deep neural networks for emotion recognition in video. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction, Sydney, Australia, 9–13 December 2013; pp. 543–550. [Google Scholar]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio-visual emotion recognition in video clips. IEEE Trans. Affect. Comput. 2017, 10, 60–75. [Google Scholar] [CrossRef]
- Khorrami, P.; Le Paine, T.; Brady, K.; Dagli, C.; Huang, T.S. How deep neural networks can improve emotion recognition on video data. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 619–623. [Google Scholar]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Liu, C.; Tang, T.; Lv, K.; Wang, M. Multi-feature based emotion recognition for video clips. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 630–634. [Google Scholar]
- Sivaprasad, S.; Joshi, T.; Agrawal, R.; Pedanekar, N. Multimodal continuous prediction of emotions in movies using long short-term memory networks. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 413–419. [Google Scholar]
- Liu, Y.; Gu, Z.; Zhang, Y.; Liu, Y. Mining Emotional Features of Movies. In Proceedings of the MediaEval, Hilversum, The Netherlands, 20–21 October 2016. [Google Scholar]
- Chen, S.; Jin, Q. RUC at MediaEval 2016 Emotional Impact of Movies Task: Fusion of Multimodal Features. In Proceedings of the MediaEval, Hilversum, The Netherlands, 20–21 October 2016. [Google Scholar]
- Yi, Y.; Wang, H. Multi-modal learning for affective content analysis in movies. Multimed. Tools Appl. 2019, 78, 13331–13350. [Google Scholar] [CrossRef]
- Goyal, A.; Kumar, N.; Guha, T.; Narayanan, S.S. A multimodal mixture-of-experts model for dynamic emotion prediction in movies. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2822–2826. [Google Scholar]
- Ma, Y.; Ye, Z.; Xu, M. THU-HCSI at MediaEval 2016: Emotional Impact of Movies Task. In Proceedings of the MediaEval, Hilversum, The Netherlands, 20–21 October 2016. [Google Scholar]
- Thi Phuong Thao, H.; Herremans, D.; Roig, G. Multimodal Deep Models for Predicting Affective Responses Evoked by Movies. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Thao, H.T.P.; Balamurali, B.; Herremans, D.; Roig, G. AttendAffectNet: Self-Attention based Networks for Predicting Affective Responses from Movies. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8719–8726. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Lian, Z.; Li, Y.; Tao, J.; Huang, J. Improving speech emotion recognition via transformer-based predictive coding through transfer learning. arXiv 2018, arXiv:1811.07691. [Google Scholar]
- Makris, D.; Agres, K.R.; Herremans, D. Generating lead sheets with affect: A novel conditional seq2seq framework. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Online, 18–22 July 2021. [Google Scholar]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video action transformer network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 244–253. [Google Scholar]
- Fu, X.; Gao, F.; Wu, J.; Wei, X.; Duan, F. Spatiotemporal Attention Networks for Wind Power Forecasting. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 149–154. [Google Scholar]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Dellandréa, E.; Huigsloot, M.; Chen, L.; Baveye, Y.; Sjöberg, M. The MediaEval 2016 Emotional Impact of Movies Task. In Proceedings of the MediaEval, Hilversum, The Netherlands, 20–21 October 2016. [Google Scholar]
- Malandrakis, N.; Potamianos, A.; Evangelopoulos, G.; Zlatintsi, A. A supervised approach to movie emotion tracking. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–23 May 2011; pp. 2376–2379. [Google Scholar]
- Zlatintsi, A.; Koutras, P.; Evangelopoulos, G.; Malandrakis, N.; Efthymiou, N.; Pastra, K.; Potamianos, A.; Maragos, P. COGNIMUSE: A multimodal video database annotated with saliency, events, semantics and emotion with application to summarization. EURASIP J. Image Video Process. 2017, 2017, 54. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Eyben, F. Real-Time Speech and Music Classification by Large Audio Feature Space Extraction; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 19–27. [Google Scholar]
- Kanade, T. Facial Expression Analysis. In Proceedings of the Second International Conference on Analysis and Modelling of Faces and Gestures, Beijing, China, 16 October 2005; Springer: Berlin/Heidelberg, Germany, 2005; p. 1. [Google Scholar] [CrossRef]
- Cohn, J.F.; Torre, F.D.L. Automated Face Analysis for Affective Computing. In The Oxford Handbook of Affective Computing; Calvo, R.A., D’Mello, S.K., Gratch, J., Kappas, A., Eds.; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Sikka, K.; Sharma, G.; Bartlett, M. Lomo: Latent ordinal model for facial analysis in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5580–5589. [Google Scholar]
- Fan, Y.; Lam, J.C.; Li, V.O. Multi-region ensemble convolutional neural network for facial expression recognition. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 84–94. [Google Scholar]
- Valstar, M.F.; Jiang, B.; Mehu, M.; Pantic, M.; Scherer, K. The first facial expression recognition and analysis challenge. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–25 March 2011; pp. 921–926. [Google Scholar]
- Baddar, W.J.; Lee, S.; Ro, Y.M. On-the-fly facial expression prediction using lstm encoded appearance-suppressed dynamics. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Yi, Y.; Wang, H.; Li, Q. Affective Video Content Analysis with Adaptive Fusion Recurrent Network. IEEE Trans. Multimed. 2019, 22, 2454–2466. [Google Scholar] [CrossRef]
- Osgood, C.E.; May, W.H.; Miron, M.S.; Miron, M.S. Cross-Cultural Universals of Affective Meaning; University of Illinois Press: Urbana, IL, USA, 1975; Volume 1. [Google Scholar]
- Lang, P.J. Cognition in emotion: Concept and action. Emot. Cogn. Behav. 1984, 191, 228. [Google Scholar]
- Ekman, P. Basic emotions. Handb. Cogn. Emot. 1999, 98, 16. [Google Scholar]
- Colombetti, G. From affect programs to dynamical discrete emotions. Philos. Psychol. 2009, 22, 407–425. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P.; Sorenson, E.R.; Friesen, W.V. Pan-cultural elements in facial displays of emotion. Science 1969, 164, 86–88. [Google Scholar] [CrossRef] [Green Version]
- Cowen, A.S.; Keltner, D. Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proc. Natl. Acad. Sci. USA 2017, 114, E7900–E7909. [Google Scholar] [CrossRef] [Green Version]
- Zentner, M.; Grandjean, D.; Scherer, K.R. Emotions evoked by the sound of music: Characterization, classification, and measurement. Emotion 2008, 8, 494. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bradley, M.M.; Greenwald, M.K.; Petry, M.C.; Lang, P.J. Remembering pictures: Pleasure and arousal in memory. J. Exp. Psychol. Learn. Mem. Cogn. 1992, 18, 379. [Google Scholar] [CrossRef]
- Watson, D.; Tellegen, A. Toward a consensual structure of mood. Psychol. Bull. 1985, 98, 219. [Google Scholar] [CrossRef]
- Watson, D.; Wiese, D.; Vaidya, J.; Tellegen, A. The two general activation systems of affect: Structural findings, evolutionary considerations, and psychobiological evidence. J. Personal. Soc. Psychol. 1999, 76, 820. [Google Scholar] [CrossRef]
- Feldman Barrett, L.; Russell, J.A. Independence and bipolarity in the structure of current affect. J. Personal. Soc. Psychol. 1998, 74, 967. [Google Scholar] [CrossRef]
- Greenwald, M.K.; Cook, E.W.; Lang, P.J. Affective judgment and psychophysiological response: Dimensional covariation in the evaluation of pictorial stimuli. J. Psychophysiol. 1989, 3, 51–64. [Google Scholar]
- Hanjalic, A.; Xu, L.Q. Affective video content representation and modeling. IEEE Trans. Multimed. 2005, 7, 143–154. [Google Scholar] [CrossRef] [Green Version]
- Hanjalic, A. Extracting moods from pictures and sounds: Towards truly personalized TV. IEEE Signal Process. Mag. 2006, 23, 90–100. [Google Scholar] [CrossRef]
- Baveye, Y.; Dellandrea, E.; Chamaret, C.; Chen, L. Liris-accede: A video database for affective content analysis. IEEE Trans. Affect. Comput. 2015, 6, 43–55. [Google Scholar] [CrossRef] [Green Version]
- Cheuk, K.W.; Luo, Y.J.; Balamurali, B.; Roig, G.; Herremans, D. Regression-based music emotion prediction using triplet neural networks. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Herremans, D.; Yang, S.; Chuan, C.H.; Barthet, M.; Chew, E. Imma-emo: A multimodal interface for visualising score-and audio-synchronised emotion annotations. In Proceedings of the 12th International Audio Mostly Conference on Augmented and Participatory Sound and Music Experiences, London, UK, 23–26 August 2017; pp. 1–8. [Google Scholar]
- Carvalho, S.; Leite, J.; Galdo-Álvarez, S.; Gonçalves, Ó.F. The emotional movie database (EMDB): A self-report and psychophysiological study. Appl. Psychophysiol. Biofeedback 2012, 37, 279–294. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Correa, J.A.M.; Abadi, M.K.; Sebe, N.; Patras, I. Amigos: A dataset for affect, personality and mood research on individuals and groups. IEEE Trans. Affect. Comput. 2018, 12, 479–493. [Google Scholar] [CrossRef] [Green Version]
- Snoek, C.G.; Worring, M.; Smeulders, A.W. Early versus late fusion in semantic video analysis. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 399–402. [Google Scholar]
- Zheng, Z.; Cao, C.; Chen, X.; Xu, G. Multimodal Emotion Recognition for One-Minute-Gradual Emotion Challenge. arXiv 2018, arXiv:1805.01060. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Carrier, P.L.; Courville, A.; Goodfellow, I.J.; Mirza, M.; Bengio, Y. FER-2013 Face Database; Universit de Montral: Montréal, QC, Canada, 2013. [Google Scholar]
- Guo, X.; Zhong, W.; Ye, L.; Fang, L.; Heng, Y.; Zhang, Q. Global Affective Video Content Regression Based on Complementary Audio-Visual Features. In Proceedings of the International Conference on Multimedia Modeling, Daejeon, Korea, 5–8 January 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 540–550. [Google Scholar]
- Baveye, Y.; Dellandréa, E.; Chamaret, C.; Chen, L. Deep learning vs. kernel methods: Performance for emotion prediction in videos. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 77–83. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. In Techniques and Applications of Image Understanding; International Society for Optics and Photonics: Washington, DC, USA, 1981; Volume 281, pp. 319–331. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Liu, L.; Shao, L.; Li, X.; Lu, K. Learning spatio-temporal representations for action recognition: A genetic programming approach. IEEE Trans. Cybern. 2015, 46, 158–170. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Cherian, A.; Porikli, F. Ordered pooling of optical flow sequences for action recognition. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 168–176. [Google Scholar]
- Mase, K. Recognition of facial expression from optical flow. IEICE Trans. Inf. Syst. 1991, 74, 3474–3483. [Google Scholar]
- Tariq, U.; Lin, K.H.; Li, Z.; Zhou, X.; Wang, Z.; Le, V.; Huang, T.S.; Lv, X.; Han, T.X. Emotion recognition from an ensemble of features. In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–25 March 2011; pp. 872–877. [Google Scholar]
- Anderson, K.; McOwan, P.W. A real-time automated system for the recognition of human facial expressions. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2006, 36, 96–105. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Taylor, G.W.; Fergus, R.; LeCun, Y.; Bregler, C. Convolutional learning of spatio-temporal features. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 140–153. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards good practices for very deep two-stream convnets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6047–6056. [Google Scholar]
- Meyer, B.L. Emotion and Meaning in Music. J. Music. Theory 2008, 16. [Google Scholar] [CrossRef]
- Panksepp, J.; Bernatzky, G. Emotional sounds and the brain: The neuro-affective foundations of musical appreciation. Behav. Process. 2002, 60, 133–155. [Google Scholar] [CrossRef] [Green Version]
- Doughty, K.; Duffy, M.; Harada, T. Practices of Emotional and Affective Geographies of Sound; University of Wollongong: Wollongong, Australia, 2016. [Google Scholar]
- Herremans, D.; Chew, E. Tension ribbons: Quantifying and visualising tonal tension. In Proceedings of the Second International Conference on Technologies for Music Notation and Representation (TENOR), Cambridge, UK, 27–29 May 2016. [Google Scholar]
- Kalyan, C.; Kim, M.Y. Detecting Emotional Scenes Using Semantic Analysis on Subtitles; Academic Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Aytar, Y.; Vondrick, C.; Torralba, A. Soundnet: Learning sound representations from unlabeled video. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 892–900. [Google Scholar]
- Mathieu, B.; Essid, S.; Fillon, T.; Prado, J.; Richard, G. YAAFE, an Easy to Use and Efficient Audio Feature Extraction Software. In Proceedings of the 11th International Society for Music Information Retrieval Conference (ISMIR), Utrecht, The Netherlands, 9–13 August 2010; pp. 441–446. [Google Scholar]
- Jiang, W.; Wang, Z.; Jin, J.S.; Han, X.; Li, C. Speech Emotion Recognition with Heterogeneous Feature Unification of Deep Neural Network. Sensors 2019, 19, 2730. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Chia, L.T.; Yi, H.; Rajan, D. Affective content detection in sitcom using subtitle and audio. In Proceedings of the 2006 12th International Multi-Media Modelling Conference, Beijing, China, 4–6 January 2006. [Google Scholar]
- Soleymani, M.; Kierkels, J.J.; Chanel, G.; Pun, T. A bayesian framework for video affective representation. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–7. [Google Scholar]
- Polyanskaya, L. Multimodal Emotion Recognition for Video Content. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2019. [Google Scholar]
- Kayhani, A.K.; Meziane, F.; Chiky, R. Movies emotional analysis using textual contents. In Proceedings of the International Conference on Applications of Natural Language to Information Systems, Saarbrucken, Germany, 23–25 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 205–212. [Google Scholar]
- Hinton, G.E. Learning distributed representations of concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, Amherst, MA, USA, 15–17 August 1986; Volume 1, p. 12. [Google Scholar]
- Turian, J.; Ratinov, L.; Bengio, Y. Word representations: A simple and general method for semi-supervised learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 384–394. [Google Scholar]
- Li, Y.; Yang, T. Word embedding for understanding natural language: A survey. In Guide to Big Data Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 83–104. [Google Scholar]
- Thada, V.; Singh, J. A Primer on Word Embedding. Data Intell. Cogn. Inform. 2021, 525–541. [Google Scholar]
- Chowdhury, H.A.; Imon, M.A.H.; Islam, M.S. A comparative analysis of word embedding representations in authorship attribution of bengali literature. In Proceedings of the 2018 21st International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2018; pp. 1–6. [Google Scholar]
- Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets; Cambridge University Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Wang, L. Support Vector Machines: Theory and Applications; Springer Science & Business Media: New York, NY, USA, 2005; Volume 177. [Google Scholar]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and word2vec for text classification with semantic features. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCI* CC), Beijing, China, 6–8 July 2015; pp. 136–140. [Google Scholar]
- Iyyer, M.; Boyd-Graber, J.; Claudino, L.; Socher, R.; Daumé III, H. A neural network for factoid question answering over paragraphs. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 633–644. [Google Scholar]
- Budhkar, A.; Vishnubhotla, K.; Hossain, S.; Rudzicz, F. Generative Adversarial Networks for text using word2vec intermediaries. arXiv 2019, arXiv:1904.02293. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised sequence learning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3079–3087. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning; Technical Report; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Yu, P.S. BERT post-training for review reading comprehension and aspect-based sentiment analysis. arXiv 2019, arXiv:1904.02232. [Google Scholar]
- Sun, C.; Huang, L.; Qiu, X. Utilizing BERT for aspect-based sentiment analysis via constructing auxiliary sentence. arXiv 2019, arXiv:1903.09588. [Google Scholar]
- Gao, Z.; Feng, A.; Song, X.; Wu, X. Target-dependent sentiment classification with BERT. IEEE Access 2019, 7, 154290–154299. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Hussain, A.; Huang, G.B. Towards an intelligent framework for multimodal affective data analysis. Neural Netw. 2015, 63, 104–116. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, J.; Fan, J.; Tao, D. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1821–1830. [Google Scholar]
- Peng, Y.; Qi, J.; Huang, X.; Yuan, Y. CCL: Cross-modal correlation learning with multigrained fusion by hierarchical network. IEEE Trans. Multimed. 2017, 20, 405–420. [Google Scholar] [CrossRef] [Green Version]
- Levi, G.; Hassner, T. Emotion recognition in the wild via convolutional neural networks and mapped binary patterns. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 503–510. [Google Scholar]
- Kaya, H.; Gürpınar, F.; Salah, A.A. Video-based emotion recognition in the wild using deep transfer learning and score fusion. Image Vis. Comput. 2017, 65, 66–75. [Google Scholar] [CrossRef]
- Wang, Y. Survey on deep multi-modal data analytics: Collaboration, rivalry, and fusion. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–25. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Wu, L.; Lin, X.; Fang, M.; Pan, S. Iterative views agreement: An iterative low-rank based structured optimization method to multi-view spectral clustering. arXiv 2016, arXiv:1608.05560. [Google Scholar]
- Wang, Y.; Zhang, W.; Wu, L.; Lin, X.; Zhao, X. Unsupervised metric fusion over multiview data by graph random walk-based cross-view diffusion. IEEE Trans. Neural Netw. Learn. Syst. 2015, 28, 57–70. [Google Scholar] [CrossRef] [PubMed]
- Witten, I.H.; Frank, E. Data mining: Practical machine learning tools and techniques with Java implementations. ACM Sigmod Rec. 2002, 31, 76–77. [Google Scholar] [CrossRef]
- Tang, G.; Müller, M.; Rios, A.; Sennrich, R. Why self-attention? A targeted evaluation of neural machine translation architectures. arXiv 2018, arXiv:1808.08946. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Eyben, F.; Weninger, F.; Wöllmer, M.; Shuller, B. Open-Source Media Interpretation by Large Feature-Space Extraction; TU Munchen, MMK: Munchen, Germany, 2016. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.; Narayanan, S.S. The Interspeech 2010 paralinguistic challenge. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder–decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models (Only Video) | Extended COGNIMUSE (Intended Emotion) | Global EIMT16 (Expected Emotion) | ||||||
|---|---|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | |||||
| MSE | PCC | MSE | PCC | MSE | PCC | MSE | PCC | |
| Feature AAN | 0.152 | 0.518 | 0.204 | 0.483 | 0.933 | 0.350 | 0.764 | 0.342 |
| Temporal AAN | 0.178 | 0.457 | 0.267 | 0.232 | 1.182 | 0.151 | 0.256 | 0.190 |
| Mixed AAN | 0.225 | 0.199 | 0.269 | 0.151 | 1.653 | 0.152 | 0.234 | 0.146 |
| 2FC-layer model | 0.349 | 0.189 | 0.333 | 0.171 | 1.501 | 0.338 | 0.428 | 0.233 |
| 2-layer LSTM model | 0.323 | 0.054 | 0.338 | 0.088 | 3.442 | 0.053 | 0.503 | 0.037 |
| Models (Only Audio) | Extended COGNIMUSE (Intended Emotion) | Global EIMT16 (Expected Emotion) | ||||||
|---|---|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | |||||
| MSE | PCC | MSE | PCC | MSE | PCC | MSE | PCC | |
| Feature AAN | 0.125 | 0.621 | 0.185 | 0.543 | 1.111 | 0.397 | 0.209 | 0.327 |
| Temporal AAN | 0.162 | 0.472 | 0.247 | 0.254 | 1.159 | 0.185 | 0.225 | 0.285 |
| Mixed AAN | 0.219 | 0.204 | 0.269 | 0.160 | 1.650 | 0.290 | 0.235 | 0.314 |
| 2FC-layer model | 0.299 | 0.203 | 0.299 | 0.173 | 1.533 | 0.395 | 0.368 | 0.318 |
| 2-layer LSTM model | 0.266 | 0.091 | 0.310 | 0.080 | 2.311 | 0.262 | 0.348 | 0.210 |
| Models (Only Subtitle) | Extended COGNIMUSE (Intended Emotion) | |||
|---|---|---|---|---|
| Arousal | Valence | |||
| MSE | PCC | MSE | PCC | |
| Feature AAN | 0.175 | 0.380 | 0.237 | 0.320 |
| Temporal AAN | 0.183 | 0.346 | 0.249 | 0.312 |
| Mixed AAN | 0.218 | 0.147 | 0.286 | 0.173 |
| 2FC-layer model | 0.344 | 0.171 | 0.345 | 0.210 |
| 2-layer LSTM model | 0.325 | 0.058 | 0.388 | 0.053 |
| Models (Video and Audio) | Extended COGNIMUSE (Intended Emotion) | Global EIMT16 (Expected Emotion) | ||||||
|---|---|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | |||||
| MSE | PCC | MSE | PCC | MSE | PCC | MSE | PCC | |
| Feature AAN | 0.124 | 0.630 | 0.178 | 0.572 | 0.742 | 0.503 | 0.185 | 0.467 |
| Temporal AAN | 0.153 | 0.551 | 0.238 | 0.319 | 0.854 | 0.210 | 0.218 | 0.415 |
| Mixed AAN | 0.217 | 0.251 | 0.285 | 0.270 | 1.556 | 0.318 | 0.234 | 0.341 |
| 2FC-layer model | 0.293 | 0.228 | 0.284 | 0.217 | 0.989 | 0.500 | 0.276 | 0.372 |
| 2-layer LSTM model | 0.247 | 0.083 | 0.301 | 0.092 | 2.222 | 0.254 | 0.303 | 0.208 |
| Sivaprasad et al. [15] | ||||||||
| (audio and video, FS) | 0.08 | 0.84 | 0.21 | 0.50 | - | - | - | - |
| Yi et al. [18] | - | - | - | - | 1.173 | 0.446 | 0.198 | 0.399 |
| Chen et al. [17] | - | - | - | - | 1.479 | 0.467 | 0.201 | 0.419 |
| Liu et al. [16] | - | - | - | - | 1.182 | 0.212 | 0.236 | 0.379 |
| Guo et al. [69] | - | - | - | - | 0.543 | 0.459 | 0.209 | 0.326 |
| Yi et al. [45] | - | - | - | - | 0.542 | 0.522 | 0.193 | 0.468 |
| Models (Video, Audio, and Subtitle) | Extended COGNIMUSE (Intended Emotion) | |||
|---|---|---|---|---|
| Arousal | Valence | |||
| MSE | PCC | MSE | PCC | |
| Feature AAN | 0.117 | 0.655 | 0.170 | 0.575 |
| Temporal AAN | 0.149 | 0.560 | 0.226 | 0.387 |
| Mixed AAN | 0.198 | 0.310 | 0.267 | 0.275 |
| 2FC-layer model | 0.289 | 0.229 | 0.283 | 0.227 |
| 2-layer LSTM model | 0.223 | 0.080 | 0.277 | 0.119 |
| Model Including Only FC Layers | Extended COGNIMUSE (Intended Emotion) | Global EIMT16 (Expected Emotion) | ||||||
|---|---|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | |||||
| MSE | PCC | MSE | PCC | MSE | PCC | MSE | PCC | |
| Only Video | 0.186 | 0.426 | 0.247 | 0.372 | 0.999 | 0.308 | 0.477 | 0.207 |
| Only Audio | 0.163 | 0.489 | 0.235 | 0.461 | 0.896 | 0.344 | 0.219 | 0.246 |
| Both Video and Audio | 0.162 | 0.503 | 0.210 | 0.498 | 0.757 | 0.478 | 0.199 | 0.418 |
| Only Text | 0.184 | 0.391 | 0.249 | 0.367 | - | - | - | - |
| Video, Audio and Text | 0.154 | 0.574 | 0.183 | 0.560 | - | - | - | - |
| Model with 2-Layer LSTM | Extended COGNIMUSE (Intended Emotion) | Global EIMT16 (Expected Emotion) | ||||||
|---|---|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | |||||
| MSE | PCC | MSE | PCC | MSE | PCC | MSE | PC | |
| Only Video | 0.193 | 0.255 | 0.277 | 0.398 | 1.431 | 0.343 | 0.232 | 0.179 |
| Only Audio | 0.167 | 0.483 | 0.241 | 0.422 | 1.413 | 0.340 | 0.231 | 0.289 |
| Both Video and Audio | 0.231 | 0.531 | 0.285 | 0.492 | 1.354 | 0.420 | 0.228 | 0.322 |
| Only Text | 0.197 | 0.220 | 0.263 | 0.210 | - | - | - | - |
| Video, Audio and Text | 0.152 | 0.554 | 0.253 | 0.542 | - | - | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thao, H.T.P.; Balamurali, B.T.; Roig, G.; Herremans, D. AttendAffectNet–Emotion Prediction of Movie Viewers Using Multimodal Fusion with Self-Attention. Sensors 2021, 21, 8356. https://doi.org/10.3390/s21248356
Thao HTP, Balamurali BT, Roig G, Herremans D. AttendAffectNet–Emotion Prediction of Movie Viewers Using Multimodal Fusion with Self-Attention. Sensors. 2021; 21(24):8356. https://doi.org/10.3390/s21248356
Chicago/Turabian StyleThao, Ha Thi Phuong, B T Balamurali, Gemma Roig, and Dorien Herremans. 2021. "AttendAffectNet–Emotion Prediction of Movie Viewers Using Multimodal Fusion with Self-Attention" Sensors 21, no. 24: 8356. https://doi.org/10.3390/s21248356
APA StyleThao, H. T. P., Balamurali, B. T., Roig, G., & Herremans, D. (2021). AttendAffectNet–Emotion Prediction of Movie Viewers Using Multimodal Fusion with Self-Attention. Sensors, 21(24), 8356. https://doi.org/10.3390/s21248356