This section will provide an overview of the architectural choices adopted by the authors in implementing this resource management approach. It will contain definitions of ambiguous terms, an analysis of possible approaches and it will offer a high-level view on the flow of the entire resource management process.
2.1. Terminology
The definition of “resource” in computer programming is not ubiquitous nor is it entirely clear. In the
Apple Developer Guide a resource is defined as “data files that accompany a program’s executable code” [
10]. Indeed, this definition is one that is commonly used in colloquial programming jargon and equates “resources” to files holding data. However, a cloud platform does not just hold data, but it also provides system resources for manipulating and handling that data. The United States National Institute of Standards and Technology defines a computing resource as “an operating system abstraction that is visible at the application program interface, has a unique name, and is capable of being shared” [
11]. It further goes on to clarify that, in the context of the document in which the definition appears, files, programs, databases and even external media are considered resources. Finally, in
The Kubernetes Resource Model (KRM), Brian Grant defines “resources” as Kubernetes pods, which are configured using YAML or JSON files [
11]. A Kubernetes pod consists of an entire Docker container, therefore making the “resource” effectively unbounded, capable of holding both data and the applications that could manipulate it. Kubernetes does not limit itself to Docker containers though, but instead offers solutions even for non-containerized applications such as object storage in the cloud or serverless operations.
We, the authors, feel that given the lack of clarity on what a “resource” is understood to mean in computer programming, a clarification needs to be made on how that term will be used in the context of this article. Hereinafter, the authors understand “resource” to mean any hardware, software or data used in the process of running an application. The broadness of the definition stems from the complexity of cloud systems, where data is not just static, but can be dynamically modified by various calls to the cloud’s API. One example of this are AWS Lambdas, chunks of code used in Serverless computing that enable developers to run an application without provisioning for it or managing servers [
12]. Lambdas can be triggered by calling any number of AWS services, from provisioning for new VMs to uploading files into S3 storage. Therefore, it stands to reason that an application which would make use of cloud storage, for example, would need to account for other types of resources used, outside of just the data storage requirements.
A “resource-management system”, therefore, needs to handle more than just balancing the loads of data upload, download or transformation from one server to another. It needs to account for the duration of time spent executing serverless or cloud-side operations. Additionally, it will need to consider if the data it manages the resources for is to be transformed upon upload or not, and if it is, what the acceptable timeframe for a response is. Based on this knowledge, we define a “resource-management system” as being an encompassing ecosystem that an application uses to carry out its business logic. It is understood that the rest of this article will accept the definitions of “resources” and “resource-management system” as defined by the authors.
2.2. Approach
There are two approaches to creating an API that manages multiple, simultaneous connections to various cloud providers: through a messaging service or as a dependency. The most common approach to working with distributed systems is Representational State Transfer, known as REST. The architectural style was first proposed by Roy Fielding and it presented a set of constraints. At the core of any RESTful service lies this set of constraints, which are treated more like suggestions and not enforcements as they would be in a SOAP architecture [
13]. The degree to which those constraints are followed indicates the application’s Richardson Maturity Model [
14], as defined in “
REST in Practice—Hypermedia and Systems Architecture” and then popularized by Martin Fowler in a 2010 article [
15]. Due to these very lax constraints only about 0.8% of web services are fully compliant with REST [
16]. Even so, the basic constraints of statelessness, usage of HTTP action verbs and data transfer structure have become synonymous with distributed computing.
Using a REST based architecture greatly reduces the onboarding or learning process for a new API. HTTP calls using basic CRUD (Create, Read, Update, Delete) commands return a predictable pattern of results. No installation or declaration of dependency is required in any one project, any API using REST can be easily scaled, HTTP is language agnostic (as are JSON and XML) and tools for documenting an API’s functionality are abundant. However, REST does have some drawbacks, the most significant of which are its statelessness and the obfuscation of internals.
Since REST is stateless, responses cannot contain resources. In the case of large media files this immediately becomes a problem because the file needs to be converted into a byte stream and then saved to file. This a costly operation, especially when resources need to be available synchronously. Furthermore, not all files are supported by MIME classification, which is widely used by REST. This leads to complications if the file is requested in a browser as the process that will implement the API will need to handle converting the file into something the end customer can see in their browser.
Finally, there is the issue of transparency. A REST API intentionally hides the implementation from the calling process (see
Figure 1). This makes the debugging process considerably more complicated. In a case where a distributed storage strategy [
16] would be employed to distribute file information over multiple clouds, debugging could become extremely complicated. Additionally, developers would be unaware during development and debugging of what is happening when they add a resource into the cloud through a REST call. This is in fact one of the biggest issues with using cloud services today, hence why solutions have been developed to debug locally. The most well-known of these is LocalStack, which mocks an AWS cluster on the developer’s local machine [
17].
The alternative to using a REST based API would be to use a library as a dependency and then call the API methods provided by that library. There is a significant caveat to this approach, specifically that an API designed to be used as a dependency is not language agnostic and needs to be declared in every project that uses it. However, this approach allows for greater visibility and customization from a development standpoint, which is why the rest of this paper will focus specifically on a more traditional, stateful implementation of a multi-cloud API.
Figure 2 shows a combination of a simplified layered architecture using agents—independently deployed applications that run on the cloud’s side—to monitor and communicate with each cloud. The API will need to provide compatibility with each of these providers separately and any others not listed. This is a common practice in many flexible ecosystems, even today, and it provides genericity and vendor agnosticism, while also allowing for customized plugins.
An example of such an architecture is Java’s JDBC API [
18], an interface layer that is used to communicate with various types of relational databases. Each database provider implements the JDBC API interface and tailors the implementation to their specific relational database solution. The finalized product is delivered to customers as a plugin that is declared as a dependency in the project and is used for CRUD operations, transaction management and security profiling for that specific database.
Kafka provides yet another example of this agent-based approach with its suite of Connectors: individual applications that handle one connectivity scenario. For example, the Kafka Connect FileStream Connectors are software build independently of the core Kafka cluster that allow developers to easily transfer data from Kafka to a file. Confluent, the parent company that operates the Kafka commercial license, offers dozens of these connectors that can be used for all types of read or write operations from or to different sources [
19]. In addition to the commercially available connectors savvy developers can create their own connectors, either by using the code bases provided by Confluent through an open-source program, or by writing their own from scratch. This gives Kafka an incredible amount of flexibility and scalability.
2.3. Functionality
Adaptability to multiple cloud solutions is a baseline requirement for any application or API working in a multi-cloud environment. Providing an easily extendable solution then becomes key to helping expand the reach of the API itself. Making the API scalable and generic allows any new cloud provider to simply add a plugin to work with their version of the cloud. Additionally, the API is also exposed to enterprises that are using it, allowing them to create their own custom plugins or connectors. Finally, all these abstractions will make the cyber-physical systems using the API better managers of resources by making them easily scalable and not reliant on any one cloud provider. Rather, the systems will simply rely on the abstraction of a concept whose implementation is handled, behind the scenes, in the API layer.
The API will communicate with each separate cloud using agents, instead of plugins or just simple connectors that ferry data. These agents need to be lightweight, relatively autonomous and deployable on command should the need arise to redeploy them.
By lightweight it is understood that agents should use as little of the managed resource as possible and that they should avoid complex implementations which would make them cumbersome to use. In essence they should do three things: return metrics from each cloud provider, query for a resource and carry back the results of requests made by the controller. Each agent will need to have a vendor specific implementation so that it can handle requests and responses successfully between the cloud provider and the controller.
The agent requires some degree of autonomy as it will need to be deployed on the fly as more resource requests are made to a different cloud provider. This is not at all dissimilar to how a cloud resource management system works, such as Kubernetes, where dockerized services and applications can be autoscaled and dynamic deployment is orchestrated based on the needs of a specific application. The difference between a Kubernetes implementation and the agents’ approach, however, is that the agents will be dynamic and not be deployed in a cluster, so that they can work on multiple clouds, on demand. To ensure seamless deployment a possible solution would be to dockerize the agent packages, thus ensuring that they are deployed in fully sustainable environments. Furthermore, dockerizing the agent deployment will make it possible to deploy agents programatically, without needing to previously set up each agent with a cloud provider.
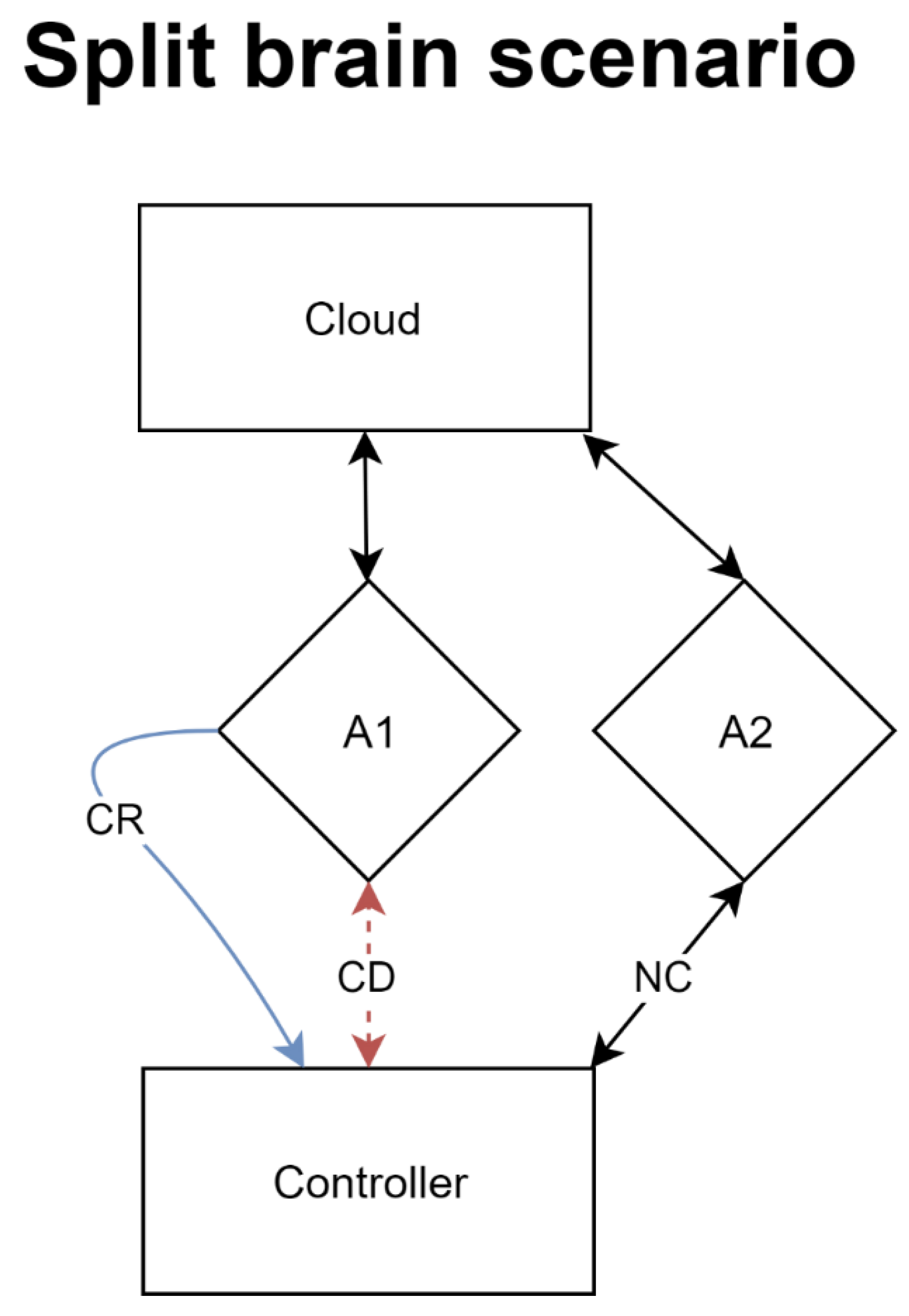
Finally, the agents need to be redeployable easily. Albeit a simple requirement, the implementation behind the redeployment process could be quite complex. Agents need to realize that they are no longer connected to a counterparty, which is difficult to measure in certain situations. A scenario that would need to be accounted for in an automatic deployment environment would be the split-brain scenario.
In a split-brain scenario, exemplified in
Figure 3, the agent loses the connection to the controller but not the cloud. The agent fails to report back to the controller, which then prompts a fail-safe trigger to deploy a new agent and attach it to that cloud provider. However, once the first agent’s internet connection comes back online it too will attempt to connect to the controller. Such a situation must be carefully managed by both the controller and the agent to ensure that partial information is not sent back to the controller nor that the controller is flooded with events and messages from duplicate services.
The controller is a component of the API and acts as the brains of the application, much like it does in a model-view-controller architecture. It is the element that coordinates the deployment of agents, or their redeployment, as needed. The controller also interprets the data it receives from the agents as well as the data it receives from the process, via the API wrapper, and it makes the decisions as to which resources to contract, when and for how long. Ideally the controller would also benefit from a predictive resource-requirements model that will make it easier for it to automatically anticipate a resource intensive task, based on the type, and frequency, of calls it receives from the API. For the controller to benefit from a predictive model it will need to be supplied with regular performance benchmarks from the clouds and cloud services the application is using. This is an optional parameter which is setup during customer implementations as the benchmarking is done automatically and can hinder performance somewhat, or interfere with high throughput tasks.
Both the controller and the agents are part of the same package. The controller is cloud agnostic while the agents are adapted to a cloud solution. The agents do not have direct visibility of the controller. They act only as a bridge between the controller and the cloud so that the former has select visibility of the cloud platform’s performance metrics and is able to issue commands to it (and get back responses). Since this approach is not REST based, the controller will not be language agnostic. The API, in its entirety, will be declared as a dependency by the project and the confirmation that a resource was acquired or a request was posted to the server will be an internal communication.
On its end, the entirety of the API communicates with both the process and the controller, albeit in different ways. The process does not necessarily need to directly communicate with the API: it will declare it as a dependency and then use the provided methods to make requests. If a request fails, the API can return an exception or an error. The API does not necessarily need to acknowledge every request, especially since all the communication is done inside the process and is, most likely, asynchronous. Assume a resource intensive operation, such as a self-driving car going from point A to point B, is being processed. The process makes requests to the API for resources as needed, it remains blissfully unaware of the API’s implementation, it only needs the resources. Furthermore, the process anticipates a heavy resource load coming up and it preemptively requests the API to provision for that heavier load, for example when the car encounters traffic on the way to its destination. The API then receives these requests from an application that implements it, and it sends them to the controller requesting more resources. Based on the requests made by the process, provisioning for a heavier incoming load, the controller allocates resources accordingly. Both the API and the controller need to work asynchronously, because multiple threads will carry out the request and send answers back to the API at various times during the execution of said request.
The last element of
Figure 2 is the process. The process is not part of the architecture and does not need to know any implementation details about any of the levels above it because of two main reasons. Firstly, as is the case with all encapsulation, the fewer elements that have access to an implementation the easier it is to isolate and track any potential bugs. Secondly, the API needs to be generic in order to accommodate multiple agent types.
In essence the architecture presented in this section is not entirely different from any type of large enterprise-level architecture, but it attempts to make use of intelligent resource rationing and modern micro-services design patterns to ensure that communication is seamless at all levels of the hierarchy. That is, of course, if said levels even require communication. One of the key goals in having a resource management system is that not all levels need to communicate to reduce the need to separately configure load-balancing solutions. What makes this approach different from a traditional load balancer though is the fact that it grants higher availability, the performance management is not solely relegated to a certain provider or on premises servers and it heavily decreases vendor reliance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}