
Pseudo-Gamma Spectroscopy Based on Plastic Scintillation Detectors Using Multitask Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Deep Learning Model
2.1.1. Multitask Learning (MTL)
2.1.2. Weighted Multi-Head Self-Attention
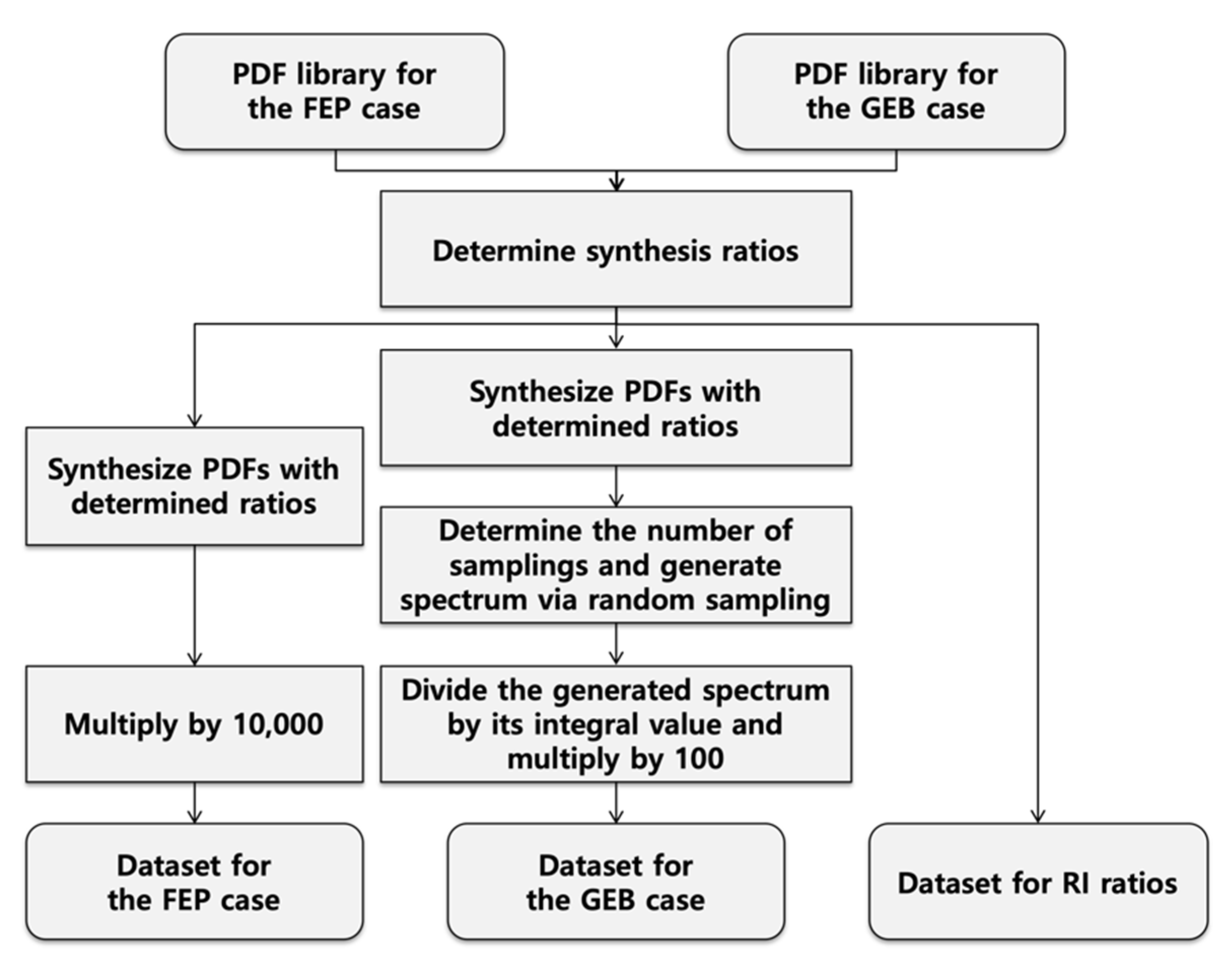
2.2. Dataset Generation
2.2.1. Experimental Environment
2.2.2. Monte Carlo Simulation
2.2.3. Dataset Generation
- Determination of synthesis ratios
- 2.
- PDF synthesis with the determined ratios
- 3.
- Random sampling for spectrum generation
- 4.
- Normalization
2.3. Implementation of a Deep- Learning Model
2.3.1. Baseline Model Implementation
2.3.2. Model Enhancement
3. Results
3.1. Model Enhancement
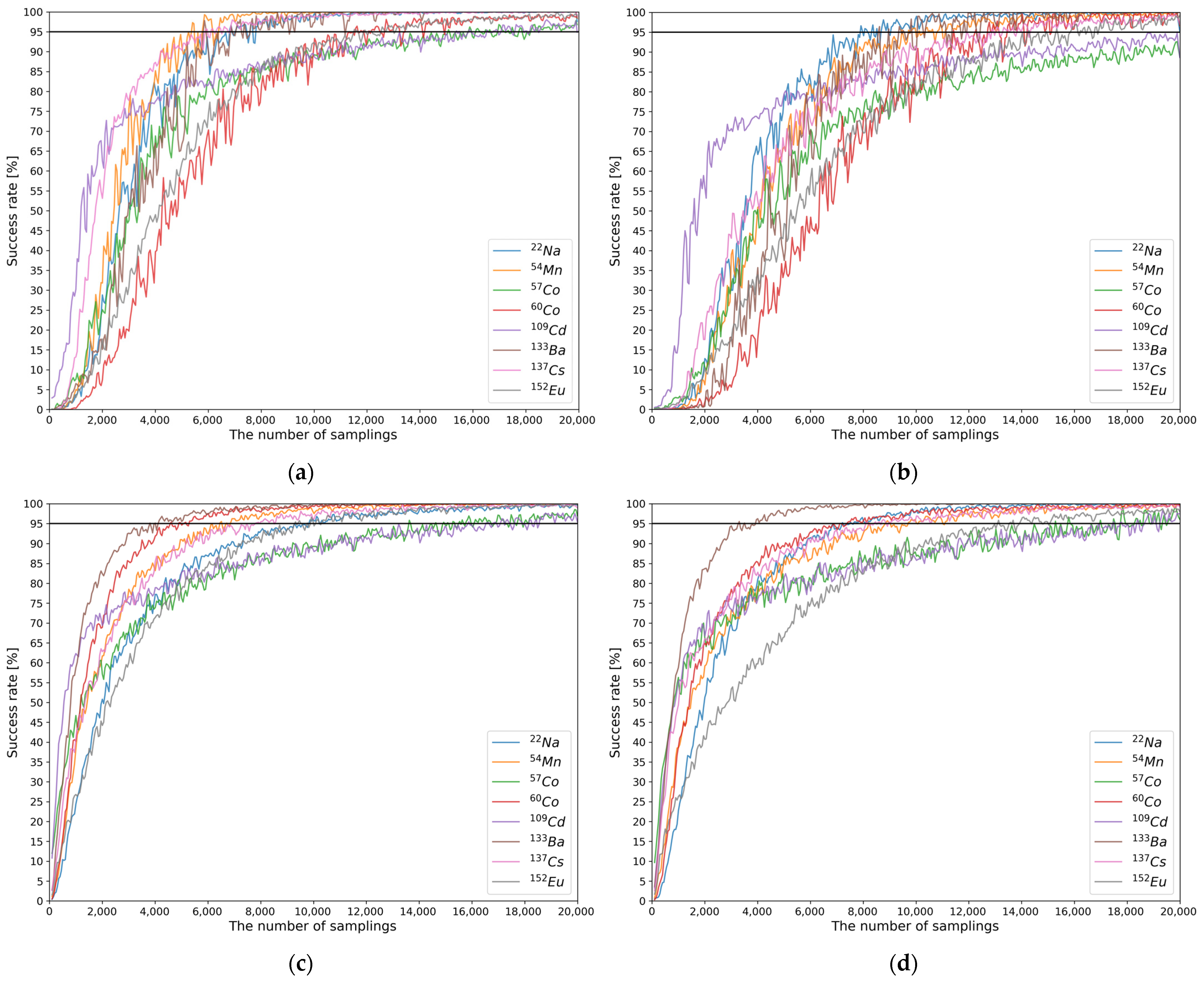
3.2. Minimum Required Counts
- PDF calculation for the evaluation set
- 2.
- Definition of the generation reference
- 3.
- Evaluation set generation
3.3. Performance Comparison
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siciliano, E.R.; Ely, J.H.; Kouzes, R.T.; Milbrath, B.D.; Schweppe, J.E.; Stromswold, D.C. Comparison of PVT and NaI (Tl) scintillators for vehicle portal monitor applications. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2005, 550, 647–674. [Google Scholar] [CrossRef]
- Ely, J.; Kouzes, R.; Schweppe, J.; Siciliano, E.; Strachan, D.; Weier, D. The use of energy windowing to discriminate SNM from NORM in radiation portal monitors. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2006, 560, 373–387. [Google Scholar] [CrossRef]
- Anderson, K.K.; Jarman, K.D.; Mann, M.L.; Pfund, D.M.; Runkle, R.C. Discriminating nuclear threats from benign sources in gamma-ray spectra using a spectral comparison ratio method. J. Radioanal. Nucl. Chem. 2008, 276, 713–718. [Google Scholar] [CrossRef]
- Hevener, R.; Yim, M.-S.; Baird, K. Investigation of energy windowing algorithms for effective cargo screening with radiation portal monitors. Radiat. Meas. 2013, 58, 113–120. [Google Scholar] [CrossRef]
- Shin, W.-G.; Lee, H.-C.; Choi, C.-I.; Park, C.S.; Kim, H.-S.; Min, C.H. A Monte Carlo study of an energy-weighted algorithm for radionuclide analysis with a plastic scintillation detector. Appl. Radiat. Isot. 2015, 101, 53–59. [Google Scholar] [CrossRef]
- Lee, H.C.; Shin, W.-G.; Park, H.J.; Yoo, D.H.; Choi, C.-I.; Park, C.-S.; Kim, H.-S.; Min, C.H. Validation of energy-weighted algorithm for radiation portal monitor using plastic scintillator. Appl. Radiat. Isot. 2016, 107, 160–164. [Google Scholar] [CrossRef]
- Paff, M.G.; Di Fulvio, A.; Clarke, S.D.; Pozzi, S.A. Radionuclide identification algorithm for organic scintillator-based radiation portal monitor. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2017, 849, 41–48. [Google Scholar] [CrossRef] [Green Version]
- Hamel, M.; Carrel, F. Pseudo-gamma spectrometry in plastic scintillators. In New Insights on Gamma Rays; InTech: London, UK, 2017; pp. 47–66. [Google Scholar]
- Lee, H.C.; Koo, B.T.; Choi, C.I.; Park, C.S.; Kwon, J.; Kim, H.-S.; Chung, H.; Min, C.H. Evaluation of Source Identification Method Based on Energy-Weighting Level with Portal Monitoring System Using Plastic Scintillator. J. Radiat. Prot. Res. 2020, 45, 117–129. [Google Scholar] [CrossRef]
- Ruch, M.L.; Paff, M.; Sagadevan, A.; Clarke, S.D.; Pozzi, S.A. Radionuclide identification by an EJ309 organic scintillator-based pedestrian radiation portal monitor using a least squares algorithm. In Proceedings of the 55th Annual Meeting of Nuclear Materials Management, Atlanta, GA, USA, 20–24 July 2014; pp. 22–24. [Google Scholar]
- Kangas, L.J.; Keller, P.E.; Siciliano, E.R.; Kouzes, R.T.; Ely, J.H. The use of artificial neural networks in PVT-based radiation portal monitors. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2008, 587, 398–412. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, M.; Lim, K.T.; Kim, J.; Cho, G. Inverse calibration matrix algorithm for radiation detection portal monitors. Radiat. Phys. Chem. 2019, 155, 127–132. [Google Scholar] [CrossRef]
- Kim, J.; Park, K.; Cho, G. Multi-radioisotope identification algorithm using an artificial neural network for plastic gamma spectra. Appl. Radiat. Isot. 2019, 147, 83–90. [Google Scholar] [CrossRef] [PubMed]
- Jeon, B.; Lee, Y.; Moon, M.; Kim, J.; Cho, G. Reconstruction of Compton Edges in Plastic Gamma Spectra Using Deep Autoencoder. Sensors 2020, 20, 2895. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Gao, J.; He, X.; Deng, L.; Duh, K.; Wang, Y.-Y. Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval. In Proceedings of the 2015 Conference of the North Americal Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 912–921. [Google Scholar]
- Jacob, L.; Vert, J.; Bach, F.R. Clustered multi-task learning: A convex formulation. In Proceedings of the Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2009; pp. 745–752. [Google Scholar]
- Hashimoto, K.; Xiong, C.; Tsuruoka, Y.; Socher, R. A joint many-task model: Growing a neural network for multiple nlp tasks. arXiv 2016, arXiv:1611.01587. [Google Scholar]
- Deng, L.; Hinton, G.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8599–8603. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; California University San Diego La Jolla Institute for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Oja, E. Simplified neuron model as a principal component analyzer. J. Math. Biol. 1982, 15, 267–273. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science (80-) 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y. Unsupervised anomaly detection via variational auto-encoder for seasonal kpis in web applications. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 187–196. [Google Scholar]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, Australia, 2 December 2014; pp. 4–11. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Chen, D.; Hua, G.; Wen, F.; Sun, J. Supervised transformer network for efficient face detection. In Proceedings of the 14th the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 122–138. [Google Scholar]
- Mousavi, S.M.; Ellsworth, W.L.; Zhu, W.; Chuang, L.Y.; Beroza, G.C. Earthquake transformer—An attentive deep-learning model for simultaneous earthquake detection and phase picking. Nat. Commun. 2020, 11, 1–12. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Jeon, B.; Kim, J.; Moon, M.; Cho, G. Parametric optimization for energy calibration and gamma response function of plastic scintillation detectors using a genetic algorithm. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2019, 930, 8–14. [Google Scholar] [CrossRef]
- Calculator, R. Available online: http://www.radprocalculator.com (accessed on 1 July 2020).
- Werner, C.J.; Bull, J.S.; Solomon, C.J.; Brown, F.B.; McKinney, G.W.; Rising, M.E.; Dixon, D.A.; Martz, R.L.; Hughes, H.G.; Cox, L.J. MCNP Version 6.2 Release Notes; Los Alamos National Lab.(LANL): Los Alamos, NM, USA, 2018.
- McConn, R.J.; Gesh, C.J.; Pagh, R.T.; Rucker, R.A.; Williams, R., III. Compendium of Material Composition Data for Radiation Transport Modeling; Pacific Northwest National Lab.(PNNL): Richland, WA, USA, 2011.
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. TensorFlow: Large-scale machine learning on heterogeneous systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. In Proceedings of the Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2012; pp. 2951–2959. [Google Scholar]
- Kirkpatrick, J.M.; Venkataraman, R.; Young, B.M. Minimum detectable activity, systematic uncertainties, and the ISO 11929 standard. J. Radioanal. Nucl. Chem. 2013, 296, 1005–1010. [Google Scholar] [CrossRef]
- Keyser, R.M.; Sergent, F.; Twomey, T.R.; Upp, D.L. Minimum detectable activity estimates for a germanium-detector based spectroscopic portal monitor. In Proceedings of the INMM 47th Annual Meeting Conference Record, Nashville, TN, USA, 6–7 November 2006. [Google Scholar]
- Casanovas, R.; Morant, J.J.; Salvadó, M. Temperature peak-shift correction methods for NaI (Tl) and LaBr3 (Ce) gamma-ray spectrum stabilisation. Radiat. Meas. 2012, 47, 588–595. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Activity (kBq) | Reference Date * | Estimated Activity ** (kBq) | Gamma Energy (MeV) | Emission Intensity (%) |
|---|---|---|---|---|---|
| 22Na | 385.5 | 1 June 2017 | 169.48 | 0.511 | 180.76 |
| 1.275 | 99.94 | ||||
| 54Mn | 341.3 | 1 June 2017 | 28.04 | 0.835 | 99.98 |
| 57Co | 395.2 | 1 June 2017 | 22.37 | 0.014 | 9.16 |
| 0.122 | 85.6 | ||||
| 0.137 | 10.68 | ||||
| 60Co | 380 | 1 June 2017 | 263.42 | 1.173 | 99.9 |
| 1.333 | 99.98 | ||||
| 109Cd | 346.1 | 1 June 2017 | 64.04 | 0.088 | 3.64 |
| 133Ba | 370 | 1 June 2017 | 301.89 | 0.081 | 32.9 |
| 0.276 | 7.16 | ||||
| 0.303 | 18.34 | ||||
| 0.356 | 62.05 | ||||
| 0.384 | 8.94 | ||||
| 137Cs | 378.1 | 1 June 2017 | 352.15 | 0.662 | 85.1 |
| 152Eu | 385.2 | 1 June 2017 | 328.92 | 0.122 | 0.87 |
| 0.245 | 0.96 | ||||
| 0.344 | 1.09 | ||||
| 0.411 | 1.09 | ||||
| 0.444 | 1.11 | ||||
| 0.678 | 1.29 | ||||
| 0.779 | 1.41 | ||||
| 0.867 | 4.25 | ||||
| 0.964 | 14.6 | ||||
| 1.086 | 10.21 | ||||
| 1.09 | 1.73 | ||||
| 1.112 | 13.64 | ||||
| 1.299 | 1.62 | ||||
| 1.408 | 21 |
| Parameter | Type | Range | Final Value |
|---|---|---|---|
| Depth of the encoder and decoder layers | Continuous | 2–8 | 6 |
| Decreasing and increasing rates for the # of neurons | Continuous | 0.5–0.98 | 0.836 |
| Regressor layers depth | Continuous | 1–4 | 2 |
| # of neurons in the regressor layers | Continuous | 10–300 | 180 |
| Activation functions in the hidden layers | Discrete | Relu, Sigmoid | Relu |
| Activation function in the last decoder layer | Discrete | Linear, Sigmoid, Tanh, Exponential | Exponential |
| Model | Generation Loss (%) | Regression Loss (%) |
|---|---|---|
| DNN (Baseline) | 310.678 | 34.225 |
| DNN + Attention | 67.987 | 34.201 |
| DNN + Attention + Skip | 58.704 | 34.797 |
| DNN + Multi-head self-attention + Skip | 124.351 | 34.397 |
| DNN + Proposed + Skip -> Final model | 37.597 | 34.146 |
| CNN | 251.524 | 34.003 |
| CNN + Attention | 82.609 | 34.148 |
| CNN + Attention + Skip | 68.262 | 34.651 |
| CNN + Multi-head self-attention + Skip | 109.087 | 38.017 |
| CNN + Proposed + Skip | 80.216 | 34.973 |
| DNN (two models) | 881.641 | 34.285 |
| DNN + Proposed + Skip (two models) | 309.856 | 34.148 |
| Source | MRC for Generation | MRC for Regression | ||
|---|---|---|---|---|
| Baseline MTL | Final MTL | Baseline MTL | Final MTL | |
| 22Na | 7820 ± 89 | 10,270 ± 102 | 9070 ± 96 | 7670 ± 88 |
| 54Mn | 6410 ± 80 | 6870 ± 83 | 11,130 ± 105 | 11,130 ± 106 |
| 57Co | 18,640 ± 137 | 17,990 ± 135 | 22,510 ± 150 | 19,540 ± 140 |
| 60Co | 14,980 ± 23 | 5310 ± 73 | 15,130 ± 123 | 7420 ± 87 |
| 109Cd | 19,990 ± 142 | 18,590 ± 137 | 26,710 ± 164 | 19,240 ± 139 |
| 133Ba | 12,430 ± 112 | 3960 ± 63 | 12,430 ± 112 | 3960 ± 63 |
| 137Cs | 14,330 ± 120 | 8970 ± 95 | 14,330 ± 120 | 8970 ± 95 |
| 152Eu | 16,940 ± 131 | 15,080 ± 123 | 16,940 ± 131 | 15,080 ± 123 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, B.; Kim, J.; Lee, E.; Moon, M.; Cho, G. Pseudo-Gamma Spectroscopy Based on Plastic Scintillation Detectors Using Multitask Learning. Sensors 2021, 21, 684. https://doi.org/10.3390/s21030684
Jeon B, Kim J, Lee E, Moon M, Cho G. Pseudo-Gamma Spectroscopy Based on Plastic Scintillation Detectors Using Multitask Learning. Sensors. 2021; 21(3):684. https://doi.org/10.3390/s21030684
Chicago/Turabian StyleJeon, Byoungil, Junha Kim, Eunjoong Lee, Myungkook Moon, and Gyuseong Cho. 2021. "Pseudo-Gamma Spectroscopy Based on Plastic Scintillation Detectors Using Multitask Learning" Sensors 21, no. 3: 684. https://doi.org/10.3390/s21030684
APA StyleJeon, B., Kim, J., Lee, E., Moon, M., & Cho, G. (2021). Pseudo-Gamma Spectroscopy Based on Plastic Scintillation Detectors Using Multitask Learning. Sensors, 21(3), 684. https://doi.org/10.3390/s21030684