
Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints

Abstract
:1. Introduction
2. Related Work
3. System Model
3.1. Problem Description
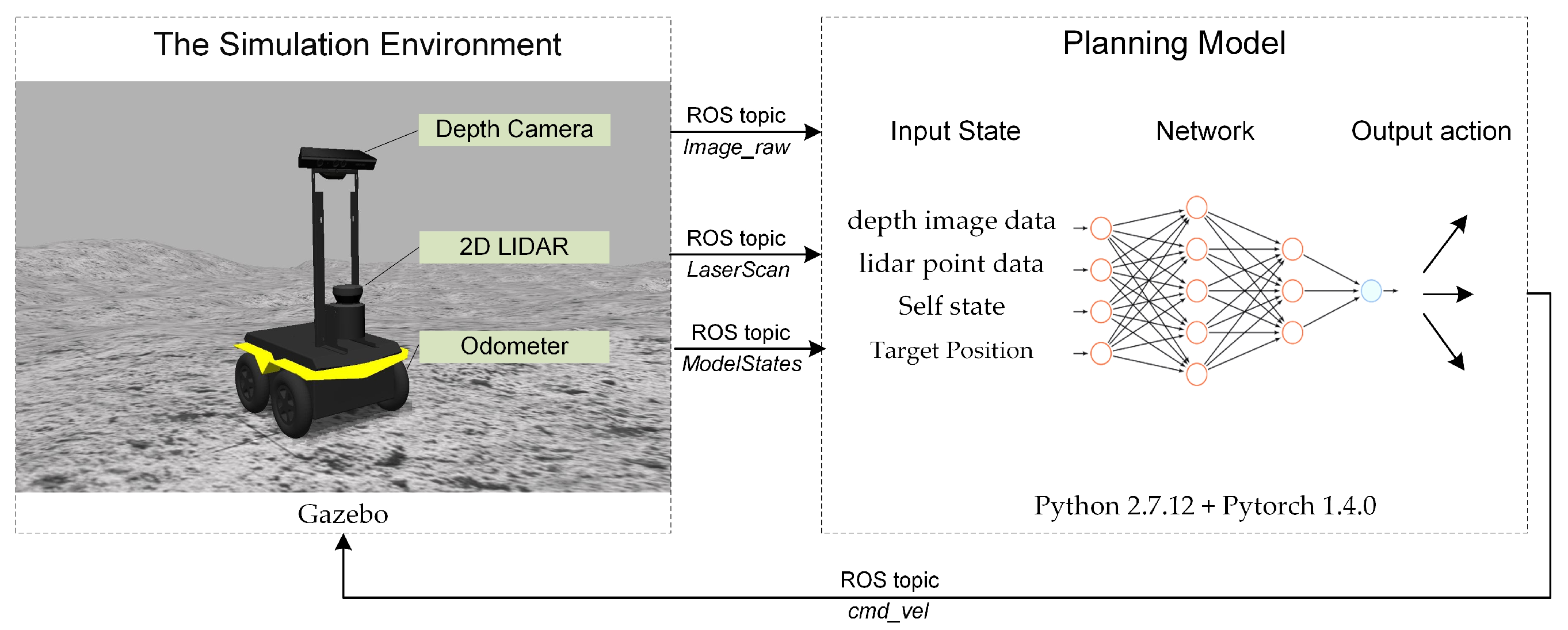
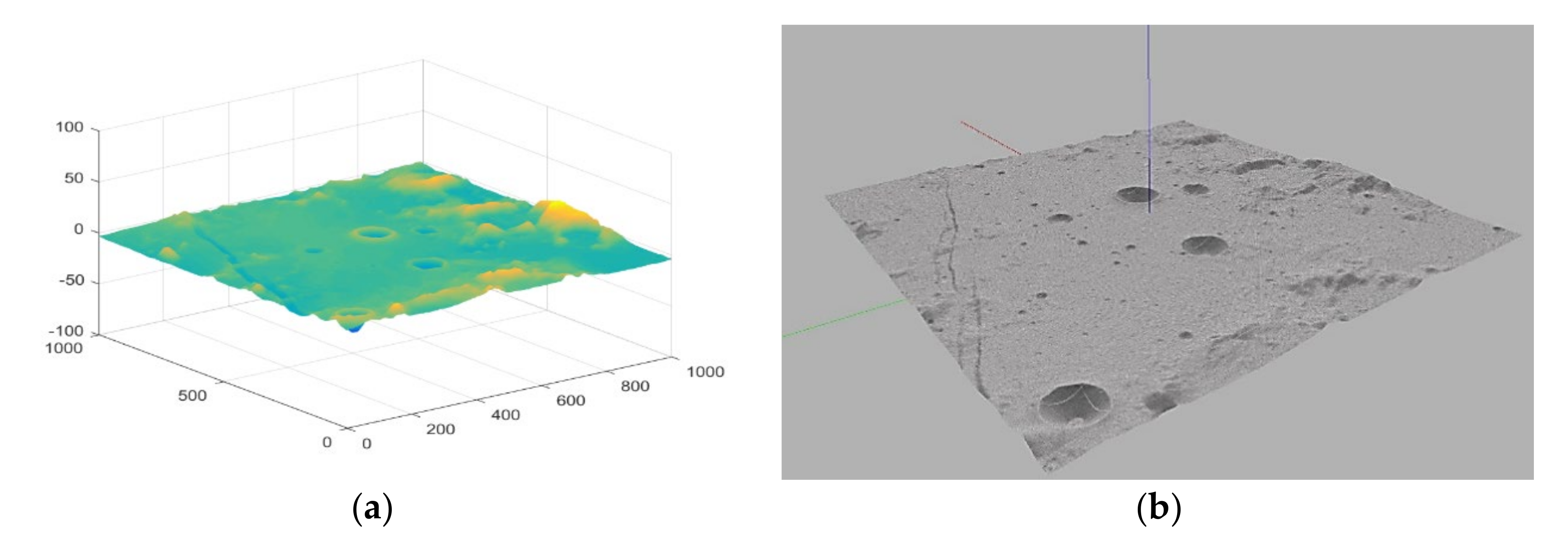
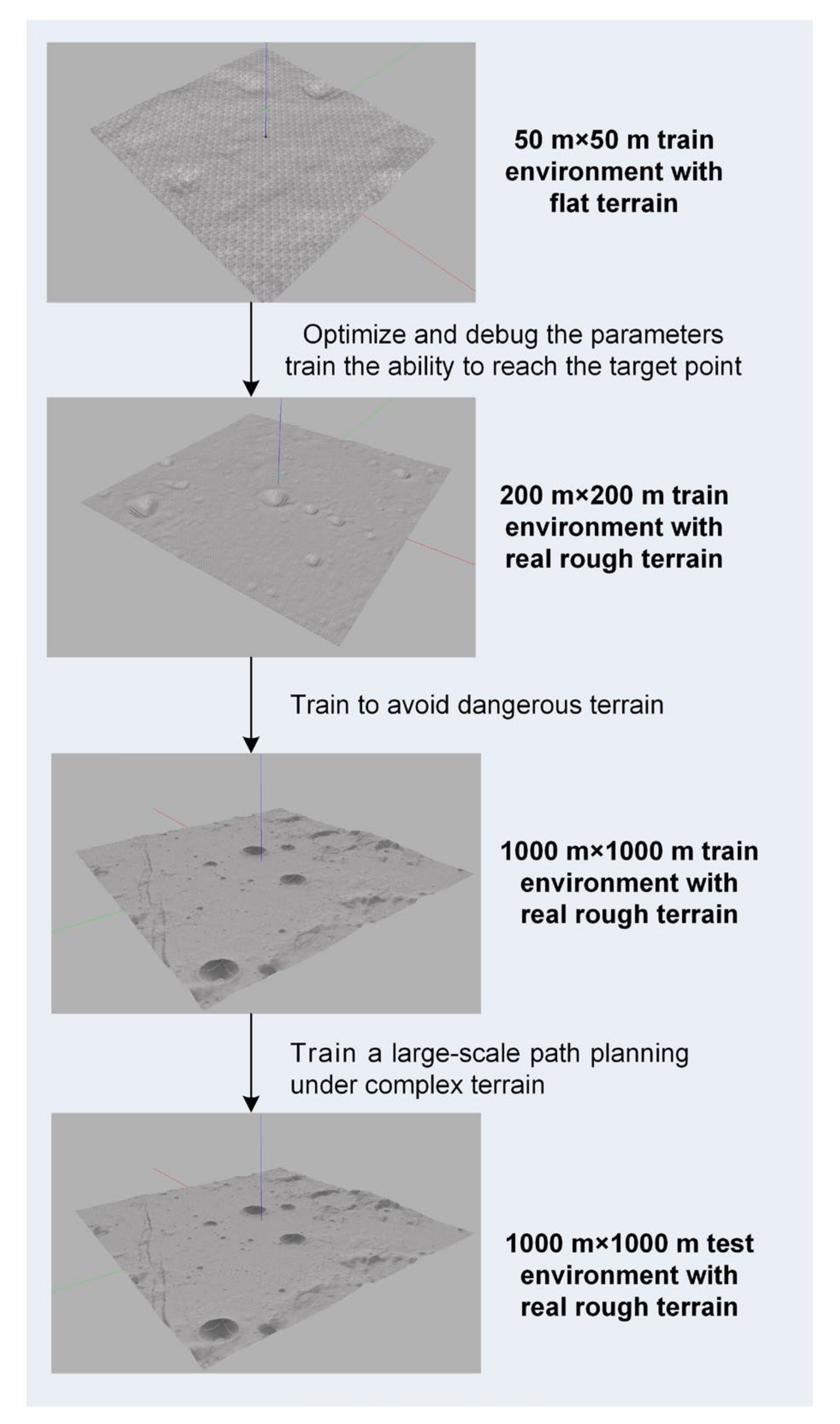
3.2. The Training Environment
3.3. The Rover Simulator
4. Deep Reinforcement Learning
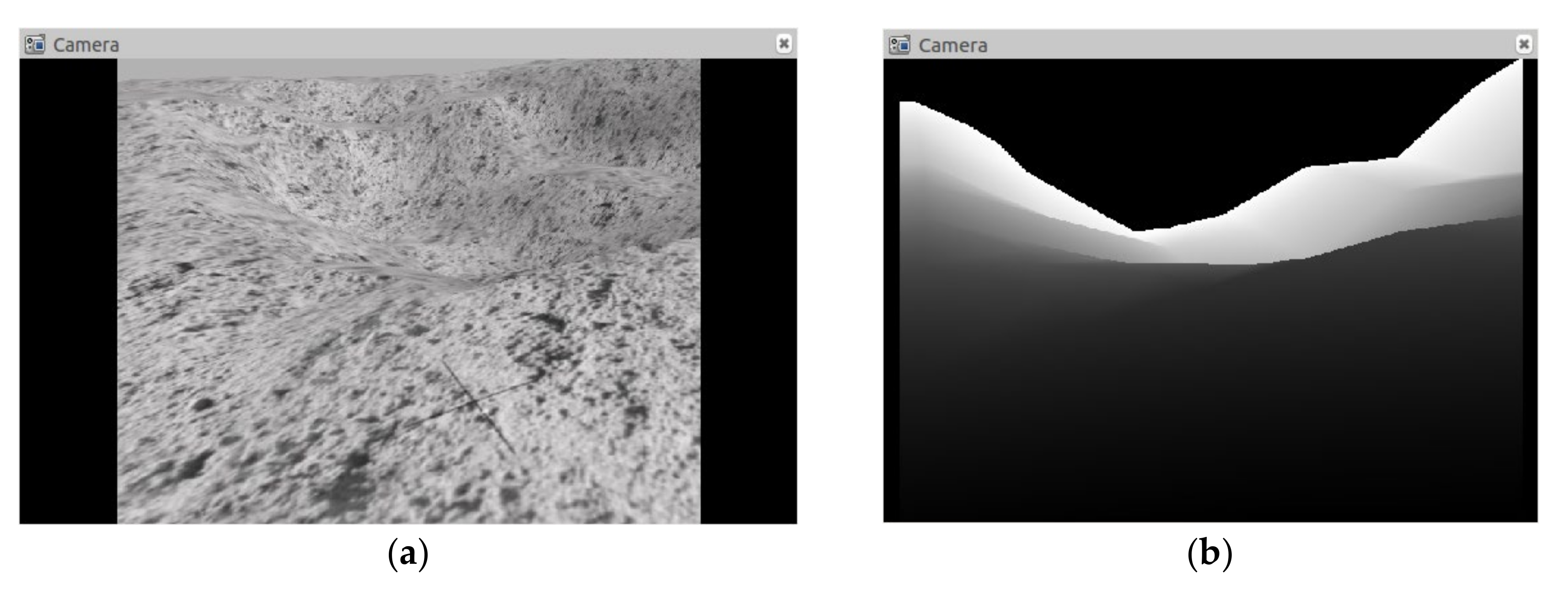
4.1. State Space
4.2. Action Space
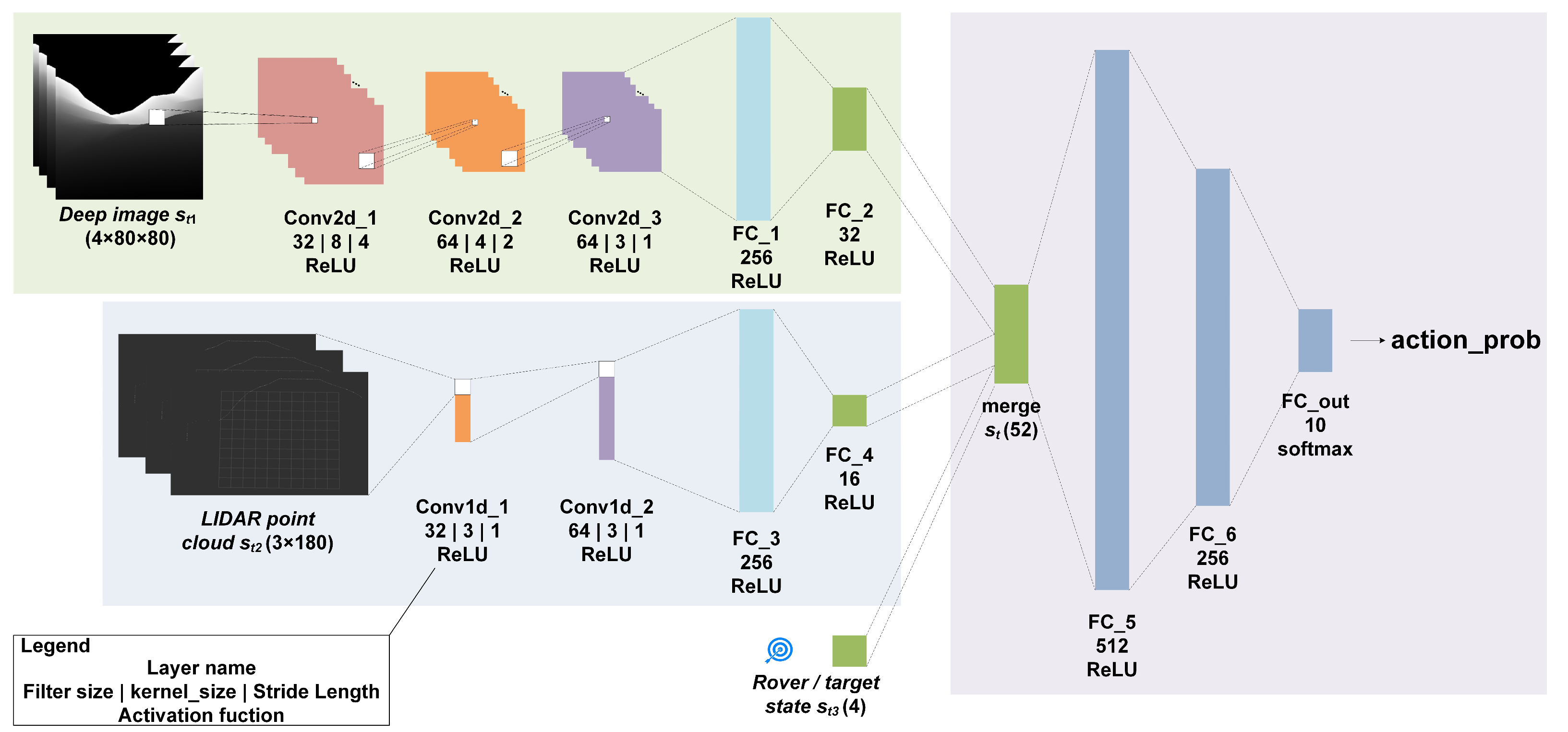
4.3. Network Architecture
4.4. Reward Function
4.5. Training Algorithm
| Algorithm 1: PPO-based training algorithm for path planning | |
| 1 | Initialize policy network , and value function , let = |
| 2 | for episode = 1,2,… N, do |
| 3 | Run policy for T timesteps, collecting experience {st, at, rt} |
| 4 | Estimate advantages using , where |
| 5 | if Memory_size > 1000, do |
| 6 | for j = 1,2,…, do |
| 7 | |
| 8 | Optimize surrogate wrt , with epochs, minibatch size Bs and the learning rate |
| 9 | end |
| 10 | for j = 1,2,…,, do |
| 11 | |
| 12 | Optimize surrogate wrt , with epochs, minibatch size Bs and the learning rate |
| 13 | end |
| 14 | Clear the memory pool |
| 15 | end |
| 16 | end |
5. Simulation Results and Analysis
5.1. Simulation Setup
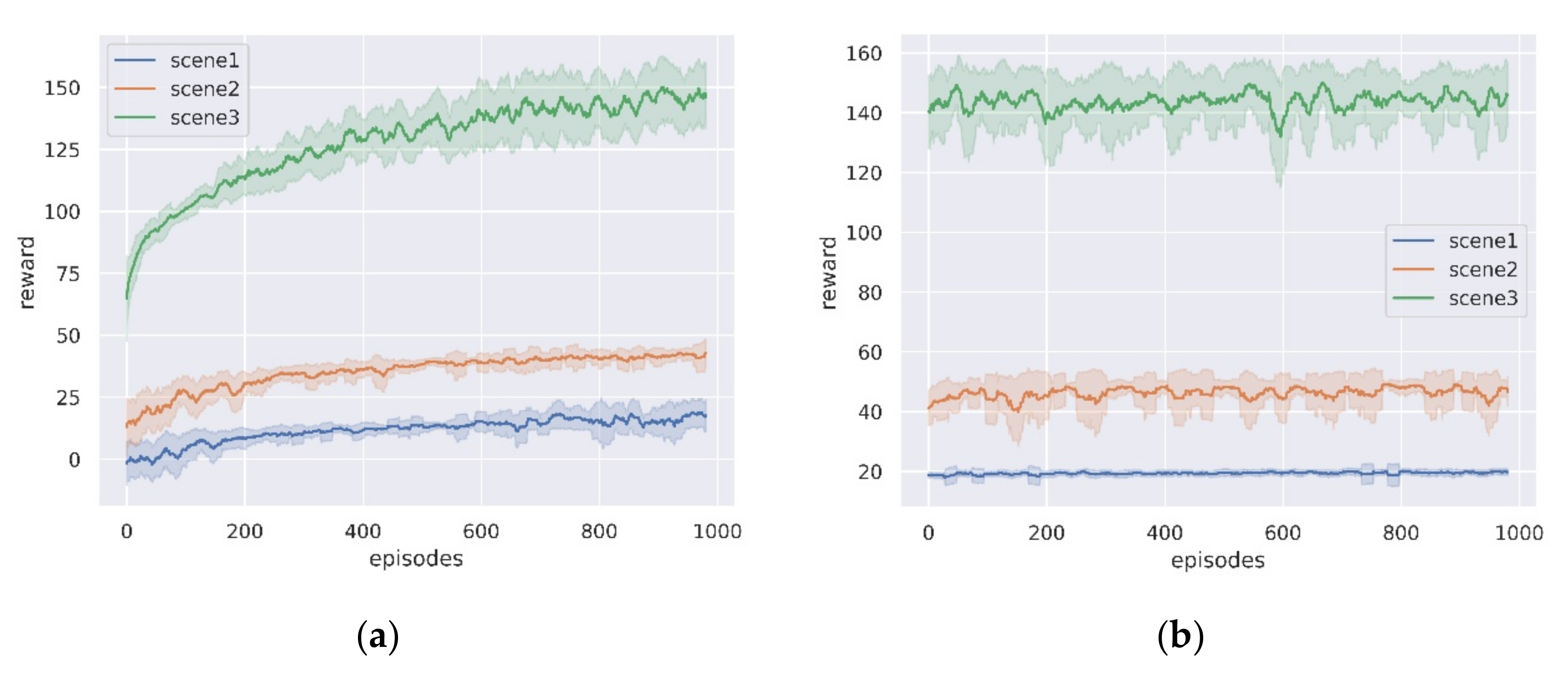
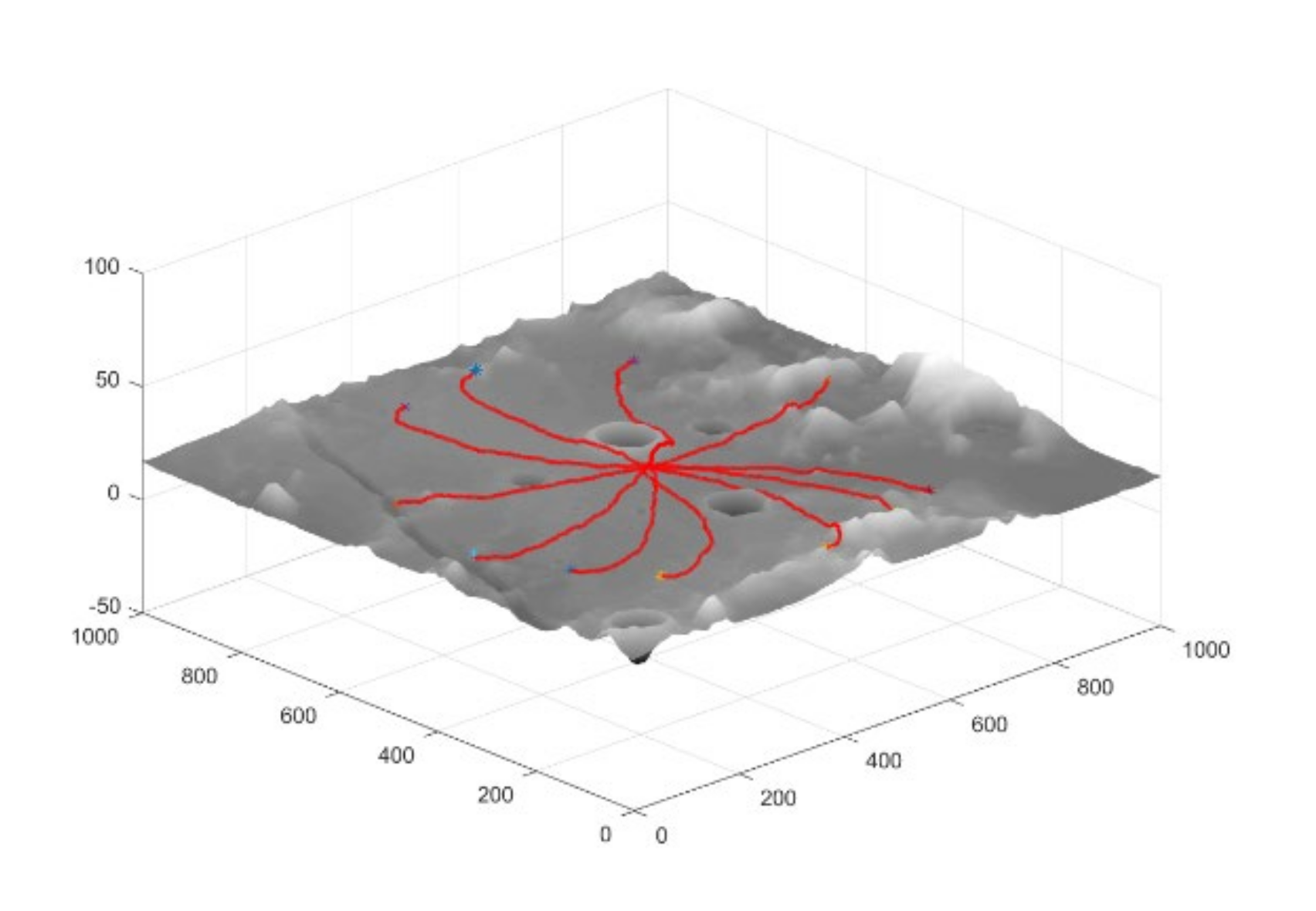
5.2. Training Results in Different Scenarios
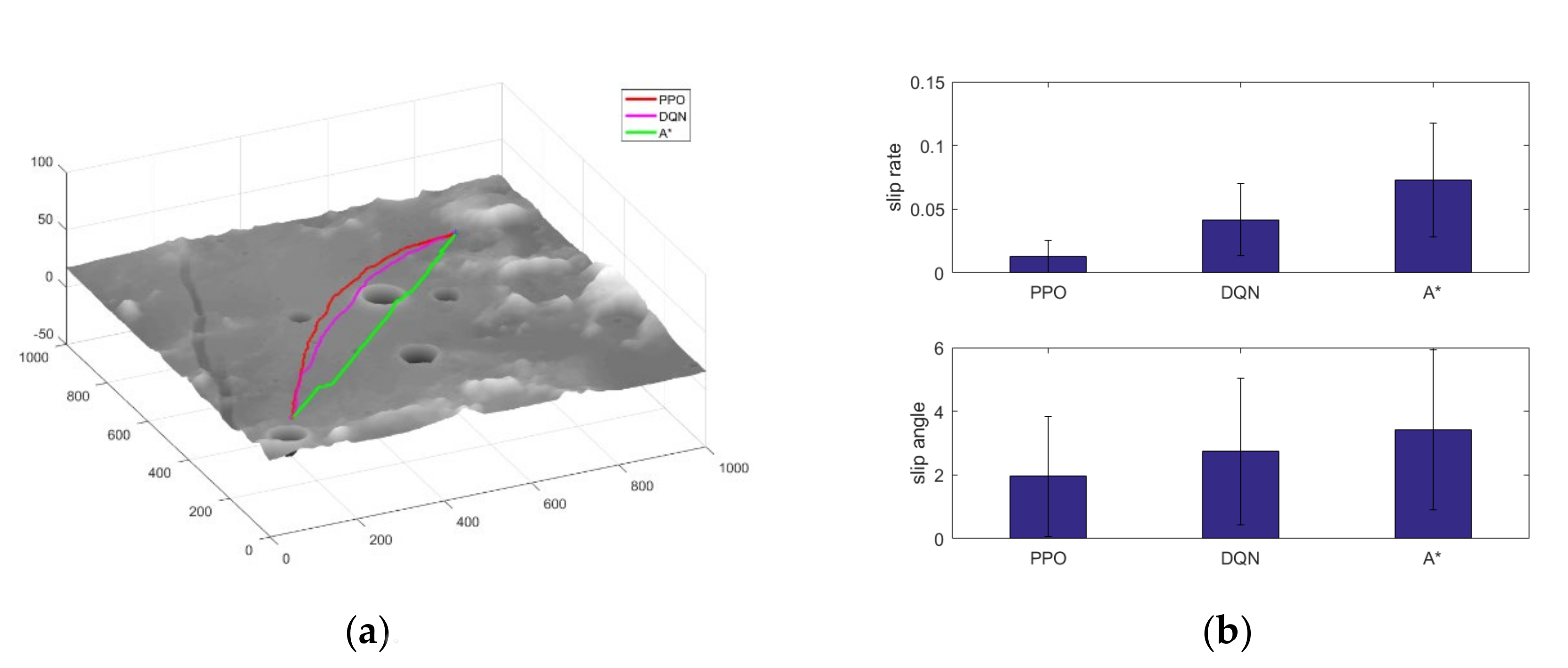
5.3. Comparison Results with Other Algorithms
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Wang, C.; Wei, Y.; Lin, Y. China’s present and future lunar exploration program. Science 2019, 365, 238–239. [Google Scholar] [CrossRef] [PubMed]
- Fan, W.; Yang, F.; Han, L.; Wang, H. Overview of Russia’s future plan of lunar exploration. Sci. Technol. Rev. 2019, 2019, 3. [Google Scholar]
- Smith, M.; Craig, D.; Herrmann, N.; Mahoney, E.; Krezel, J.; McIntyre, N.; Goodliff, K. The Artemis Program: An Overview of NASA’s Activities to Return Humans to the Moon. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–10. [Google Scholar]
- Sasaki, H.; Director, J. JAXA’s Lunar exploration activities. In Proceedings of the 62nd Session of COPUOS, Vienna, Austria, 12–21 June 2019. [Google Scholar]
- Colaprete, A.; Andrews, D.; Bluethmann, W.; Elphic, R.C.; Bussey, B.; Trimble, J.; Zacny, K.; Captain, J.E. An overview of the Volatiles Investigating Polar Exploration Rover (VIPER) mission. AGUFM 2019, 2019, P34B-03. [Google Scholar]
- Wong, C.; Yang, E.; Yan, X.-T.; Gu, D. Adaptive and intelligent navigation of autonomous planetary rovers—A survey. In Proceedings of the 2017 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Pasadena, CA, USA, 24–27 July 2017; pp. 237–244. [Google Scholar]
- Sutoh, M.; Otsuki, M.; Wakabayashi, S.; Hoshino, T.; Hashimoto, T. The right path: Comprehensive path planning for lunar exploration rovers. IEEE Robot. Autom. Mag. 2015, 22, 22–33. [Google Scholar] [CrossRef]
- Song, T.; Huo, X.; Wu, X. A Two-Stage Method for Target Searching in the Path Planning for Mobile Robots. Sensors 2020, 20, 6919. [Google Scholar] [CrossRef]
- Yu, X.; Huang, Q.; Wang, P.; Guo, J. Comprehensive Global Path Planning for Lunar Rovers. In Proceedings of the 2020 3rd International Conference on Unmanned Systems (ICUS), Athens, Greece, 1–4 September 2020; pp. 505–510. [Google Scholar]
- Takemura, R.; Ishigami, G. Traversability-based RRT* for planetary rover path planning in rough terrain with LIDAR point cloud data. J. Robot. Mechatron. 2017, 29, 838–846. [Google Scholar] [CrossRef]
- Bai, C.; Guo, J.; Guo, L.; Song, J. Deep multi-layer perception based terrain classification for planetary exploration rovers. Sensors 2019, 19, 3102. [Google Scholar] [CrossRef] [Green Version]
- Helmick, D.; Angelova, A.; Matthies, L. Terrain adaptive navigation for planetary rovers. J. Field Robot. 2009, 26, 391–410. [Google Scholar] [CrossRef] [Green Version]
- Pflueger, M.; Agha, A.; Sukhatme, G.S. Rover-IRL: Inverse reinforcement learning with soft value iteration networks for planetary rover path planning. IEEE Robot. Autom. Lett. 2019, 4, 1387–1394. [Google Scholar] [CrossRef]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Zhou, X.; Bai, T.; Gao, Y.; Han, Y. Vision-based robot navigation through combining unsupervised learning and hierarchical reinforcement learning. Sensors 2019, 19, 1576. [Google Scholar] [CrossRef] [Green Version]
- Yan, Z.; Xu, Y. Data-driven load frequency control for stochastic power systems: A deep reinforcement learning method with continuous action search. IEEE Trans. Power Syst. 2018, 34, 1653–1656. [Google Scholar] [CrossRef]
- Radac, M.-B.; Lala, T. Robust Control of Unknown Observable Nonlinear Systems Solved as a Zero-Sum Game. IEEE Access 2020, 8, 214153–214165. [Google Scholar] [CrossRef]
- Moreira, I.; Rivas, J.; Cruz, F.; Dazeley, R.; Ayala, A.; Fernandes, B. Deep Reinforcement Learning with Interactive Feedback in a Human–Robot Environment. Appl. Sci. 2020, 10, 5574. [Google Scholar] [CrossRef]
- Ishigami, G.; Nagatani, K.; Yoshida, K. Path planning and evaluation for planetary rovers based on dynamic mobility index. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 601–606. [Google Scholar]
- Xing, Y.; Liu, X.; Teng, B. Autonomous local obstacle avoidance path planning of Lunar surface ex-ploration rovers. Control Theory Appl. 2019, 36, 2042–2046. [Google Scholar]
- Ono, M.; Fuchs, T.J.; Steffy, A.; Maimone, M.; Yen, J. Risk-aware planetary rover operation: Autonomous terrain classification and path planning. In Proceedings of the 2015 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2015; pp. 1–10. [Google Scholar]
- Gao, J.; Ye, W.; Guo, J.; Li, Z. Deep Reinforcement Learning for Indoor Mobile Robot Path Planning. Sensors 2020, 20, 5493. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xia, Y.; Shen, G. A novel learning-based global path planning algorithm for planetary rovers. Neurocomputing 2019, 361, 69–76. [Google Scholar] [CrossRef] [Green Version]
- Ono, M.; Rothrock, B.; Otsu, K.; Higa, S.; Iwashita, Y.; Didier, A.; Islam, T.; Laporte, C.; Sun, V.; Stack, K. MAARS: Machine learning-based Analytics for Automated Rover Systems. In Proceedings of the 2020 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2020; pp. 1–17. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; p. 5. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; pp. 2149–2154. [Google Scholar]
- Xin, X.; Liu, B.; Di, K.; Yue, Z.; Gou, S. Geometric Quality Assessment of Chang’E-2 Global DEM Product. Remote Sens. 2020, 12, 526. [Google Scholar] [CrossRef] [Green Version]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Value | Linear Velocity (m/s) | Angular Velocity (rad/s) |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 1 | 0.5 |
| 2 | 1 | 0 |
| 3 | 1 | −0.5 |
| 4 | 1 | −1 |
| 5 | 0.5 | 1 |
| 6 | 0.5 | 0.5 |
| 7 | 0.5 | 0 |
| 8 | 0.5 | −0.5 |
| 9 | 0.5 | −1 |
| Parameters | Values | Descriptions |
|---|---|---|
| T | 100 (scene 1) 300 (scene 2) 3000 (scene 3) | The maximum timesteps in one episode |
| N | 1000 | The total episode |
| 0.5 (scene 1) 1 (scene 2) 1 (scene 3) | The safe factor | |
| 0.99 | The reward discount | |
| 0.95 | Generalized advantage estimation parameter | |
| 0.1 | Clip range | |
| 10 | The actor network training times | |
| 10 | The critic network training times | |
| Bs | 64 | Minibatch size |
| 0.00002 | The actor network learning rate | |
| 0.001 | The critic network learning rate |
| Performance Item | Scene1 | Scene2 | Scene3 |
|---|---|---|---|
| The success rate (%) | 99.5 | 95.1 | 88.6 |
| Average path length (m) | 21.35 | 53.48 | 217.32 |
| Average slip rate | 0.0122 | 0.0165 | 0.0266 |
| Average slip angle (°) | 1.1178 | 1.5815 | 1.9710 |
| Parameters | Values | Descriptions |
|---|---|---|
| T | 100 (scene 1) 300 (scene 2) 3000 (scene 3) | The maximum timesteps in one episode |
| 0.5 (scene 1) 1 (scene 2) 1 (scene 3) | The safe factor | |
| 0.99 | The reward discount | |
| Bs | 64 | Minibatch size |
| 0.0005 | The learning rate | |
| Ms | 10000 | The replay memory size |
| Performance Item | PPO | DQN | A* |
|---|---|---|---|
| Average path length (m) | 845.78 | 851.66 | 691.54 |
| Average slip rate | 0.0276 | 0.0528 | 0.0844 |
| Average slip angle (°) | 2.0648 | 2.9362 | 3.6952 |
| Maximum pitch angle (°) | 13.3583 | 17.8628 | 18.575 |
| Maximum roll angle (°) | 8.4252 | 8.5486 | 13.5572 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Wang, P.; Zhang, Z. Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints. Sensors 2021, 21, 796. https://doi.org/10.3390/s21030796
Yu X, Wang P, Zhang Z. Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints. Sensors. 2021; 21(3):796. https://doi.org/10.3390/s21030796
Chicago/Turabian StyleYu, Xiaoqiang, Ping Wang, and Zexu Zhang. 2021. "Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints" Sensors 21, no. 3: 796. https://doi.org/10.3390/s21030796
APA StyleYu, X., Wang, P., & Zhang, Z. (2021). Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints. Sensors, 21(3), 796. https://doi.org/10.3390/s21030796