
Eight-Channel Multispectral Image Database for Saliency Prediction




Abstract
:1. Introduction
2. Methods
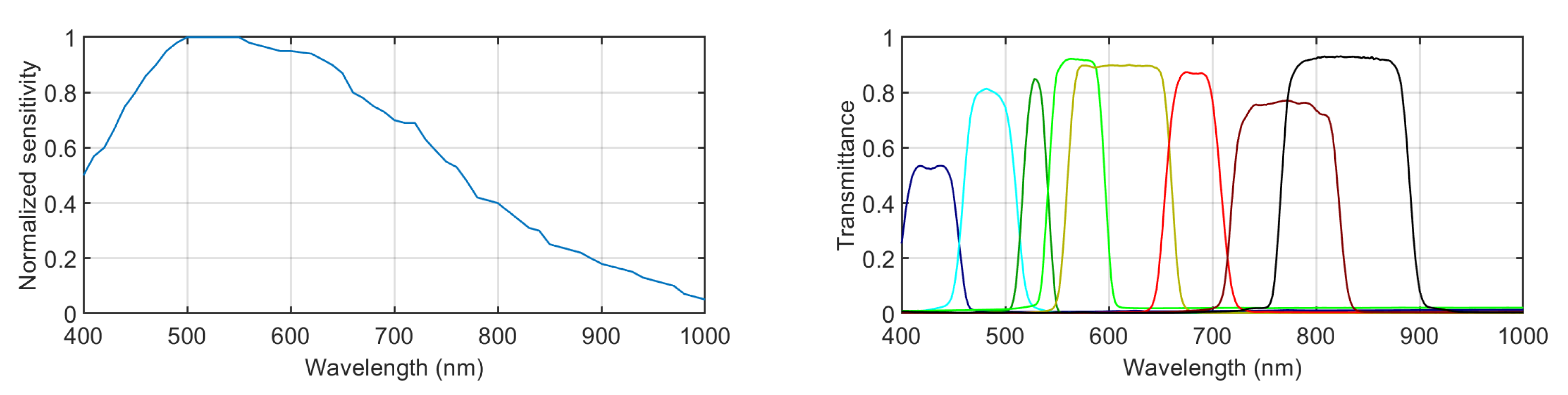
2.1. Multispectral Image Capturing
2.2. Gaze Data Recording
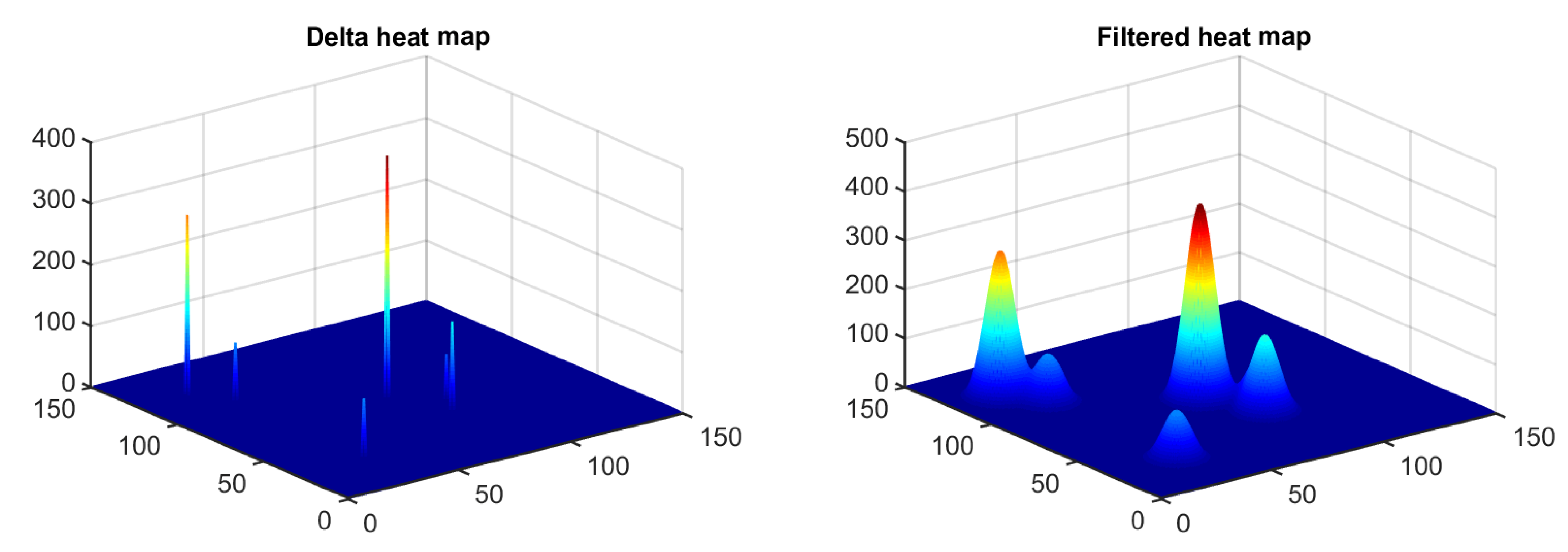
2.3. Building of the Fixation Maps
2.4. Experiments
2.4.1. Small Image Set: Free Viewing + Categorization
2.4.2. Large Image Set: Free Viewing
2.4.3. Saliency Prediction Comparison: RGB vs. Spectral
2.5. Heat Map Comparison Metrics
- Normalized scanpath saliency (NSS) [13]: averaged normalized saliency at the ground-truth location. This solves the issue existing in AUC methods of not penalizing low-valued false positives.
- Information gain (IG) [35]: compares two heat maps, taking into account the similarity of the probability distribution function and the heat map acting as ground truth.
2.6. Image Complexity Metrics
- Self-similarity: self-similarity compares the histogram of gradients (HOG) across different equally sized sub-images of the original image [37]. The HOG feature is calculated for each sub-image in the pyramid using the histogram intersection kernel [38]. By comparing the HOG features of each sub-image at level 3 with those of the entire image at level 0, the self-similarity of an image is calculated as shown in Equation (1).where I represents the image, L represents the three pyramid levels used, h(S) is the HOG value for a sub-image, and Pr(S) corresponds to the parent of sub-image S [39].
- Complexity: by computing first the maximum gradient magnitudes in the image channels, the gradient image Gmax is generated as shown in Equation (2).where , , and are the gradients at pixel (x, y) for each R, G, and B image component. Finally, the complexity of an image is computed as the mean norm of the gradient across all orientations over Gmax(x, y) [37], as shown in Equation (3).
- Birkhoff-like metric: this metric computes the amount of effort the human visual system has to put into the processing of an image. Following on from [37], the Birkhoff metric is defined as the ratio between self-similarity and the complexity metrics previously explained (see Equation (4)).
- Anisotropy: calculated as the variance of all the HOG values at level 3 as explained in [37]. This metric gives an idea about how the Fourier spectrum is more or less uniform across orientations (that is, less anisotropic).
3. Results
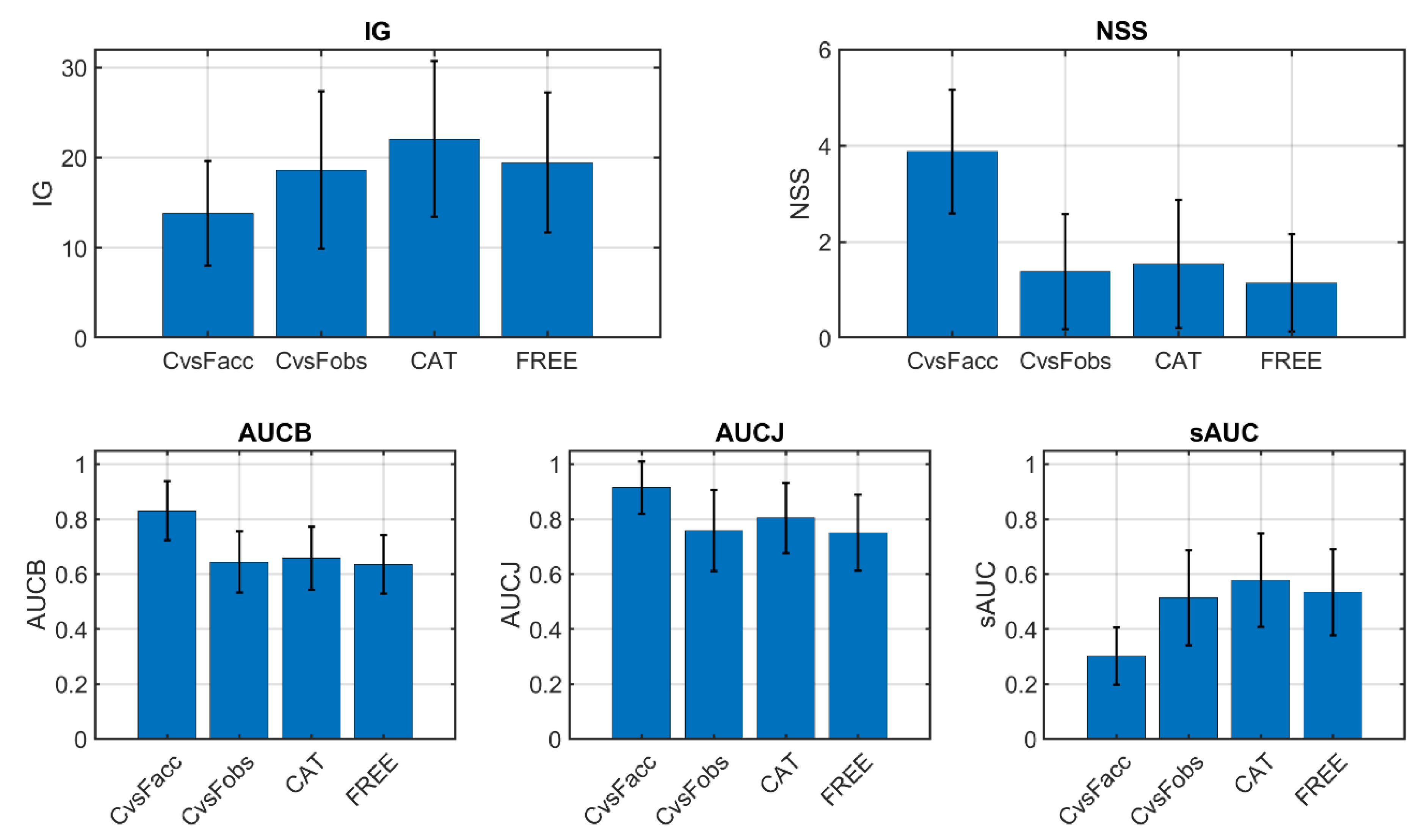
3.1. Inter-Observer and Inter-Experiment Heat Map Comparisons
3.2. Correlation with Image Complexity Metrics
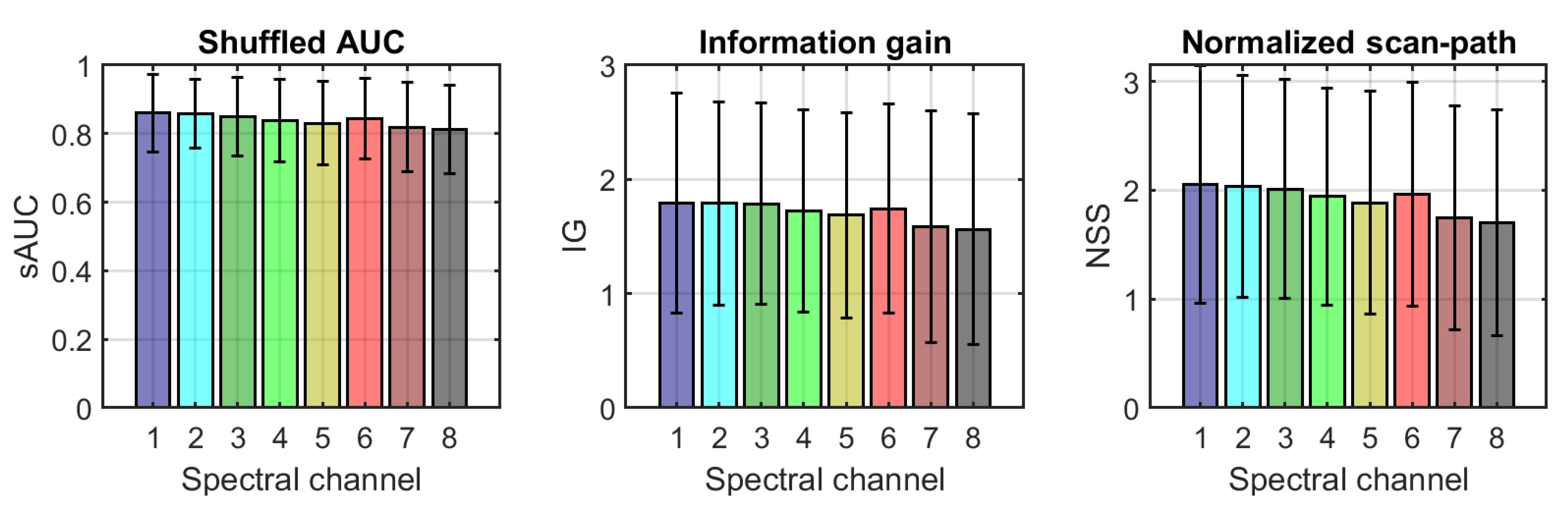
3.3. Example of Saliency Prediction Comparing RGB and Single-Band Spectral Images
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence; Springer: Berlin/Heidelberg, Germany, 1987. [Google Scholar]
- Canosa, R. Modeling Selective Perception of Complex, Natural Scenes. Int. J. Artif. Intell. Tools 2005, 14, 233–260. [Google Scholar] [CrossRef] [Green Version]
- Dale, L.M.; Thewis, A.; Boudry, C.; Rotar, I.; Dardenne, P.; Baeten, V.; Pierna, J.A.F. Hyperspectral imaging applications in agriculture and agro-food product quality and safety control: A review. Appl. Spectrosc. Rev. 2013, 48, 142–159. [Google Scholar] [CrossRef]
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Gao, W. Visual Saliency Computation: A Machine Learning Perspective; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8408. [Google Scholar]
- Liang, H. Advances in multispectral and hyperspectral imaging for archaeology and art conservation. Appl. Phys. A 2012, 106, 309–323. [Google Scholar] [CrossRef] [Green Version]
- Borji, A. Saliency prediction in the deep learning era: An empirical investigation. arXiv 2018, arXiv:1810.0371610. [Google Scholar]
- Wang, L.; Gao, C.; Jian, J.; Tang, L.; Liu, J. Semantic feature based multi-spectral saliency detection. Multimed. Tools Appl. 2017, 77, 3387–3403. [Google Scholar] [CrossRef]
- Wang, T.; Borji, A.; Zhang, L.; Zhang, P.; Lu, H. A stagewise refinement model for detecting salient objects in images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Borji, A.; Itti, L. State-of-the-art in visual attention modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 185–207. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Shen, J.; Xie, J.; Cheng, M.-M.; Ling, H.; Borji, A. Revisiting Video Saliency Prediction in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- TobiiProX2-60. Available online: https://www.tobiipro.com/product-listing/tobii-pro-x2-30/ (accessed on 30 January 2021).
- Peters, R.J.; Iyer, A.; Itti, L.; Koch, C. Components of bottom-up gaze allocation in natural images. Vis. Res. 2005, 45, 2397–2416. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Le Moan, S.; Mansouri, A.; Hardeberg, J.Y.; Voisin, Y. Saliency for Spectral Image Analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2013, 6, 2472–2479. [Google Scholar] [CrossRef] [Green Version]
- Borji, A.; Sihite, D.N.; Itti, L. Quantitative Analysis of Human-Model Agreement in Visual Saliency Modeling: A Comparative Study. IEEE Trans. Image Process. 2013, 22, 55–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What Do Different Evaluation Metrics Tell Us About Saliency Models? IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 740–757. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Bylinskii, Z.; Judd, T.; Borji, A.; Itti, L.; Durand, F.; Oliva, A.; Torralba, A. Mit Saliency Benchmark; MIT: Boston, MA, USA, 2015. [Google Scholar]
- Jiang, M.; Huang, S.; Duan, J.; Zhao, Q. Salicon: Saliency in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Cheng, M.-M.; Mitra, N.J.; Huang, X.; Hu, S.-M. SalientShape: Group saliency in image collections. Vis. Comput. 2013, 30, 443–453. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.-H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Alpert, S.; Galun, M.; Brandt, A.; Basri, R. Image segmentation by probabilistic bottom-up aggregation and cue integration. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 315–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Martínez, M.Á.; Etchebehere, S.; Valero, E.M.; Nieves, J.L. Improving unsupervised saliency detection by migrating from RGB to multispectral images. Color Res. Appl. 2019, 44, 875–885. [Google Scholar] [CrossRef]
- Song, S.; Yu, H.; Miao, Z.; Fang, J.; Zheng, K.; Ma, C.; Wang, S. Multi-Spectral Salient Object Detection by Adversarial Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence; Association for the Advancement of Artificial Intelligence (AAAI): Palo Alto, CA, USA, 2020. [Google Scholar]
- Tu, Z.; Xia, T.; Li, C.; Lu, Y.; Tang, J. M3S-NIR: Multi-modal Multi-scale Noise-Insensitive Ranking for RGB-T Saliency Detection. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019. [Google Scholar]
- İmamoğlu, N.; Ding, G.; Fang, Y.; Kanezaki, A.; Kouyama, T.; Nakamura, R. Salient object detection on hyperspectral images using features learned from unsupervised segmentation task. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Riche, N.; Mancas, M.; Duvinage, M.; Mibulumukini, M.; Gosselin, B.; Dutoit, T. RARE2012: A multi-scale rarity-based saliency detection with its comparative statistical analysis. Signal Process. Image Commun. 2013, 28, 642–658. [Google Scholar] [CrossRef]
- PixelTeq. Available online: https://www.oceaninsight.com/products/imaging/multispectral/spectrocam/ (accessed on 30 January 2021).
- Zeiss. Available online: https://www.zeiss.es/consumer-products/fotografia/milvus/milvus-2815.html (accessed on 30 January 2021).
- Ezio Color Edge CG 277. 2020. Available online: https://eizo.es/producto/coloredge-cg277/ (accessed on 30 August 2020).
- Engmann, S.; Hart, B.M.; Sieren, T.; Onat, S.; König, P.; Einhäuser, W. Saliency on a natural scene background: Effects of color and luminance contrast add linearly. Atten. Percept. Psychophys. 2009, 71, 1337–1352. [Google Scholar] [CrossRef] [PubMed]
- Kümmerer, M.; Wallis, T.S.A.; Bethge, M. Information-theoretic model comparison unifies saliency metrics. Proc. Natl. Acad. Sci. USA 2015, 112, 16054–16059. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Riche, N.; Duvinage, M.; Mancas, M.; Gosselin, B.; Dutoit, T. Saliency and human fixations: State-of-the-art and study of comparison metrics. In Proceedings of the IEEE international conference on computer vision, Sydney, Australia, 1–8 December 2013; pp. 1153–1160. [Google Scholar]
- Redies, C.; Amirshahi, S.A.; Koch, M.; Denzler, J. PHOG-derived aesthetic measures applied to color photographs of artworks, natural scenes and objects. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Barla, A.; Franceschi, E.; Odone, F.; Verri, A. Image kernels. In International Workshop on Support Vector Machines; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Choudhary, B.K.; Shanker, N.K.S.P. Pyramid method in image processing. J. Inf. Syst. Commun. 2012, 3, 269–273. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E.; Eddins, S.L. Digital Image Processing Using MATLAB; Pearson Education India: Chennai, India, 2004. [Google Scholar]
- UGR Spectral Saliency Database. Available online: http://colorimaginglab.ugr.es/pages/Data (accessed on 30 January 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| λ (nm) | 425 | 482 | 530 | 570 | 615 | 680 | 770 | 833 |
| BW (nm) | 50 | 56 | 24 | 50 | 100 | 50 | 102 | 125 |
| Metric | AUCB | AUCJ | sAUC | NSS | IG |
|---|---|---|---|---|---|
| C vs. Fobs | 0.0214 (0.0141) | 0.0170 (0.0160) | 0.0193 (0.0138) | 0.0349 (0.0208) | 0.0048 (0.0047) |
| C vs. Facc | 0.0074 (0.0074) | 0.0021 (0.0020) | 0.0062 (0.0080) | 0.0066 (0.0081) | 0.0076 (0.0114) |
| CAT | 0.0041 (0.0045) | 0.0062 (0.0096) | 0.0012 (0.0019) | 0.0032 (0.0054) | 0.0009 (0.0013) |
| FREE | 0.0061 (0.0096) | 0.0053 (0.0062) | 0.0086 (0.0102) | 0.0089 (0.0167) | 0.0119 (0.0137) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez-Domingo, M.Á.; Nieves, J.L.; Valero, E.M. Eight-Channel Multispectral Image Database for Saliency Prediction. Sensors 2021, 21, 970. https://doi.org/10.3390/s21030970
Martínez-Domingo MÁ, Nieves JL, Valero EM. Eight-Channel Multispectral Image Database for Saliency Prediction. Sensors. 2021; 21(3):970. https://doi.org/10.3390/s21030970
Chicago/Turabian StyleMartínez-Domingo, Miguel Ángel, Juan Luis Nieves, and Eva M. Valero. 2021. "Eight-Channel Multispectral Image Database for Saliency Prediction" Sensors 21, no. 3: 970. https://doi.org/10.3390/s21030970
APA StyleMartínez-Domingo, M. Á., Nieves, J. L., & Valero, E. M. (2021). Eight-Channel Multispectral Image Database for Saliency Prediction. Sensors, 21(3), 970. https://doi.org/10.3390/s21030970