In this section, we first present the overall framework of the LC-CRDSA3 scheme, then provide a more detailed outline of the basic load estimation and load forecasting processes in our proposed scheme.
3.1. Overview
As discussed in
Section 1, the key concept underpinning LC-CRDSA3 is that of dynamically controlling the network load. When the load threatens to exceed the critical value, only certain nodes are allowed to send data, and the load is controlled to be close to the critical value, which effectively improves the throughput.
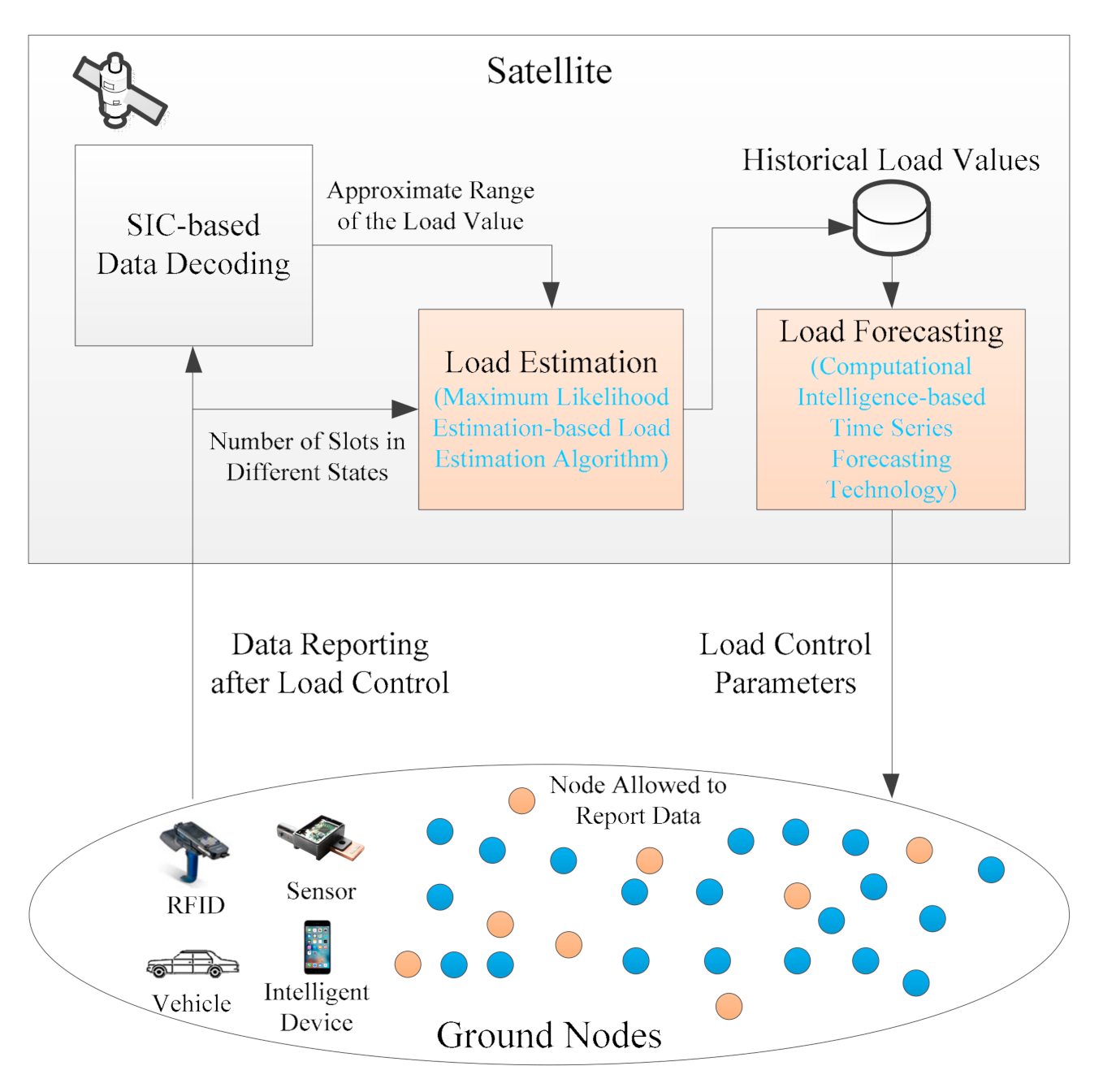
Figure 1 illustrates the framework of the LC-CRDSA3 scheme. When a frame arrives at the satellite, the satellite decodes the data based on SIC technology. In order to control load, LC-CRDSA3 needs to perform load estimation and load forecasting. After the data reception process for each frame is complete, the satellite estimates the load value of the frame (that is, estimates how many packets are sent by ground nodes in this frame). In terms of load estimation, we first determines the approximate range of the load value according to the decoding result of a frame, and innovatively propose an MLE-based load estimation algorithm, which makes full use of the number of slots in different states to estimate the load. Through load estimation, we can obtain the load value of each frame, which is the historical load value. Based on these historical load values, LC-CRDSA3 employs computational intelligence-based time series forecasting technology to forecast the load values of future frames.
If the forecasted load value of a future frame does not exceed the critical value, no load control is required and the ground nodes send data normally. Otherwise, the load needs to be controlled. The satellite calculates the load control parameter according to the forecasted load value, then broadcasts it to the ground nodes before the start of the frame. The load control parameter is the proportion of nodes that are permitted to send data, and also represents the probability of each node being able to send data. After receiving the load control parameter, the ground nodes determine whether to send data according to the parameter in the corresponding frame. If the load forecasting is sufficiently accurate, the load after controlling will be near the critical value, thereby avoiding the throughput drop caused by excessive load.
3.2. Load Estimation
Even if SIC technology is employed, a satellite usually cannot decode all packets transmitted in a frame. After the data decoding process is complete, some packets may still remain in some slots that cannot be decoded due to the presence of some so-called “loops” [
11]. Due to data collisions, we cannot know exactly how many packets remain in these slots. Accordingly, in order to obtain the historical load value, when the satellite is unable to decode all packets in a frame, load estimation is required.
Suppose that the load value of a particular frame (that is, the number of packets transmitted in this frame) is
, the number of replicas of each packet is
, and the number of slots contained in a frame is
. According to the number of packets (or packet replicas, when
) in a slot, each slot has three states: idle (the number of packets is 0), successful (the number of packets is 1) and collided (the number of packets exceeds 1). Accordingly, we refer to slots in these three states as idle slots, successful slots, and collided slots respectively. The number of idle, successful and collided slots in a frame is denoted by
,
, and
, respectively. Since the number of slots in different states will be affected by
, we can estimate
by observing the values of
,
, and
in the frame. The estimated value of
is represented by
. We define the load estimation precision of a frame as follows:
The load estimation precision will affect the accuracy of subsequent load forecasting.
For not sending multiple replicas (that is, when
), several load estimation algorithms have been proposed. Vogt [
34] proposed a simple load estimation algorithm, which assumes that each collided slot contains two packets; its load estimation expression is:
In [
35], Cha et al. modified the above algorithm, assuming that each collided slot contains 2.39 packets on average, i.e.,:
Another load estimation algorithm was proposed by Khandelwal et al. [
36]; this algorithm uses only the number of idle slots to estimate the load value. The load estimation expression is as follows:
where
represents the random variable of the number of idle slots in a frame,
is the expectation of
, and ⌈ · ⌋ represents integer rounding. When
:
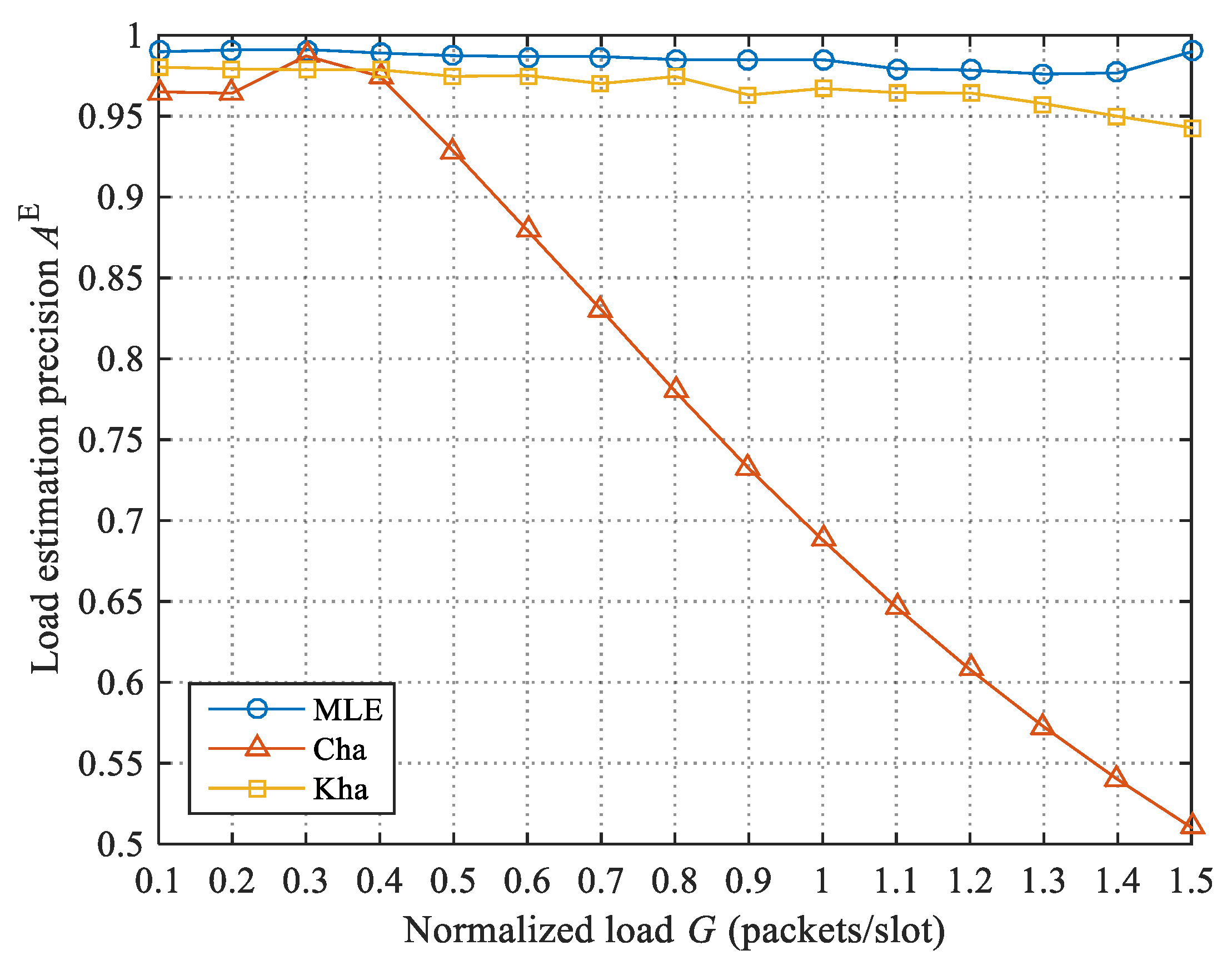
None of the above algorithms make full use of the number of slots in the three different states for load estimation, and the algorithm in Equation (4) is not suitable for situations in which no idle slot exists. In order to further improve the load estimation precision, we propose an MLE-based load estimation algorithm. This algorithm first determines the approximate range of the load value according to the decoding result of a frame, then uses MLE to accurately estimate the load.
Suppose the number of packets successfully received in a certain frame is
LS, while the number of slots still in a collided state following data decoding is
. Each packet will generate
replicas, and there are at least two packet replicas in each collided slot; thus:
We use
,
, and
to represent the random variables of the number of idle slots, successful slots and collided slots, respectively. Taking the idle slots as an example, according to the basic concept of MLE, since a sample
of the random variable
has already taken the sample value
, we contend that the probability
of
taking this sample value is relatively large.
will be affected by
; therefore, the value of
needs to make
relatively large. If only the sample value
is used to estimate
, we can obtain the estimated value:
in which
.
Suppose that the probability of samples
and
of random variables
and
taking sample values
and
is
and
respectively. In the same way, the value of
also needs to make
and
relatively large. Therefore, we choose the
that maximizes
as the estimated value of
; that is:
As is clear from the above, we use the number of slots in the three states simultaneously to estimate the load. It should be noted that, unlike the general MLE, we use the sample values of three random variables to calculate the estimated value of the parameter; accordingly, although there is only one sample value for each random variable, we can still obtain high estimation precision.
We next derive the expressions of
,
and
. As mentioned earlier, a packet
(
) generates
replicas, which randomly select
different slots from a total of
slots for transmission. The probability of a slot
(
) being selected by the packet
is thus:
Each packet selects slots independently. If slot
is in the idle state, this means no packet has selected it; the corresponding probability is:
When slot
is selected by only one packet, it is in the successful state, the corresponding probability of which is:
Hence, the probability of slot
being in the collided state is:
Therefore:
The above load estimation process estimates the number of packets actually sent in a frame. When implementing load control, it is necessary to forecast how many packets need to be sent before load control in future frames. We refer to the number of packets that need to be sent before load control in a frame as the original load of the frame. Therefore, in subsequent load forecasting, we need to forecast the original load values of future frames based on the historical values of the original load. If load control has been conducted in a frame, and the corresponding load control parameter is
pLC (this is known at the time of load estimation), then the estimated value of the original load of the frame is:
Otherwise, the estimated value of the actual load of the frame is the estimated value of the original load; that is:
3.3. Load Forecasting
It is first necessary to determine whether the load needs to be controlled according to the forecasted load values, after which the load control parameters can be calculated as required. We use time series forecasting technology to forecast the original load values of future frames based on the time series composed of the historical values of the original load in past frames (referred to as the load series). Suppose that the original load value of a frame is
, and the forecasted value of
is
. Similarly, we define the load forecast precision of this frame as follows:
In the network, a frame’s original load will be affected by the number of newly generated packets in the frame, the number of packets with no chance of being transmitted in the previous frames, the number of retransmitted packets, and the accuracy of the previous load forecasting. Worse yet, since the load series will be affected by the load forecasting process, before a load forecasting method is applied, we cannot obtain the load series in advance under this method for feature analysis. It is therefore difficult to use classic time series models, such as the autoregressive integrated moving average (ARIMA) model, to model the load series.
Computational intelligence-based time series forecasting is a new type of time series forecasting technology. The key advantage of this approach is that it is well-suited to capture the characteristics of the load series through learning. Moreover, we can use the load series during network operation to train the forecasting model dynamically, which enables the model to dynamically adapt to the law of load changes. Two representative and most commonly used methods of this type are neural network-based and support vector machine-based time series forecasting.
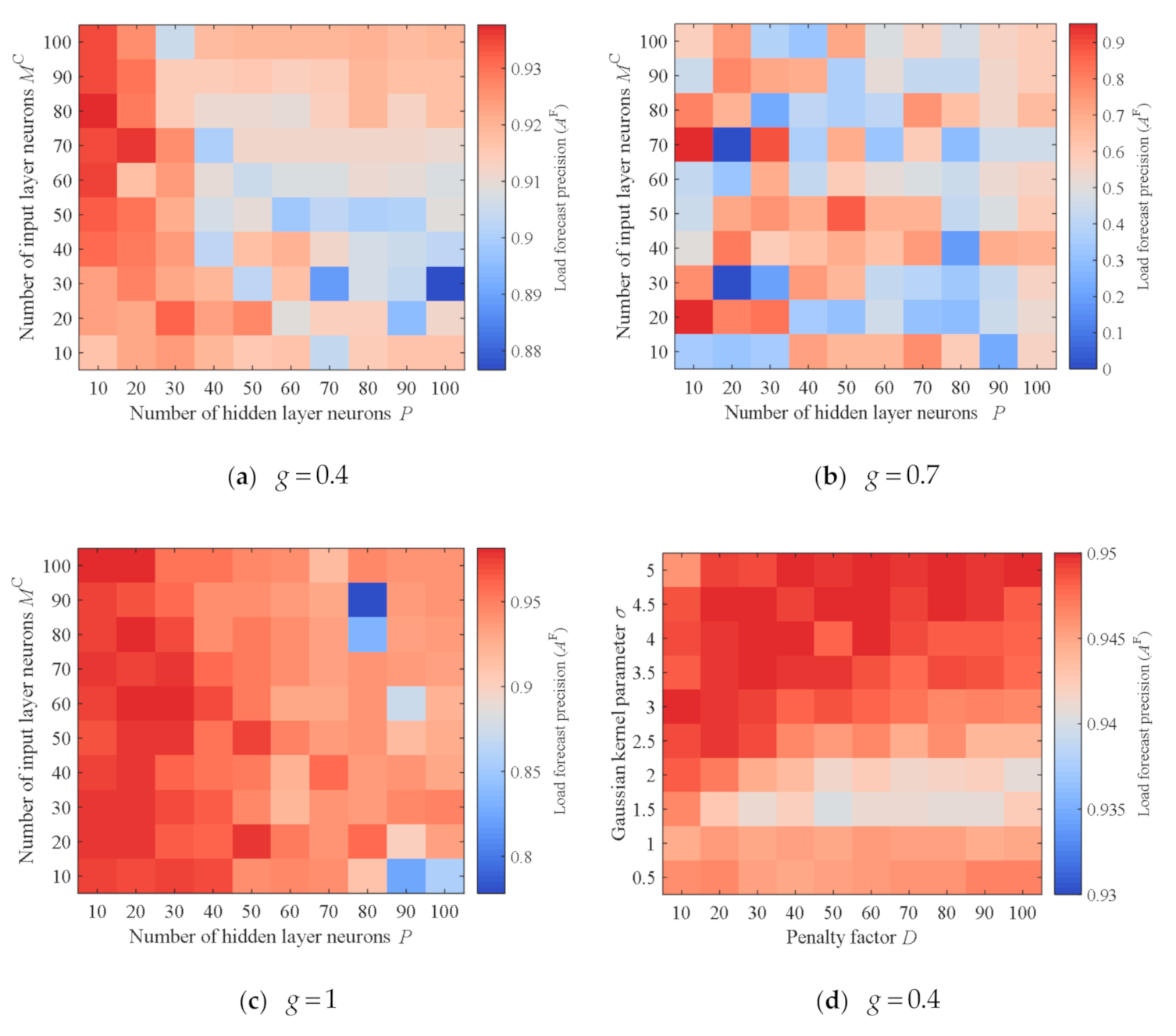
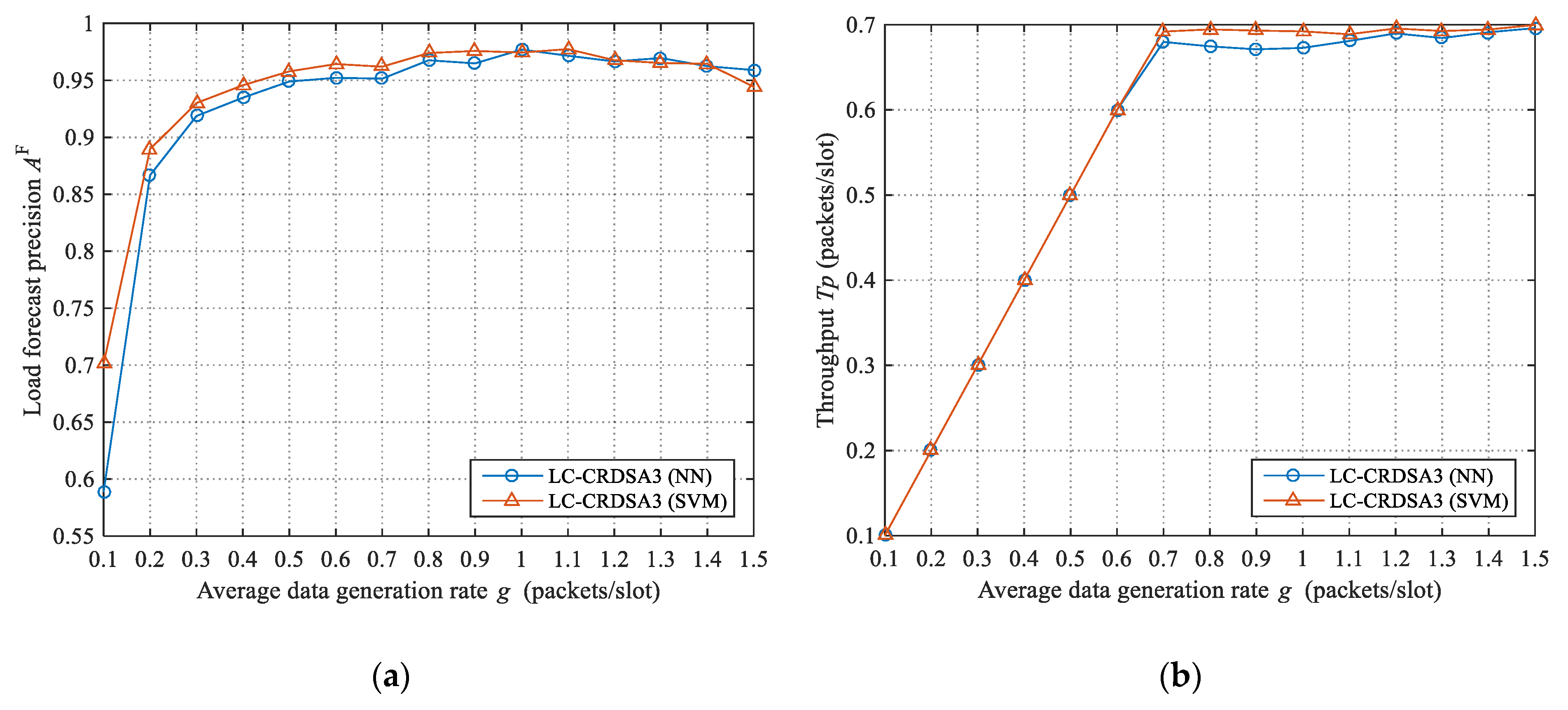
Neural network-based time series forecasting is a non-parametric method that makes no assumptions about the time series model. As long as the neural network has enough hidden layers and each hidden layer has enough neurons, this approach can approximate any complex function with any level of precision. However, neural network-based time series forecasting is difficult to guarantee accuracy when the number of learning samples is small; when the number of samples is large, the generalization performance is low.
Support vector machine is an algorithm based on the principle of structural risk minimization. Support vector machine-based time series forecasting is a convex quadratic optimization problem, which can ensure that the extremal solution obtained is the global optimal solution. However, when the number of samples is large, this method causes great computational and storage overhead. Moreover, this method is very sensitive to the parameters and kernel function.
It can be seen that these two methods have their own advantages and disadvantages. Since we do not know the characteristics of the load series, and the characteristics will be affected by the forecasting methods, we explore the use of these two methods for load forecasting respectively.
3.3.1. Neural Network-Based Load Forecasting
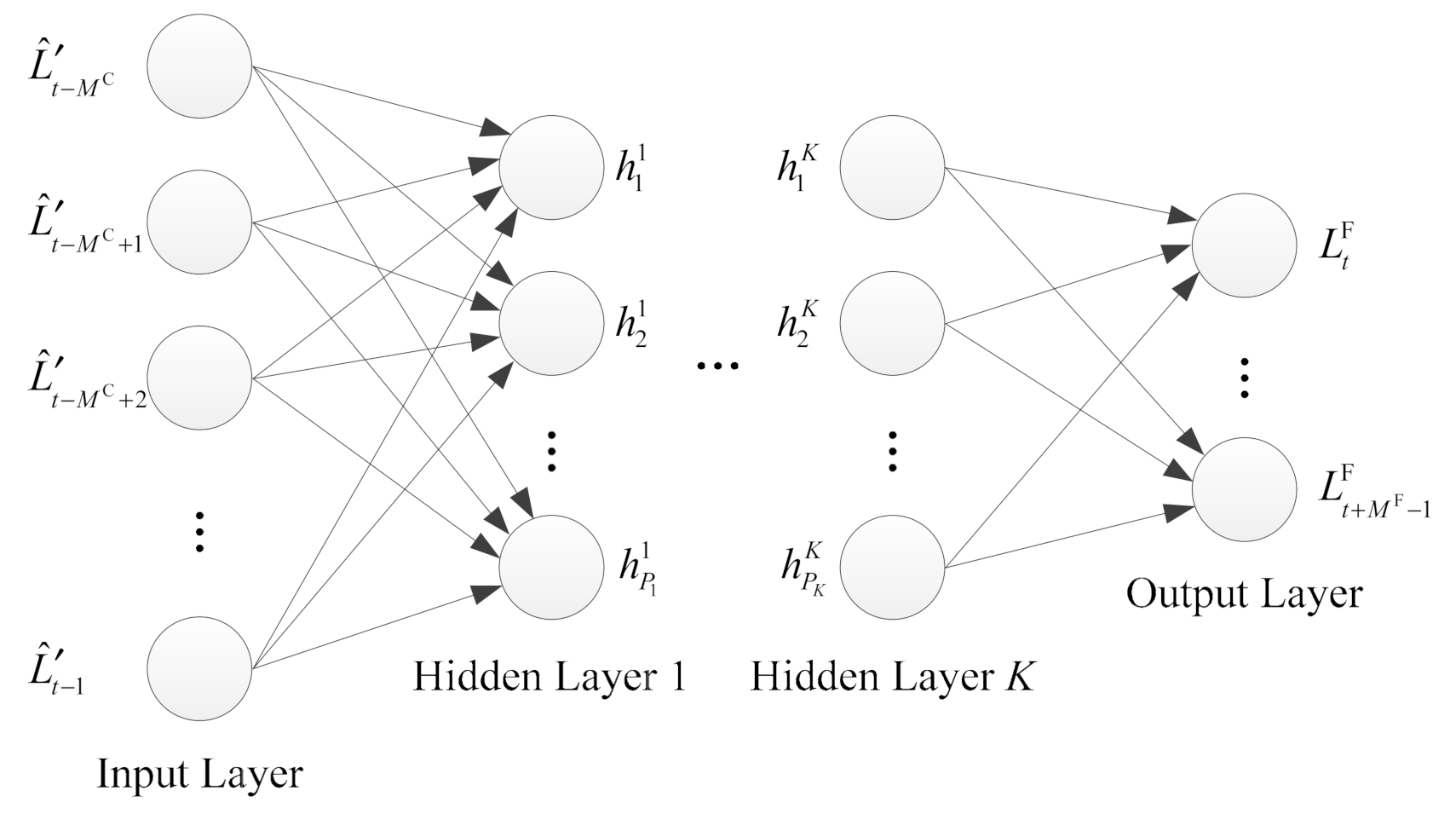
As shown in
Figure 2, we adopt the most widely used multilayer feedforward neural network for load forecasting. The neural network consists of one input layer,
hidden layers and one output layer. It is assumed that the load value of a frame is strongly correlated with the load values of the past
MC frames; the value of
MC is related to the specific network scenarios. Therefore, we use the load values of the past
MC frames to forecast the load value of a future frame. If we assume that the satellite is currently receiving the signal of the
-th frame, then the input layer contains
MC neurons, which receive
MC historical load values
respectively. It should be noted that since the
-th frame has not been completely received, its load value cannot yet be obtained.
The number of hidden layers and the number of neurons in each hidden layer need to be determined according to specific network scenarios. If the number of hidden layers or the number of neurons in each layer is too small, the neural network may not be able to fully capture the characteristics of the load series; on the other hand, if these values are too high, this may cause overfitting and reduce generalization ability. The neural network processes the information from one layer to the next through the activation function. We denote the input layer as layer 0,
as
respectively; then,
, the hidden layers are from layer 1 to layer
, and the output layer is layer
. The value of the
-th (
) neuron
in the
k-th (
) layer is:
in which
is the value of the
-th (
) neuron
in the
-th layer,
is the weight of the connection between
and
,
is the constant deviation, and
is the activation function; moreover, the symbolic logic function is typically used, that is:
The load control parameter of a frame needs to be broadcast to the ground nodes before the start of the frame. Since both load forecasting and load control parameter transmission take time, the load forecasting of a frame needs to be performed in advance. Suppose that the time required for load forecasting is
, while the one-way propagation delay between the satellite and ground node is
; thus, the time period for which the load forecasting is advanced relative to the start of a frame is
, where
is the safety factor. The number of load forecasting steps is therefore:
where
is the duration of a slot. Accordingly, the output layer contains
neurons, where the value of the
-th neuron
—that is, the forecasted load value of the
-th frame is:
Here,
is the value of the
-th neuron
in the
-th layer,
is the weight of the connection between
and
,
is the constant deviation, and
is the activation function; the linear function is typically used, i.e.:
Before using the neural network for load forecasting, it is necessary to train the neural network with the historical load values. We use the load series
obtained in the previous time period
to train the neural network, where
is the number of frames contained in
. In training, the load series
(
) is input, and the load series
is output. The trained neural network can be regarded as a nonlinear autoregressive model:
where
is the relationship function obtained through training, while
is the white noise random disturbance.
3.3.2. Support Vector Machine-Based Load Forecasting
The use of support vector machines for time series forecasting is based on support vector regression. As discussed above, in the load forecasting problem, our goal is to predict the load value of the -th frame through the historical load values of the past frames. We can obtain the forecasted load value of the -th frame through single-step forecasting. First, we calculate the forecasted load value of the -th frame using , after which we calculate the forecasted load value of the -th frame through . By analogy, can be forecasted through .
To successfully execute the above forecasting process, we aim to obtain the functional relationship between the load values
of
consecutive frames and the load value
of the next frame. Let
and
; here, our goal is to get the function
so that:
We can learn an approximation
of
from the load series
obtained in the previous time period
through support vector regression for load forecasting.
samples
can be obtained from
, where
(
) is an
-dimensional vector, and the definitions of
and
are as follows:
The basic concept of support vector regression is to map the samples to a specific feature space
through a non-linear mapping
, and linear regression can be performed in this space; that is:
where
is the offset. Support vector regression can tolerate a deviation between
and
smaller than
. We select the linear insensitive loss
, which has good sparsity and can ensure the generalization ability of the result. Support vector regression can be formally expressed as:
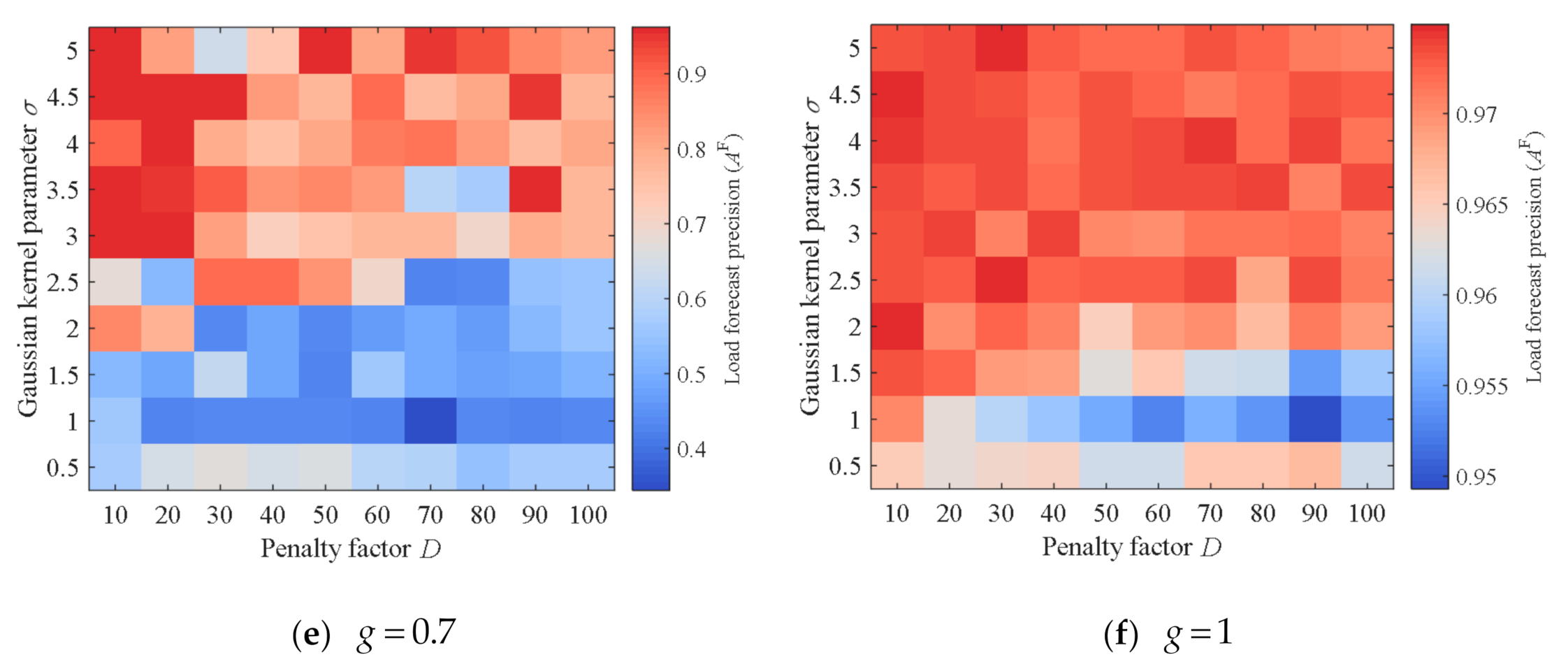
In the above formula, is the penalty factor, which can balance the complexity of the regression model and the degree of sample fit. The larger the , the higher the degree of fit and the higher the model complexity.
By using the duality principle, and introducing Lagrangian multipliers and kernel function, the above support vector regression can be transformed into the following optimization problem:
In the above formula,
is the Lagrangian multiplier vector.
is the kernel function, which can combine the two steps of feature mapping and inner product calculation into one step, maintaining the computational complexity at
. There are many kernel functions, which need to meet Mercer conditions. We adopt the most commonly used Gaussian kernel function:
where
is the Gaussian kernel parameter. At this time:
By solving the above convex quadratic programming problem, we can obtain:
According to the KKT (Karush-Kuhn-Tucker) theorem, by deriving equation:
the offset
b can be solved.
As discussed above, after learning to obtain the function
, through
-step forecasting, we can obtain the forecasted load value of the
-th frame:
where
.
3.3.3. Carrying Out Load Forecasting in the Network
Load forecasting using neural network- or support vector machine-based time series forecasting technology can be divided into two stages, specifically model training and load forecasting.
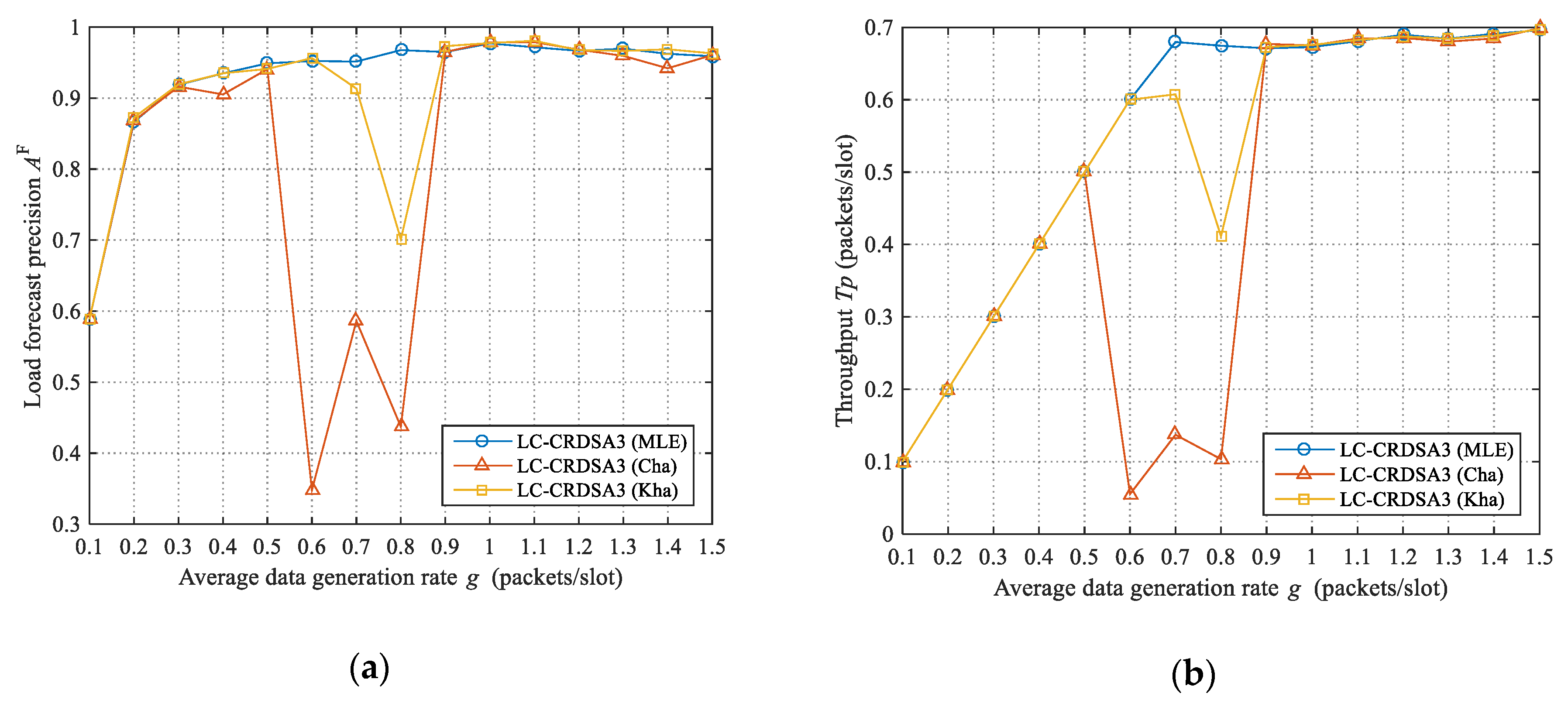
Model training: Since the load series will be affected by the load forecasting, we cannot obtain the load series samples in advance to train the forecasting model (neural network or support vector machine). In addition, the law of load change usually differs across different time periods. We accordingly update the forecasting model dynamically during use. More specifically, in the initial period , no load control is performed, and the load series of this period is obtained to train the forecasting model. The trained forecasting model is then used for load forecasting. After that, the forecasting model is retrained every . Therefore, the forecasting model can update the parameters according to the change of the load series law, thereby ensuring that high load forecast precision is always maintained. In actual scenarios, we can use two forecasting models, and . Note that, here, and are the same kind of forecasting model (that is, both and are either neural networks or support vector machines). While a model is in use, the other model is retrained using the newly obtained load series; when the training of model is complete, we switch to using for load forecasting, and vice versa.
Load forecasting: Once a forecasting model has been trained, we can use it for load forecasting. By taking the load series of the past frames as input, we can obtain the forecasted load value of the subsequent frames. As discussed above, we need the forecasted load value of the -th frame.
We denote the critical load value of CRDSA3 as
. If
, load control is required for the
-th frame, and its load control parameter is:
The process of load forecasting is outlined in Algorithm 1. In this algorithm, is the frame sequence numbers, is the sequence number of the frame when the load forecasting is first carried out, is the load series used for forecasting model training in the -th frame,
is a function used to find the remainder of divided by , is the function that uses the load series to train the forecasting model , and is a function that uses the prediction model to perform load forecasting through the load series .
| Algorithm 1 Load Forecasting |
| Input: (), , , |
| Output: () |
| Initialize: |
| 1. for each do |
| 2. if |
| 3. /* Train the forecasting models every frames */ |
|
4. if |
| 5. |
| 6. if |
|
7. |
| 8.
else |
| 9.
|
| 10.
end if |
| 11.
end if |
|
12.
/* Use the trained forecasting models for load forecasting */ |
| 13.
|
|
14.
if |
|
15.
if has been trained |
| 16.
if |
| 17.
|
| 18. end if |
| 19.
|
| 20.
else if |
| 21.
|
| 22.
end if |
| 23.
else |
| 24.
if has been trained |
| 25.
|
| 26.
else |
| 27.
|
| 28.
end if |
| 29.
end if |
| 30.
end if |
| 31.
end for |
| 32. return () |
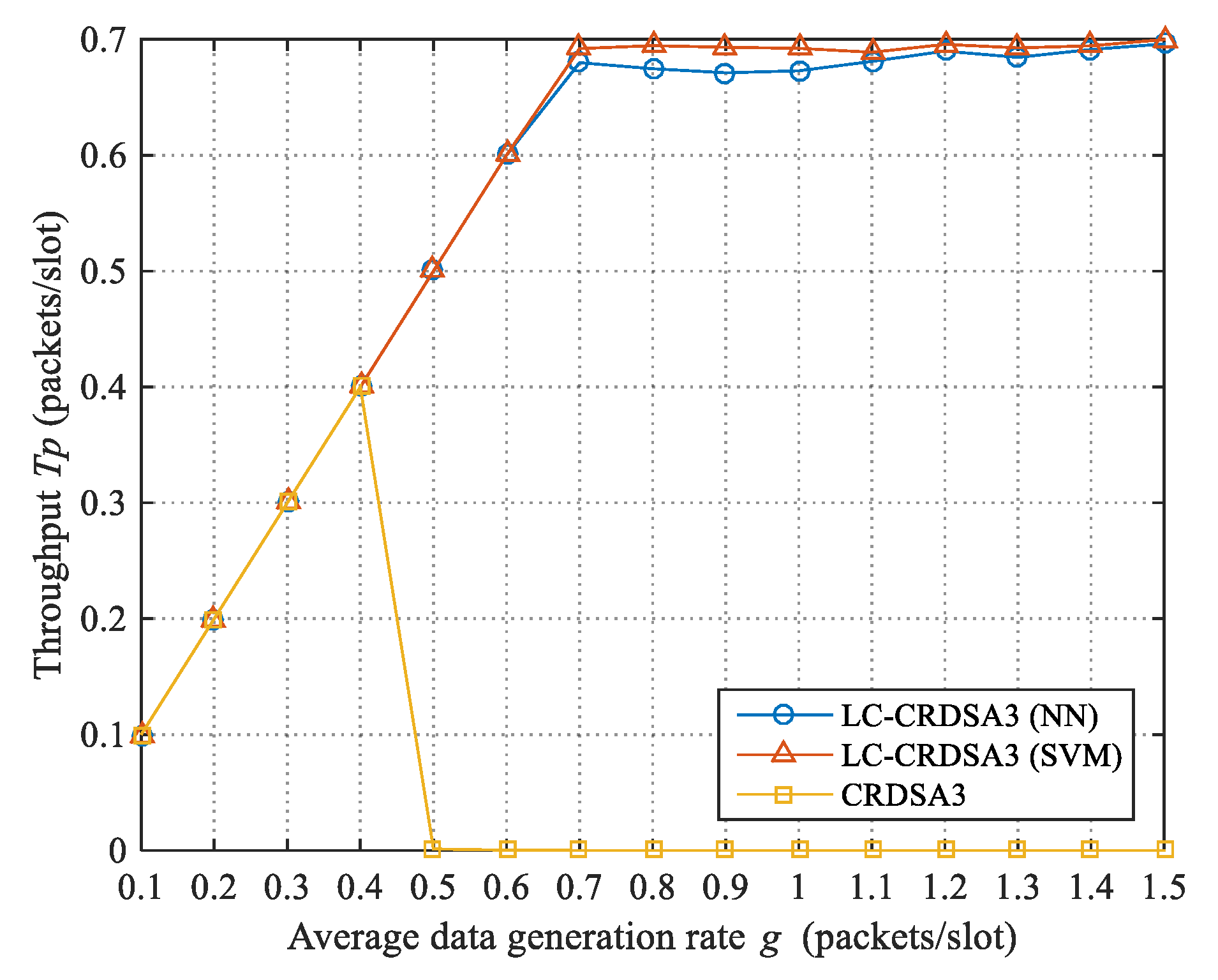
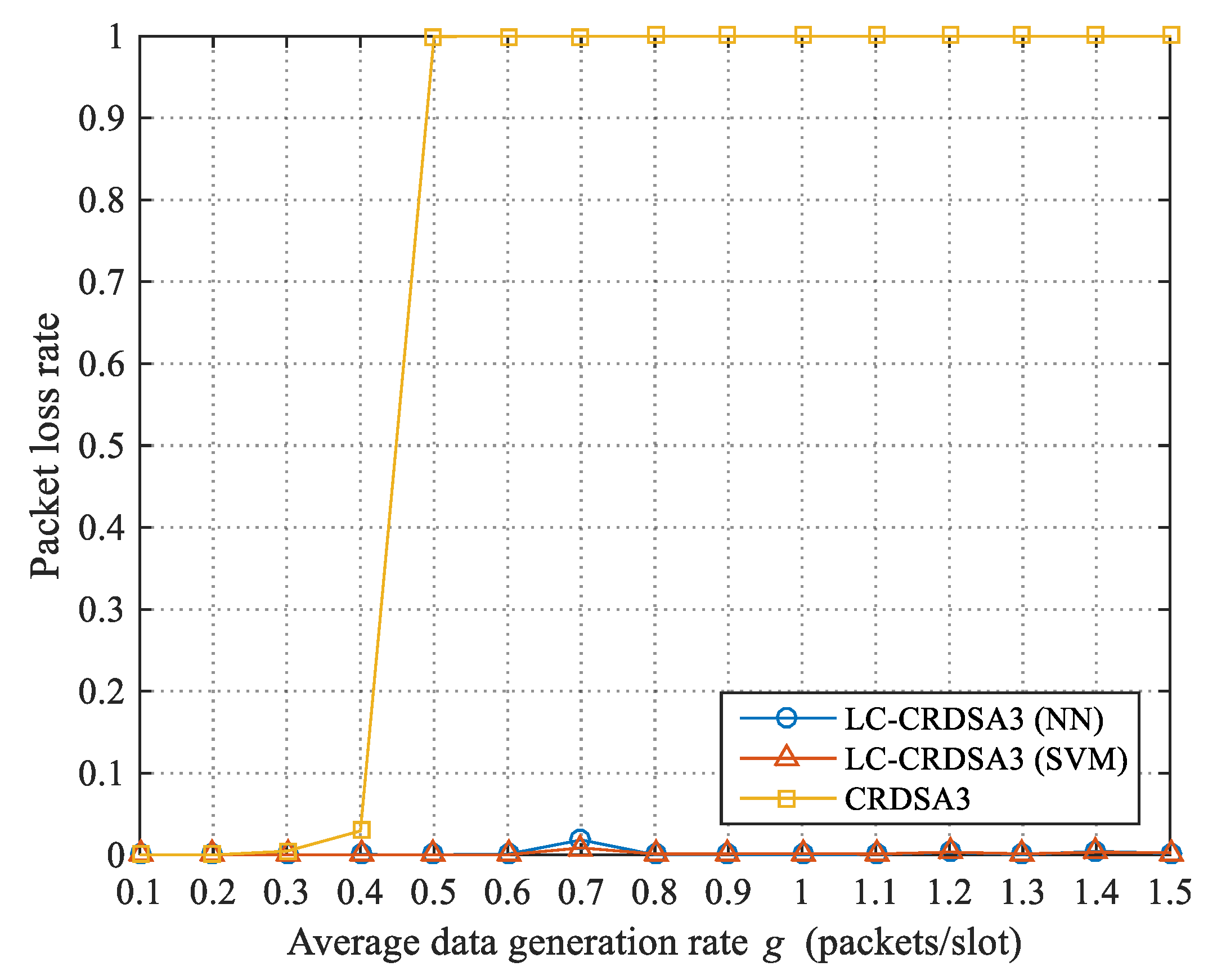
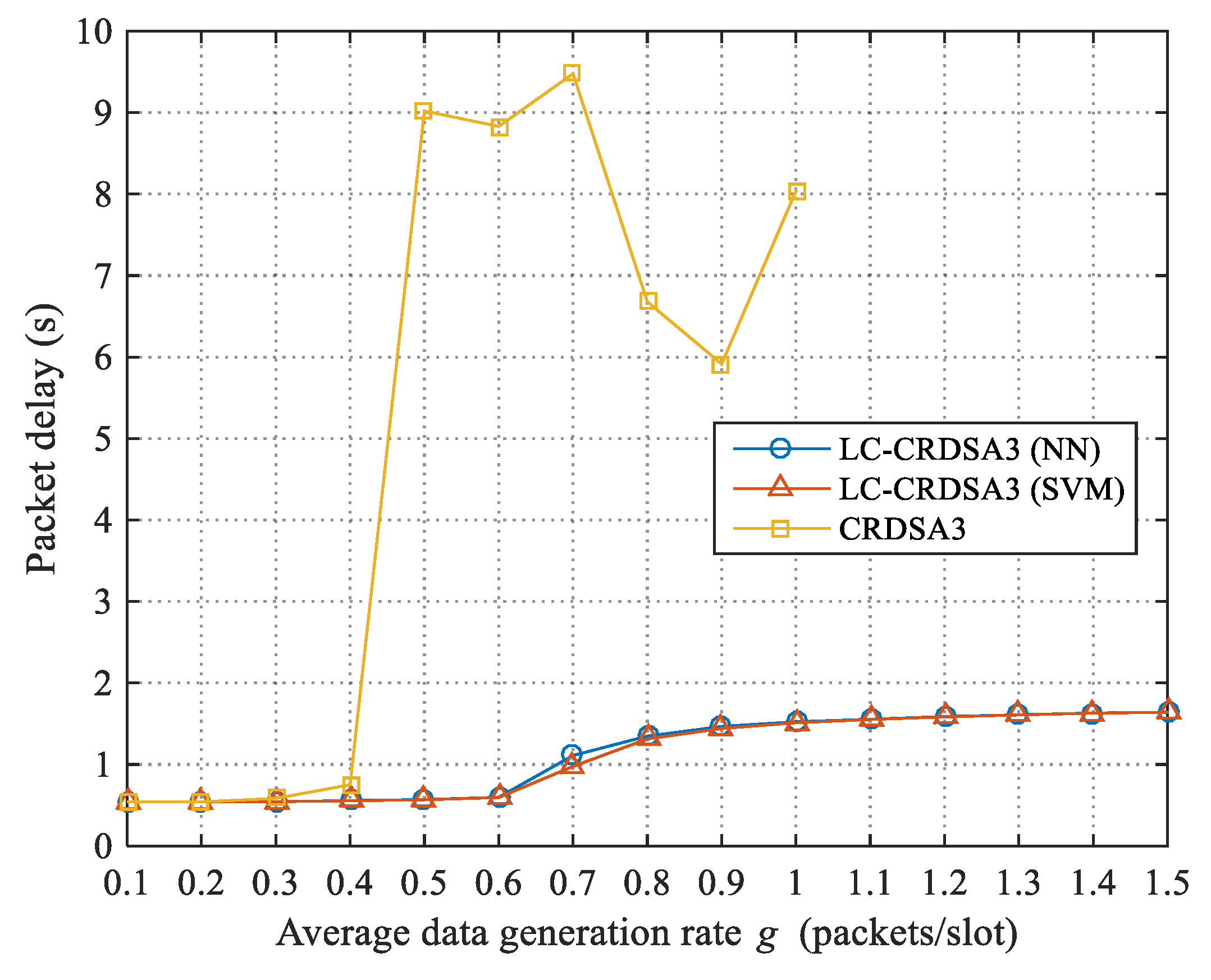
3.3.4. The Impact of Load Forecast Precision on Throughput
When the forecasted load value
of a frame is less than or equal to the critical load value
, no load control is performed, and the load forecasting process will not affect the throughput of the frame. When
is greater than
, the frame will carry out load control. Suppose the original load of the frame is
, while the load forecast precision is
; then,
is equal to
(50% probability) or
(50% probability). The load control parameter of this frame is:
and the load of this frame after load control—that is, the actual load—is:
According to [
29], when the number of SIC iterations is
and the normalized load is
, the throughput of CRDSA3 is:
where
is the probability of a replica
of a packet being successfully transmitted:
while
is the probability of a packet being interfered by
packets in a given slot, and
is the probability that the replica
is alone in a given slot.
The normalized load of this frame is
. Therefore, when SIC iterates
times, the expected throughput of the frame is:
CRDSA3 reaches maximum throughput at the critical load value
(the normalized load is
):
It can be observed that the higher the load forecast precision (i.e., the closer to 1), the closer the load after control will be to the critical value, and the closer the throughput will be to the maximum throughput. The expected value of the gap between the throughput and the maximum throughput caused by the load forecast error is:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}