
From Data to Actions in Intelligent Transportation Systems: A Prescription of Functional Requirements for Model Actionability



{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- In the first place, we identify the gap between the data-driven research reported so far, and the practical requirements that ITS experts demand in operation. We capitalize on this gap to define what we herein refer to as actionable data-based modeling workflow, which comprises all data processing stages that should be considered by any actionable data-based ITS model. Although diverse data-based modeling workflows can be found in literature with different purposes, most of them count on recognized stages, that are presented in this work from an actionability perspective, i.e., what to take into account from the operational point of view when designing the workflow, how to capture and preprocess data, how to develop a model and how to prescribe its output. These guidelines are proposed and argued within an ITS application context. However, they can be useful for any other discipline in which data-based modeling is performed.
- Next, functional requirements to be satisfied by the aforementioned workflow are described and framed in the context of ITS systems and processes, with examples exposing their relevance and consequences if they are not fulfilled.The contributions of this section are twofold: on the one hand, we identify and define the holistically actionable ITS model along with its main features; on the other hand, we enumerate requirements for each feature to be considered actionable, as well as a review of the latest literature dealing with these features and requisites.
- Finally, on a prospective note we elaborate on current research areas of Data Science that should progressively enter the ITS arena to bridge the identified gap to actionability. Once the challenges of modeling and ITS requirements have been stated, we review emerging research areas in Artificial Intelligence and Data Science that can contribute to the fulfilment of such requirements. We expect that our reflexive analysis serves as a guiding material for the community to steer efforts towards modeling aspects of more impact for the field than the performance of the model itself.
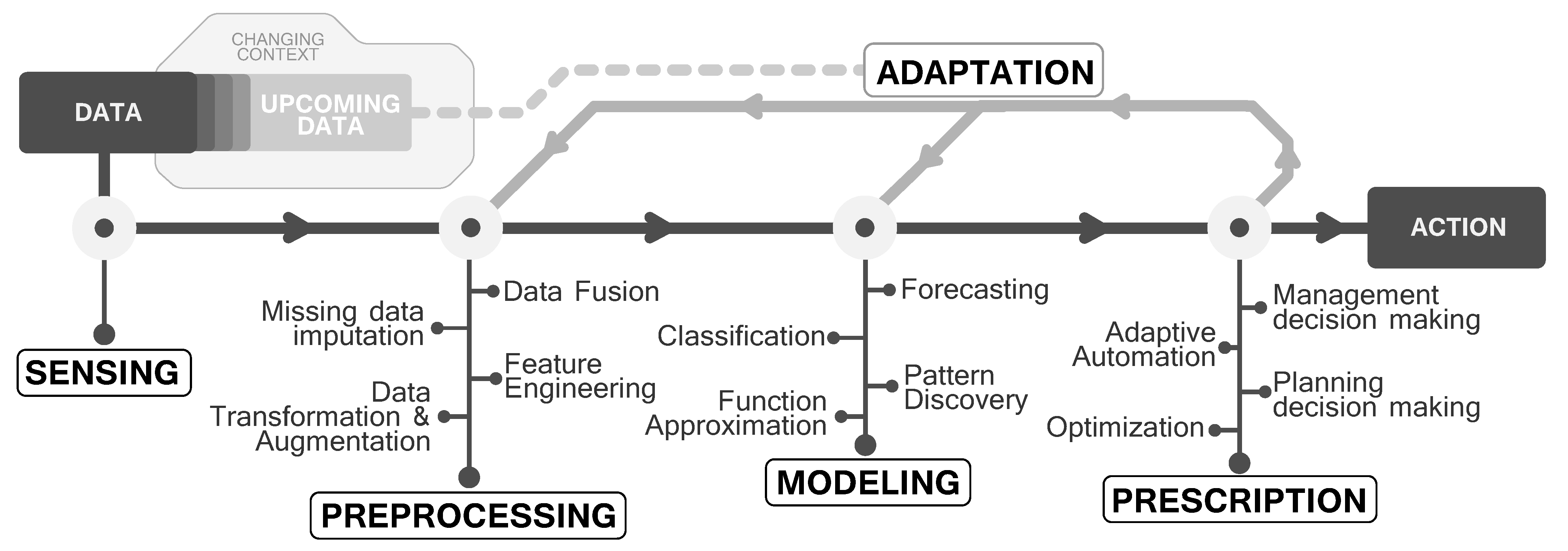
2. From Data to Actions: An Actionable Data-Based Modeling Workflow
2.1. Data Acquisition (Sensing)
- 1.
- Roadside sensing, which brings together tools and mechanisms that directly capture and convey data measurements from the road, obtaining valuable metrics such as speed, occupation, flow or even which vehicles are traversing a given road segment. These are the most commonly used sensors in ITS, most frequently based on computer vision and radar, as they directly provide traffic information close to the point where it originates. This kind of sensed metrics are useful for traffic flow or speed modeling, allowing practitioners to identify mobility patterns and to model them, so future behavior in sensorized locations can be estimated. Counting vehicles or detecting their speed at a certain point of the road also allows to obtain network wide mobility patterns that can be compared to those provided by a simulation engine. This can help traffic managers and city planners take long-term decisions, such as which road should be extended or how a road cut could affect other segments. However, this information is tethered to the exact points where the sensors are placed, thus the actionability of a system built upon these data is subject to the geographical area where such sensing devices are deployed and their range.
- 2.
- In-vehicle sensing, which includes a broad range of transponder devices that are part of the on-board equipment of certain fleets. Commercial vehicles on land, air and water usually have location devices that record and emit the position and other metrics of the vehicles at all times. This opens up a wide range of ITS applications, such as fleet management [8], route optimization [9], delay analysis and detection [10], airport/port management [11] or, when the vehicles are a part of traffic, a detailed analysis of their behavior along a complete route (not only in certain sensorized locations) [12]. This technology is highly extended in commercial fleets and its multiple analytic applications are nowadays remarkably actionable, due to industry standards requirements. However, machine learning modeling based approaches are starting to emerge, and should consider actionability as a core concern.
- 3.
- Cooperative sensing, which denotes the general family of data collection strategies that regards the information provided by different users of the ITS ecosystem as a whole, thus being grouped and jointly processed forward. This inner perspective of traffic and transportation can be obtained through many mechanisms, and, although it is more specific and scarce, it is also more complete than the one obtained from roadside sensing. These data open the door to mobility profiling and anomaly detection, enriching the outlook of a transportation model by means of the fusion of different data-based views of an ITS scenario. This includes all forms of mobile sensing data, from call detail record data that can be used to obtain users trajectories [13], to GPS data [14]. These sources are the foundation of abundant research [15,16], but in most cases the data fusion part is obviated. Crowdsourced and Social Media sensing can be analogously considered in this category. These data sources can also contribute to data-based ITS models by means of sentiment analysis and geolocation. The use of crowd-sourced data is well established among technology-based companies (Google, Uber etc), yet not very often available to research community and private and public authorities in the transport operations management. The limited information that becomes available is deprived from the necessary statistical representativeness and truthfulness in order to be easily integrated to legacy management systems.
- 4.
- External data sources, which include all data that are not directly related to traffic of demand, but have an impact on it, such as weather, calendar, or planned events, social and economic indicators, demographic characteristics etc. These data are usually easy to obtain, and their incorporation to ITS models augments in general the quality of their produced insights and ultimately, the actionability of the actions yielded therefrom. It is also true that this data source is typically unstructured, which can pose a challenge regarding its automatic integration.
- 5.
- Structured/static data, which refers to data sources that provide information of elements that have a direct impact on transportation, such as public transportation lines and timetables, or municipal bike rental services. Due to their inherently structured nature, data provided by these sources are often arranged in a fixed format, making it easier to incorporate to subsequent data-based modeling stages. Any of the previous data and applications can be enriched with these kind of data; a model that is able to represent the mobility of a city would probably enhance its capabilities if it considered these data. For instance, a bus timetable can help understand traffic in the street segments that are traversed by the bus service or where its stops are located. These information sources must be considered for an intelligent transportation system to be actionable, being a particularly essential piece of urban and interurban mobility.
2.2. Data Preprocessing
2.3. Modeling
2.4. Prescription
2.5. Adaptation
- 1.
- In the preprocessing stage, adaptation could be understood from many perspectives: the incorporation of new sources of data, the partial or total failure of data capturing sensors, which lead to an increased need for data fusion, imputation, engineering or augmentation.
- 2.
- In the modeling stage, adaptations could range from model retraining, adaptation to new data or alternative model switching, to the change of the learning algorithm due to a change in the requested system requirements (for instance, in terms of processing latency any other performance indicator).
- 3.
- In the prescription stage, adaptation is intended to dynamically support decisions accounting for changes in data that propagate to the output of preceding modeling stages. Data-based modeling can deal with such changes and adapt their output accordingly, yet they are effective to a point. For instance, online learning strategies devised to overcome from concept drift in data streams can speed up the learning process after the drift occurs (by e.g., diversity induction in ensembles or active learning mechanisms). Unfortunately, even when model adaptation is considered the performance of the adapted model degrades at different levels after the drift. Extending adaptation to the prescription stage provides an additional capacity of the overall workflow to adapt to changes, leveraging techniques from prescriptive analysis such as dynamic or stochastic optimization.
3. Functional Requirements for Model Actionability
3.1. Usability
3.1.1. User Interface
- Usability techniques: if the output of the developed model is consumed through the use of an interface, common techniques like asking directly the users about their experience can be adopted [80]. Among them SUS surveys are the standard to provide interpretable metrics that can be used for the evaluation of passenger information systems [83] or any other kind of automated traveler information system [79].
- Quality of the provided information: in [76], another perspective is proposed, based on estimating the quality of the information provided by the model. Characteristics such as the means to access the information, the reliability of the information provider, or the awareness of the information availability can be measured for assessing the model’s usability.
- Transportation-aware strategies: an alternative way to measure usability is to take into account the transportation context and how the use of the model impacts the system. As many of these systems are used during the course of transportation, the environment must be considered in order to provide an adequate and pertinent output [82]. This particular aspect is regarded below in Section 3.4.
- Public transportation guidelines: when ITS developments are intended for the public domain, inclusion of disadvantaged collectives in the usability evaluation is a must [81]. The extent in which these concerns are addressed by the ITS solution should not be disregarded.
3.1.2. Consumption of the Model’s Output
- Confidence-based outputs: data-driven models are often subject to stochasticity as a result of their learning procedure or the uncertainty/randomness of their input data (as specially occurs in crowdsourced and Social Media data). This randomness imprints a certain degree of uncertainty in their outputs, which can be estimated values, predicted categories, solutions to an optimization problem or any other alike. Such outcomes are often assessed in terms of their similarity to a ground truth in order to quantitatively assess the performance of the data-based model. Thus, a practitioner aiming to make decisions based on the model’s output is informed with a nominal performance score (which has been computed over test data), and the predicted output for a given input. However, when one of such data-based models is intended to work in a real environment, there is no ground truth to evaluate the quality of the result they are providing towards making a decision.For instance, a predictive model could score high on average as per the errors made during the testing phase. However, predictions produced by the model could be less reliable during peak hours than during the night, being less trustworthy in the first case as per the variability of the data from which it was learned, and/or the model’s learning algorithm itself. For this reason, the estimation of the confidence of outputs from a data-based model must be analyzed for the sake of its usability. For example, a public transportation model that provides outlooks of future demand could be more usable if, besides the estimation itself, some kind of confidence metric was provided. Elaborating on this aspect is not very frequent in academic research, mainly due to the fact that confidence is not always that easy to obtain and the estimation procedure is, in most cases, model-specific, requiring a previous statistical analysis of input data to properly understand their variability and characteristics. Unfortunately, such a confidence analysis is usually left out of the scope of research contributions, which rather focus on finding the best scoring model for a particular problem. Exceptions to this scarcity of related works are [84], in which the uncertainty inherent to artificial neural networks is analyzed in a real ITS context; [85], in which a committee of different models provides intervals of confidence to predictions;or the more recent contribution in [86], which departs from previous findings in [87,88] to estimate the uncertainty of traffic demand. This uncertainty estimation is then used as an input to assess the confidence of traffic demand predictions. These few references exemplify good practices that should be universally considered in contributions to appear.
- Interpretability: a stream of work has been lately concentrated around the noted need for explaining how complex models process input data and produce decisions/actions therefrom. Under the so-called XAI (eXplainable Artificial Intelligence) term, a torrent of techniques have been reported lately to explain the rationale behind traditional black-box models, mainly built for prediction purposes [89,90]. Nowadays, Deep Learning is arguably the family of data-driven models mostly targeted by XAI-related studies [91,92].The interest of transport researchers to interpretable data-driven models is not new; intuitively, any decision in transportation and traffic operations should be based on a solid understanding of the mechanism by which different factors interact and influence transportation phenomena [93]. In the transportation context explainability is closely related to integrability, when it comes to traffic managers, as ensuring that data-based models can be understood by non-AI expert can make them appropriately trust and favor the inclusion of data-based models in their decisional processes. When framed within ITS systems and processes, the need for explainable data-based models can help decision makers understand how information is processed along the data modeling pipeline, including the quantification of insightful managerial aspects such as the relationship and sensibility of a predicted output with respect to their inputs.
- Trade-off between accuracy and usability: when ITS data-based models aim at superior performances, they often work in ideal scenarios where the real context of application is disregarded; should that context apply in practice, the claimed suitability of the developed model for its particular purpose could be compromised. For instance, the goodness of an ITS model devised to detect users’ typical trajectories can be measured with regard to the exactitude of the detected trajectories. If the pursuit of a superb performance relies on a constant stream of data (hence, eventually depleting the user’s phone battery), it could be a pointless achievement when put to practice. This particular example has been already considered by plenty of researchers [94,95]. However, there is a long way to go in this aspect, as most ITS research developments consider only ideal circumstances without regarding the implications that an accurate design could have on its final usability.
3.2. Self-Sustainability
- Adaptable: Data-driven models for ITS applications created in controlled conditions, with static, self-contained datasets, can provide great performance metrics, but could also fail if data evolve along time [96]. Adaptation is the reaction of a system, model or process to new circumstances intended to reduce its performance deterioration in comparison to the one expected before the change in the environment happened. If data change over time, their evolution is not detected by the model and it does not adapt to it whatsoever, then the developed model will eventually provide an obsolete output. When these contextual variations occur over data streams and models are learned on-line therefrom (for e.g., on-line clustering or classification), such variations can imprint changes in the statistical distribution of input and/or output data, making it necessary to update such models to reflect this change in their learned knowledge. This phenomenon is known as concept drift [97], and has been identified as an active research challenge for most of fields connected to machine learning in non-stationary environment [98]. Many of those fields are already studying this topic, from spam detection [99,100] to medicine [101].There are two main lines related to concept drift: how to detect drift, and how to adapt to it. Both lines should be scheduled in the research agenda of data-driven ITS, as they have obvious implications when analyzing traffic [102]. Situations like road works can modify completely traffic profiles over a certain area during a period of time, after which the situation goes back to normal. A similar casuistry happens with road design changes (i.e., new lanes, transformation of types of lanes, new accesses, roundabouts, etc), although in those cases there is a new stable traffic profile largely after the change. Even without man-crafted changes, traffic profiles may change for social-economical reasons [103]. Besides, analysis of drift can be used to detect anomalies in the normal operation of roads [104], or to analyze patterns in maritime traffic flow data [105]. However, the adaptability of ITS models to evolving data is scarcely found in literature, and certainly, in many cases concept drift management is the scope of the work, and not a circumstance that is considered to achieve a greater goal [104,106]. There are though some online approaches to typical ITS problems that consider the effects of drift in data [36,107,108], and we consider this kind of initiatives should lead the way for an actionable ITS research.
- Robust: When an ITS system is deployed in a real-life environment, diverse kinds of setbacks can affect its normal operation, from power failures that preclude its functioning to the interruption of the input data flow. Robustness is a self-sustainability trait that prevents a system to stop working when external disruptions occur. Although in most research-level designs this is not a relevant feature, it is essential for actionable, self-sustainable designs. Robustness, defined as the ability to recover from failures, would have, however, different requirements depending on the criticality of the ITS system. Thus, in a traffic flow forecasting system robustness could only imply that the system does not crack when input data fail [109], and it continues to operate; on the other hand, for critical systems such as air traffic management, robustness would require additional measurements to contain damage [110,111]. All in all, robust data-based workflows should be able to accommodate unseen operational circumstances, such as data distribution shifts or unprecedented levels of information uncertainty, which particularly prevail in crowdsourced and Social Media data [112,113].
- Stable and resilient: Actionable systems require a certain output stability in order to be understandable by their users. This notion is apparently opposed to adaptability, but while the latter is the ability to adapt the output to environment or data changes, stability pursues maintaining the output statistically bounded even when contextual changes occur, through e.g., model adaptation techniques. When adaptation is not perfect and the model violates a given level of statistical stability, stability requires another kind of adaptation, namely resilience, to make the model return to its normal operation and thus, minimize the impact of external changes on the quality of its output [114]. This entails, in essence, going one step further in the knowledge of the environment and taking into account those circumstances that can affect the system, and it could be linked to transferable models, which would be addressed below. For instance, a traffic volume characterization model would be adaptable if it considers the changes inherent to traffic volume (an increase over time due to economical factors), and it would be stable if a change in the weather conditions does not deteriorate its performance, or in other words, it has considered this essential circumstance. These kind of considerations are almost nonexistent in literature [78], but however crucial for a model to be self-sustainable.
- Scalable: In the research environment, tests are run in a delimited scale, constrained to the size of data, and useful for the experiments, in contrast with large, multi-variate real environments. Scaling up is not, of course, a matter of ITS research, but an engineering problem. However, models should be designed to be scalable since their conception.Leaving aside calibration and training phases, classic transportation theories tend in general to be computationally more affordable than data-driven models. However, the unprecedented amount of computing power available nowadays discards any real pragmatic limitation due to the computational complexity of learning algorithms in data-based modeling. An exception occurs with models falling within the Deep Learning category which, depending on their architecture and size of training data, may require specialized computing hardware such as GPU or multi-core equipment. Nevertheless, the rising trend in terms of scalability is to make data-based models incremental and adaptable [3], which finds its rationale not only in the environmental sustainability of data centers (lower energy consumption and thereby, carbon footprint), but also in the deployment of scalable model architectures on edge devices, usually with significantly less computing resources than data centers.Although some ITS problems are easier to scale and this feature would not be troublesome, there are some fields that can be very sensitive to scalability. For instance, route planners frequently consist of shortest-path problem and travel-salesman problem implementations that increase in complexity when the number of nodes grow [115]. This is a good example where artificial intelligence and optimization tools provide solutions that are actionable in terms of scalability, and where cases are found effortlessly [116,117]. Caring about aspects like the easiness to introduce new variables when needed, the complexity of tuning if applies, or the execution time, would make a model more actionable, by increasing its self-sustainability. This need for scalability is not just a matter related to the computational complexity of modeling elements along the pipeline, but also links to the feasibility of migrating the designed models from a lab setup to a, e.g., Big Data computing architecture. Unfortunately, scarce publications reflect nowadays on whether their proposed data-based workflows can be deployed and run on legacy ITS systems, thereby avoiding costly upgrade investments in computing equipment.
3.3. Traffic Theory Awareness
3.4. Application Context Awareness
3.5. Transferability
4. Emerging AI Areas towards Actionable ITS
- Real-time data processing and online learning, which are not brand new research avenues in ITS, as we can find advanced developments in the literature. However, as we will later show, emerging fields with great potential such as dynamic data fusion and dynamic optimization can expedite and proliferate the adoption of incremental data-based models in more ITS-related applications.
- Transfer learning and domain adaptation, that could allow to develop models for certain contexts and export them to others, linking directly to the transferability requirement, but also to the integration of transportation theories and physical models to data-based models.
- Gray-box modeling, a paradigm halfway between white-box (physical) and black-box (data-based) models. Gray-box modeling represents a promising area to bring awareness to traffic theory and other physical modeling when developing data-based models, with the potential to increase the performance, usability and comprehensibility of the latter.
- Green AI, a trend in Artificial Intelligence research that connects directly with energy and cost efficiency. Developing efficient models has a relevant impact in their sustainability and context awareness.
- Fairness, Accountability, Transparency and Ethics: Data-based models—specially those learning from large amounts of diverse data from many sources—are fragile to biases, and can compromise aspects such as the fairness of decisions or the differential privacy of data. In this context of growing sources of data, including those gathered from people, and increasingly opaque data-based models, it has become essential to understand what models have learned from data, and to analyze them beyond their predictive performance to consider ethical, societal and legal aspects. These aspects have been scarcely considered in ITS research.
- Other Artificial Intelligence areas such as imbalanced learning, reinforcement learning, adversarial machine learning are later highlighted for their noted relevance in ITS.
4.1. Online Learning and Dynamic Data Fusion/Optimization
4.2. Transfer Learning and Domain Adaptation
4.3. Gray-Box Modeling
4.4. Green Artificial Intelligence
4.5. Fairness, Accountability, Transparency and Ethics
- To gauge as many consequences of the actions as possible, identifying situations where decision making based on the outputs of the data-based workflow gives rise to socially unfair scenarios due to the propagation of inadvertently encoding bias to the automated decisions of the model.
- To ensure him/her that the output of the model is reliable and invariant under the same data stimuli, maintaining a record of the intermediate decisions made along the pipeline, allowing for the post-mortem, potentially correcting analysis of bad decision paths, and thereby maximizing the trust and certainty of the user when embracing its output.
- To make the user understand why the developed model produces its prescriptive output when fed with a set of data inputs, shedding light on which inputs correlate more significantly with the prescribed actions, tracing back causal relations between intermediate data inputs, and discriminating extreme cases where decisions can change radically under slight modifications of the model inputs.
- To supervise the ethics of data-based workflows, identifying potentially illegal uses of unlawful data given the prevailing legislation, guaranteeing the privacy and governance of personal data by third-party data-based ITS applications and processes, and certifying that the output of the model’s output does not favor inequalities in terms of gender, religion, race or any other aspect alike.
4.6. Other AI Research Areas Connected to Actionability
- Few-shot learning [208], which aims at overcoming the lack of reliably annotated data and the practical difficulty of performing annotation in certain application scenarios. For instance, accident prevention models cannot be enriched with positive samples unless a fatality occurs and the data captured in place is fed into the model. Few shots learning and related subareas (zero-shot, one-shot) deriving solutions that can automatically learn from very small amounts of training data, incorporating mechanisms (e.g., generative models, regularization techniques, guided simulation) to prevent the overall model from overfitting [209]. In regards to actionability, this family of learning techniques can be helpful to make data-based ITS models deployable in situations lacking data supervision, specially when such a data annotation cannot be guaranteed to be achievable over time.
- Imbalanced and cost-sensitive learning [210,211], which link to the need for avoiding model bias, not only to ensure the generalization of its output, but also to reduce the likeliness of the workflow to cause discriminatory issues as the ones exemplified above. The history of these AI areas in the ITS community has been going for years now [3]. However, we here emphasize the crucial role of these techniques beyond performance boosting: the techniques originally aimed to counteract the effects of class imbalance in the output of data-based models could be also leveraged to reflect legal impositions that not necessarily relate to the model’s performance nor can they be inferred easily for the attributes within the data themselves. The lack of compliance of the model with fairness and ethics standards does not necessarily render a performance degradation observed at its output, nor can it be inferred easily from the available data.
- Hybrid models encompassing linguistic rules and data-based learning techniques, capable of supporting the transition from the traditional way of doing to the new data-based modeling era in the management of ITS systems. We foresee that the community will witness a renaissance of data mining methods incorporating methods such as fuzzy logic not only to implement human knowledge to decision workflows, but also to explain and describe the internal structure of learned models, as it is currently under investigation in many contributions under the XAI umbrella [212,213].
- New prescriptive data-based techniques such as Deep Reinforcement Learning [214] and Algorithmic Game Theory [215] will also grasp interest in the near future for their close connection to actionable data science. The interaction of data-based workflows with humans will require techniques capable of learning actions from experience, and eventually orchestrating the interaction and negotiation among users when their actions are governed by interrelated yet conflicting objectives. In fact such new prescriptive elements are progressively entering the literature in certain ITS applications that target machine autonomy (e.g., autonomous vehicle [216,217] or automated signaling [51]), but it is our vision that they will gain momentum in many other ITS setups.
- Privacy-preserving Data Mining [218,219], which has garnered a great interest in the last year with major breakthroughs reported in the intersection between machine learning, cryptography, homomorphic encryption, secure enclaves and blockchains [220]. The use of personal data and the stringent pressure placed by governments and agencies on differential privacy preservation has spurred a flurry of research to prevent models from revealing sensitive data from their training instances [197,221]. Within the ITS domain, it is possible to find many areas in which privacy preservation has recently been a subject of intense research: from origin-destination flow estimation [222] to route planners [223,224], or pattern mining [225], a glance at recent literature reveals the momentum this topic has acquired lately. In any of these examples data are available as a result of the sensing pervasiveness (specially in the case of VANETs) and the capture of user data. While previous works explored how to used these data in a proper way with respect to privacy matters, it is straightforward to think that the natural evolution of this research line arrives at how protected data is preserved through the modeling workflow.
- Furthermore, the proven vulnerability of data-based models against adversarial attacks has also motivated the community to lay the foundations of an entirely new research area—Adversarial Machine Learning—, committed to the design of robust models against attacks crafted to confuse their outputs [226,227]. Interestingly, one of the most widely exemplified scenarios in this research area relates to ITS: automated traffic signal classification models were proven to be vulnerable to adversarial attacks by placing a simple, intelligently designed sticker on the traffic sign itself [228]. Likewise, the rationale behind Federated Learning (discussed in Section 4.2) also spans beyond the efficient distribution of locally captured knowledge among models: since no raw data instances are involved in the information transfer, privacy of local data is consequently preserved. In short: security also matters in actionable data-based pipelines.
- Finally, the ever-growing scales of ITS scenarios demand more research invested in scaling up learning algorithms in a computationally efficient manner [229]. Automated traffic, smart cities, mobility as a service constitute ITS scenarios where a plethora of information sources interact with each other. Definitely more efforts must be invested in aggregation strategies for data-based models learned from different interrelated data ecosystems, either in a distributed fashion (e.g., federated learning) or in a centralized system (correspondingly, Map-Reduce implementations of data-based models, cloud-based architectures, etc). Computational aspects of large-scale implementations should be also under study due to their implications in terms of actionability, such as the latency of the system when prescribing decisions from data. This latter aspect can be a key for real-time ITS applications for which the gap from data to actions must be shortened to its minimum.
5. Concluding Notes and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, L.; Yu, F.R.; Wang, Y.; Ning, B.; Tang, T. Big data analytics in intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2018, 20, 383–398. [Google Scholar] [CrossRef]
- Albino, V.; Berardi, U.; Dangelico, R.M. Smart cities: Definitions, dimensions, performance, and initiatives. J. Urban Technol. 2015, 22, 3–21. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, F.Y.; Wang, K.; Lin, W.H.; Xu, X.; Chen, C. Data-driven intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1624–1639. [Google Scholar] [CrossRef]
- Karlaftis, M.G.; Vlahogianni, E.I. Statistical methods versus neural networks in transportation research: Differences, similarities and some insights. Transp. Res. Part C Emerg. Technol. 2011, 19, 387–399. [Google Scholar] [CrossRef]
- Del Ser, J.; Osaba, E.; Sanchez-Medina, J.J.; Fister, I. Bioinspired Computational Intelligence and Transportation Systems: A Long Road Ahead. IEEE Trans. Intell. Transp. Syst. 2019, 21, 466–495. [Google Scholar] [CrossRef]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2003; Volume 53. [Google Scholar]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in nonstationary environments: A survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Said, H.; Nicoletti, T.; Perez-Hernandez, P. Utilizing telematics data to support effective equipment fleet-management decisions: Utilization rate and hazard functions. J. Comput. Civ. Eng. 2016, 30, 04014122. [Google Scholar] [CrossRef]
- Urbahs, A.; Žavtkēvičs, V. Remotely Piloted Aircraft route optimization when performing oil pollution monitoring of the sea aquatorium. Aviation 2017, 21, 70–74. [Google Scholar] [CrossRef] [Green Version]
- Khaksar, H.; Sheikholeslami, A. Airline delay prediction by machine learning algorithms. Sci. Iran. 2019, 26, 2689–2702. [Google Scholar] [CrossRef] [Green Version]
- Mott, J.H.; Bullock, D.M.; McNamara, M.L. Estimating Aircraft Operations at Airports Using Transponder Data. US Patent Application No. 15/248,581, 18 May 2017. [Google Scholar]
- Herring, R.; Hofleitner, A.; Abbeel, P.; Bayen, A. Estimating arterial traffic conditions using sparse probe data. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Madeira, Portugal, 19–22 September 2010; pp. 929–936. [Google Scholar]
- Kujala, R.; Aledavood, T.; Saramäki, J. Estimation and monitoring of city-to-city travel times using call detail records. EPJ Data Sci. 2016, 5, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Hao, P.; Ban, X.J.; Yang, D. Trajectory-based vehicle energy/emissions estimation for signalized arterials using mobile sensing data. Transp. Res. Part D Transp. Environ. 2015, 34, 27–40. [Google Scholar] [CrossRef]
- Rodrigues, J.G.; Aguiar, A.; Vieira, F.; Barros, J.; Cunha, J.P.S. A mobile sensing architecture for massive urban scanning. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1132–1137. [Google Scholar]
- Laña, I.; Del Ser, J.; Velez, M.; Vlahogianni, E.I. Road Traffic Forecasting: Recent Advances and New Challenges. IEEE Intell. Transp. Syst. Mag. 2018, 10, 93–109. [Google Scholar] [CrossRef]
- García, S.; Luengo, J.; Herrera, F. Data Preprocessing in Data Mining; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Lopes, J.; Bento, J.; Huang, E.; Antoniou, C.; Ben-Akiva, M. Traffic and mobility data collection for real-time applications. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Madeira, Portugal, 19–22 September 2010; pp. 216–223. [Google Scholar]
- Vlahogianni, E.I.; Golias, J.C.; Karlaftis, M.G. Short-term traffic forecasting: Overview of objectives and methods. Transp. Rev. 2004, 24, 533–557. [Google Scholar] [CrossRef]
- Chen, H.; Grant-Muller, S.; Mussone, L.; Montgomery, F. A study of hybrid neural network approaches and the effects of missing data on traffic forecasting. Neural Comput. Appl. 2001, 10, 277–286. [Google Scholar] [CrossRef]
- Qu, L.; Li, L.; Zhang, Y.; Hu, J. PPCA-based missing data imputation for traffic flow volume: A systematical approach. IEEE Trans. Intell. Transp. Syst. 2009, 10, 512–522. [Google Scholar]
- Tan, H.; Feng, G.; Feng, J.; Wang, W.; Zhang, Y.J.; Li, F. A tensor-based method for missing traffic data completion. Transp. Res. Part C Emerg. Technol. 2013, 28, 15–27. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Li, Z.; Li, L. Missing traffic data: Comparison of imputation methods. IET Intell. Transp. Syst. 2014, 8, 51–57. [Google Scholar] [CrossRef]
- Ran, B.; Tan, H.; Wu, Y.; Jin, P.J. Tensor based missing traffic data completion with spatial–temporal correlation. Phys. A Stat. Mech. Appl. 2016, 446, 54–63. [Google Scholar] [CrossRef]
- Laña, I.; Olabarrieta, I.I.; Vélez, M.; Del Ser, J. On the imputation of missing data for road traffic forecasting: New insights and novel techniques. Transp. Res. Part C Emerg. Technol. 2018, 90, 18–33. [Google Scholar] [CrossRef]
- Krempl, G.; Žliobaite, I.; Brzeziński, D.; Hüllermeier, E.; Last, M.; Lemaire, V.; Noack, T.; Shaker, A.; Sievi, S.; Spiliopoulou, M.; et al. Open challenges for data stream mining research. ACM SIGKDD Explor. Newsl. 2014, 16, 1–10. [Google Scholar] [CrossRef]
- Etemad, M.; Soares Júnior, A.; Matwin, S. Predicting transportation modes of GPS trajectories using feature engineering and noise removal. In Proceedings of the Advances in Artificial Intelligence: 31st Canadian Conference on Artificial Intelligence, Canadian AI 2018, Toronto, ON, Canada, 8–11 May 2018; pp. 259–264. [Google Scholar]
- Zheng, C.; Chen, S.; Wang, W.; Lu, J. Using principal component analysis to solve a class imbalance problem in traffic incident detection. Math. Probl. Eng. 2013, 2013, 524861. [Google Scholar] [CrossRef]
- Smith, B.L.; Babiceanu, S. Investigation of extraction, transformation, and loading techniques for traffic data warehouses. Transp. Res. Rec. 2004, 1879, 9–16. [Google Scholar] [CrossRef]
- El Faouzi, N.E.; Leung, H.; Kurian, A. Data fusion in intelligent transportation systems: Progress and challenges—A survey. Inf. Fusion 2011, 12, 4–10. [Google Scholar] [CrossRef]
- Choi, K.; Chung, Y. A data fusion algorithm for estimating link travel time. ITS J. 2002, 7, 235–260. [Google Scholar] [CrossRef]
- Chang, B.R.; Tsai, H.F.; Young, C.P. Intelligent data fusion system for predicting vehicle collision warning using vision/GPS sensing. Expert Syst. Appl. 2010, 37, 2439–2450. [Google Scholar] [CrossRef]
- Han, L.; Wu, K. Radar and radio data fusion platform for future intelligent transportation system. In Proceedings of the 7th European Radar Conference, Paris, France, 30 September–1 October 2010; pp. 65–68. [Google Scholar]
- Treiber, M.; Kesting, A.; Wilson, R.E. Reconstructing the traffic state by fusion of heterogeneous data. Comput. Aided Civ. Infrastruct. Eng. 2011, 26, 408–419. [Google Scholar] [CrossRef] [Green Version]
- Vlahogianni, E.I. Enhancing predictions in signalized arterials with information on short-term traffic flow dynamics. J. Intell. Transp. Syst. 2009, 13, 73–84. [Google Scholar] [CrossRef]
- Laña, I.; Lobo, J.L.; Capecci, E.; Del Ser, J.; Kasabov, N. Adaptive long-term traffic state estimation with evolving spiking neural networks. Transp. Res. Part C Emerg. Technol. 2019, 101, 126–144. [Google Scholar] [CrossRef]
- Liu, T.; Hu, J.; Pei, X. Mining the Temporal-Spatial Patterns of Urban Traffic Demands Based on Taxi Mobility Data. In Proceedings of the 19th COTA International Conference of Transportation Professionals, Nanjing, China, 6–8 July 2019; pp. 2716–2728. [Google Scholar]
- Moretti, F.; Pizzuti, S.; Panzieri, S.; Annunziato, M. Urban traffic flow forecasting through statistical and neural network bagging ensemble hybrid modeling. Neurocomputing 2015, 167, 3–7. [Google Scholar] [CrossRef]
- Cong, Y.; Wang, J.; Li, X. Traffic flow forecasting by a least squares support vector machine with a fruit fly optimization algorithm. Procedia Eng. 2016, 137, 59–68. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.J.; Hong, J.S. Urban traffic flow prediction system using a multifactor pattern recognition model. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2744–2755. [Google Scholar]
- Fusco, G.; Colombaroni, C.; Comelli, L.; Isaenko, N. Short-term traffic predictions on large urban traffic networks: Applications of network-based machine learning models and dynamic traffic assignment models. In Proceedings of the 2015 International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Budapest, Hungary, 3–5 June 2015; pp. 93–101. [Google Scholar]
- Montanino, M.; Punzo, V. Trajectory data reconstruction and simulation-based validation against macroscopic traffic patterns. Transp. Res. Part B Methodol. 2015, 80, 82–106. [Google Scholar] [CrossRef]
- Chaulwar, A.; Botsch, M.; Utschick, W. A hybrid machine learning approach for planning safe trajectories in complex traffic-scenarios. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 540–546. [Google Scholar]
- Vlahogianni, E.I. Optimization of traffic forecasting: Intelligent surrogate modeling. Transp. Res. Part C Emerg. Technol. 2015, 55, 14–23. [Google Scholar] [CrossRef]
- Teodorović, D. Swarm intelligence systems for transportation engineering: Principles and applications. Transp. Res. Part C Emerg. Technol. 2008, 16, 651–667. [Google Scholar] [CrossRef]
- Kumar, S.N.; Panneerselvam, R. A survey on the vehicle routing problem and its variants. Intell. Inf. Manag. 2012, 4, 66. [Google Scholar] [CrossRef] [Green Version]
- Osaba, E.; Yang, X.S.; Diaz, F.; Lopez-Garcia, P.; Carballedo, R. An improved discrete bat algorithm for symmetric and asymmetric traveling salesman problems. Eng. Appl. Artif. Intell. 2016, 48, 59–71. [Google Scholar] [CrossRef]
- Mendes-Moreira, J.; Moreira-Matias, L.; Gama, J.; de Sousa, J.F. Validating the coverage of bus schedules: A machine learning approach. Inf. Sci. 2015, 293, 299–313. [Google Scholar] [CrossRef]
- Szeto, W.; Jiang, Y.; Wang, D.; Sumalee, A. A sustainable road network design problem with land use transportation interaction over time. Netw. Spat. Econ. 2015, 15, 791–822. [Google Scholar] [CrossRef]
- Van Winden, K.; Biljecki, F.; Van der Spek, S. Automatic update of road attributes by mining GPS tracks. Trans. GIS 2016, 20, 664–683. [Google Scholar] [CrossRef]
- Mannion, P.; Duggan, J.; Howley, E. An experimental review of reinforcement learning algorithms for adaptive traffic signal control. In Autonomic Road Transport Support Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 47–66. [Google Scholar]
- Osaba, E.; Yang, X.S.; Diaz, F.; Onieva, E.; Masegosa, A.D.; Perallos, A. A discrete firefly algorithm to solve a rich vehicle routing problem modelling a newspaper distribution system with recycling policy. Soft Comput. 2017, 21, 5295–5308. [Google Scholar] [CrossRef] [Green Version]
- Imprialou, M.I.M.; Orfanou, F.P.; Vlahogianni, E.I.; Karlaftis, M.G. Methods for defining spatiotemporal influence areas and secondary incident detection in freeways. J. Transp. Eng. 2013, 140, 70–80. [Google Scholar] [CrossRef]
- Yu, C.; Wang, X.; Xu, X.; Zhang, M.; Ge, H.; Ren, J.; Sun, L.; Chen, B.; Tan, G. Distributed Multiagent Coordinated Learning for Autonomous Driving in Highways Based on Dynamic Coordination Graphs. IEEE Trans. Intell. Transp. Syst. 2019, 21, 735–748. [Google Scholar] [CrossRef]
- Lécué, F.; Tallevi-Diotallevi, S.; Hayes, J.; Tucker, R.; Bicer, V.; Sbodio, M.L.; Tommasi, P. Star-city: Semantic traffic analytics and reasoning for city. In Proceedings of the 19th International Conference on Intelligent User Interfaces, Haifa, Israel, 24–27 February 2014; pp. 179–188. [Google Scholar]
- Gindele, T.; Brechtel, S.; Dillmann, R. Learning driver behavior models from traffic observations for decision making and planning. IEEE Intell. Transp. Syst. Mag. 2015, 7, 69–79. [Google Scholar] [CrossRef]
- Kammoun, H.M.; Kallel, I.; Casillas, J.; Abraham, A.; Alimi, A.M. Adapt-Traf: An adaptive multiagent road traffic management system based on hybrid ant-hierarchical fuzzy model. Transp. Res. Part C Emerg. Technol. 2014, 42, 147–167. [Google Scholar] [CrossRef]
- Mesbah, A. Stochastic model predictive control: An overview and perspectives for future research. IEEE Control. Syst. Mag. 2016, 36, 30–44. [Google Scholar]
- Hrovat, D.; Di Cairano, S.; Tseng, H.E.; Kolmanovsky, I.V. The development of model predictive control in automotive industry: A survey. In Proceedings of the 2012 IEEE International Conference on Control Applications, Dubrovnik, Croatia, 3–5 October 2012; pp. 295–302. [Google Scholar]
- Buchanan, C. Traffic in Towns: A Study of the Long Term Problems of Traffic in Urban Areas; Routledge: Abingdon, UK, 2015. [Google Scholar]
- Pan, B.; Zheng, Y.; Wilkie, D.; Shahabi, C. Crowd sensing of traffic anomalies based on human mobility and social media. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 344–353. [Google Scholar]
- Davison, L.J.; Knowles, R.D. Bus quality partnerships, modal shift and traffic decongestion. J. Transp. Geogr. 2006, 14, 177–194. [Google Scholar] [CrossRef]
- Nielsen, J. Usability Engineering; Elsevier: Amsterdam, The Netherlands, 1994. [Google Scholar]
- Nielsen, J. Usability inspection methods. In Proceedings of the Conference Companion on Human Factors in Computing Systems, Boston, MA, USA, 24–28 April 1994; pp. 413–414. [Google Scholar]
- Brooke, J. SUS-A quick and dirty usability scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
- Nielsen, J. 10 Usability Heuristics for User Interface Design. 1995. Available online: https://www.nngroup.com/articles/ten-usability-heuristics/ (accessed on 1 December 2018).
- Nielsen, J. Usability 101: Introduction to Usability. 2003. Available online: http://www.nngroup.com/articles/usability-101-introduction-to-usability/ (accessed on 1 December 2018).
- Noy, Y.I. Human factors in modern traffic systems. Ergonomics 1997, 40, 1016–1024. [Google Scholar] [CrossRef]
- Green, P. Estimating compliance with the 15-second rule for driver-interface usability and safety. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Houston, TX, USA, 27 September–1 October 1999; Volume 43, pp. 987–991. [Google Scholar]
- Green, P. Navigation System Data Entry: Estimation of Task Times. 1999. Available online: https://deepblue.lib.umich.edu/bitstream/handle/2027.42/1288/94020.0001.001.pdf?sequence=2 (accessed on 2 September 2018).
- Burns, P.; Harbluk, J.; Foley, J.P.; Angell, L. The importance of task duration and related measures in assessing the distraction potential of in-vehicle tasks. In Proceedings of the 2nd International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Pittsburgh, PA, USA, 11–12 November 2010; pp. 12–19. [Google Scholar]
- Burnett, G. ‘Turn right at the traffic lights’: The requirement for landmarks in vehicle navigation systems. J. Navig. 2000, 53, 499–510. [Google Scholar] [CrossRef]
- Dos Santos, C.; Botura, G. Proposal of Ergonomic Intervention in Horizontal Traffic Signaling. In Proceedings of the International Conference on Applied Human Factors and Ergonomics, Los Angeles, CA, USA, 17–21 July 2017; pp. 1121–1130. [Google Scholar]
- Avelar, S.; Hurni, L. On the design of schematic transport maps. Cartogr. Int. J. Geogr. Inf. Geovis. 2006, 41, 217–228. [Google Scholar] [CrossRef]
- Roberts, M.J.; Newton, E.J.; Canals, M. Radi (c) al departures: Comparing conventional octolinear versus concentric circles schematic maps for the Berlin U-Bahn/S-Bahn networks using objective and subjective measures of effectiveness. Inf. Des. J. 2016, 22, 92–115. [Google Scholar]
- Lyons, G. From Advanced Towards Effective Traveller Information Systems. In Travel Behaviour Research The Leading Edge; Hensher, D., Ed.; International Association for Travel Behaviour Research: Pergamon, Turkey, 2001; Volume 47, pp. 813–826. [Google Scholar]
- Barfield, W.; Dingus, T.A. Human Factors in Intelligent Transportation Systems; Psychology Press: Hove, UK, 2014. [Google Scholar]
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Short-term traffic forecasting: Where we are and where we’re going. Transp. Res. Part C Emerg. Technol. 2014, 43, 3–19. [Google Scholar] [CrossRef]
- Horan, T.A.; Abhichandani, T.; Rayalu, R. Assessing user satisfaction of e-government services: Development and testing of quality-in-use satisfaction with advanced traveler information systems (ATIS). In Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), Kauai, Hawaii, 4–7 January 2006; Volume 4, p. 83b. [Google Scholar]
- Ross, T.; Burnett, G. Evaluating the human–machine interface to vehicle navigation systems as an example of ubiquitous computing. Int. J. Hum. Comput. Stud. 2001, 55, 661–674. [Google Scholar] [CrossRef]
- Fischer, G.; Sullivan, J., Jr. Human-centered public transportation systems for persons with cognitive disabilities. In Proceedings of the Participatory Design Conference, Malmo, Sweden, 23–25 June 2002; pp. 194–198. [Google Scholar]
- Dingus, T.A.; Hulse, M.C.; Jahns, S.K.; Alves-Foss, J.; Confer, S.; Rice, A.; Roberts, I.; Hanowski, R.J.; Sorenson, D. Development of Human Factors Guidelines for Advanced Traveler Information Systems and Commercial Vehicle Operations: Literature Review. 1996. Available online: https://www.fhwa.dot.gov/publications/research/safety/95153/index.cfm (accessed on 3 August 2018).
- Beul-Leusmann, S.; Samsel, C.; Wiederhold, M.; Krempels, K.H.; Jakobs, E.M.; Ziefle, M. Usability evaluation of mobile passenger information systems. In Proceedings of the International Conference of Design, User Experience, and Usability, Heraklion, Greece, 22–27 June 2014; pp. 217–228. [Google Scholar]
- Mazloumi, E.; Rose, G.; Currie, G.; Moridpour, S. Prediction intervals to account for uncertainties in neural network predictions: Methodology and application in bus travel time prediction. Eng. Appl. Artif. Intell. 2011, 24, 534–542. [Google Scholar] [CrossRef]
- Van Hinsbergen, C.I.; Van Lint, J.; Van Zuylen, H. Bayesian committee of neural networks to predict travel times with confidence intervals. Transp. Res. Part C Emerg. Technol. 2009, 17, 498–509. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Li, X.; Huang, W.; Wei, Y.; Cao, J.; Guo, J. Dynamic traffic demand uncertainty prediction using radio-frequency identification data and link volume data. IET Intell. Transp. Syst. 2019, 13, 1309–1317. [Google Scholar] [CrossRef]
- Tsekeris, T.; Stathopoulos, A. Short-term prediction of urban traffic variability: Stochastic volatility modeling approach. J. Transp. Eng. 2009, 136, 606–613. [Google Scholar] [CrossRef]
- Khosravi, A.; Mazloumi, E.; Nahavandi, S.; Creighton, D.; Van Lint, J. Prediction intervals to account for uncertainties in travel time prediction. IEEE Trans. Intell. Transp. Syst. 2011, 12, 537–547. [Google Scholar] [CrossRef]
- Gunning, D. Explainable artificial intelligence (xai). In Defense Advanced Research Projects Agency (DARPA), nd Web; 2017; Available online: https://www.cc.gatech.edu/~alanwags/DLAI2016/(Gunning)%20IJCAI-16%20DLAI%20WS.pdf (accessed on 4 April 2018).
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv 2017, arXiv:1708.08296. [Google Scholar]
- Ras, G.; van Gerven, M.; Haselager, P. Explanation methods in deep learning: Users, values, concerns and challenges. In Explainable and Interpretable Models in Computer Vision and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–36. [Google Scholar]
- Vlahogianni, E.I.; Karlaftis, M.G.; Orfanou, F.P. Modeling the effects of weather and traffic on the risk of secondary incidents. J. Intell. Transp. Syst. 2012, 16, 109–117. [Google Scholar] [CrossRef]
- Thiagarajan, A.; Ravindranath, L.; LaCurts, K.; Madden, S.; Balakrishnan, H.; Toledo, S.; Eriksson, J. VTrack: Accurate, energy-aware road traffic delay estimation using mobile phones. In Proceedings of the 7th ACM Conference on Embedded Networked Sensor Systems, Berkeley, CA, USA, 4–6 November 2009; pp. 85–98. [Google Scholar]
- Thiagarajan, A. Probabilistic Models for Mobile Phone Trajectory Estimation. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2011. [Google Scholar]
- Geisler, S.; Quix, C.; Schiffer, S.; Jarke, M. An evaluation framework for traffic information systems based on data streams. Transp. Res. Part C Emerg. Technol. 2012, 23, 29–55. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 44. [Google Scholar] [CrossRef]
- Žliobaitė, I.; Pechenizkiy, M.; Gama, J. An overview of concept drift applications. In Big Data Analysis: New Algorithms for a New Society; Springer: Berlin/Heidelberg, Germany, 2016; pp. 91–114. [Google Scholar]
- Delany, S.J.; Cunningham, P.; Tsymbal, A.; Coyle, L. A case-based technique for tracking concept drift in spam filtering. In Applications and Innovations in Intelligent Systems XII; Springer: Berlin/Heidelberg, Germany, 2005; pp. 3–16. [Google Scholar]
- Méndez, J.R.; Fdez-Riverola, F.; Iglesias, E.L.; Díaz, F.; Corchado, J.M. Tracking concept drift at feature selection stage in spamhunting: An anti-spam instance-based reasoning system. In Proceedings of the European Conference on Case-Based Reasoning, Fethiye, Turkey, 4–7 September 2006; pp. 504–518. [Google Scholar]
- Stiglic, G.; Kokol, P. Interpretability of sudden concept drift in medical informatics domain. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops (ICDMW), Vancouver, BC, Canada, 11–14 December 2011; pp. 609–613. [Google Scholar]
- Moreira-Matias, L.; Mendes-Moreira, J.; Gama, J.; Ferreira, M. On Improving Operational Planning and Control in Public Transportation Networks Using Streaming Data: A Machine Learning Approach. Ph.D. Thesis, Porto University, Porto, Porgutal, 2014. [Google Scholar]
- Laña, I.; Del Ser, J.; Padró, A.; Vélez, M.; Casanova-Mateo, C. The role of local urban traffic and meteorological conditions in air pollution: A data-based case study in Madrid, Spain. Atmos. Environ. 2016, 145, 424–438. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Alesiani, F. Drift3flow: Freeway-incident prediction using real-time learning. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems (ITSC), Gran Canaria, Spain, 15–18 September 2015; pp. 566–571. [Google Scholar]
- Osekowska, E.; Johnson, H.; Carlsson, B. Maritime vessel traffic modeling in the context of concept drift. Transp. Res. Procedia 2017, 25, 1457–1476. [Google Scholar] [CrossRef]
- Wibisono, A.; Jatmiko, W.; Wisesa, H.A.; Hardjono, B.; Mursanto, P. Traffic big data prediction and visualization using fast incremental model trees-drift detection (FIMT-DD). Knowl. Based Syst. 2016, 93, 33–46. [Google Scholar] [CrossRef]
- Wu, T.; Xie, K.; Xinpin, D.; Song, G. A online boosting approach for traffic flow forecasting under abnormal conditions. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Chongqing, China, 29–31 May 2012; pp. 2555–2559. [Google Scholar]
- Procopio, M.J.; Mulligan, J.; Grudic, G. Learning terrain segmentation with classifier ensembles for autonomous robot navigation in unstructured environments. J. Field Robot. 2009, 26, 145–175. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, Z. Short-term traffic flow forecasting using fuzzy logic system methods. J. Intell. Transp. Syst. 2008, 12, 102–112. [Google Scholar] [CrossRef]
- Isaacson, D.; Robinson, J.; Swenson, H.; Denery, D. A concept for robust, high density terminal air traffic operations. In Proceedings of the 10th AIAA Aviation Technology, Integration, and Operations (ATIO) Conference, Fort Worth, TX, USA, 13–15 September 2010; p. 9292. [Google Scholar]
- Chen, J.; Chen, L.; Sun, D. Air traffic flow management under uncertainty using chance-constrained optimization. Transp. Res. Part B Methodol. 2017, 102, 124–141. [Google Scholar] [CrossRef]
- Wechsler, S.P.; Ban, H.; Li, L. The Pervasive Challenge of Error and Uncertainty in Geospatial Data. In Geospatial Challenges in the 21st Century; Springer: Berlin/Heidelberg, Germany, 2019; pp. 315–332. [Google Scholar]
- Adar, E.; Re, C. Managing uncertainty in social networks. IEEE Data Eng. Bull. 2007, 30, 15–22. [Google Scholar]
- De Lara, M. A mathematical framework for resilience: Dynamics, strategies, shocks and acceptable paths. arXiv 2017, arXiv:1709.01389. [Google Scholar]
- Colpaert, P.; Ballieu, S.; Verborgh, R.; Mannens, E. The Impact of an Extra Feature on the Scalability of Linked Connections. In Proceedings of the 7th International Workshop on Consuming Linked Data co-located with 15th International Semantic Web Conference, COLD@ISWC 2016, Kobe, Japan, 18 October 2016; p. 10. [Google Scholar]
- Basu, A.; Vanajakshi, L. Genetic Algorithm Based Dynamic Route Planner for Public Transport 2. Transport 2016, 2, 3. [Google Scholar]
- Schmitt, F.; Schulte, A. Experimental evaluation of a scalable mixed-initiative planning associate for future military helicopter missions. In Proceedings of the International Conference on Engineering Psychology and Cognitive Ergonomics, Las Vegas, NV, USA, 15–20 July 2018; pp. 649–663. [Google Scholar]
- Zhang, W.; Zhu, B.; Zhang, L.; Yuan, J.; You, I. Exploring urban dynamics based on pervasive sensing: Correlation analysis of traffic density and air quality. In Proceedings of the 2012 Sixth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Palermo, Italy, 4–6 July 2012; pp. 9–16. [Google Scholar]
- Zhang, Z.; Ni, M.; He, Q.; Gao, J.; Gou, J.; Li, X. Exploratory study on correlation between Twitter concentration and traffic surges. Transp. Res. Rec. 2016, 2553, 90–98. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, G.; Costeira, J.P.; Moura, J.M. Understanding traffic density from large-scale web camera data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5898–5907. [Google Scholar]
- Kerner, B.S. Three-phase traffic theory and highway capacity. Phys. A Stat. Mech. Its Appl. 2004, 333, 379–440. [Google Scholar] [CrossRef] [Green Version]
- Kerner, B.S. The physics of traffic. Phys. World 1999, 12, 25. [Google Scholar] [CrossRef]
- Karpatne, A.; Atluri, G.; Faghmous, J.H.; Steinbach, M.; Banerjee, A.; Ganguly, A.; Shekhar, S.; Samatova, N.; Kumar, V. Theory-guided data science: A new paradigm for scientific discovery from data. IEEE Trans. Knowl. Data Eng. 2017, 29, 2318–2331. [Google Scholar] [CrossRef]
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Spatio-temporal short-term urban traffic volume forecasting using genetically optimized modular networks. Comput. Aided Civ. Infrastruct. Eng. 2007, 22, 317–325. [Google Scholar] [CrossRef]
- Ramezani, M.; Geroliminis, N. On the estimation of arterial route travel time distribution with Markov chains. Transp. Res. Part B Methodol. 2012, 46, 1576–1590. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Cheng, H.H. A review of the applications of agent technology in traffic and transportation systems. IEEE Trans. Intell. Transp. Syst. 2010, 11, 485–497. [Google Scholar] [CrossRef]
- Shahrbabaki, M.R.; Safavi, A.A.; Papageorgiou, M.; Papamichail, I. A data fusion approach for real-time traffic state estimation in urban signalized links. Transp. Res. Part C Emerg. Technol. 2018, 92, 525–548. [Google Scholar] [CrossRef]
- Mintsis, E.; Vlahogianni, E.I.; Mitsakis, E.; Ozkul, S. Evaluation of a cooperative speed advice service implemented along an urban arterial corridor. In Proceedings of the 2017 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Naples, Italy, 26–28 June 2017; pp. 232–237. [Google Scholar]
- Gupta, A.; Ong, Y.S. Memetic Computation: The Mainspring of Knowledge Transfer in a Data-Driven Optimization Era; Springer: Berlin/Heidelberg, Germany, 2018; Volume 21. [Google Scholar]
- Neri, F.; Cotta, C. Memetic algorithms and memetic computing optimization: A literature review. Swarm Evol. Comput. 2012, 2, 1–14. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779. [Google Scholar] [CrossRef]
- Chatterjee, S.; Mitra, B.; Chakraborty, S. Type2Motion: Detecting Mobility Context from Smartphone Typing. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 753–755. [Google Scholar]
- Tselentis, D.I.; Yannis, G.; Vlahogianni, E.I. Innovative motor insurance schemes: A review of current practices and emerging challenges. Accid. Anal. Prev. 2017, 98, 139–148. [Google Scholar] [CrossRef]
- Andreasson, H.; Bouguerra, A.; Cirillo, M.; Dimitrov, D.N.; Driankov, D.; Karlsson, L.; Lilienthal, A.J.; Pecora, F.; Saarinen, J.P.; Sherikov, A.; et al. Autonomous transport vehicles: Where we are and what is missing. IEEE Robot. Autom. Mag. 2015, 22, 64–75. [Google Scholar] [CrossRef]
- Kulik, A.; Dergachev, K. Intelligent transport systems in aerospace engineering. In Intelligent Transportation Systems–Problems and Perspectives; Springer: Berlin/Heidelberg, Germany, 2016; pp. 243–303. [Google Scholar]
- Barmpounakis, E.N.; Vlahogianni, E.I.; Golias, J.C. Unmanned Aerial Aircraft Systems for transportation engineering: Current practice and future challenges. Int. J. Transp. Sci. Technol. 2016, 5, 111–122. [Google Scholar] [CrossRef]
- Lin, M.; Hsu, W.J. Mining GPS data for mobility patterns: A survey. Pervasive Mob. Comput. 2014, 12, 1–16. [Google Scholar] [CrossRef]
- Khodaei, M.; Papadimitratos, P. The key to intelligent transportation: Identity and credential management in vehicular communication systems. IEEE Veh. Technol. Mag. 2015, 10, 63–69. [Google Scholar] [CrossRef] [Green Version]
- Menouar, H.; Guvenc, I.; Akkaya, K.; Uluagac, A.S.; Kadri, A.; Tuncer, A. UAV-enabled intelligent transportation systems for the smart city: Applications and challenges. IEEE Commun. Mag. 2017, 55, 22–28. [Google Scholar] [CrossRef]
- Sucasas, V.; Mantas, G.; Saghezchi, F.B.; Radwan, A.; Rodriguez, J. An autonomous privacy-preserving authentication scheme for intelligent transportation systems. Comput. Secur. 2016, 60, 193–205. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, F.Y. Towards blockchain-based intelligent transportation systems. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2663–2668. [Google Scholar]
- Lei, A.; Cruickshank, H.; Cao, Y.; Asuquo, P.; Ogah, C.P.A.; Sun, Z. Blockchain-based dynamic key management for heterogeneous intelligent transportation systems. IEEE Internet Things J. 2017, 4, 1832–1843. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Chen, W.; Wang, P.; Shen, D.; Chen, S.; Wang, X.; Zhang, Q.; Yang, L. Big data for social transportation. IEEE Trans. Intell. Transp. Syst. 2015, 17, 620–630. [Google Scholar] [CrossRef]
- He, J.; Shen, W.; Divakaruni, P.; Wynter, L.; Lawrence, R. Improving traffic prediction with tweet semantics. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Ni, M.; He, Q.; Gao, J. Forecasting the subway passenger flow under event occurrences with social media. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1623–1632. [Google Scholar] [CrossRef]
- Evans-Cowley, J.S.; Griffin, G. Microparticipation with social media for community engagement in transportation planning. Transp. Res. Rec. 2012, 2307, 90–98. [Google Scholar] [CrossRef]
- Kuflik, T.; Minkov, E.; Nocera, S.; Grant-Muller, S.; Gal-Tzur, A.; Shoor, I. Automating a framework to extract and analyse transport related social media content: The potential and the challenges. Transp. Res. Part C Emerg. Technol. 2017, 77, 275–291. [Google Scholar] [CrossRef] [Green Version]
- Woodcock, J.; Edwards, P.; Tonne, C.; Armstrong, B.G.; Ashiru, O.; Banister, D.; Beevers, S.; Chalabi, Z.; Chowdhury, Z.; Cohen, A.; et al. Public health benefits of strategies to reduce greenhouse-gas emissions: Urban land transport. Lancet 2009, 374, 1930–1943. [Google Scholar] [CrossRef]
- Chen, Z.; Xia, J.C.; Irawan, B. Development of fuzzy logic forecast models for location-based parking finding services. Math. Probl. Eng. 2013, 2013, 473471. [Google Scholar] [CrossRef] [Green Version]
- Kramers, A. Designing next generation multimodal traveler information systems to support sustainability-oriented decisions. Environ. Model. Softw. 2014, 56, 83–93. [Google Scholar] [CrossRef]
- Zhang, S.; Lee, C.K.; Chan, H.K.; Choy, K.L.; Wu, Z. Swarm intelligence applied in green logistics: A literature review. Eng. Appl. Artif. Intell. 2015, 37, 154–169. [Google Scholar] [CrossRef]
- Feigon, S.; Murphy, C. Shared Mobility and the Transformation of Public Transit; TRID: Washington, DC, USA, 2016. [Google Scholar]
- Vlahogianni, E.I.; Barmpounakis, E.N. Driving analytics using smartphones: Algorithms, comparisons and challenges. Transp. Res. Part C Emerg. Technol. 2017, 79, 196–206. [Google Scholar] [CrossRef]
- Huang, Y.; Ng, E.C.; Zhou, J.L.; Surawski, N.C.; Chan, E.F.; Hong, G. Eco-driving technology for sustainable road transport: A review. Renew. Sustain. Energy Rev. 2018, 93, 596–609. [Google Scholar] [CrossRef]
- Adamidis, F.K.; Mantouka, E.G.; Barmpounakis, E.N.; Vlahogianni, E.I. Impacts of Eco Driving on Traffic Flow and Emissions in Large Scale Urban Networks; Technical Report; TRID: Washington, DC, USA, 2019. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Bajwa, S.I.; Chung, E.; Kuwahara, M. Performance evaluation of an adaptive travel time prediction model. In Proceedings of the Intelligent Transportation Systems, Vienna, Austria, 13–16 September 2005; pp. 1000–1005. [Google Scholar]
- Getachew, A.; Obrien, E.J. Simplified site-specific traffic load models for bridge assessment. Struct. Infrastruct. Eng. 2007, 3, 303–311. [Google Scholar] [CrossRef]
- Habibzadeh, H.; Boggio-Dandry, A.; Qin, Z.; Soyata, T.; Kantarci, B.; Mouftah, H.T. Soft sensing in smart cities: Handling 3vs using recommender systems, machine intelligence, and data analytics. IEEE Commun. Mag. 2018, 56, 78–86. [Google Scholar] [CrossRef]
- Shew, C.; Pande, A.; Nuworsoo, C. Transferability and robustness of real-time freeway crash risk assessment. J. Saf. Res. 2013, 46, 83–90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, C.; Wang, W.; Liu, P.; Guo, R.; Li, Z. Using the Bayesian updating approach to improve the spatial and temporal transferability of real-time crash risk prediction models. Transp. Res. Part C Emerg. Technol. 2014, 38, 167–176. [Google Scholar] [CrossRef]
- Ibisch, A.; Stümper, S.; Altinger, H.; Neuhausen, M.; Tschentscher, M.; Schlipsing, M.; Salinen, J.; Knoll, A. Towards autonomous driving in a parking garage: Vehicle localization and tracking using environment-embedded lidar sensors. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast City, Australia, 23–26 June 2013; pp. 829–834. [Google Scholar]
- Shen, M.; Habibi, G.; How, J.P. Transferable Pedestrian Motion Prediction Models at Intersections. arXiv 2018, arXiv:1804.00495. [Google Scholar]
- Smirnov, A.; Levashova, T. Knowledge fusion patterns: A survey. Inf. Fusion 2019, 52, 31–40. [Google Scholar] [CrossRef]
- Wang, P.; Yang, L.T.; Li, J.; Chen, J.; Hu, S. Data fusion in cyber-physical-social systems: State-of-the-art and perspectives. Inf. Fusion 2019, 51, 42–57. [Google Scholar] [CrossRef]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Ramachandran, U.; Kumar, R.; Wolenetz, M.; Cooper, B.; Agarwalla, B.; Shin, J.; Hutto, P.; Paul, A. Dynamic data fusion for future sensor networks. ACM Trans. Sens. Networks (TOSN) 2006, 2, 404–443. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.T.; Yang, S.; Branke, J. Evolutionary dynamic optimization: A survey of the state of the art. Swarm Evol. Comput. 2012, 6, 1–24. [Google Scholar] [CrossRef]
- Mavrovouniotis, M.; Li, C.; Yang, S. A survey of swarm intelligence for dynamic optimization: Algorithms and applications. Swarm Evol. Comput. 2017, 33, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Chang, W.C.; Cho, C.W. Online boosting for vehicle detection. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 40, 892–902. [Google Scholar] [CrossRef] [PubMed]
- Saadallah, A.; Moreira-Matias, L.; Sousa, R.; Khiari, J.; Jenelius, E.; Gama, J. BRIGHT-Drift-Aware Demand Predictions for Taxi Networks. IEEE Trans. Knowl. Data Eng. 2019, in press. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Predicting taxi–passenger demand using streaming data. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1393–1402. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Shi, H.; Wu, Y. A survey of multi-source domain adaptation. Inf. Fusion 2015, 24, 84–92. [Google Scholar] [CrossRef]
- Ou, C.; Ouali, C.; Karray, F. Transfer Learning Based Strategy for Improving Driver Distraction Recognition. In Proceedings of the International Conference Image Analysis and Recognition, Póvoa de Varzim, Portugal, 27–29 June 2018; pp. 443–452. [Google Scholar]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.Y. Driver activity recognition for intelligent vehicles: A deep learning approach. IEEE Trans. Veh. Technol. 2019, 68, 5379–5390. [Google Scholar] [CrossRef] [Green Version]
- Xing, Y.; Tang, J.; Liu, H.; Lv, C.; Cao, D.; Velenis, E.; Wang, F.Y. End-to-End Driving Activities and Secondary Tasks Recognition Using Deep Convolutional Neural Network and Transfer Learning. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26 June–1 July 2018; pp. 1626–1631. [Google Scholar]
- Ye, H.; Liang, L.; Li, G.Y.; Kim, J.; Lu, L.; Wu, M. Machine learning for vehicular networks: Recent advances and application examples. IEEE Veh. Technol. Mag. 2018, 13, 94–101. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Ferdowsi, A.; Challita, U.; Saad, W. Deep Learning for Reliable Mobile Edge Analytics in Intelligent Transportation Systems: An Overview. IEEE Veh. Technol. Mag. 2019, 14, 62–70. [Google Scholar] [CrossRef]
- Vögel, H.J.; Süß, C.; Hubregtsen, T.; André, E.; Schuller, B.; Härri, J.; Conradt, J.; Adi, A.; Zadorojniy, A.; Terken, J.; et al. Emotion-awareness for intelligent vehicle assistants: A research agenda. In Proceedings of the IEEE/ACM 1st International Workshop on Software Engineering for AI in Autonomous Systems (SEFAIAS), Gothenburg, Sweden, 28 May 2018; pp. 11–15. [Google Scholar]
- Kroll, A. Grey-box models: Concepts and application. New Front. Comput. Intell. Its Appl. 2000, 57, 42–51. [Google Scholar]
- Oussar, Y.; Dreyfus, G. How to be a gray box: Dynamic semi-physical modeling. Neural Netw. 2001, 14, 1161–1172. [Google Scholar] [CrossRef]
- Inga, J.; Flad, M.; Diehm, G.; Hohmann, S. Gray-Box Driver Modeling and Prediction: Benefits of Steering Primitives. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Kowloon Tong, Hong Kong, 9–12 October 2015; pp. 3054–3059. [Google Scholar]
- Flad, M.; Fröhlich, L.; Hohmann, S. Cooperative shared control driver assistance systems based on motion primitives and differential games. IEEE Trans. Hum. Mach. Syst. 2017, 47, 711–722. [Google Scholar] [CrossRef]
- Mittal, S. A survey of techniques for approximate computing. ACM Comput. Surv. (CSUR) 2016, 48, 62. [Google Scholar] [CrossRef] [Green Version]
- Alwadi, M.; Chetty, G. Energy Efficient Data Mining Scheme for High Dimensional Data. Procedia Comput. Sci. 2015, 46, 483–490. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Orshansky, M. Approximate computing: An emerging paradigm for energy-efficient design. In Proceedings of the 2013 18th IEEE European Test Symposium (ETS), Avignon, France, 27–30 May 2013; pp. 1–6. [Google Scholar]
- Lane, N.D.; Georgiev, P. Can deep learning revolutionize mobile sensing? In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, Santa Fe, NM, USA, 12–13 February 2015; pp. 117–122. [Google Scholar]
- Faisal, S. Towards Energy Efficient Data Mining & Graph Processing. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2015. [Google Scholar]
- Zliobaite, I.; Hollmen, J.; Koskinen, L.; Teittinen, J. Towards hardware-driven design of low-energy algorithms for data analysis. ACM SIGMOD Rec. 2015, 43, 15–20. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Ser, J.D.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. arXiv 2019, arXiv:1910.10045. [Google Scholar]
- Martin, K. Ethical implications and accountability of algorithms. J. Bus. Ethics 2018, 160, 835–850. [Google Scholar] [CrossRef] [Green Version]
- Veale, M.; Binns, R. Fairer machine learning in the real world: Mitigating discrimination without collecting sensitive data. Big Data Soc. 2017, 4, 2053951717743530. [Google Scholar] [CrossRef]
- Stoyanovich, J.; Howe, B.; Abiteboul, S.; Miklau, G.; Sahuguet, A.; Weikum, G. Fides: Towards a platform for responsible data science. In Proceedings of the 29th International Conference on Scientific and Statistical Database Management, Chicago, IL, USA, 27–29 June 2017; p. 26. [Google Scholar]
- Whittaker, M.; Crawford, K.; Dobbe, R.; Fried, G.; Kaziunas, E.; Mathur, V.; West, S.M.; Richardson, R.; Schultz, J.; Schwartz, O. AI Now Report 2018; AI Now Institute at New York University: New York, NY, USA, 2018. [Google Scholar]
- Victor, N.; Lopez, D.; Abawajy, J.H. Privacy models for big data: A survey. Int. J. Big Data Intell. 2016, 3, 61–75. [Google Scholar] [CrossRef]
- Rashidi, T.H.; Abbasi, A.; Maghrebi, M.; Hasan, S.; Waller, T.S. Exploring the capacity of social media data for modelling travel behaviour: Opportunities and challenges. Transp. Res. Part C Emerg. Technol. 2017, 75, 197–211. [Google Scholar] [CrossRef]
- Boyd, D.; Crawford, K. Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon. Information, Commun. Soc. 2012, 15, 662–679. [Google Scholar] [CrossRef]
- Chen, Y.; Guizani, M.; Zhang, Y.; Wang, L.; Crespi, N.; Lee, G.M. When traffic flow prediction meets wireless big data analytics. arXiv 2017, arXiv:1709.08024. [Google Scholar] [CrossRef]
- Wilson, B.; Hoffman, J.; Morgenstern, J. Predictive inequity in object detection. arXiv 2019, arXiv:1902.11097. [Google Scholar]
- Lim, H.S.M.; Taeihagh, A. Algorithmic decision-making in AVs: Understanding ethical and technical concerns for smart cities. Sustainability 2019, 11, 5791. [Google Scholar] [CrossRef] [Green Version]
- Bigman, Y.E.; Gray, K. Life and death decisions of autonomous vehicles. Nature 2020, 579, E1–E2. [Google Scholar] [CrossRef]
- Fu, K.; Alhamadani, A.; Ji, T.; Lu, C.T. Batman or the joker? the powerful urban computing and its ethics issues. SIGSPATIAL Spec. 2019, 11, 16–25. [Google Scholar] [CrossRef]
- Leben, D. Normative Principles for Evaluating Fairness in Machine Learning. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–8 February 2020; pp. 86–92. [Google Scholar]
- Verma, S.; Rubin, J. Fairness definitions explained. In Proceedings of the IEEE/ACM International Workshop on Software Fairness (FairWare), Gothenburg, Sweden, 29 May 2018; pp. 1–7. [Google Scholar]
- Zook, M.; Barocas, S.; Crawford, K.; Keller, E.; Gangadharan, S.P.; Goodman, A.; Hollander, R.; Koenig, B.A.; Metcalf, J.; Narayanan, A.; et al. Ten Simple Rules for Responsible Big Data Research. 2017. Available online: https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1005399 (accessed on 5 January 2019).
- Fei-Fei, L.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Yao, Q.; Kwok, J.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. arXiv 2019, arXiv:1904.05046. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. (CSUR) 2016, 49, 31. [Google Scholar] [CrossRef]
- Fernandez, A.; Herrera, F.; Cordon, O.; del Jesus, M.J.; Marcelloni, F. Evolutionary Fuzzy Systems for Explainable Artificial Intelligence: Why, When, What for, and Where to? IEEE Comput. Intell. Mag. 2019, 14, 69–81. [Google Scholar] [CrossRef]
- Mencar, C.; Alonso, J.M. Paving the Way to Explainable Artificial Intelligence with Fuzzy Modeling. In Proceedings of the International Workshop on Fuzzy Logic and Applications, Genoa, Italy, 6–7 September 2018; pp. 215–227. [Google Scholar]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Nisan, N.; Roughgarden, T.; Tardos, E.; Vazirani, V.V. Algorithmic Game Theory; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef] [Green Version]
- Ruch, C.; Richards, S.; Frazzoli, E. The Value of Coordination in One-Way Mobility-on-Demand Systems. IEEE Trans. Netw. Sci. Eng. 2019, in press. [Google Scholar] [CrossRef]
- Aldeen, Y.A.A.S.; Salleh, M.; Razzaque, M.A. A comprehensive review on privacy preserving data mining. SpringerPlus 2015, 4, 694. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Srikant, R. Privacy-preserving data mining. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; Volume 29, pp. 439–450. [Google Scholar]
- Mendes, R.; Vilela, J.P. Privacy-preserving data mining: Methods, metrics, and applications. IEEE Access 2017, 5, 10562–10582. [Google Scholar] [CrossRef]
- Ding, W.; Jing, X.; Yan, Z.; Yang, L.T. A survey on data fusion in internet of things: Towards secure and privacy-preserving fusion. Inf. Fusion 2019, 51, 129–144. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, S.; Mo, Z.; Yin, Y. Privacy preserving origin-destination flow measurement in vehicular cyber-physical systems. In Proceedings of the 2013 IEEE 1st International Conference on Cyber-Physical Systems, Networks, and Applications (CPSNA), Taipei, Taiwan, 19–20 August 2013; pp. 32–37. [Google Scholar]
- Florian, M.; Finster, S.; Baumgart, I. Privacy-preserving cooperative route planning. IEEE Internet Things J. 2014, 1, 590–599. [Google Scholar] [CrossRef]
- Rabieh, K.; Mahmoud, M.M.; Younis, M. Privacy-preserving route reporting scheme for traffic management in VANETs. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 7286–7291. [Google Scholar]
- Kim, S.W.; Park, S.; Won, J.I.; Kim, S.W. Privacy preserving data mining of sequential patterns for network traffic data. Inf. Sci. 2008, 178, 694–713. [Google Scholar] [CrossRef]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.; Tygar, J. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Nguyen, G.; Dlugolinsky, S.; Bobák, M.; Tran, V.; García, Á.L.; Heredia, I.; Malík, P.; Hluchỳ, L. Machine Learning and Deep Learning frameworks and libraries for large-scale data mining: A survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef] [Green Version]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer Nature: Berlin/Heidelberg, Germany, 2019. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laña, I.; Sanchez-Medina, J.J.; Vlahogianni, E.I.; Del Ser, J. From Data to Actions in Intelligent Transportation Systems: A Prescription of Functional Requirements for Model Actionability. Sensors 2021, 21, 1121. https://doi.org/10.3390/s21041121
Laña I, Sanchez-Medina JJ, Vlahogianni EI, Del Ser J. From Data to Actions in Intelligent Transportation Systems: A Prescription of Functional Requirements for Model Actionability. Sensors. 2021; 21(4):1121. https://doi.org/10.3390/s21041121
Chicago/Turabian StyleLaña, Ibai, Javier J. Sanchez-Medina, Eleni I. Vlahogianni, and Javier Del Ser. 2021. "From Data to Actions in Intelligent Transportation Systems: A Prescription of Functional Requirements for Model Actionability" Sensors 21, no. 4: 1121. https://doi.org/10.3390/s21041121
APA StyleLaña, I., Sanchez-Medina, J. J., Vlahogianni, E. I., & Del Ser, J. (2021). From Data to Actions in Intelligent Transportation Systems: A Prescription of Functional Requirements for Model Actionability. Sensors, 21(4), 1121. https://doi.org/10.3390/s21041121