
Learning Local–Global Multiple Correlation Filters for Robust Visual Tracking with Kalman Filter Redetection



Abstract
:1. Introduction
1.1. Motivation
1.2. Contribution
- We propose an intelligent local–global multiple correlation filter (LGCF) learning model. Our global filter uses multilayer CNN features to capture the whole appearance of the target. At the same time, the object is divided into two equal sized parts to construct local filters, which use handcraft features to capture the partial appearance of the target. We choose a position estimation method from coarse to fine and use a combination of multiple features to achieve accurate object tracking.
- We introduce an effective method where the target can be tracked accurately through Kalman filter redetection (KFR). We also propose time-space peak to sidelobe ratio (TSPSR) as a confidence value to measure the reliability of the current estimated position. Compared with CF with a different appearance model, we comprehensively use the time and motion information of the target instead of just the appearance information. If the tracking result of the correlation filter with the appearance model is unreliable, this method can make the target position regained to continue the tracking procedure.
- Based on the local–global learning model, we propose a collaborative update strategy with multiple correlation filters. In the update phase, we divide the global filter into three cases according to the state of the local filter: normal update, slow update, and no update. This method can effectively prevent the collaborative filters from learning the wrong target appearance.
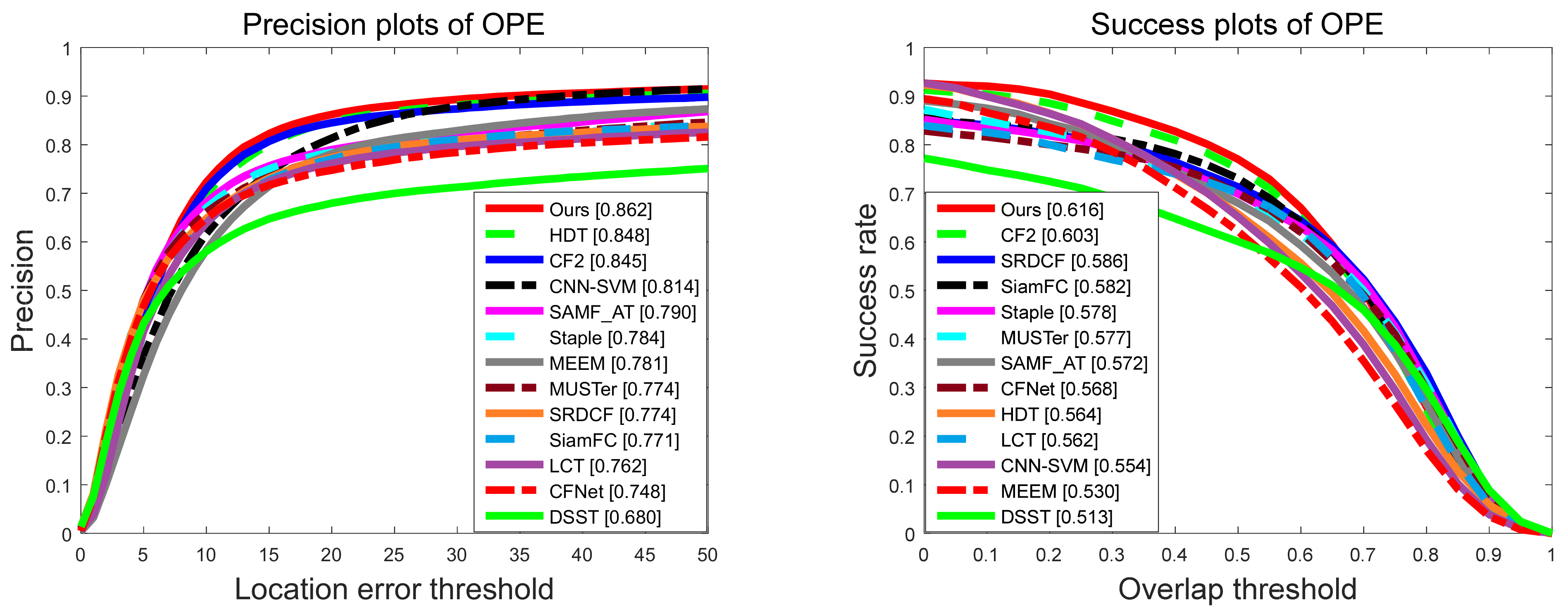
- We have evaluated the performance of the proposed LGCF algorithm on the OTB-2013 [25] and OTB-2015 [26] datasets, and verified the effectiveness of each contribution. Experimental data show that this method can improve the tracking accuracy and success rate effectively. The precision and success rates on the OTB-2013 reached 90.6% and 64.9%, respectively. On OTB-2015, the accuracy of our tracker reached 86.2%, and the success rate reached 61.6%.
2. Related Work
2.1. Tracking by CF
2.2. Tracking by Deep Learning
2.3. Tracking by KF
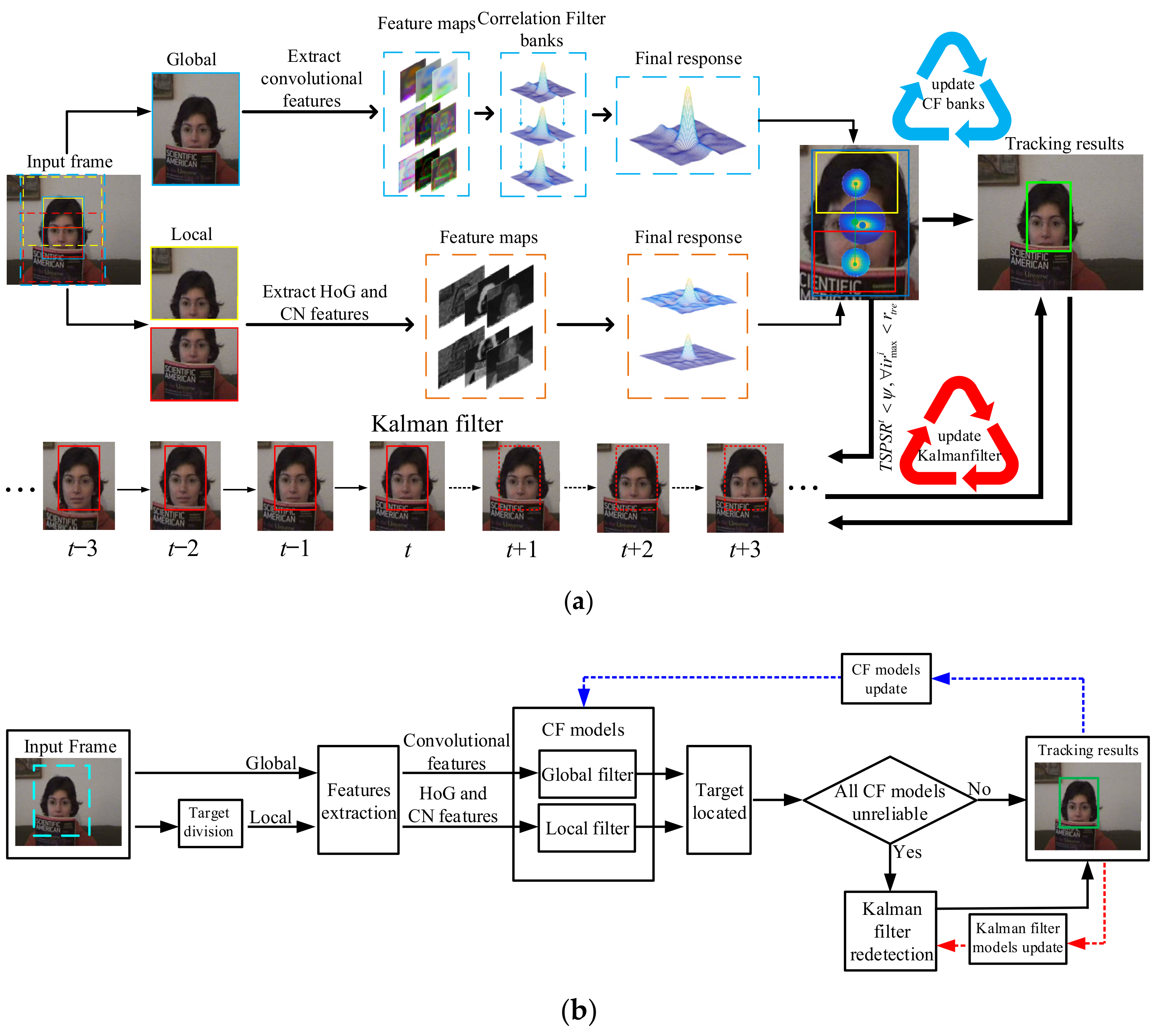
3. Our Approach
3.1. Overview
| Algorithm 1 The Main Steps of Our Algorithm |
| Input: Initial object position
in the first frame, VGGNet-19 pretrained models; |
| Output:Estimated position ; updated multiple correlation filters. |
|
1. Divided target as Figure 3; 2. Initiate global filter models using Equation (19); 3. Initiate Kalman filter redetection models using Equations (22) and (23); 4. for = 2, 3, … do 5. Exploit the VGGNet-19 to obtain multi-layer deep features; 6. Compute the response maps of global filter using Equation (5); 7. Compute the TSPSR using Equations (28) and (29); 8. Find the final global target position using Equation (17); 9. Compute the response maps of local filter using Equation (5); 10. Find the final local target position using Equation (15); 11. if then 12. Obtain the target position of the current frame by Kalman filter using Equation (26); 13. Update Kalman filter redetection models using Equations (24)–(27); 14. else 15. Obtain the target position of the current frame by multiple correlation filters using Equation (16); 16. end if 17. Update global filters using Equation (19); 18. Update local filters using Equation (20); 19. end for |
3.2. Global Filter
3.3. Local Filter
3.4. Local–Global Collaboration Model
3.5. Kalman Filter Redetection
4. Performance Analysis
4.1. Experimental Setup
4.1.1. Implementation Details
4.1.2. Datasets
4.1.3. Evaluation Indicators
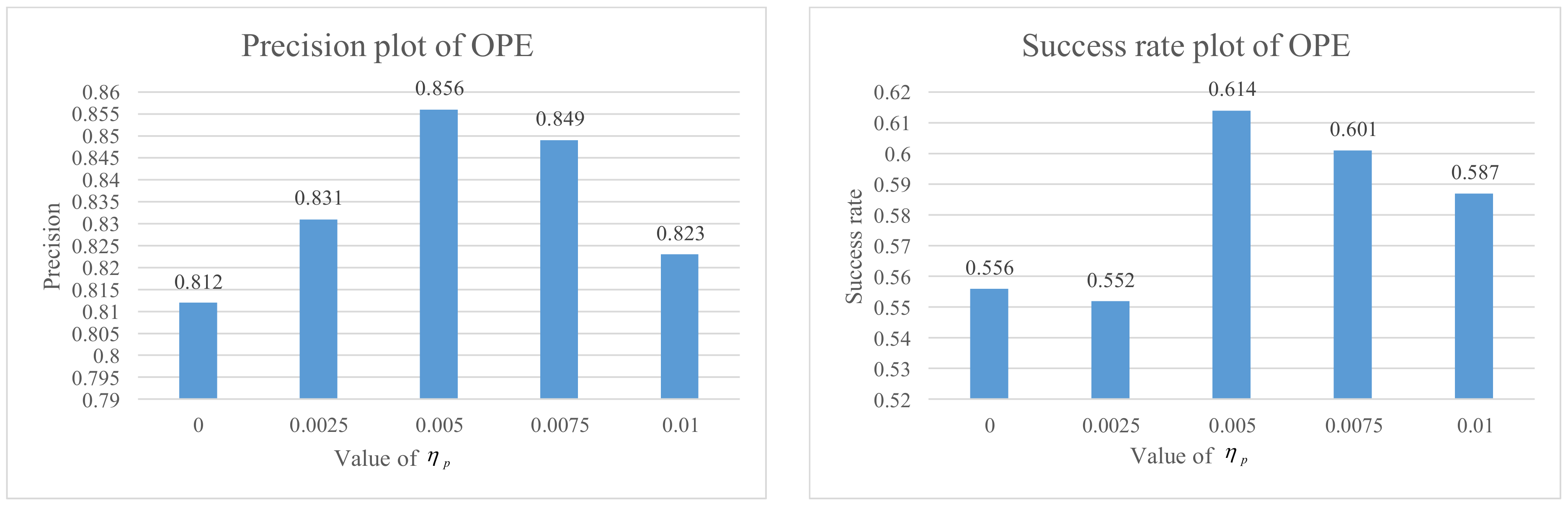
4.2. Effectiveness Analysis
4.2.1. Analysis of Local–Global Multiple CF Learning Model
4.2.2. Analysis of Collaborative Update Strategy
4.3. Overall Performance
4.3.1. Quantitative Evaluation
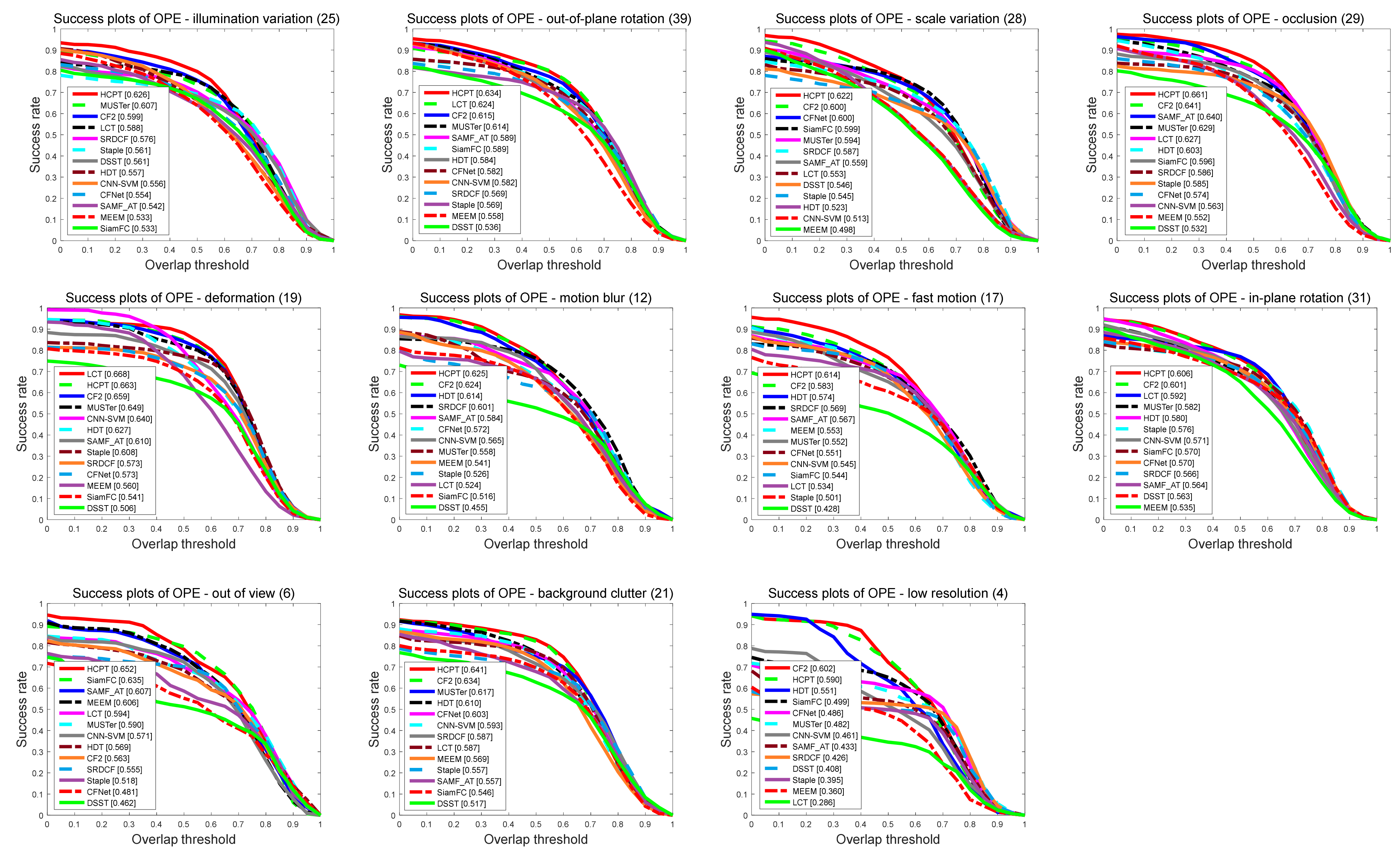
4.3.2. Attribute-Based Evaluation
4.3.3. Qualitative Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adam, A.; Rivlin, E.; Shimshoni, I. Robust Fragments-Based Tracking Using the Integral Histogram. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; IEEE Xplore: New York, NY, USA, 2006; Volume 1, pp. 798–805. [Google Scholar]
- Bao, C.; Wu, Y.; Ling, H.; Ji, H. Real Time Robust L1 Tracker Using Accelerated Proximal Gradient Approach. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–17 June 2012; IEEE Xplore: New York, NY, USA, 2012; pp. 1830–1837. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1619–1632. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Jin, X.; Sun, J.; Wang, J.; Li, K. Dual model learning combined with multiple feature selection for accurate visual tracking. IEEE Access 2019, 7, 43956–43969. [Google Scholar] [CrossRef]
- Bolme, D. Visual Object Tracking Using Adaptive Correlation Filters. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 4310–4318. [Google Scholar]
- Chen, Y.; Wang, J.; Xia, R.; Zhang, Q.; Cao, Z.; Yang, K. The visual object tracking algorithm research based on adaptive combination kernel. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 4855–4867. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [Green Version]
- Comaniciu, D.; Ramesh, V.; Meer, P. Real-Time Tracking of Non-Rigid Objects Using Mean Shift. In Proceedings of the 2000 IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 13–15 June 2000; IEEE Xplore: New York, NY, USA, 2000; pp. 142–149. [Google Scholar]
- Tuytelaars, T.; Mikolajczyk, K. Local Invariant Feature Detectors: A Survey. In Foundations and Trends in Computer Graphics and Vision; now Publisher: Hanover, MA, USA, 2008; Volume 3, pp. 177–280. [Google Scholar]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Wang, S.; Lu, H.; Yang, F.; Yang, M.H. Superpixel Tracking. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1323–1330. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 13–16 December 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 58–66. [Google Scholar]
- Zhang, J.; Jin, X.; Sun, J.; Wang, J.; Sangaiah, A.K. Spatial and semantic convolutional features for robust visual object tracking. Multimed. Tools Appl. 2020, 79, 15095–15115. [Google Scholar] [CrossRef]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, J.; Lim, J.; Yang, M.H. Hedged Deep Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE Xplore: New York, NY, USA, 2016; pp. 4303–4311. [Google Scholar]
- Zhang, J.; Wu, Y.; Feng, W.; Wang, J. Spatially attentive visual tracking using multi-model adaptive response fusion. IEEE Access 2019, 7, 83873–83887. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 13–16 December 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 3074–3082. [Google Scholar]
- He, Z.; Fan, Y.; Zhuang, Y.; Dong, Y.; Bai, H. Correlation Filters with Weighted Convolution Responses. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE Xplore: New York, NY, USA, 2017; pp. 1992–2000. [Google Scholar]
- Song, Y.; Ma, C.; Gong, L.; Zhang, J.; Lau, R.W.; Yang, M.H. Crest: Convolutional Residual Learning for Visual Tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE Xplore: New York, NY, USA, 2017; pp. 2555–2564. [Google Scholar]
- Zhang, J.; Sun, J.; Wang, J.; Yue, X.G. Visual object tracking based on residual network and cascaded correlation filters. J. Ambient Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Akin, O.; Erdem, E.; Erdem, I.A.; Mikolajczyk, K. Deformable part-based tracking by coupled global and local correlation filters. J. Vis. Commun. Image Represent. 2016, 38, 763–774. [Google Scholar] [CrossRef]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M.H. Long-Term Correlation Tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 5388–5396. [Google Scholar]
- Jing, X.Y.; Zhu, X.; Wu, F.; You, X.; Liu, Q.; Yue, D.; Hu, R. Super-Resolution Person Re-Identification with Semi-Coupled Low-Rank Discriminant Dictionary Learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 695–704. [Google Scholar]
- Lai, Z.; Wong, W.K.; Xu, Y.; Yang, J.; Zhang, D. Approximate orthogonal sparse embedding for dimensionality reduction. IEEE Trans. Neural Networks Learn. Syst. 2015, 27, 723–735. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; IEEE Xplore: New York, NY, USA, 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. In Proceedings of the 12th European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 702–715. [Google Scholar]
- Zhang, J.; Wang, W.; Lu, C.; Wang, J.; Sangaiah, A.K. Lightweight deep network for traffic sign classification. Ann. Telecommun. 2020, 75, 369–379. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Li, X.; Kim, H.J.; Wang, J. A full convolutional network based on DenseNet for remote sensing scene classification. Math. Biosci. Eng. 2019, 16, 3345–3367. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; IEEE Xplore: New York, NY, USA, 2017; Volume 7, pp. 6638–6646. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 472–488. [Google Scholar]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the 8th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 254–265. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the 25th British Machine Vision Conference, Nottingham, UK, 1–5 September 2014; BMVA Press: Durham, UK, 2014; Volume 7, pp. 83873–83887. [Google Scholar]
- Li, Y.; Zhu, J.; Hoi, S.C. Reliable Patch Trackers: Reliable Patch Trackers: Robust Visual Tracking by Exploiting Reliable Patches. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 353–361. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R. Learning Dynamic Siamese Network for Visual Object Tracking. In Proceedings of the 2017 IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE Xplore: New York, NY, USA, 2017; pp. 1763–1771. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Xplore: New York, NY, USA, 2018; pp. 8971–8980. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L. Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; IEEE Xplore: New York, NY, USA, 2019; pp. 1328–1338. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K. A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE Xplore: New York, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:abs/1409.1556. [Google Scholar]
- Ba, S.; He, Z.; Xu, T.B.; Zhu, Z.; Dong, Y.; Bai, H. Multi-Hierarchical Independent Correlation Filters for Visual Tracking. arXiv 2018, arXiv:abs/1811.10302v1. [Google Scholar]
- Sun, Y.; Xie, J.; Guo, J.; Wang, H.; Zhao, Y. A Modified Marginalized Kalman Filter for Maneuvering Target Tracking. In Proceedings of the 2nd International Conference on Information Technology and Electronic Commerce, Zurich, Switzerland, 14–15 June 2014; pp. 107–111. [Google Scholar]
- Divya, V.X.; Kumari, B.L. Performance Analysis of Extended Kalman Filter for Single and Multi Target Tracking. In Proceedings of the 13th International Conference on Electromagnetic Interference and Compatibility, Visakhapatnam, India, 22–23 July 2015; pp. 53–57. [Google Scholar]
- Bukey, C.M.; Kulkarni, S.V.; Chavan, R.A. Multi-Object Tracking Using Kalman Filter and Particle Filter. In Proceedings of the 2017 IEEE International Conference on Power, Control, Signals and Instrumentation Engineering, Chennai, India, 21–22 September 2017; IEEE Xplore: New York, NY, USA, 2017; pp. 1688–1692. [Google Scholar]
- Patel, H.A.; Thakore, D.G. Moving object tracking using Kalman filter. Int. J. Comput. Sci. Mob. Comput. 2013, 2, 326–332. [Google Scholar]
- Naresh Boddeti, V.; Kanade, T.; Vijaya Kumar, B. Correlation Filters for Object Alignment. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; IEEE Xplore: New York, NY, USA, 2013; pp. 2291–2298. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van de Weijer, J.; Schmid, C.; Verbeek, J.; Larlus, D. Learning color names for real-world applications. IEEE Trans. Image Process. 2009, 18, 1512–1523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bibi, A.; Mueller, M.; Ghanem, B. Target Response Adaptation for Correlation Filter Tracking. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 419–433. [Google Scholar]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.; Tao, D. Multistore Tracker (Muster): A Cognitive Psychology Inspired Approach to Object Tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 749–785. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary Learners for Real-Time Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; IEEE Xplore: New York, NY, USA, 2016; pp. 1401–1409. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; IEEE Xplore: New York, NY, USA, 2017; Volume 7, pp. 2805–2813. [Google Scholar]
- Lee, D.Y.; Sim, Y.J.; Kim, C.S. Multihypothesis Trajectory Analysis for Robust Visual Tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; IEEE Xplore: New York, NY, USA, 2015; pp. 5088–5096. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | State of Tracker | State of Learning Rate | Value of Learning Rate | Condition in t-th Frame |
|---|---|---|---|---|
| 1 | No occlusion | Normal update | ||
| 2 | Partial occlusion | Slow update | ||
| 3 | Complete occlusion | Not update |
| Types of Models | OTB-2013 Precision | OTB-2013 Success Rate | OTB-2015 Precision | OTB-2015 Success Rate |
|---|---|---|---|---|
| Global (Baseline) | 0.891 | 0.635 | 0.845 | 0.603 |
| Global + Local | 0.903 | 0.647 | 0.856 | 0.614 |
| Global + Local + KFR | 0.906 | 0.649 | 0.862 | 0.616 |
| Trackers | IV | OR | SV | OCC | DEF | MB | FM | IR | OV | BC | LR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN-SVM | 0.789 | 0.806 | 0.791 | 0.73 | 0.793 | 0.767 | 0.742 | 0.798 | 0.659 | 0.776 | 0.79 |
| SRDCF | 0.786 | 0.724 | 0.75 | 0.703 | 0.699 | 0.782 | 0.762 | 0.739 | 0.572 | 0.775 | 0.631 |
| Staple | 0.776 | 0.738 | 0.739 | 0.728 | 0.751 | 0.719 | 0.709 | 0.772 | 0.644 | 0.749 | 0.591 |
| MUSTer | 0.776 | 0.753 | 0.72 | 0.734 | 0.689 | 0.699 | 0.684 | 0.756 | 0.603 | 0.784 | 0.677 |
| LCT | 0.739 | 0.748 | 0.687 | 0.682 | 0.689 | 0.673 | 0.667 | 0.768 | 0.616 | 0.734 | 0.49 |
| MEEM | 0.733 | 0.795 | 0.74 | 0.741 | 0.754 | 0.722 | 0.728 | 0.79 | 0.690 | 0.746 | 0.605 |
| SiamFC | 0.728 | 0.75 | 0.739 | 0.722 | 0.69 | 0.724 | 0.741 | 0.752 | 0.65 | 0.69 | 0.815 |
| SAMF_AT | 0.723 | 0.764 | 0.75 | 0.748 | 0.687 | 0.765 | 0.718 | 0.778 | 0.652 | 0.713 | 0.716 |
| DSST | 0.714 | 0.641 | 0.655 | 0.597 | 0.542 | 0.595 | 0.562 | 0.689 | 0.483 | 0.704 | 0.55 |
| CFNet | 0.686 | 0.728 | 0.715 | 0.674 | 0.643 | 0.687 | 0.695 | 0.759 | 0.572 | 0.724 | 0.787 |
| HDT | 0.815 | 0.807 | 0.812 | 0.774 | 0.821 | 0.794 | 0.802 | 0.834 | 0.687 | 0.844 | 0.766 |
| HCF | 0.835 | 0.817 | 0.807 | 0.776 | 0.791 | 0.804 | 0.792 | 0.849 | 0.689 | 0.852 | 0.822 |
| Ours | 0.87 | 0.85 | 0.835 | 0.817 | 0.806 | 0.846 | 0.796 | 0.856 | 0.784 | 0.851 | 0.867 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Liu, Y.; Liu, H.; Wang, J. Learning Local–Global Multiple Correlation Filters for Robust Visual Tracking with Kalman Filter Redetection. Sensors 2021, 21, 1129. https://doi.org/10.3390/s21041129
Zhang J, Liu Y, Liu H, Wang J. Learning Local–Global Multiple Correlation Filters for Robust Visual Tracking with Kalman Filter Redetection. Sensors. 2021; 21(4):1129. https://doi.org/10.3390/s21041129
Chicago/Turabian StyleZhang, Jianming, Yang Liu, Hehua Liu, and Jin Wang. 2021. "Learning Local–Global Multiple Correlation Filters for Robust Visual Tracking with Kalman Filter Redetection" Sensors 21, no. 4: 1129. https://doi.org/10.3390/s21041129
APA StyleZhang, J., Liu, Y., Liu, H., & Wang, J. (2021). Learning Local–Global Multiple Correlation Filters for Robust Visual Tracking with Kalman Filter Redetection. Sensors, 21(4), 1129. https://doi.org/10.3390/s21041129