Autonomous Identification and Positioning of Trucks during Collaborative Forage Harvesting



Abstract
:1. Introduction
2. System Description and Proposed Method
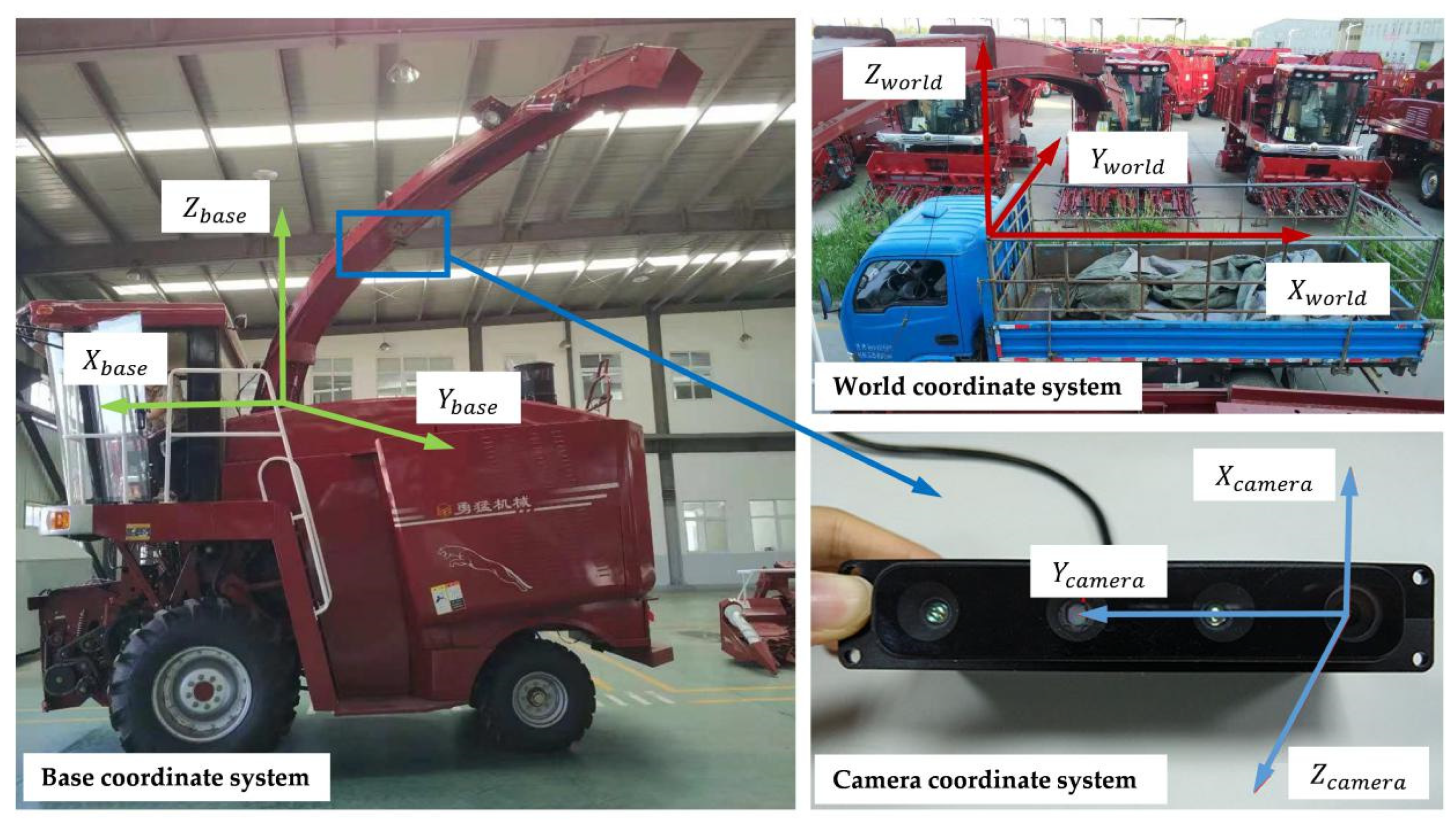
2.1. System Description
2.2. Proposed Method
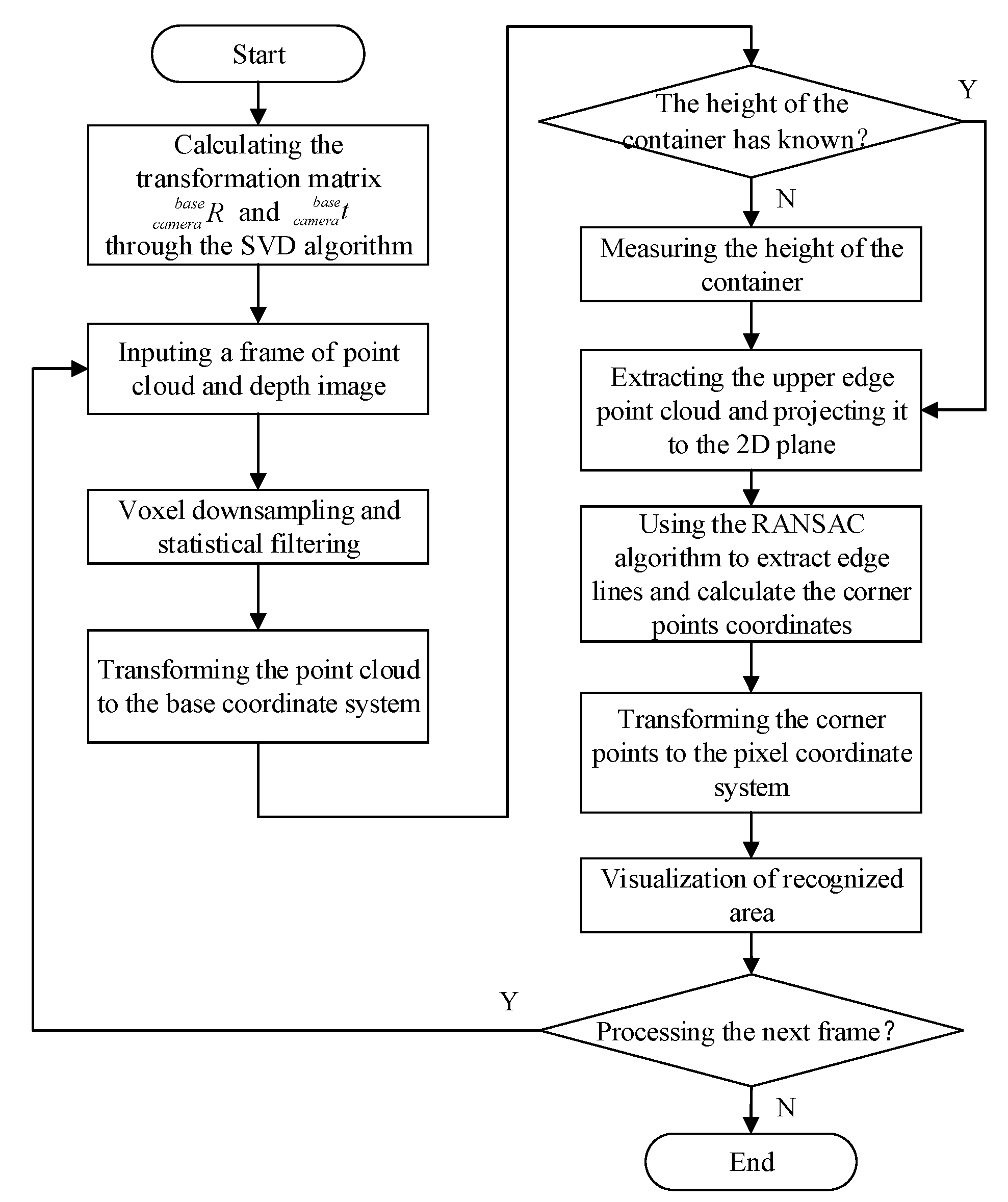
2.2.1. Method Overview
2.2.2. Point Cloud Preprocessing
2.2.3. Point Cloud Pose Transformation
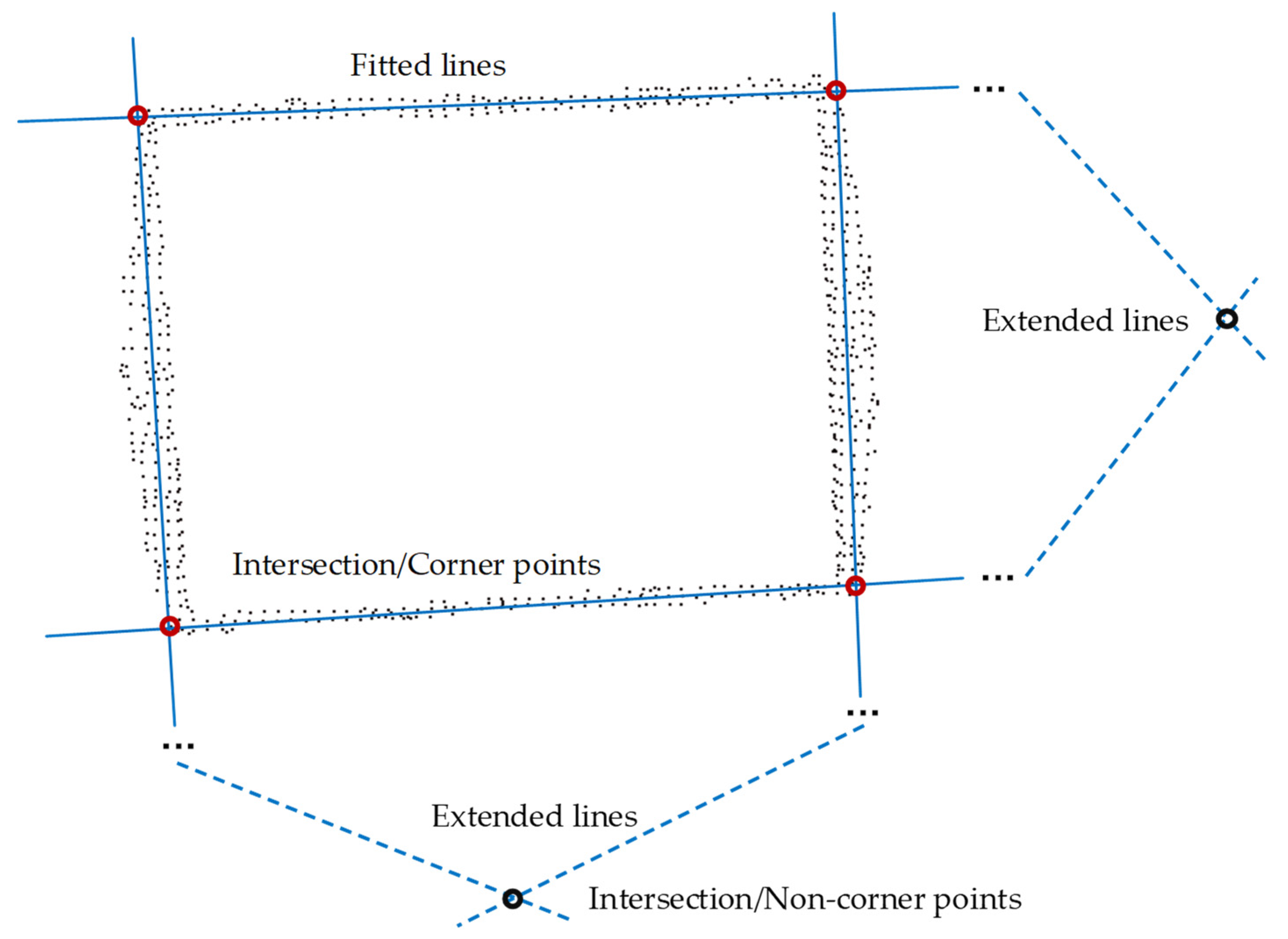
2.2.4. Segmentation of the Upper Edge Points
2.2.5. Identification and Positioning of the Container
2.2.6. Visualization of the Results
3. Field Experiment and Results Analysis
3.1. Field Experiment Site and Equipment
3.2. Evaluation Metrics of the CAIP Method
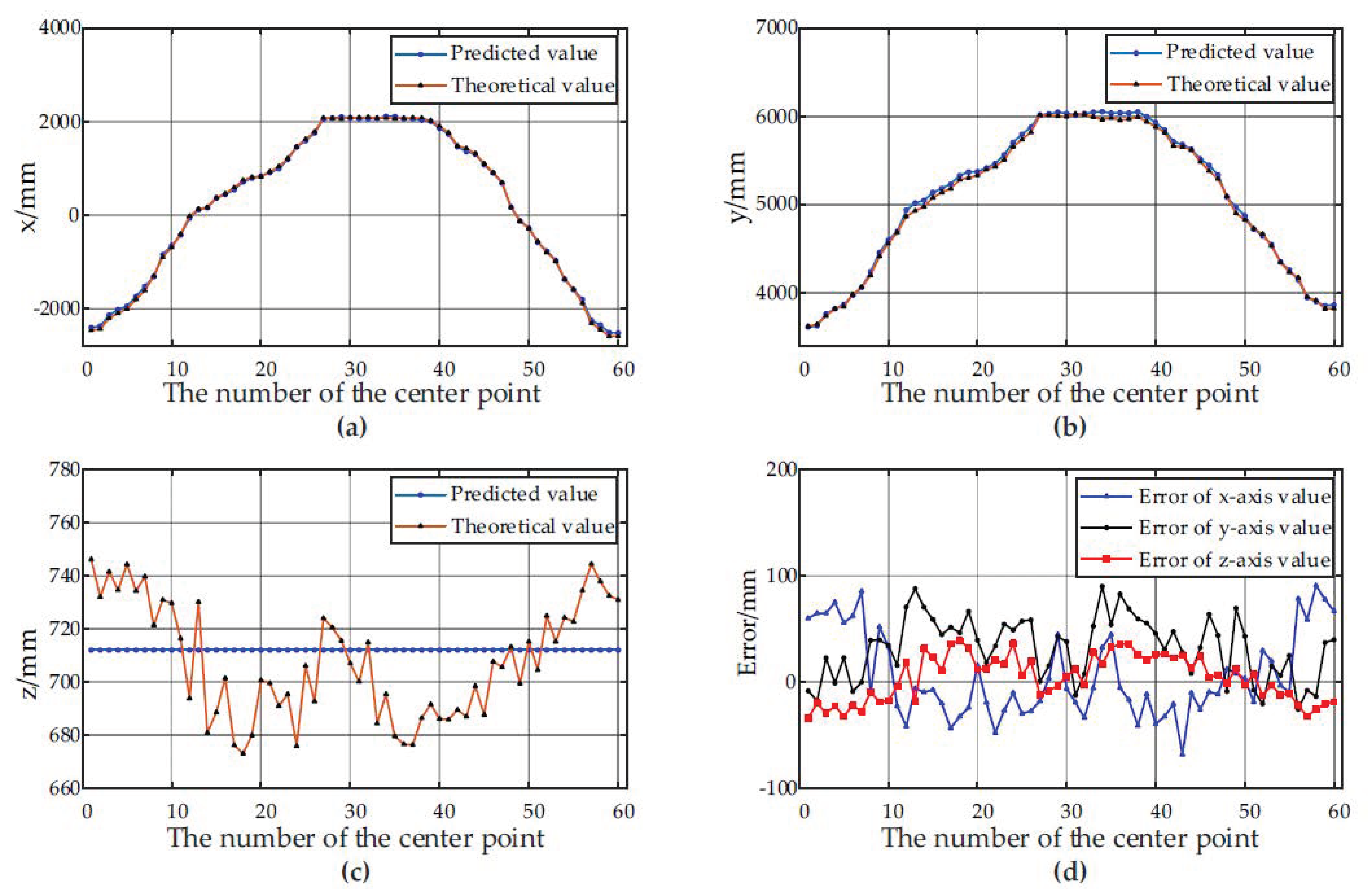
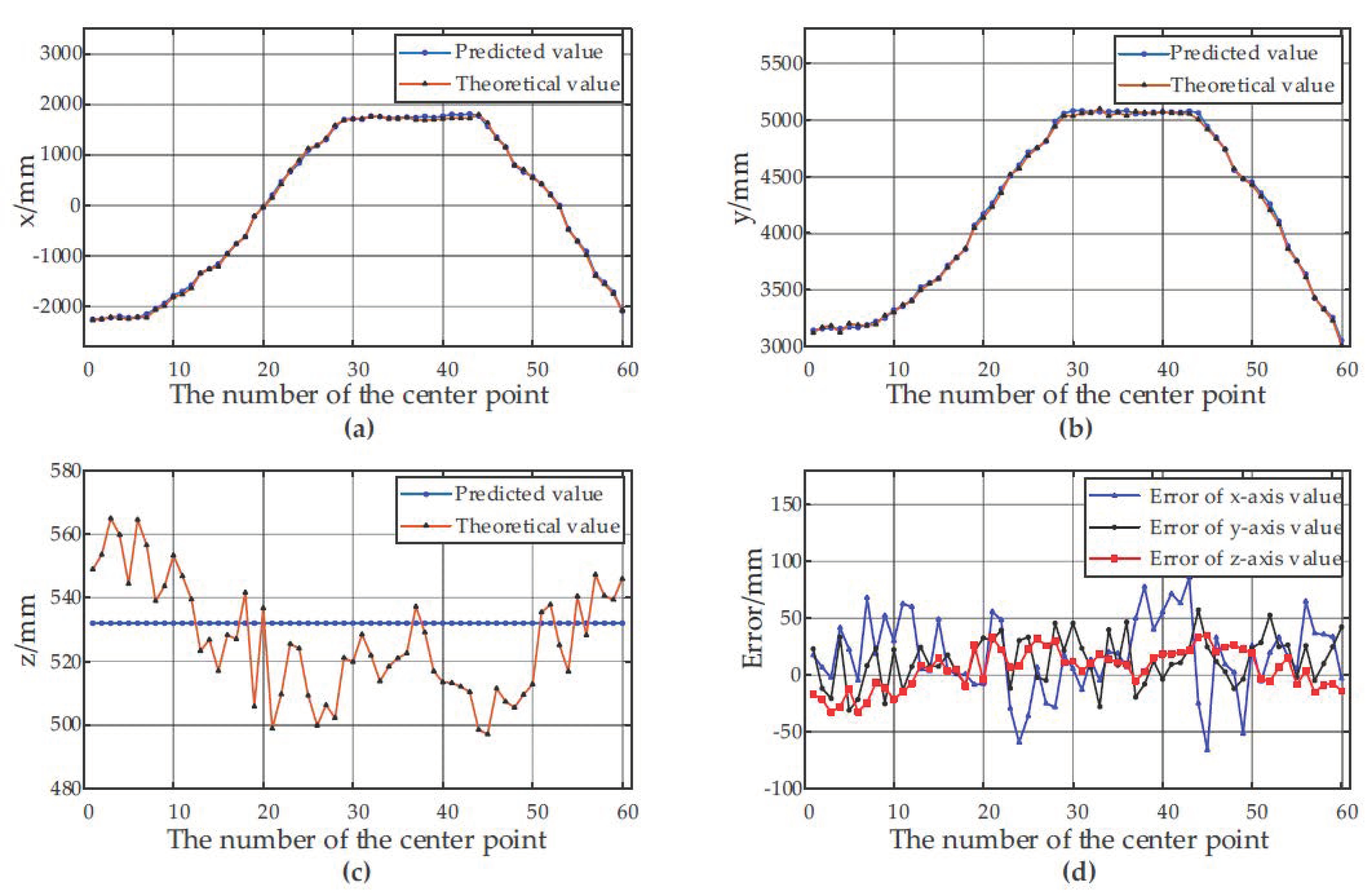
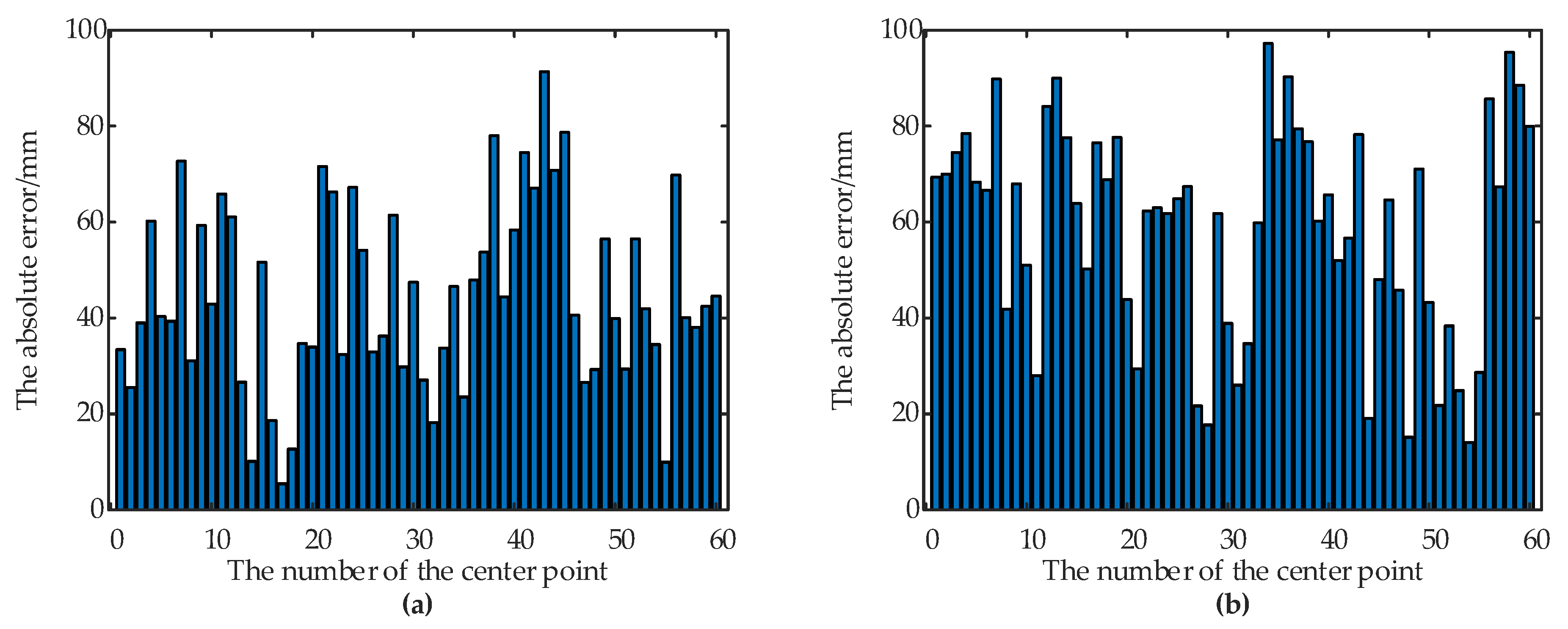
3.3. Results Analysis and Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cozzi, G.; Mazzenga, A.; Contiero, B.; Burato, G. Use of maize silage in beef cattle feeding during the finishing period. Ital. J. Anim. Sci. 2008, 7, 39–52. [Google Scholar] [CrossRef] [Green Version]
- Goulart, R.S.; Vieira, R.A.; Daniel, J.L.; Amaral, R.C.; Santos, V.P.; Filho, S.G.T.; Cabezas-Garcia, E.H.; Tedeschi, L.O.; Nussio, L.G. Effects of source and concentration of neutral detergent fiber from roughage in beef cattle diets on feed intake, ingestive behavior, and ruminal kinetics. J. Anim. Sci. 2020, 98, 1–15. [Google Scholar] [CrossRef]
- Mazzenga, A.; Gianesella, M.; Brscic, M.; Cozzi, G. Feeding behaviour, diet digestibility, rumen fluid and metabolic parameters of beef cattle fed total mixed rations with a stepped substitution of wheat straw with maize silage. Livest. Sci. 2009, 122, 16–23. [Google Scholar] [CrossRef]
- Salinas-Chavira, J.; Alvarez, E.; Montaño, M.; Zinn, R. Influence of forage NDF level, source and pelletizing on growth performance, dietary energetics, and characteristics of digestive function for feedlot cattle. Anim. Feed Sci. Technol. 2013, 183, 106–115. [Google Scholar] [CrossRef]
- Scudamore, K.A.; Livesey, C.T. Occurrence and significance of mycotoxins in forage crops and silage: A review. J. Sci. Food Agric. 1998, 77, 1–17. [Google Scholar] [CrossRef]
- Muck, R.; Shinners, K.J. Conserved forage (silage and hay): Progress and priorities. In Proceedings of the International Grassland Congress, Sao Pedro, Sao Paulo, Brazil, 11–21 February 2001; pp. 753–762. [Google Scholar]
- Bietresato, M.; Pavan, S.; Cozzi, G.; Sartori, L. A numerical approach for evaluating and properly setting self-propelled forage harvesters. Trans. ASABE 2013, 56, 5–14. [Google Scholar] [CrossRef]
- Shinners, K.J. Engineering principles of silage harvesting equipment. Silage Sci. Technol. 2003, 42, 361–403. [Google Scholar]
- Jensen, M.A.F.; Bochtis, D. Automatic recognition of operation modes of combines and transport units based on GNSS trajectories. IFAC Proc. Vol. 2013, 46, 213–218. [Google Scholar] [CrossRef]
- Happich, G.; Harms, H.-H.; Lang, T. Loading of Agricultural Trailers Using a Model-Based Method. Agric. Eng. Int. CIGR J. 2009, XI, 1–13. [Google Scholar]
- Pollklas, M. Device for Automatic Filling of Containers. U.S. Patent Application No. 5575316, 19 November 1996. [Google Scholar]
- Bonefas, Z.T.; Herman, H.; Campoy, J. Fill Level Indicator for an Automated Unloading System. U.S. Patent Application No. 10019790B2, 10 July 2018. [Google Scholar]
- Gaard, J.D. Grain Wagon Fill Detection Using Ultrasonic Sensors. Master’s Thesis, Iowa State University, Ames, IA, USA, 2012. [Google Scholar]
- Alexia, B.M.; Brislen, A.J.; Wicking, J.R.; Frandsen, W.J., Jr. Image Processing Spout Control System. U.S. Patent Application No. 6943824B2, 13 September 2005. [Google Scholar]
- Kurita, H.; Iida, M.; Suguri, M.; Masuda, R. Application of image processing technology for unloading automation of robotic head-feeding combine harvester. Eng. Agric. Environ. Food 2012, 5, 146–151. [Google Scholar] [CrossRef]
- Cho, W.; Kurita, H.; Iida, M.; Suguri, M.; Masuda, R. Autonomous positioning of the unloading auger of a combine harvester by a laser sensor and GNSS. Eng. Agric. Environ. Food 2015, 8, 178–186. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Z.; Bai, X.; Zhao, Y. Grain Truck Loading Status Detection Based on Machine Vision. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 40–44. [Google Scholar]
- Bechar, A.; Vigneault, C. Agricultural robots for field operations: Concepts and components. Biosyst. Eng. 2016, 149, 94–111. [Google Scholar] [CrossRef]
- Tang, Y.-C.; Wang, C.; Luo, L.; Zou, X. Recognition and localization methods for vision-based fruit picking robots: A review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef]
- Lin, G.; Tang, Y.; Zou, X.; Cheng, J.; Xiong, J. Fruit detection in natural environment using partial shape matching and probabilistic Hough transform. Precis. Agric. 2020, 21, 160–177. [Google Scholar] [CrossRef]
- Balta, H.; Velagic, J.; Bosschaerts, W.; De Cubber, G.; Siciliano, B. Fast statistical outlier removal based method for large 3D point clouds of outdoor environments. IFAC-PapersOnLine 2018, 51, 348–353. [Google Scholar] [CrossRef]
- Xu, H.; Chen, G.; Wang, Z.; Sun, L.; Su, F. RGB-D-Based Pose Estimation of Workpieces with Semantic Segmentation and Point Cloud Registration. Sensors 2019, 19, 1873. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the 2011 IEEE international conference on robotics and automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Xu, S.; Lu, K.; Pan, L.; Liu, T.; Zhou, Y.; Wang, B. 3D Reconstruction of Rape Branch and Pod Recognition Based on RGB-D Camera. Trans. Chin. Soc. Agric. Mach. 2019, 50, 21–27. [Google Scholar]
- Scaramuzza, D.; Fraundorfer, F. Visual odometry [tutorial]. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Shin, D.; Lee, W.; Na, S. Dynamic load estimation in silage harvesting. Trans. ASAE 2005, 48, 1311–1320. [Google Scholar] [CrossRef] [Green Version]
- Derpanis, K.G. Overview of the RANSAC Algorithm. Image Rochester N. Y. 2010, 4, 2–3. [Google Scholar]
- Lin, G.; Tang, Y.; Zou, X.; Xiong, J.; Fang, Y. Color-, depth-, and shape-based 3D fruit detection. Precis. Agric. 2020, 21, 1–17. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Huang, Z.; Zhou, H.; Wang, C.; Lian, G. Three-dimensional perception of orchard banana central stock enhanced by adaptive multi-vision technology. Comput. Electron. Agric. 2020, 174, 105508. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Container Type | Image No. | Union/Pixels | Intersection/Pixels | IoU | Average of IoU |
|---|---|---|---|---|---|
| Container A | 1 | 69474 | 63180 | 0.9094 | 0.9069 |
| 2 | 70520 | 64258 | 0.9112 | ||
| 3 | 72525 | 66331 | 0.9146 | ||
| 4 | 71343 | 65643 | 0.9201 | ||
| 5 | 74794 | 67015 | 0.8960 | ||
| 6 | 71794 | 63854 | 0.8894 | ||
| 7 | 72794 | 65595 | 0.9011 | ||
| 8 | 75297 | 67105 | 0.8912 | ||
| 9 | 71352 | 66329 | 0.9296 | ||
| 10 | 69400 | 62994 | 0.9077 | ||
| 11 | 72093 | 64588 | 0.8959 | ||
| 12 | 72539 | 66337 | 0.9145 | ||
| 13 | 73709 | 67982 | 0.9223 | ||
| 14 | 76293 | 67237 | 0.8813 | ||
| 15 | 71228 | 65444 | 0.9188 | ||
| Container B | 1 | 147787 | 135003 | 0.9135 | 0.8956 |
| 2 | 156686 | 138087 | 0.8813 | ||
| 3 | 152595 | 133139 | 0.8725 | ||
| 4 | 156609 | 141512 | 0.9036 | ||
| 5 | 161556 | 147064 | 0.9103 | ||
| 6 | 157791 | 139408 | 0.8835 | ||
| 7 | 156961 | 141438 | 0.9011 | ||
| 8 | 166250 | 149475 | 0.8991 | ||
| 9 | 146632 | 133655 | 0.9115 | ||
| 10 | 153721 | 141931 | 0.9233 | ||
| 11 | 149072 | 132570 | 0.8893 | ||
| 12 | 160023 | 134659 | 0.8415 | ||
| 13 | 148056 | 134050 | 0.9054 | ||
| 14 | 159701 | 143843 | 0.9007 | ||
| 15 | 151321 | 135856 | 0.8978 |
| Container Type | Error | Maximum Value/mm | Minimum Value/mm | Average Value/mm | RMSE/mm |
|---|---|---|---|---|---|
| Container A | x | 90.76 | −68.66 | 5.77 | 39.53 |
| y | 90.10 | −25.88 | 32.48 | 29.16 | |
| z | 38.99 | −34.24 | 4.10 | 21.23 | |
| Absolute error | 97.22 | 14.04 | 58.88 | 23.85 | |
| Container B | x | 85.70 | −66.06 | 13.04 | 33.62 |
| y | 57.09 | −31.12 | 13.01 | 21.14 | |
| z | 34.91 | −32.96 | 5.41 | 17.51 | |
| Absolute error | 91.36 | 5.43 | 44.62 | 26.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Gong, L.; Chen, S.; Wang, W.; Miao, Z.; Liu, C. Autonomous Identification and Positioning of Trucks during Collaborative Forage Harvesting. Sensors 2021, 21, 1166. https://doi.org/10.3390/s21041166
Zhang W, Gong L, Chen S, Wang W, Miao Z, Liu C. Autonomous Identification and Positioning of Trucks during Collaborative Forage Harvesting. Sensors. 2021; 21(4):1166. https://doi.org/10.3390/s21041166
Chicago/Turabian StyleZhang, Wei, Liang Gong, Suyue Chen, Wenjie Wang, Zhonghua Miao, and Chengliang Liu. 2021. "Autonomous Identification and Positioning of Trucks during Collaborative Forage Harvesting" Sensors 21, no. 4: 1166. https://doi.org/10.3390/s21041166
APA StyleZhang, W., Gong, L., Chen, S., Wang, W., Miao, Z., & Liu, C. (2021). Autonomous Identification and Positioning of Trucks during Collaborative Forage Harvesting. Sensors, 21(4), 1166. https://doi.org/10.3390/s21041166