3D Object Detection and Instance Segmentation from 3D Range and 2D Color Images †

Abstract
:1. Introduction
1.1. Problem Definition
1.1.1. 3D Object Detection
1.1.2. 3D Instance Segmentation
1.2. Our Solutions
- We have significantly improved efficiency with respect to the state-of-the-art in 3D detection. Our 3D detection without segmentation has been presented in [14]. In this paper, we provide an enhanced system that performs both detection and segmentation. That improves the detection performance, and it also includes instance segmentation results. The increased space and time efficiency makes our method appropriate for real-time robotic applications.
- We are able to provide accurate detection and segmentation results using Depth only images, unlike competing methods such as [9]. This is significant, since our methods can also work well in low lighting conditions, or with sensors that do not acquire RGB images.
2. Related Work
3. 3D Object Detection
3.1. Dataset
3.2. Frustum VoxNet V1 System Overview
3.3. Frustum Voxelization
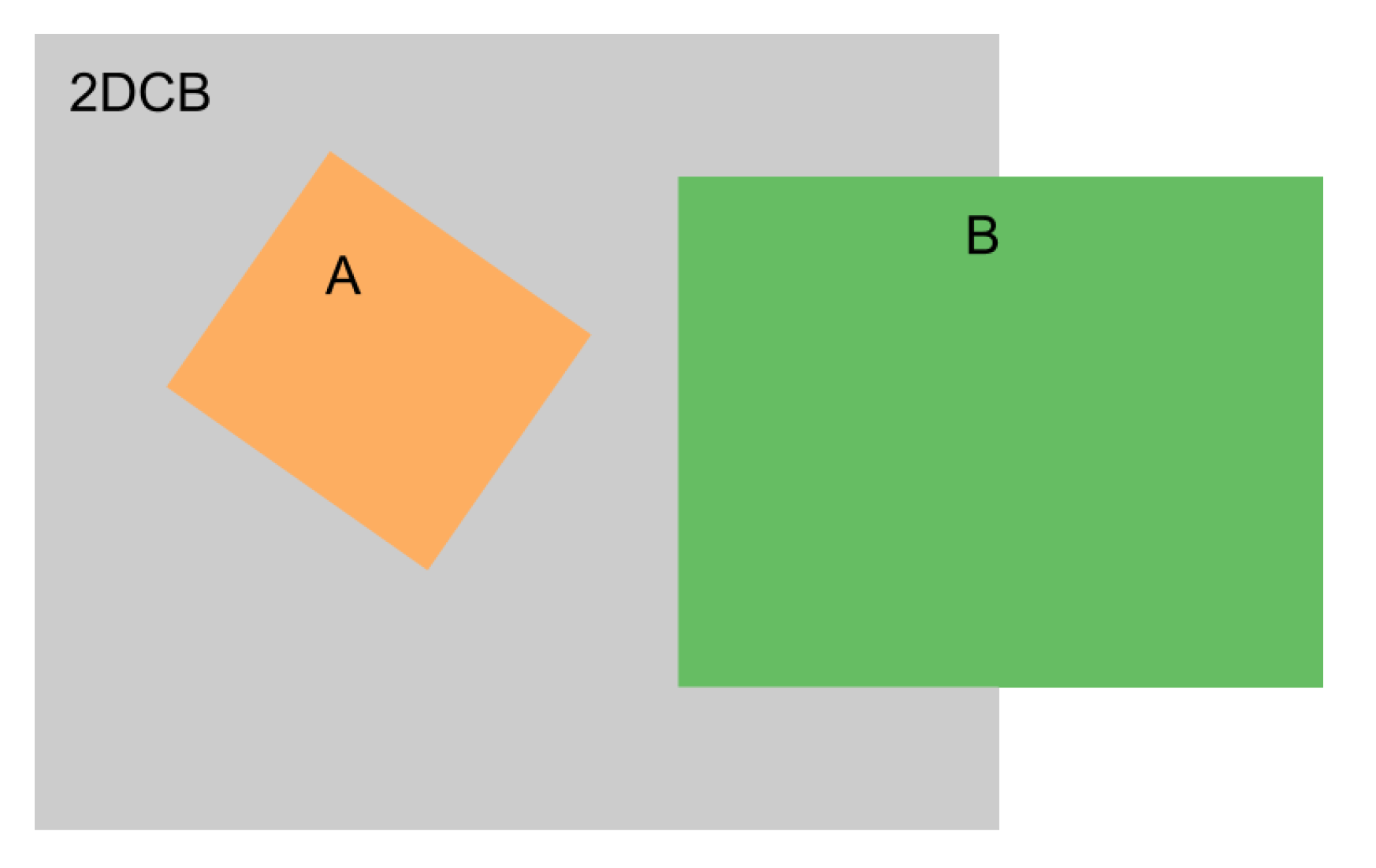
3.3.1. 3D Cropped Box (3DCB) and 3D Intersection over Itself (IoI)
3.3.2. Generating 3DCBs Using an IoI Metric and Frustum Voxelization Based on 3DCBs
3.4. Double Frustum Method
3.5. Multiple Scale Networks
3.6. 3D Object Detection
3.6.1. 3D Bounding Box Encoding
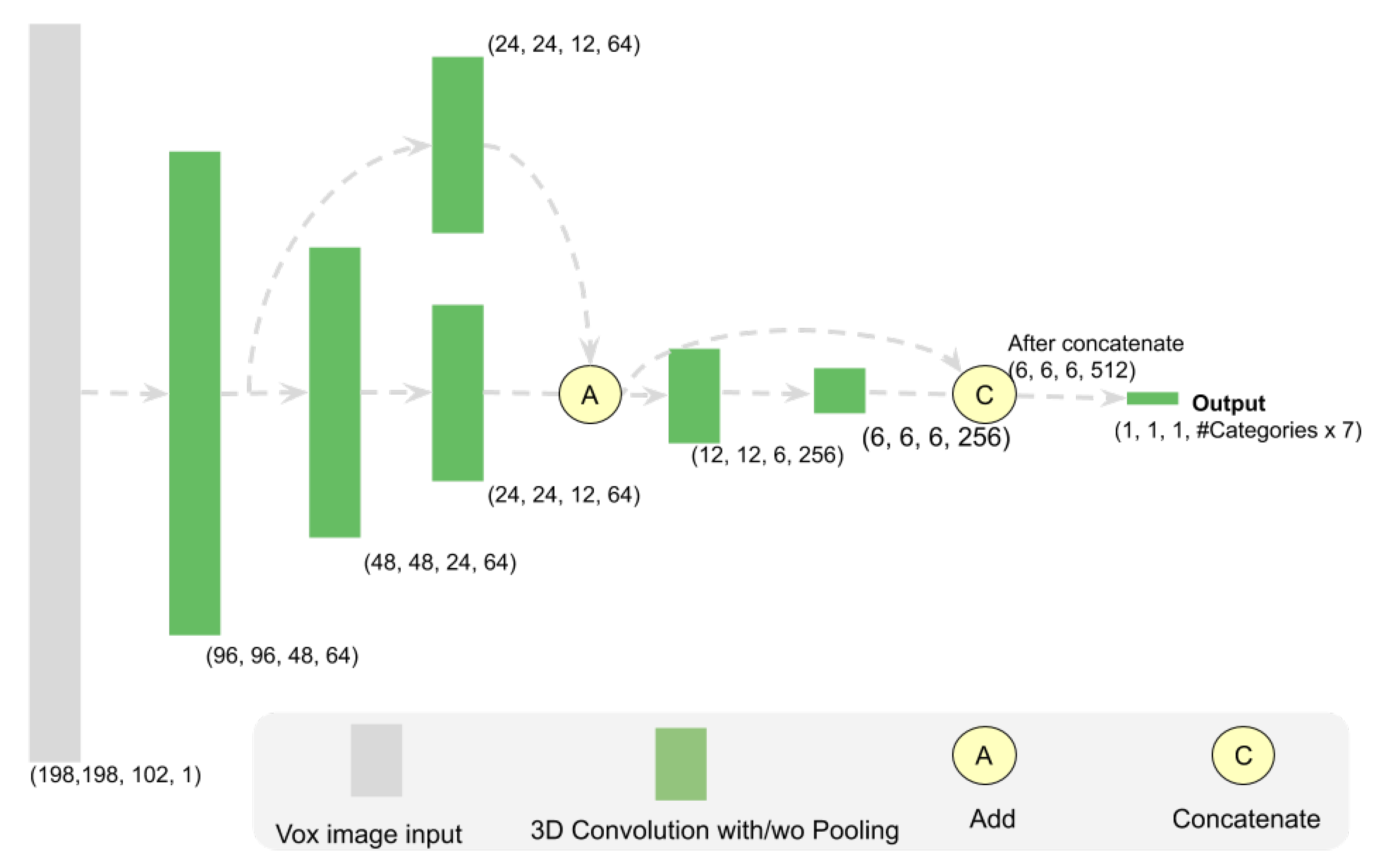
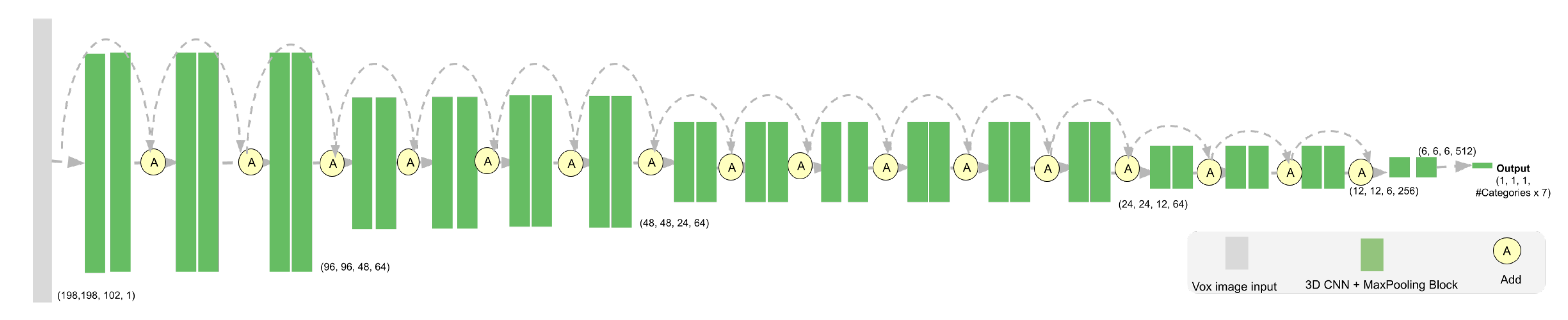
3.6.2. Detection Network Architecture
3.6.3. Loss Function
3.7. Training Process and Data Augmentation
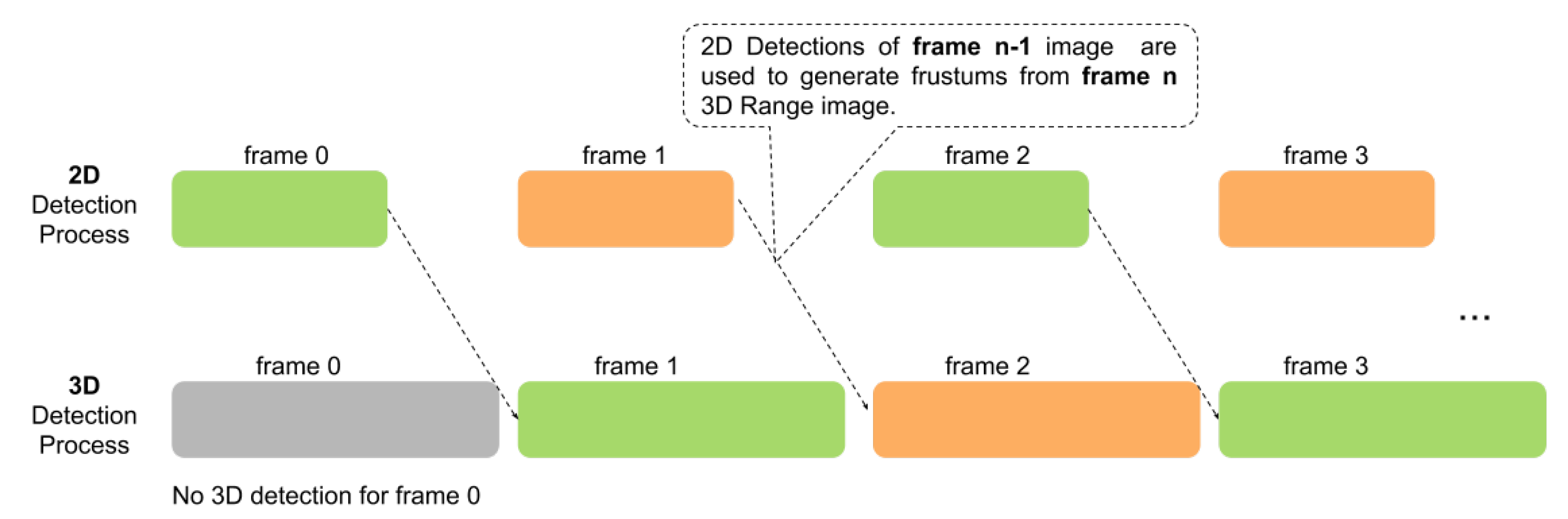
3.8. Efficiency Boost by Pipelining
3.9. Experimental Results for the Frustum VoxNet V1 System
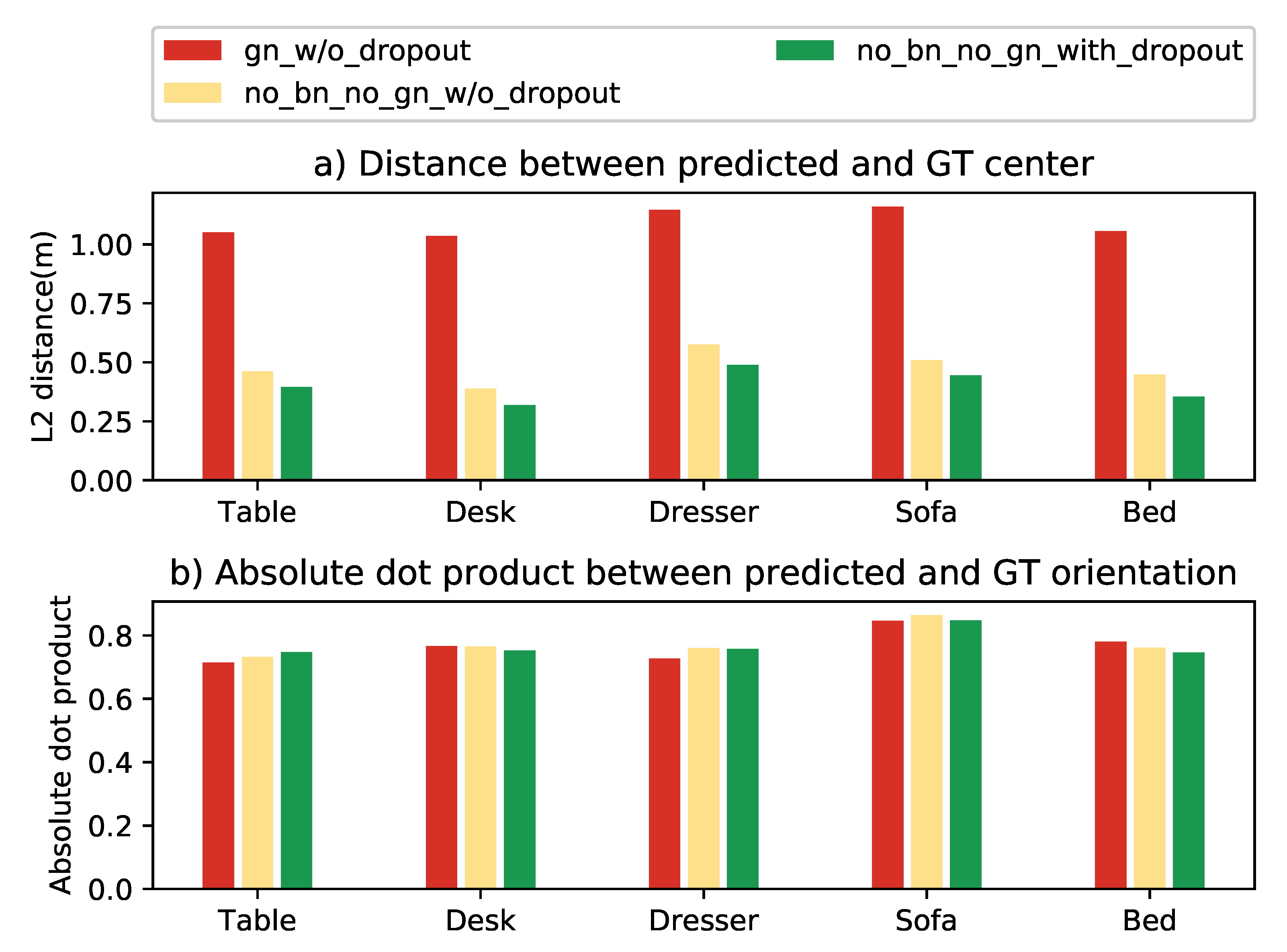
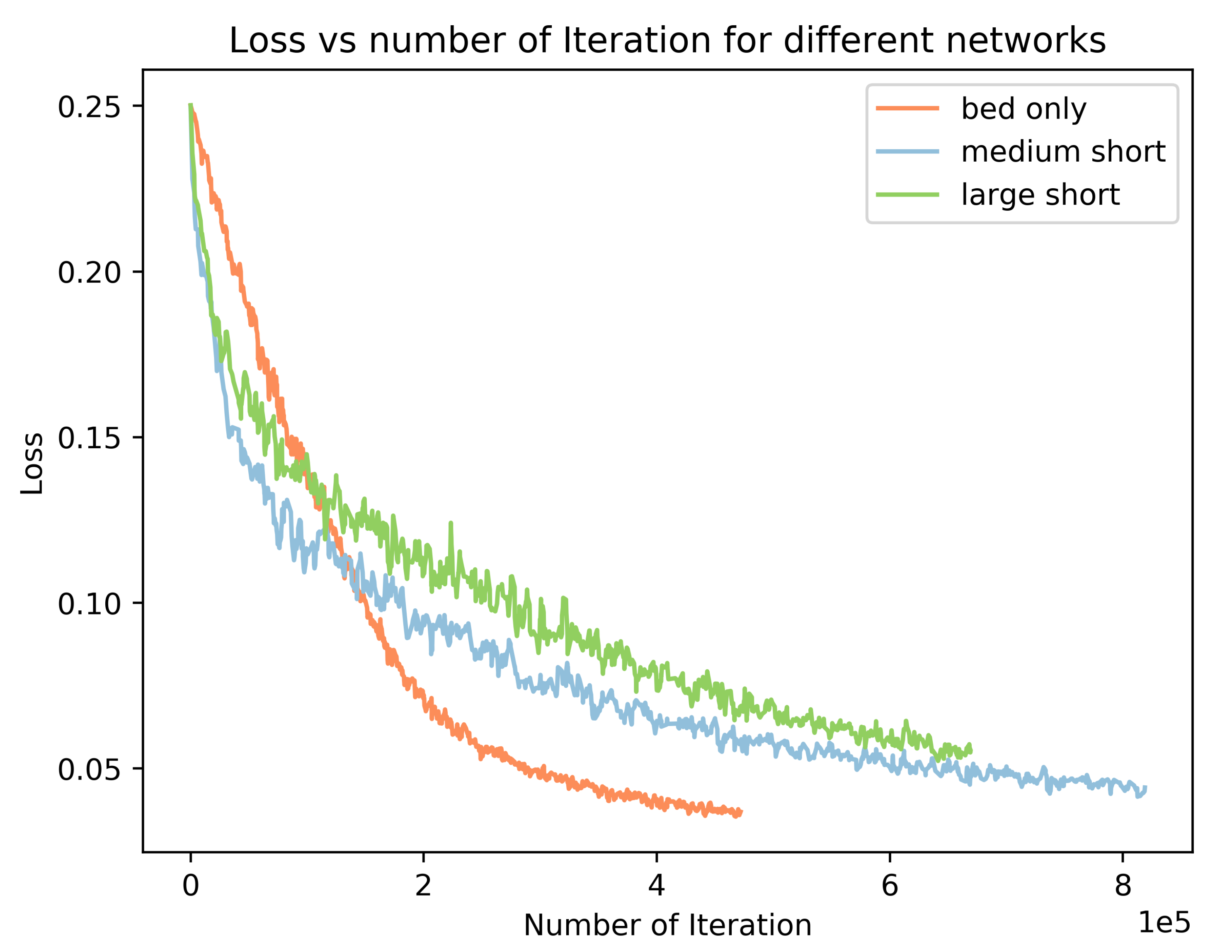
3.9.1. Effects of Batch Normalization, Group Normalization, and Dropout
3.9.2. Evaluation of the Whole System
3.10. Evaluate Frustum VoxNet Results Based on Ground Truth 2D Bounding Box
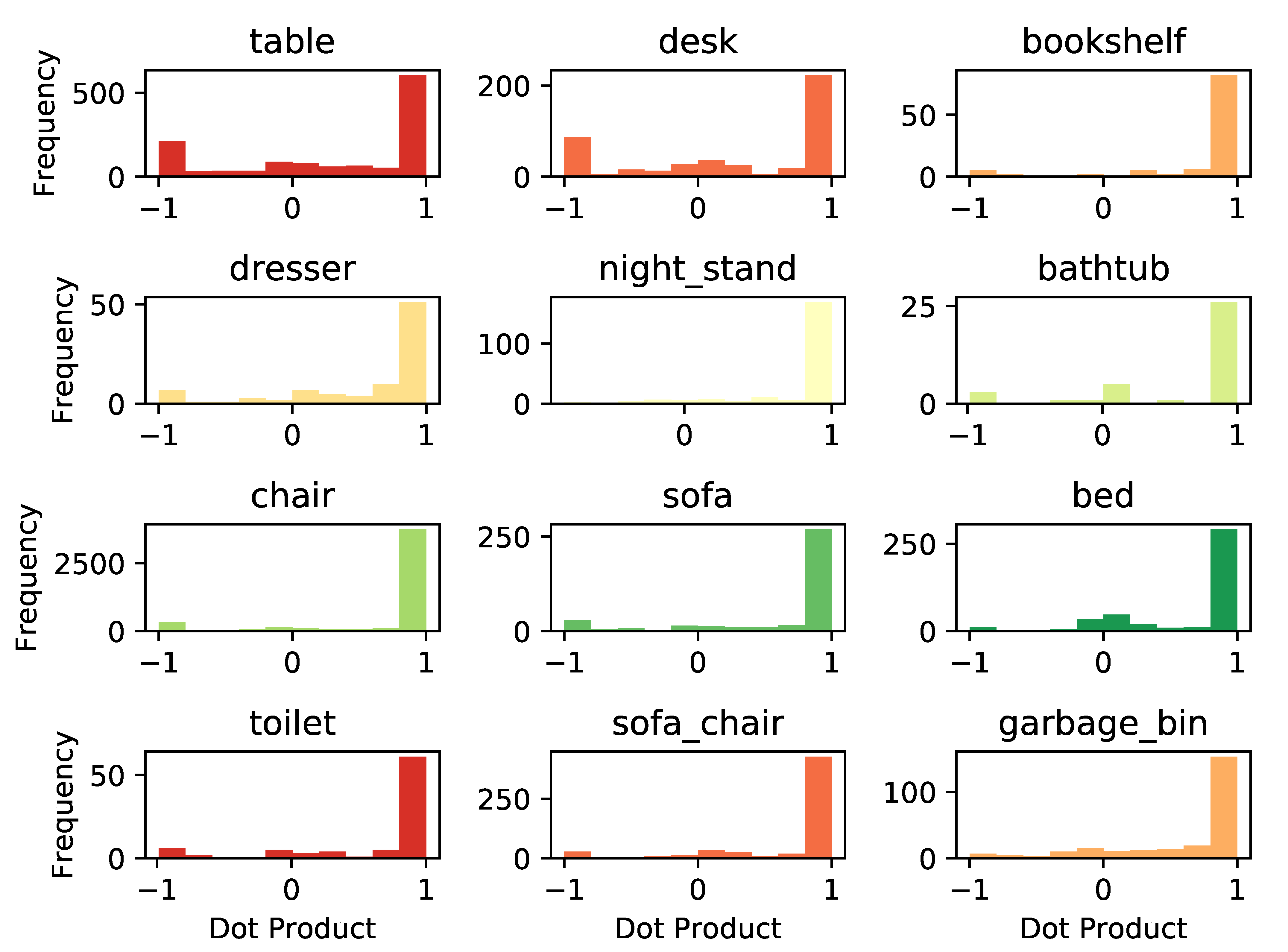
3.10.1. Orientation Results
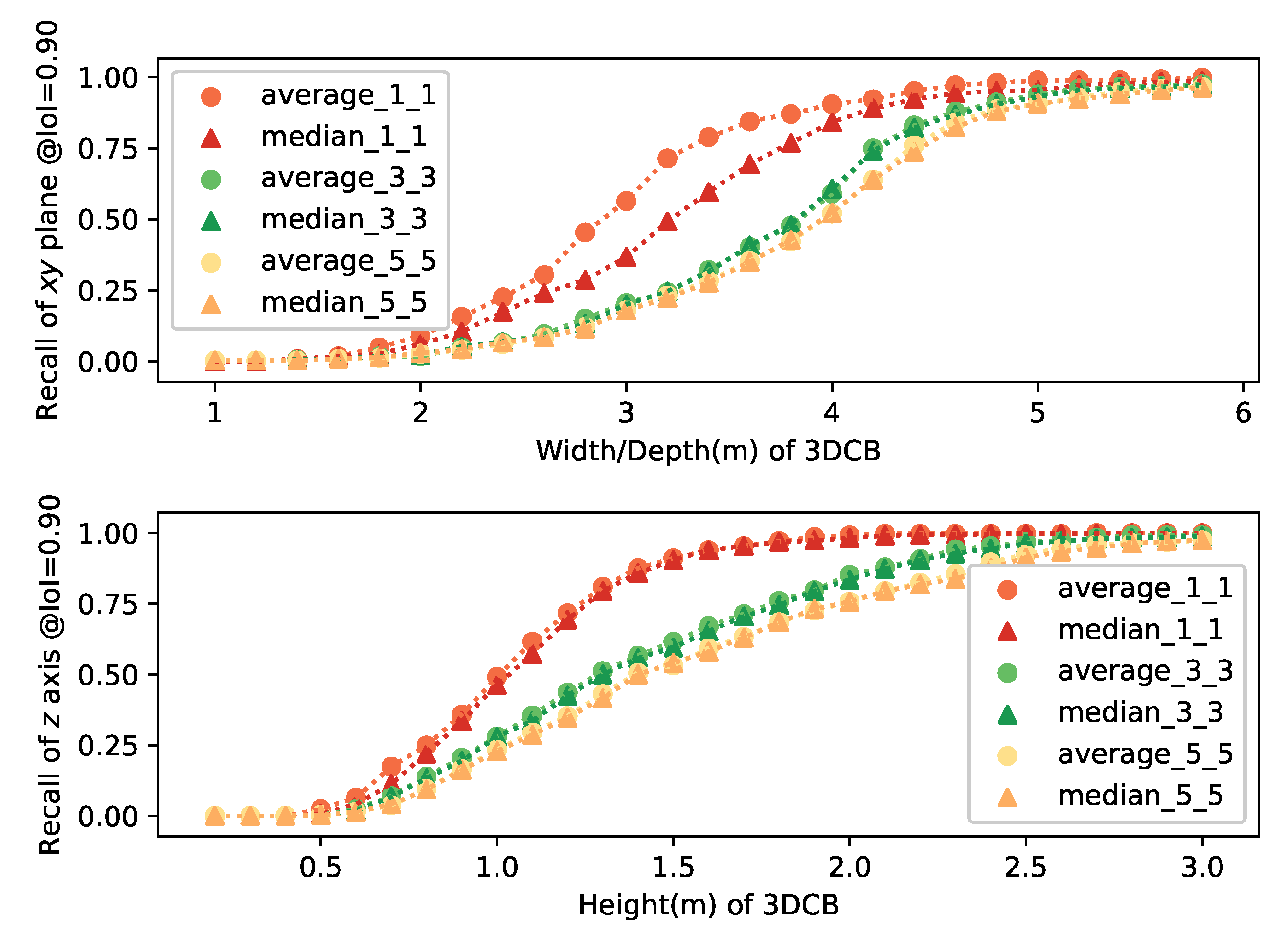
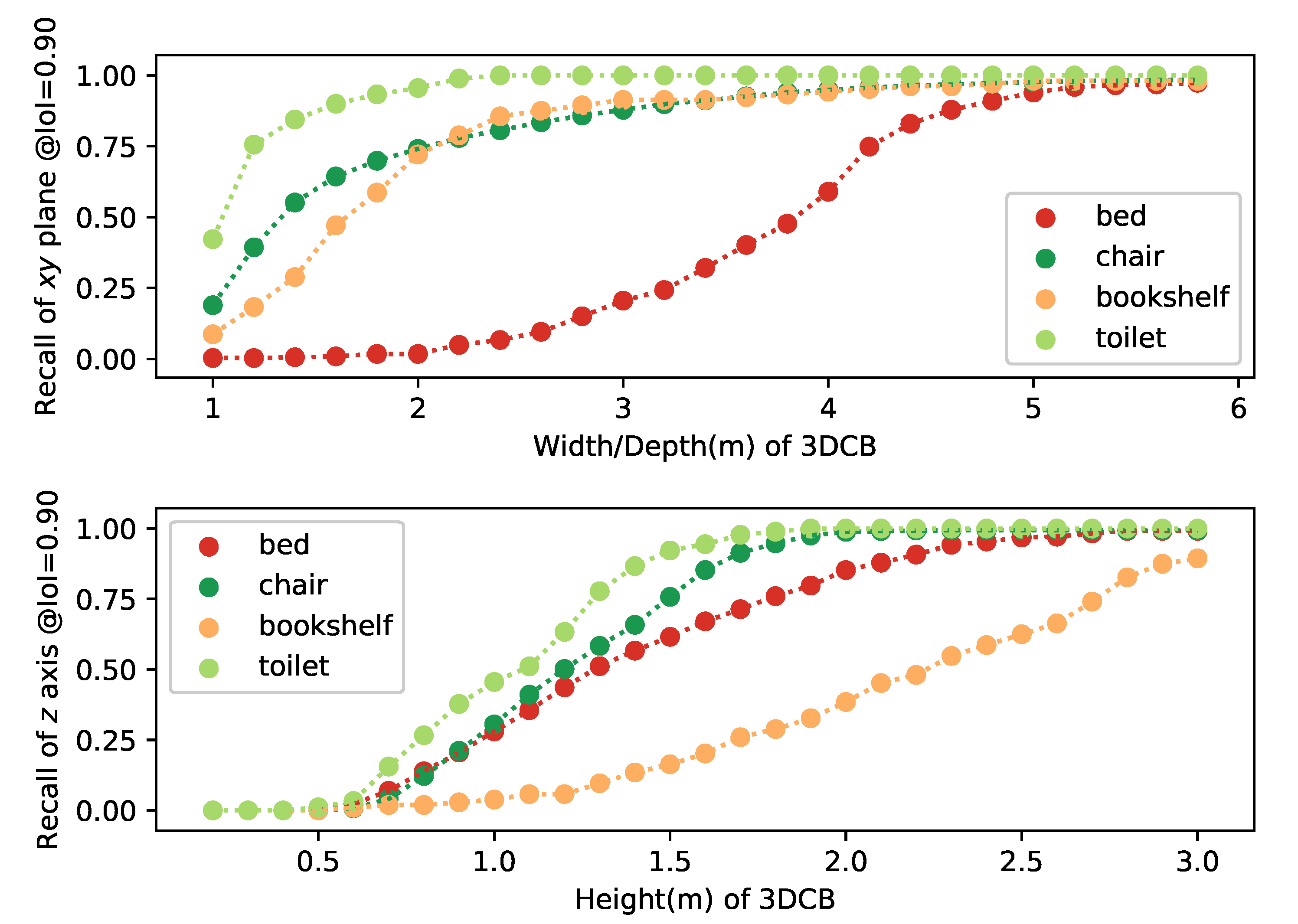
3.10.2. Bounding Box Center, Physical Size, and 3D Detection Results
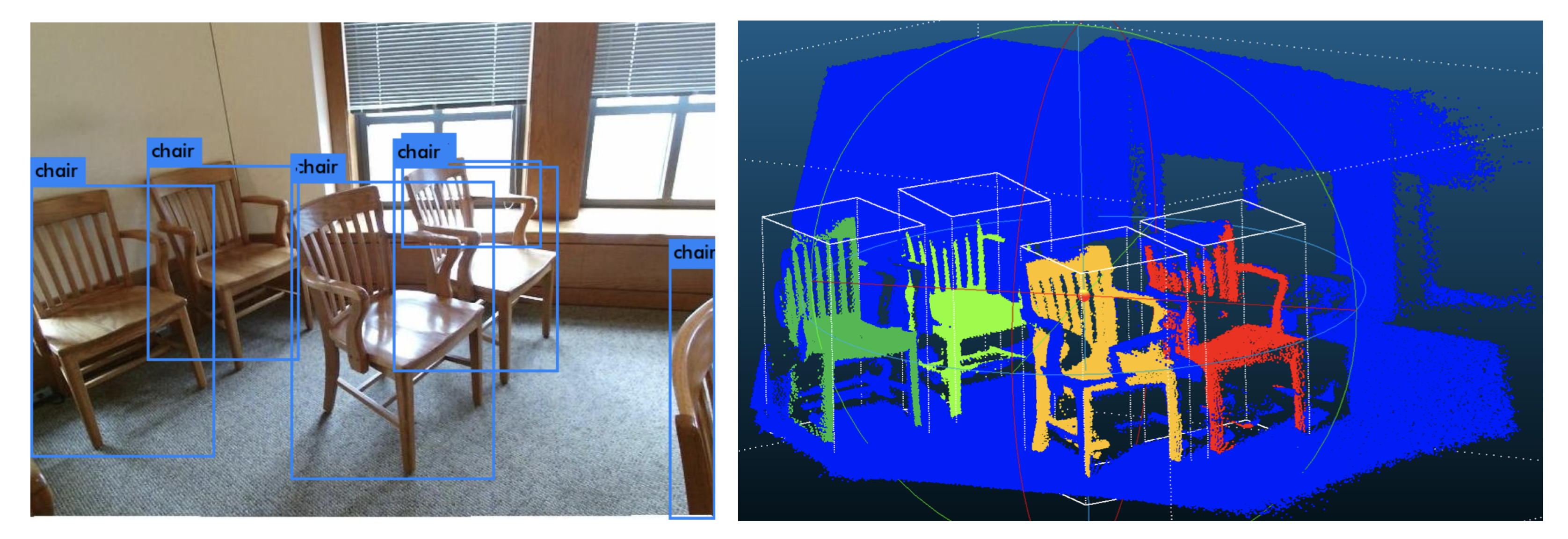
3.11. Visualizations of 2D and 3D Detection Results
4. 3D Instance Segmentation and Object Detection
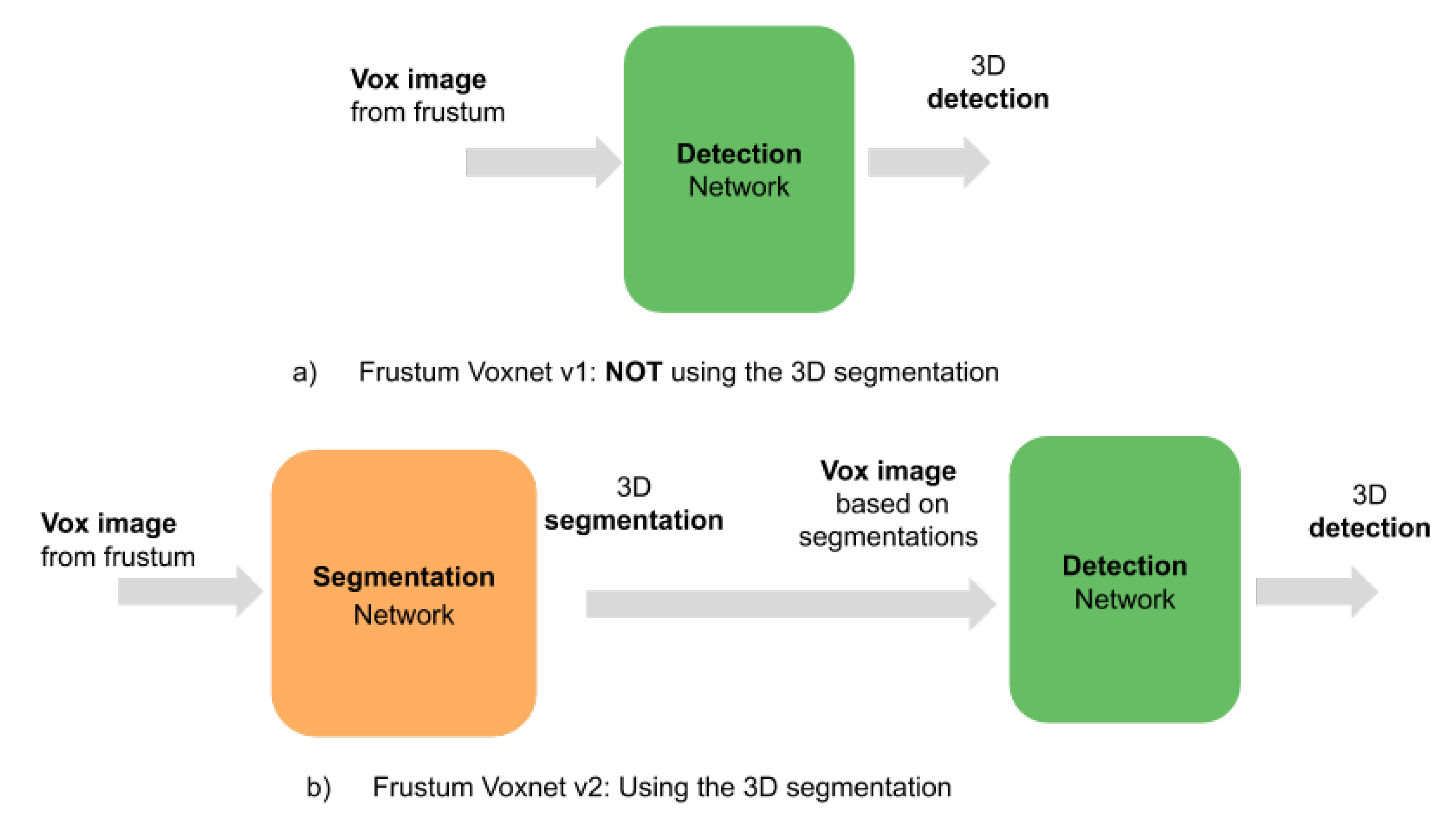
4.1. Overview of the Frustum VoxNet V2 System
4.2. 3D Instance Segmentation
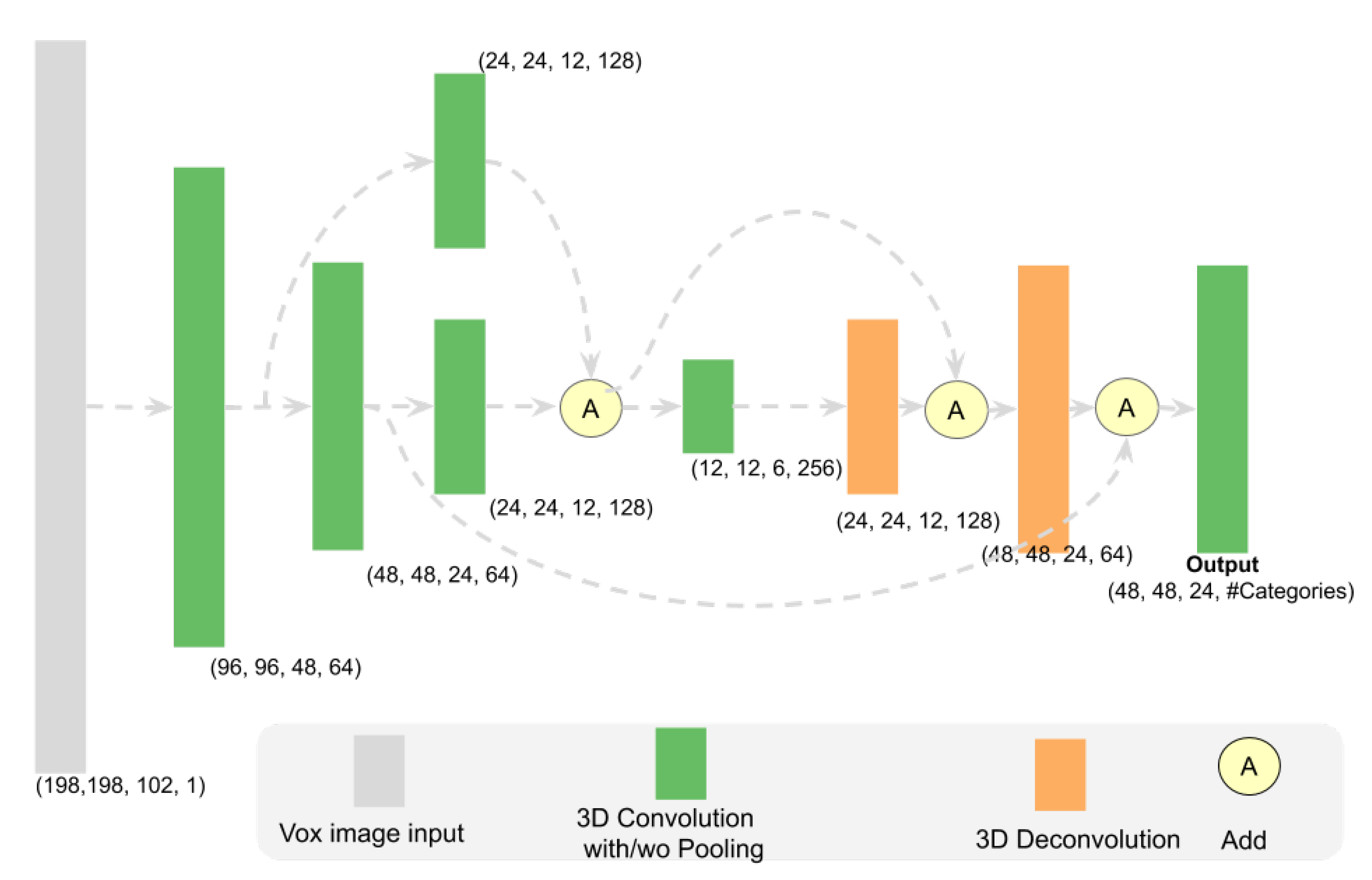
4.2.1. Instance Segmentation Network Architecture
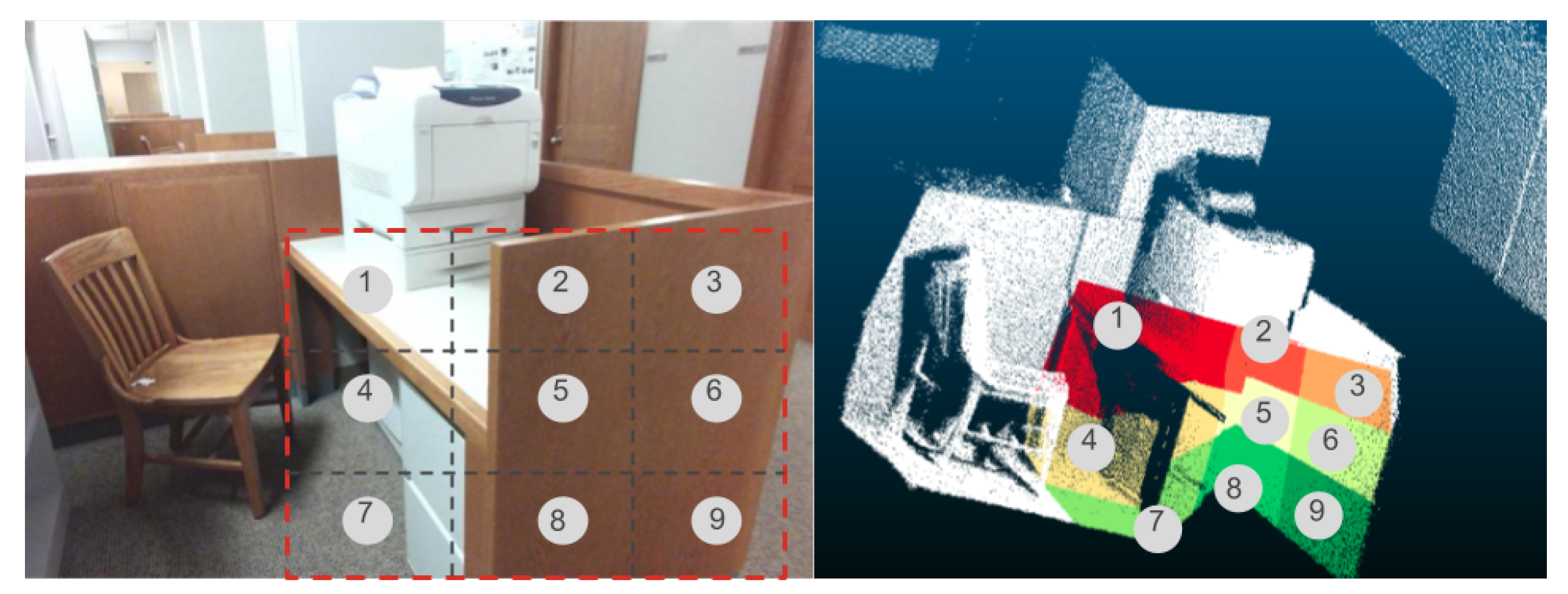
4.2.2. Segmentation Ground Truth Based on Voxelization
4.2.3. Segmentation Loss Function
4.3. 3D Object Detection
4.3.1. 3D Object Detection Network Architecture and Loss Function
4.3.2. 3D Object Detection Network Inputs
4.4. Training Process
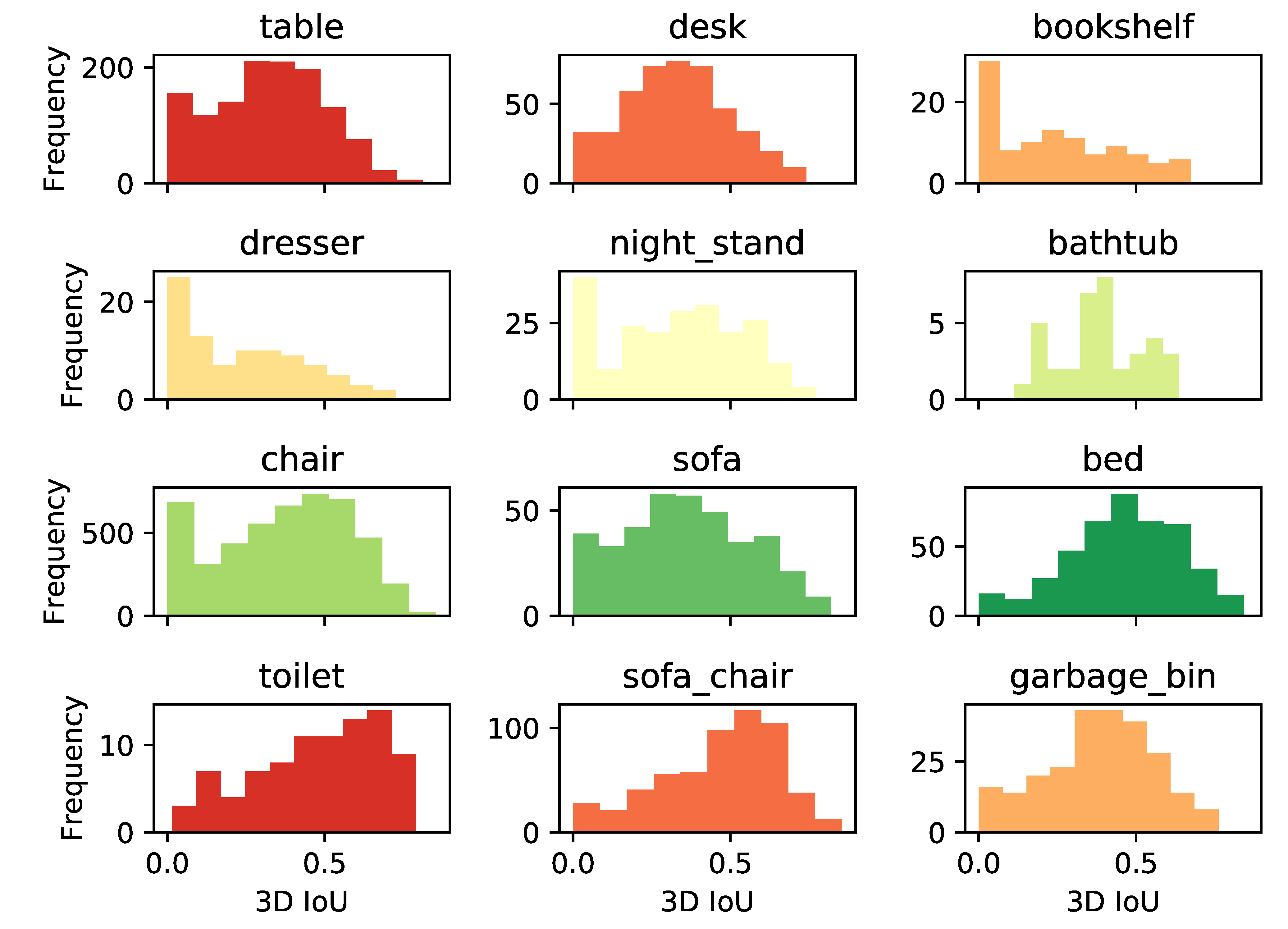
4.5. Evaluation of the Whole System
4.6. Visualizations of 3D Segmentation Results
4.7. Visualizations of 3D Detection Results Compared between V2 and V1
5. Conclusions
- We have significantly improved efficiency with respect to the state-of-the-art in 3D detection, as you can see in Table 4 and Table 10. Our 3D detection without segmentation has been presented in [14]. In this paper, we provide an enhanced system that performs both detection and segmentation. That improves the detection performance, as shown in Table 10, and it also includes instance segmentation results. The increased space and time efficiency makes our method appropriate for real-time robotic applications.
- We are able to provide accurate detection and segmentation results using depth only images, unlike competing methods such as [9], as you can see in Table 4 and Table 10. This is significant, since our methods can also work well in low lighting conditions, or with sensors that do not acquire RGB images.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 3DBBOX | 3D Bounding Box |
| 3DCB | 3D Cropped Box |
| BEV | Bird’s Eye View |
| BN | Batch Normalization |
| CNN | Convolutional Neural Network |
| DHS | Depth Height and Signed angle |
| FCN | Fully Convolutional Neural Network |
| FPN | Feature Pyramid Network |
| GN | Group Normalization |
| IoI | Intersection over Itself |
| IoU | Intersection over Union |
| SGD | Stochastic Gradient Descent |
| YOLO | You Only Look Once |
References
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. CoRR 2013, arXiv:1311.2524. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision ( ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature pyramid networks for object detection. CoRR 2016, arXiv:1612.03144. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. CoRR 2017, arXiv:1703.06870. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wei, Z.; Wang, Y.; Yi, H.; Chen, Y.; Wang, G. Semantic 3D reconstruction with learning MVS and 2D segmentation of aerial images. Appl. Sci. 2020, 10, 1275. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection From RGB-D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, L.C.; Hermans, A.; Papandreou, G.; Schroff, F.; Wang, P.; Adam, H. MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zelener, A.; Stamos, I. CNN-Based Object Segmentation in Urban LIDAR with Missing Points. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford University, CA, USA, 25–28 October 2016; pp. 417–425. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar] [CrossRef] [Green Version]
- Shen, X.; Stamos, I. Frustum VoxNet for 3D object detection from RGB-D or Depth images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Aspen, CO, USA, 1–5 March 2020. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. CoRR 2015, arXiv:11506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. CoRR 2016, arXiv:1612.08242. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. CoRR 2017, arXiv:11708.02002. [Google Scholar]
- Shi, W.; Bao, S.; Tan, D. FFESSD: An accurate and efficient single-shot detector for target detection. Appl. Sci. 2019, 9, 4276. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 8 December 2020).
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. CoRR 2014, arXiv:1405.0312. [Google Scholar]
- Murthy, C.; Hashmi, M.; Bokde, N.; Geem, Z. Investigations of Object Detection in Images/Videos Using Various Deep Learning Techniques and Embedded Platforms—A Comprehensive Review. Appl. Sci. 2020, 9, 3280. [Google Scholar] [CrossRef]
- Shen, X. A survey of Object Classification and Detection based on 2D/3D data. arXiv 2019, arXiv:1905.12683. [Google Scholar]
- Gupta, S.; Girshick, R.B.; Arbelaez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. CoRR 2014, arXiv:1407.5736. [Google Scholar]
- Stamos, I.; Hadjiliadis, O.; Zhang, H.; Flynn, T. Online Algorithms for Classification of Urban Objects in 3D Point Clouds. In Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 332–339. [Google Scholar] [CrossRef]
- Lahoud, J.; Ghanem, B. 2D-Driven 3D Object Detection in RGB-D Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep Hough Voting for 3D Object Detection in Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. CoRR 2016, arXiv:1611.07759. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S. Joint 3D Proposal Generation and Object Detection from View Aggregation. arXiv 2017, arXiv:1712.02294. [Google Scholar]
- Wu, Y.; Qin, H.; Liu, T.; Liu, H.; Wei, Z. A 3D object detection based on multi-modality sensors of USV. Appl. Sci. 2019, 9, 535. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Xiao, J. Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images. CoRR 2015, arXiv:1511.02300. [Google Scholar]
- Zhao, K.; Liu, L.; Meng, Y.; Gu, Q. Feature deep continuous aggregation for 3D vehicle detection. Appl. Sci. 2019, 9, 5397. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. CoRR 2015, arXiv:1512.03385. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. CoRR 2014, arXiv:1411.4038. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning; Proceedings of Machine Learning Research. Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. CoRR 2018, arXiv:abs/1803.08494. [Google Scholar]
- Ensemble Learning. Available online: https://en.wikipedia.org/wiki/Ensemble_learning (accessed on 10 November 2020).
- Ren, Z.; Sudderth, E.B. Three-Dimensional Object Detection and Layout Prediction Using Clouds of Oriented Gradients. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1525–1533. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Short () | Tall () | |
|---|---|---|
| Small () | toilet | N/A |
| Medium () | chair, nightstand, sofa chair, garbage bin, bathtub | bookshef |
| Large () | table, desk, sofa, bed, dresser | N/A |
| Method | Network | 3DCB Physical Size (m) | 3DCB Shape | Resolution (cm) |
|---|---|---|---|---|
| DSS [30] | RPN | |||
| Detection (bed) | ||||
| Detection (trash can) | ||||
| Ours | small short | |||
| medium short | ||||
| large short | ||||
| medium tall |
| Bed | Toilet | Night Stand | Bathtub | Chair | Dresser | Sofa | Table | Desk | Bookshelf | Sofa Chair | Kitchen Counter | Kitchen Cabinet | Garbage Bin | Microwave | Sink | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RGB-D RCNN [23] (RGB-D) | 76.0 | 69.8 | 37.1 | 49.6 | 41.2 | 31.3 | 42.2 | 43.0 | 16.6 | 34.9 | N/A | N/A | N/A | 46.8 | N/A | 41.9 |
| 2D-driven [25] (RGB) | 74.5 | 86.2 | 49.5 | 45.5 | 53.0 | 29.4 | 49.0 | 42.3 | 22.3 | 45.7 | N/A | N/A | N/A | N/A | N/A | N/A |
| Frustum PointNets [9] (RGB) | 56.7 | 43.5 | 37.2 | 81.3 | 64.1 | 33.3 | 57.4 | 49.9 | 77.8 | 67.2 | N/A | N/A | N/A | N/A | N/A | N/A |
| OURS (RGB) | 81.0 | 89.5 | 35.1 | 50.0 | 52.4 | 21.9 | 53.1 | 37.7 | 18.3 | 40.4 | 47.8 | 22.0 | 29.8 | 52.8 | 39.7 | 31.0 |
| OURS (D) | 78.7 | 77.6 | 34.2 | 51.9 | 51.8 | 16.5 | 48.5 | 34.9 | 14.2 | 19.2 | 48.7 | 19.1 | 18.5 | 30.3 | 22.2 | 30.1 |
| Bed | Toilet | Night Stand | Bathtub | Chair | Dresser | Sofa | Table | Desk | Bookshelf | Sofa Chair | Garbage Bin | Frustum Proposal Runtime | 3D Detection Runtime | Total Runtime | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DSS [30] (RGB-D) | 78.8 | 78.9 | 15.4 | 44.2 | 61.2 | 6.4 | 53.5 | 50.3 | 20.5 | 11.9 | N/A | N/A | N/A | N/A | 19.55 s |
| COG [38] (RGB-D) | 63.7 | 70.1 | 27.4 | 58.3 | 62.2 | 15.5 | 51.0 | 51.3 | 45.2 | 31.8 | N/A | N/A | N/A | N/A | 10–30 min |
| 2D-driven [25] (RGB-D) | 64.5 | 80.4 | 41.9 | 43.5 | 48.3 | 15.5 | 50.4 | 37.0 | 27.9 | 31.4 | N/A | N/A | N/A | N/A | 4.15 s |
| Frustum PointNets [9] (RGB-D) | 81.1 | 90.0 | 58.1 | 43.3 | 64.2 | 32.0 | 61.1 | 51.1 | 24.7 | 33.3 | N/A | N/A | 60 ms | 60 ms | 0.12 s |
| OURS RGB-D (FPN+3D ResNetFCN6 V1) | 78.5 | 84.5 | 34.5 | 42.4 | 47.2 | 18.2 | 40.3 | 30.4 | 12.4 | 18.0 | 47.1 | 47.6 | 110 ms | 48 ms | 0.16 s |
| OURS RGB-D (FPN+3D ResNetFCN35 V1) | 79.5 | 84.6 | 36.2 | 44.6 | 49.1 | 19.6 | 40.8 | 27.5 | 12.5 | 19.1 | 47.9 | 48.2 | 110 ms | 128 ms | 0.24 s |
| OURS Depth only (FPN+3D ResNetFCN6 V1) | 77.1 | 76.1 | 32.4 | 42.0 | 45.9 | 14.1 | 35.8 | 25.3 | 11.7 | 16.8 | 48.5 | 35.0 | 110 ms | 48 ms | 0.16 s |
| OURS Depth only (FPN+3D ResNetFCN35 V1) | 77.4 | 76.8 | 33.1 | 43.7 | 45.8 | 15.2 | 37.3 | 25.5 | 11.8 | 17.4 | 48.8 | 35.4 | 110 ms | 148 ms | 0.24 s |
| 2D Network | 3D Network | Bed | Toilet | Chair | Sofa | Table | |
|---|---|---|---|---|---|---|---|
| 2D Detection | FPN | 81.0 | 89.5 | 52.4 | 53.1 | 37.7 | |
| YOLO v3 | 71.8 | 73.7 | 38.5 | 51.4 | 22.1 | ||
| 3D Detection | FPN | 3D ResNetFCN6 | 78.5 | 84.5 | 47.2 | 40.3 | 30.4 |
| YOLO v3 | 3D ResNetFCN6 | 66.9 | 69.8 | 30.1 | 37.9 | 18.8 |
| Methods | # Parameters | Runtime (ms) | |||
|---|---|---|---|---|---|
| —– | Frustum Proposal | 3D Detection | Frustum Proposal | 3D Detection | Total |
| Frustum PointNets (FPN + Pointnet V1) | 28 M | 19 M | 60 | 60 | 120 |
| Frustum PointNets (FPN + Pointnet V2) | 28 M | 22 M | 60 | 107 | 167 |
| Ours w/o Pipeline (FPN + 3D ResNetFCN6 V1) | 42 M | 2.5 M | 110 | 48 | 158 |
| Ours w/o Pipeline (FPN + 3D ResNetFCN35 V1) | 42 M | 23.5 M | 110 | 149 | 259 |
| Ours w/o Pipeline (YOLO v3 + 3D ResNetFCN6 V1) | N/A | 2.5 M | 29 | 48 | 77 |
| Ours with Pipeline (YOLO v3 + 3D ResNetFCN6 V1) | N/A | 2.5 M | 29 | 48 | 48 |
| Table | Frustum Average Center | −0.005 | −0.233 | 0.075 | 0.522 |
| Predicted from Frustum VoxNet | 0.014 | −0.040 | 0.030 | 0.395 | |
| Desk | Frustum Average Center | −0.010 | −0.198 | 0.109 | 0.428 |
| Predicted from Frustum VoxNet | 0.028 | −0.040 | 0.048 | 0.319 | |
| Sofa | Frustum Average Center | −0.015 | −0.168 | 0.010 | 0.516 |
| Predicted from Frustum VoxNet | 0.007 | 0.041 | 0.013 | 0.444 | |
| Bed | Frustum Average Center | 0.031 | −0.195 | 0.013 | 0.573 |
| Predicted from Frustum VoxNet | −0.009 | 0.010 | −0.012 | 0.354 |
| Category | Instance Number | Average 3D IoU | 3D Recall ([email protected]) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| table | 1269 | 0.201 | 0.280 | 0.070 | 0.395 | 0.206 | 0.132 | 0.042 | 0.287 | 0.747 | 0.319 | 0.656 |
| desk | 457 | 0.158 | 0.220 | 0.080 | 0.319 | 0.180 | 0.122 | 0.052 | 0.258 | 0.752 | 0.329 | 0.674 |
| dresser | 91 | 0.248 | 0.298 | 0.135 | 0.489 | 0.126 | 0.064 | 0.107 | 0.209 | 0.758 | 0.241 | 0.451 |
| sofa | 381 | 0.213 | 0.320 | 0.075 | 0.444 | 0.210 | 0.099 | 0.048 | 0.264 | 0.847 | 0.459 | 0.796 |
| bed | 441 | 0.195 | 0.220 | 0.096 | 0.354 | 0.154 | 0.125 | 0.083 | 0.246 | 0.746 | 0.462 | 0.898 |
| night stand | 220 | 0.156 | 0.226 | 0.069 | 0.314 | 0.050 | 0.037 | 0.044 | 0.087 | 0.830 | 0.329 | 0.655 |
| bathtub | 37 | 0.162 | 0.114 | 0.067 | 0.226 | 0.134 | 0.071 | 0.040 | 0.173 | 0.805 | 0.383 | 0.811 |
| chair | 4777 | 0.118 | 0.217 | 0.067 | 0.286 | 0.038 | 0.048 | 0.047 | 0.089 | 0.886 | 0.369 | 0.708 |
| sofa chair | 575 | 0.109 | 0.168 | 0.070 | 0.242 | 0.058 | 0.051 | 0.045 | 0.103 | 0.840 | 0.466 | 0.849 |
| garbage bin | 248 | 0.065 | 0.098 | 0.050 | 0.145 | 0.043 | 0.035 | 0.042 | 0.082 | 0.760 | 0.384 | 0.782 |
| toilet | 87 | 0.051 | 0.093 | 0.073 | 0.148 | 0.028 | 0.039 | 0.047 | 0.076 | 0.825 | 0.498 | 0.929 |
| bookshelf | 106 | 0.183 | 0.303 | 0.130 | 0.433 | 0.410 | 0.063 | 0.149 | 0.474 | 0.880 | 0.345 | 0.679 |
| Network | 3DCB Physical Size (m) | Input 3DCB Shape | Output Tensor Shape |
|---|---|---|---|
| small short | |||
| medium short | |||
| large short | |||
| medium tall |
| Bed | Toilet | Night Stand | Bathtub | Chair | Dresser | Sofa | Table | Desk | Bookshelf | Average mAP | Frustum Proposal Runtime | 3D Detection Runtime | Total Runtime | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Frustum PointNets [9] (RGB-D) | 81.1 | 90.0 | 58.1 | 43.3 | 64.2 | 32.0 | 61.1 | 51.1 | 24.7 | 33.3 | 53.4 | 60 ms | 60 ms | 0.12 s |
| OURS RGB-D (FPN+3D ResNetFCN6 V1) | 78.5 | 84.5 | 34.5 | 42.4 | 47.2 | 18.2 | 40.3 | 30.4 | 12.4 | 18.0 | 40.6 | 110 ms | 48 ms | 0.16 s |
| OURS RGB-D (FPN+3D ResNetFCN6 V2) | 79.9 | 91.6 | 38.8 | 56.7 | 48.1 | 22.3 | 43.2 | 34.1 | 15.1 | 19.8 | 45.0 | 110 ms | 100 ms | 0.21 s |
| OURS Depth only (FPN+3D ResNetFCN6 V1) | 77.1 | 76.1 | 32.4 | 42.0 | 45.9 | 14.1 | 35.8 | 25.3 | 11.7 | 16.8 | 37.7 | 110 ms | 48 ms | 0.16 s |
| OURS Depth only (FPN+3D ResNetFCN6 V2) | 78.6 | 89.0 | 37.2 | 45.7 | 46.3 | 20.3 | 37.0 | 32.5 | 12.9 | 17.7 | 41.7 | 110ms | 100 ms | 0.21 s |
| Methods | # Parameters | Runtime (ms) | ||||
|---|---|---|---|---|---|---|
| —– | Frustum Proposal | 3D Detection | Frustum Proposal | 3D Instance Segmentation | 3D Detection | Total |
| Frustum PointNets [9] (FPN + Pointnet V1) | 28 M | 19 M | 60 | - | 60 | 120 |
| Frustum PointNets [9] (FPN + Pointnet V2) | 28 M | 22 M | 60 | 88 | 19 | 167 |
| Ours w/o Pipeline (FPN + 3D ResNetFCN6 V1) | 42 M | 2.5 M | 110 | - | 48 | 158 |
| Ours w/o Pipeline (FPN + 3D ResNetFCN6 V2) | 42 M | 5.5 M | 110 | 52 | 48 | 210 |
| Ours w/o Pipeline (YOLO v3 + 3D ResNetFCN6 V1) | N/A | 2.5 M | 29 | - | 48 | 77 |
| Ours with Pipeline (YOLO v3 + 3D ResNetFCN6 V1) | N/A | 2.5 M | 29 | - | 48 | 48 |
| Ours w/o Pipeline (YOLO v3 + 3D ResNetFCN6 V2) | N/A | 5.5 M | 29 | 52 | 48 | 129 |
| Ours with Pipeline (YOLO v3 + 3D ResNetFCN6 V2) | N/A | 5.5 M | 29 | 52 | 48 | 52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, X.; Stamos, I. 3D Object Detection and Instance Segmentation from 3D Range and 2D Color Images. Sensors 2021, 21, 1213. https://doi.org/10.3390/s21041213
Shen X, Stamos I. 3D Object Detection and Instance Segmentation from 3D Range and 2D Color Images. Sensors. 2021; 21(4):1213. https://doi.org/10.3390/s21041213
Chicago/Turabian StyleShen, Xiaoke, and Ioannis Stamos. 2021. "3D Object Detection and Instance Segmentation from 3D Range and 2D Color Images" Sensors 21, no. 4: 1213. https://doi.org/10.3390/s21041213
APA StyleShen, X., & Stamos, I. (2021). 3D Object Detection and Instance Segmentation from 3D Range and 2D Color Images. Sensors, 21(4), 1213. https://doi.org/10.3390/s21041213