
A Joint 2D-3D Complementary Network for Stereo Matching

 , ,
, ,
Abstract
:1. Introduction
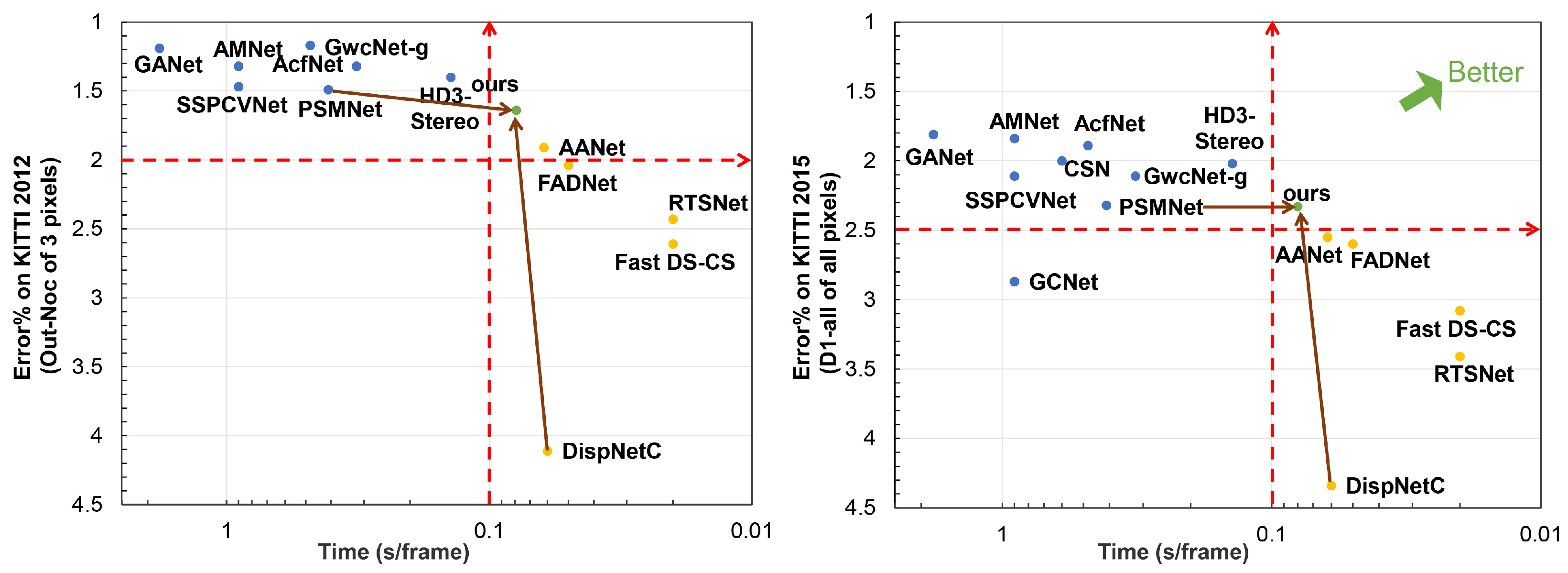
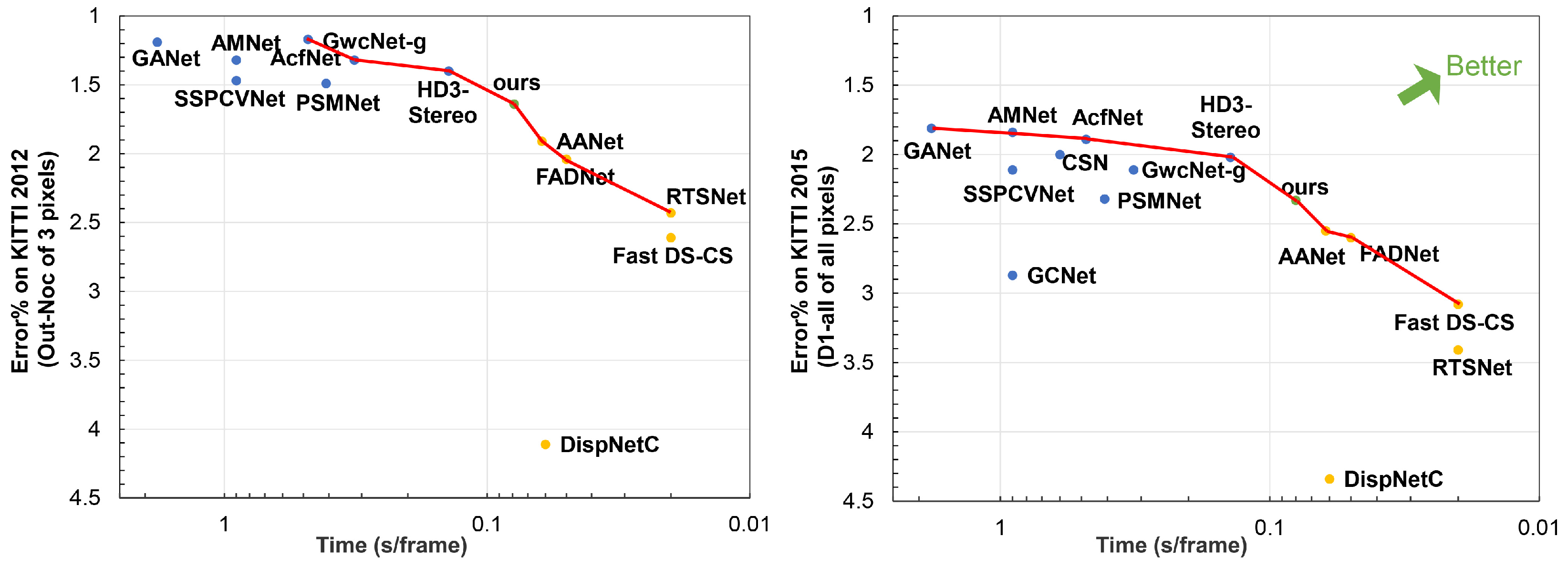
- We propose a complementary stereo method by integrating the advantages of 2D and 3D stereo networks. Our network can improve the accuracy of the 2D network and reduce the running time for the 3D network.
- We propose a fast and accurate stereo network, which can quickly generate an accurate disparity result in 80 ms.
2. Related Work
3. Method
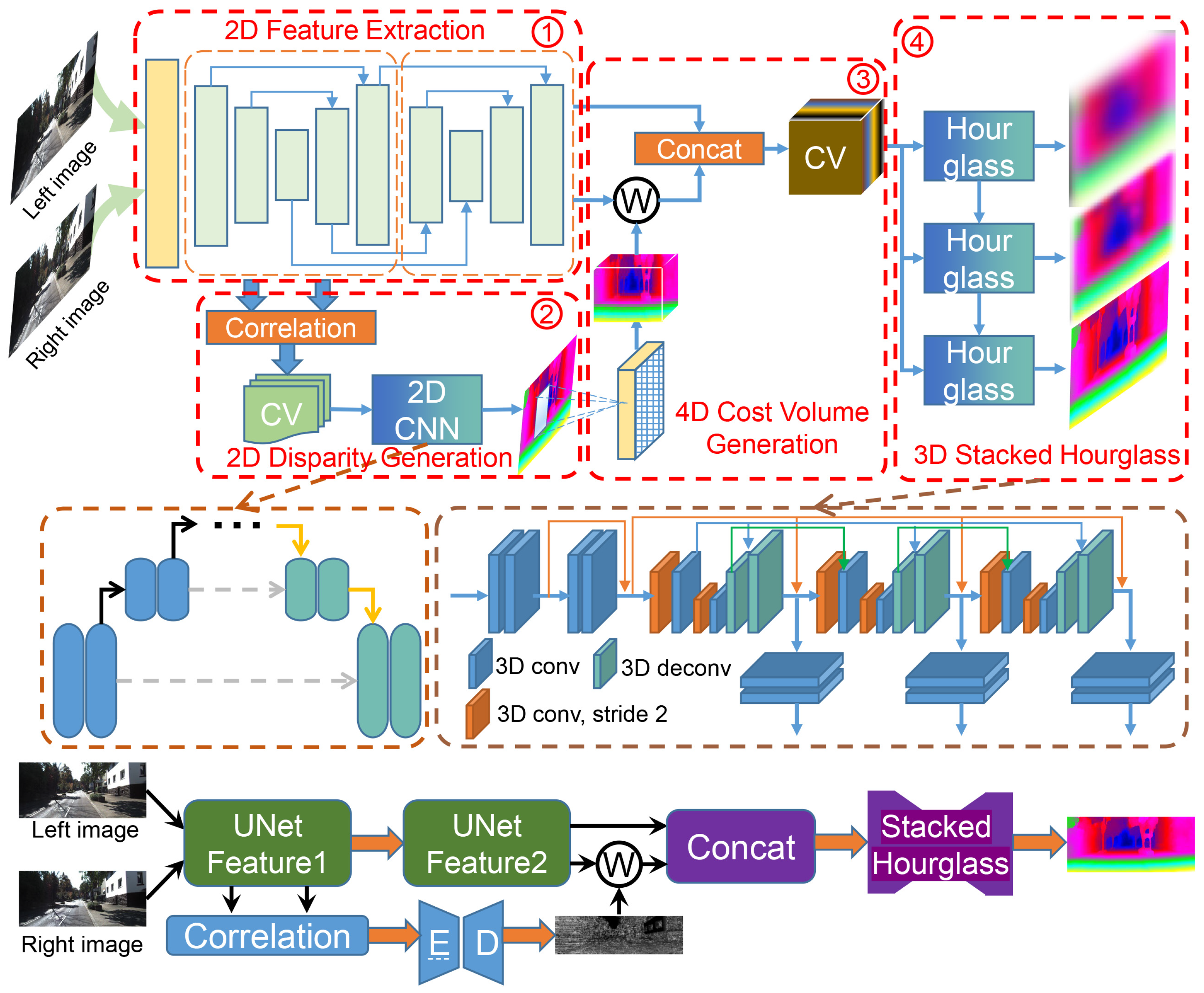
3.1. Network Architecture
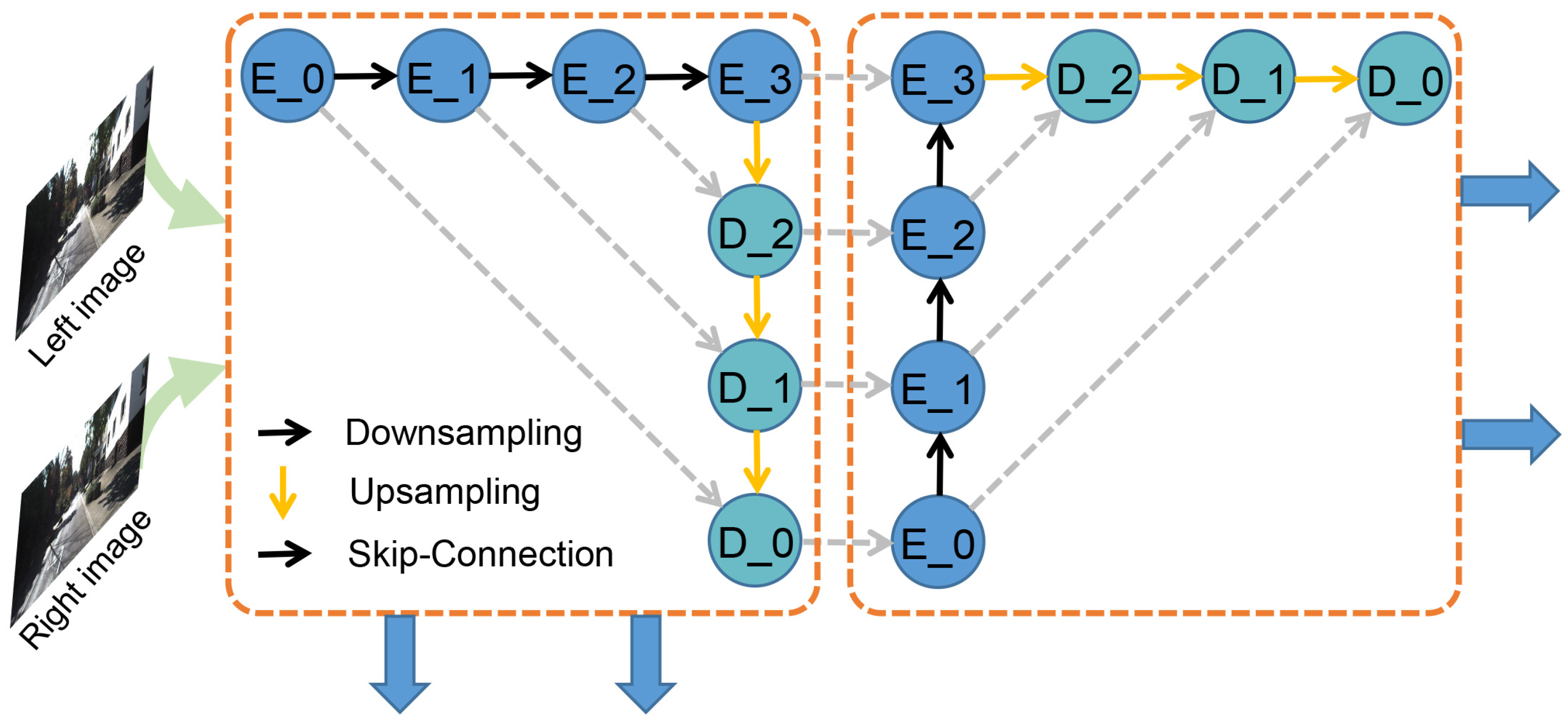
3.2. 2D Feature Extraction Module
3.3. 2D Disparity Generation Module
3.4. 4D Cost Volume Generation Module
| Algorithm 1 Calculating the disparity range. |
| Input: |
| Rough disparity map generated by 2D network: ; |
| Output: |
| Disparity range: ; |
| 1: Initialize: |
| Downsample the input to 1/4 resolution by bilinear interpolation: ; |
| 2: |
| 3: |
| 4: Use the threshold to adjust the disparity range: |
| 5: |
| 6: |
| 7: Upsample the output to original resolution by trilinear interpolation: |
| 8 |
3.5. 3D Stacked Hourglass Module
3.6. Disparity Regression
3.7. Loss Function
4. Experiments
4.1. Network Settings and Details
4.2. Results on Scene Flow
4.3. Results on KITTI
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, P.; Chen, X.; Shen, S. Stereo r-cnn based 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7644–7652. [Google Scholar]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3d reconstruction in real-time. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 963–968. [Google Scholar]
- Kao, C.Y.; Fahn, C.S. A human-machine interaction technique: Hand gesture recognition based on hidden Markov models with trajectory of hand motion. Procedia Eng. 2011, 15, 3739–3743. [Google Scholar] [CrossRef] [Green Version]
- Łuczyński, T.; Łuczyński, P.; Pehle, L.; Wirsum, M.; Birk, A. Model based design of a stereo vision system for intelligent deep-sea operations. Measurement 2019, 144, 298–310. [Google Scholar] [CrossRef]
- Bajracharya, M.; Maimone, M.W.; Helmick, D. Autonomy for mars rovers: Past, present, and future. Computer 2008, 41, 44–50. [Google Scholar] [CrossRef] [Green Version]
- Hrabar, S.; Sukhatme, G.S.; Corke, P.; Usher, K.; Roberts, J. Combined optic-flow and stereo-based navigation of urban canyons for a UAV. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 3309–3316. [Google Scholar]
- Zeng, K.; Ning, M.; Wang, Y.; Guo, Y. Hierarchical clustering with hard-batch triplet loss for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, Seattle, DC, USA, 14–19 June 2020; pp. 13657–13665. [Google Scholar]
- Zeng, K.; Ning, M.; Wang, Y.; Guo, Y. Energy clustering for unsupervised person re-identification. Image Vis. Comput. 2020, 98, 103913. [Google Scholar] [CrossRef] [Green Version]
- Kanade, T.; Kano, H.; Kimura, S.; Yoshida, A.; Oda, K. Development of a video-rate stereo machine. In Proceedings of the 1995 IEEE/RSJ International Conference on Intelligent Robots and Systems, Human Robot Interaction and Cooperative Robots, Pittsburgh, PA, USA, 5–9 August 1995. [Google Scholar] [CrossRef]
- Kim, J.; Kolmogorov, Z. Visual correspondence using energy minimization and mutual information. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003. [Google Scholar] [CrossRef] [Green Version]
- Heo, Y.S.; Lee, K.M.; Lee, S.U. Mutual Information as a Stereo Correspondence Measure. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]
- Ma, L.; Li, J.; Ma, J.; Zhang, H. A Modified Census Transform Based on the Neighborhood Information for Stereo Matching Algorithm. In Proceedings of the 2013 Seventh International Conference on Image and Graphics, Qingdao, China, 26–28 July 2013. [Google Scholar] [CrossRef]
- Balk, Y.K.; Jo, J.H.; LEE, K.M. Fast Census Transform-based Stereo Algorithm using SSE2. In Proceedings of the 12th Korea-Japan Joint Workshop on Frontiers of Computer Vision, Tokushima, Japan, 2–3 February 2006; pp. 305–309. [Google Scholar]
- Gu, Z.; Su, X.; Liu, Y.; Zhang, Q. Local stereo matching with adaptive support-weight, rank transform and disparity calibration. Pattern Recognit. Lett. 2008, 29, 1230–1235. [Google Scholar] [CrossRef]
- Banks, J.; Bennamoun, M.; Kubik, K.; Corke, P. A constraint to improve the reliability of stereo matching using the rank transform. In Proceedings of the 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP99), Phoenix, AZ, USA, 15–19 March 1999. [Google Scholar] [CrossRef] [Green Version]
- Birchfield, S.; Tomasi, C. A pixel dissimilarity measure that is insensitive to image sampling. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 401–406. [Google Scholar] [CrossRef] [Green Version]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Xu, H.; Zhang, J. AANet: Adaptive Aggregation Network for Efficient Stereo Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, Seattle, DC, USA, 14–19 June 2020; pp. 1959–1968. [Google Scholar]
- Lee, H.; Shin, Y. Real-Time Stereo Matching Network with High Accuracy. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4280–4284. [Google Scholar]
- Wang, Q.; Shi, S.; Zheng, S.; Zhao, K.; Chu, X. FADNet: A Fast and Accurate Network for Disparity Estimation. arXiv 2020, arXiv:2003.10758. [Google Scholar]
- Yee, K.; Chakrabarti, A. Fast Deep Stereo with 2D Convolutional Processing of Cost Signatures. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 183–191. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4040–4048. [Google Scholar]
- Duggal, S.; Wang, S.; Ma, W.C.; Hu, R.; Urtasun, R. Deeppruner: Learning efficient stereo matching via differentiable patchmatch. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4384–4393. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, Seattle, DC, USA, 14–19 June 2020; pp. 2495–2504. [Google Scholar]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H. Ga-net: Guided aggregation net for end-to-end stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 185–194. [Google Scholar]
- Scharstein, D.; Szeliski, R.; Zabih, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. In Proceedings of the IEEE Workshop on Stereo and Multi-Baseline Vision (SMBV 2001), Kauai, HI, USA, 9–10 December 2001. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3273–3282. [Google Scholar]
- Rao, Z.; He, M.; Dai, Y.; Zhu, Z.; Li, B.; He, R. NLCA-Net: A non-local context attention network for stereo matching. APSIPA Trans. Signal Inf. Process. 2020, 9, E18. [Google Scholar] [CrossRef]
- Melo, A.G.; Pinto, M.F.; Honório, L.M.; Dias, F.M.; Masson, J.E. 3D Correspondence and Point Projection Method for Structures Deformation Analysis. IEEE Access 2020, 8, 177823–177836. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Menze, M.; Heipke, C.; Geiger, A. Joint 3D Estimation of Vehicles and Scene Flow. In Proceedings of the ISPRS Geospatial Week, La Grande Motte, France, 28 September–3 October 2015. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cascaded Feature Extraction (10 ms) | Hourglass | ||||||
|---|---|---|---|---|---|---|---|
| Kernel | Str | Ch (I/O) | OutRes | Kernel | Str | Ch (I/O) | OutRes |
| 3 × 3 | 1 | 3/32 | H × W | 3 × 3 × 3 | 2 1 | 32/64 64/64 | 1/6H × 1/6W × 16 |
| 5 × 5 | 3 | 32/32 | 1/3H × 1/3W | 3 × 3 × 3 | 2 1 | 64/128 128/128 | 1/12H × 1/12W × 32 |
| 3 × 3 | 1 | 32/32 | 1/3H × 1/3W | 3 × 3 × 3 | −2 | 128/64 | 1/6H × 1/6W × 16 |
| 3 × 3 | 2 | 32/48 48/64 64/96 96/128 | 1/6H × 1/6W 1/12H × 1/12W 1/24H × 1/24W 1/48H × 1/48W | 3 × 3 × 3 | 1 | 64/64 | 1/6H × 1/6W × 16 |
| 3 × 3 | −2 | 128/96 96/64 64/48 48/32 | 1/24H × 1/24W 1/12H × 1/12W 1/6H × 1/6W 1/3H × 1/3W | 3 × 3 × 3 | −2 | 64/32 | 1/3H × 1/3W × 8 |
| 3 × 3 | 2 | 32/48 48/64 64/96 96/128 | 1/6H × 1/6W 1/12H × 1/12W 1/24H × 1/24W 1/48H × 1/48W | 3 × 3 × 3 | 1 | 32/32 | 1/3H × 1/3W × 8 |
| 3 × 3 | −2 | 128/96 96/64 64/48 48/32 | 1/24H × 1/24W 1/12H × 1/12W 1/6H × 1/6W 1/3H × 1/3W | Classify and Disparity Regression | |||
| 2D Disparity Generation (15 ms) | Kernel | Str | Ch (I/O) | OutRes | |||
| Kernel | Str | Ch (I/O) | OutRes | 3 × 3 × 3 | 1 | 32/32 | 1/3H × 1/3W × 8 |
| Correlation | - | 32/64 | 1/3H × 1/3W | 3 × 3 × 3 | 1 | 32/1 | 1/3H × 1/3W × 8 |
| 3 × 3 | 2 | (64/64) × 4 | 1/6H × 1/6W 1/12H × 1/12W 1/24H × 1/24W 1/48H × 1/48W | Trilinear interpolation | 3 | 8/24 | H × W |
| 3 × 3 | −2 | (64/64) × 4 | 1/24H × 1/24W 1/12H × 1/12W 1/6H × 1/6W 1/3H × 1/3W | Disparity Regression | 1 | 24/1 | H × W |
| Trilinear interpolation | 3 | 64/192 | H × W | 3D Stacked Hourglass (5 ms) | |||
| Disparity Regression | 1 | 192/1 | H × W | Kernel | Str | Ch (I/O) | OutRes |
| 4D Cost Volume Generation (0.7 ms) | 3 × 3 × 3 | 1 | 32/32 32/32 | 1/3H × 1/3W × 8 | |||
| Kernel | Str | Ch (I/O) | OutRes | Hourglass | - | - | 1/3H × 1/3W × 8 |
| Algorithm 1 | - | 1/24 | H × W | Hourglass | - | - | 1/3H × 1/3W × 8 |
| Triliner interpolation | 1/3 | 24/8 | 1/3H × 1/3W | Hourglass | - | - | 1/3H × 1/3W × 8 |
| Warp | - | 32/32 | 1/3H × 1/3W × 8 | CDR | - | - | H × W |
| Concat | - | 32/64 | 1/3H × 1/3W × 8 | CDR | - | - | H × W |
| 3 × 3 × 3 | 1 | 64/32 32/32 | 1/3H × 1/3W × 8 | CDR | - | - | H × W |
| Method | GCNet [24] | PSMNet [25] | GANet [27] | DispNetC [22] | AANet [18] | JDCNet |
|---|---|---|---|---|---|---|
| EPE | 2.51 | 1.09 | 0.84 | 1.68 | 0.87 | 0.83 |
| Time(s) | 0.9 | 0.41 | 1.5 | 0.06 | 0.068 | 0.08 |
| Method | >2 pixel | >3 pixel | >5 pixel | Runtime(s) | |||
|---|---|---|---|---|---|---|---|
| Out-Noc | Out-All | Out-Noc | Out-All | Out-Noc | Out-All | ||
| GANet [27] | 1.89 | 2.50 | 1.19 | 1.60 | 0.76 | 1.02 | 1.8 |
| GwcNet [31] | 2.16 | 2.71 | 1.32 | 1.70 | 0.80 | 1.03 | 0.32 |
| PSMNet [25] | 2.44 | 3.10 | 1.49 | 1.89 | 0.90 | 1.15 | 0.41 |
| GCNet [24] | 2.71 | 3.46 | 1.77 | 2.30 | 1.12 | 1.46 | 0.9 |
| DispNetC [22] | 7.38 | 8.11 | 4.11 | 4.65 | 2.05 | 2.39 | 0.06 |
| RTSNet [19] | 3.98 | 4.61 | 2.43 | 2.90 | 1.42 | 1.72 | 0.023 |
| Fast DS-CS [21] | 4.54 | 5.34 | 2.61 | 3.20 | 1.46 | 1.85 | 0.021 |
| FADNet [20] | 3.27 | 3.84 | 2.04 | 2.46 | 1.19 | 1.45 | 0.05 |
| AANet [18] | 2.30 | 2.96 | 1.91 | 2.42 | 1.20 | 1.53 | 0.068 |
| JDCNet | 2.49 | 3.13 | 1.64 | 2.11 | 1.07 | 1.38 | 0.08 |
| Method | All Pixels | Non-Occluded Pixels | Runtime(s) | ||||
|---|---|---|---|---|---|---|---|
| D1-bg | D1-fg | D1-all | D1-bg | D1-fg | D1-all | ||
| GANet [27] | 1.48 | 3.16 | 1.81 | 1.34 | 3.11 | 1.63 | 1.8 |
| CSN [26] | 1.86 | 4.62 | 2.32 | 1.71 | 4.31 | 2.14 | 0.41 |
| GwcNet [31] | 1.74 | 3.93 | 2.11 | 1.61 | 3.49 | 1.92 | 0.32 |
| PSMNet [25] | 1.86 | 4.62 | 2.32 | 1.71 | 4.31 | 2.14 | 0.41 |
| GCNet [24] | 2.21 | 6.16 | 2.87 | 2.02 | 5.58 | 2.61 | 0.9 |
| DispNetC [22] | 4.32 | 4.41 | 4.34 | 4.11 | 3.72 | 4.05 | 0.06 |
| RTSNet [19] | 2.86 | 6.19 | 3.14 | 2.67 | 5.83 | 3.19 | 0.023 |
| Fast DS-CS [21] | 2.83 | 4.31 | 3.08 | 2.53 | 3.74 | 2.73 | 0.021 |
| FADNet [20] | 2.50 | 3.10 | 2.60 | 2.35 | 2.61 | 2.39 | 0.05 |
| DeepPruner [23] | 2.32 | 3.91 | 2.59 | 2.13 | 3.43 | 2.35 | 0.06 |
| AANet [18] | 1.99 | 5.39 | 2.55 | 1.80 | 4.93 | 2.32 | 0.068 |
| JDCNet | 1.91 | 4.47 | 2.33 | 1.73 | 3.86 | 2.08 | 0.08 |
| Matching Cost Computation | Cost Aggregation | KITTI 2015 | |||
|---|---|---|---|---|---|
| PC3 (%) | EPE | Time (s) | |||
| 1 | Correlation | Encoder-Decoder/2D | 96.98 | 0.62 | 0.02 |
| 2 | Concat | Hourglass/3D | 97.58 | 0.57 | 0.41 |
| 3 | Correlation + Correlation | Encoder-Decoder/2D | 97.28 | 0.59 | 0.042 |
| 4 | Concat + Concat | Hourglass/3D | 97.78 | 0.55 | 0.6 |
| 5 | Correlation + Concat | Encoder-Decoder/2D + Hourglass/3D | 97.56 | 0.57 | 0.079 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, X.; Chen, W.; Liang, Z.; Luo, X.; Wu, M.; Li, C.; He, Y.; Tan, Y.; Huang, L. A Joint 2D-3D Complementary Network for Stereo Matching. Sensors 2021, 21, 1430. https://doi.org/10.3390/s21041430
Jia X, Chen W, Liang Z, Luo X, Wu M, Li C, He Y, Tan Y, Huang L. A Joint 2D-3D Complementary Network for Stereo Matching. Sensors. 2021; 21(4):1430. https://doi.org/10.3390/s21041430
Chicago/Turabian StyleJia, Xiaogang, Wei Chen, Zhengfa Liang, Xin Luo, Mingfei Wu, Chen Li, Yulin He, Yusong Tan, and Libo Huang. 2021. "A Joint 2D-3D Complementary Network for Stereo Matching" Sensors 21, no. 4: 1430. https://doi.org/10.3390/s21041430
APA StyleJia, X., Chen, W., Liang, Z., Luo, X., Wu, M., Li, C., He, Y., Tan, Y., & Huang, L. (2021). A Joint 2D-3D Complementary Network for Stereo Matching. Sensors, 21(4), 1430. https://doi.org/10.3390/s21041430