
A Machine Learning Processing Pipeline for Reliable Hand Gesture Classification of FMG Signals with Stochastic Variance




Abstract
:1. Introduction
2. Materials and Methods
2.1. Pipeline Design
- FDA Model: The raw FMG data first underwent Fisher’s Discriminant Analysis (FDA) [28] processing to maximize class separation linearly, reduce the degree of overlap between different classes, and thus improve the overall effect of the pipeline. FDA is a processing technique that finds the linear boundary separating different classes’ data. This boundary maximizes the distances between different classes’ points, inter-class variance, while minimizing distances between the same class points, intra-class variance. FDA solves a constrained optimization function using Lagrangian multiplierswhere is the variance between classes, inter-class variance, and is the variance within each of the classes, intra-class variance. Both of the variances matrices’ dimensions are where d is the number of the original data dimensions. The solution W, containing the basis vectors of the transformation space, is given by
- PCA Model: After FDA processing, PCA [29] was applied to remove the correlation or dependence between data dimensions. The elimination of correlation benefited the final step of the pipeline, UMAP, significantly, as it learned the underlying structure more easily given no dimensions’ correlation or relationship needed to be taken into account. The principal components can be obtained fromwhere is the matrix of n data samples in d-dimensional space, and is the mean of the data.
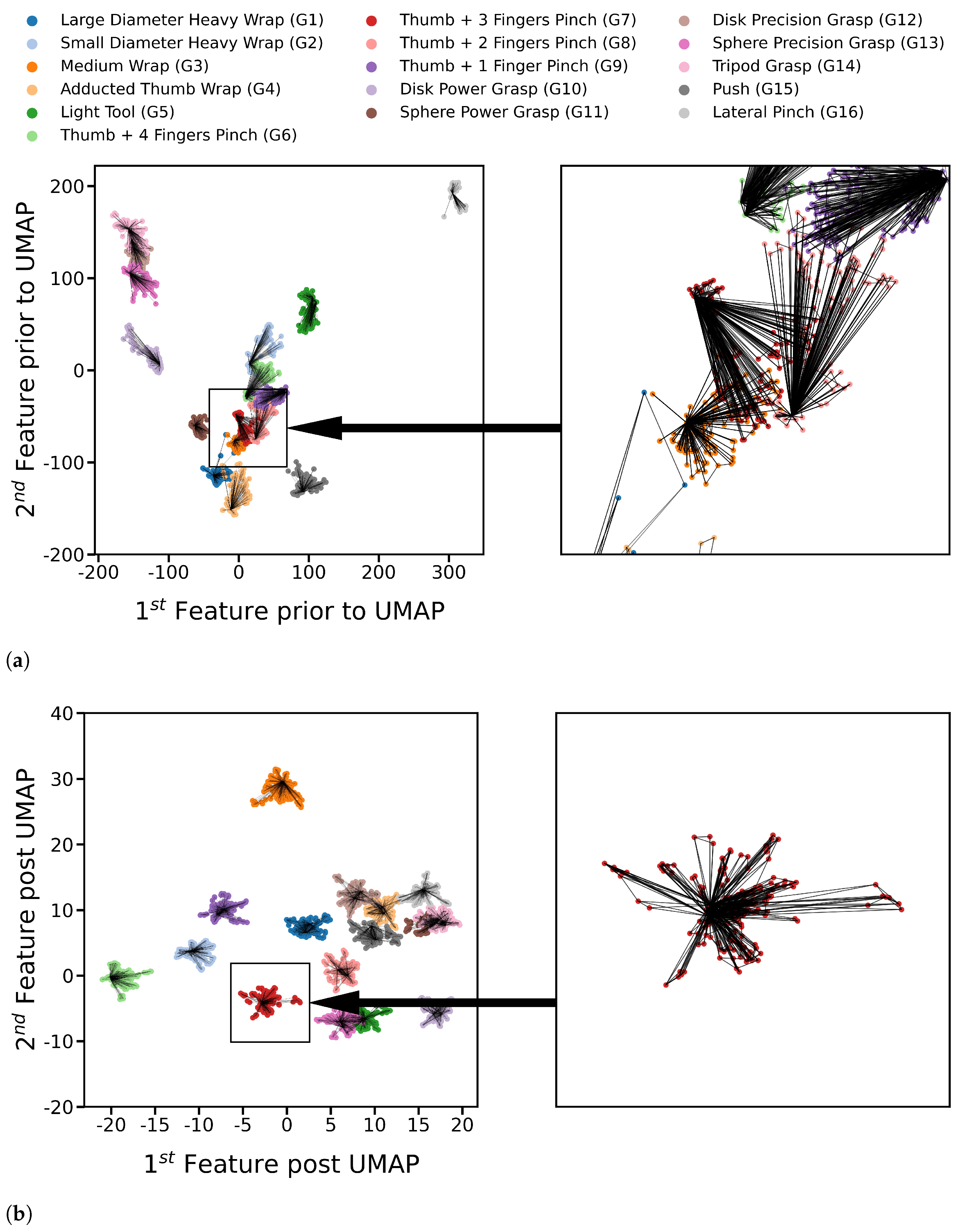
- UMAP Model: Finally, UMAP [30] was used to produce a more robust set of data features. UMAP assumes the data is distributed on a connected manifold, a nonlinear surface, that resembles a new Euclidean space if unfolded. UMAP connects data points to construct that manifold, followed by an optimization step to find the transformation yielding the data points’ representation on the unfolded manifold features. UMAP optimization is weighted between conserving the relative positions of points through the established connections and separating different classes via the points’ labels. The graph resulting from UMAP connections between training points for participant two after applying FDA and PCA is depicted in Figure 2a, whereas the same points distribution with the same connections after applying UMAP is shown in Figure 2b. UMAP [31,32] algorithm has many hyperparameters to tune its manifold. One manifold can preserve the original structure of the data, whereas another separates the classes non-linearly. Finding the best transformation to separate different classes’ points was preferred due to the stochastic variance of FMG signals, and participant two’s data was used for tuning. The separation’s precedence was considered during the tuning of hyperparameters listed in Table 1.
2.2. Classification Models for Evaluation
- Quadratic Discriminant Analysis (QDA) [38] is similar to LDA, as it assumes classes are normally-distributed but with independent variances, giving a quadratic decision boundary.
- Support Vector Machine with Radial Basis Kernel (SVM-RBF) [39] uses a kernel to transform data into another feature space before finding a linear decision boundary in that new space. The radial basis function transforms data into infinite-dimensional space, theoretically. The linear decision boundary in that space is nonlinear in the original feature space.
- Fully-Connected Neural Network (FC-NN) [40] is the most complex of the used models. Only a few fully-connected layers were sufficient for this study. Neural networks have numerous hyperparameters to tune and random weights initialization, making them extremely flexible during design. One neural network architecture with fixed hyperparameters values was used to evaluate the processing effect subjectively. The hyperparameters used for it are listed in Table 2. Regularization techniques are used with the neural network for a better generalization of test data.
- K-nearest Neighbors (KNN) [41] is one of the most basic classifiers, which uses neighboring labeled data points to classify unlabelled data. The pipeline’s results for KNN with five neighbor points can be extended to most metric-dependent methods in unsupervised learning like clustering since these methods share the same principles.
2.3. FMG Data
2.4. Statistical Analysis
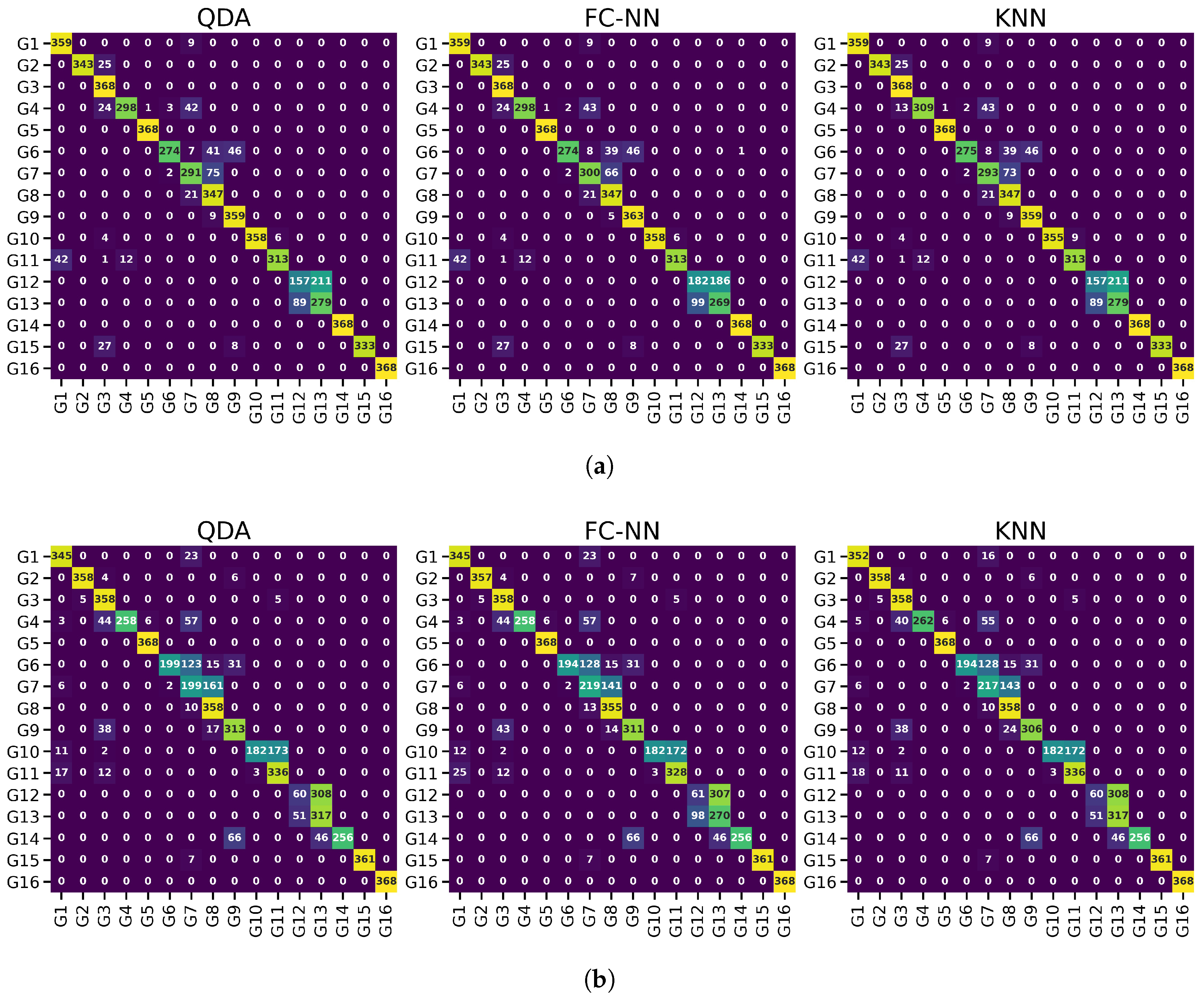
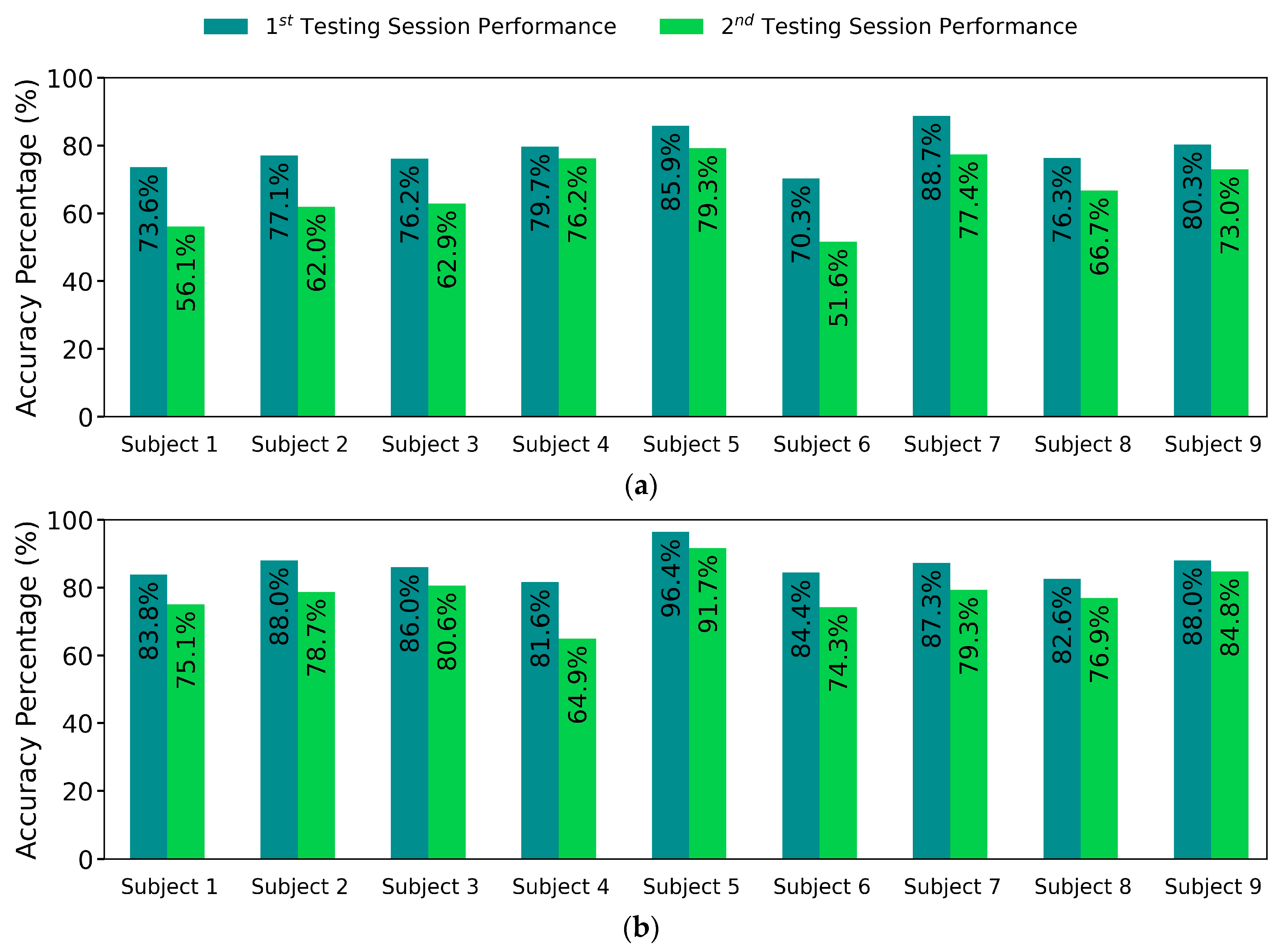
3. Results
4. Discussion
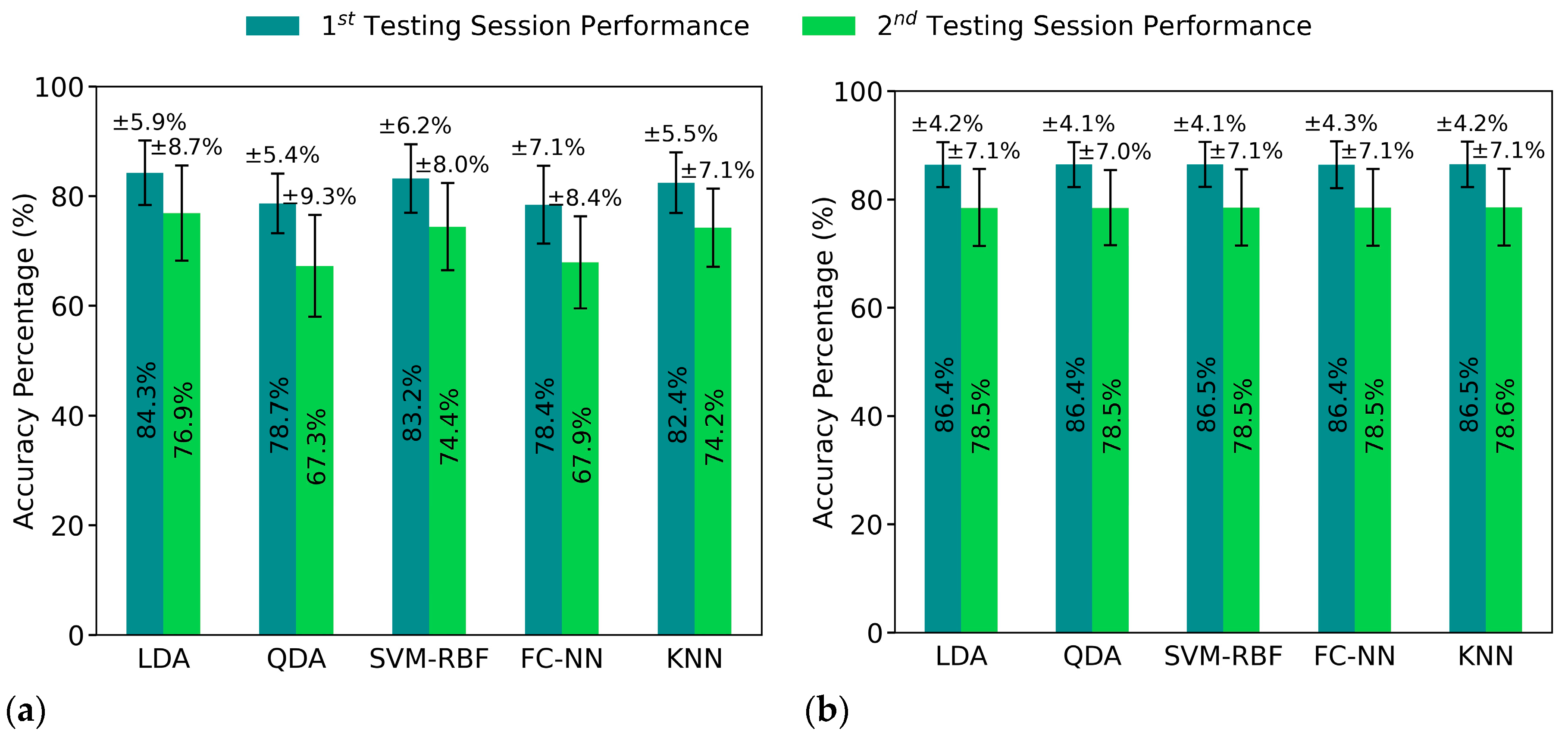
4.1. Classification Performance Improvement
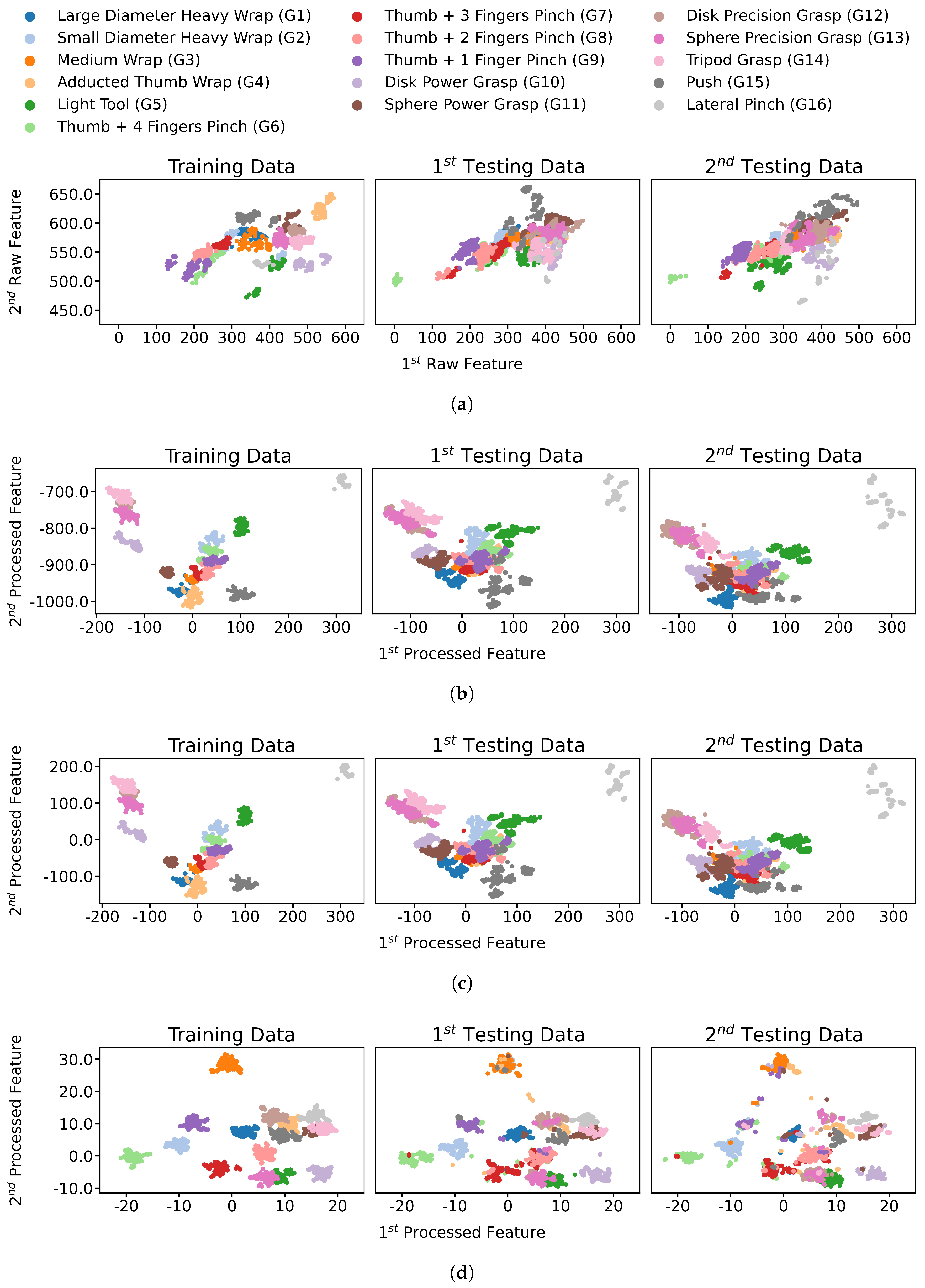
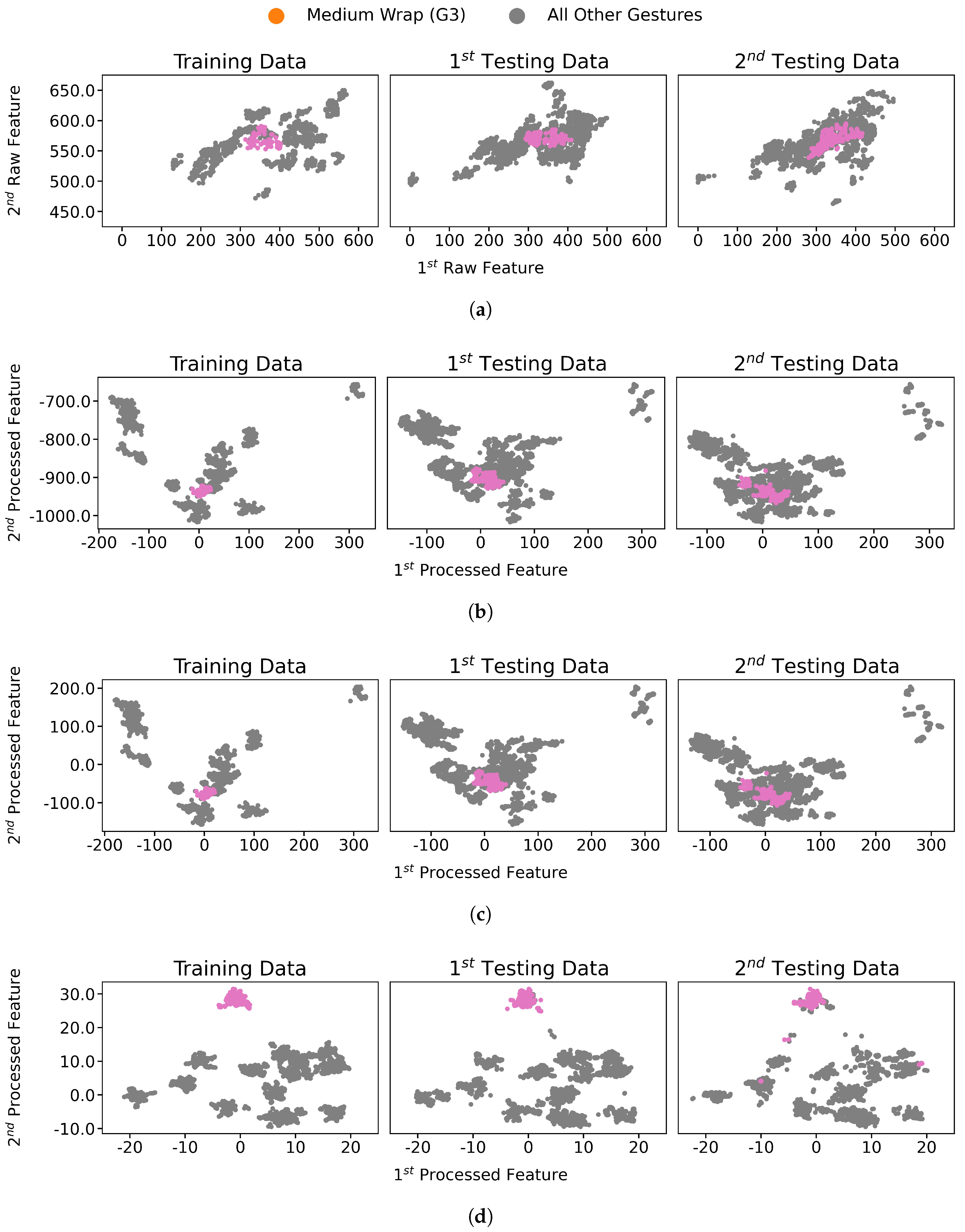
4.2. Processed Distributions Similarity
5. Limitation and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dwivedi, A.; Kwon, Y.; Liarokapis, M. EMG-Based Decoding of Manipulation Motions in Virtual Reality: Towards Immersive Interfaces. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, CA, USA, 11–14 October 2020. [Google Scholar]
- Simão, M.; Mendes, N.; Gibaru, O.; Neto, P. A Review on Electromyography Decoding and Pattern Recognition for Human-Machine Interaction. IEEE Access 2019, PP, 1. [Google Scholar] [CrossRef]
- Hassan, H.; Abou-Loukh, S.; Ibraheem, I. Teleoperated Robotic Arm Movement Using Electromyography Signal With Wearable Myo Armband. J. King Saud Univ. 2019, 32, 378–387. [Google Scholar] [CrossRef]
- Yang, D.P.; Zhao, J.D.; Jiang, L.; Liu, H. Embedded online recognition of hand gesture EMG modes. Harbin Gongye Daxue Xuebao/J. Harbin Inst. Technol. 2010, 42, 1060–1065. [Google Scholar]
- Kapuscinski, T.; Oszust, M.; Wysocki, M.; Warchoł, D. Recognition of Hand Gestures Observed by Depth Cameras. Int. J. Adv. Robot. Syst. 2015, 12, 36. [Google Scholar] [CrossRef]
- Kim, M.; Cho, J.; Lee, S.; Jung, Y. IMU Sensor-Based Hand Gesture Recognition for Human-Machine Interfaces. Sensors 2019, 19, 3827. [Google Scholar] [CrossRef] [Green Version]
- Naik, G.; Kumar, D.; Singh, V.; Palaniswami, M. Hand gestures for HCI using ICA of EMG. HCSNet Workshop Use Vis. HCI 2006, 56, 67–72. [Google Scholar]
- Artemiadis, P.; Kyriakopoulos, K. An EMG-based robot control scheme robust to time-varying EMG signal. Inf. Technol. Biomed. IEEE Trans. 2010, 14, 582–588. [Google Scholar] [CrossRef]
- Qi, J.; Jiang, G.; Li, G.; Sun, Y.; Tao, B. Intelligent Human-Computer Interaction Based on Surface EMG Gesture Recognition. IEEE Access 2019, 7, 1. [Google Scholar] [CrossRef]
- Haria, A.; Subramanian, A.; Asokkumar, N.; Poddar, S.; Nayak, J. Hand Gesture Recognition for Human Computer Interaction. Procedia Comput. Sci. 2017, 115, 367–374. [Google Scholar] [CrossRef]
- Prakash, A.; Sahi, A.; Sharma, N.; Sharma, S. Force myography controlled multifunctional hand prosthesis for upper-limb amputees. Biomed. Signal Process. Control. 2020, 62, 102122. [Google Scholar] [CrossRef]
- Rovira, J.; Rocon, E.; Reynaerts, D.; Saro, B.; Levin, S.; Moorleghem, W. The MANUS-HAND Dextrous Robotics upper limb prosthesis: Mechanical and manipulation aspects. Auton. Robots 2004, 16, 143–163. [Google Scholar] [CrossRef]
- Sun, Y.; Xu, C.; Li, G.; Xu, W.; Kong, J.; Jiang, D.; Tao, B.; Chen, D. Intelligent human computer interaction based on non redundant EMG signal. Alex. Eng. J. 2020, 59, 1149–1157. [Google Scholar] [CrossRef]
- Ribeiro, J.; Mota, F.; Cavalcante, T.; Nogueira, I.; Gondim, V.; Albuquerque, V.; Alexandria, A. Analysis of Man-Machine Interfaces in Upper-Limb Prosthesis: A Review. Robotics 2019, 8, 16. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Samuel, O.; Zhang, X.; Wang, H.; Fang, P.; Li, P. A motion-classification strategy based on sEMG-EEG signal combination for upper-limb amputees. J. Neuroeng. Rehabil. 2017, 14, 2. [Google Scholar] [CrossRef] [Green Version]
- Parajulli, N.; Sreenivasan, N.; Bifulco, P.; Cesarelli, M.; Savino, S.; Niola, V.; Esposito, D.; Hamilton, T.; Naik, G.; Gunawardana, U.; et al. Real-Time EMG Based Pattern Recognition Control for Hand Prostheses: A Review on Existing Methods, Challenges and Future Implementation. Sensors 2019, 19, 4596. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Z.; Menon, C. A Review of Force Myography Research and Development. Sensors 2019, 19, 4557. [Google Scholar] [CrossRef] [Green Version]
- Ha, N.; Withanachchi, G.; Yihun, Y. Performance of Forearm FMG for Estimating Hand Gestures and Prosthetic Hand Control. J. Bionic Eng. 2019, 16, 88–98. [Google Scholar] [CrossRef]
- Jiang, S.; Gao, Q.; Liu, H. A Novel, Co-Located EMG-FMG-Sensing Wearable Armband for Hand Gesture Recognition. Sensors Actuators Phys. 2020, 301, 111738. [Google Scholar] [CrossRef]
- Radmand, A.; Scheme, E.; Englehart, K. High-density force myography: A possible alternative for upper-limb prosthetic control. J. Rehabil. Res. Dev. 2016, 53, 443–456. [Google Scholar] [CrossRef]
- Belyea, A.; Englehart, K.; Scheme, E. FMG vs EMG: A Comparison of Usability for Real-time Pattern Recognition Based Control. IEEE Trans. Biomed. Eng. 2019, PP, 1. [Google Scholar] [CrossRef]
- Jiang, X.; Merhi, L.K.; Xiao, Z.G.; Menon, C. Exploration of Force Myography and surface Electromyography in hand gesture classification. Med Eng. Phys. 2017, 41, 63–73. [Google Scholar] [CrossRef] [PubMed]
- Pale, U.; Atzori, M.; Müller, H.; Scano, A. Variability of Muscle Synergies in Hand Grasps: Analysis of Intra-and Inter-Session Data. Sensors 2020, 20, 4297. [Google Scholar] [CrossRef] [PubMed]
- Zanghieri, M.; Benatti, S.; Burrello, A.; Kartsch, V.; Conti, F.; Benini, L. Robust Real-Time Embedded EMG Recognition Framework Using Temporal Convolutional Networks on a Multicore IoT Processor. IEEE Trans. Biomed. Circuits Syst. 2019, 14, 244–256. [Google Scholar] [CrossRef]
- Tkach, D.; Huang, H.; Kuiken, T. Study of stability of time-domain features for electromyographic pattern recognition. J. Neuroeng. Rehabil. 2010, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Ketykó, I.; Kovács, F.; Varga, K.Z. Domain Adaptation for sEMG-based Gesture Recognition with Recurrent Neural Networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar]
- Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Geng, W. Surface EMG-Based Inter-Session Gesture Recognition Enhanced by Deep Domain Adaptation. Sensors 2017, 17, 458. [Google Scholar] [CrossRef] [Green Version]
- Patil, B.V.M. PCA and FDA Based Dimensionality Reduction Techniques for Effective Fault diagnosis of Rolling Element Bearing. J. Emerg. Technol. Innov. Res. 2015, 2, 1297. [Google Scholar]
- Jolliffe, I.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Saul, N.; Grossberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- Wander, L.; Vianello, A.; Vollertsen, J.; Westad, F.; Braun, U.; Paul, A. Exploratory analysis of hyperspectral FTIR data obtained from environmental microplastics samples. Anal. Methods 2020, 12, 781–791. [Google Scholar] [CrossRef]
- Diaz-Papkovich, A.; Anderson-Trocmé, L.; Ben-Eghan, C.; Gravel, S. UMAP reveals cryptic population structure and phenotype heterogeneity in large genomic cohorts. PLoS Genet. 2019, 15, e1008432. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Merhi, L.; Menon, C. Force Exertion Affects Grasp Classification Using Force Myography. IEEE Trans. -Hum.-Mach. Syst. 2018, 48, 219–226. [Google Scholar] [CrossRef]
- Xanthopoulos, P.; Pardalos, P.; Trafalis, T. Linear discriminant analysis. In Robust Data Mining; Springer: New York, NY, USA, 2013; pp. 27–33. [Google Scholar] [CrossRef]
- Godiyal, A.; Mondal, M.; Joshi, S.; Joshi, D. Force Myography Based Novel Strategy for Locomotion Classification. IEEE Trans. -Hum.-Mach. Syst. 2018, 48, 1–10. [Google Scholar] [CrossRef]
- Ahmadizadeh, C.; Merhi, L.; Pousett, B.; Sangha, S.; Menon, C. Toward Intuitive Prosthetic Control: Solving Common Issues Using Force Myography, Surface Electromyography, and Pattern Recognition in a Pilot Case Study. IEEE Robot. Autom. Mag. 2017, 24, 102–111. [Google Scholar] [CrossRef]
- Sadarangani, G.; Jiang, X.; Simpson, L.; Eng, J.; Menon, C. Force Myography for Monitoring Grasping in Individuals with Stroke with Mild to Moderate Upper-Extremity Impairments: A Preliminary Investigation in a Controlled Environment. Front. Bioeng. Biotechnol. Sect. Bionics Biomimetics 2017, 5, 42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tharwat, A. Linear vs. quadratic discriminant analysis classifier: A tutorial. Int. J. Appl. Pattern Recognit. 2016, 3, 145. [Google Scholar] [CrossRef]
- Guenther, N.; Schonlau, M. Support Vector Machines. Stata J. 2016, 16, 917–937. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Peterson, L. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- AlOmari, F.; Liu, G. Analysis of extracted forearm sEMG signal using LDA, QDA, K-NN classification algorithms. Open Autom. Control. Syst. J. 2014, 6, 108–116. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharyya, S.; Khasnobish, A.; Chatterjee, S.; Konar, A.; Tibarewala, D. Performance Analysis of LDA, QDA and KNN Algorithms in Left-Right limb movement classification from EEG data. In Proceedings of the 2010 International Conference on Systems in Medicine and Biology, Kharagpur, India, 16–18 December 2010. [Google Scholar] [CrossRef]
- Raza, M.; Waris, M.; Kamavuako, E.; Bai, S. A comparative study of motion detection with FMG and sEMG methods for assistive applications. J. Rehabil. Assist. Technol. Eng. 2020, 7, 1–11. [Google Scholar] [CrossRef]
- Nair, N.G.; Satpathy, P.; Christopher, J. Covariate Shift: A Review and Analysis on Classifiers. In Proceedings of the 2019 Global Conference for Advancement in Technology (GCAT), Bangalore, India, 18–20 October 2019; pp. 1–6. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UMAP Hyperparameter | Chosen Value |
|---|---|
| Number of Neighbors | 2 |
| Metric | Cosine Distance |
| Output Metric | Euclidean |
| Target Metric | Euclidean |
| Target Weight | 0.75 |
| Repulsion Weight | 3.0 |
| Embedding Initialization | Random |
| Minimum Distance | 0.25 |
| Hyperparameter | Used Value |
|---|---|
| Learning Rate | 0.001 |
| Epochs | 30 |
| Batch Size | 1024 |
| Validation Split | 0.2 |
| Classifier | FDA Features | PCA Features | UMAP Features | Pipeline Features | ||||
|---|---|---|---|---|---|---|---|---|
| Session 1 | Session 2 | Session 1 | Session 2 | Session 1 | Session 2 | Session 1 | Session 2 | |
| LDA | 86.5% | 77.4% | 84.3% | 76.9% | 81.5% | 72.5% | 86.4% | 78.5% |
| QDA | 79.4% | 67.7% | 78.8% | 67.3% | 81.5% | 72.5% | 86.4% | 78.5% |
| SVM-RBF | 83.2% | 75.4% | 85.3% | 76.0% | 81.5% | 72.5% | 86.5% | 78.5% |
| FC-NN | 82.1% | 72.8% | 79.6% | 68.4% | 81.5% | 72.6% | 86.4% | 78.5% |
| KNN | 86.5% | 78.4% | 82.4% | 74.2% | 81.6% | 72.5% | 86.5% | 78.6% |
| Mean | 83.6% | 74.2% | 82.3% | 72.5% | 81.5% | 72.5% | 86.4% | 78.5% |
| Std Dev | ±10.4% | ±12.9% | ±11.4% | ±13.8% | ±10.8% | ±12.1% | ±8.6% | ±11.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asfour, M.; Menon, C.; Jiang, X. A Machine Learning Processing Pipeline for Reliable Hand Gesture Classification of FMG Signals with Stochastic Variance. Sensors 2021, 21, 1504. https://doi.org/10.3390/s21041504
Asfour M, Menon C, Jiang X. A Machine Learning Processing Pipeline for Reliable Hand Gesture Classification of FMG Signals with Stochastic Variance. Sensors. 2021; 21(4):1504. https://doi.org/10.3390/s21041504
Chicago/Turabian StyleAsfour, Mohammed, Carlo Menon, and Xianta Jiang. 2021. "A Machine Learning Processing Pipeline for Reliable Hand Gesture Classification of FMG Signals with Stochastic Variance" Sensors 21, no. 4: 1504. https://doi.org/10.3390/s21041504
APA StyleAsfour, M., Menon, C., & Jiang, X. (2021). A Machine Learning Processing Pipeline for Reliable Hand Gesture Classification of FMG Signals with Stochastic Variance. Sensors, 21(4), 1504. https://doi.org/10.3390/s21041504