In this section, we present an overview of the software-based RA schemes in chronological order. Their strength and weaknesses are discussed, as well as possible extensions.
5.1. Schemes Description
5.1.1. Reflection
Reflection [
13] is the earliest attestation found, and it is designed as a simple challenge-response protocol to attest a prover. At the attestation time, the verifier sends two challenges, and each challenge contains a range of memory addresses to attest. Upon receiving a challenge, the prover computes a hash or message digest of the given memory space and its program version. The prover then returns the hash and its version as a response to the challenge. When the verifier has received both responses, it computes the expected hash values and compares them with the the prover’s responses; if they do not match the prover is considered compromised. To guarantee the security, this attestation scheme imposes constraints on the two ranges sent in the challenge. To guarantee that the entire program memory is attested, the ranges should be overlapping and unpredictable. For instance, the verifier randomly chooses two integers
and
such that
, where
is the range of the programs memory addresses where the program is stored. When the first challenge attests the range
, the second challenge attests the range
and
, the ranges overlap and many addresses are attested by both challenges.
This protocol is vulnerable to an attacker that first compresses the unused program memory to create space to hide itself, and then during attestation, it decompresses the memory to compute a valid checksum. The paper recommends that the state of the program running on the system be included in the response as a countermeasure to such an attack. The paper also proposes to fill unused memory with random high entropy noise, to be able to attest the memory. The attacker could also hide the original memory values in the devices’s data memory, which is not being attested. To detect this attacker, the paper suggests imposing a time limit within which the prover responds. Additionally, the paper mentions that the protocol is vulnerable to man-in-the-middle attacks because the compromised device could redirect the request to an uncompromised device, intercept the response and use it to pass the attestation. This attack has not been addressed in the paper because it is assumed that the cost outweigh the benefit for the attacker.
While Reflection is the first software-based attestation scheme, it also presents several weaknesses. The paper mentions the memory entropy but it does not consider the entropy of the randomly chosen integers used for the memory ranges. The paper does not explain how the hash is computed and how the memory is traversed. For instance, if the hash is just of the memory’s value and the memory is traversed in a predictable sequential order, it is easier for the attacker to redirect, with an offset, the attestation to where the original memory is stored, computing a valid response. This problem was later tackled in SWATT [
4] by not attesting the memory sequentially. In addition, Reflection has a risk of being inefficient. For example, if
and
, then the entire memory is attested twice, which is unnecessary, and if
and
is just close to the boundaries of the range, it means most of the memory is attested twice. From an IoT point of view, attesting memory twice during the same run, uses precious battery, bandwidth and prevents devices from doing their regular operations. Depending on how often devices are attested, the attestation could result to be a costly operation.
5.1.2. SWATT
SWATT [
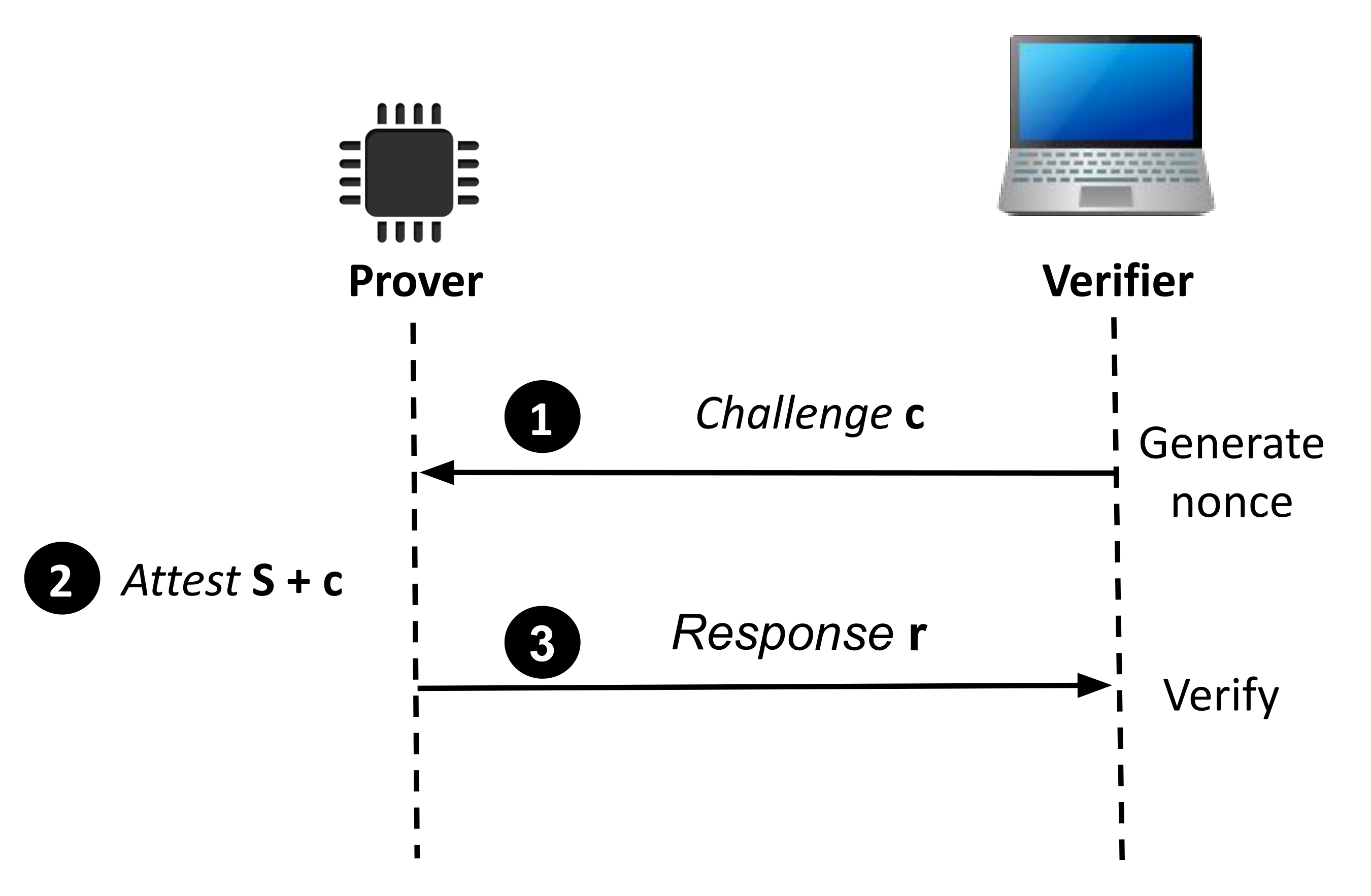
4] is a simple challenge-response protocol, similar to the one shown in
Figure 1. SWATT computes the response by performing a checksum of the memory. It uses a pseudo random number generator (PRNG) to iterate over the memory in an unpredictable order. In this way, the attacker has to check every memory access during the attestation, in order to redirect the memory access to where the original code for that memory location is stored. The prover receives the seed for the PRNG in the challenge from the verifier. To ensure with high probability that the device is not compromised, SWATT traverses
memory addresses, where n is the number of memory addresses, in which the program running on the device is stored. This value comes from the Coupon Collectors Problem, which states that with this number of memory accesses, it is likely that every memory address in the device is accessed at least once. With every memory address accessed at least once, the attacker cannot store unexpected values in the attested memory.
To prevent an attacker from computing a valid response on the fly during the attestation execution, by redirecting the attestation to memory regions where the attacker has stored the original values, SWATT requires a strict running time of the attestation procedure. To meet the upper bound time limit of attestation procedure execution, the SWATT attestation code must be fully optimized. Due to PRNG properties, the attacker needs to insert if statements into the attestation code to redirect the check to where the original code is stored. Thus, any injected malicious code will result in a measurable delay. Another requirement for the timing check, is that the attestation response cannot be computed concurrently, i.e., different parts cannot be computed at the same time. If this was possible, a number of devices would be able to collude to compute the legitimate response within the permitted time. To prevent the concurrent computation, each checksum and memory address is dependent on the previous one.
The fact that SWATT relies on a strict time limit and optimized function execution is considered a drawback. In particular, as devices become powerful and algorithms get improved, the SWATT algorithm would need to be continuously updated, to ensure that no faster implementation exists. Furthermore, it presents a problem when used in networks with unpredictable delays. In this case, the allowed time might be too long, which would allow attackers to remain undetected. In contrast, if the allowed time is not long enough, devices might be considered compromised even if they are not.
5.1.3. Pioneer
Pioneer [
5] is a RA scheme similar to SWATT [
4], but it focuses on legacy devices with more processing power and more memory. Pioneer differs from SWATT in that it includes more information in the checksum. Unlike SWATT that includes only the values of the memory addresses in the checksum, Pioneer also includes the program counter and the data pointer in the checksum, in order to detect memory copy attacks. Furthermore, the jump locations for jump instructions are also included in the checksum, to detect illegal jumps.
Pioneer is a two-step challenge-response protocol. First, it computes a checksum of the checksum code to verify that it works correctly. Then, it computes a hash of the executable that is being attested. The verifier checks both the checksum and the hash to confirm the executable is trusted. Pioneer also differs from the other schemes presented, in what is being attested. For devices with large amounts of memory and many different programs, Pioneer only attests one executable, which is then used to provide a route of trust for that executable. Pioneer requires the same strict time constraints as SWATT and uses the same PRNG to select memory addresses.
5.1.4. PIV
The Program Integrity Verification (PIV) [
36] is a RA scheme based on a randomized hash function (RHF). The RHF used is a multivariate quadratic (MQ) polynomial. The MQ polynomials have successfully been used as a one-way trap-door function. The special MQ polynomial characteristic PIV uses, is that the same hash value can be computed from both the memory content and a special digest of the memory content. That is, running the RHF on both the program and a special digest of the program, will produce the same value. The MQ polynomials have the following special characteristic. If a program x is split into n blocks
, where each block is a
vector
, then the special digest is the
matrix
.
The digest is clearly related to the program x. During the verification the verifier computes the hash
Y from the digest
by
and the prover computes the hash
Y from the program
x by
where
H is the random hash function,
is a cryptographic key and
n is the number of blocks the program consists of.
PIV is a typical challenge-response protocol, but it sends more messages to authenticate the verifier. The protocol starts either when a device tries to join the network, or when an intrusion detection mechanism flags the device as potentially compromised. When a device tries to join the network, it first finds at least a verifier and an authentication server (AS), and then, it asks the AS to authenticate the verifier. Once it has found an authenticated verifier, it will ask that verifier to attest its code. The verifier sends the randomized hash function H and the key to the device. The device computes the hash from the program and sends the hash as a response to the challenge. If it does not match the verifier’s expected checksum, the device is considered compromised and cannot join the network. Suppose the device is already on the network and the intrusion detection system flags it as suspicious. In that case, the verifier can initiate the protocol by sending the hash function and the key. The device still authenticates the verifier with the authentication server.
Unlike Reflection [
13] or SWATT [
4], in PIV [
36], the verifier does not store the programs but only some digest of program blocks. Since programs from different sensors might use the same blocks, this means the verifier might need to store less information. PIV claims to be efficient as it does not attest devices often: a device is attested when it joins and when an intrusion detection system (IDS) flags a device as possibly compromised. Since how often PIV will attest devices depend on the IDS, it might often run if the IDS is very sensitive or if many attacks are triggering the IDS to attest the devices.
5.1.5. Self-Modifying Code
Shaneck et al. [
37] propose a RA protocol that improves the strict time constraint of SWATT [
4]. The key idea is to make it difficult for attackers to insert conditional offsets into the read statements of the attestation code by making the code different for every attestation. In order to achieve this, the attestation code is required to be fresh and unpredictable. The freshness is to avoid replay attacks, while unpredictability prevents pre-computation. In the proposed solution, the verifier sends the attestation code over the network. For this, the code should be small not to introduce high communications overhead during the attestation procedure.
The scheme focuses on making static program analysis of the attestation code difficult and time-consuming, preventing attackers from computing a valid response within the expected time limit. Unlike SWATT that relies on a strict time constraint and optimized attestation code, this scheme has a looser time constraint and does not rely on the optimized code. In particular, the scheme relies on code obfuscation to prevent any attacker from analysing the code and computing a correct response in time. The solution suggested is intended to add more delay from an attack, to ease the strict time limit, allowing for more delay in the network. The proposed time constraint for this attestation scheme is , where r is the transmission time of the challenge and response, e is the expected execution time of the attestation code, and is the variable time. is based on the delay to an attacker, and hence is the allowed network delay.
This scheme is a challenge-response protocol, with the addition of using encryption and message authentication codes (MAC). The challenge contains the actual attestation code, which has been encrypted and sent along with a MAC of it. After the prover has verified the MAC, it decrypts the code and loads it into the program memory to execute it. When the verifier constructs the attestation code, some form of randomness is used to provide freshness and make the code unpredictable.
This scheme is an improvement over SWATT when it comes to maintainability. Since SWATTs attestation code has to be fully optimized, it needs to be continuously checked and updated so that no attacker could have a faster version with conditional offsets. This is not required by Self-Modifying Code, as the code is a fresh version provided by the verifier at each attestation. This means that the verifier has to send more data, which could be an issue for sensor networks, where the bandwidth is low. For example, if the sensor is somewhere remote and running on a battery, then this communications overhead might be too costly.
5.1.6. Proactive
Proactive Code Verification [
38] is an attestation scheme trying to improve upon SWATT [
4]. Like the Self-Modifying Code [
37] scheme, it aims to solve the strict time constraint imposed by SWATT. Rather than changing the attestation code, Proactive focuses on filling the memory with random values to prevent the attacker from hiding the original values or the malicious code. This protocol is a classic challenge-response protocol attesting the memory by computing a checksum over the content. It suggests adding an identifier for the verifier to the request, allowing the prover to authenticate it. In the request, the prover receives a seed, same as SWATT. Instead of using the seed to attest memory in random order from the randomly generated values, Proactive uses the seed to generate random values used to fill the empty memory. Additionally, instead of responding with only the program memory checksum, Proactive includes the data memory in the checksum. To verify the checksum, the verifier needs the data memory content, which the prover sends in the response along with the checksum.
This scheme also has a time constraint, but it is not required to be as strict as SWATT. As the entire memory is attested, an attacker cannot use unused memory to calculate a valid response from original values. Moreover, in Proactive, the values used to fill the memory rely on the previous values. The attacker will therefore not generate the values easily and hash them. Since Proactive fills the memory twice, the attacker cannot simply calculate the chains, as the results propagate through the values for all the filled memory. Proactive includes the data memory in the checksum and sends the memory content in the response to introduce more data to be sent over the network. Since the verifier does not know the legitimate state of the data memory, it accepts the response content despite potentially malicious code that it may include.
Proactive’s improvement on the time constraint of SWATT is due to the fact that it would take an attacker a long time to compute each block of memory to be attested, without overwriting its own malicious code. The attacker would have to compute each block of memory from the beginning since each block relies upon the previous blocks. Because the memory is filled twice, it means the first block relies on all the other blocks.
5.1.7. Distributed
Yang et al. [
39] propose two different distributed attestation schemes. The idea behind both of them is to remove the need for a trusted verifier as in other attestation schemes. In addition, an efficiency enhancement for SWATTs [
4] pseudo-random memory traversal is suggested at the cost of security. This scheme relies on SWATT but with the difference that it works on memory blocks instead of cells. Instead of computing the checksum by iterating over each memory address and updating the checksum, the proposed block-based approach handles a block of cells at a time, which are Xor-ed together to compute the checksum. Such an approach results in fewer iterations since each iteration handles more memory. If the block size is set to one, then it is the same as SWATT. If the block size is the memory’s size, then the checksum is computed in one iteration, where all memory is Xor-ed together. A block size equal to the size of the attested memory is a security risk, as it makes it easy for an attacker to store the computed checksum since there is no actual traversal. Therefore one has to be careful when choosing the block size.
In the first scheme, one device is elected and acts as the verifier. Majority rule verifies the attestation response in the second scheme. In both schemes, the memory is filled before the devices are deployed. The memory is filled with pseudo-randomly generated noise. It uses RC5 in CTR mode to fill the memory, which is a common hash algorithm running in counter mode. Counter mode means that the values generated are not reliant on the previously computed values. Instead, the computed values depend on a counter, which is encrypted. That means, if the seed and the counter value are known for a specific block, then it is possible to compute the value without having to compute any other values. This is less secure, as the values are not mixed together the same way as in CBC mode. These schemes do not have a powerful verifier with lots of memory to handle the CBC mode, which is why the CTR mode was chosen, as it uses less memory.
In the first scheme, the idea is for the provers neighbours to have the seed for the memory filling as a shared secret. This means the neighbours can recreate the values used to fill the memory to compute a checksum to attest against. Once the device is deployed, it finds its neighbours and then sends a part of the seed together with a hash of the seed to each neighbour. The secret sharing relies on a () threshold, where n is the number of neighbours and k is a value representing a trade-off between security and performance. This has to do with defining how many neighbours the secret has to be shared between to be secure. The threshold k is defining how many shares are needed to restore the secret. The higher k is, the more shares are needed, making it more difficult to obtain the secret and requiring more communication when a device actually needs to get the secret.
The second scheme does not rely on a cluster head but a democratic process. Instead of sharing the seed amongst the neighbours, each device is loaded with n challenge-response pairs before it is deployed, where n is the number of expected neighbours. The number of memory traversal iterations is configurable and is a trade-off between security and performance. When the device is deployed, it finds its neighbours and sends a challenge-response pair to each of them. Upon a device is chosen for attestation, each neighbour sends its challenge sequentially. The prover computes the responses with the PRNG block-based memory traversal. The neighbours then vote on the result and the majority rules.
In the first scheme, the protection of the seed is critical. If the seed is compromised, then the attacker can pass any attestation for the device to which the seed belongs. That means the attacker needs to obtain k or more secret shares, e.g., by compromising the neighbours. Another possibility the attacker has is to be cluster head during attestations, then compromise those devices it attested. This way, it will have the secret seed for them, letting them pass attestation and do the same when they are cluster head.
The second scheme does not have the weakness mentioned above. Instead, it is a democratic scheme, so if the attacker has compromised enough devices, the attack will not be detected. This means this scheme relies on the probability of each device being compromised and detection mechanism to detect the attack before too many devices are compromised. Furthermore, the second scheme could end up being extremely inefficient if focused too much on security. If a prover has many neighbours and it has to traverse the entire memory for each neighbour, it would prove extremely inefficient. The first scheme has the advantage here since only one attestation execution is performed.
Furthermore, the schemes presented here have a high communications overhead, which can be costly on devices’ power consumption, especially when considering IoT battery-powered and resource-constrained devices. The second scheme introduces communications overhead and computational overhead, as the prover might have to attest its whole memory several times.
5.1.8. Memory Filling
AbuHmed et al. [
40] present another attempt at using memory filling to overcome the time constraints imposed by SWATT. Filling the memory is proposed to be done in two different ways, together with two attestation protocols. Furthermore, an alteration is suggested to the block-based pseudo-random memory traversal used in the Distributed [
39] schemes. The pre-deployment memory filling scheme of Memory Filling [
40] is very similar to that of [
39]. Both schemes use RC5 in CTR mode to fill the memory of the devices before they are deployed. The difference is that in [
40] a trusted verifier does the attestation. The change suggested to the PRNG is to make the block size dynamic in the algorithm. This involves calculating a new block size in each iteration. The paper suggests having the block size be a function of the output from the RC5 hash function but does not suggest any requirements.
The paper suggests two attestation protocols. The first one is the same basic protocol as any other attestation scheme, but with ids and encryption for authentication and protection of the messages during communication. It also sends a nonce from the verifier to the prover and another nonce from the prover to the verifier. This is a basic and common way to provide freshness proof for both sides. The second attestation scheme adds a timestamp to the attestation request, in order to prevent replay attacks.
The post-deploy memory filling could be useful if some data is collected and stored in the program memory, to be used for the devices normal operation. It would notify the verifier about the seed and memory. The block-based pseudo memory traversal algorithm is an interesting suggestion to make it less predictable, but it is not justified from a performance or security perspective. It would randomly increase performance or security, depending on whether the block gets bigger or smaller. In the end, it will depend on the number of iterations done. The dynamic block size is not a good measure for number of iterations, as b is not fixed. The likely scenario is to run iterations to be on the safe side.
The memory filling of these schemes is using RC5 in CTR mode. The reason Distributed [
39] used CTR mode was because of the better performance on memory usage. This choice was made because the code was running on other resource-constrained devices, where memory usage performance matter. In Memory Filling [
40], a verifier, which is likely a more powerful machine, does the attestation. The prover does not need to fill the memory again, it just needs to compute the checksum, so it is unaffected by CTR vs. CBC mode. The verifier is likely to have the memory to generate the expected memory with RC5 in CBC mode rather than in CTR mode, thus being more secure at the cost of some temporary memory usage. After the attestation, the memory with the expected memory content can be overwritten and used for the next attestation.
5.1.9. USAS
USAS [
41] is a RA scheme that aims to improve the time and power performance of Distributed [
39] and SWATT [
4]. Thus, it relies on two layers of attestation, where only one layer is dependent on a PRNG, improving the performance of the second layer. Even though the scheme is mostly based on Distributed [
39], it uses a trusted verifier, rather than the distributed model of [
39]. The focus is on the time and power performance of the attestation.
In the scheme presented, I- and F-devices distinguish the two layers. The I-device is the initiator, which means that it is where the attestation starts. The F-devices are the followers, which are in the second layer of attestation. The devices to attest, both the I-device and the F-devices, are picked randomly by the verifier to ensure unpredictability. The basic idea is that the verifier sends a random challenge to the I-device. The device computes a checksum from the challenge. The I-device then sends the checksum to the F-devices, instead of to the verifier. The F-devices use the checksum to compute their checksum. The F-devices send their checksum to the verifier, and the verifier compares them with a locally computed expected checksum.
The memory of the devices is filled before they are deployed, similar to previously described schemes. The challenge message contains the seed for the PRNG and the seed used for the random noise generation used to fill the memory. The devices have a hash of the seed stored, which they use to authenticate the challenge. The I-device receiving the first challenge uses RC4 to generate random memory addresses for the attestation. This is the attestation algorithm used in SWATT [
4]. The resulting checksum is sent to all the selected F-devices. This is where the the most significant difference comes. Instead of using RC4 to generate a random address for attestation, the F-devices use the I-device checksum for generating addresses. The noticeable part of the algorithm is that the memory address to be attested is computed from the I-device checksum combined with its checksum, which it is currently computing. It still iterates over the memory
times, but it does not run RC4 on every iteration to generate a new random address. The RC4 value is, therefore, also not used to update the checksum. When the verifier compares the checksums from the F-devices with its own locally computed checksums, it also verifies the checksum of the I-device each time. This is because the checksum from the I-device is used to compute all the other checksums. If the checksum of the I-device would not pass, then none of the other checksums would pass. That means if at least one F-device passes the attestation, then the I-device also passes. However, it does also mean that if the I-device is compromised and cannot pass, then all the F-devices will also fail even if they are not compromised. This means one attestation round is not enough to say that a F-device has failed if all the F-devices failed. If just one F-device passes, then the I-device can be trusted, and any F-device that fails can be considered compromised. If all checksums’ validation fails, there will be another round necessary to check if it was because of the I-device. Thus, the devices will be re-attested until at least one device passes.
Even if the performance might be better for each attestation, it depends on how likely it is that the I-device is compromised. Each time the I-device is the compromised device, all the F-device attestations are useless, and SWATT would have been more efficient. There is also always the possibility that the I-device is not compromised, but all the F-devices are, depending on how many F-devices there are in each attestation.
A security risk with this scheme is that the challenge includes the seed used to fill the memory. This means an attacker can obtain the seed and generate the expected memory content on the fly. Since there is no time constraint imposed, the attacker has plenty of time to generate a valid response. This seed is only used to authenticate the verifier and thereby the challenge. Instead of sending the seed, the hash value should be sent not to disclose the actual seed. However, if an attacker eavesdrops and learns the message, be it the seed or a hash of it, then the attacker can authenticate as the verifier. This means that it is crucial having a secure authentication protocol with messages encrypted with a strong enough encryption.
5.1.10. DataGuard
DataGuard [
42] focuses on preventing overflow attacks in the data memory. Unlike the other schemes, it provides security assurances for the data memory’s integrity, without overwriting the memory content. As long as the dataguards cannot be reconstructed, the scheme will detect any overflow attack, which has happened since the last attestation.
The way the scheme prevents these kinds of attacks is by introducing new variables called dataguards. The dataguards are appended to the end of the variables used by the program. The point is, that memory is always filled in one direction, so if more memory is filled than is allocated to the variable, it will fill the dataguard. Since the dataguard has been changed, the device will not be able to pass attestation. To prevent an attacker from passing attestation, the dataguards are not allowed to be able to be recreated, without some secret information, which is not stored in the device.
The dataguards are initialized from a secret e and a provided by the trusted verifier. The first dataguard is a hash of the two values from the verifier and the initial value of a counter c, that is the initial dataguard is , where is the dataguard and is the initial value of the counter c. Both e and are fresh and randomly chosen, thus providing entropy and making if difficult to guess them. The security of the dataguards, relies on the attacker not knowing e and , since knowing them would allow the attacker to compute all valid dataguards for passing attestation. When a new dataguard is computed the previous dataguard is updated as well. The previous dataguard becomes and the new dataguard is set to . Note that the new dataguard is computed from the old value of the previous dataguard, not from its new value. The dataguards computed are never deleted or removed. If they are not used anymore, because they belonged to a temporary variable, then they are stored in a list of dataguards as they are still needed during attestation.
The attestation protocol of this scheme is again a challenge-response scheme. The verifier sends a challenge to the prover. The prover computes a checksum of the dataguards which it sends, together with the number of dataguards m computed, as a response to the challenge. The verifier then computes the expected value locally, as it knows both e and . If any of the dataguards do not have the expected value, then the checksums will not match, the attestation fails, and the device is considered compromised.
It can be prevented by attesting that the program memory has not been altered or by using hardware such as a TPM for the dataguard generating program. Furthermore, it is interesting that the verifier sends both e and during the initialization, but it has no freshness in the actual attestation challenge. If e is a freshly generated secret, it provides the freshness, making redundant. On the other hand, it increases the entropy, making it more difficult to guess the initial dataguard.
Since there is no freshness in the attestation challenge, an old computed response can be used. That is the attacker can compute a checksum of the current dataguards and save the counter value. Then, the attacker can overwrite all the current and new dataguards. When attestation time comes, the attacker sends the computed checksum with the counter as a response and passes attestation.
If this is done as part of the update operation, the attacker will also gain the new secret and nonce, thus being able to compute valid dataguards.
This attestation scheme relies a lot on the dataguard generating program not being compromised but does not attempt ensuring it, either by attesting it or using hardware. It might also run into some performance issues. According to [
42], 150 dataguards can be stored in the list if it has 1 K memory. Furthermore, it says it can compute a dataguard in 0.01 s. It does not mention the communications overhead from update operations. The communications overhead depends on the program, as it depends on how often a dataguard is generated. If the program uses many local variables, it will generate many dataguards. Let us say the program generates 150 dataguards every hour and stores 150 dataguards in the list, then it will run the update operation with the attestation run every hour. This could be costly for battery-powered and resource-constrained IoT devices.
5.1.11. Lightweight
The attestation scheme presented in Lightweight [
43] is very similar to the second scheme of Distributed [
39]. They are both distributed schemes, in that they do not use a trusted verifier. They also both distribute the responses for an attestation challenge. Lightweight [
43] uses an initialize phase, where the responses are distributed amongst devices. It works by each device filling some attestation memory with checksums of values from other devices registers. For all registers of a device to be checked and to avoid one register to be checked by multiple devices, each register is only distributed to one other device. For this, this work assumes the memory is divided into program memory and attestation memory, both still being static memory. The two memories should be equal in size, and if the program part of the memory is not filled by whatever program is on the device, it should be filled with random noise. The initialization phase is complete when all devices have filled their attestation memory with checksums of register values from other devices.
The attestation protocol involves only two devices. Let us say device a initiates the attestation. It then picks one register from program memory and one from the attestation memory, both to be attested. It then collects the equivalent values from the devices that store them. The register from the program memory stores an actual value, so the device collects the corresponding checksum form the device that stores it, computes the checksum for its register and compares the two. The register in the attestation memory contains a checksum, so it collects the original value from the device it got the value to compute the checksum from, computes the checksum of the value it just collected and compares the two. If either of these two checks fails, both devices are terminated.
In Distributed [
39], the responses to challenges are also distributed amongst devices. Each response does, however, consider more than one register. Furthermore, it does not terminate two devices on one failed attestation, as only one device is being attested by many, done through a democratic process. Lightweight assumes the program and attestation code are stored in read-only memory to prevent it from being modified. The reason it terminates both devices, is because it is attesting both devices together on the same checksum one to one and carried out by one device. This also makes it susceptible to DoS attacks, which is considered out of scope in [
43]. One issue here is the assumption that a bad device will terminate when failing. This is assumed to happen because the code is stored in a read-only memory and cannot be changed. Furthermore, this termination procedure means that an uncompromised device is terminated for each device which fails attestation. This could mean that many uncompromised devices are terminated, which is undesirable since it could interrupt operations relying on them.
Another consideration of this is how the whole scheme is affected when many devices are terminated. If a register checksum is stored on another device, then that register cannot be attested if the device is terminated. If enough devices have been terminated, the attacker may have enough unattested memory to avoid detection. However, it requires the attacker to know which registers were in the terminated devices, which could prove difficult. Furthermore, Ref. [
43] does not explain how it deals with a device picking a register, which is stored in a terminated device, to attest.
Another interesting question for this protocol is how it would work in a more heterogeneous network. The current design focuses ona homogeneous network, where every device has the same memory size, in order for all registers to be stored on another device. Nevertheless, in a heterogeneous IoT network, this might not be possible. As an example lets consider a network with 2 devices a and b. Device a has a memory size n and device b a memory size m, where . If the memories n and m are both equally split in program memory and attestation memory, then device b could store all checksum values of device a registers, but device a would only be able to store of device b registers. Thus, not all registers of device b would be able to be attested. Even though this small example only has two devices, the problem gets more prominent in larger networks with even more different devices. It also gets more complicated if the device’s memory is not split evenly or not split equally across the same type/model of the device.
5.1.12. LRMA
Low-cost Remote Memory Attestation [
44] is building on top of SWATT [
4]. The scheme addresses the strict timing constraints imposed by SWATT. It modifies the time handling to allow for attestation of devices, not in direct contact with the verifier. Furthermore, it adds a probabilistic risk level, which is used to determine the sequence and frequency of attestation. These two parts are disjoint, so the time handling will be described first and then the risk level.
In LRMA devices any number of hops away can be attested. In most attestation schemes, only devices in direct communication with the verifier are considered. Since [
44] uses SWATT as the base attestation scheme, they need to consider the time constraints in a setting with several network messages which can be delayed. LRMA handles this by having the verifier receive the network delay for each hop in the response. It then uses these delays to compute an average and use the average to estimate to estimate the actual attestation time.
LRMA [
44] introduces the use of risk levels to determine the frequency with which a device is attested. This means that a device with a high-risk level is attested more often than a device with a lower risk level. The risk level is calculated as the sum of failed attestations in some
recent attestation runs. When determining the frequency
at which a device is to be attested, it uses the calculated risk
, the average risk level
, a time unit
T, a scaling factor
and a constant
.
The verifier uses this frequency to determine the devices next attestation time. This is done by picking a random value between zero and and adding it with the sum of the previous frequencies. If zero was picked randomly and the sum of previous frequencies was not added, it would mean the device should be attested right away; thus, the sum provides an offset. Interestingly it is a sum and not an average, which means the offset increases as time passes.
On the other hand, if a device is still terminated if it fails attestation, then the risk would reflect how often a device is compromised. Thus, saying something about that particular device having some vulnerability that needs to be fixed if it has a high-risk level. However, it might take a while for a compromised to be fixed and be allowed back on the network. When the device gets back on the network, it needs to be identified as the same device. Since it is unknown when a device will be back on the network, the next attestation time should not be determined until it is connected again.
Another way the risk level could be used is to only use it for the timeout check. If the attestation fails because the checksum does not match, then the device is terminated. However, if the time used check fails, then the risk level and attestation frequency are updated. There should then be a threshold for the risk level, so if a devices risk level surpasses the threshold, it is terminated. This will let the average time measurement of the network delay have a little more time to compute a more accurate average. However, it will also give an attacker more time to remain undetected on a device, thus increasing false negative attestations.
If the compromised device is not terminated, but just attested more often, it also introduces much bias in the performance calculations and experiments. In [
44], results of some experiments on its performance are shown. One of the experiments shows that LRMA has a lot more successful attestations and no undetected attacks after some time. In these experiments, the successful attestations are attestations that correctly detects an attack. However, if the compromised device is never terminated, and instead the compromised devices are attested more often, then at some point only the compromised devices are attested and fails because of the same attack.
Since the total number of attestation is same, it would also mean that after some time, some devices might never be attested, thus being a perfect target for an attacker in case they would learn this. By collecting and considering the network delay, this scheme should reduce the amount of false negative attestations. These false negatives would be attestation that fails because they used too much time, but the time used was actually because of network delay, not because the device was compromised.






{kind=link}