1. Introduction
Novel applications of 5G services are cataloged with three kinds of quality of service (QoS) features: massive machine-type communication (mMTC), enhanced mobile broadband (eMBB), and ultra-reliable low-latency communication (uRLLC) in 5G cellular networks [
1]. Two system architectures have been proposed for ensuring the scalability and flexibility of resource allocation and scheduling for the diverse QoS requirements. The first highly acceptable approach is the cloud radio access network (C-RAN). The baseband processing and networking functions are virtually centralized in a resource pool for resource scalability and flexibility [
2]. The other one is mobile edge computing (MEC). It supports interactive and real-time applications associated with nearby cloud hosts to obtain the required latency for addressing urgent and distributed requirements [
3]. To implement C-RAN and MEC, software-defined networking (SDN) and network function virtualization (NFV) have been integrated to develop network slicing technologies in 5G [
4]. Network slices are end-to-end (E2E) mutually separate sets of programmable infrastructure resources with independent control. A slice is a logical network adapted for particular applications regarding the diverse QoS requirements [
1].
However, SDN and NFV have paved the way for employing the slicing concept. The network slice-as-a-service (NSaaS) strategy has several problems and challenges [
4,
5]. Furthermore, the failure of virtualized network functions (VNFs) may impact the QoS for service provisioning of the control plane (e.g., MME) and the data plane (e.g., S-GWsor PDN-GWs), respectively [
4]. The related factors would be addressed and collected to design an orchestrator with the resource management efficiently and effectively for the VNFs, such as resource allocation, load balancing, and high availability (HA) for building up a high performance and robust slicing network.
Furthermore, HA is considered a high stringency requirement for providing a sustainable business with emergency response applications to support a reliable performance with zero downtime and costs. Some technologies can be adopted by the redundant array of independent discs, the replication of nodes, or master-slave database redundancy to offer data protection in an HA-equipped system [
6,
7,
8]. From the network operator perspective, 5G network slices’ resources are limited for simultaneous profit maximization. Load balancing is typically adopted by an orchestrator to achieve resource planning and provisioning and enhance performance [
4,
9].
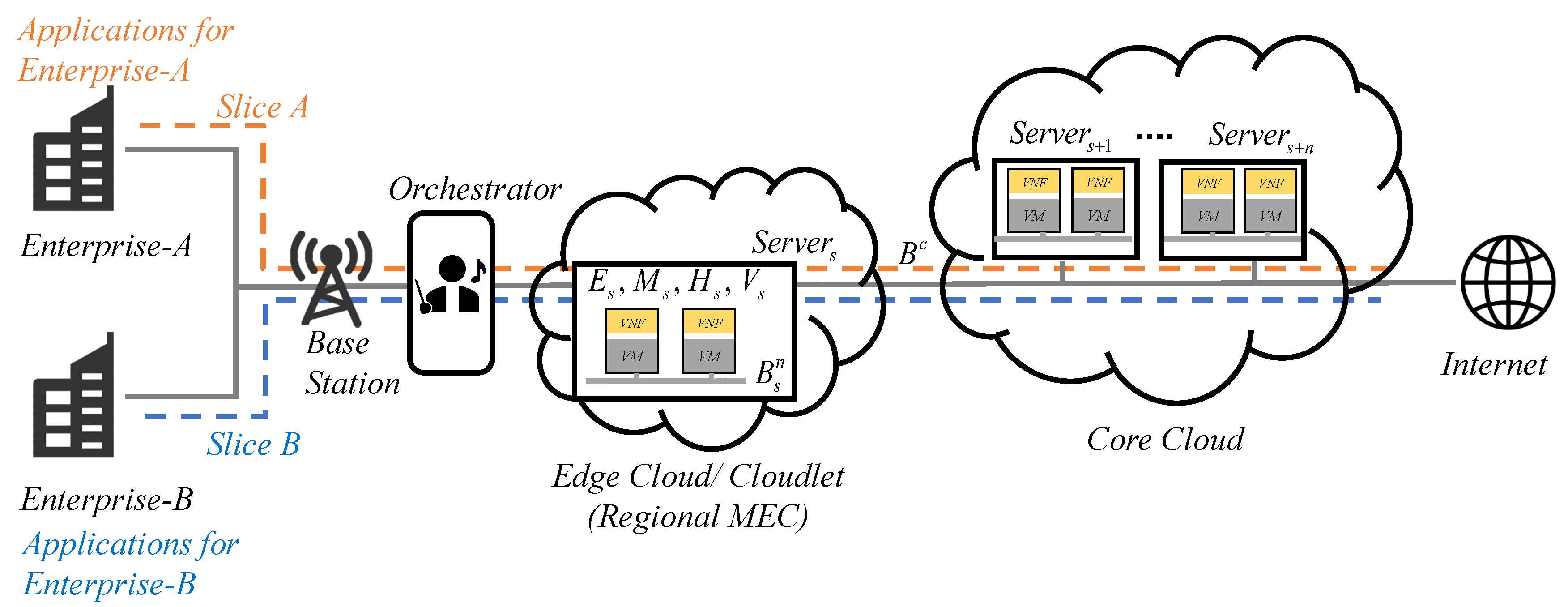
In this paper, the efficient elastic mechanisms of resource management in virtual machines (VMs) with VNFs are proposed to integrate admission control, load balancing, resource allocation, and HA arrangement in 5G network slices. The system architecture is shown in
Figure 1. An integer programming problem is formulated to maximize system utilization, subject to the quality of services, resource requirements, and HA constraints. The resource allocation problem is combined with knapsack and bin-packing problems. Generally, the VNFs or called tasks with various amounts of resource requirements emulated as VMs should be packed into a finite number of servers. A few servers in active status and then stepping forward servers by increasing demands are possible to reduce the operating costs in a bin-packing problem. A set of tasks for applications with diverse weights and values is selected for inclusion to remain within the resource limit and reach the maximum benefit, a well-known knapsack problem. Furthermore, the knapsack problem is the aforementioned combinatorial nondeterministic polynomial time (NP) hard problem. One possible solution is adopted by the Lagrangian relaxation (LR) method efficiently and effectively. Near-optimal solutions provide practical methods to overcome the bottleneck within limited computing resources of slices. The virtualization, parallel computing, and mathematical programming techniques are also developed in this paper to make near-optimal decisions from an NSaaS service provider’s perspective. The proposed resource management algorithms ensure that computing resources are equitably distributed in the slices of cloudlets and core clouds. The computation in the edge and core clouds is performed to achieve maximum resource utilization with HA and minimal cost. Moreover, the admission control scheme with the additional HA requirements is devised to admit the maximum number of jobs. Each job requires various types of resources.
The remainder of this paper is organized as follows:
Section 2 reviews related works.
Section 3 introduces the mathematical model and problem description. The LR-based solution approach is developed, as shown in
Section 4.
Section 5 presents computational experiments. Conclusions are drawn in
Section 6.
2. Literature Review
A cloud computing environment in 5G network slices supports share-based services in a pay-as-you-go approach. It provides operators with a flexible architecture from the perspective of a network operator. Resource management with complex on-demand traffic in the share-based cloud computing environment is a considerable challenge. Inappropriately designed resource management solutions might lead to the network’s increasing costs. This is related to unsatisfactory quality of services (QoS) and system reliability regarding the penalty of user experience and call-blocking probability due to the virtualized network function failure.
Table 1,
Table 2 and
Table 3 compare the resource management problems investigated with those investigated in related studies in terms of (i) resource allocation, (ii) load balancing, and (iii) admission control.
2.1. Resource Allocation
For the maximization of the benefits of the cloud system and service quality enhancement, Liu et al. [
10] developed a joint multi-resource allocation model based on a semi-Markov decision process (SMDP). They solved the optimization problem using linear programming to attain wireless resource allocation and near-optimal decisions in cloud computing. However, cloud service providers fulfill individual requirements to achieve a win-win situation for both parties in terms of computational efficiency, budget balance, and truthfulness. Jin et al. [
11] designed an incentive-compatible auction mechanism to appropriately allocate matching among cloud resources and user demands. In this auction model, the buyers are mobile devices, and the sellers are cloudlets. The nearest control center can adopt the role of the auctioneer to reduce transmission costs and latency. Furthermore, by assuming that all cloudlets can provide the same resources with distinct rewards, Liu and Fan [
12] presented a two-stage optimization strategy to achieve optimal cloudlet selection in a multi-cloudlet environment and optimal resource allocation in response to the request in the cloudlet. Studies on resource allocation in a cloud computing environment are shown in
Table 1. Resource allocation and scheduling algorithms have been proposed in numerous research areas, such as transportation management, industrial management, operational research, computer science, and particularly in real-time operating systems [
13,
14]. For instance, the earliest deadline first (EDF) is a dynamic scheduling algorithm used in real-time operating systems to allocate computing resources in central processing units (CPUs) using a priority queue. The queue searches for the task with the closest deadline; if a job cannot be completed within its time frame, the operating system must release the job. The main idea is to maximize resource use for several competing interests while balancing the load. A weighted priority for each data flow can be assigned inversely proportional to the respective flow’s anticipated resource consumption [
15,
16]. Ding et al. [
17] proposed a Linux scheduling policy with a priority queue rather than a first-in-first-out (FIFO) queue to improve kernel-based virtual machine performance. Zhao et al. [
18] proposed online VM placement algorithms to cost efficiently allocate resources to VMs to increase revenues in a managed server farm. First-fit (FF), FF migration (FFM), least reliable first (LRF), and decreased density greedy (DDG) algorithms are packing strategies relevant to task optimization for achieving desirable performance.
Table 1.
Resource allocation comparisons with existing methods. SMDP, semi-Markov decision process; EDF, earliest deadline first; FF, First-fit; FFM, FF migration; LRF, least reliable first; DDG, decreased density greedy.
Table 1.
Resource allocation comparisons with existing methods. SMDP, semi-Markov decision process; EDF, earliest deadline first; FF, First-fit; FFM, FF migration; LRF, least reliable first; DDG, decreased density greedy.
| Classification | Objective | Strategy | Related Studies | Proposed Methods |
|---|
| Resource allocation | Maximizing revenue and satisfying QoS | SMDP; auction; EDF; FIFO; FF; FFM; LRF; DDG | [10,11,12,13,14,15,16,17,18] | LR and next-fit are adopted |
| Comparison with related studies |
| This paper regards offloading tasks as virtual machines with distinct rewards with various levels of demands in the cloudlet and core cloud environment. The Lagrangian relaxation-based approach is proposed to maximize system revenue, subject to constraints such as computing capacity, assignments, and quality of service requirements. The objective is to maximize the total value of tasks by using proposed heuristics to appropriately rearrange resources using the next-fit algorithm to allocate tasks and satisfy application requirements. |
Based on the analysis of the previous studies, this paper regards offloading tasks as virtual machines with distinct rewards with various levels of demands in the cloudlets and core clouds. The Lagrangian relaxation-based approach is proposed to maximize system revenue, subject to constraints such as computing capacity, assignments, and quality of service requirements. The approach is adopted by considering finding the optimal solutions other than SMDP within limited states or constraints. The objective is to maximize the total value of tasks using proposed heuristics in polynomial time. It also appropriately rearranges resources using the next-fit algorithm to allocate tasks and satisfy application requirements.
2.2. Load Balancing
Load balancing is a crucial technology that optimizes mobile application performance. Several studies have proposed cloudlet technology solutions [
19] to achieve load balancing for mobile devices (
Table 2). Jia et al. [
19] devised a load-balancing algorithm to balance the workload among multiple cloudlets in wireless metropolitan area networks. A redirection scheme shortened the average offload task response time and improved user experience. Yao et al. [
20] studied load balancing for cloudlet nodes. The task allocation problem was formulated as an integer linear problem. A two-step centralized appointment-driven strategy was used to obtain a solution with minimal average response time and a balanced load. From a network operator perspective, time-varying and periodically changing demands are challenges in providing on-demand services. Furthermore, cloud service providers face load-balancing problems in cloud computing environments. The system availability of on-demand access should be considered using an adjustable resource assignment mechanism to satisfy QoS. If resource demands are stochastic, their accurate forecast is severe. Historical data are measured for estimating usage data to determine the load distribution and evaluate the proposed algorithm [
21].
Table 2.
Load balancing comparisons with existing methods.
Table 2.
Load balancing comparisons with existing methods.
| Classification | Objective | Strategy | Related Studies | Proposed Methods |
|---|
| Load balance | Maximum system availability | Bin packing; 0/1 knapsack | [19,20,21] | Based on the system utilization in global view |
| Comparison with related studies |
| In general, as many tasks as possible are admitted to maximize total revenue; however, the supply and demand for resources are unbalanced during peak traffic hours. This study determines which tasks are selected and dispatched to achieve maximum objective values subject to task assignment and limited capacity. The problems are classified as bin-packing and 0/1 knapsack problems. Herein, the assignment decisions are based on resource utilization functions, including a central processing unit, random access memory, hard drive, and bandwidth for each server type. The assignment strategies are designed to fit the QoS requirements, such as those of computing and transmission in variant traffic loads in a global view adopted by the heuristics of bin-packing strategies. |
In general, as many tasks as possible are admitted to maximize total revenue; however, the supply and demand for resources are unbalanced during peak traffic hours. This study determines the orchestrator’s decisions for which tasks are selected and dispatched to achieve the maximum objective values subject to task assignment and limited capacity. The problems are classified as the bin-packing and 0/1 knapsack combined problems. Herein, the orchestrator’s decisions are based on resource utilization functions, including a central processing unit, random access memory, hard drive, and bandwidth for each server type. The orchestrator’s objective is also designed for that assignment strategy fitting the QoS requirements, such as those of computing and transmission in variant traffic loads in a global view adopted by the heuristics of bin-packing strategies.
2.3. Admission Control
Preventing server overload and ensuring application performance are the goals of admission control [
22]. This mechanism decides whether to admit a particular service request to the server. It is implemented for meeting QoS requirements and achieving service providers’ expected revenue [
23]. Hoang et al. [
24] developed a semi-Markov decision process (SMDP)-based optimization model for mobile cloud computing that considers constraints such as resources, bandwidth, and QoS to perform admission control tasks. This framework ensures QoS performance and maximizes the reward. Xia et al. [
25] aimed to optimize cloud system throughput. An effective admission algorithm based on the proposed resource cost paradigm to model various resource consumptions was devised according to the online request following the current workload.
Table 3 presents the comparison of the admission control methods.
Table 3.
Admission control comparisons with existing methods.
Table 3.
Admission control comparisons with existing methods.
| Classification | Objective | Strategy | Related Studies | Proposed Methods |
|---|
| Admission control | Maximum QoS and throughput | SMDP; priority; no-priority; 0/1 knapsack | [22,23,24,25] | Non-priority and Lagrangian multipliers are adopted |
| Comparison with related studies |
| The semi-Markov decision process (SMDP) approach relies on partial data, such as resources, bandwidth, and quality of service (QoS), to decide whether to accept or reject a task. SMDP computing time is inefficient for jobs with time constraints, such as delay and delay tolerance sensitive applications. The priority of user information is unknown for decision making under a computing time constraint. In this paper, call admission control mechanisms within the conditions with non-priority and QoS constraints are jointly considered. The Lagrangian relaxation-based approach is proposed to maximize system revenue combined with the proposed resource allocation methods to admit tasks and satisfy application requirements appropriately. |
The SMDP-based approach relies on partial data. The computing time is also inefficient for jobs with time constraints, such as delay and delay tolerance sensitive applications. The priority of user information is unknown for decision making under a computing time constraint. In this paper, call admission control mechanisms within the conditions with non-priority and QoS constraints are jointly considered. The Lagrangian relaxation-based approach is proposed to maximize system revenue combined with the proposed resource allocation methods to appropriately admit tasks and satisfy application requirements.
2.4. Research Scope
This research focuses on resource management in various scenarios in 5G network slices. An optimization-based approach (LR) is used to solve the mathematical programming problem to maximize system revenue. In our proposed cloud computing framework (cloudlets and core clouds) in 5G network slices, two primary research questions are considered. What is the most efficient algorithm for resource allocation within admission control, resource scheduling, and load-balancing policies in a limited-resource cloud computing environment? Is the HA of VMs considerably influenced in the system?
Additionally, the problem is addressed under rapidly increasing data traffic conditions and a limited resource pool to obtain near-optimal policies using a combination of LR approaches. The solutions satisfy the QoS-related constraints in transmission and stand on computation perspectives to fulfill the throughput, delay, and delay jitter requirements. They are compared with other resource management schemes for efficiency and effectiveness.
3. Mathematical Formulation
A mathematical model is proposed to manage an optimization programming problem. It focuses on developing a well-designed algorithm in a parallel computing environment for admission control, resource scheduling, and an HA arrangement to maximize cloud service provider profits in 5G network slices. Based on the combined cloudlet and core cloud network architecture (
Figure 1), VMs with VNFs are requested by various applications and require specific resources. They should be allocated to the server
k with computation and transmission capacities concerning CPU, RAM, storage, and internal or shared bandwidth, expressed as
,
,
,
, and
, respectively, in cloudlets and core clouds. The proposed model in the orchestrator supports network resource management in front of the cloudlet and core cloud environments when assuming that resource management strategies are followed when facing a batch of requests.
Table 4 and
Table 5 present lists of the given parameters and decision variables.
The system’s profit is the combination of the rewards of admitting applications, the penalties of rejecting the other applications, and the cost for turning on the servers.
The objective function
is shown in Equation (
1), and its goal is to maximize system profits among all VMs requested by the applications.
To acquire the highest revenue, the optimization problem is shown as:
where C1–C3 belong to the admission control and assignment constraints, C4–C9 belong to the capacity constraints, and C10–C12 belong to the HA constraints.
For admission control and assignment constraints, is the total number of standard or additional HA VMs required by an application, in which the VMs are in disjoint sets, where in constraint C1. is the number of standard VMs that must be admitted and allocated into servers. is the number of admitted and allocated HA VMs. The total number of allocated HA and standard VMs should be greater than or equal to the requirement, as shown in constraint C1. That is, while application i is completely served, the summation of and should be greater than and equal to the demand on the right-hand side of constraint C1.
and are shown in the constraints C2 and C3, which means when the value of or is less than or equal to one, the VMs are inseparably assigned to servers. In other words, a virtual machine is not partially allocated to servers.
For capacity constraints, the resources offered by a server are defined as a set of four factors: the maximum number of VMs in the server s (), the processing capacity of each CPU core (), the RAM capacity (), and the storage capacity (). The total resources required by VMs for each server cannot exceed its available resources as formulated in the constraints C4–C7.
We also set the internal bandwidth rate (
) in the server
s for internal transmission between VMs. For example, two applications,
i and
, and their index sets of VMs are
,
,
, and
, as shown in
Figure 2. The link between VM
and VM
represents the internal bandwidth required by VM
to connect to VM
in server
s. The constraint C8 indicates that the total bandwidth required by all the VMs should not exceed the internal bandwidth
in server
s. The external bandwidth rate (
) is set for the transmission between servers in the cloud computing environment (cloudlets and core clouds), as illustrated in
Figure 2. The link between server
and server
s represents the bandwidth requested by VM
to connect to VM
. The constraint C9 indicates that the total bandwidth required by all VMs accepted by servers in a cloud should not exceed the external bandwidth.
In this work, we assume two kinds of VMs, standard VMs and VMs with HA, of the same application, cannot be assigned to the same server, as shown in
Figure 2. In the beginning, all servers contain no VMs; then, for example: application
i comes in and needs two standard VMs and one VM with HA, as mentioned in the previous paragraph. First, we put two standard VMs, VM
and VM
, in server
, while the two kinds of VMs cannot be assigned to the same server, then VM
has to be assigned to server
s. To continue, the next application
comes in, and we put its standard VMs
and
in server
and server
s, respectively, while server
and server
s have no residual capacity to handle one more VM. Meanwhile, the VM with HA, VM
, cannot be put in server
or server
s due to our exclusive assumption. Thus, VM
is assigned to server
.
For HA configuration constraints, the decision variable for application i is set for the VM assignments. The index sets j and ℓ for different kinds of VMs must be collocated to server s and separated into different servers, where and . The relationships are expressed as the constraint C12. The constraints C10 and C11 indicate the server power status. If any VM is admitted and assigned to server s, server s must be powered on, and should be set to one. The constraint C12 assures that when VMs j and ℓ are assigned to the same server s, which means that and are both set to one, the exclusive setting must also be one. In other words, the standard VM and the HA VM requested from the same application cannot be allocated to the same server s.
4. Lagrangian Relaxation-Based Solution Processes
The Lagrangian relaxation method is proposed for solving large-scale mathematical programming problems, including optimization problems with linear, integer, and nonlinear programming problems in many practical applications [
26]. The key idea is to relax complicated constraints into a primal optimization problem and extend feasible solution regions to simplify the primal problem. Based on the relaxation, the primal problem is transformed into an LR problem associated with Lagrangian multipliers [
27,
28,
29].
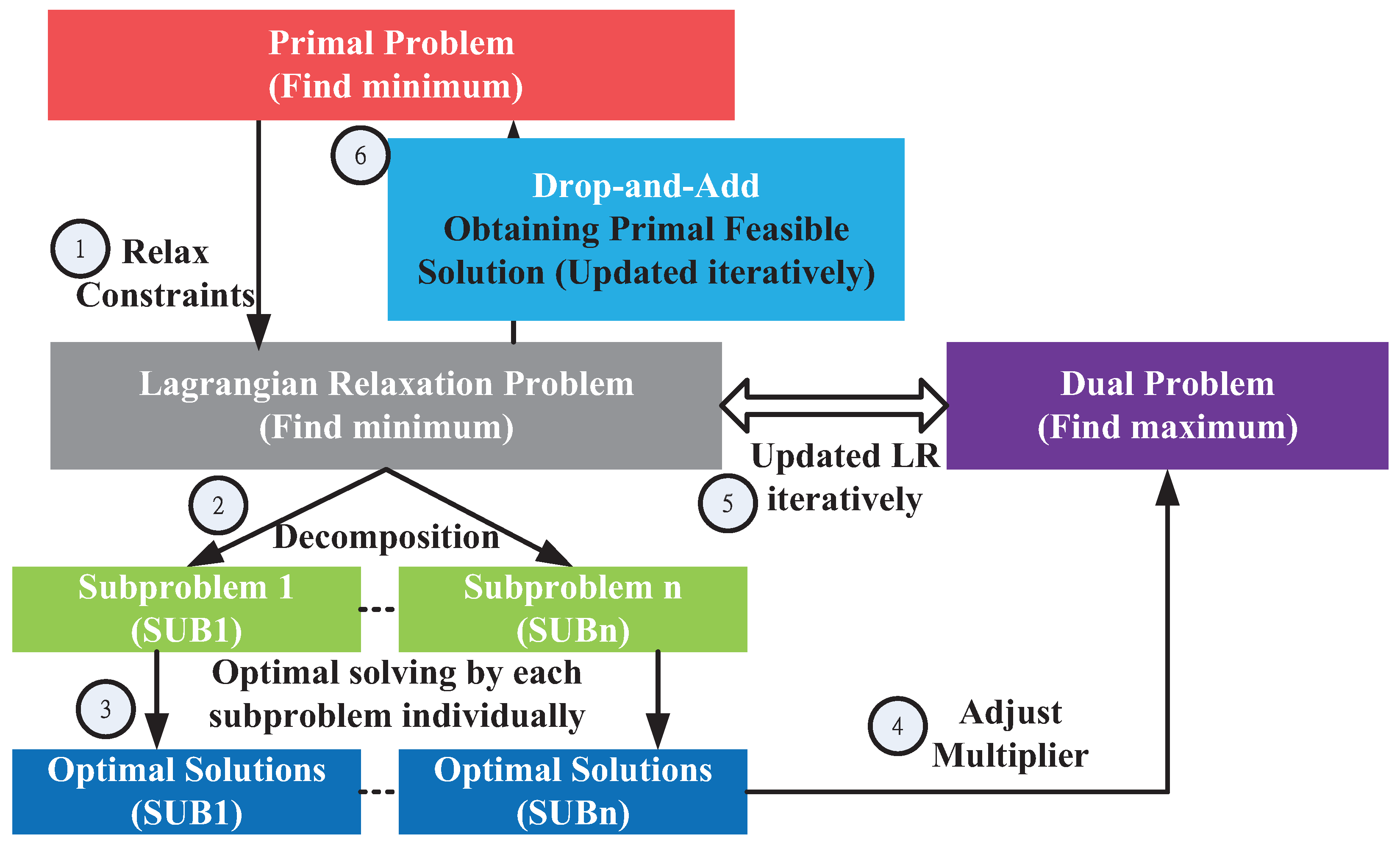
Figure 3 illustrates the six procedural steps in the LR method.
4.1. Procedures of Step 1: Relaxation
To separate the feasible region of the primal problem into several subproblems with an independent set of decision variables, the primal problem is transformed into an LR problem. The relaxation method associated with Lagrangian multipliers is applied to the constraints C1 and C4–C13 in Step 1, as presented in
Figure 3. Then, the constraints C1 and C4–C12 with the multipliers are added to the primal problem Equation (
1), as shown in Equation (
2) and denoted as
.
Then, the optimization problem can be reformulated as:
where
,
,
,
, and
.
4.2. Procedures of Steps 2 and 3: Decomposition and Solving Subproblems
The LR problem can be decomposed into several independent subproblems, with their related decision variables. The divide-and-conquer approach is used to solve the subproblems correspondingly.
4.2.1. Subproblem 1 (Related to )
By extracting items with decision variable
, the optimization problem of Subproblem 1 can be developed as:
Equation (
3) can be divided into
independent subproblems. For each application
i, where
, the decision variable
is set to one when the coefficient
is less than zero. Otherwise,
is set to zero. The run time is
, and the pseudocode is illustrated in Algorithm 1.
| Algorithm 1: Subproblem 1. |
Input: Given parameters , , , and Lagrangian multipliers . Output: Decision variable . Initialize:, for to do if then end if end for
|
4.2.2. Subproblem 2 (Related to )
By extracting items with decision variable
, the optimization problem of Subproblem 2 can be developed as:
Equation (
4) can be divided into
cases. The decision variable
is set to one, and the minimum coefficient
is less than zero and corresponds to alliance subindices
i,
j, and
s. To satisfy the constraint C2, the decision variable should be set to one only if the minimum coefficient with subindex
s is a required sorting processes. Otherwise,
is set to zero. The run time is
. The pseudocode is illustrated in Algorithm 2.
| Algorithm 2: Subproblem 2. |
Input: Given parameters and Lagrangian multipliers . Output: Decision variable . Initialize:, for to do for to do for to do end for Find the index m that has the minimum value in . if then end if end for end for
|
4.2.3. Subproblem 3 (Related to )
By extracting items with decision variable
, the optimization problem of Subproblem 3 can be developed as:
The solution process of Equation (
5) is similar to that of Equation (
4) and can be also divided into
subproblems. The decision variable
is set to one when the minimum coefficient
is less than zero and corresponds to alliance subindices
i,
ℓ, and
s. Otherwise,
is set to zero. The run time of this subproblem is
. The pseudocode is illustrated in Algorithm 3.
| Algorithm 3: Subproblem 3. |
Input: Given parameters and Lagrangian multipliers . Output: Decision variable . Initialize:, for to do for to do for to do end for Find the index m that has the minimum value in . if then end if end for end for
|
4.2.4. Subproblem 4 (Related to )
By extracting items with decision variable
, the optimization problem of Subproblem 4 can be developed as:
Equation (
6) can be divided into
cases. For the alliance subindices
i,
j,
ℓ, and
s, the decision variable
is set to one when the coefficient
is less than zero. Otherwise,
is set to zero. The run time is
. The pseudocode is illustrated in Algorithm 4.
| Algorithm 4:Subproblem 4. |
Input: Given parameters and Lagrangian multipliers , , . Output: Decision variable . Initialize:, for to do for to do for to do for to do if then end if end for end for end for end for
|
4.2.5. Subproblem 5 (Related to )
By extracting items with decision variable
, the optimization problem of Subproblem 5 can be developed as:
Equation (
7) can be divided into
or
cases. In each case with subindex
s, the decision variable
is set to one when the coefficient
, which corresponds to alliance subindex
s, is less than zero. Otherwise,
is set to zero. The run time is
or
, and the pseudocode is illustrated in Algorithm 5.
| Algorithm 5: Subproblem 5. |
Input: Given parameters and Lagrangian multipliers , . Output: Decision variable . Initialize:, for to do for to do for to do end for for to do end for end for if then end if end for
|
4.3. Procedure of Step 4: Dual Problem and the Subgradient Method
According to the weak Lagrangian duality theorem [
30], the objective values of the LR problem
are the lower bounds (LBs) of the primal problem
with multiples
,
. The formulation of the dual problem (D) is constructed to calculate the tightest LB (
), where max
. Then, the dual problem can be formulated as:
The subgradient method is commonly used for solving the dual problem by iteratively updating the Lagrangian multipliers [
26,
31,
32].
First, let vector be a subgradient of . In the th iteration of the subgradient optimization procedure, the multiplier vector is updated by . The step size is determined by equation . The denominator is the sum of relaxed constraints concerning to the decision variable values based on the th iteration. is the primal objective value in the th iteration. is the objective value of the dual problem in the th iteration. is a constant, where . Accordingly, the optimal objective value of the dual problem is obtained iteratively.
4.4. Procedure of Step 5: Obtaining the Primal Feasible Solutions
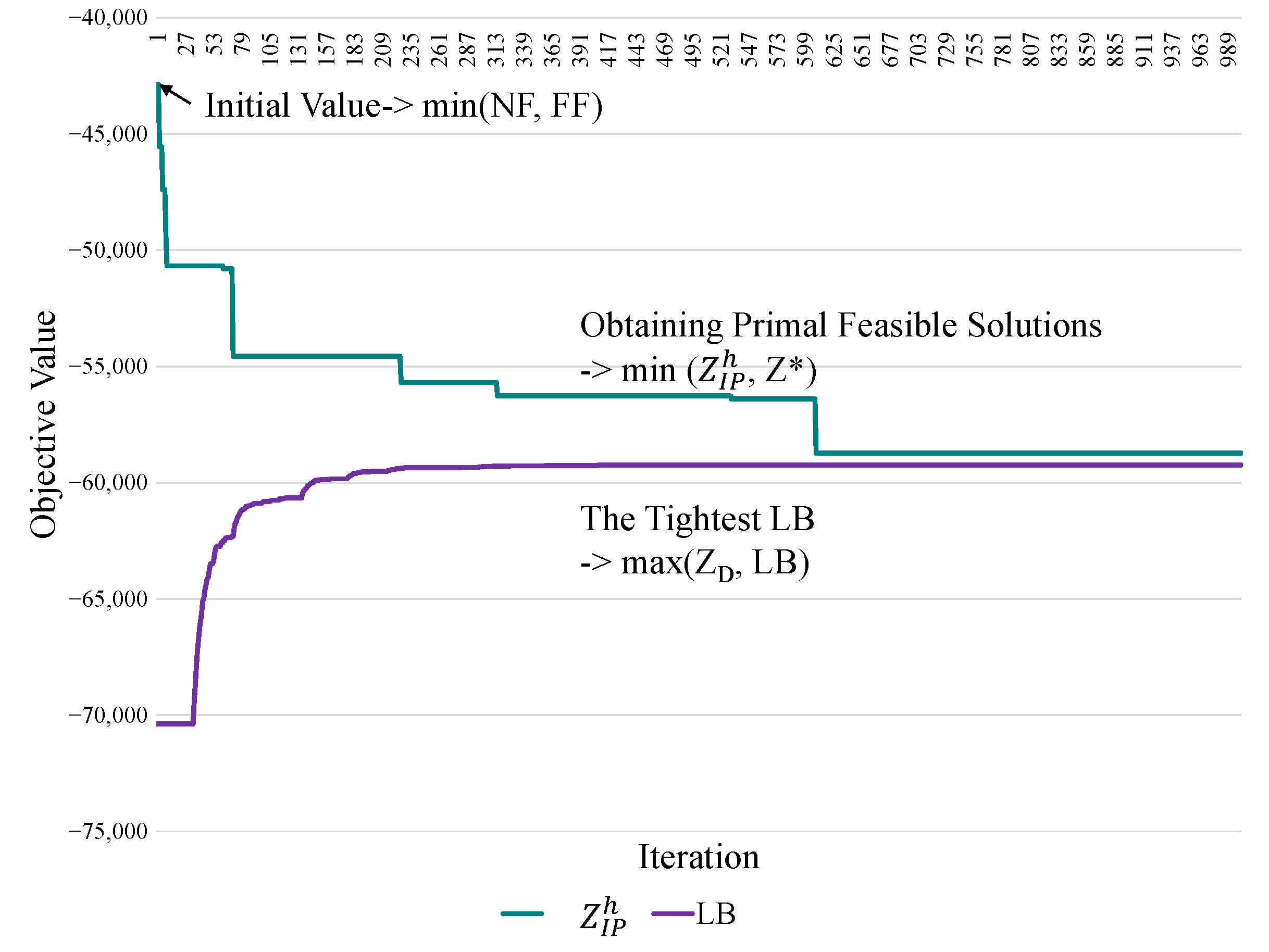
Applying the LR and the subgradient methods to solve the LR and dual problems determines a theoretical LB from the primal feasible solution. Crucial information regarding the primal feasible solution can be identified [
28]. The feasible region of a mathematical programming problem defined by the solutions must be satisfied by all constraints. A set of primal feasible solutions to
is a subset of the infeasible region solutions to
or
. Several alternative methods can be used sophisticatedly to obtain the primal feasible solutions from the observations of the infeasible region. For example,
Figure 4 presents an experimental case. The green curve represents the process of obtaining the primal feasible solutions iteratively. The objective is to identify the minimum value of the primal problem (
). Then, the LBs are determined using the subgradient method to iteratively obtain the tightest LB (max
), represented by the purple line. The proposed resource management approach for obtaining primal feasible solutions is called the drop-and-add algorithm. It is a heuristic-based allocation mechanism for optimizing the objective function. It searches for a solution that satisfies not only all the user demands, but also the constraints. The initial solution is adopted using next-fit (NF) or first-fit (FF) as baselines for evaluating solution quality [
33]. The proposed algorithm, FF, and NF are simultaneously implemented for result comparison.
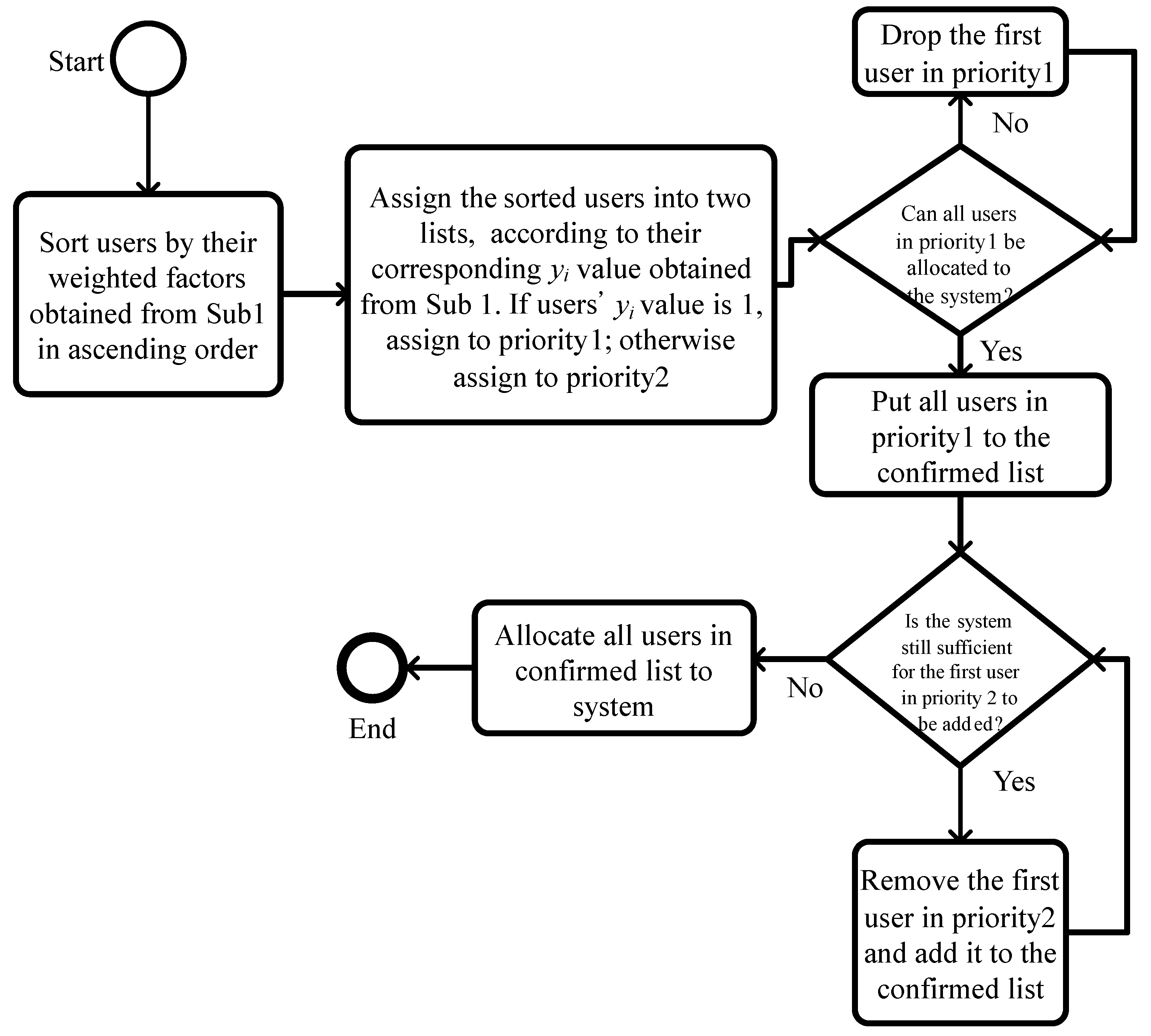
4.5. Procedure of Step 6: Drop-and-Add Algorithm
Lagrangian multipliers determined from the dual problem have significant values for evaluating the sensitivity of objective value improvement [
26,
28,
30,
32]. Through the subproblems, the integrated weighting factor of applications is represented in (
3) as
; therefore, the sum of the values can be used as an index to interpret the application’s significance of
i. The corresponding multipliers determine the ordering set of admitting, assigning, and scheduling decision variables. The other decision variables
or
and the assignment of indices
j,
ℓ, and
s can be regarded as two bin-packing problems. The VM
j can be packed into the server
s. The VM
ℓ can be packed into servers except server
s to comply with the HA conditions for
. For performance evaluation, NF is adopted for sequentially performing the algorithm of assignment for
and then
. The flowchart of the drop-and-add algorithm is shown in
Figure 5.
5. Computational Experiments
A cloud service provider’s resource parameters and the applications’ demand attributes were simulated in a cloud computing experimental environment and are presented in
Table 6.
means a number uniform distributed between the parameters of
x and
y.
The algorithms were constructed and implemented to analyze solution quality and improvement ratios (IRs) in several simulation cases. Solution quality is defined as the objective value gap (denoted as GAP) between the proposed algorithm and the LR problem, which is expressed as , where is the objective value of applying the drop-and-add algorithm and is the objective value of the LR problem. is expressed as . is expressed as , where and are the objective values of employing the NF algorithm or FF algorithm, respectively. The experiments were developed in Python and implemented in a VM on a workstation with a quad-core CPU, 8 GB RAM, and Ubuntu 14.04. The traffic loads of tasks and arrival time intervals were randomly generated. The experimental environment was initialized for a data center including edge and core clouds. VMs were requested by applications to represent computing requirements. Based on resource admission control strategies and scheduling models, the VMs were packed into the corresponding servers in the cloud computing environments.
5.1. Performance Evaluation Case: Traffic Load
This experiment was designed to analyze VMs requested by applications in a time slot, which can be interpreted as a snapshot of the system loading. First, the trend of the objective function with the number of applications as the control variable was examined. The result in
Figure 6 indicates that the objective value of (IP)increases with the number of applications. The drop-and-add and LB values were almost the same in some cases (20∼80), indicating that the optimal solution was determined when the GAP was less than 0.80% (the minimized one was 0.60%).
Table 7 compares drop-and-add with NF or FF (higher values are preferable) in the primal problem. The maximum IR was 89.48%, with 180 applications in both FF and NF. The penalty of unsatisfied applications significantly increased the objective value for indicating when arriving applications exceeded system capacity with the NF or FF algorithm in the cases of the number of applications being over 100. Otherwise, the drop-and-add algorithm can select valuable applications to pack into servers, which results in a higher objective value than NF or FF in the cases of the number of applications being over 100.
5.2. Performance Evaluation Case: Number of Servers
The cost function is emulated as the capital expenditure (CAPEX) of the cloudlets and core clouds related to network infrastructure deployment of appropriate levels of servers, where the budget is a significant constraint. The cost difference between high- and low-end servers is also typically significant. Service providers generally conduct a comprehensive system analysis to determine the methods of how to manage, control, and operate a system appropriately. The plans, such as turning servers on or off, provide sufficient QoS to applications efficiently and effectively. Furthermore, the servers purchased were deployed at four levels with different capacities in this experiment. Nonhomogeneous servers were deployed under the same limited budget. The rapid increases in data traffic are represented as traffic loads to determine which method delivered superior QoS for applications at affordable costs and preserved revenue. The following are the experimental scenarios tested.
Figure 7 and
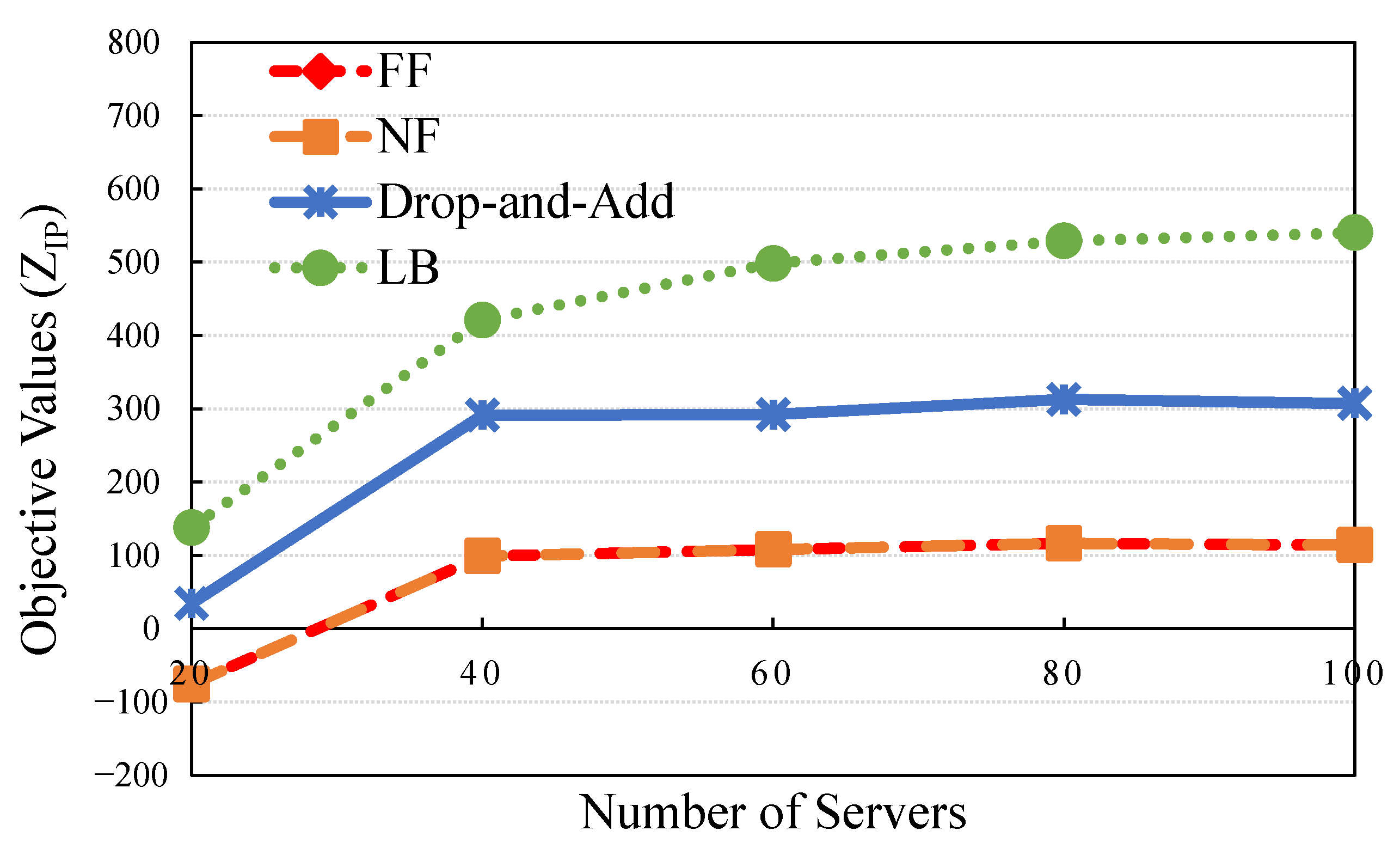
Table 8 present the results of the proposed methods (drop-and-add, LB, NF, and FF). The drop-and-add algorithm attained the most practical objective value (higher is preferable) compared with NF and FF in the case of 40.
Regarding the GAP, some values in the other situations were calculated to determine the difference in rate value between drop-and-add and LB. The GAP values indicate that the minimum value (44.62%) was determined in one of the cases with numerous servers (40). A data center has sufficient resource space in servers with the drop-and-add, NF, and FF algorithms. The maximum improvement ratio is represented by the ratio of improvement of feasible solutions and was 193.73% in numerous servers (i.e., 40). The result reveals that the resource allocation algorithm has a significant impact on system performance with a limited resource constraint.
5.3. Performance Evaluation Case: Effect of HA
As far as crucial business requirements are concerned, cloud service providers should offer high quality, excellent availability, good performance, and reliable services. In this case, the applications are divided into levels by using VM replication for HA requests. The VMs requesting to be in the
set with HA by the application
i asking for VM placement must be mutually and exclusively allocated into different physical servers. The level of exclusivity is called the dual-rate. In the subsequent experiment, the dual-rate was the parameter configured for HA VMs. Moreover, a dual-rate of 0.5 indicates that the HA VMs,
, requested by half of
for application
i are allocated to different servers. The dual-rate equals 0.3, which indicates 30% of standard VMs required for application
i with HA capability. In
Figure 8, it is evident that the dual-rate significantly affected the application satisfaction rate. Thus, the drop-and-add algorithm offers more benefits (higher values are preferable) than NF or FF in the dual-rate cases. The improvement ratios increased significantly when the dual-rate was higher than 0.3, and the maximum IR was 608.39%. The drop-and-add algorithm achieved flexibility and efficiency and could sufficiently obtain the maximum objective value to deal with HA requests. As observed in
Table 9, FF and NF performed poorly when the dual-rate was beyond 0.3. The tasks were not assigned to appropriate servers with HA. This resulted in turning on more servers, which corresponded to cost generation.
5.4. Performance Evaluation Case: Time complexity comparison
Table 10 shows the time complexity of the LR-based solution for resource management in a sliced network. We added an existing scheme, brute force, for comparison in
Table 10. The time complexity of this scheme was higher than the proposed LR-based algorithm. Furthermore, the corresponding explanations were included to support our statements. The time complexity of the proposed LR-based solutions was
.
Table 10 shows the time complexity of the LR-based solution. The Lagrange dual solution was determined by Sub-problems (
4)–(
6), which were solved using the minimum algorithm with
servers. Each sub-problem required
time minimum coefficient among servers. Since the sub-problems were solved individually by divide-and-conquer algorithms, the time complexity for each of the sub-problems was constant. Thus, the worst case of time complexity among these subproblems was considered significant in each iteration. The Lagrange dual solutions for the sub-problems could be obtained after a maximum number of iterations
N, and the time complexity was
. The number of iterations pre-defined to converge was about 600 based on the experiment results shown in
Figure 4. Fortunately, all given parameters and multipliers for the solution did not need the same initial values. The convergence was achieved in a small number of iterations with the previous execution results. Furthermore, the proposed algorithms can be set as the output results at any complete iteration. Thus, the time can be controlled in practice.
5.5. Discussion
To test the proposed algorithm, we designed three experiments involving changes in application demands, the cost of servers, and dual-rates for HA with application requests, as shown in
Table 11. The research problem was formulated as a mathematical programming problem to determine both admission control and resource scheduling problems from a service provider perspective. Overall, the drop-and-add algorithm is the most effective for obtaining the optimal solution in the fewest iterations. The optimization-based energy-efficient admission control and resource allocation algorithms have significant benefits in cloud computing systems. The significance of applications was inspired by the coefficient of (
3), which sorts applications by a composition of application weights, client satisfaction, and high availability. Therefore, using the LR-based solution approach with multipliers to obtain the primal feasible solutions was suitable for allocating VMs to servers efficiently and effectively. The mathematical formulation was decomposed into five subproblems. It was solved optimally using parallel computation techniques to reduce computation time substantially. Furthermore, the experimental results reveal and confirm that the drop-and-add algorithm was active in a few minutes by the most significant in the sliced network stages shown in
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11. The following suggested problems and limitations of this paper can be further studied and solved: QoS requirements can be classified into more categories. Resource sharing between multiple service providers is a new research problem that necessitates considering related issues, such as the sharing economy, from multiple network service provider perspectives. Hence, operator pricing policies could be a worthwhile topic.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







