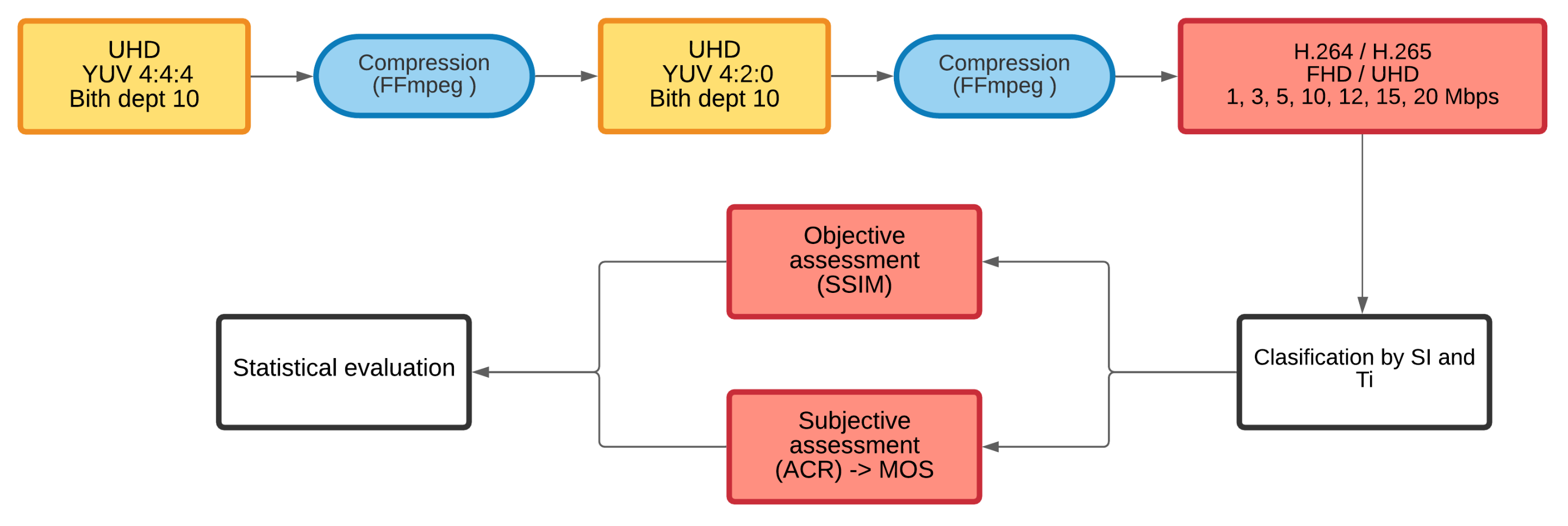
Figure 1.
The process of coding, classification, and evaluation of quality.
Figure 1.
The process of coding, classification, and evaluation of quality.
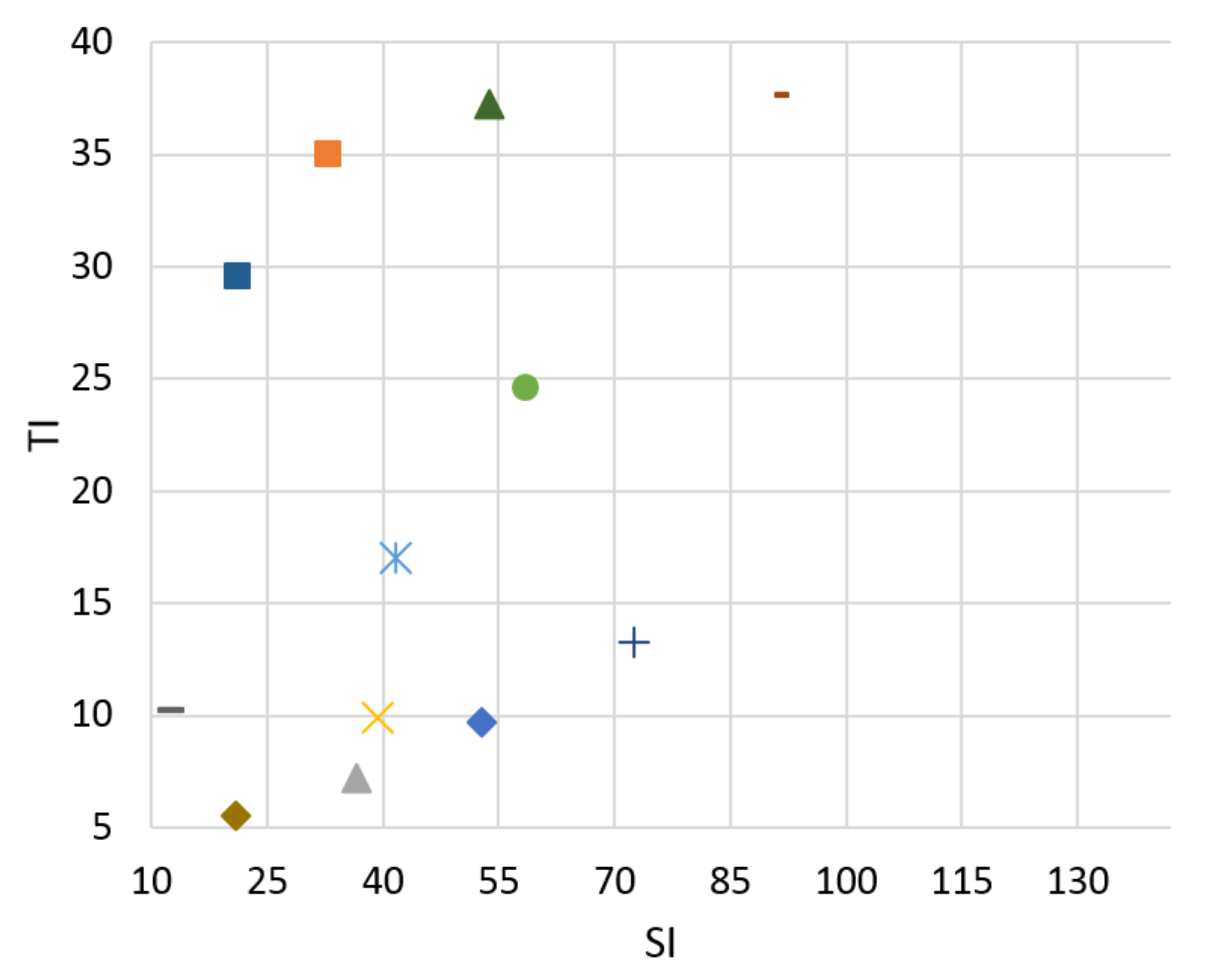
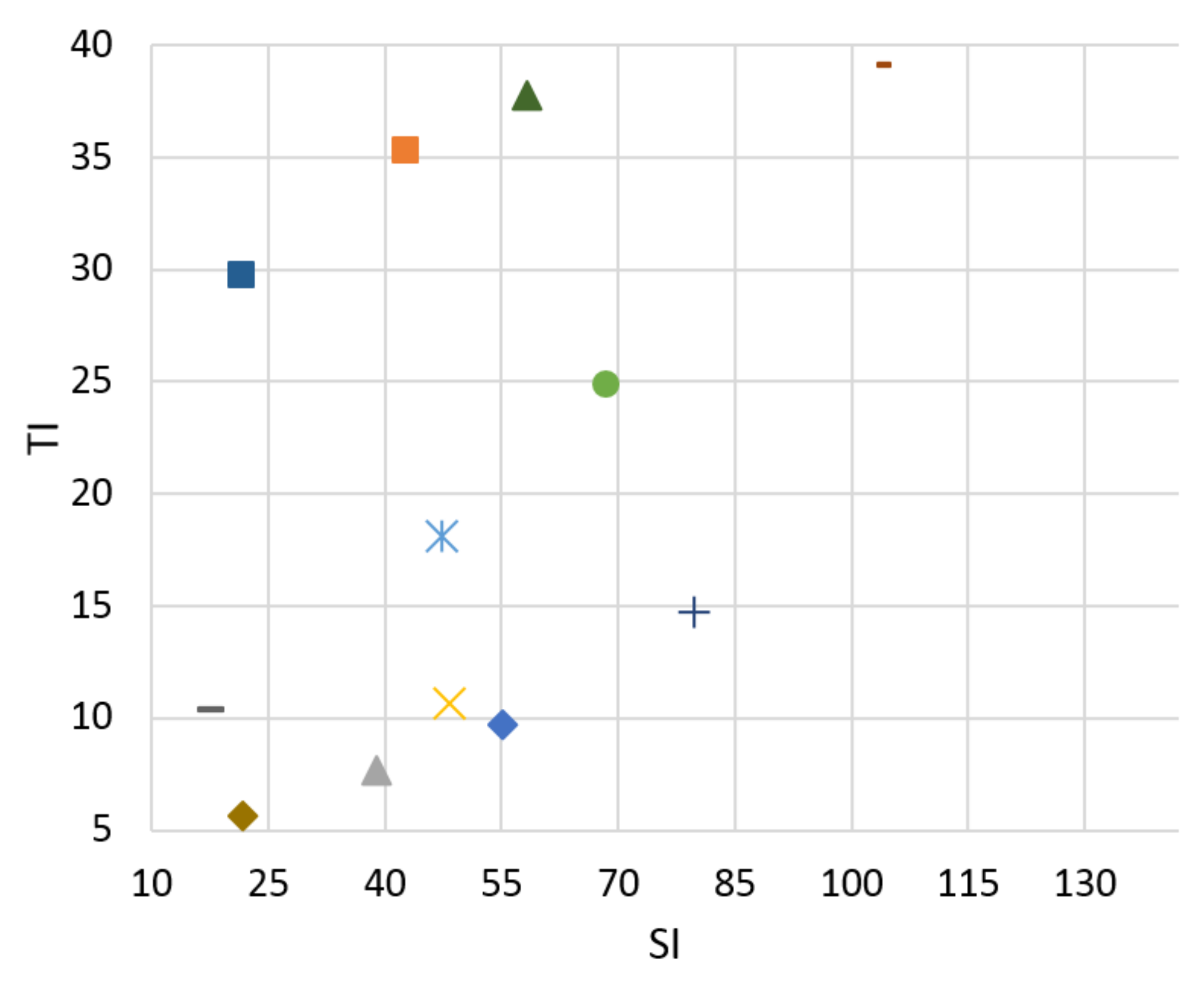
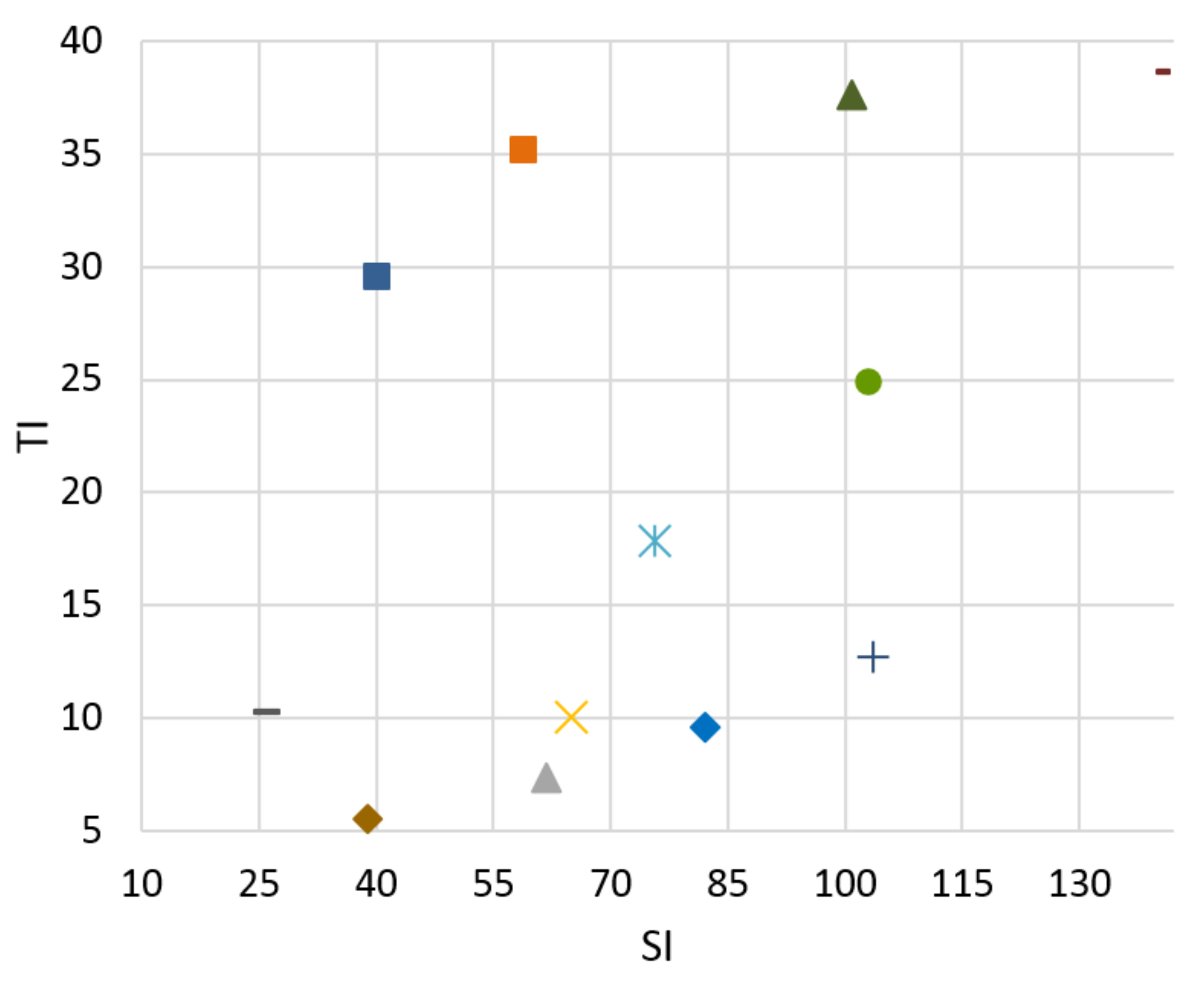
Figure 2.
Spatial information (SI).
Figure 2.
Spatial information (SI).
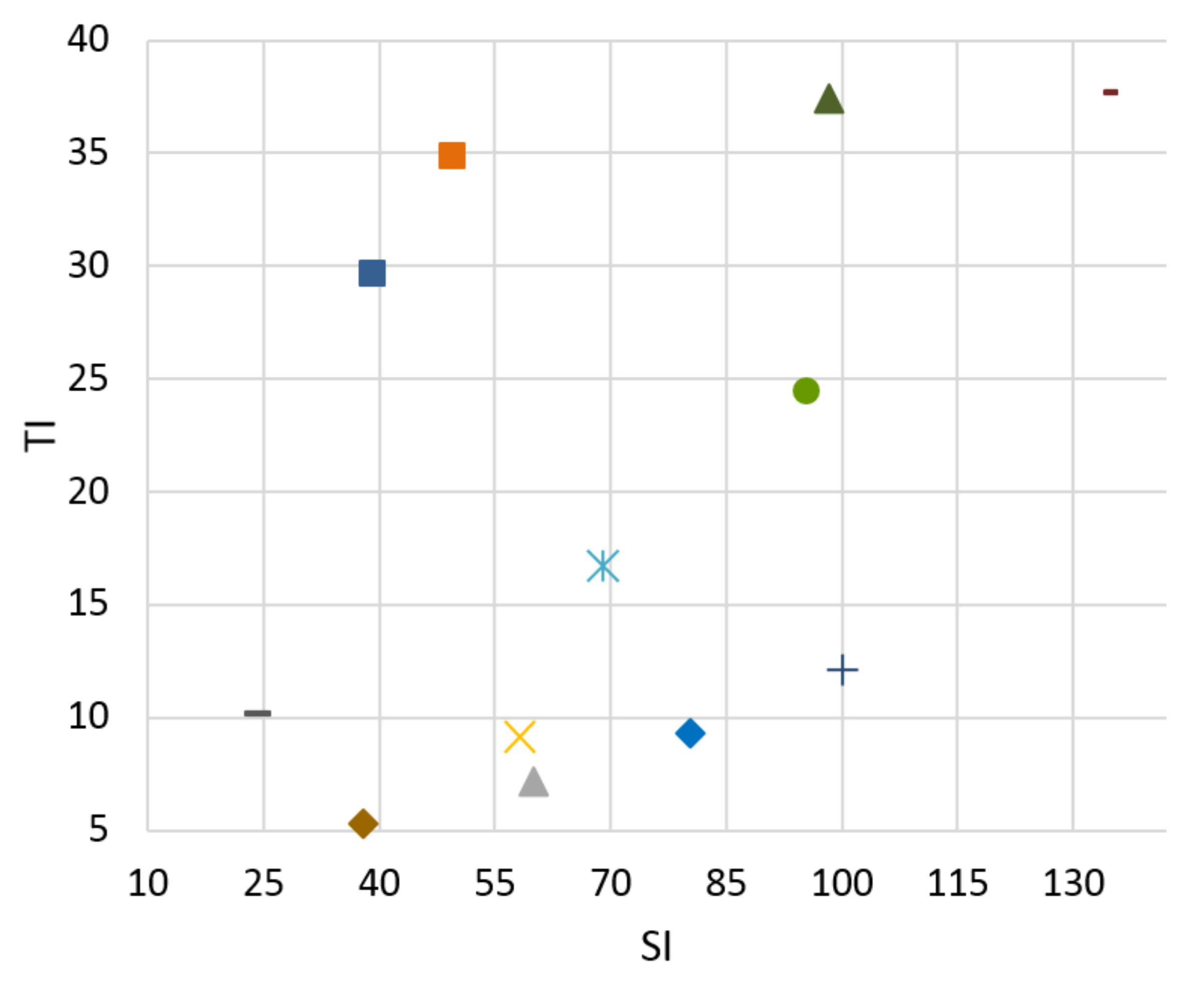
Figure 3.
Temporal information (TI).
Figure 3.
Temporal information (TI).
Figure 4.
Ultra HD, H.265, bitrate 3 Mbps.
Figure 4.
Ultra HD, H.265, bitrate 3 Mbps.
Figure 5.
Ultra HD, H.265, bitrate 20 Mbps.
Figure 5.
Ultra HD, H.265, bitrate 20 Mbps.
Figure 6.
Full HD, H.265, bitrate 3 Mbps.
Figure 6.
Full HD, H.265, bitrate 3 Mbps.
Figure 7.
FULL HD, H.265, bitrate 20 Mbps.
Figure 7.
FULL HD, H.265, bitrate 20 Mbps.
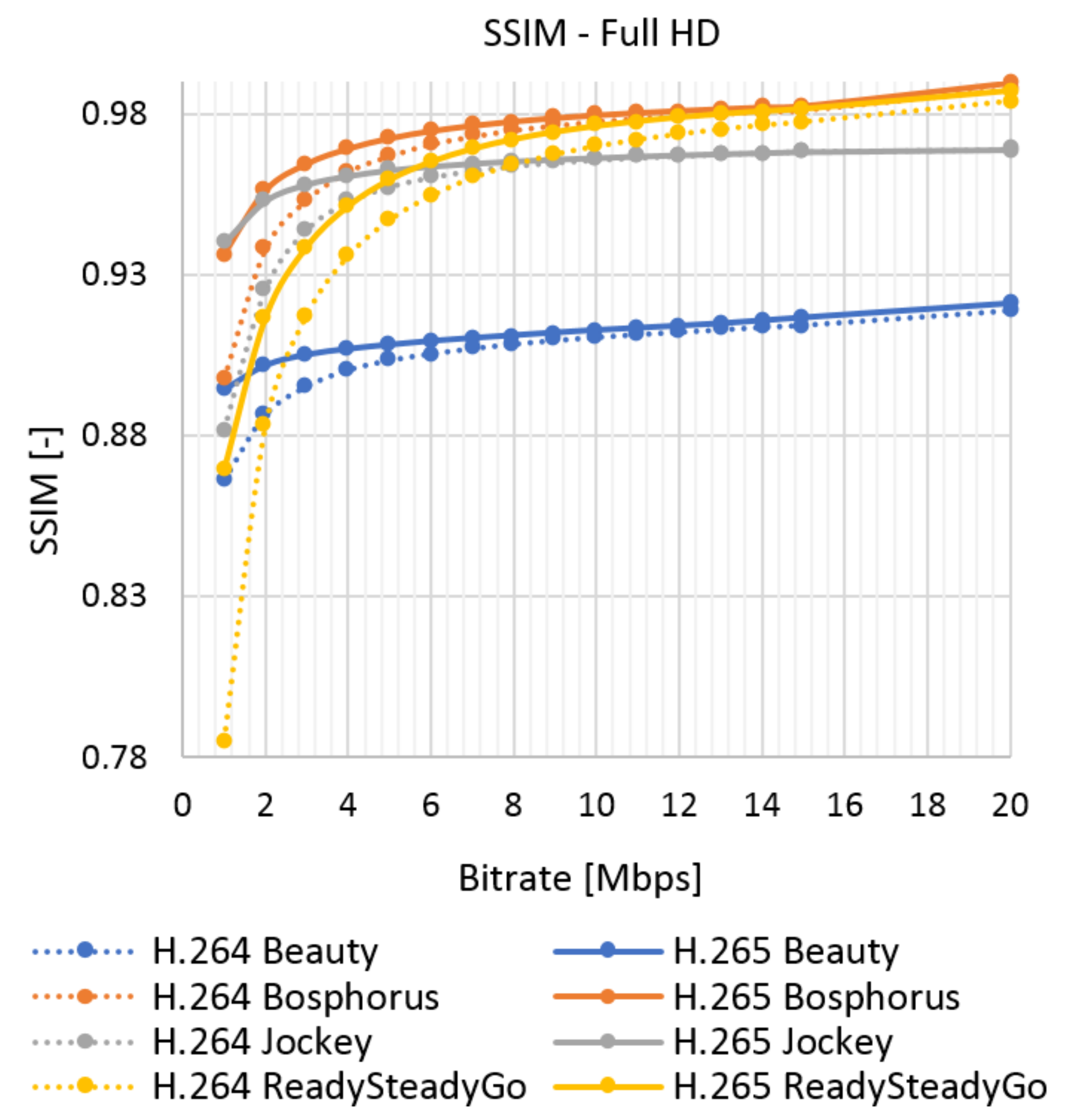
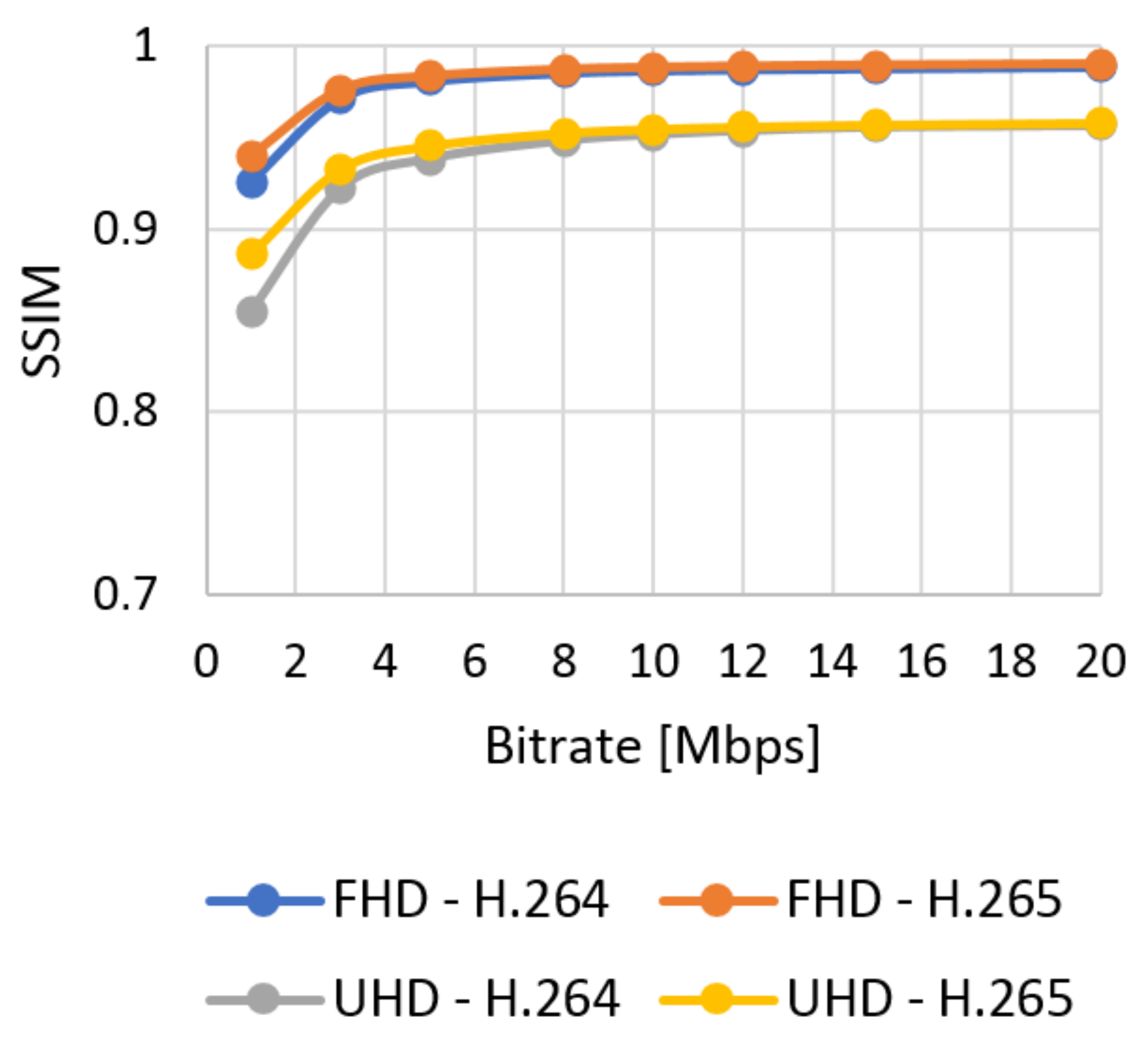
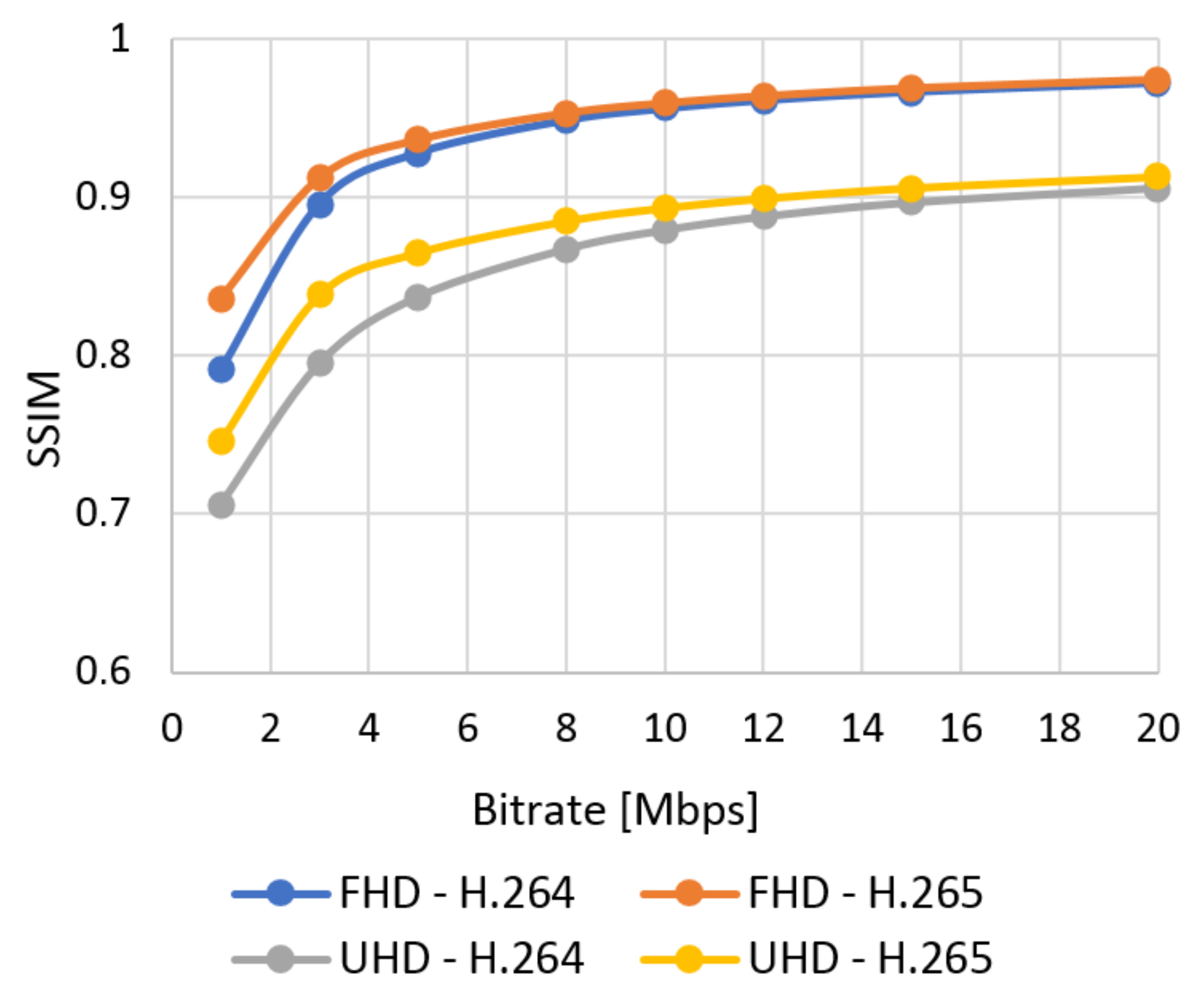
Figure 9.
SSIM evaluation of Ultra Video Group (UVG) sequences—Full HD.
Figure 9.
SSIM evaluation of Ultra Video Group (UVG) sequences—Full HD.
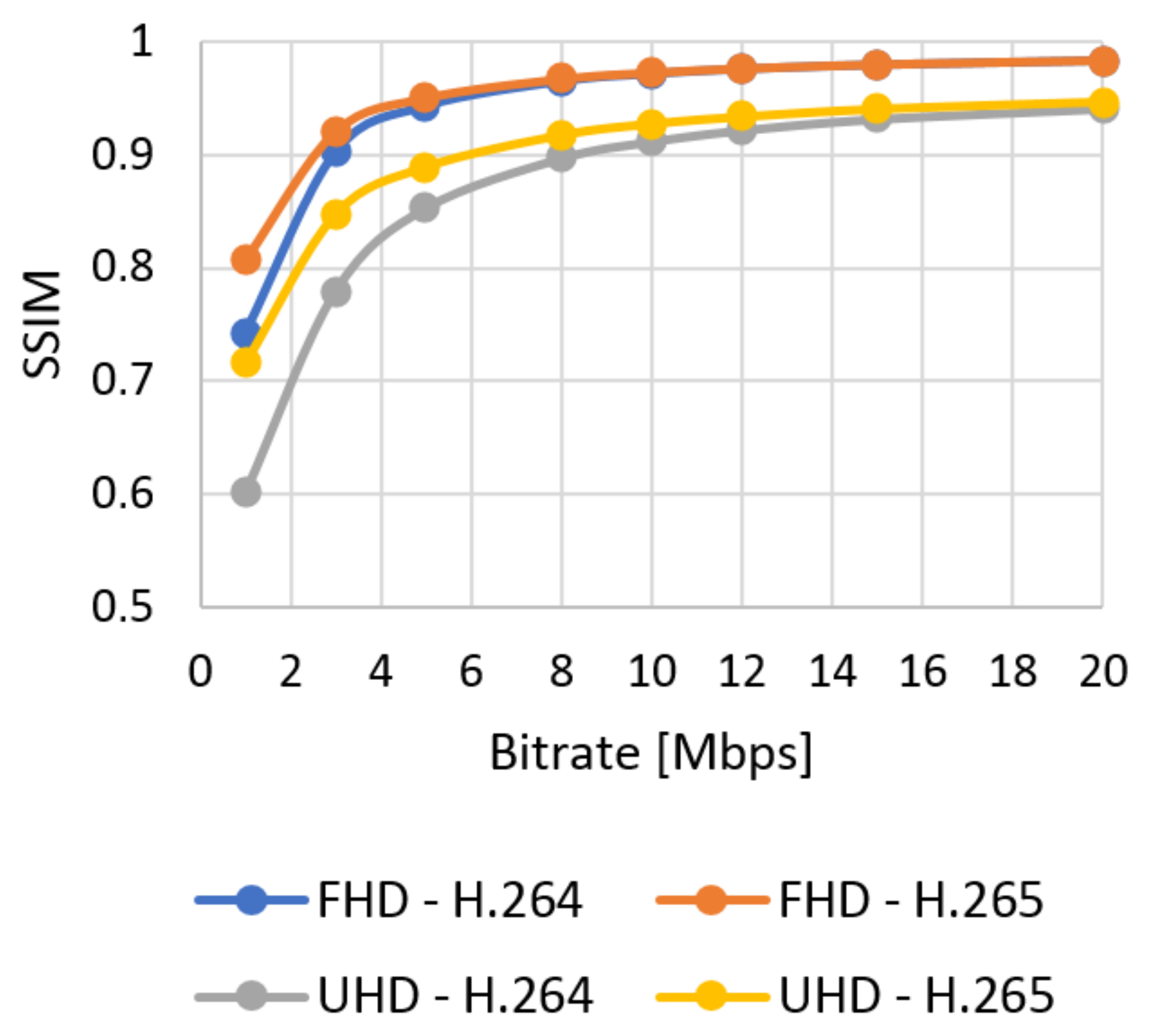
Figure 10.
SSIM evaluation of UVG sequences—Ultra HD.
Figure 10.
SSIM evaluation of UVG sequences—Ultra HD.
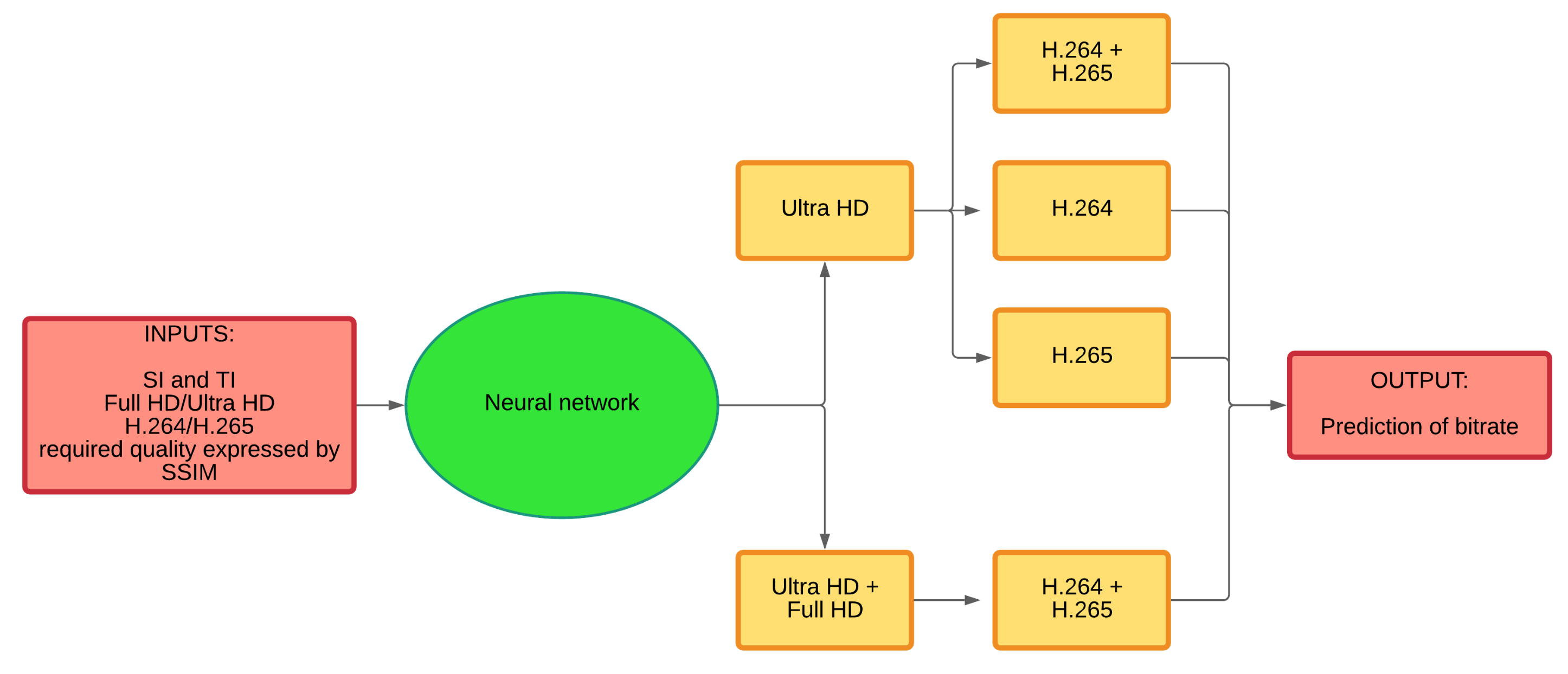
Figure 11.
An example of the neural network.
Figure 11.
An example of the neural network.
Figure 12.
Bund Nightscape, subjective evaluation.
Figure 12.
Bund Nightscape, subjective evaluation.
Figure 13.
Wood, subjective evaluation.
Figure 13.
Wood, subjective evaluation.
Figure 14.
Bund Nightscape, objective evaluation.
Figure 14.
Bund Nightscape, objective evaluation.
Figure 15.
Wood, objective evaluation.
Figure 15.
Wood, objective evaluation.
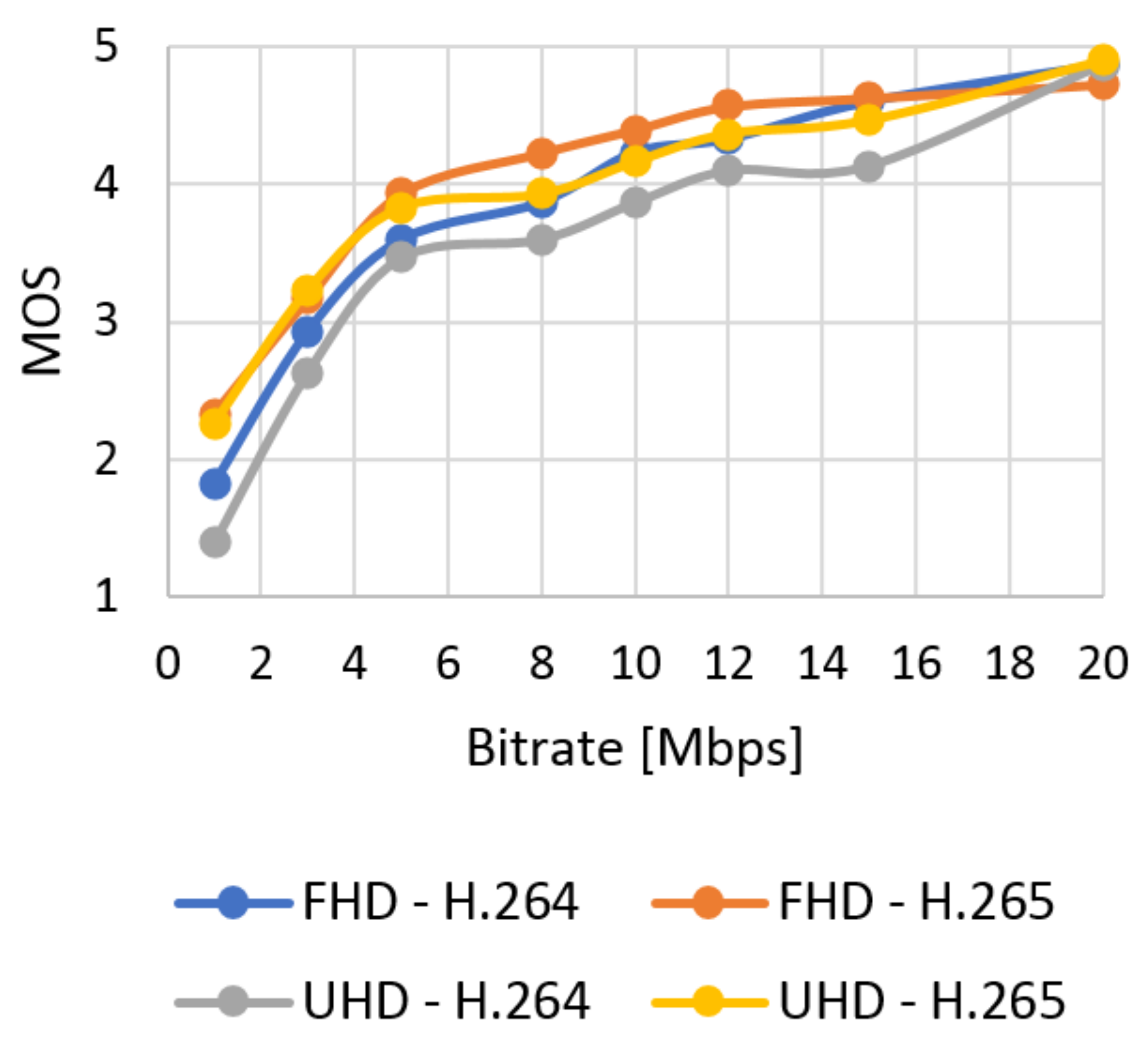
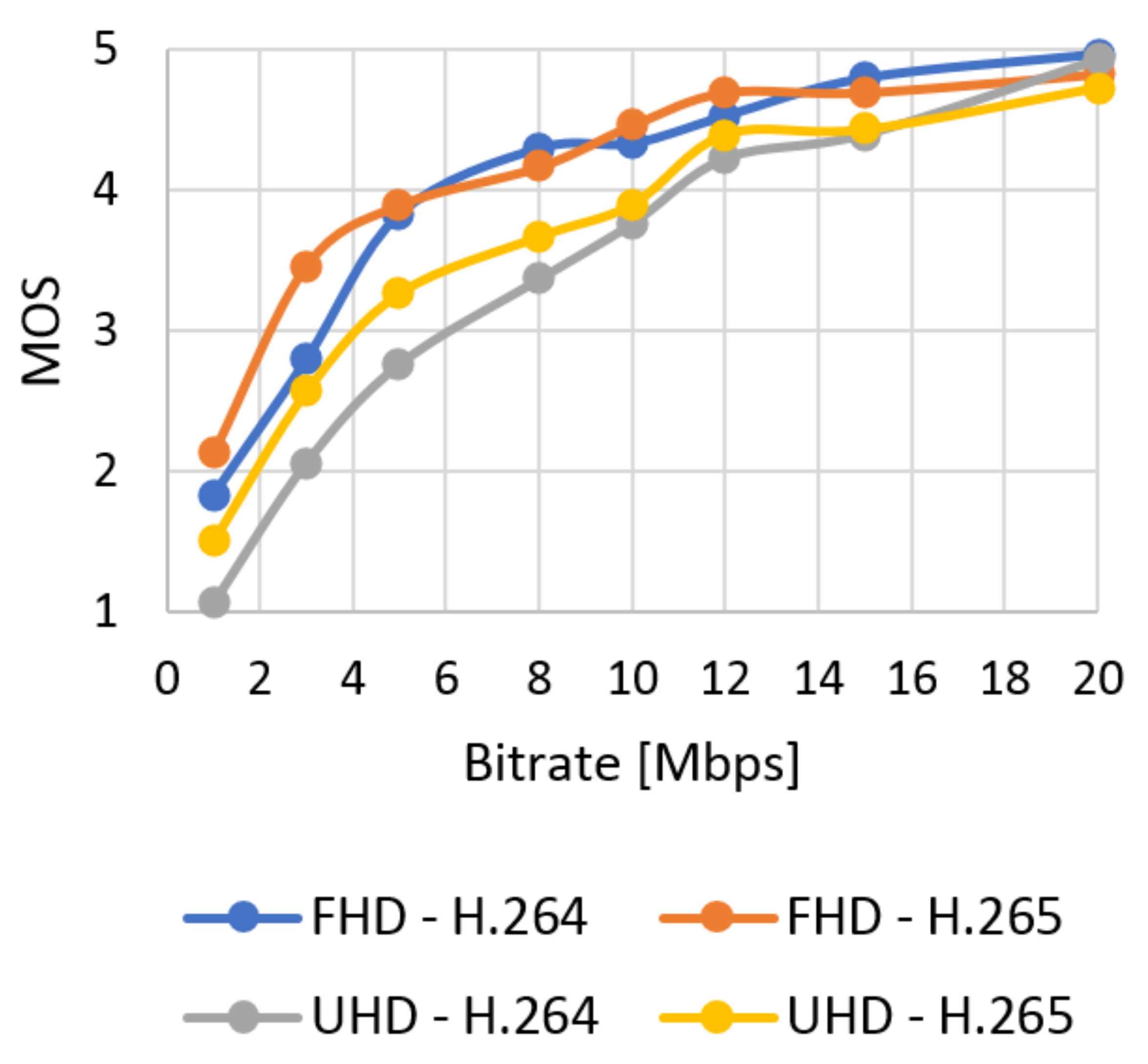
Figure 16.
The average results of MOS.
Figure 16.
The average results of MOS.
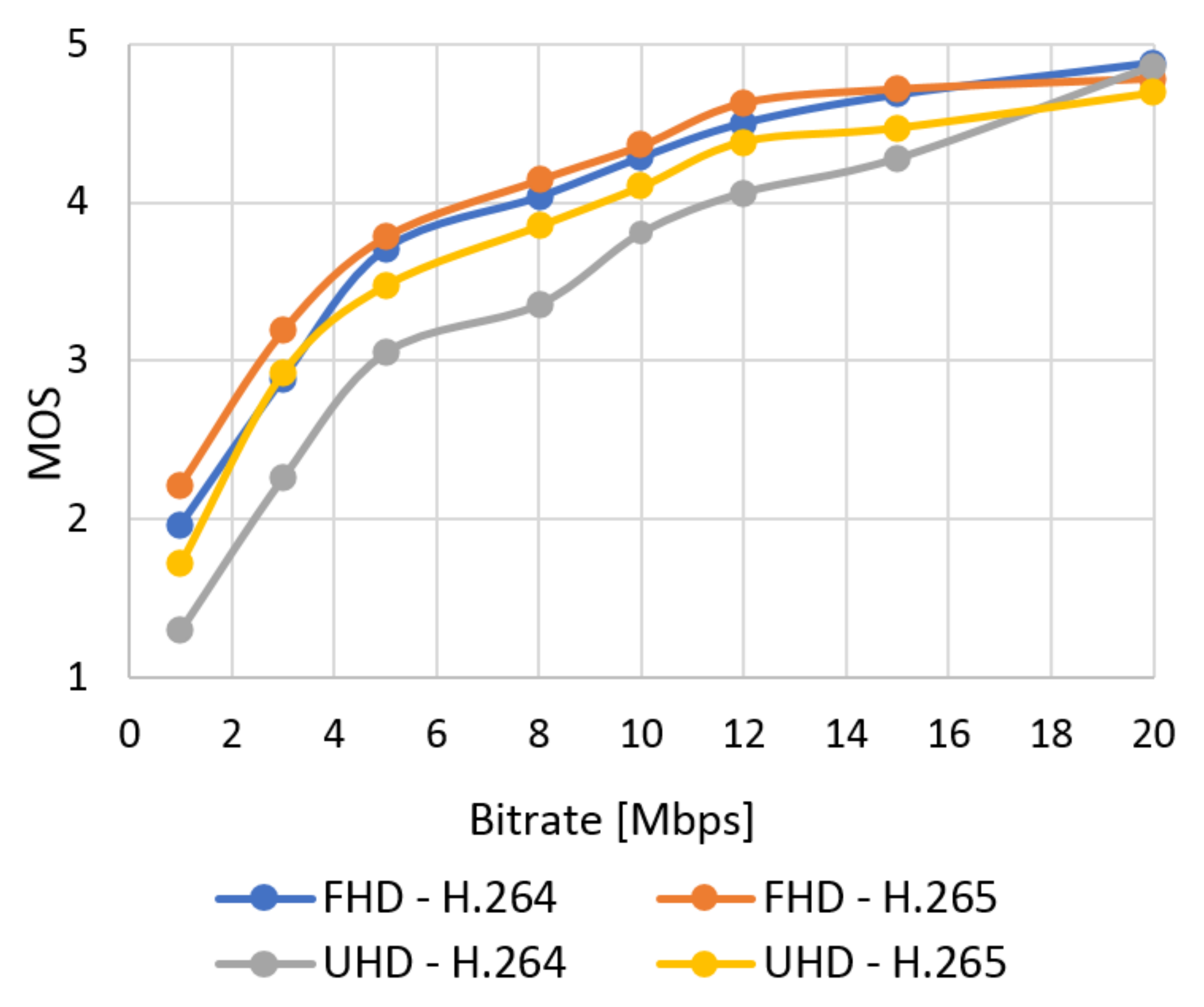
Figure 17.
The average results of SSIM.
Figure 17.
The average results of SSIM.
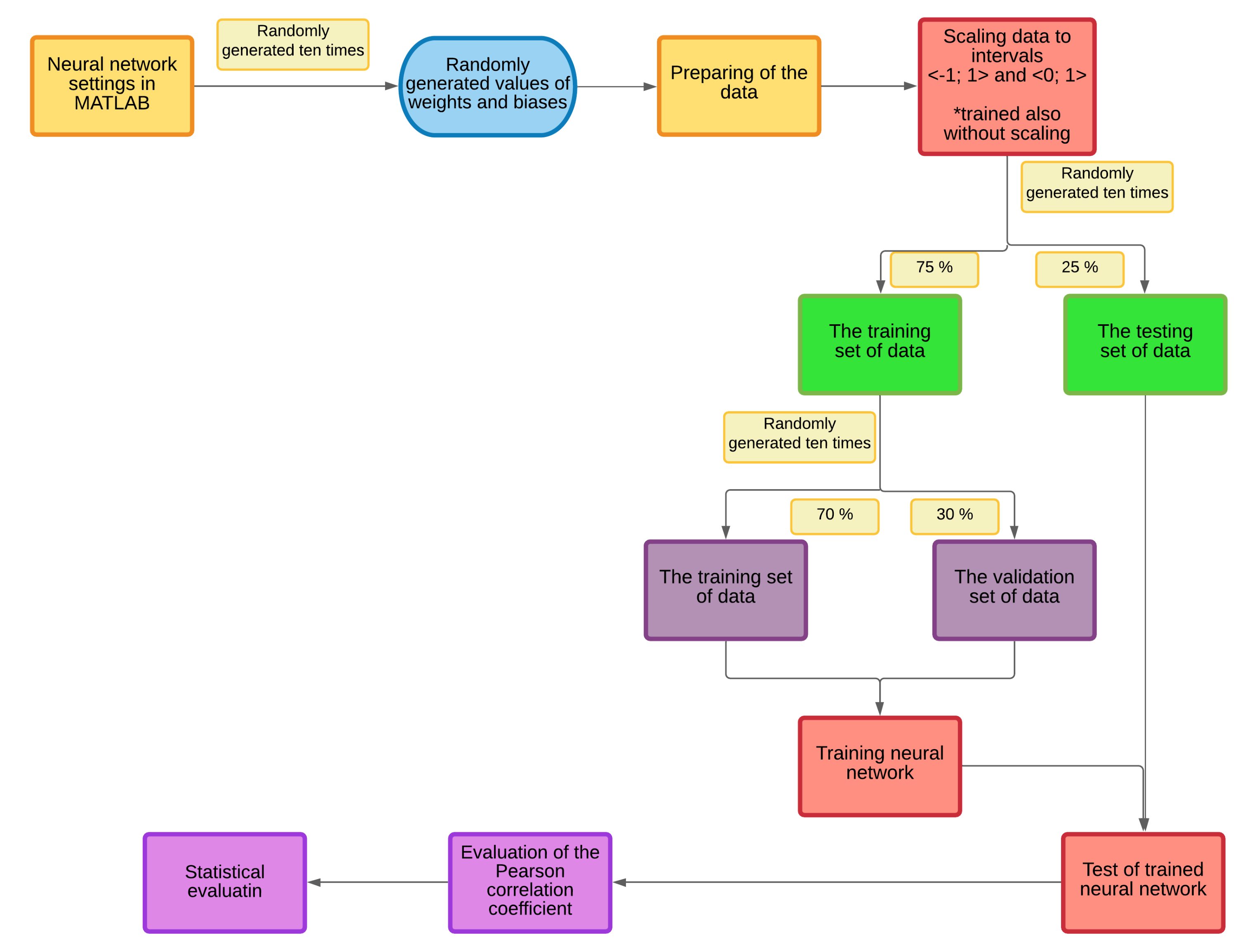
Figure 18.
The process of creating the neural network.
Figure 18.
The process of creating the neural network.
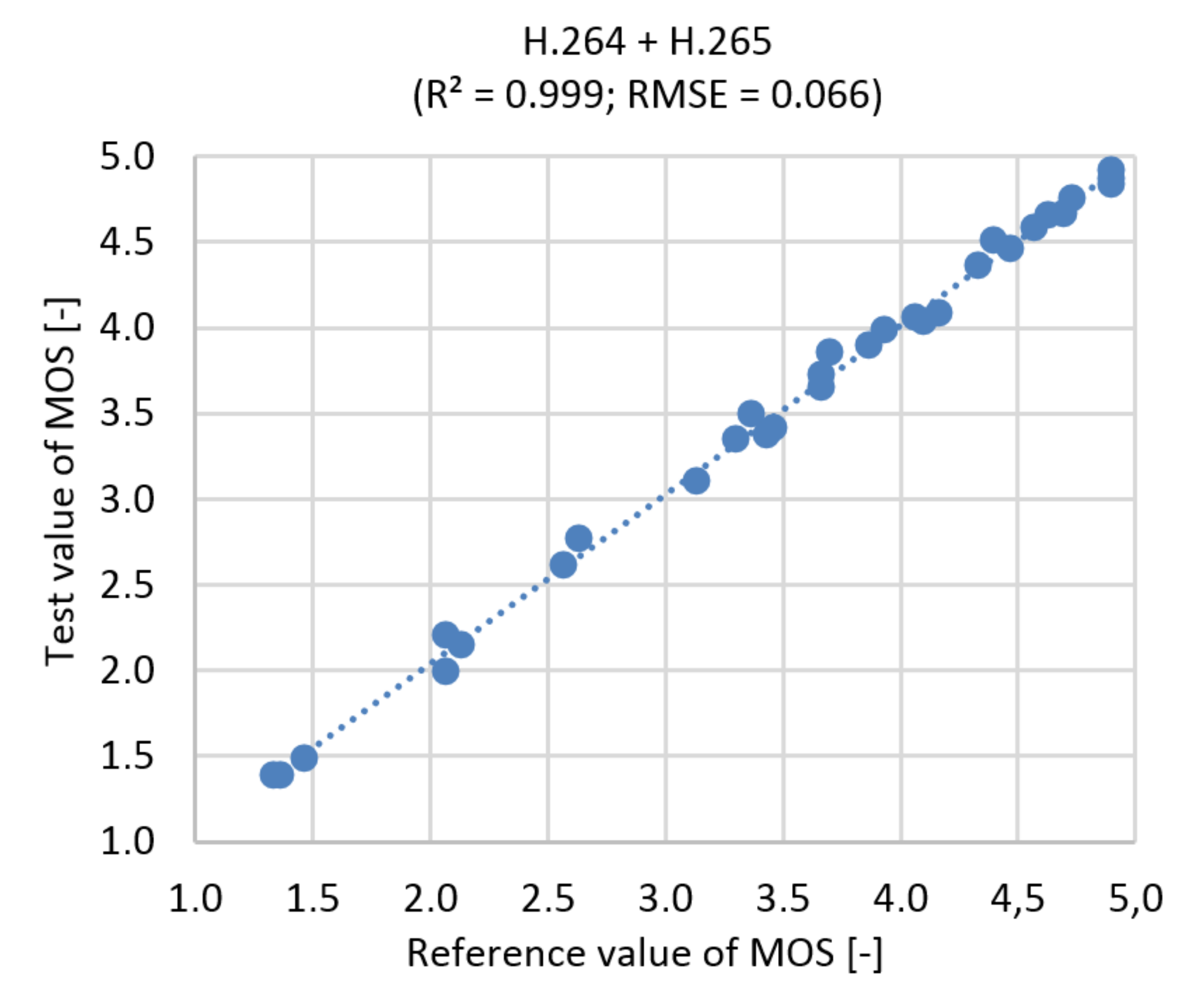
Figure 19.
Correlation diagram for MOS prediction, Ultra HD, H.264 + H.265.
Figure 19.
Correlation diagram for MOS prediction, Ultra HD, H.264 + H.265.
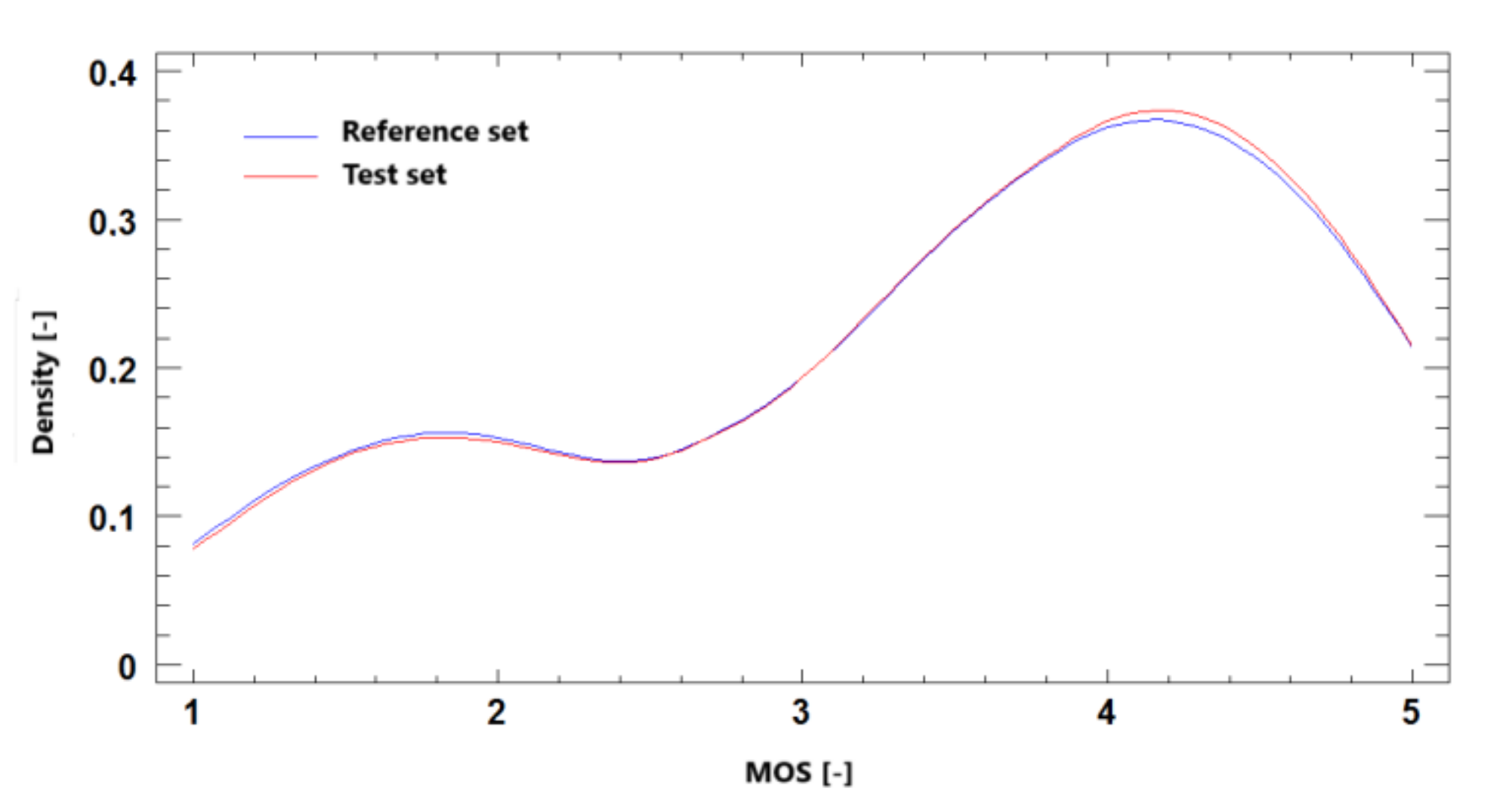
Figure 20.
The probability density function for MOS prediction, Ultra HD, H.264 + H.265.
Figure 20.
The probability density function for MOS prediction, Ultra HD, H.264 + H.265.
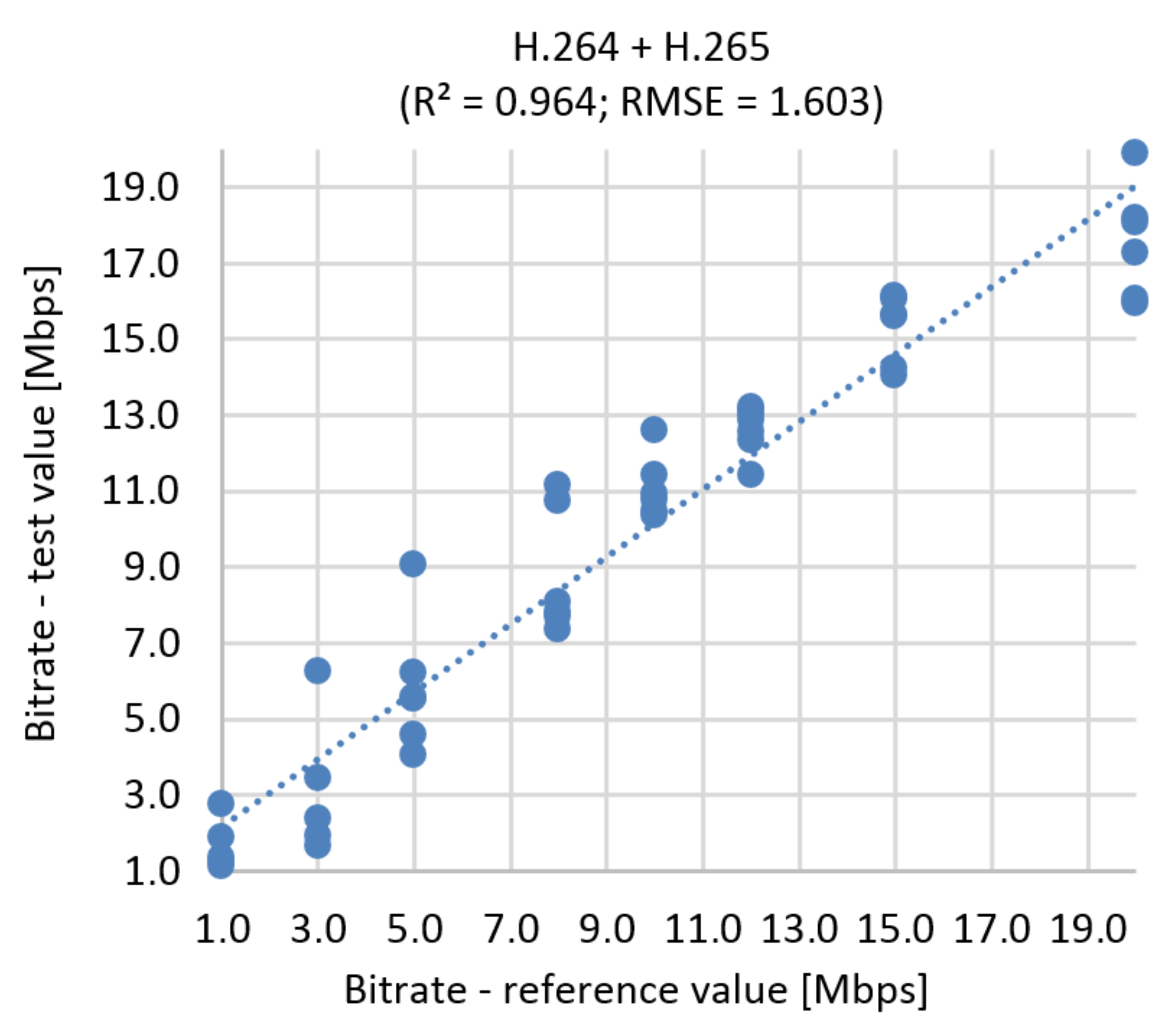
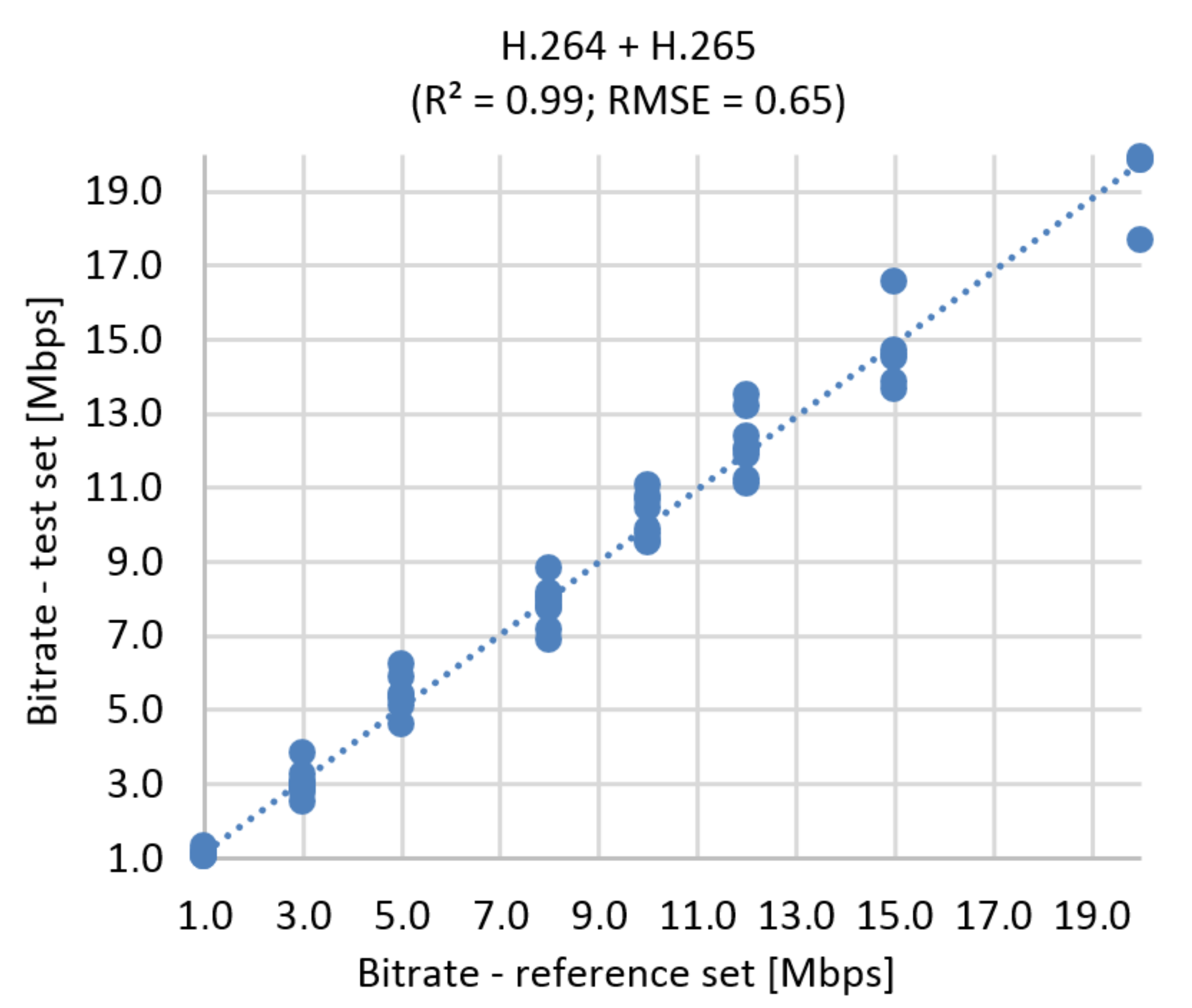
Figure 21.
Correlation diagram for bitrate prediction based on SSIM, Ultra HD, H.264 + H.265.
Figure 21.
Correlation diagram for bitrate prediction based on SSIM, Ultra HD, H.264 + H.265.
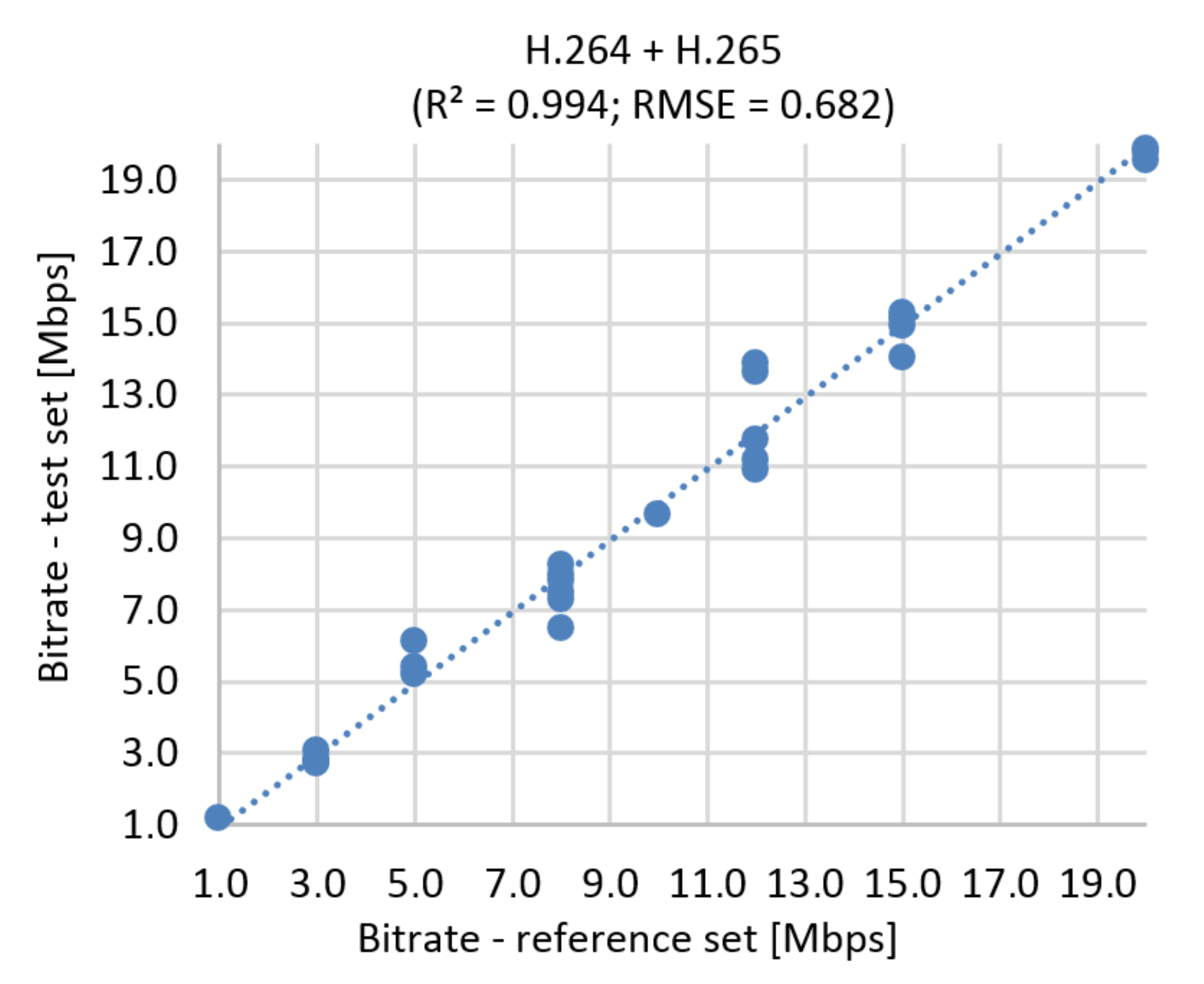
Figure 22.
Correlation diagram for bitrate prediction based on SSIM, Full HD + Ultra HD, H.264 + H.265.
Figure 22.
Correlation diagram for bitrate prediction based on SSIM, Full HD + Ultra HD, H.264 + H.265.
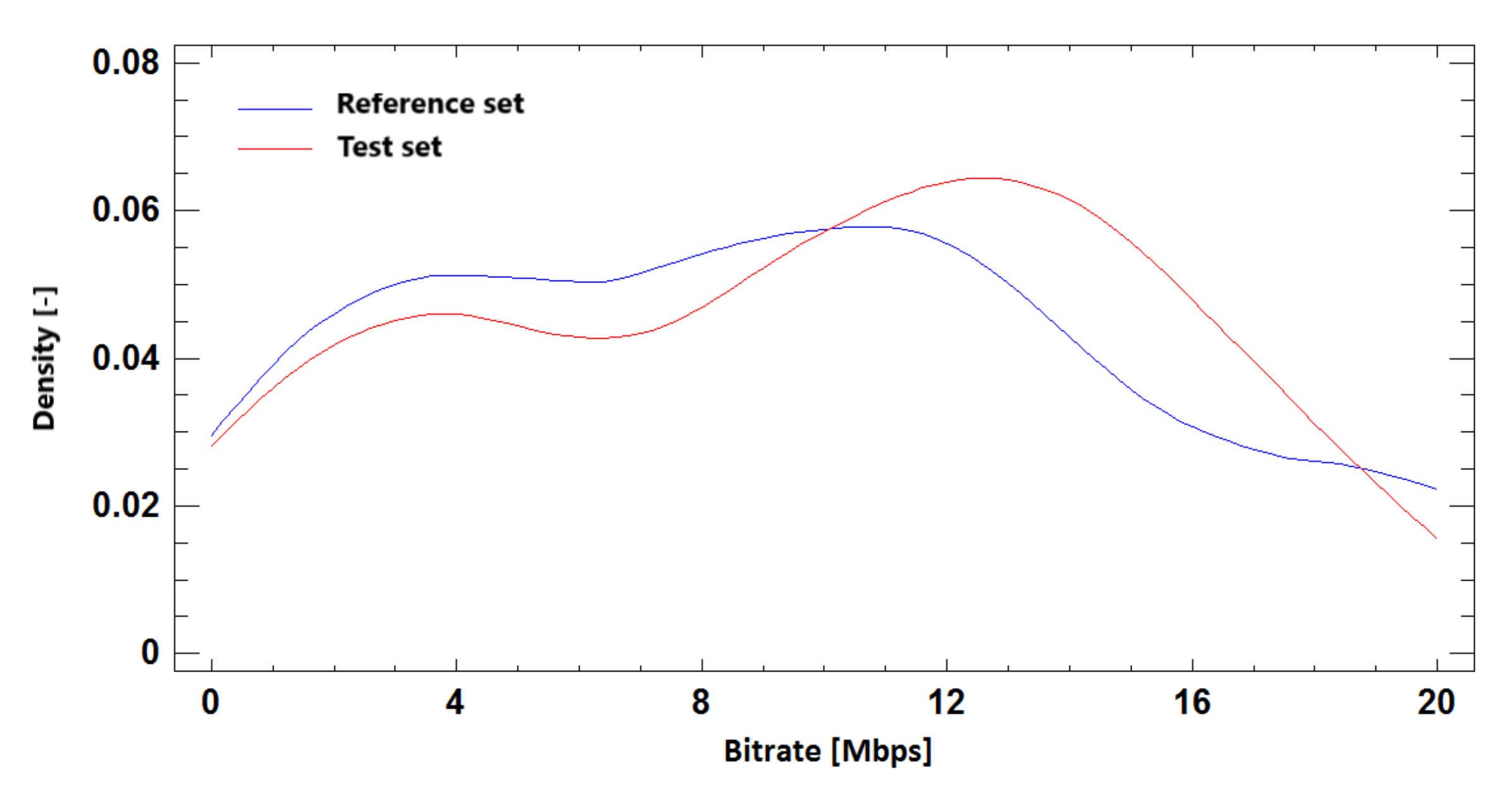
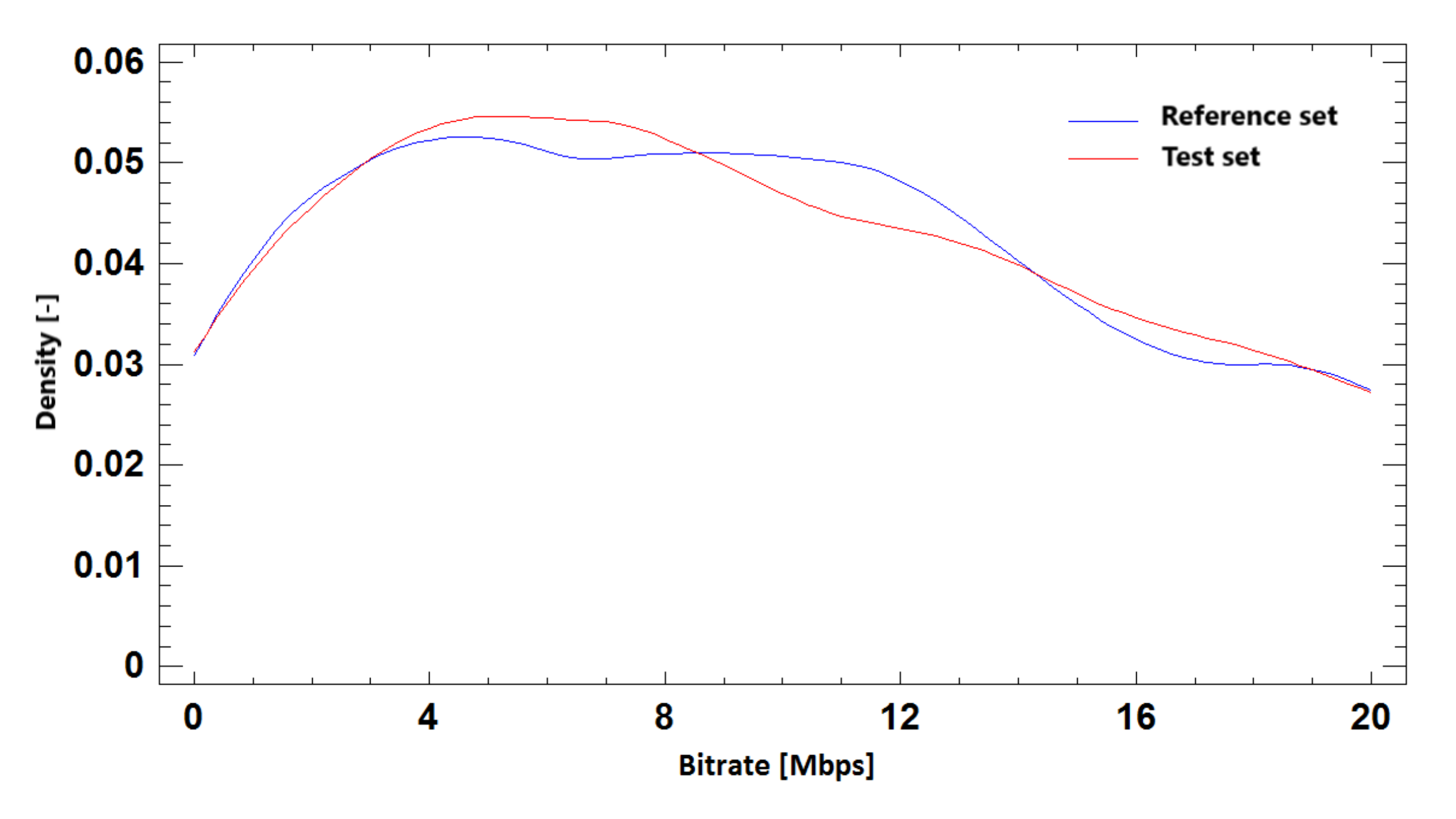
Figure 23.
The probability density function for bitrate prediction based on SSIM, Ultra HD, H.264 + H.265.
Figure 23.
The probability density function for bitrate prediction based on SSIM, Ultra HD, H.264 + H.265.
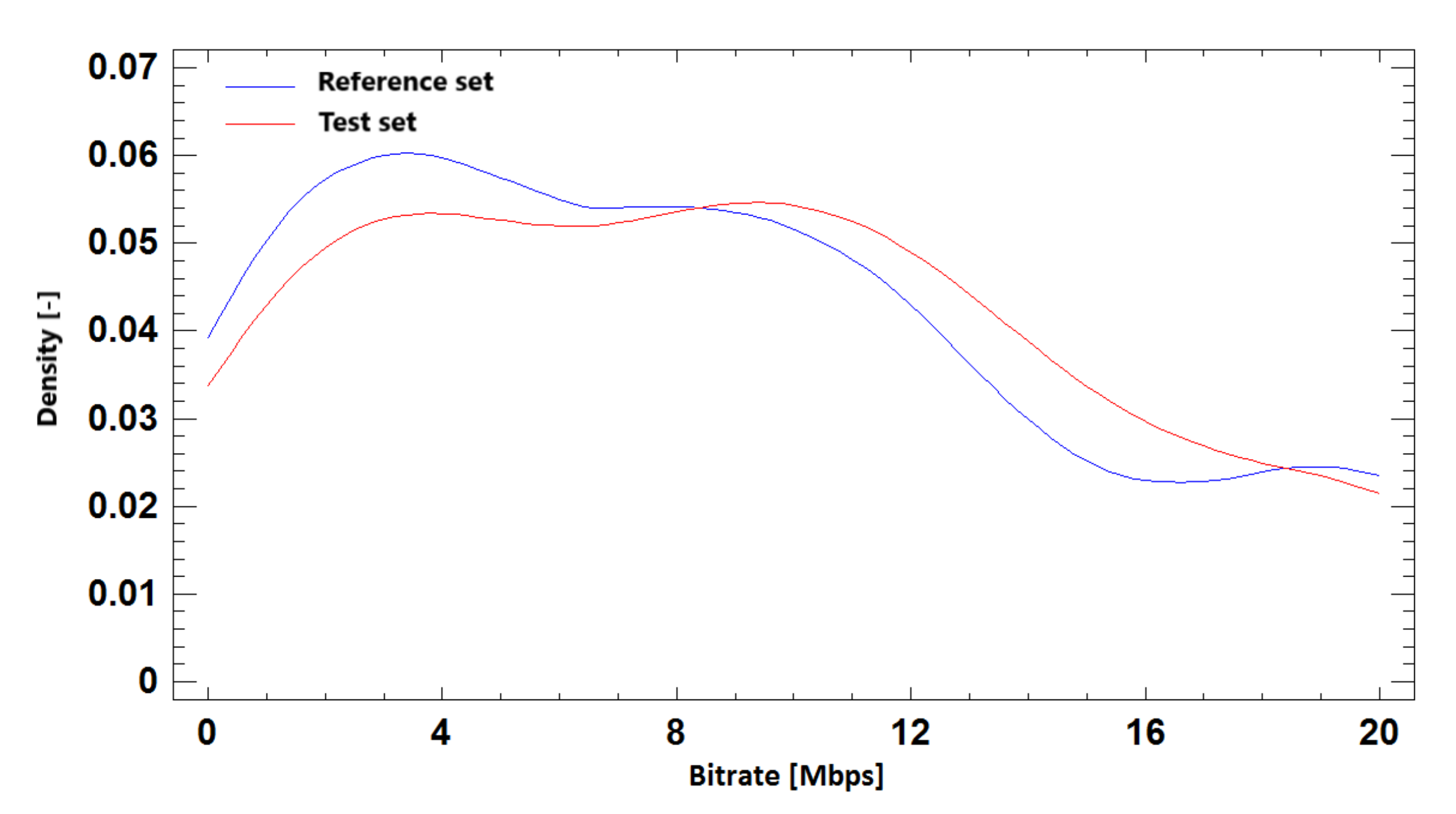
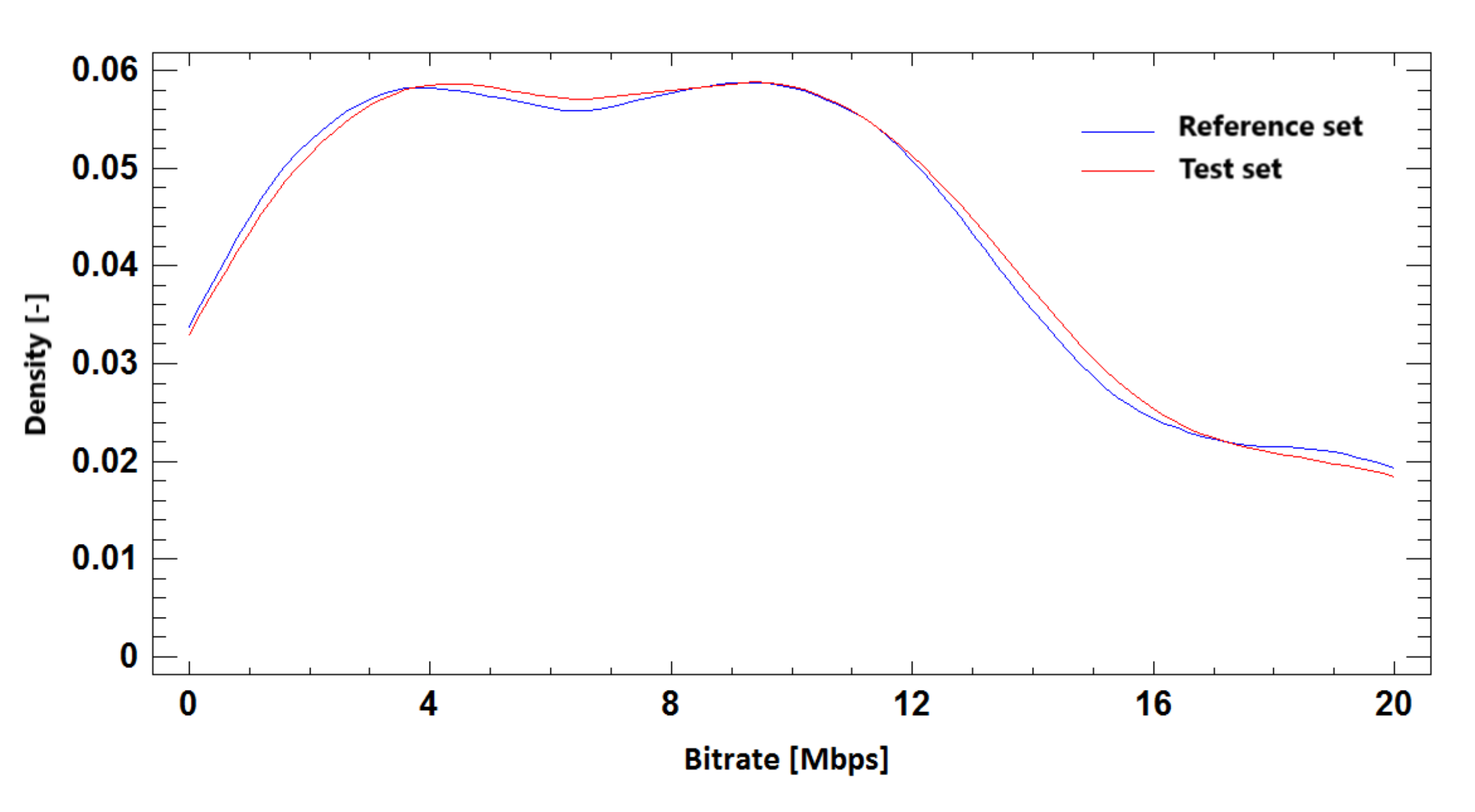
Figure 24.
The probability density function for bitrate prediction based on SSIM, Full HD + Ultra HD, H.264 + H.265.
Figure 24.
The probability density function for bitrate prediction based on SSIM, Full HD + Ultra HD, H.264 + H.265.
Figure 25.
Correlation diagram for bitrate prediction based on MOS, Ultra HD, H.264 + H.265.
Figure 25.
Correlation diagram for bitrate prediction based on MOS, Ultra HD, H.264 + H.265.
Figure 26.
Correlation diagram for bitrate prediction based on MOS, Full HD + Ultra HD, H.264 + H.265.
Figure 26.
Correlation diagram for bitrate prediction based on MOS, Full HD + Ultra HD, H.264 + H.265.
Figure 27.
The probability density function for bitrate prediction based on MOS, Ultra HD, H.264 + H.265.
Figure 27.
The probability density function for bitrate prediction based on MOS, Ultra HD, H.264 + H.265.
Figure 28.
The probability density function for bitrate prediction based on MOS, Full HD + Ultra HD, H.264 + H.265.
Figure 28.
The probability density function for bitrate prediction based on MOS, Full HD + Ultra HD, H.264 + H.265.
Table 1.
A comparison table of the selected relevant works.
Table 1.
A comparison table of the selected relevant works.
| | Our Paper | Paper [29] | Paper [30] |
|---|
| The main idea of the paper | Setting an appropriate bitrate based on a new classifier for predicting the boundaries SI and TI followed the quality requirements | The method of estimating the perceived quality of experience of users of UHD video flows in the emerging 5G networks is presented | The paper describes streaming of the video sequences using both the classical and the adaptive streaming approach; 3 type of Bandwidth scenarios |
| Source of the video sequences | Media Lab (8)/Ultra Video Group (4) | Ultra Video Group (4)/Mitch Martinez (5) | N/A |
| Number of video sequences | 12 | 9 | 5 |
| Duration of the video sequences [sec.] | 10 | 10 | 60 |
| Definition of the individual video sequences | SI, TI, qualitative parameters | N/A | SI, TI |
| Software for the encoding | FFmpeg | A modified version of the scalable HEVC reference software (version SHM 6.1) | N/A |
| Compression standards | H.264, H.265 | H.265 | N/A |
| The resolution | Full HD, Ultra HD | Full HD, Ultra HD | Quad HD |
| Frame rate | 30 | 30/24 | 30/24 |
| Subjective evaluators | 30 | 64 | 40 |
| Methods of the evaluation | Subjective (ACR), Objective (SSIM) | Subjective (ACR) | Subjective (ACR) |
| Performance | Each simulation is statistically verified with a high success rate of predicting the simulated variables | The results of subjective testing achieve an accuracy of up to 94%. MOS scores of the test subject have the maximum variance of 0.06 and 0.17. | The adaptive streaming case outperforms the standard for all the scenarios |
Table 2.
Parameters for encoding.
Table 2.
Parameters for encoding.
| Parameter | Description |
|---|
| Resolution | Full HD, Ultra HD |
| Type of codec | H.264 (AVC), H.265 (HEVC) |
| Bitrate [Mb/s] | 1, 3, 5, 8, 10, 12, 15, 20 |
| Chroma subsampling | 4:2:0 |
| Bit depth | 10 |
| Framerate | 30 fps |
| Duration | 10 s |
Table 3.
Equation parameters.
Table 3.
Equation parameters.
| Parameter | Description |
|---|
| The maximum value in the time |
| Standard deviation over pixels |
| Sobel | The Sobel filter |
| Number of frames in time n |
Table 4.
The basic and the best topologies of the subjective prediction; Ultra HD.
Table 4.
The basic and the best topologies of the subjective prediction; Ultra HD.
| Codec | Topology | [-] | Time [s] | Num. of Epochs [-] |
|---|
| H.264 + H.265 | 5-1 | 0.97 | 64.962 | 681 |
| 51-25 | 0.996 | 12.446 | 302 |
| 5-1-1 | 0.974 | 99.480 | 762 |
| 5-3-1 | 0.977 | 108.160 | 965 |
| 5-3-2-1 | 0.974 | 91.926 | 820 |
| 5-5-3-1 | 0.98 | 106.551 | 924 |
| H.264 | 5-1 | 0.934 | 93.305 | 853 |
| 31-15 | 0.993 | 281.610 | 273 |
| 5-1-1 | 0.953 | 91.826 | 963 |
| 5-3-1 | 0.934 | 135.354 | 1101 |
| 5-3-2-1 | 0.957 | 152.567 | 1118 |
| 5-5-3-1 | 0.953 | 94.658 | 888 |
| H.265 | 5-1 | 0.971 | 96.904 | 808 |
| 39-19 | 0.992 | 30.651 | 278 |
| 5-1-1 | 0.969 | 91.443 | 836 |
| 5-3-1 | 0.975 | 116.228 | 1037 |
| 5-3-2-1 | 0.984 | 103.205 | 827 |
| 5-5-3-1 | 0.989 | 118.936 | 918 |
Table 5.
Simulation of the MOS prediction for the best topologies.
Table 5.
Simulation of the MOS prediction for the best topologies.
| Resolution | Codec | Topology | MSE | [-] | [-] | [-] |
|---|
| Ultra HD | H.264 + H.265 | 51-25 | 0.002 | 0.996 | 0.996 | 0.997 |
| H.264 | 31-15 | 0.004 | 0.994 | 0.987 | 0.999 |
| H.265 | 39-19 | 0.004 | 0.993 | 0.998 | 0.997 |
Full HD+
Ultra HD | H.264 + H.265 | 47-23 | 0.006 | 0.986 | 0.991 | 0.993 |
Table 6.
Simulation of bitrate prediction based on SSIM for the best topologies.
Table 6.
Simulation of bitrate prediction based on SSIM for the best topologies.
| Resolution | Codec | Topology | MSE | [-] | [-] | [-] |
|---|
| Ultra HD | H.264 + H.265 | 43-21 | 0.041 | 0.949 | 0.944 | 0.963 |
| H.264 | 79-39 | 0.0001 | 0.999 | 0.999 | 0.999 |
| H.265 | 63-31 | 0.001 | 0.999 | 0.999 | 0.999 |
Full HD+
Ultra HD | H.264 + H.265 | 47-23 | 0.029 | 0.963 | 0.957 | 0.985 |
Table 7.
The best topologies of bitrate prediction based on SSIM.
Table 7.
The best topologies of bitrate prediction based on SSIM.
| Resolution | Codec | Topology | [-] | Time[s] | Num. of Epochs[-] |
|---|
| Ultra HD | H.264 + H.265 | 43-21 | 0.946 | 191.265 | 338 |
| H.264 | 79-39 | 0.970 | 363.562 | 266 |
| H.265 | 63-31 | 0.939 | 627.246 | 360 |
| Full HD + Ultra HD | H.264 + H.265 | 47-23 | 0.965 | 217.427 | 294 |
Table 8.
The best topologies of bitrate prediction based on MOS.
Table 8.
The best topologies of bitrate prediction based on MOS.
| Resolution | Codec | Topology | [-] | Time[s] | Num. of Epochs [-] |
|---|
| Ultra HD | H.264 + H.265 | 47-23 | 0.988 | 12.163 | 270 |
| H.264 | 35-17 | 0.992 | 18.957 | 330 |
| H.265 | 71-35 | 0.990 | 20.299 | 347 |
| Full HD + Ultra HD | H.264 + H.265 | 71-35 | 0.990 | 29.113 | 250 |
Table 9.
Simulation of bitrate prediction based on MOS for the best topologies.
Table 9.
Simulation of bitrate prediction based on MOS for the best topologies.
| Resolution | Codec | Topology | MSE | [-] | [-] | [-] |
|---|
| Ultra HD | H.264 + H.265 | 47-23 | 0.013 | 0.982 | 0.991 | 0.992 |
| H.264 | 35-17 | 0.006 | 0.992 | 0.991 | 0.996 |
| H.265 | 71-35 | 0.011 | 0.988 | 0.982 | 0.993 |
Full HD+
Ultra HD | H.264 + H.265 | 71-35 | 0.008 | 0.989 | 0.99 | 0.995 |
Table 10.
Descriptive statistics for MOS prediction, Ultra HD, H.264 + H.265.
Table 10.
Descriptive statistics for MOS prediction, Ultra HD, H.264 + H.265.
| | Reference Set | Test Set |
|---|
| Average value [-] | 3.481 | 3.501 |
| Minimum [-] | 1.333 | 1.382 |
| Maximum [-] | 4.900 | 4.920 |
| Median [-] | 3.700 | 3.850 |
| Confidence interval [-] | <3.067; 3.896> | <3.091; 3.910> |
| Pearson’s correlation coef. [-] | 0.999 |
| Spearman’s correlation coef. [-] | 0.976 |
Table 11.
Descriptive statistics for bitrate prediction based on SSIM, H.264 + H.265.
Table 11.
Descriptive statistics for bitrate prediction based on SSIM, H.264 + H.265.
| | Ultra HD | Full HD + Ultra HD |
|---|
| | Reference Set | Test Set | Reference Set | Test Set |
|---|
| Average value [-] | 9.438 | 9.664 | 8.583 | 9.14 |
| Minimum [-] | 1.000 | 0.369 | 1 | 0.73 |
| Maximum [-] | 20.000 | 19.884 | 20.00 | 22.11 |
| Median [-] | 10.000 | 10.744 | 8.00 | 22.84 |
| Confidence interval [-] | <7.708; 11.167> | <8.071; 11.257> | <5.43; 7.22> | <5.39; 7.18> |
| Pearson’s correlation coef. [-] | 0.964 | 0.985 |
| Spearman’s correlation coef. [-] | 0.976 | 0.970 |
Table 12.
Descriptive statistics for bitrate prediction based on MOS, Ultra HD, H.264 + H.265.
Table 12.
Descriptive statistics for bitrate prediction based on MOS, Ultra HD, H.264 + H.265.
| | Ultra HD | Full HD + Ultra HD |
|---|
| | Reference Set | Test Set | Reference Set | Test Set |
|---|
| Average value [-] | 9.656 | 9.594 | 8.73 | 8.74 |
| Minimum [-] | 1 | 0.667 | 1.00 | 0.93 |
| Maximum [-] | 20 | 20.467 | 20.00 | 19.83 |
| Median [-] | 8 | 8.106 | 8.00 | 8.05 |
| Confidence interval [-] | <7.380; 11.932> | <7.307; 11.881> | <7.28; 10.19> | <7.31; 10.18> |
| Pearson’s correlation coef. [-] | 0.994 | 0.99 |
| Spearman’s correlation coef. [-] | 0.99 | 0.99 |

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}