
Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning


Abstract
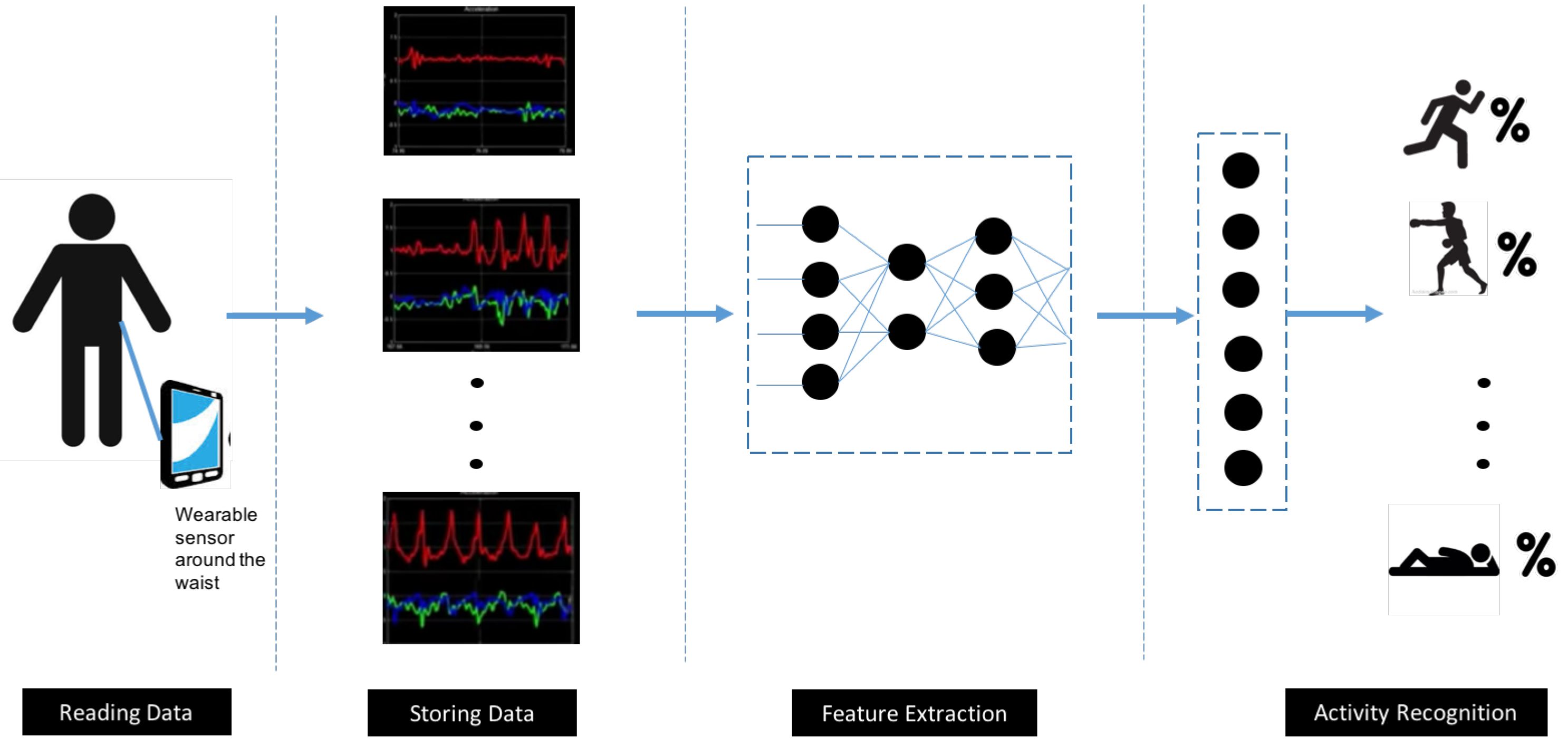
:1. Introduction
2. Background
2.1. Types of Sensor Modalities
2.1.1. Body-Worn Sensors
2.1.2. Ambient Sensors
2.1.3. Hybrid Sensors
2.2. Deep-Learning Models
2.2.1. Convolution Neural Networks (CNN)
2.2.2. Autoencoder
2.2.3. Restricted Boltzmann Machine (RBMs)
2.2.4. Recurrent Neural Network (RNN)
2.2.5. Hybrid Model
2.3. Literature Review
3. Proposed Approach
3.1. Basic Structure of CNNs
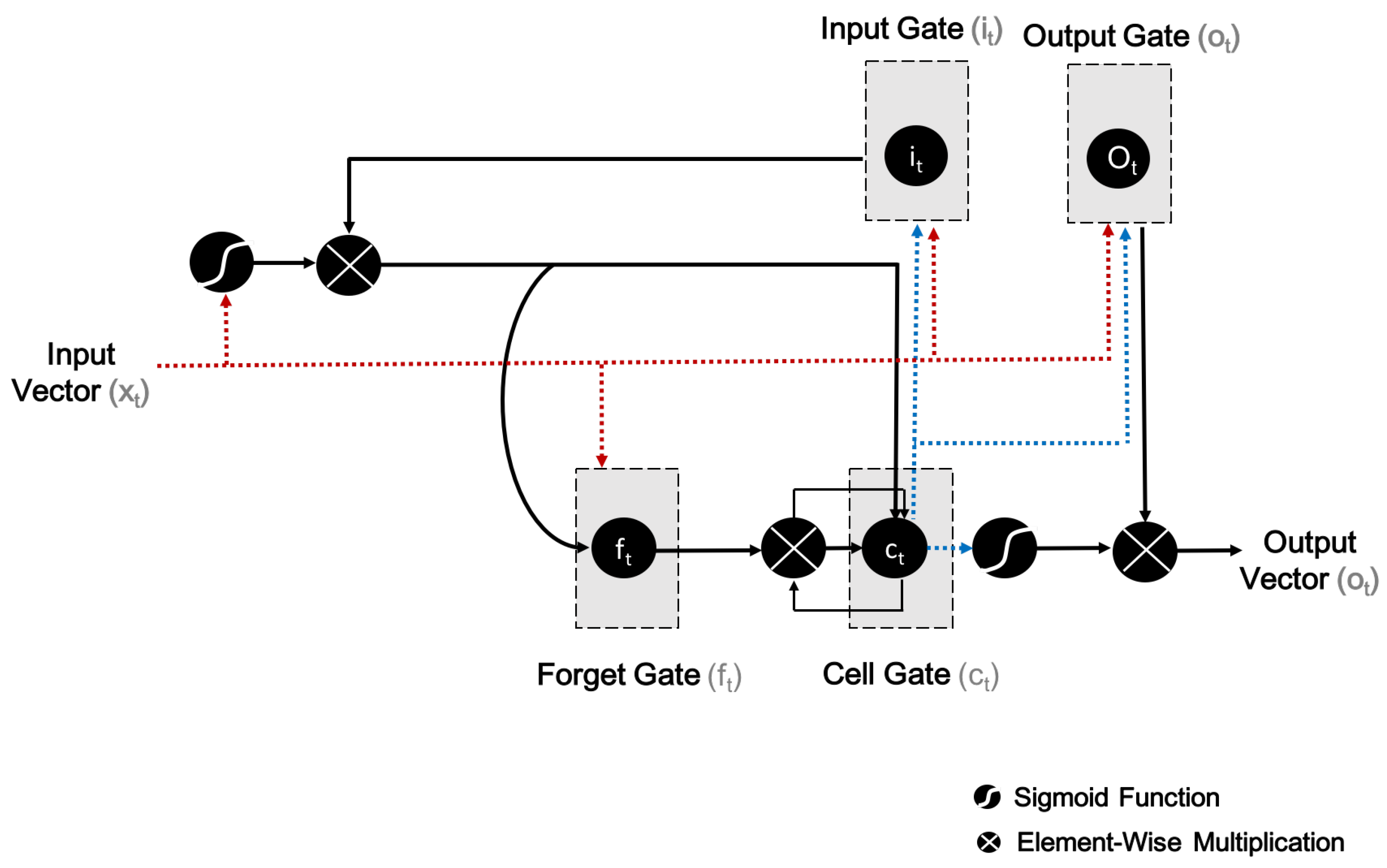
3.2. Basic Structure of Long Short-Term Memory (LSTM)
3.2.1. Training LSTM
 , whereas the circle marked with an
, whereas the circle marked with an  denotes the use of the sigmoid function (or, for that matter, any other application function) to a weighted sum. The LSTM network involves the automatic learning of high-level features which are related to long-term ways across time steps [27].
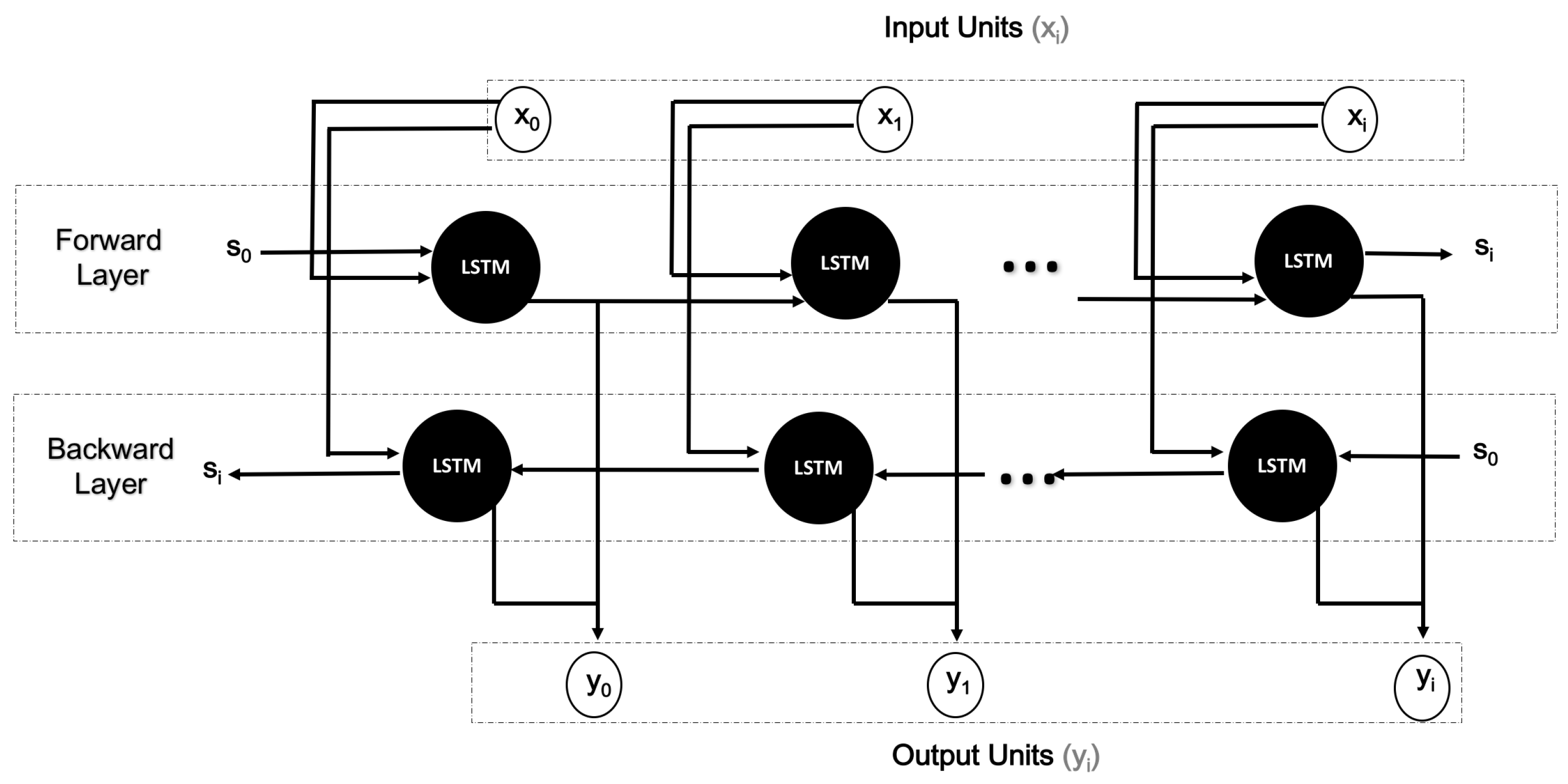
denotes the use of the sigmoid function (or, for that matter, any other application function) to a weighted sum. The LSTM network involves the automatic learning of high-level features which are related to long-term ways across time steps [27].3.2.2. Basic Structure of Bi-Directional Long Short-Term Memory (BiLSTM)
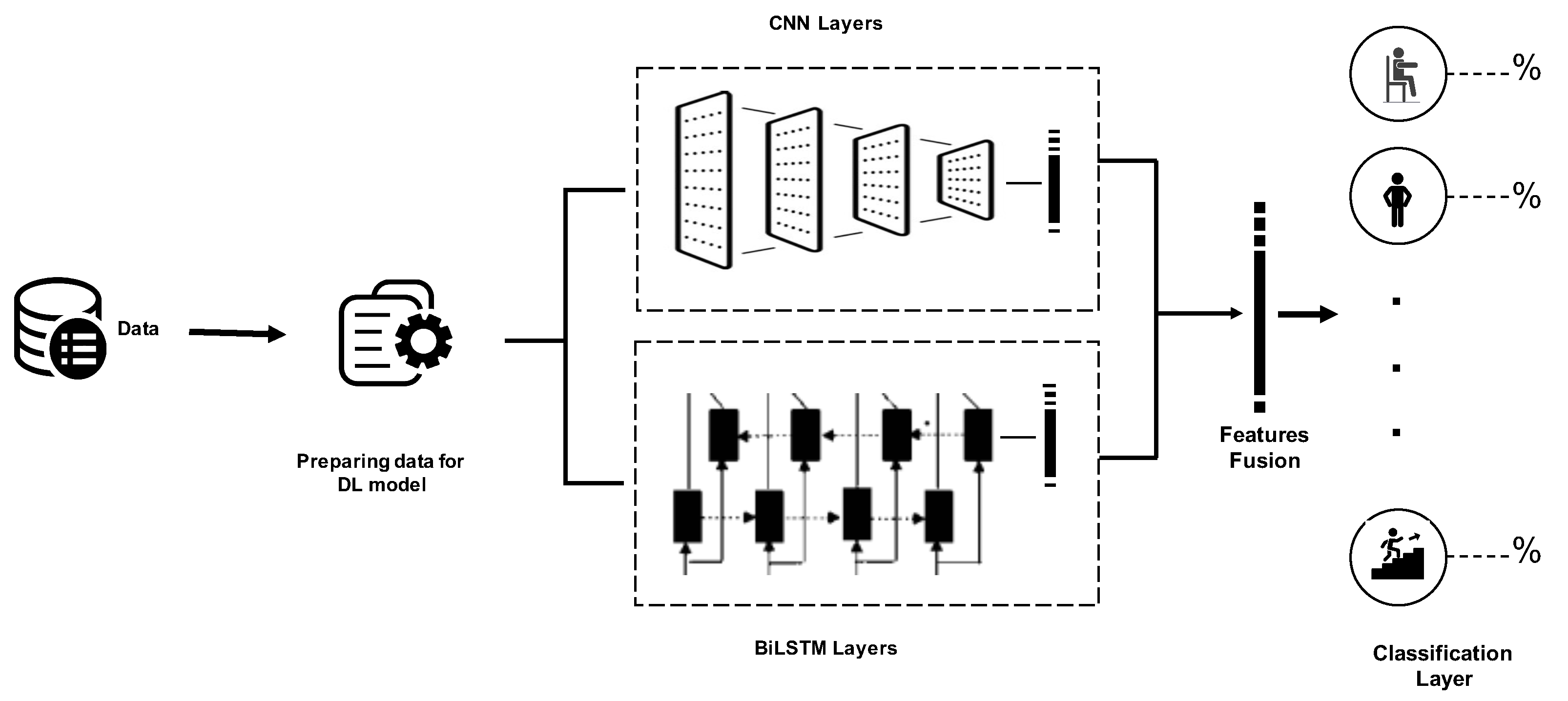
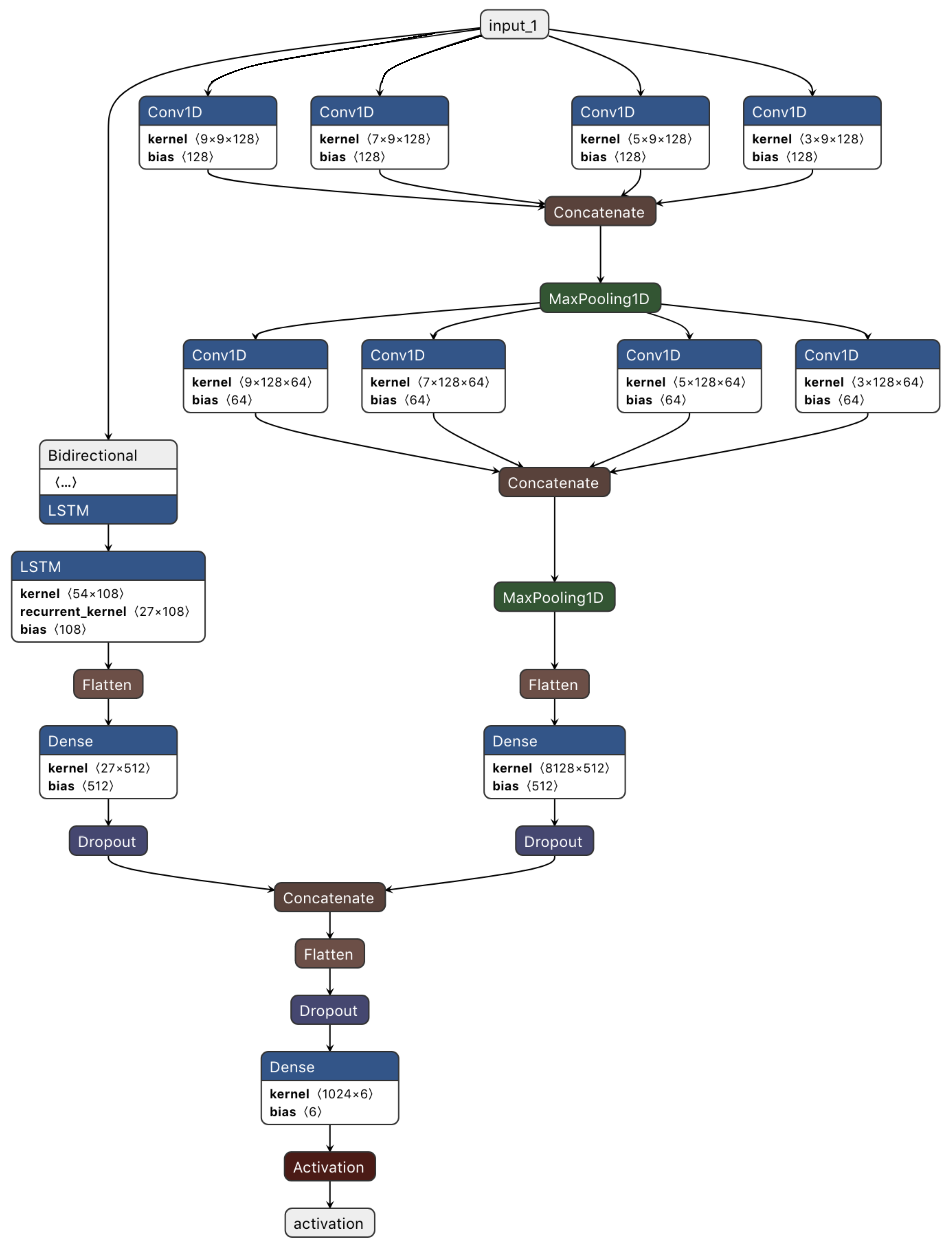
3.2.3. Designing a Deep CNN-BiLSTM Learning Model
4. Experimental Results and Discussion
4.1. Database Setting
4.1.1. Wireless Sensor Data Mining (WISDM)
4.1.2. UCI-HAR
4.2. Evaluation Metrics
4.3. Experimental Setup
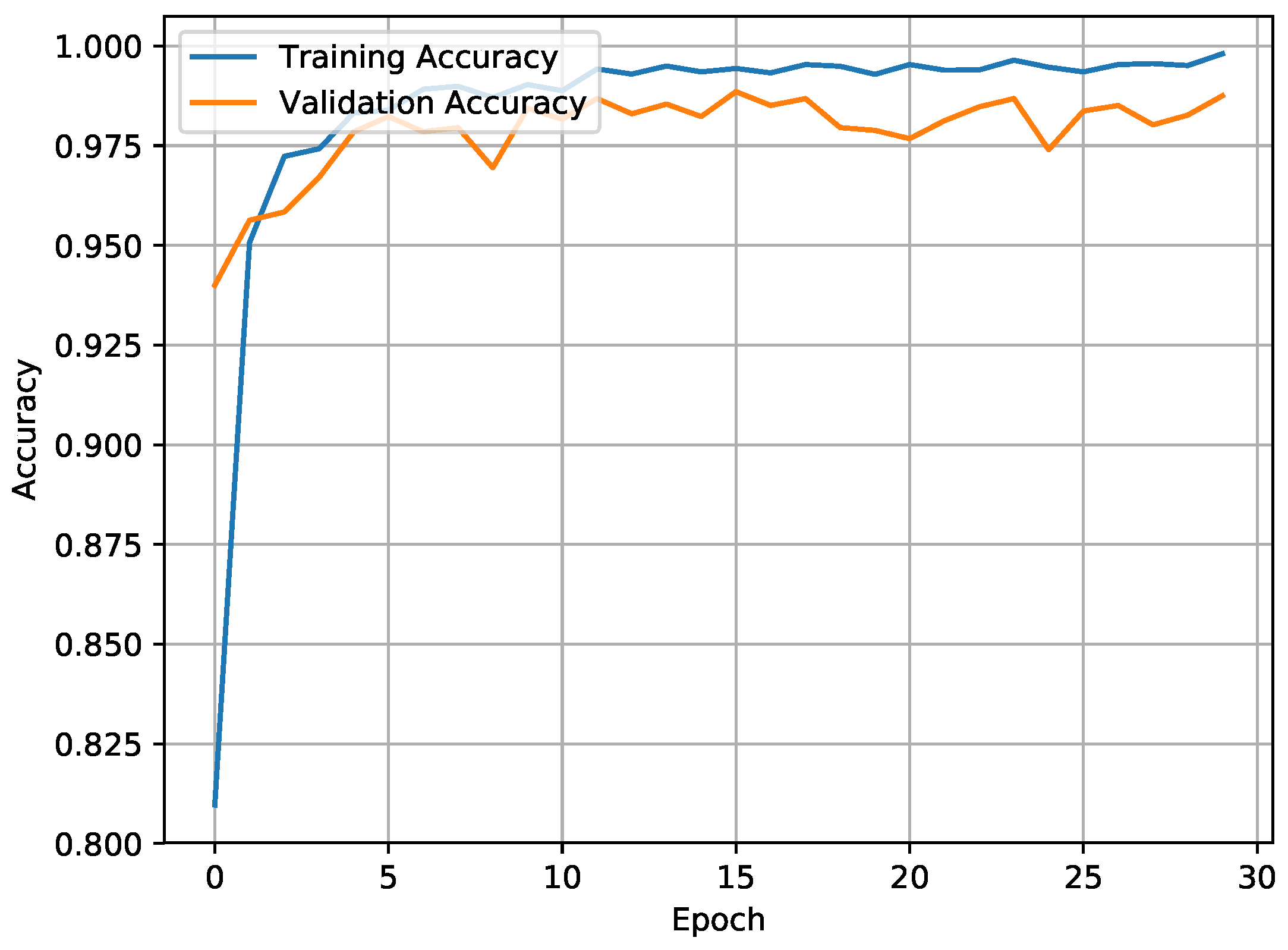
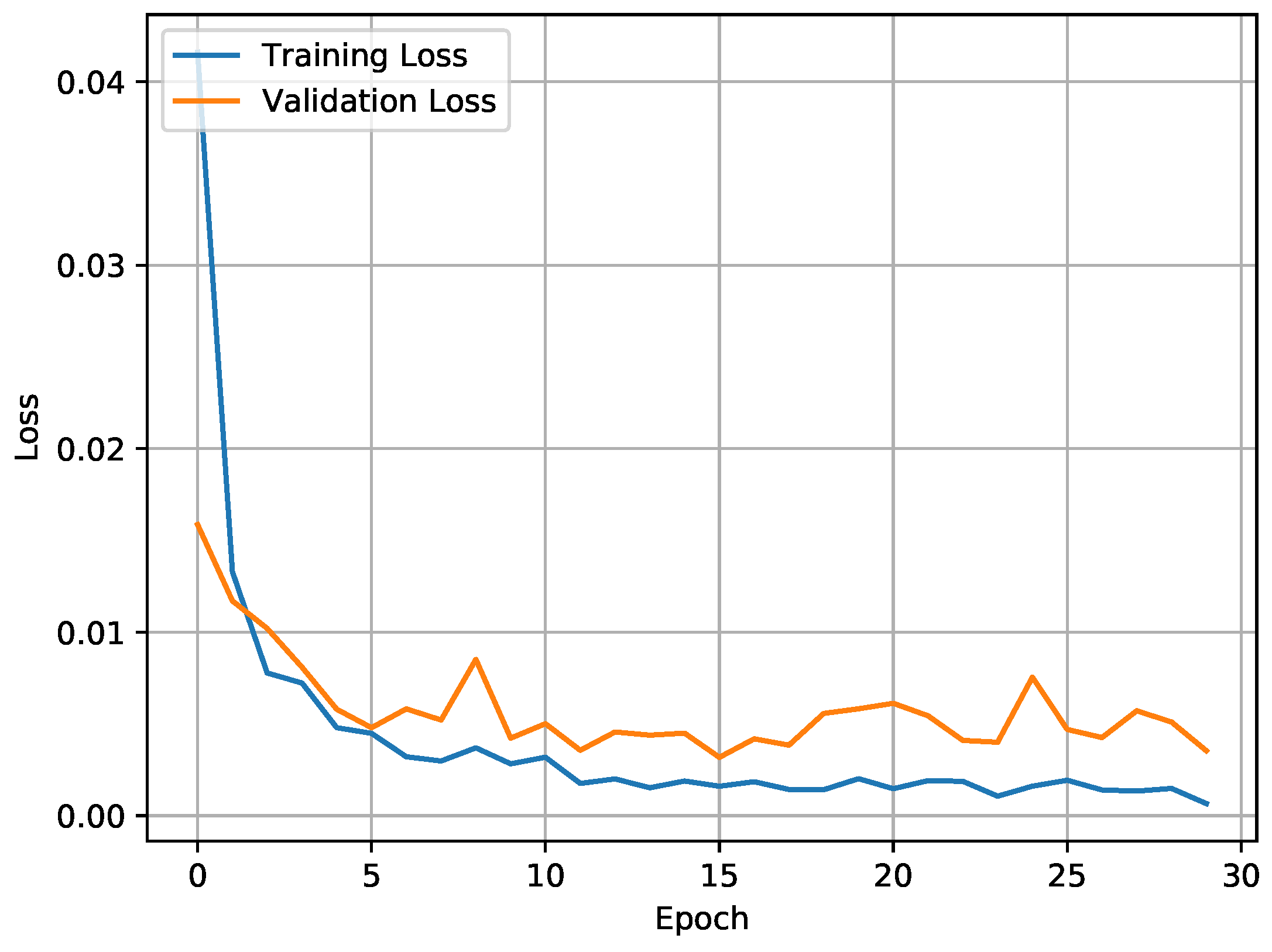
4.4. Discussion
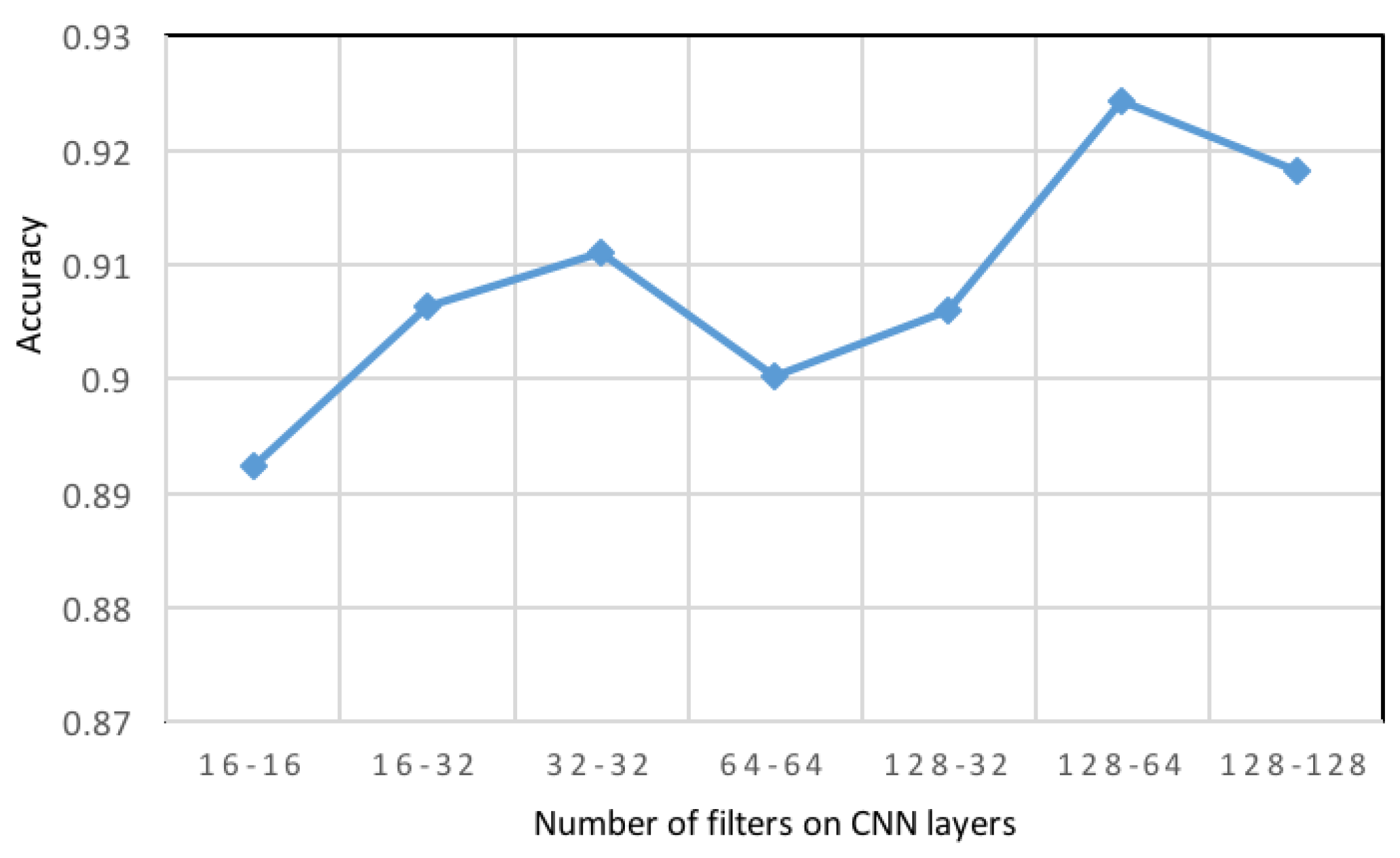
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADL | Activities of Daily Living |
| BiLSTM | Bi-directional Long Short-Term Memory |
| CNN | Convolution Neural Networks |
| DBNs | Deep Belief Networks |
| HAR | Human Activity Recognition |
| iDTs | improved Dense Trajectories |
| LSTM | Long Short-Term Memory |
| RBM | Restricted Boltzmann Machine |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machine |
| TDD | Trajectory-Pooled Deep-Convolutional Descriptor |
| TSN | Temporal Segment Networks |
| UCI | University of California, Irvine |
| WISDM | Wireless Sensor Data Mining |
References
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN architecture for human activity recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Tang, Y.; Teng, Q.; Zhang, L.; Min, F.; He, J. Efficient convolutional neural networks with smaller filters for human activity recognition using wearable sensors. arXiv 2020, arXiv:2005.03948. [Google Scholar]
- Qin, Z.; Zhang, Y.; Meng, S.; Qin, Z.; Choo, K.K.R. Imaging and fusing time series for wearable sensor-based human activity recognition. Inf. Fusion 2020, 53, 80–87. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Abbaspour, S.; Fotouhi, F.; Sedaghatbaf, A.; Fotouhi, H.; Vahabi, M.; Linden, M. A comparative analysis of hybrid deep learning models for human activity recognition. Sensors 2020, 20, 5707. [Google Scholar] [CrossRef]
- Wang, Y.; Cang, S.; Yu, H. A survey on wearable sensor modality centred human activity recognition in health care. Expert Syst. Appl. 2019, 137, 167–190. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Fang, H.; Hu, C. Recognizing human activity in smart home using deep learning algorithm. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 4716–4720. [Google Scholar]
- Shakya, S.R.; Zhang, C.; Zhou, Z. Comparative study of machine learning and deep learning architecture for human activity recognition using accelerometer data. Int. J. Mach. Learn. Comput 2018, 8, 577–582. [Google Scholar]
- Mliki, H.; Bouhlel, F.; Hammami, M. Human activity recognition from UAV-captured video sequences. Pattern Recognit. 2020, 100, 107140. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep activity recognition models with triaxial accelerometers. arXiv 2015, arXiv:1511.04664. [Google Scholar]
- Brownlee, J. Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs and LSTMs in Python; Machine Learning Mastery: New York, NY, USA, 2018. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards good practices for very deep two-stream convnets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- Bilen, H.; Fernando, B.; Gavves, E.; Vedaldi, A.; Gould, S. Dynamic image networks for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3034–3042. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Mahmud, T.; Sayyed, A.S.; Fattah, S.A.; Kung, S.Y. A Novel Multi-Stage Training Approach for Human Activity Recognition From Multimodal Wearable Sensor Data Using Deep Neural Network. IEEE Sens. J. 2020, 21, 1715–1726. [Google Scholar] [CrossRef]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Jung, M.; Chi, S. Human activity classification based on sound recognition and residual convolutional neural network. Autom. Constr. 2020, 114, 103177. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 6299–6308. [Google Scholar]
- Wang, L.; Xu, Y.; Cheng, J.; Xia, H.; Yin, J.; Wu, J. Human action recognition by learning spatio-temporal features with deep neural networks. IEEE Access 2018, 6, 17913–17922. [Google Scholar] [CrossRef]
- Nan, Y.; Lovell, N.H.; Redmond, S.J.; Wang, K.; Delbaere, K.; van Schooten, K.S. Deep Learning for Activity Recognition in Older People Using a Pocket-Worn Smartphone. Sensors 2020, 20, 7195. [Google Scholar] [CrossRef]
- Van, J. Analysis of Deep Convolutional Neural Network Architectures. In Proceedings of the 21st Twente Student Conference on IT, Enschede, The Netherlands, 23 June 2014. [Google Scholar]
- Rashid, K.M.; Louis, J. Times-series data augmentation and deep learning for construction equipment activity recognition. Adv. Eng. Inform. 2019, 42, 100944. [Google Scholar] [CrossRef]
- Li, C.; Bao, Z.; Li, L.; Zhao, Z. Exploring temporal representations by leveraging attention-based bidirectional lstm-rnns for multi-modal emotion recognition. Inf. Process. Manag. 2020, 57, 102185. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. arXiv 2017, arXiv:1701.04128. [Google Scholar]
- Grais, E.; Wierstorf, H.; Ward, D.; Plumbley, M. Multi-resolution fully convolutional neural networks for monaural audio source separation. arXiv 2017, arXiv:1710.11473. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 24–26 April 2013; pp. 24–26. [Google Scholar]
- Rothermel, K.; Fritsch, D.; Blochinger, W.; Dürr, F. Quality of Context, Proceedings of the First International Workshop, QuaCon 2009, Stuttgart, Germany, 25–26 June 2009; Revised Papers; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 5786. [Google Scholar]
- Wiseman, Y. Autonomous vehicles. In Encyclopedia of Information Science and Technology, 5th ed.; IGI Global: Hershey, PA, USA, 2021; pp. 1–11. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Model | Domain | Proposed Study | Comments |
|---|---|---|---|---|---|
| [13] | 2015 | CNN | video-based | Two-stream convNets (VGGNet, GoogLeNet); 10-frame stacking of optical flow for temporal network and a single frame for spatial network; data augmentation to increase the size of the dataset | * It requires features pre-processing. * It needs the augmentation to handle the issue of overfitting. * It introduces a new representation of features and nets but it is not effectively representing the spatio-temporal features in HAR. |
| [14] | 2016 | video-based | Propose the idea of dynamic map and rank pooling to encode the video frames into a single RGB image per video. | ||
| [15] | 2016 | sensor-based | Propose a multi-layer CNN with alternating convolution and pooling layers to extract the features. | ||
| [16] | 2016 | video-based | Propose a two-stream network, fusion is done at the level of convolution layer. | ||
| [17] | 2016 | video-based | Propose a temporal segment network (TSN); Instead of working on each frame individually it works on a set of a short snippets sparsely sampled from the video; these snippets will be fed up to a two-stream of CNN. | ||
| [2] | 2020 | sensor-based | Propose to use Lego filters to have a lightweight deep CNNs | ||
| [18] | 2020 | video-based | Propose to use CNN as a feature extractor from different transformed domains | ||
| [19] | 2015 | CNNs with hand-crafted features | video-based | A new video representation, called trajectory-pooled deep-convolutional descriptor (TDD); two-stream ConvNets; using improved dense trajectories (iDTs) features | * It requires features pre-processing. |
| [20] | 2018 | sensor-based | Propose a new design of CNN and combine it with stats. features | * A new designing of nets but it is not effectively representing the spatio-temporal features in HAR. | |
| [22] | 2015 | 3D-CNN | video-based | Propose a C3D (Convolutional-3D), with a simple linear classifier | * It can capture the spatio-temporal feature more effectively than 3D-CNN. |
| [23] | 2018 | video-based | Two-steam inflated 3D-ConvNet (I3D) | ||
| [24] | 2018 | CNN-LSTM | video-based | CNN to extract the spatial features, then these feature will be the input to two different stream of LSTM(FC-LSTM, ConvLSTM) to extract the temporal features | * CNN-LSTM model was found to be the most suitable approach for investigation long-term activity recognition. |
| [25] | 2020 | sensor-based | They improved many models such as 1D CNN, a multichannel CNN, a CNN-LSTM, and multichannel CNN-LSTM |
| Activity | Walk | Jog | Up | Down | Sit | Std |
|---|---|---|---|---|---|---|
| Samples | 424,400 | 342,177 | 122,869 | 100,427 | 59,939 | 48,397 |
| Percentage (%) | 38.6 | 31.2 | 11.2 | 9.1 | 5.5 | 4.4 |
| Activity | Walk | Up | Down | Sit | Std | Lay |
|---|---|---|---|---|---|---|
| Samples | 122,091 | 116,707 | 107,961 | 126,677 | 138,105 | 136,865 |
| Percentage(%) | 16.3 | 15.6 | 14.4 | 16.9 | 18.5 | 18.3 |
| Activities | Down | Jog | Sit | Std | Up | Walk | Precision | F1 |
|---|---|---|---|---|---|---|---|---|
| Down | 739 | 2 | 0 | 0 | 34 | 5 | 0.94 | 0.96 |
| Jog | 0 | 2576 | 0 | 0 | 8 | 0 | 0.99 | 0.99 |
| Sit | 0 | 0 | 395 | 20 | 1 | 2 | 0.94 | 0.97 |
| Std | 0 | 0 | 2 | 353 | 1 | 0 | 0.99 | 0.97 |
| Up | 20 | 4 | 0 | 0 | 855 | 0 | 0.97 | 0.95 |
| Walk | 6 | 2 | 0 | 0 | 14 | 3197 | 0.99 | 0.99 |
| Recall | 0.96 | 0.99 | 0.99 | 0.94 | 0.93 | 0.99 | ||
| Accuracy | 98.53% | |||||||
| Kappa | 0.98 | |||||||
| Activities | Down | Jog | Sit | Std | Up | Walk | Precision | F1 |
|---|---|---|---|---|---|---|---|---|
| Down | 646 | 0 | 2 | 0 | 30 | 2 | 0.95 | 0.96 |
| Jog | 1 | 2574 | 0 | 0 | 7 | 2 | 0.99 | 0.99 |
| Sit | 1 | 0 | 395 | 20 | 1 | 1 | 0.94 | 0.97 |
| Std | 2 | 0 | 0 | 354 | 0 | 0 | 0.99 | 0.97 |
| Up | 22 | 3 | 0 | 0 | 854 | 0 | 0.97 | 0.96 |
| Walk | 10 | 1 | 1 | 0 | 13 | 3194 | 0.99 | 0.99 |
| Recall | 0.94 | 0.99 | 0.99 | 0.94 | 0.94 | 0.99 | ||
| Accuracy | 98.53% | |||||||
| Kappa | 0.98 | |||||||
| Activities | Walk | Up | Down | Sit | Std | Lay | Precision | F1 |
|---|---|---|---|---|---|---|---|---|
| Walk | 494 | 2 | 0 | 0 | 0 | 0 | 0.99 | 0.99 |
| Up | 0 | 470 | 0 | 1 | 0 | 0 | 0.99 | 0.99 |
| Down | 2 | 10 | 407 | 0 | 1 | 0 | 0.96 | 0.99 |
| Sit | 0 | 3 | 0 | 449 | 36 | 3 | 0.94 | 0.91 |
| Std | 0 | 0 | 0 | 29 | 503 | 0 | 0.93 | 0.94 |
| Lay | 0 | 0 | 0 | 0 | 0 | 537 | 0.99 | 1.00 |
| Recall | 0.99 | 0.96 | 1.00 | 0.93 | 0.93 | 0.99 | ||
| Accuracy | 97.04% | |||||||
| Kappa | 0.96 | |||||||
| Activities | Walk | Up | Down | Sit | Std | Lay | Precision | F1 |
|---|---|---|---|---|---|---|---|---|
| Walk | 494 | 2 | 0 | 0 | 0 | 0 | 0.99 | 0.99 |
| Up | 0 | 465 | 5 | 1 | 0 | 0 | 0.98 | 0.99 |
| Down | 0 | 4 | 415 | 0 | 1 | 0 | 0.98 | 0.99 |
| Sit | 0 | 0 | 0 | 448 | 43 | 0 | 0.91 | 0.93 |
| Std | 0 | 0 | 0 | 24 | 508 | 0 | 0.95 | 0.94 |
| Lay | 0 | 0 | 0 | 0 | 0 | 537 | 1.00 | 1.00 |
| Recall | 1.00 | 0.98 | 0.98 | 0.94 | 0.92 | 1.00 | ||
| Accuracy | 97.28% | |||||||
| Kappa | 0.96 | |||||||
| Database | Ref. | Year | Used Technique | Accuracy (%) |
|---|---|---|---|---|
| UCF101 | [13] | 2015 | GoogLeNet & VGG-16 | 91.40 |
| [19] | 2015 | TDD | 91.50 | |
| [22] | 2016 | Two CNN stream (VGG-16) | 93.50 | |
| [16] | 2016 | TSN | 94.20 | |
| [17] | 2016 | CNN | 89.10 | |
| [14] | 2017 | Two-stream-3D-ConvNet | 93.40 | |
| [23] | 2018 | CNN-LSTM | 84.10 | |
| HMDB51 | [19] | 2015 | TDD | 65.90 |
| [16] | 2016 | Two CNN stream—iDT | 69.20 | |
| [17] | 2016 | TSN | 69.40 | |
| [14] | 2016 | CNN | 65.20 | |
| [23] | 2017 | Two-3D-ConvNet | 88.40 | |
| ASLAN | [22] | 2015 | CONV3D-SVM | 78.30 |
| Sports 1M | [22] | 2015 | CONV3D-SVM | 85.20 |
| UCF-ARG | [10] | 2020 | Pre-trained CNN | 87.60 |
| Sound dataset | [21] | 2020 | CNN | 87.20 |
| HHAR | [3] | 2020 | Fusion ResNet | 96.63 |
| MHEALTH | [3] | 2020 | Fusion ResNet | 98.50 |
| WISDM | [1] | 2020 | CNN-LSTM | 95.75 |
| [2] | 2020 | CNN | 97.51 | |
| Proposed | 2020 | CNN-BiLSTM | 98.53 | |
| UCI | [15] | 2016 | CNN | 93.75 |
| [20] | 2018 | CNN | 95.31 | |
| [20] | 2018 | CNN with stat. features | 97.63 | |
| [1] | 2020 | CNN-LSTM | 95.80 | |
| [2] | 2020 | Lightweight CNN | 96.27 | |
| Proposed | 2020 | CNN-BiLSTM | 97.05 |
| Experiment | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) | Cohens Kappa |
|---|---|---|---|---|---|
| Six Conv. Layers at each level, work in parallel with two BiLSTM layers, then their output are concatenated | 95.55 | 95.52 | 95.55 | 95.52 | 0.9465 |
| Two Conv. Layers at each level, work in parallel with three BiLSTM layers, then their output are concatenated | 75.97 | 78.93 | 75.97 | 75.27 | 0.7107 |
| Two Conv. Layers, followed by BatchNormalization layer, work in parallel with two BiLSTM layers, then their output are concatenated | 87.13 | 89.98 | 87.13 | 87.23 | 0.8456 |
| One Conv. Layers, work in parallel with three BiLSTM layers, then their output are concatenated | 88.63 | 88.99 | 88.63 | 88.51 | 0.8633 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning. Sensors 2021, 21, 2141. https://doi.org/10.3390/s21062141
Nafea O, Abdul W, Muhammad G, Alsulaiman M. Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning. Sensors. 2021; 21(6):2141. https://doi.org/10.3390/s21062141
Chicago/Turabian StyleNafea, Ohoud, Wadood Abdul, Ghulam Muhammad, and Mansour Alsulaiman. 2021. "Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning" Sensors 21, no. 6: 2141. https://doi.org/10.3390/s21062141
APA StyleNafea, O., Abdul, W., Muhammad, G., & Alsulaiman, M. (2021). Sensor-Based Human Activity Recognition with Spatio-Temporal Deep Learning. Sensors, 21(6), 2141. https://doi.org/10.3390/s21062141