1. Introduction
The importance of safety is indisputable for any aircraft from unmanned aerial vehicles (UAVs) to commercial flights. Sensor redundancy is the basic element for safety critical systems. There are multiple types of redundancy from sophisticated voting methods [
1] to analytical redundancy [
2,
3]. In sensor fusion, different types of sensors measure the same phenomenon to achieve more robustness. Beyond fault detection capability of multiple sensors, sensor fusion can give improved performance compared to each component [
4,
5,
6].
For fixed-wing UAVs and aircraft, the most dangerous flight phases are final approach and landing [
7] where precise navigation data are the key factor. Navigation data are acquired from Global Navigation Satellite System (GNSS) and Instrument Landing System (ILS) if ILS is available at the target landing site. Numerous extensions and additional sensors were introduced to aid piloted landing and support autonomous landing. Charnley [
8] presented an auto-landing system in 1959 based on ILS and barometer for the first part of the approach (above 30.5 m height) and radio altimeter and magnetic leader cable in horizontal plane for the landing part. Today, augmented GPS solutions can also meet the requirements of the CAT IIIb approach [
9]. The increasing demand for aerial mobility and transport motivates researchers to develop navigation solutions with less infrastructural dependence (radio beacons and satellites). Camera-based navigation sensors provide more autonomy in the case of unavailable or degraded GNSS, and enhance robustness in sensor fusion. Camera sensors are completely passive and non-cooperative which is beneficial for military use, and the lack of signal emission is also important in future civil utilization where dense population of UAVs could interfere and cause signal pollution.
Vision-based navigation in general has three main components: sensor type (ultraviolet [
10], infrared [
11,
12], visible RGB/mono [
11,
13], stereo [
14]), a priori data (terrain model [
10], satellite images [
15], UAV images [
16], 3D position of key features [
11,
13,
14]), and data accumulation (single frame [
11,
13,
14] and optic flow/SLAM [
6,
16,
17,
18,
19,
20]). Runway relative navigation for autonomous landing is a special case. The runway and its standardized markings are useful key features with known 3D positions, and they can be applied in the most critical phase of the approach when the aircraft has low altitude and thus highest precision is required. All-weather marking solutions exist (infrared (IR) and ultraviolet (UV)), however detection of current runway markers requires good visibility conditions. The vehicle has high speed and long-range detection is required. Vision-based solutions for autonomous landing of fixed-wing aircraft always use information about the target runway and the detection of relevant runway features is the starting point of navigation data extraction.
If a 3D runway model is available, one can generate an artificial image of it from an estimated 6D pose (3D position and 3D attitude), then it can be fine tuned based on detection in the real camera image. In [
10], a GPS-IMU (Inertial Measurement Unit) 6D pose is used to generate a synthetic image of the runway ultraviolet lights, and it is registered with the actual detection in the UV image of the runway. UV is beneficial, because almost no natural background radiation is detectable on the surface of the Earth below 0.285 micron. Binary images of a complete polygon model of the runway with taxiway exits is generated in [
21] from a neighborhood of the IMU/GPS pose, and these images are compared with the shifted hue channel of the HSV version of an RGB camera image to get the best fit. From IMU pose and runway geoinformation, four edges are rendered in [
12] and line features are fitted in the real image which defined the homography from the synthetic image to the real image. Four corner points of the runway (parallel lines with four points) are also enough for 6D pose calculations. Hecker et al. [
11] use the Aeronautical Information Publication database to get 3D runway corner points, and this model is projected to camera image using global orientation derived from IMU and estimated position of the camera. The projection is fine-tuned in a region of interest (ROI) based on line contour features. Hecker et al. also use infrared camera along with RGB camera, and detection is performed on both sensors. The IR sensor was able to detect the runway surface from further distance (2 km), while runway markers were only visible in RGB images (<600 m). The same team introduces integrity check of a GNSS/INS based positioning and tracking system augmented by an optical navigation sensor [
22].
Visual-inertial odometry (VIO) [
23,
24] and visual-inertial simultaneous localization and mapping (VI-SLAM) and their extensions with GNSS [
17,
18] is the current development trend in visual navigation, but we still need better vision sensors in these complete multisensor solutions. Vision senors in navigation are used for enhancement of IMU/GPS Kalman filter solutions; however, most of the runway relative navigation methods rely on the estimate coming from the IMU/GPS which dependence can be eliminated with robust image processing.
Robust detection of a runway from long distance (>1 km) without a good initial guess is challenging. Deep learning solutions exist for runway detection in remote sensing images [
25]. Current long-range solutions for aircraft imagery utilize at least IMU attitude information to obtain ROI for the runway detection. Within 1 km from a 30 m width runway it is possible to define vision-only detection without any IMU support. The detection of runway features is also necessary for ROI-based methods, thus runway detection in camera images has to be addressed for any navigation sensor which is dedicated for the final approach. Obstacle detection during landing also requires runway detection [
26,
27,
28] to identify the target area.
Runway detection should be done in IR and RGB/monochrome camera images. IR has the advantage of weather independence, however, it has lower resolution, higher price, and lack of texture details. IR is beneficial for all-weather complete runway detection from longer distances, while RGB can provide detailed information about threshold marker and center line at the end of the approach and during landing and taxiing [
11]. Line features are straight edges which can be detected with horizontal/vertical Sobel filters, which are separable 2D filters thus they can be applied to the whole image at low computation cost. Hough transform is used in [
13,
29,
30,
31], which gives a complete representation of possible lines, but has higher computational cost and short segments on the same line gives as high response as a long continuous line and the separation of lines with same orientation and close distance is hard. Detection of short line features is not possible with a complete Hough transform. Specialized line segment detectors LSD [
32] and EDLines [
33] are used in [
34]. In [
35], the authors present a family of edge detectors for various orientations. Beyond line feature detection, the registration of a synthetic image with known 6D pose [
36,
37] and registration of real images from database [
38] are also applied to solve the runway detection problem.
Most of the runway detection methods are developed and tested in a simulator environment where the runway area has perfect contours and markings. In real life, the side line and threshold line of the runway is often missing or its width is too narrow for detection from longer distances, thus complete runway detectors need to rely on texture difference or contours in special color channels to detect the tarmac area. The difference between the tarmac and the environment has much higher variability (seasons and different runways) than the difference between the tarmac and the threshold marker. Usage of an image database for matching has high computational complexity and fine tuning is still necessary to have precise detection results. All existing methods focus on the complete runway detection with the assumption of flat runways. This assumption is not true for km long targets; furthermore, many airfields have a bump at the middle to support acceleration and deceleration of aircraft. Threshold markers (white bars) can support relative navigation without any other features they are designed for good visibility and they lay in a planar area. The pattern of these white bars provide additional information for filtering out false detections, and makes it possible to detect runway in full frames without initial guess coming from IMU/GPS measurements. Our detection method is designed for the last phase of the approach (600–50 m from threshold of 30 m width runway), where the most precise navigation data is required. This paper does not cover the landing and taxiing phase, where radio altimeter, center line, and side line detection (they are in close proximity during landing phase) can be used.
Theory and technology for vision-based runway relative navigation were ready for real flight validation in 2018. One major goal of the H2020 VISION (Validation of Integrated Safety-enhanced Intelligent flight cONtrol) project was to build a fixed-wing experimental UAV with a cutting edge stereo sensor [
14] and pair of monocular sensors with different field of view (FOV) to validate vision-based sensor performance in real flight situations and use visual sensors for integrity monitoring and sensor fusion [
5,
24].
Optical navigation sensors have great potential in sensor fusion setups. Different sensors have different bias and standard deviation with low probability for having fault at the same time. Avionics of fixed-wing UAVs and manned aircraft have IMU for attitude, GNSS for position, Satellite-based Augmentation System (SBAS) for the reduction of GNSS bias, radar altimeter for landing support, barometric altimeter, airspeed sensor, and compass for yaw angle measurement. The bias and standard deviation of optical sensors are theoretically decreasing during the approach, which attracts interest of researchers and industry to add them to the sensor setup. Camera sensors are relatively cheap and have low power/weight footprint; however, on-board image processing requires a payload computer, and image processing adds >20 ms delay between the measurement (exposure) and the navigation data, which makes the integration of optical sensor data hard into the sensor fusion filter.
This paper presents the methods and real flight test results for the pair of monocular RGB sensors. We focus on raw image-based navigation performance, because we consider the vision sensor as a building block for integrity test and sensor fusion with IMU/GNSS. Integration of IMU units into the camera can be beneficial for robotic applications; however, the methods which are described here do not need IMU. The core of our runway detection is a robust threshold marker detection which can support IMU-free runway detection when the marker becomes visible and also provides superior precision at the end of the approach. The sensor hardware is also described with the achieved results of the on-board real-time operation during flight tests. The results of different FOV sensors are compared. Beyond the own flight test results, the image processing method is also tested on the real flight data which was provided by the C2Land project [
11]. The paper summarizes the main concepts for navigation data extraction from image features of a runway (
Section 2), presents the image processing method for threshold marker detection (
Section 3), introduces the experimental platform and the monocular image sensor hardware (
Section 4) and finally discusses the raw image-based navigation results (
Section 5).
2. Navigation Data from Runway Features
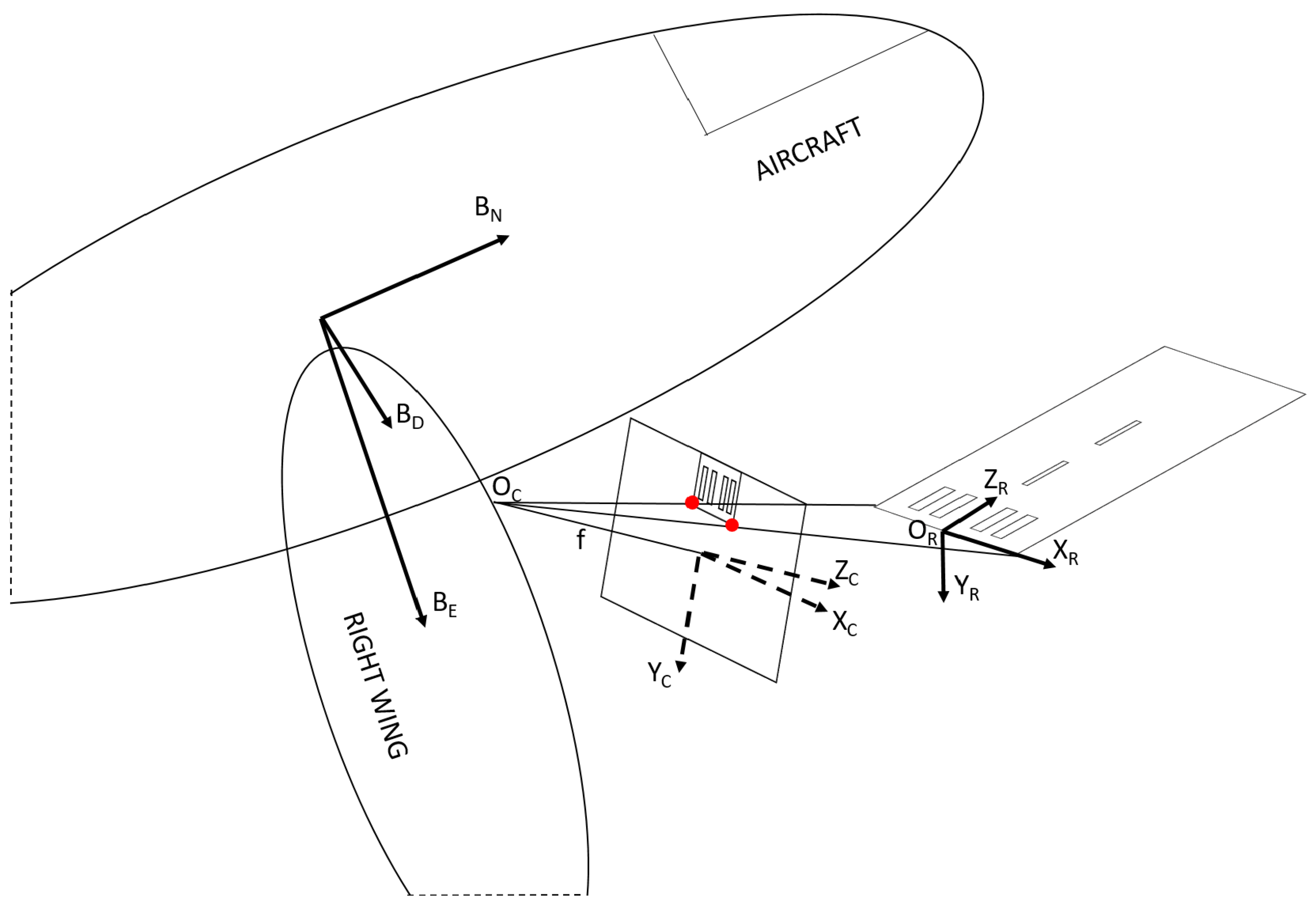
Navigation always defines coordinates according to a reference coordinate system. The most common global reference is the Latitude Longitude Altitude (LLA) of the WGS’84 system, which defines a point on the geoid surface model of the Earth and altitude above that point. For low-range aerial vehicles, the most common navigation frame is the North East Down (NED) Cartesian coordinate system which is defined by an origin on the surface, and flat earth approximation gives the North and East unit vectors.
Figure 1 presents the relevant coordinate systems and their relations in 3D. Runway features are detected in the 2D image of the camera which is on a plane in the camera frame at
, where
f is the focal length of the pinhole camera. From these feature points in the image and physical position coordinates of these features in 3D, one can get the 6D relative pose (3D position and 3D attitude) to any global Cartesian systems (global NED,
). The relation of the camera
and the aircraft body system
can be obtained through camera calibration.
In the most general case, 3D positions of features are given with their 2D projections into the image (
). The question of Perspective-n-Point (PnP) is to find 6D pose of a calibrated camera [
39].
Equation (
1) describes the homogeneous transformation of the projection from homogeneous physical coordinates
to homogeneous image coordinates
, where
s is a scaling factor because many physical points have the same image projection. The first matrix of the right side describes the intrinsic parameters of the pinhole camera, which are known from calibration. Focal length in pixels
are derived from the physical dimensions of a sensor pixel, skew
(zero for most optics), and image coordinates of the principal point
(the center of the image for a high quality optics). The second matrix encodes the extrinsic parameters which are the 3D translation (
,
,
) and 3D rotation (3 × 3 matrix
to
) of the camera. PnP defines the unknown parameters of the extrinsic matrix, which encodes the 6D pose of the camera.
Runway features lie on a surface in 3D thus more specific pose estimation methods are available. Homography defines transformation between 3D positions on a surface (
) to 2D projections in a camera image. In Equation (
1), the column of the extrinsic matrix (
,
,
) which corresponds to
z can be excluded.
Equation (
2) describes this special case were the 3 × 3 matrix which describes the overall transformation is called the homography matrix and 6D pose of the camera can be decomposed from it [
40]. Features on the same plane surface can also support camera motion estimation and calibration [
41,
42].
In the VISION project [
43] beyond homography, the 3-point algorithm of Li et al. [
44] was also used for runway relative navigation, because it has minimum number of image features which can be tightly coupled into the sensor fusion. The three points are the right and left corner points of the runway and the vanishing point of the side lines.
D denotes the known width of the runway, and
and
are the 3D image vectors with real metric sizes pointing from the camera frame origin to the detected corner features on the image surface
.
and
are the vectors pointing from the camera frame origin to the physical corners. Let
be the physical vector of the runway threshold and
be the image vector of the vanishing point.
,
depths are the two unknowns of Equation (
3).
t and
should be perpendicular, while the length of
t is equal to the width of the runway (
D).
The camera frame to runway frame rotation matrix R can be defined by the normalized (hat) version of the perpendicular
t and
vectors (Equation (
4))
is the vector in camera frame pointing to the runway frame origin. Translation of the camera in runway frame is . If the navigation problem is solved by homography, we just calculate the three image features which corresponds to the result; however, the above equations give insight into the close connection of these features to the runway relative navigation data.
3. Runway Marker Detection
Runway detection defines achievable accuracy of later steps in sensor fusion [
24] or visual servoing [
45,
46]. Runway markers, especially the threshold bars, are designed for good visibility and provide relative visual navigation for the pilots. The number of bars indicates the width of the runway and these large long rectangles give enough features for homography. We assume that the real size and relative position of threshold bars are known, and they are on a planar surface (homography). We use the runway relative metric coordinate system with origin at the center of the bottom line of the threshold bars (
Figure 1).
Threshold bars are transformed rectangles in the captured images. We assume that spatial order and distance/width ratio (
) of consecutive rectangles is similar to the top-view template (representation). It is true for possible approach trajectories towards the pattern from
direction, in general, only the cross-ratio can be used which describes relation of four collinear points. The detection has two main stages: detection of possible transformed rectangles and then representation matching of the threshold marker. The representation consists of 4–16 rectangles with given distance/width ratios. At Septfonds airfield we have 2 × 3 bars, the width of a bar is 1.5 m and the distance between the the two bars in the middle is 6 m while the other bars have 4.5 m separation. An example image and the corresponding detection are presented in
Figure 2. Optics can have radial distortion; however, in the case of small distortion, the detection of short line features is possible without undistortion of the image. Undistortion is applied after the runway marker representation matching inside the ROI of the detected threshold bar area.
3.1. Detection of Threshold Bar Candidates
Our approach focuses on the threshold bars which are brighter quadrangles on the runway surface. The image is converted to grayscale, and the transposed image is also created to calculate horizontal and vertical edge features in parallel. For vertical edge detection, a 3 × 3 Sobel filter is used on each 2nd row of the image and on its transposed version (horizontal edges).
Figure 3 presents the result of the Sobel calculations for the vertical edges with both bright-to-dark (right) and dark-to-bright (left) edges where the local extreme values are selected above an absolute value threshold. After filtering out singletons, we start to build right and left edge chains (similarly in the transposed image for bottom and top edge chains). Edge chains are trees in general, however they are almost straight lines for the threshold bars (small branches or top/bottom corner area added in the case of large roll angles). Pruning of shorter branches results right and left line segments for the threshold bars. Pairing of right and left segments is done through the horizontal segments which should intersect both a right and left segment to create a clamp. Clamps can have more than two intersecting horizontal segments thus we need to choose the two extremal one which leads Left-Right-Bottom-Top (LRBT) complete quadrangles and also LRT and LRB detections which also define quadrangles. We do not care much about other false detected clamps, because we apply representation match for the threshold marker to choose the clamps (transformed rectangles) which represent the bars of the threshold marker.
3.2. Representation Matching of the Threshold Marker
Detection of bright quadrangles is only sufficient inside a ROI which is often given by an IMU-based guess about the position of the runway in the image. For an independent full-frame detection, we need to assign quadrangle candidates to positions in a complex pattern (representation). In the Septfonds case, we need to assign 6 bar indices to 6 quadrangles from possibly a hundred of candidates.
The general idea of representation matching is described in [
47]. We derived a special case with some additional heuristics to meet our operational needs. A representation can have elements of multiple types (representation of a face has eyes, ears, hair, etc.) and each has a cost of goodness. The key is the cost of relative pose of the elements in the image compared to an ideal representation were each element can be connected to multiple elements through the cost functions. We have a simple representation with only bars, and for each bar we have relative pose cost only for the consecutive bar. At this point,
M transformed rectangles are given in the image and the threshold marker (
B bars) is required (if it presents in the image).
We assume that the spatial order of rectangles in the image is the same as in the ideal threshold bar pattern (
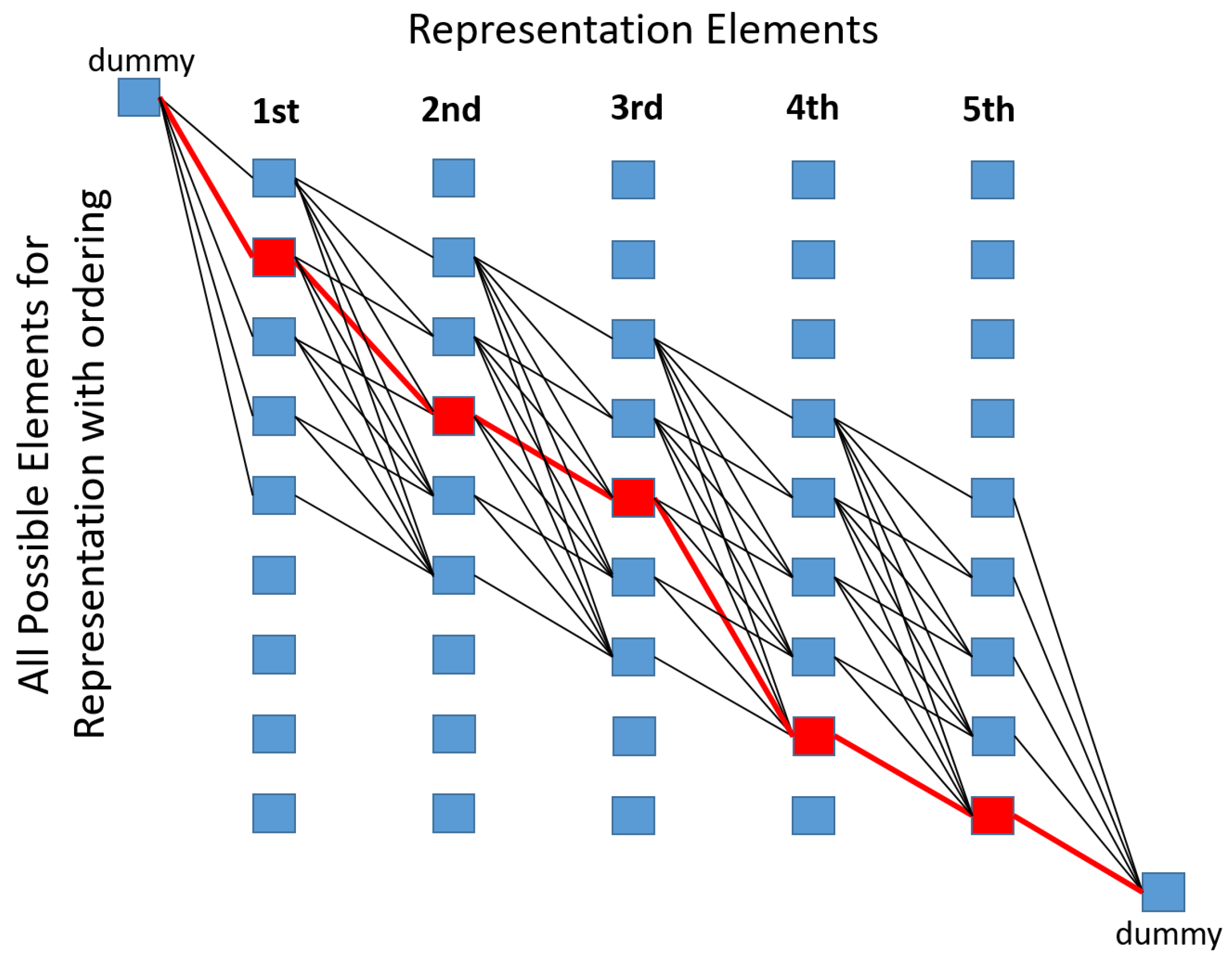
B rectangles as a top-view pattern). The bar candidates can be ordered according to their x coordinate, and it is sure that any rectangle in a fit cannot be followed by a rectangle with lower index. To evade exhaustive search of all possible combinations, dynamic programming is applied.
Figure 4 shows the simplest case of the dynamic programming table with ordered elements. Each edge in the table represents a succession cost in the pattern, and each route between the two dummy nodes corresponds to a pattern fit (selected candidates for each position in the pattern). In our model, only consecutive elements of the pattern interacts in the cost function which yields
M rows and
B columns in the table. However, we let missing elements which requires additional edges between elements of nonadjacent columns thus the number of edges is multiplied by 2. Spatial ordering of bar candidates also makes it possible to further decrease the edges to be calculated in the table by excluding far elements in successor search. This excursion destroys theoretical optimality, however, we have already forced to use heuristic approach to define the cost functions.
Each edge in
Figure 4 represents a succession cost assuming that the two rectangle candidates are chosen for the two consecutive positions in the representation. We have the following assumptions which are mainly true in the case of an approach towards the runway marker:
Line segments of the threshold bars are not longer than the sides of the quadrangle: number of pixels beyond corners.
The two TB and two LR segments have nearly the same length: .
Consecutive candidates have nearly same width and height: .
Vertical directions for consecutive candidates nearly the same: .
The ratio of width and distance between pattern elements is the same as in the top-view pattern: .
The first two elements inhibit the false bar detections while the other components lead the optimization towards the correct identification of the bars inside the threshold marker. The weighted sum of the cost components is used with additional penalty on a missing element in the representation match. Weights are not sensitive parameters, they just normalize the components.
Figure 5 visualizes the succession costs.
Dummy nodes are connected to all possible first and last candidates with zero cost edges. In the example of
Figure 4, we have 5 representation elements (missing elements are not allowed) in the representation, thus the last 4 candidates cannot be the first element, similarly the first 4 candidates cannot be chosen as the last element. The candidates are ordered, which means that only candidates with higher indices are available as a successor. Succession costs (last 3 entries of the cost function list) are weights on the edges between the candidates, while candidates also have their own goodness (first two entries of the cost function list). The solution is the minimal cost route between the two dummy nodes which can be obtained by the Dijkstra algorithm.
At this point, we have the best possible matching of quadrangle candidates for the threshold marker. The cost function makes it possible to drop weak detections (typically when the marker is not present in the image) which also increases the robustness. The threshold marker area is further processed to obtain better accuracy.
3.3. Fine Tune and Output Generation
After runway marker detection, we can use the homography which is defined by the corner features of the bars and their known 3D positions to create a top-view from the threshold marker area.
Figure 6 shows the top-view on which we repeat the complete detection algorithm without downsampling but with undistortion. The result is the final detection of threshold bars and the corresponding homography.
The output of the image processing is the runway relative 6D pose and the three key image feature points which are equivalent representation of the 6D pose. Key image feature points are used in tight coupling into the navigation/control. Representation match is useful for any special land marking detection where the elements of the pattern can be detected with high recall.
4. On-Board Vision System
Our vision-based navigation sensor which is described in this paper (SZTAKI sensor) was a building block of a complex UAV system (
Figure 7). It is designed for real flight validation of navigation and guidance performance recovery from sensor failures (e.g., degradation of GPS/SBAS or ILS) [
5]. The experimental platform was equipped with an avionic (computer and navigation sensors: 9-axis IMU, GNSS, barometer, and pitot tube) developed by ONERA, a stereo-vision sensor of RICOH company, and SZTAKI sensor based on 2 different field-of-view (FOV) cameras. RICOH stereo and SZTAKI monocular sensors are devoted to runway relative navigation. Other navigation sensors (IMU, GNSS, and barometer) are used for ground truth collection. On-board emulated ILS and GNSS degradation models are applied to emulate failures and degradations in the guidance performance recovery tests where the independent optical sensors provided the necessary additional information. Stereo sensor was also used for obstacle detection on the runway. All the payloads were time-synchronized by the pulse per second (PPS) signal of the central GPS receiver. Information of vision-based sensors were processed in real-time and collected by ONERA payload for ground-station feedback and for the navigation filter [
14].
The SZTAKI sensor is developed by our team and dedicated to monocular vision-based navigation. The system has two GEthernet cameras (2048 × 1536 image resolution, 7.065 × 5.299 mm physical sensor size) with narrow angle (12 mm focal length, 32.8· FOV) and wide angle (6 mm focal length, 60.97· FOV) optics. Both cameras can see the runway during the approach which makes the comparison of the different FOV sensor outputs possible. This setup is good for scientific experiments. In a real use case, the FOVs can be narrower, because if the narrow FOV sensor cannot see the runway, the wide FOV system surely sees it during final approach assuming small/medium deviance in the position/orientation.
Figure 8 presents the components and communication interfaces of the monocular navigation sensor. Each camera has a dedicated Nvidia TX1-based image processing computer (256 CUDA Cores, Quad-core ARM Cortex-A57, 4 GB LPDDR4). One of the computers plays a master role and only this subsystem provides the output of vision system.
All calculations are done on-board, while the ONERA payload sends diagnostics with downsampled camera images and state variables through wifi to the ground station. Payload computers must have small power/weight footprint and high computational capacity. RS232 communication interfaces are used for state information exchange and UDP for transmission of the diagnostic images.
The two cameras are placed under the wings, while the image processing modules reside inside the bottom payload bay of the K50 aircraft. Monocular camera sensors are placed in metallic tubes which have 3D-printed plastic holders. The cameras and optics lay on a balanced plate with vibration dumpers and an IMU unit is also fixed to the plate for supporting IMU-based calibration (
Figure 9).
Intrinsic parameters of the cameras were defined through the classical checkerboard calibration method [
48]. Beyond focal length and principal point, 2nd and 4th order radial distortion parameters were identified. Lenses with minimum radial distortion were used, because on-line undistortion of the image is computationally expensive. With small distortion, the line features can be detected in the original image, and only some selected feature points should be undistorted to get exact pinhole representation for homography or other navigation data calculations.
Identification of extrinsic parameters of a camera (aircraft body system
to camera
) is a more challenging task. The simplest but less accurate way is to fix a 3rd camera near the central IMU with known relative pose, and stereo calibrations are possible to the three pairings to get 6D poses of each camera relative to the remaining two which gives the external parameters. A more precise solution is to add IMU units next to each camera, have a fixed checkerboard in FOV and move the aircraft which supports a Camera-IMU calibration [
18,
49]. It is interesting that even the runway marker can be used for calibration this way. We obtained 2–3 cm precision with the first method which was suitable for our navigation sensor setup which operates at 30–600 m distances, orientation was also measured by an IMU-only approach.
Image processing has an inevitable time delay which must be considered in any vision-based navigation system. The SZTAKI sensor sends two types of messages. At time of exposure it sends a timestamp message, and later the corresponding image processing results. This makes able the Kalman filter with time delay to prepare the filter for the upcoming delayed measurement. Results contain 3D position and Euler angles of the aircraft with the raw coordinates of three key features of the runway in the image (pixel coordinates of left and right corner points and the vanishing point of the side lines). These features can be derived directly from the threshold marker representation. The vision sensor was able to operate at 15 FPS, however 10 FPS was used during flight tests to provide stable operation with approximately 60 ms delay.
6. Conclusions
This paper introduces an optical navigation sensor for fixed-wing aircraft during final approach to a runway with a visible threshold marker. Vision-based navigation sensors are additional building blocks for INS/GNSS sensor fusion. Raw precision of vision sensors is still an important issue. Robust and continuous detection of threshold marker is solved by representation matching of quadrangle candidates coming from a Sobel-based edge chain pairing. After threshold marker initial detection, homography can generate a top-view projection of the threshold marker area on which fine-tuning of key corner markers is possible. A complete hardware solution was also designed for real flight tests. On-board real-time performance was 10 Hz stable (15 Hz free run avg.) full frame (2048 × 1536) detection with 60 ms image processing delay.
Navigation data of the vision sensor were compared to the GNSS(SBAS)/INS sensor fusion results, which confirmed high precision for longitudinal distance and height within 400 m and acceptable precision for lateral displacement (lateral error is also precise for C2Land data within 400 m). Yaw and pitch angles are also calculated precisely, however, roll angle measurements were degraded by the vibration dumpers. Image processing approach was also compared to the competitive C2Land project results, which confirmed that threshold marker based approach is beneficial within 400 m, however, side line detection can enhance lateral accuracy. The threshold marker detector can also give good estimates within 600 m for the ROI-based complete runway fitting methods.
One of the most important design parameters is the FOV of the optics. Comparison of 32.8 degree and 60.97 degree optics suggests that using a larger FOV is better for operational robustness while narrow optics gives mainly additional detection range. Accuracy improvement is significant only for long distance measurements. Large idealistic (plane surface, no dirt) visual markers can enhance the robustness and precision of runway relative navigation; the methods which are described in this paper can be applied for other patterns, for instance, threshold bars with touch down markers or other fixed visual features nearby the runway.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}