
How to Interact with a Fully Autonomous Vehicle: Naturalistic Ways for Drivers to Intervene in the Vehicle System While Performing Non-Driving Related Tasks





Abstract
:1. Introduction
- RQ1: What are the most and least preferable natural input interactions in FAVs regardless of NDRTs and intervention scenarios? How could FAVs help regulate interactions based on the driver’s in-vehicle activity and the driving context?
- RQ2: Based on previous studies [14,25,26,27] that show that physical and cognitive load negatively affect user interaction and influence human–computer interaction and design, how do NDRTs with various physical and cognitive engagement levels affect driver acceptance of input interactions inside FAVs?
- RQ3: As maneuver-based intervention is an essential technique since it gives AV drivers a feeling of control and satisfaction compared to pure automation [24,28], how do maneuver and nonmaneuver-based intervention scenarios affect a driver’s selection of input interactions? Additionally, which factor most influences the selection of input interactions inside FAVs?
- Demonstrate the most naturalistic input interaction possibilities in FAVs for NDRTs, according to variation in physical and cognitive load demands.
- Understand the factors that affect a driver’s natural input interaction while intervening with the FAV system and highlight their impacts.
- Suggest guidelines to design natural input interaction channels for FAVs based on the driver’s level of engagement in NDRTs and the specific intervention scenario. In other words, design a mental model to represent the driver’s method of selecting the most appropriate input interaction inside the FAV.
1.1. Literature Review
1.2. Proposed Input Interactions, NDRTs, and Intervention Scenarios
2. Method
2.1. Procedure
2.2. Survey Design
- Familiarity: I know how to use this input interaction or have used it before.
- Quick to learn: I think I can learn this input interaction quickly and easily.
- Easy to use: I think it is easy to use this input interaction to request this scenario while performing the current NDRT (e.g., eating).
- Satisfactory: I feel satisfied using this input interaction to request this scenario (e.g., to request the overtaking) while performing the current NDRT.
- Naturalistic: I think I would feel natural interacting with the car using this input interaction to request the current scenario (e.g., to request the overtaking) while I am involved in the current NDRT.
- Controlling: I feel I am optimally controlling vehicle behavior using this input interaction to request this scenario while performing the current NDRT.
- Useful: I think this input interaction could match the typical interactions in today’s cars to be used to request the current scenario (e.g., stopping the car!) while performing the current NDRT (e.g., relaxing).
3. Results
3.1. Identifying Input Interaction Preferences
3.1.1. Input Interaction Preference Order Based on the Ranked Data
3.1.2. Input Interaction Preference Order Based on the Five Parameters Rate
3.2. Influence of NDRTs on the Input Interactions
3.2.1. Preference Order of Input Interactions in Each NDRT
3.2.2. Input Interaction Preference Rate across NDRTs
3.3. Influence of Physical and Cognitive Load
3.3.1. High Physical Load vs. Low Physical Load
3.3.2. High Cognitive Load vs. Low Cognitive Load
3.4. Influence of Intervention Scenarios (MBI vs. NMBI)
4. Discussion
4.1. Evaluate the Proposed Natural Input Interactions
4.2. Effect of NDRT on the Selection of Input Interaction Regardless of Intervention Scenarios
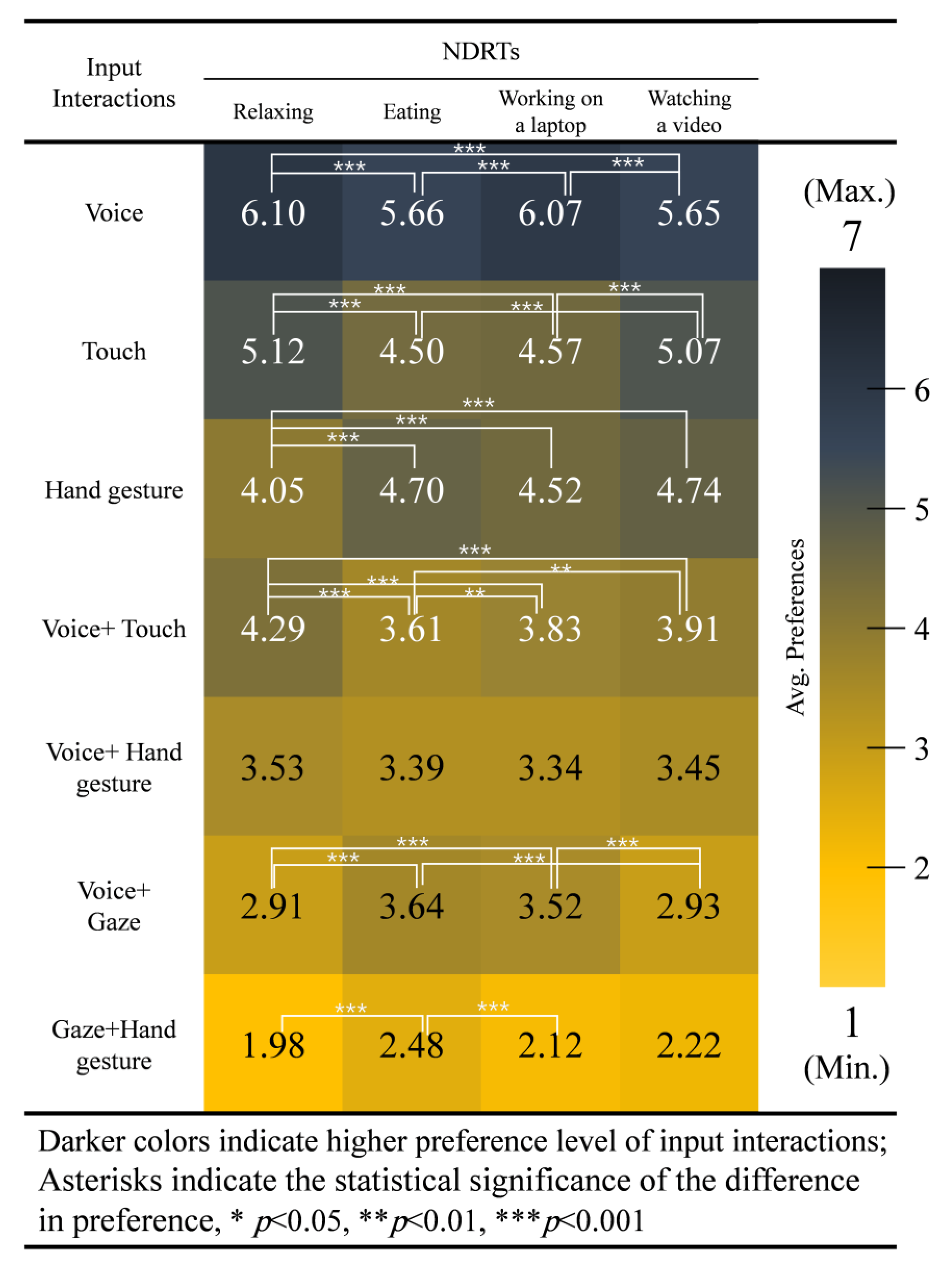
- Voice input: Participants significantly preferred voice input when relaxing or working on a laptop than when eating or watching a video. Indeed, voice input was known to minimize distraction [34] and require minimum visual attention [21]. Conversely, voice input disrupts driver attention when another sound source is active in the FAV, like when watching a video, and is inconvenient when the driver’s mouth is busy. This confirms findings in [16,34].
- Touch input: Participants significantly preferred touch input while relaxing or watching a video than while eating or working on laptop. Unsurprisingly, touch input is preferred more when the NDRT does not require the use of hands. In other words, since the use of touch input increases physical load, drivers prefer not to use it while they are engaged in high physical load NDRTs.
- Hand gesture: Participants preferred hand gesture while watching a video, eating, and working on a laptop significantly higher than when relaxing. Indeed, when relaxing, drivers would not want to initiate physical activity like hand movement and risk their relaxation. However, drivers are physically active when eating or working on a laptop, which explains why hand gesture would be easier to use as an input interaction for those NDRTs.While watching a video, hand gestures seem like the least obtrusive option; i.e., drivers prefer not to avert their gaze from the screen, give a voice command, or lean forward to perform touch input. Therefore, for this NDRT, hand gesture could be an ideal candidate.
- Voice + Touch: Participants preferred voice + touch when relaxing significantly higher than in all other NDRTs. However, using voice + touch input while eating ranked significantly lower than using it when working on laptop or watching a video. Participants still do not prefer to use voice inputs while eating, and adding touch to voice would increase physical load for the driver. Therefore, voice + touch input interaction is preferable while relaxing mainly, though not as preferable as voice alone. Although an input interaction that includes voice would seem counterintuitive to watching a video, a single word could be used to trigger an interaction, which the driver could complete using touch input. Therefore, it also scores relatively high while engaging in watching a video.Tscharn et al. [17] found that voice + touch input causes a physical and cognitive load and redirects attention from the driver’s current view to the touch panel to interact. Thus this input was preferred only while relaxing which has no high physical or cognitive load and nothing to be distracted from. On other hand, it was not preferable while eating, working on laptop, or watching a video, NDRTs that require driver attention. Furthermore, each of these NDRTs cause high physical or cognitive load, which make an input that increases them not preferable.
- Voice + Hand gesture: Participants reported no significant differences in using voice + hand gesture between the four NDRTs. Thus, using hand gesture input could be considered as a neutral input between the four NDRTs where no significant difference in usage could be noticed. This finding confirms [17], where voice + hand gesture was most preferred and shown as more naturalistic than voice + touch input for intervening in the FAV.
- Voice + Gaze: Participants preferred to use voice + gaze while eating or working on a laptop significantly higher that when relaxing or watching a video. Although voice input alone was not preferred to use while eating, combining gaze with voice interaction compensates for the drawbacks of using voice input alone; e.g., drivers could use gaze to select an intended object while chewing, then use voice to confirm the selection via a trigger word between bites. This decreases the physical load voice input causes in talking which make its usage while eating or working on a laptop preferable. On the other hand, it may not work well while watching a video, where any voice commands and diversion of gaze would interrupt the experience or while relaxing where drivers would not want to initiate physical activity like speaking or moving their eyes and risk losing their relaxing state.
- Gaze + Hand gesture: Participants preferred gaze + hand gesture while eating significantly higher than while relaxing or working on laptop. Again, gaze input is not preferred while relaxing, yet seems helpful when the participant is engaged in a high physical load task like eating because drivers are physically active. This matched with the case of using hand gesture alone. It was also less preferable while relaxing.
Physical and Cognitive Load Variation Effect
4.3. Effect of Intervention Scenario Category
- Different types of NDRTs and accompanying variation in the levels of physical and cognitive load primarily influence the selection of input interactions.
- Different categories for intervention scenarios (maneuver and nonmaneuver-based interventions) are secondary factors that influence the selection of input interactions.
4.4. Driver’s Decision-Making Model for Naturally Intervening FAV
FAV Suggesting Input Interactions
4.5. Limitations
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- SAE International. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. Available online: https://www.sae.org/standards/content/j3016_201806 (accessed on 15 June 2020).
- NHTSA. Automated Vehicles for Safety. National Highway Traffic Safety Administration. Available online: https://www.nhtsa.gov/technology-innovation/automated-vehicles-safety (accessed on 13 April 2018).
- Yeo, D.; Lee, J.; Kim, W.; Kim, M.; Cho, K.; Ataya, A.; Kim, S. A Hand-Over Notification System of Vehicle Driving Control according to Driver’s Condition based on Cognitive Load in Autonomous Driving Situation. In Proceedings of the HCI Korea, Seogwiposi, Korea, 13–16 February 2019; pp. 495–500. [Google Scholar]
- Kim, H.S.; Yoon, S.H.; Kim, M.J.; Ji, Y.G. Deriving future user experiences in autonomous vehicle. In Proceedings of the 7th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Nottingham, UK, 1–3 September 2015; pp. 112–117. [Google Scholar]
- Stevens, G.; Bossauer, P.; Vonholdt, S.; Pakusch, C. Using Time and Space Efficiently in Driverless Cars: Findings of a Co-Design Study. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–14. [Google Scholar]
- Pfleging, B.; Rang, M.; Broy, N. Investigating user needs for non-driving-related activities during automated driving. In Proceedings of the 15th International Conference on Mobile and Ubiquitous Multimedia, Rovaniemi, Finland, 13–15 December 2016; pp. 91–99. [Google Scholar]
- Hecht, T.; Darlagiannis, E.; Bengler, K. Non-driving Related Activities in Automated Driving–An Online Survey Investigating User Needs. In Proceedings of the International Conference on Human Systems Engineering and Design: Future Trends and Applications, Springer, Cham, 14 August 2019; pp. 182–188. [Google Scholar]
- Manary, M.A.; Reed, M.P.; Flannagan, C.A.; Schneider, L.W. ATD positioning based on driver posture and position. SAE Trans. 1998, 2911–2923. [Google Scholar] [CrossRef]
- Large, D.; Burnett, G.; Morris, A.; Muthumani, A.; Matthias, R. Design Implications of Drivers’ Engagement with Secondary Activities During Highly-Automated Driving—A Longitudinal Simulator Study. In Proceedings of the Road Safety and Simulation International Conference (RSS), The Hague, The Netherlands, 17–19 October 2017; pp. 1–10. [Google Scholar]
- Bengler, K.; Rettenmaier, M.; Fritz, N.; Feierle, A. From HMI to HMIs: Towards an HMI Framework for Automated Driving. Information 2020, 11, 61. [Google Scholar] [CrossRef] [Green Version]
- Bilius, L.B.; Vatavu, R.D. A Synopsis of Input Modalities for In-Vehicle Infotainment and Consumption of Interactive Media. In Proceedings of the ACM International Conference on Interactive Media Experiences (IMX’20), Barcelona, Spain, 17–19 June 2020; pp. 195–199. [Google Scholar]
- Manawadu, U.E.; Kamezaki, M.; Ishikawa, M.; Kawano, T.; Sugano, S. A hand gesture based driver-vehicle interface to control lateral and longitudinal motions of an autonomous vehicle. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 1785–1790. [Google Scholar]
- Detjen, H.; Geisler, S.; Schneegass, S. Maneuver-based Driving for Intervention in Autonomous Cars. In CHI’19 Work-Shop on “Looking into the Future: Weaving the Threads of Vehicle Automation”; ACM: New York, NY, USA, 2019. [Google Scholar]
- Reimer, B.; Pettinato, A.; Fridman, L.; Lee, J.; Mehler, B.; Seppelt, B.; Park, J.; Iagnemma, K. Behavioral impact of drivers’ roles in automated driving. In Proceedings of the 8th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI ‘16), Ann Arbor, MI, USA, 24–26 October 2016; pp. 217–224. [Google Scholar]
- Yoon, S.H.; Ji, Y.G. Non-driving-related tasks, workload, and takeover performance in highly automated driving contexts. Transp. Res. Part F Traffic Psychol. Behav. 2018, 60, 620–631. [Google Scholar] [CrossRef]
- Detjen, H.; Faltaous, S.; Geisler, S.; Schneegass, S. User-Defined Voice and Mid-Air Gesture Commands for Maneuver-based Interventions in Automated Vehicles. In Proceedings of the Mensch und Computer (MuC’19), Hamburg, Germany, 8–11 September 2019; pp. 341–348. [Google Scholar]
- Tscharn, R.; Latoschik, M.E.; Löffler, D.; Hurtienne, J. “Stop over there”: Natural gesture and speech interaction for non-critical spontaneous intervention in autonomous driving. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 91–100. [Google Scholar]
- Oliveira, L.; Luton, J.; Iyer, S.; Burns, C.; Mouzakitis, A.; Jennings, P.; Birrell, S. Evaluating How Interfaces Influence the User Interaction with Fully Autonomous Vehicles. In Proceedings of the 10th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI’18), Toronto, ON, Canada, 23–25 September 2018; pp. 320–331. [Google Scholar]
- Lee, S.C.; Nadri, C.; Sanghavi, H.; Jeon, M. Exploring User Needs and Design Requirements in Fully Automated Vehicles. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–9. [Google Scholar]
- Frison, A.K.; Wintersberger, P.; Liu, T.; Riener, A. Why do you like to drive automated? A context-dependent analysis of highly automated driving to elaborate requirements for intelligent user interfaces. In Proceedings of the 24th International Conference on Intelligent User Interfaces (IUI’19), Marina del Rey, CA, USA, 17–20 March 2019; pp. 528–537. [Google Scholar]
- Kim, M.; Seong, E.; Jwa, Y.; Lee, J.; Kim, S. A Cascaded Multimodal Natural User Interface to Reduce Driver Distraction. IEEE Access 2020, 8, 112969–112984. [Google Scholar] [CrossRef]
- Neßelrath, R.; Moniri, M.M.; Feld, M. Combining speech, gaze, and micro-gestures for the multimodal control of in-car functions. In Proceedings of the 2016 12th International Conference on Intelligent Environments (IE), London, UK, 14–16 September 2016; pp. 190–193. [Google Scholar]
- Roider, F.; Gross, T. I See Your Point: Integrating Gaze to Enhance Pointing Gesture Accuracy While Driving. In Proceedings of the 10th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Toronto, ON, Canada, 23–25 September 2018; pp. 351–358. [Google Scholar]
- Detjen, H.; Faltaous, S.; Pfleging, B.; Geisler, S.; Schneegass, S. How to Increase Automated Vehicles’ Acceptance through In-Vehicle Interaction Design: A Review. Int. J. Hum.-Comput. Interact. 2021, 37, 308–330. [Google Scholar] [CrossRef]
- Kim, S.; Dey, A.K. Simulated augmented reality windshield display as a cognitive mapping aid for elder driver navigation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’09), Boston, Massachusetts, USA, 4–9 April 2009; pp. 133–142. [Google Scholar]
- Jutras, M.A.; Labonte-LeMoyne, E.; Senecal, S.; Leger, P.M.; Begon, M.; Mathieu, M.È. When should I use my active workstation? The impact of physical demand and task difficulty on IT users’ perception and performance. In Proceedings of the Special Interest Group on Human-Computer Interaction 2017 Proceedings, Seoul, Korea, 10 December 2017; p. 14. [Google Scholar]
- Du, Y.; Qin, J.; Zhang, S.; Cao, S.; Dou, J. Voice user interface interaction design research based on user mental model in autonomous vehicle. In International Conference on Human-Computer Interaction; Springer: Cham, Switzerland, 2018; Volume 10903, pp. 117–132. [Google Scholar]
- Frison, A.K.; Wintersberger, P.; Riener, A.; Schartmüller, C. Driving Hotzenplotz: A Hybrid Interface for Vehicle Control Aiming to Maximize Pleasure in Highway Driving. In Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI’17), Oldenburg, Germany, 24–27 September 2017; pp. 236–244. [Google Scholar]
- Hoffman, G.; Ju, W. Designing robots with movement in mind. J. Hum.-Robot Interact. 2014, 3, 91–122. [Google Scholar] [CrossRef]
- Park, S.Y.; Moore, D.J.; Sirkin, D. What a Driver Wants: User Preferences in Semi-Autonomous Vehicle Decision-Making. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar] [CrossRef]
- Fridman, L.; Mehler, B.; Xia, L.; Yang, Y.; Facusse, L.Y.; Reimer, B. To walk or not to walk: Crowdsourced assessment of external vehicle-to-pedestrian displays. arXiv 2017, arXiv:1707.02698. [Google Scholar]
- Walch, M.; Sieber, T.; Hock, P.; Baumann, M.; Weber, M. Towards cooperative driving: Involving the driver in an autonomous vehicle’s decision making. In Proceedings of the 8th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Ann Arbor, MI, USA, 24–26 October 2016; pp. 261–268. [Google Scholar]
- Kauer, M.; Schreiber, M.; Bruder, R. How to conduct a car? A design example for maneuver based driver-vehicle interaction. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; IEEE: Piscataway Township, NJ, USA, 2010; pp. 1214–1221. [Google Scholar]
- Walch, M.; Jaksche, L.; Hock, P.; Baumann, M.; Weber, M. Touch screen maneuver approval mechanisms for highly automated vehicles: A first evaluation. In Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications Adjunct (AutomotiveUI’17), Oldenburg, Germany, 24–27 September 2017; pp. 206–211. [Google Scholar]
- Kyriakidis, M.; Happee, R.; de Winter, J.C. Public opinion on automated driving: Results of an international questionnaire among 5000 respondents. Transp. Res. Part F Traffic Psychol. Behav. 2015, 32, 127–140. [Google Scholar] [CrossRef]
- König, M.; Neumayr, L. Users’ resistance towards radical innovations: The case of the self-driving car. Transp. Res. Part F Traffic Psychol. Behav. 2016, 44, 42–52. [Google Scholar] [CrossRef]
- Rödel, C.; Stadler, S.; Meschtscherjakov, A.; Tscheligi, M. Towards autonomous cars: The effect of autonomy levels on acceptance and user experience. In Proceedings of the 6th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI’14), Seattle, WA, USA, 17–19 September 2014; pp. 1–8. [Google Scholar]
- Walch, M.; Woide, M.; Mühl, K.; Baumann, M.; Weber, M. Cooperative Overtaking: Overcoming Automated Vehicles’ Obstructed Sensor Range via Driver Help. In Proceedings of the 11th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI’19), Utrecht, Netherlands, 21–25 September 2019; pp. 144–155. [Google Scholar]
- Winner, H.; Hakuli, S. Conduct-by-wire–following a new paradigm for driving into the future. In Proceedings of the 2006 FISITA World Automotive Congress, Yokohama, Japan, 22–27 October 2006; Volume 22, p. 27. [Google Scholar]
- Manawadu, U.; Ishikawa, M.; Kamezaki, M.; Sugano, S. Analysis of individual driving experience in autonomous and human-driven vehicles using a driving simulator. In Proceedings of the 2015 IEEE International Conference on Advanced Intelligent Mechatronics (AIM), Busan, Korea, 7–11 July 2015; pp. 299–304. [Google Scholar]
- Miglani, A.; Diels, C.; Terken, J. Compatibility between Trust and Non-Driving Related Tasks in UI Design for Highly and Fully Automated Driving. In Proceedings of the 8th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI’16 Adjunct), Ann Arbor, MI, USA, 24–26 October 2016; pp. 75–80. [Google Scholar]
- Wang, C. A framework of the non-critical spontaneous intervention in highly automated driving scenarios. In Proceedings of the 11th International Conference on Automotive User Interfaces and Interactive Vehicular Applications: Adjunct Proceedings (AutomotiveUI’19), Utrecht, Netherlands, 21–25 September 2019; pp. 421–426. [Google Scholar]
- Tan, H.; Zhou, Y.; Shen, R.; Chen, X.; Wang, X.; Zhou, M.; Guan, D.; Zhang, Q. A classification framework based on driver’s operations of in-car interaction. In Proceedings of the 11th International Conference on Automotive User Interfaces and Interactive Vehicular Applications: Adjunct Proceedings (AutomotiveUI’19), Utrecht, The Netherlands, 21–25 September 2019; pp. 104–108. [Google Scholar]
- Hecht, T.; Feldhütter, A.; Draeger, K.; Bengler, K. What do you do? An analysis of non-driving related activities during a 60 minutes conditionally automated highway drive. In Proceedings of the International Conference on Human Interaction and Emerging Technologies, Nice, France, 22–24 August 2019; pp. 28–34. [Google Scholar]
- Blanco, M.; Biever, W.J.; Gallagher, J.P.; Dingus, T.A. The impact of secondary task cognitive processing demand on driving performance. Accident Anal. Prev. 2006, 38, 895–906. [Google Scholar] [CrossRef]
- Merat, N.; Jamson, A.H.; Lai, F.C.; Carsten, O. Highly automated driving, secondary task performance, and driver state. Hum. Factors 2012, 54, 762–771. [Google Scholar] [CrossRef]
- Ataya, A.; Kim, W.; Elsharkawy, A.; Kim, S. Gaze-Head Input: Examining Potential Interaction with Immediate Experience Sampling in an Autonomous Vehicle. Appl. Sci. 2020, 10, 9011. [Google Scholar] [CrossRef]
- Oliveira, L.; Burns, C.; Luton, J.; Iyer, S.; Birrell, S. The influence of system transparency on trust: Evaluating interfaces in a highly automated vehicle. Transp. Res. Part F Traffic Psychol. Behav. 2020, 72, 280–296. [Google Scholar] [CrossRef]
- Continental, A.G. Continental and Leias New 3D Lightfield Display Bring the Third Dimension into Automotive Vehicles. 9 July 2019. Available online: https://www.continental.com/en/press/press-releases/2019-06-11-3d-instrument-cluster-174836Continental (accessed on 15 August 2020).
- Müller, C.; Weinberg, G. Multimodal input in the car, today and tomorrow. IEEE MultiMed. 2011, 18, 98–103. [Google Scholar] [CrossRef] [Green Version]
- Jung, J.; Lee, S.; Hong, J.; Youn, E.; Lee, G. Voice+Tactile: Augmenting In-vehicle Voice User Interface with Tactile Touchpad Interaction. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI’20), Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Sauras-Perez, P.; Gil, A.; Gill, J.S.; Pisu, P.; Taiber, J. VoGe: A Voice and Gesture System for Interacting with Autonomous Cars (No. 2017-01-0068); SAE Technical Paper; SAE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Diels, C.; Thompson, S. Information expectations in highly and fully automated vehicles. In Proceedings of the International Conference on Applied Human Factors and Ergonomics, Los Angeles, CA, USA, 17–21 July 2017; pp. 742–748. [Google Scholar]
- Gerber, M.A.; Schroeter, R.; Xiaomeng, L.; Elhenawy, M. Self-Interruptions of Non-Driving Related Tasks in Automated Vehicles: Mobile vs Head-Up Display. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI’20), Honolulu, HI, USA, 25–30 April 2020; pp. 1–9. [Google Scholar]
- Forster, Y.; Kraus, J.; Feinauer, S.; Baumann, M. Calibration of trust expectancies in conditionally automated driving by brand, reliability information and introductionary videos: An online study. In Proceedings of the 10th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI’18), Toronto, ON, Canada, 23–25 September 2018; pp. 118–128. [Google Scholar]
- Henry, S.G.; Fetters, M.D. Video elicitation interviews: A qualitative research method for investigating physician-patient interactions. Ann. Family Med. 2012, 10, 118–125. [Google Scholar] [CrossRef] [PubMed]
- Stanton, N.A.; Eriksson, A.; Banks, V.A.; Hancock, P.A. Turing in the driver’s seat: Can people distinguish between automated and manually driven vehicles? Hum. Factors Ergon. Manuf. Serv. Ind. 2020, 30, 418–425. [Google Scholar] [CrossRef]
- Fuest, T.; Schmidt, E.; Bengler, K. Comparison of Methods to Evaluate the Influence of an Automated Vehicle’s Driving Behavior on Pedestrians: Wizard of Oz, Virtual Reality, and Video. Information 2020, 11, 291. [Google Scholar] [CrossRef]
- Kittur, A.; Chi, E.H.; Suh, B. Crowdsourcing user studies with Mechanical Turk. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’08), Florence, Italy, 5–10 April 2008; pp. 453–456. [Google Scholar]
- Złotowski, J.; Yogeeswaran, K.; Bartneck, C. Can we control it? Autonomous robots threaten human identity, uniqueness, safety, and resources. Int. J. Hum.-Comput. Stud. 2016, 100, 48–54. [Google Scholar] [CrossRef]
- Braun, V.; Clarke, V.; Boulton, E.; Davey, L.; McEvoy, C. The online survey as a qualitative research tool. Int. J. Soc. Res. Methodol. 2020, 1–14. [Google Scholar] [CrossRef]
- Abbey, J.D.; Meloy, M.G. Attention by design: Using attention checks to detect inattentive respondents and improve data quality. J. Oper. Manag. 2017, 53, 63–70. [Google Scholar] [CrossRef]
- Young, G.; Milne, H.; Griffiths, D.; Padfield, E.; Blenkinsopp, R.; Georgiou, O. Designing Mid-Air Haptic Gesture Controlled User Interfaces for Cars. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–23. [Google Scholar] [CrossRef]
- Nie, N.H.; Bent, D.H.; Hull, C.H. SPSS: Statistical Package for the Social Sciences; McGraw-Hill: New York, NY, USA, 1975; Volume 227. [Google Scholar]
- Ghasemi, A.; Zahediasl, S. Normality tests for statistical analysis: A guide for non-statisticians. Int. J. Endocrinol. Metab. 2012, 10, 486–489. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corder, G.W.; Foreman, D.I. Nonparametric Statistics for Non-Statisticians; John Wiley & Sons: Hoboken, NJ, USA, 2009; pp. 99–105. [Google Scholar]
- Klein, G. Naturalistic Decision Making. Hum. Factors 2008, 50, 456–460. [Google Scholar] [CrossRef] [Green Version]
- Endsley, M.R. The role of situation awareness in naturalistic decision making. In Naturalistic Decision Making; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1997; pp. 269–284. [Google Scholar]
- Simon, H.A. Rational Choice and the Structure of the Environment. Psychol. Rev. 1956, 63, 129–138. [Google Scholar] [CrossRef] [PubMed] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NDRTs (1–4) | Description | Physical Load | Cognitive Load |
|---|---|---|---|
| Relaxing | The driver was in a resting condition, reclining and looking forward. | Low | Low |
| Eating | The driver was holding a food container in one hand and an eating utensil in the other. | High | Low |
| Working on a laptop | Using both hands, the driver was typing on a laptop located on his lap. | High | High |
| Watching video | The driver deeply engaged in watching a video playing from the in-vehicle touch screen. | Low | High |
| Category | Scenario | Description |
|---|---|---|
| Maneuver-based Intervention Scenarios |
| Ask the vehicle to pass the car ahead for some reason (e.g., blocks the front view). |
| Ask the vehicle to slow down then maintain the lower speed. | |
| Ask the vehicle to stop at a stated location. | |
| Ask the vehicle to reroute the navigation. | |
| Nonmaneuver-based Intervention Scenarios |
| Ask the vehicle to provide information about a point of interest. |
| Control the vehicle infotainment, e.g., play a YouTube video. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ataya, A.; Kim, W.; Elsharkawy, A.; Kim, S. How to Interact with a Fully Autonomous Vehicle: Naturalistic Ways for Drivers to Intervene in the Vehicle System While Performing Non-Driving Related Tasks. Sensors 2021, 21, 2206. https://doi.org/10.3390/s21062206
Ataya A, Kim W, Elsharkawy A, Kim S. How to Interact with a Fully Autonomous Vehicle: Naturalistic Ways for Drivers to Intervene in the Vehicle System While Performing Non-Driving Related Tasks. Sensors. 2021; 21(6):2206. https://doi.org/10.3390/s21062206
Chicago/Turabian StyleAtaya, Aya, Won Kim, Ahmed Elsharkawy, and SeungJun Kim. 2021. "How to Interact with a Fully Autonomous Vehicle: Naturalistic Ways for Drivers to Intervene in the Vehicle System While Performing Non-Driving Related Tasks" Sensors 21, no. 6: 2206. https://doi.org/10.3390/s21062206
APA StyleAtaya, A., Kim, W., Elsharkawy, A., & Kim, S. (2021). How to Interact with a Fully Autonomous Vehicle: Naturalistic Ways for Drivers to Intervene in the Vehicle System While Performing Non-Driving Related Tasks. Sensors, 21(6), 2206. https://doi.org/10.3390/s21062206