1. Introduction
In the human body, the brain is an enormous and complex organ that controls the whole nervous system, and it contains around 100-billion nerve cells [
1]. This essential organ is originated in the center of the nervous system. Therefore, any kind of abnormality that exists in the brain may put human health in danger. Among such abnormalities, brain tumors are the most severe ones. Brain tumors are uncontrolled and unnatural growth of cells in the brain that can be classified into two groups such as primary tumors and secondary tumors. The primary tumors present in the brain tissue, while the secondary tumors expand from other parts of the human body to the brain tissue through the bloodstream [
2]. Among the primary tumors, glioma and meningioma are two lethal types of brain tumors, and they may lead a patient to death if not diagnosed at an early stage [
3]. In fact, the most common brain tumor in humans is glioma [
4].
According to the World Health Organization (WHO), brain tumors can be classified into four grades [
1]. The grade 1 and grade 2 tumors describe lower-level tumors (e.g., meningioma), while grade 3 and grade 4 tumors consist of more severe ones (e.g., glioma). In clinical practice, the incidence rates of meningioma, pituitary, and glioma tumors are approximately 15%, 15%, and 45%, respectively.
There are different ways to treat brain tumors depends on the tumor location, size, and type. Presently, the most common treatment for brain tumors is surgery as it has no side effects on the brain [
5]. Different types of medical imaging technologies such as computed tomography (CT), positron emission tomography (PET), and magnetic resonance imaging (MRI) are available that are used to observe the internal parts of the human body conditions. Among all these imaging modalities, MRI is considered most preferable as it is the only non-invasive and non-ionizing modality that offers valuable information in 2D and 3D formats about brain tumor type, size, shape, and position [
6]. However, manually reviewing these images is time-consuming, hectic, and even prone to error due to the influx of patients [
7]. To address this problem, the development of an automatic computer-aided diagnosis (CAD) system is required to alleviate the workload of the classification and diagnosis of brain MRI and act as a tool for helping radiologists and doctors.
Several efforts have been made to develop a highly accurate and robust solution for the automatic classification of brain tumors. However, due to high inter and intra shape, texture, and contrast variations, it remains a challenging problem. The traditional machine learning (ML) techniques rely on handcrafted features, which restrains the robustness of the solution. Whereas the deep learning-based techniques automatically extract meaningful features which offer significantly better performance. However, deep learning-based techniques require a large amount of annotated data for training, and acquiring such data is a challenging task. To overcome these issues, in this study, we proposed a hybrid solution that exploits (1) various pre-trained deep convolutional neural networks (CNNs) as feature extractors to extract powerful and discriminative deep features from brain magnetic resonance (MR) images, and (2) various ML classifiers to identify the normal and abnormal brain MR images. Also, to investigate the benefits of combining features from different pre-trained CNN models, we designed the novel feature ensemble method for the MRI-based brain tumor classification task. We proposed the novel feature evaluation and selection mechanism where the deep features from 13 different pre-trained CNNs are evaluated using 9 different ML classifiers and selected based on our proposed feature selection criteria. In our proposed framework, we concatenated the selected top three deep features from three different CNNs to form a synthetic feature. The concatenation process integrates the information from different CNNs to create a more discriminative feature representation than using the feature extracted from a single CNN model since different CNN architectures can capture diverse information in brain MR images. An ensemble of deep features is then fed into several ML classifiers to predict the final output, whereas most of the previous works have employed traditional feature extraction techniques [
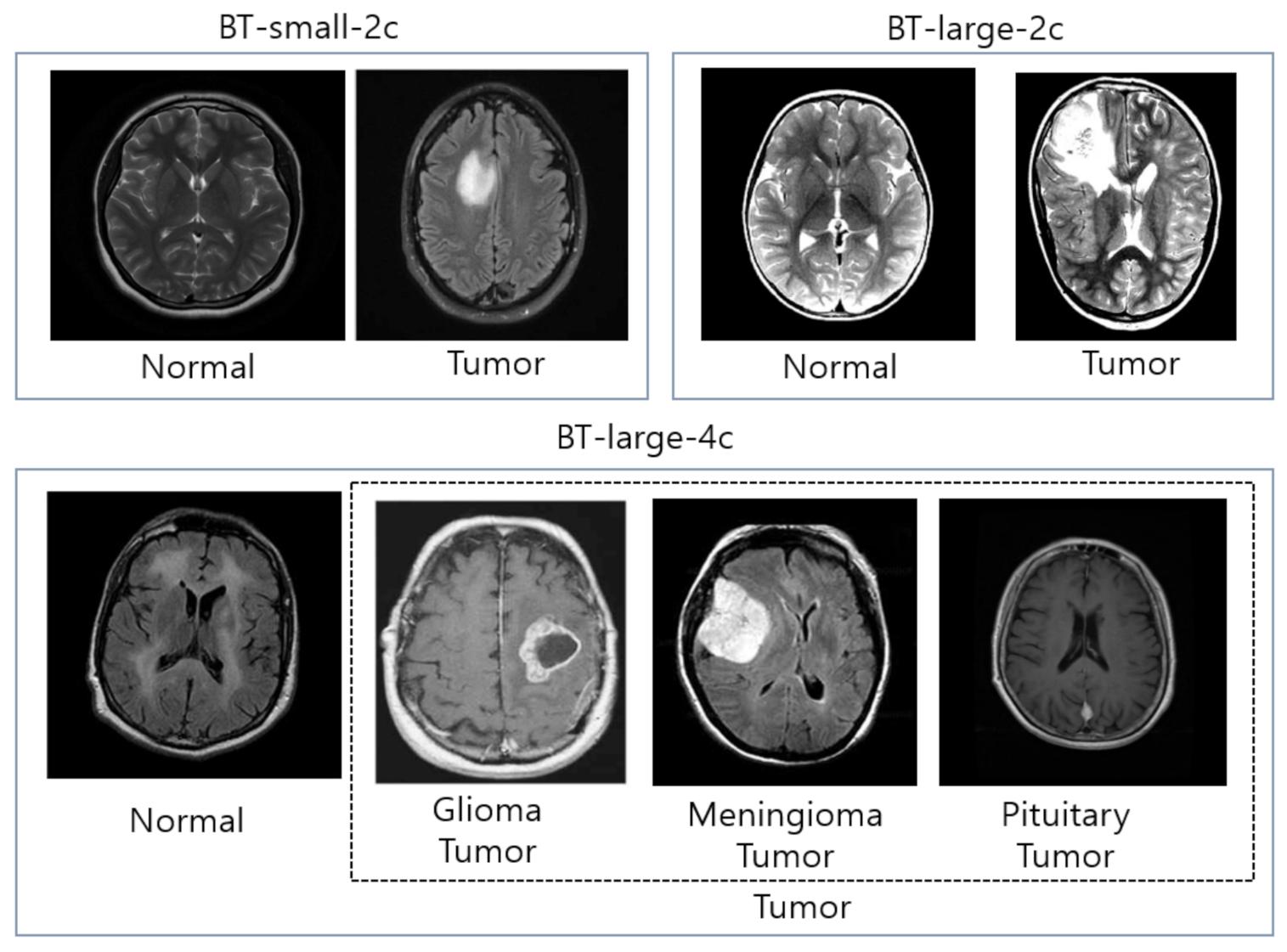
8]. In our experiment, we provided an extensive evaluation using 13 different pre-trained deep convolutional neural networks and 9 different ML classifiers on three different datasets: (1) BT-small-2c, the small dataset with 2 classes (normal/tumor), (2) BT-large-2c, the large dataset with 2 classes (normal/tumor), and (3) the large dataset with 4 classes (normal, glioma tumor, meningioma tumor, and pituitary tumor) for brain tumor classification. Our experiment results demonstrate that the ensemble of deep features can help improving performance significantly. In summary, our contributions are listed as follows:
We designed and implemented a fully automatic hybrid scheme for brain tumor classification, which uses both (1) the pre-trained CNN models to extract the deep features from brain MR images and (2) ML classifiers to classify brain tumor type effectively.
We proposed a novel method which consists of three steps: (1) extract deep features using pre-trained CNN models for meaningful information extraction and better generalization, (2) select the top three performing features using fined-tuned several ML models for our task, and (2) combine them to build the ensemble model to achieve state-of-the-art performance for brain tumor classification in brain MR images.
We conducted extensive experiments on 13 different pre-trained CNN models and 9 different ML classifiers to compare the effectiveness of each pre-trained CNN model and each ML classifier on three different brain MRI datasets: (1) BT-small-2c, the small dataset with 2 classes (normal/tumor), (2) BT-large-2c, the large dataset with 2 classes (normal/tumor), and (3) the large dataset with 4 classes (normal, glioma tumor, meningioma tumor, and pituitary tumor) for brain tumor classification.
The layout of this study is organized as follows: The related work is given in
Section 2. The proposed method is presented in
Section 3. The experimental settings and results are shown in
Section 4. The conclusion section is described in
Section 5.
2. Related Work
Numerous techniques have been proposed for automatic brain MRI classification based on traditional ML and deep learning methods as shown in
Table 1.
The traditional ML methods are comprised of several steps: pre-processing, feature extraction, feature reduction, and classification. In traditional ML methods, feature extraction is a core step as the classification accuracy relies on extracted features. There are two main types of feature extraction. The first type of feature extraction is low-level (global) features, for instance, texture features and intensity, first-order statistics (e.g., mean, standard deviation, and skewness), and second-order statistics such as gray-level co-occurrence matrix (GLCM), wavelet transform (WT), Gabor feature, and shape. For instance, Selvaraj et al. [
9] employed first-order and second-order statistics using least square support vector machine (SVM) and develop a binary classifier to classify the normal and abnormal brain MR images. John et al. [
10] used GLCM and discrete wavelet transformation-based methods for tumor identification and classification. The low-level features represent the image efficiently; however, the low-level features and their representation capacity are limited since most brain tumors have similar appearances such as texture, boundary, shape, and size. Ullah et al. [
8] extracted the approximation and detail coefficient of level-3 decomposition using DWT, reduced the coefficient by employing color moments (CM), and finally employed a feed-forward artificial neural network to identify the normal and abnormal brain MR images.
The second type of feature extraction is the high-level (local) features, such as fisher vector (FV), scale-invariant feature transformation (SIFT), and bag-of-words (BoW). Different researchers have employed BoW for medical image retrieval and classification. Such as the classification of breast tissue density in mammograms [
11], X-ray images retrieval and classification on pathology and organ levels [
12], and content-based retrieval of brain tumor [
13]. Cheng et al. [
14] employed FV to retrieve the brain tumor. The statistical features extracted from SIFT, FV, and BoW are high-level features formulated on a local scale that does not consider spatial information. Hence, it is noticeable that in the traditional ML method, there are two main problems in the feature extraction stage. First, it only focuses on either high-level or low-level features. Second, the traditional ML method depends on handcrafted features, which need strong prior information such as the location or position of the tumor in an image, and there are high chances of human errors. Therefore, it is essential to develop a method to combine both high-level and low-level features without using handcrafted features.
Most of the existing works in medical MR imaging refers to automatic segmentation of tumor region. Recently, Numerous researchers have proposed different techniques to detect and segment the tumor region in MR images [
15,
16,
17]. Once the tumor in MRI is segmented, these tumors need to be classified into different grades. In previous research studies, binary classifiers have been employed to identify the benign and malignant classes [
8,
18,
19]. For instance, Ullah et al. [
8] proposed a hybrid scheme for the classification of brain MR images into normal and abnormal using histogram equalization, Discrete wavelet transform, and feed-forward artificial neural network, respectively. Kharrat et al. [
18] categorize the brain tumor into normal and abnormal using a genetic algorithm and support vector machine. Besides, Papageorgiou et al. [
19] categorized the high-grade and low-grade gliomas based on fuzzy cognitive maps and attained 93.22% and 90.26% accuracy for high-grade and low-grade brain tumors, respectively.
Shree and Kumar [
20] divided the brain MRI into two classes: normal and abnormal. They used GLCM for feature extraction, while a probabilistic neural network (PNN) classifier has been employed to classify the brain MR image into normal and abnormal and obtained 95% accuracy. Arunachalam and Savarimuthu [
21] proposed a model to categorize the normal and abnormal brain tumor in brain MR images. Their proposed model comprised enhancement, transformation, feature extraction, and classification. First, they have enhanced the brain MR image using shift-invariant shearlet transform (SIST). Then, they extracted the features using Gabor, grey level co-occurrence matrix (GLCM), and discrete wavelet transform (DWT). Finally, these extracted features were then fed into feed-forward backpropagation neural network and obtained a high accuracy rate. Rajan and Sundar [
22] proposed a hybrid energy-efficient method for automatic tumor detection and segmentation. Their proposed method is comprised of seven long phases and reported 98% accuracy. The main drawback of their proposed model is high computation time due to the use of numerous techniques.
Since the last decade, deep learning methods have been widely used for brain MRI classification [
23,
24]. The deep learning method does not need handcrafted (manually) extracted features as it embedded the feature extraction and classification stage in self-learning. The deep learning method requires a dataset where sometimes a pre-processing operation needs to be done, and then salient features are determined in a self-learning manner [
25]. In MR imaging classification, a key challenge is to reduce the semantic gap between the high-level visual information perceived by the human evaluator and the low-level visual information captured by the MR imaging machine. To reduce the semantic gap, the convolutional neural networks (CNNs), one of the famous deep learning techniques for image data, can be used as a feature extractor to capture the relevant features for the classification task. Feature maps in the initial layers and higher layers of CNNs models extract low-level features and high-level content (domain) specific features, respectively. Feature maps in the earlier layer construct simple structural information, for instance, shape, textures, and edges, whereas higher layers combine these low-level features to construct (encode) efficient representation, which integrates global and local information.
Recently, different researchers have used CNNs for brain MRI classification and validated their proposed methodology on brain tumor classification datasets [
26,
27,
28]. Deepak and Ameer [
29] used a pre-trained GoogLeNet to extract features from brain MR images with deep CNN to classify three types of brain tumor and obtained 98% accuracy. Ahmet and Muhammad [
30] used different CNN models such as GoogLeNet, Inception V3, DenseNet-201, AlexNet, and ResNet-50 to classify the brain MR images and obtained reasonable accuracies. They modified pre-trained ResNet-50 CNN by removing its last 5 layers and added new 8 layers, and obtained 97.2% accuracy with this model, which is the highest accuracy among all pre-trained models. Khwaldeh et al. [
31] proposed a CNN model to classify the normality and abnormality of brain MR images as well as high-grade and low-grade glioma tumors. They have modified the AlexNet CNN model and used it as their network architecture, and they obtained 91% accuracy. Despite the valuable works being done in this area, developing a robust and practical method still requires more effort to classify brain MR images. Saxena et al. [
32] used Inception V3, ResNet-50, and VGG-16 models with transfer learning methods to classify brain tumor data. The ResNet-50 model obtained the highest accuracy rate with 95%. In studies [
33,
34] CNN architectures have been introduced to classify brain tumors. In these architectures, the convolution neural network extracts the features from brain MRI using convolution and pooling operations. The main purpose of these proposed models is to find the best deep learning model that accurately classifies the brain MR images. Francisco et al. [
35] presented a multi-pathway CNN architecture for automatic brain tumor segmentation such as glioma, meningioma, and pituitary tumor. They have evaluated their proposed model using a publicly available T1-weighted contrast-enhanced MRI dataset and obtained 97.3% accuracy. However, their training procedure is quite expensive. Raja et al., [
36] proposed a hybrid deep autoencoder (DAE) for brain tumor classification using the Bayesian fuzzy clustering (BFC) approach. Initially, they have used a non-local mean filter to remove the noise from the image. Then the BFC approach is employed for brain tumor segmentation. Furthermore, some robust features were extracted using scattering transform (ST), information-theoretic measures, and wavelet packet Tsallis entropy (WPTE). Eventually, a hybrid scheme of DAE is employed for brain tumor classification and achieved high accuracy. The main drawback of this approach is, it requires high computation time due to the complex proposed model.
In summary, as observed from the above research studies, the acquired accuracies using deep learning techniques for brain MRI classification are significantly high as compared to traditional ML techniques. However, the deep learning models require a massive amount of data for training in order to perform better than traditional ML techniques.
It is clearly seen from recently published studies that deep learning techniques have become one of the mainstream of expert and intelligent systems and medical image analysis. Furthermore, the techniques mentioned earlier have certain limitations which should be considered while working with brain tumor classification and segmentation. The major drawback of the previously proposed systems is that they only consider binary classification (normal and abnormal) MR image dataset and ignore the multi-class dataset [
37]. In the pre-screening stage of a patient, binary class classification is required for physicians and radiologists, where the physicians take further action based on binary class classification. Preethi and Aishwarya [
38] proposed a model to classify the brain tumor based on multiple stages. They combined the wavelet-based gray-level co-occurrence matrix and GLCM to produce the feature matrix. The extracted features were further reduced using the oppositional flower pollination algorithm (OFPA). Finally, the deep neural network is employed to classify the MR brain image based on the selected features and obtained 92% accuracy. Ural [
39] initially enhanced the brain MRI using different image processing techniques. Also, different segmentation process has been mixed for boosting the performance of the solution. Further, the PNN method is employed to detect and localize the tumor area in the brain. The computational time of their proposed method is quite low and also the acquired accuracy rate is quite reasonable.
3. Proposed Methods
In this section, the overall architecture of our proposed method is first described. After that, we describe the details of four key components in the following subsections.
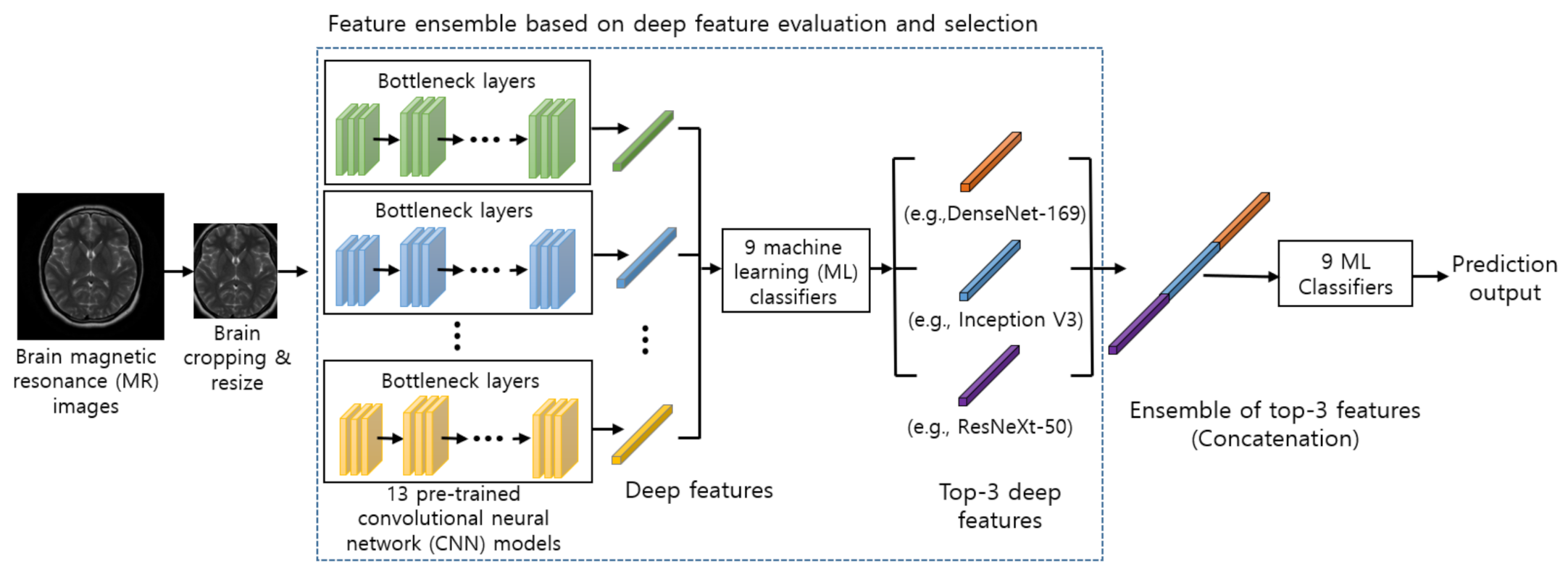
The architecture of our proposed method for brain tumor classification is illustrated in
Figure 1. First, input MR images are pre-processed (e.g., brain cropping, resize, and augmentation) before feeding into the model (
Section 3.1). Second, the pre-processed images are used as the input of pre-trained CNN models as feature extractors (
Section 3.2). The extracted features from pre-trained CNN models are evaluated by several ML classifiers. (
Section 3.3). The top three deep features are selected based on evaluation results from the classifiers (
Section 3.4). The top three deep features are concatenated in our ensemble module, and the concatenated deep features are further used as an input to ML classifiers to predict final output (
Section 3.5).
3.1. Image Pre-Processing
Almost every image in our brain MRI datasets contains undesired spaces and areas, leading to poor classification performance. Hence, it is necessary to crop the images to remove unwanted areas and use only useful information from the image. We use the cropping method in [
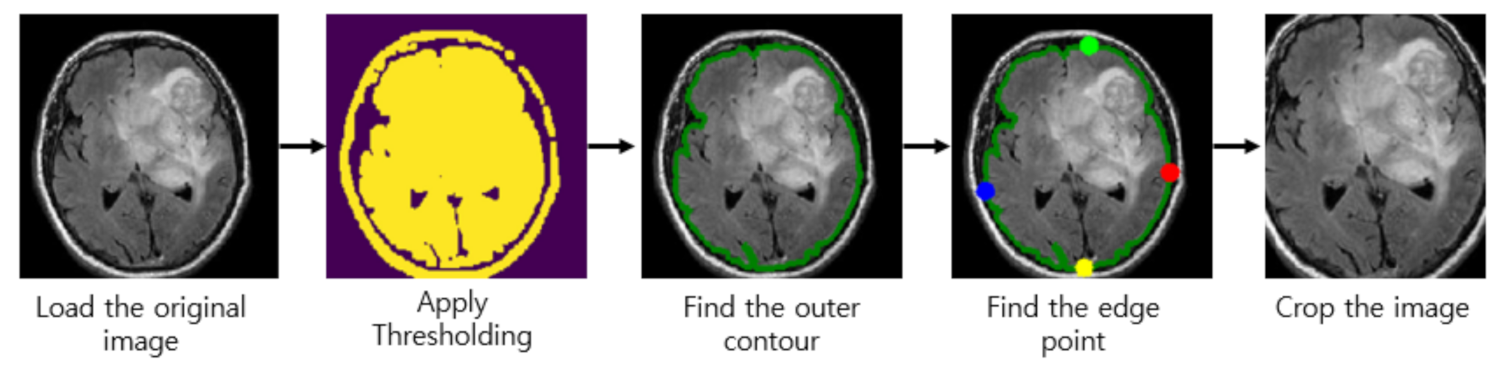
40] which uses extreme point calculation. The step to crop the MR images using extreme point calculation is shown in
Figure 2. First, we load the original MR images for pre-processing. After that, we apply thresholding to the MR images to convert them into binary images. Also, we perform the dilation and erosions operations to remove the noise of images. After that, we selected the largest contour of the threshold images and calculated the four extreme points (extreme top, extreme bottom, extreme right, and extreme left) of the images. Lastly, we crop the image using the information of contour and extreme points. The cropped tumor images are resized by bicubic interpolation. The specific reason to choose the bicubic interpolation is that it can create a smoother curve than other interpolation methods such as bilinear interpolation and is a better choice for MR images since there is a large amount of noise along the edges.
Also, we used image augmentation since the size of our MRI dataset is not very large. Image augmentation is the technique that creates an artificial dataset by modifying the original dataset. It is known as the process of creating multiple copies of the original image with different scales, orientation, location, brightness, and so on. It is reported that the classification accuracy of the model can be improved by augmenting the existing data rather than collecting new data.
In our image augmentation step, we used 2 augmentation strategies (rotation and horizontal flipping) to generate new training sets. The rotation operation used for data augmentation is done by randomly rotating the input by 90 degrees zero or more times. Also, we applied horizontal flipping to each of the rotated images.
Since the MR images in our dataset are of different width, height, and sizes, it is recommended to resize them to equal width and height to get optimum results. In this work, we resize the MR images to the size of either 224 × 224 (or 299 × 299) pixels since input image dimensions of pre-trained CNN models are 224 × 224 pixels except for the Inception V3, which requires the input images with size 299 × 299.
3.2. Deep Feature Extraction Using Pre-Trained CNN Models
3.2.1. Convolutional Neural Network
CNN is a class of deep neural networks that uses the convolutional layers for filtering inputs for useful information. The convolutional layers of CNN apply the convolutional filters to the input for computing the output of neurons that are connected to local regions in the input. It helps in extracting the spatial and temporal features in an image. A weight-sharing method is used in the convolutional layers of CNN to reduce the total number of parameters [
41,
42].
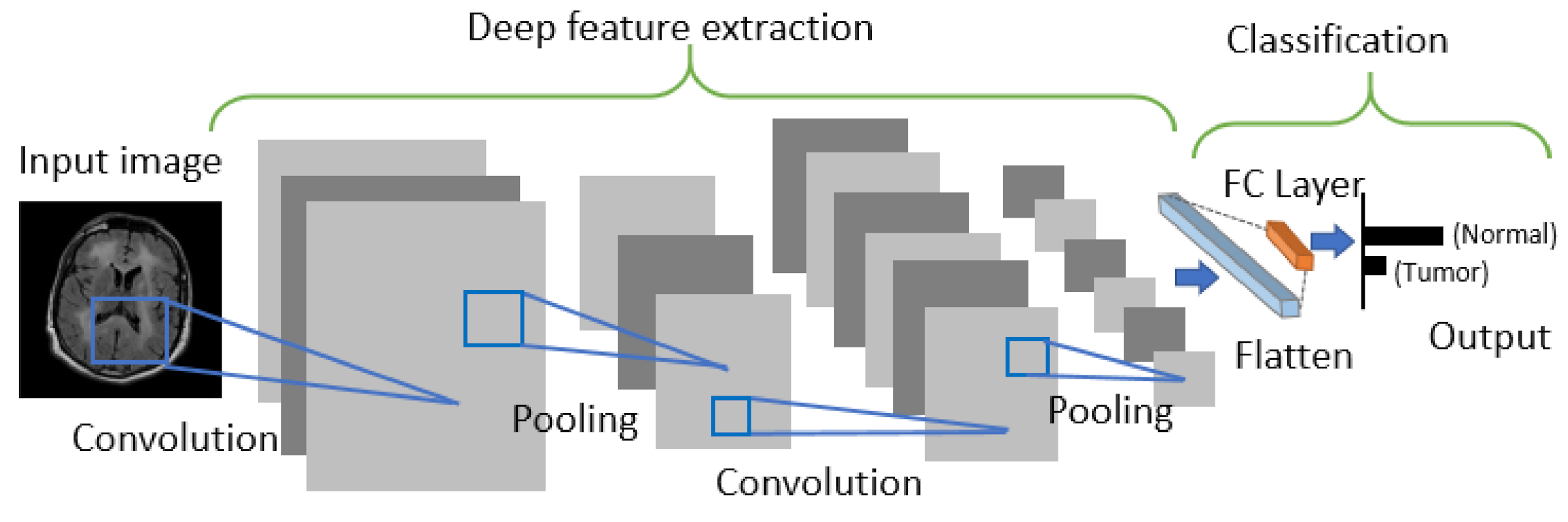
CNN is generally comprised of three building blocks: (1) a convolutional layer to learn the spatial and temporal features, (2) a subsampling (max-pooling) layer to reduce or downsample the dimensionality of an input image, and (3) a fully connected (FC) layer for classifying the input image into various classes. The architecture of CNN is shown in
Figure 3.
3.2.2. Transfer Learning
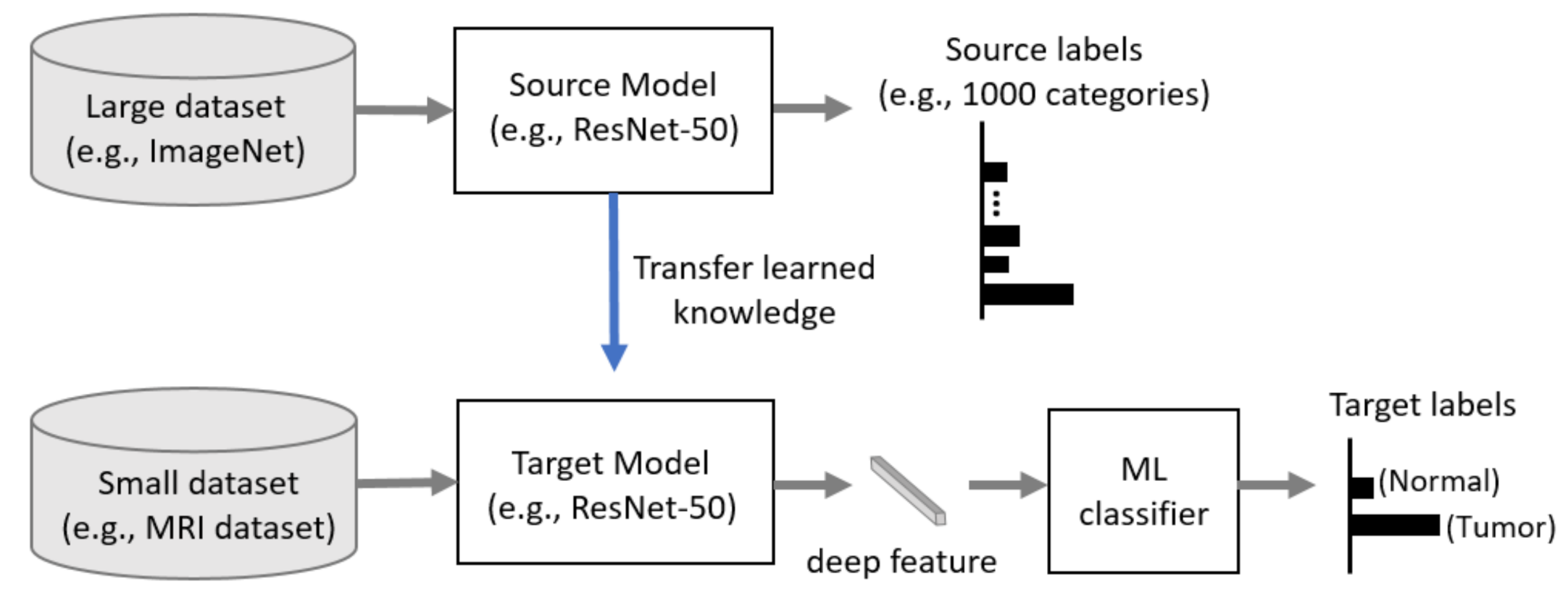
Generally, CNN has better performance in a larger dataset than a smaller one. Transfer learning can be used when it is not feasible to create a large training dataset. The concept of transfer learning can be depicted in
Figure 4, where the model pre-trained on large benchmark datasets (e.g., ImageNet [
43]) can be used as a feature extractor for the different task with a relatively smaller dataset such as an MRI dataset. In recent years, transfer learning technique has been successfully applied in various domains, such as medical image classification and segmentation, and X-ray baggage security screening [
44,
45,
46,
47]. This reduces the long training time that is normally required for training deep learning models from scratch and also removes the requirement of having a large dataset for the training model [
48,
49].
3.2.3. Deep Feature Extraction
In this study, we use a CNN-based model as a deep learning-based feature extractor since it can capture the important features without any human supervision. Also, we use a transfer learning-based approach to build our feature extractor since our MRI dataset is not very large and training and optimizing deep CNN such as DenseNet-121 from scratch is often not feasible. Hence, we use the fixed weights of each CNN model pre-trained on a large ImageNet dataset to extract the deep features of brain MR images.
The pre-trained CNN models used in our study are ResNet [
50], DenseNet [
51], VGG [
52], AlexNet [
53], Inception V3 [
54], ResNeXt [
55], ShuffleNet V2 [
56], MobileNet V2 [
57], and MnasNet [
58]. The extracted deep features are then fed into the ML classifiers, including neural networks with a FC layer as a traditional deep learning approach using CNN as shown in
Figure 3 to predict the output.
3.3. Machine Learning Classifiers for Brain Tumor Classification
The extracted deep features from pre-trained CNN models are used as an input of several ML classifiers, including neural networks with an FC layer, Gaussian Naïve Bayes (Gaussian NB), Adaptive Boosting (AdaBoost), K-Nearest Neighbors (k-NN), Random forest (RF), SVM with three different kernels: linear, sigmoid, and radial basis function (RBF), Extreme Learning Machine (ELM). We implemented these ML classifiers using the scikit-learn ML library [
59]. These ML classifiers and their hyper-parameter settings used in our experiments for brain tumor classification are discussed in the following subsections.
3.3.1. Fully Connected Layer
In neural networks with an FC layer, which is the traditional deep learning approach, the loss function is defined to calculate the loss, which is a prediction error of the neural network. The loss is used to calculate the gradients to update the weights of the neural network as a training step. In our training step of the FC classifier, we use the cross-entropy loss function, which is the most commonly used loss function for CNN and other neural networks. It calculates the loss between the soft target estimated by the softmax function and the ground-truth label to learn our model parameters as follows:
where
M is the total number of class, for instance, M is set to 2 when the classifier is trained on the two MRI datasets, BT-small-2c and BT-large-2c, which contain two classes (normal and tumor) of MR images, and M is set to 4 when the classifier is trained on the MRI dataset, BT-large-4c, which contains four classes (normal, glioma tumor, meningioma tumor, and pituitary tumor) of MR images (See
Section 4.1 for the details of these datasets),
y is a one-hot encoded vector representing the ground-truth label of the training set as 1 and all other elements as 0, and
is the logit which is the output of the last layer for the
i-th class of the model.
In this work, we update the weight of the layers via Adaptive Moment Estimation (Adam), the optimizer that calculates the adaptive learning rates of every parameter. The learning rate is set to 0.001. We run each of the methods for 100 epochs. We collect the highest average accuracy for our test dataset for each run.
3.3.2. Gaussian Naïve Bayes
Naïve Bayes classifier is the ML classifier with the assumption of conditional independence between the attributes given the class. In this work, we use Gaussian NB classifier as one of our ML classifiers for brain tumor classification. In Gaussian NB classifier, the conditional probability
P(y|X) is calculated as a product of the individual conditional probabilities using the naïve independence assumption as follows:
where
X is given data instance (extracted deep feature from brain MR image) which is represented by its feature vector
,
y is a class target (type of brain tumor) with two classes (normal and tumor) for two MRI datasets, BT-small-2c and BT-large-2c, or four classes (normal, glioma tumor, meningioma tumor, and pituitary tumor) for BT-large-4c dataset. Since
is constant, the given data instance can be classified as follows:
where
is calculated assuming that the likelihood of features to be Gaussian as follows:
where the parameters
and
are estimated using maximum likelihood.
In this work, the smoothing variable representing the portion of the largest variance of all features that are added to variances for calculation stability is set to , the default value of the scikit-learn ML library.
3.3.3. AdaBoost
AdaBoost, proposed by Freund and Schapire [
60], is an ensemble learning algorithm that combines multiple classifiers to improve performance. AdaBoost classifier builds a well-performing strong classifier by combining multiple weak classifiers using the iterative ensemble method. The underlying idea of Adaboost is to set the weights of classifiers and train the data sample in each boosting iteration to accurately predict a class target (a type of brain tumor) of a given data instance (extracted deep feature from brain MR image) with two classes (normal and tumor) for two MRI datasets, BT-small-2c and BT-large-2c, or four classes (normal, glioma tumor, meningioma tumor, and pituitary tumor) for BT-large-4c dataset. Any ML classifier that accepts the weights on the training set can be used as a base classifier.
In this work, we adopt the decision tree classifier as our base classifier since it is a commonly used base classifier for AdaBoost. Also, the number of the estimator is set to 150.
3.3.4. K-Nearest Neighbors
k-NN is one of the simplest classification techniques. It performs predictions directly from the training set that is stored in the memory. For instance, to classify a new data instance (a deep feature from brain MR image), k-NN chooses the set of k objects from the training instances that are closest to the new data instance by calculating the distance and assigns the label with two classes (normal or tumor) or four classes (normal, glioma, meningioma, and pituitary tumor) and does the selection based on the majority vote of its k neighbors to the new data instance.
Manhattan distance and Euclidean distance are the most commonly used to measure the closeness of the new data instance with the training data instances. In this work, we used the Euclidean distance measure for the k-NN algorithm. Euclidean distance
d between data point
x and data point
y are calculated as follows:
The brief summary of k-NN algorithm is illustrated below:
First select a suitable distance metric.
Store all the training data set
P in pairs in the training phase as follows:
where in the training dataset,
is a training pattern,
n is the amount of training patterns and
is its corresponding class.
In the testing phase, compute the distances between the new features vector and the stored (training data) features, and classify the new class example by a majority vote of its k neighbors.
The correct classification given in the test phase is used to evaluate the accuracy of the algorithm. If the result is not satisfactory, the k value can be adjusted until a reasonable level of accuracy is obtained. It is noticeable here that we set the number of neighbors from 1 to 4 and selected the one with the highest accuracy.
3.3.5. Random Forest
RF, proposed by Breiman [
61], is an ensemble learning algorithm that builds multiple decision trees using the bagging method to classify new data instance (a deep feature of brain MR image) to a class target (a type of brain tumor) with two classes (normal and tumor) for two MRI datasets, BT-small-2c and BT-large-2c, or four classes (normal, glioma tumor, meningioma tumor, and pituitary tumor) for BT-large-4c dataset. RF selects random
n attributes or features to find the optimal split point using the Gini index as a cost function while creating the decision trees. This random selection of the attributes or features can reduce the correlation among the trees and have lower ensemble error rates. The new observation is fed into all classification trees of the RF for predicting a class target (a type of brain tumor) of the new incoming data instance. RF counts the numbers of predictions for each class and selects the class with the largest number of votes as the class label for the new data instance.
In this work, the number of features to consider when looking for the best split is set to the square root of the total number of features. Also, we set the number of trees from 1 to 150 and selected the one with the highest accuracy.
3.3.6. Support Vector Machine
SVM, proposed by Vapnik [
62], is one of the most powerful classification algorithms. SVM uses the kernel function,
, to transform the original data space into an another space with a higher dimension. The hyperplane function for separating the data can be defined as follows:
where
is support vector data (deep features from brain MR image),
is Lagrange multiplier, and
represent a target class of these three datasets employed in this paper, such that the two datasets are binary (normal and abnormal) class datasets, while the third dataset has four different classes (normal, glioma, meningioma, and pituitary tumor) with
.
In this work, we used the most commonly used kernel functions at the SVM algorithm: (1) linear kernel, (2) sigmoid kernel, and (3) RBF kernel.
Table 2 shows the details of three kernels. Also, SVM has two key hyper-parameters, C and Gamma. C is the hyper-parameter for the soft margin cost function that controls the influence of each support vector. Gamma is the hyper-parameter that decides how much curvature we want in a decision boundary. We set the gamma and C values to [0.00001, 0.0001, 0.001, 0.01] and [0.1, 1, 10, 100, 1000, 10000], respectively, and selected the combination of gamma and C values with the highest accuracy.
3.3.7. Extreme Learning Machine (ELM)
Extreme Learning Machine (ELM) is a simple learning algorithm for single-hidden layer feed-forward neural networks (SLFNs). ELM was initially proposed by Huang et al. [
63] to overcome the limitations of traditional SLFNs learning algorithms, such as poor generalization effectiveness, irrelevant parameter tuning, and slow learning speed. ELM has shown a considerable ability for regression and classification tasks with good generalization performance.
In ELM, the output of a SLFN with
hidden nodes given
N distinct training samples, can be represented as follows:
where
is the output vector of the SLFN, which represents the probability of the input sample
(deep features from brain MR image) belonging to a class target (type of brain tumor) with two classes (normal and tumor) for two MRI datasets, BT-small-2c and BT-large-2c, or four classes (normal, glioma tumor, meningioma tumor, and pituitary tumor) for BT-large-4c dataset,
and
are learning parameters generated randomly of the
j-th hidden node, respectively,
is the link connecting the
j-th hidden node and the output nodes, and
is the activation function of ELM.
The ELM learning algorithm can be explained in 3 steps. First, the parameters (weights and biases) of all neurons are randomly initialized. Second, the hidden layer output matrix of the neural network
H is calculated. Third, the output weight,
is calculated as follows:
where
is the Moore-Penrose generalized inverse of matrix H (the hidden layer output matrix), which can be obtained by minimum-norm least-squares solution, and
T is the target matrix corresponding to
H.
In this work, the number of the hidden layer is set to [5000, 6000, 7000, 8000, 9000, 10,000], and select the one with the highest accuracy.
3.3.8. Discussion
Several efforts have been made to develop a highly accurate and robust solution for MRI-based brain tumor classification using various ML classifiers: neural network classifier [
8,
21,
64], Naïve Bayes classifier [
65], AdaBoost classifier [
66], k-NN classifier [
64], RF classifier [
64,
67], SVM classifier [
18,
22], and ELM classifier [
68]. However, there have been no studies done on evaluating the effectiveness of ML classifiers for the MRI-based brain tumor classification task. Hence, in our study, we use 9 well-known different ML classifiers to examine which ML classifier performs well for the MRI-based brain tumor classification task.
Since the performance of ML classifiers are highly dependent on input feature map, designing a method to produce a discriminative and informative feature from brain MR images plays a key role to successfully build the model for MRI-based brain tumor classification. In recent years, several studies proposed deep-learning-based feature extraction methods for MRI-based brain tumor classification using pre-trained deep CNN models: ResNet-50 [
69,
70], ResNet-101 [
71], DenseNet-121 [
70,
72], VGG-16 [
69,
70], VGG-19 [
70,
73], AlexNet [
74], Inception V1 (GoogLeNet) [
29], Inception V3 [
69,
75], and MobileNet V2 [
76]. However, no study has been carried out to evaluate the effectiveness of several pre-trained deep CNN models as a feature extractor for MRI-based brain tumor classification task. Hence, we use 13 different pre-trained deep CNN models to examine which pre-trained CNN models are useful as a feature extractor for MRI-based brain tumor classification task.
3.4. Deep Feature Evaluation and Selection
We evaluate each deep feature extracted from 13 different pre-trained CNNs using 9 different ML classifiers (FC, Gaussian NB, AdaBoost, k-NN, RF, SVM-linear, SVM-sigmoid, SVM-RBF, and ELM) described in
Section 3.3 and choose the top three deep features based on the average accuracy of 9 different ML classifiers for each of our 3 different MRI datasets. In case the accuracy of two or more deep features is the same, we choose the one with the lowest standard deviation. Also, if there are more than 2 deep features extracted from two homogeneous pre-trained models (e.g., DenseNet-121 and DenseNet-169) among the top three features, we exclude the one with lower accuracy and choose the next best deep feature. The reason for doing this is that the deep features extracted from two homogeneous models share similar feature spaces. Hence, the ensemble of these features has redundant feature space and a lack of diversity. The top three deep features are fed into our ensemble module described in the following sub-section.
3.5. Ensemble of Deep Features
Ensemble learning aims at improving the performance and prevents the risk of using a single feature extracted from one model with a poor performance by combining multiple features from several different models into one predictive feature. Ensemble learning can be divided into feature ensemble and classifier ensemble depending on integration level. Feature ensemble involves integrating feature sets that are further fed to the classifier for final output, while classifier ensemble involves integrating output sets from classifiers where voting methods determine the final output. Since the feature set contains richer information about the MR images than the output set of each classifier, integration at this level is expected to provide better classification results. Hence, in this work, we use feature ensemble as our ensemble learning.
In our ensemble module, we concatenate the top three deep features from three different pre-trained CNNs as one sequence. For instance, in
Figure 1, the top three deep features are DenseNet-169, Inception V3, and ResNeXt-50, and these features are concatenated into one sequence as our feature-level ensemble step. The concatenated deep feature is further fed to ML classifiers for predicting the final output. Also, we concatenate all the possible combinations of two features from the top three features, which is further fed to ML classifiers to compare with the model using the ensemble of the top three features in our experiments.
5. Conclusions
In summary, we presented a brain tumor classification method using the ensemble of deep features from pre-trained deep convolutional neural networks with ML classifiers. In our proposed framework, we use several pre-trained deep convolutional neural networks to extract deep features from brain MR images. The extracted deep features are then evaluated by several ML classifiers. The top three deep features which perform well on several ML classifiers are selected and concatenated as an ensemble of deep feature which is then fed into several ML classifiers to predict the final output. In our experiment, we provided an extensive evaluation using 13 different pre-trained deep convolutional neural networks and nine different ML classifiers on three different datasets (BT-small-2c, BT-large-2c, and BT-large-4c) for brain tumor classification. Our experiment results indicate that from our architecture, (1) DenseNet-169 deep feature alone is a good choice in case the size of the MRI dataset is very small and the number of classes is 2 (normal, tumor), (2) the ensemble of DenseNet-169, Inception V3, and ResNeXt-50 deep features is a good choice in case the size of MRI dataset is large and the number of classes is 2 (normal, tumor) and (3) the ensemble of DenseNet-169, ShuffleNet V2, and MnasNet deep features is a good choice in case the size of MRI dataset is large and there are four classes (normal, glioma tumor, meningioma tumor, and pituitary tumor). Also, in most cases, SVM with RBF kernel outperforms other ML classifiers for the MRI-based brain tumor classification task. In summary, our proposed novel feature ensemble method helps to overcome the limitations of a single CNN model and produces superior and robust performance, especially for large datasets. These results indicated that our proposed method using an ensemble of deep features and ML classifiers is suitable for the classification of brain tumors. Although the performance of our proposed method is promising, further research needs to be done to reduce the size of the model to deploy on a real-time medical diagnosis system using knowledge distillation approaches.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}