
Edge-Sensitive Left Ventricle Segmentation Using Deep Reinforcement Learning

 ,
,  , , , , and
, , , , and
Abstract
:1. Introduction
2. Related Works
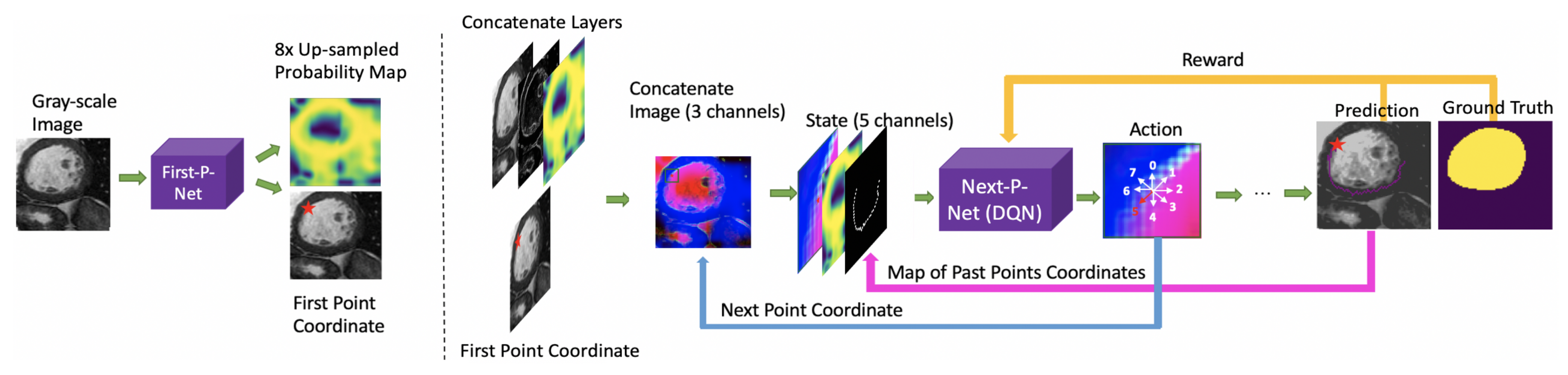
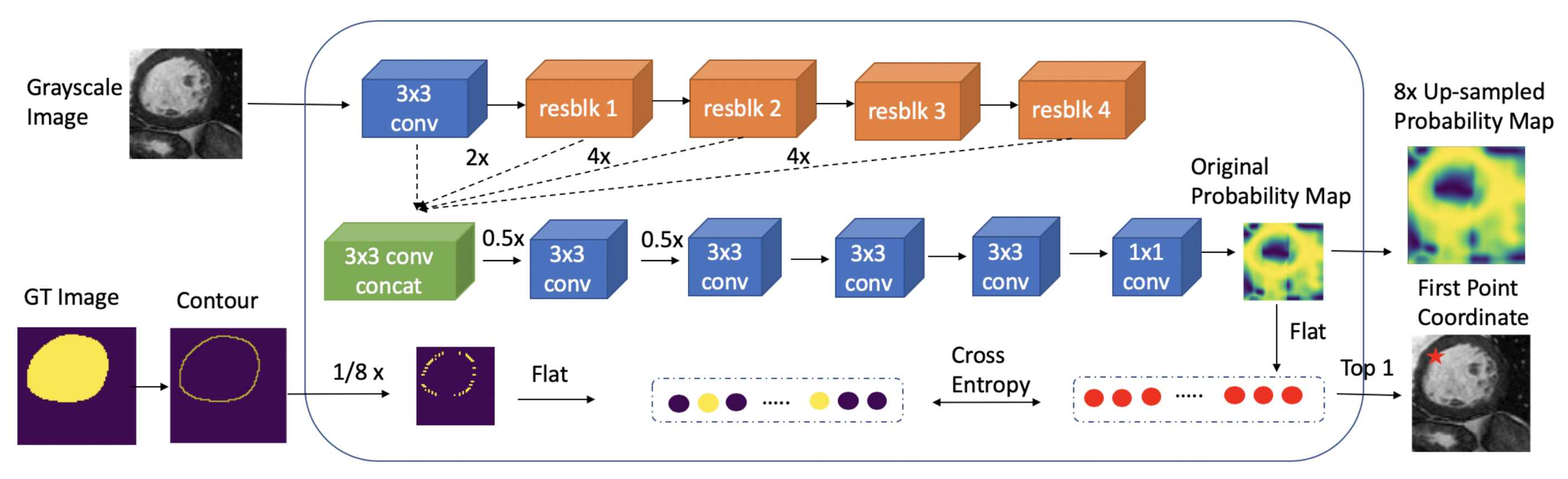
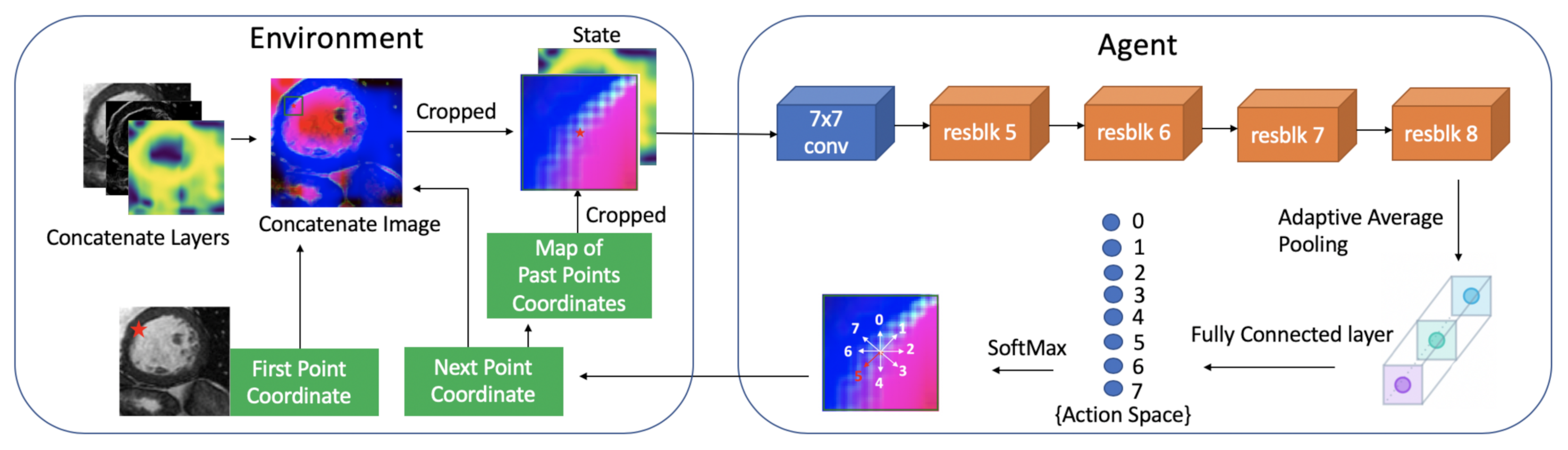
3. Methodology
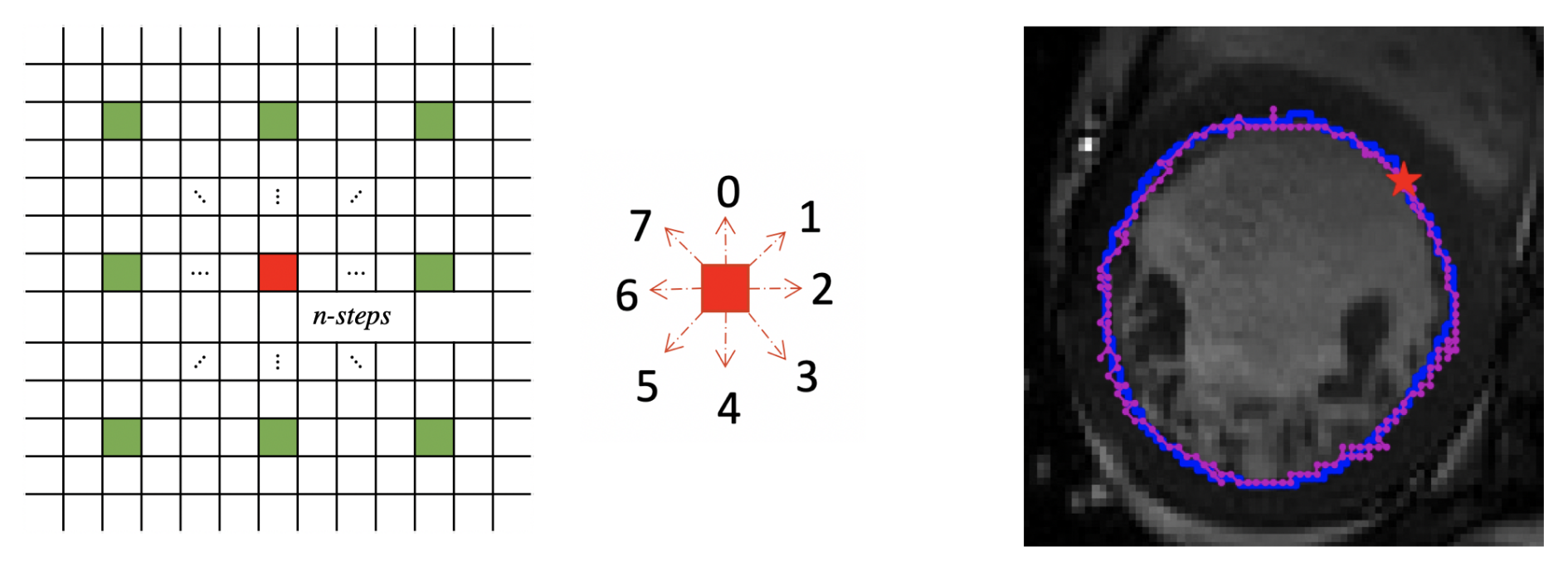
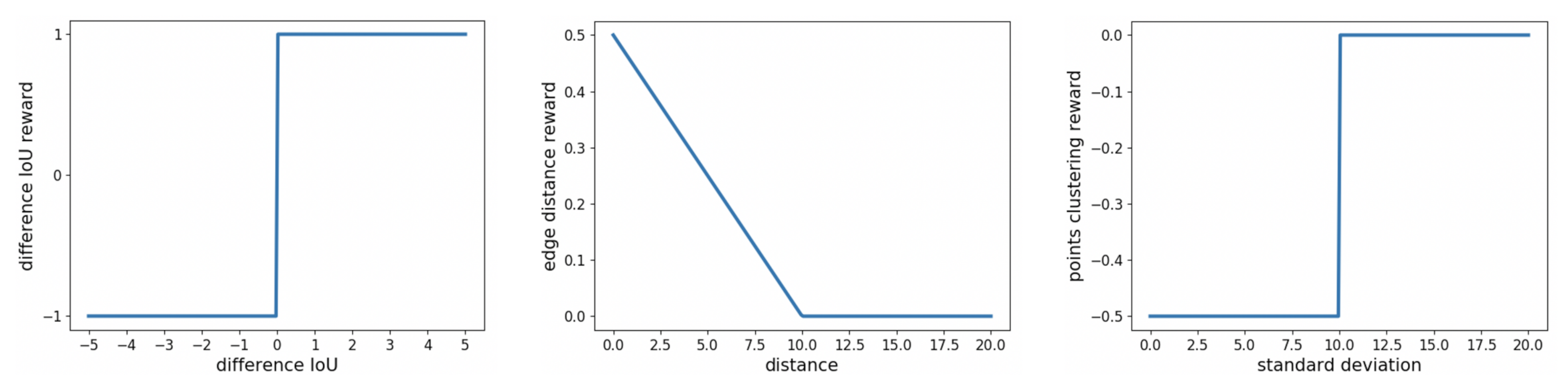
3.1. Markov Decision Process (MDP)
3.2. Double Deep Q-Network (Double DQN)
3.3. Model Architecture
4. Experiments
4.1. Datasets
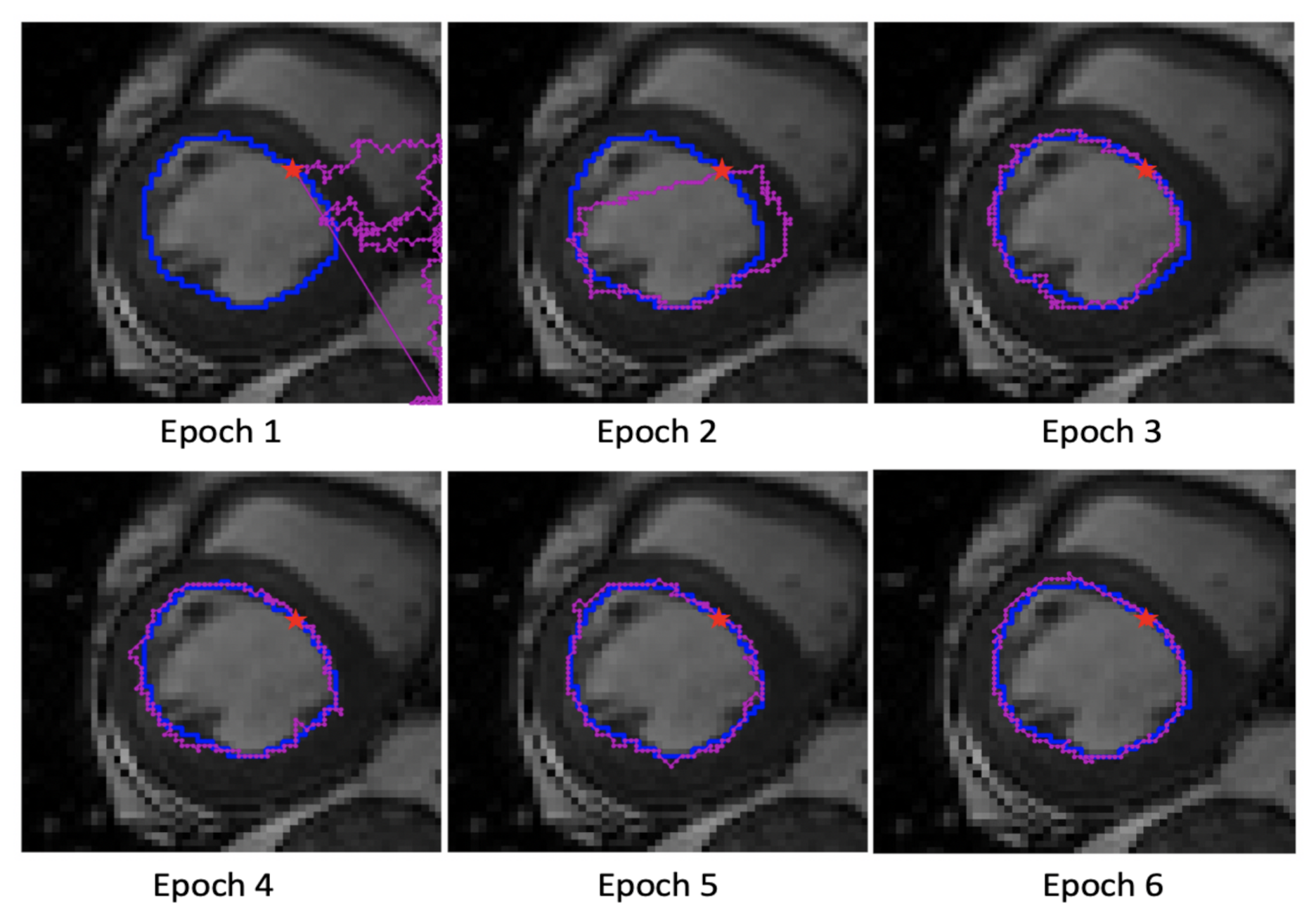
4.2. Training
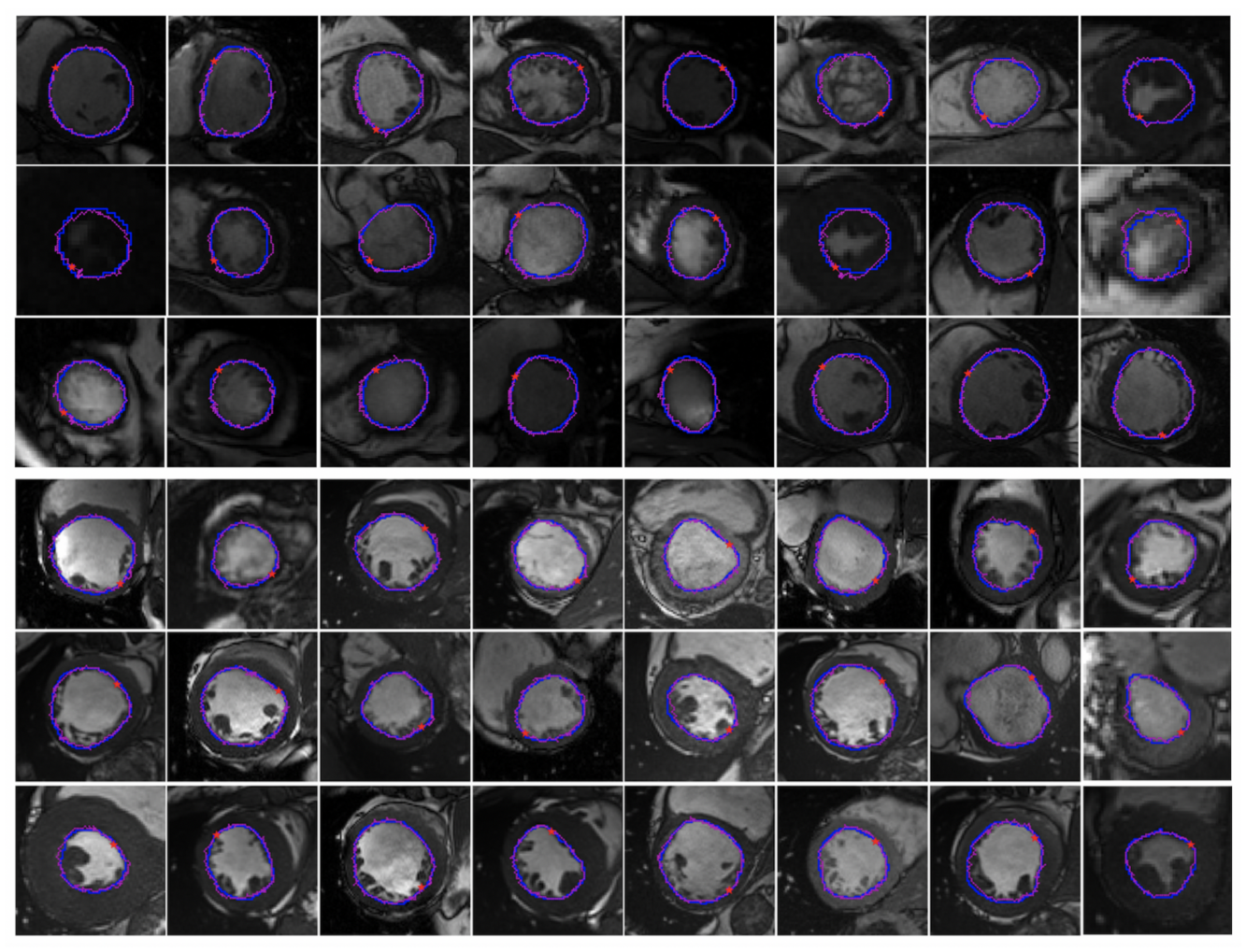
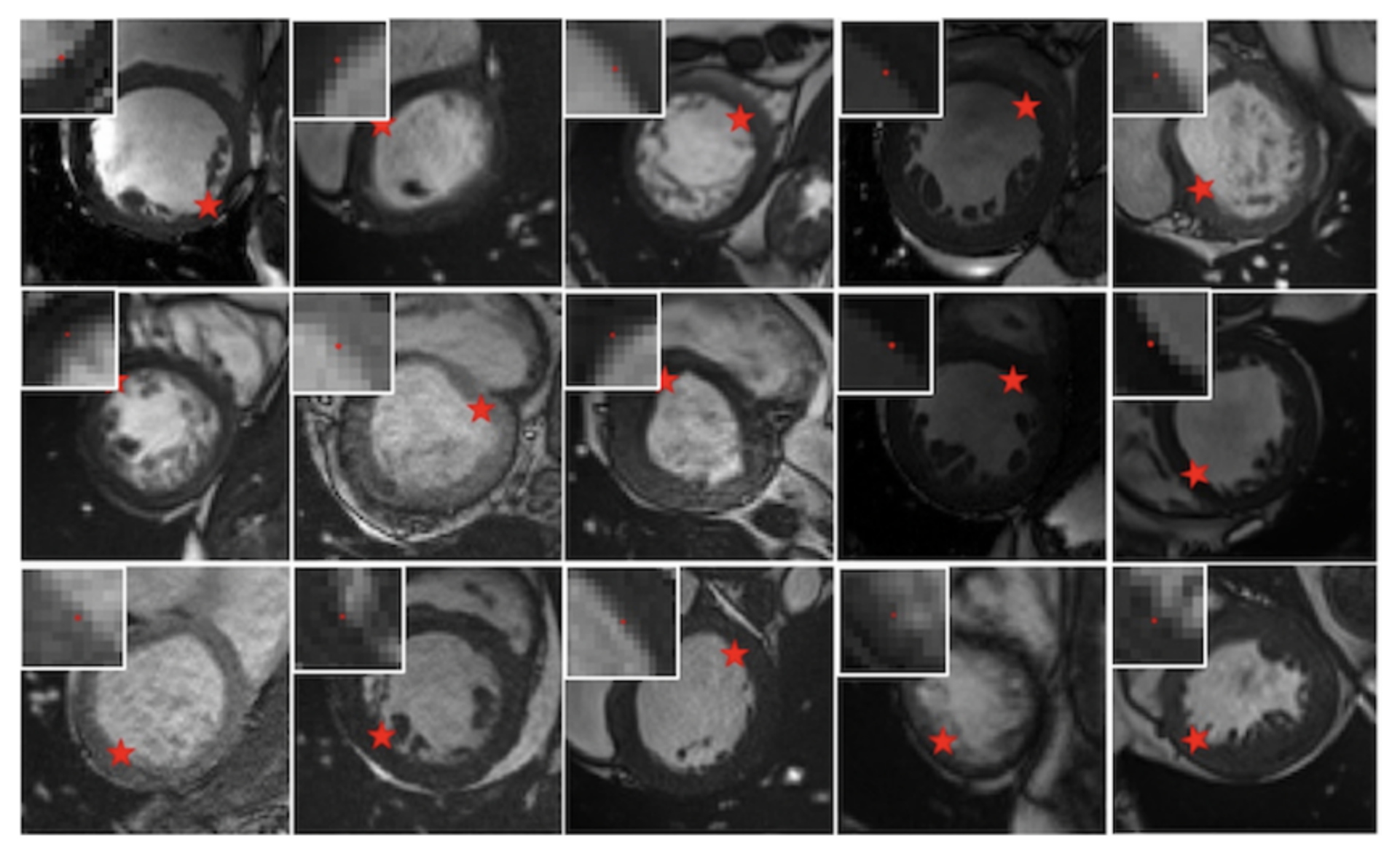
4.3. Performance
4.4. Ablation Study
4.5. Comparison with Other Methods
4.6. Performance on Small Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rundo, L.; Militello, C.; Vitabile, S.; Casarino, C.; Russo, G.; Midiri, M.; Gilardi, M.C. Combining split-and-merge and multi-seed region growing algorithms for uterine fibroid segmentation in MRgFUS treatments. Med. Biol. Eng. Comput. 2016, 54, 1071–1084. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA; London, UK, 2018. [Google Scholar]
- Li, Y. Deep Reinforcement Learning. Available online: https://arxiv.org/abs/1810.06339 (accessed on 15 October 2018).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Hasselt, H.V.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.V.; Lanctot, M.; Freitas, N.D. Dueling Network Architectures for Deep Reinforcement Learning. Available online: https://arxiv.org/abs/1511.06581 (accessed on 5 April 2016).
- Hausknecht, M.; Stone, P. Deep Recurrent q-Learning for Partially Observable Mdps. Available online: https://arxiv.org/abs/1507.06527 (accessed on 11 January 2017).
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. Available online: https://arxiv.org/abs/1511.05952 (accessed on 25 February 2016).
- Caicedo, J.C.; Lazebnik, S. Active object localization with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2488–2496. [Google Scholar]
- Bellver, M.; GiroiNieto, X.; Marques, F.; Torres, J. Hierarchical Object Detection with Deep Reinforcement Learning. Available online: https://arxiv.org/abs/1611.03718 (accessed on 25 November 2016).
- Codari, M.; Pepe, A.; Mistelbauer, G.; Mastrodicasa, D.; Walters, S.; Willemink, M.J.; Fleischmann, D. Deep Reinforcement Learning for Localization of the Aortic Annulus in Patients with Aortic Dissection. In Proceedings of the International Workshop on Thoracic Image Analysis, Lima, Peru, 8 October 2020; pp. 94–105. [Google Scholar]
- Ren, L.; Lu, J.; Wang, Z.; Tian, Q.; Zhou, J. Collaborative deep reinforcement learning for multi-object tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 586–602. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Pero, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 19, 70–76. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. Available online: https://arxiv.org/abs/2001.05566 (accessed on 15 November 2020).
- Chen, C.; Qin, C.; Qiu, H.; Tarroni, G.; Duan, J.; Bai, W.; Rueckert, D. Deep learning for cardiac image segmentation: A review. Front. Cardiovasc. Med. 2020, 7, 25. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Ciompi, F.; Wolterink, J.M.; de Vos, B.D.; Leiner, T.; Teuwen, J.; Išgum, I. State-of-the-art deep learning in cardiovascular image analysis. JACC Cardiovasc. Imaging 2019, 12, 1549–1565. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Xie, L.; Song, Y.; Chen, Q. Automatic left ventricle segmentation in short-axis MRI using deep convolutional neural networks and central-line guided level set approach. Comput. Biol. Med. 2020, 122, 103877. [Google Scholar] [CrossRef] [PubMed]
- Kallenberg, M.; Petersen, K.; Nielsen, M.; Ng, A.Y.; Diao, P.; Igel, C.; Vachon, C.M.; Holland, K.; Winkel, R.R.; Karssemeijer, N.; et al. Unsupervised deep learning applied to breast density segmentation and mammographic risk scoring. IEEE Trans. Med. Imaging 2016, 35, 1322–1331. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive medical image segmentation using deep learning with image-specific fine tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Abdeltawab, H.; Khalifa, F.; Taher, F.; Alghamdi, N.S.; Ghazal, M.; Beache, G.; Mohamede, T.; Keyntona, R.; El-Baz, A. A deep learning-based approach for automatic segmentation and quantification of the left ventricle from cardiac cine MR images. Comput. Med. Imaging Graph. 2020, 81, 101717. [Google Scholar] [CrossRef]
- Liu, L.; Cheng, J.; Quan, Q.; Wu, F.X.; Wang, Y.P.; Wang, J. A survey on U-shaped networks in medical image segmentations. Neurocomputing 2020, 409, 244–258. [Google Scholar] [CrossRef]
- Rundo, L.; Han, C.; Nagano, Y.; Zhang, J.; Hataya, R.; Militello, C.; Tangherloni, A.; Nobile, M.S.; Ferretti, C.; Besozzi, D.; et al. USE-Net: Incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets. Neurocomputing 2019, 365, 31–43. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Galea, R.R.; Diosan, L.; Andreica, A.; Popa, L.; Manole, S.; Bálint, Z. Region-of-Interest-Based Cardiac Image Segmentation with Deep Learning. Appl. Sci. 2021, 11, 1965. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Militello, C.; Rundo, L.; Toia, P.; Conti, V.; Russo, G.; Filorizzo, C.; Ludovico, L.G.; Massimo, M.; Vitabile, S. A semi-automatic approach for epicardial adipose tissue segmentation and quantification on cardiac CT scans. Comput. Biol. Med. 2019, 114, 103424. [Google Scholar] [CrossRef] [PubMed]
- Commandeur, F.; Goeller, M.; Razipour, A.; Cadet, S.; Hell, M.M.; Kwiecinski, J.; Chang, H.; Marwan, M.; Achenbach, S.; Berman, B.S.; et al. Fully automated CT quantification of epicardial adipose tissue by deep learning: A multicenter study. Radiol. Artif. Intell. 2019, 1, e190045. [Google Scholar] [CrossRef]
- Moreno, R.A.; Rebelo, D.S.M.F.; Carvalho, T.; Assuncao, A.N.; Dantas, R.N.; Val, R.D.; Marin, A.S.; Bordignom, A.; Nomura, C.H.; Gutierrez, M.A. A combined deep-learning approach to fully automatic left ventricle segmentation in cardiac magnetic resonance imaging. In Proceedings of the Medical Imaging 2019: Biomedical Applications in Molecular, Structural, and Functional Imaging, San Diego, CA, USA, 16–21 February 2019. [Google Scholar]
- Romaguera, L.V.; Romero, F.P.; Costa, C.F.F.; Costa, M.G.F. Left ventricle segmentation in cardiac MRI images using fully convolutional neural networks. In Proceedings of the Medical Imaging 2017: Computer-Aided Diagnosis, Orlando, FL, USA, 11–16 February 2017. [Google Scholar]
- Nasr-Esfahani, M.; Mohrekesh, M.; Akbari, M.; Soroushmehr, S.R.; Nasr-Esfahani, E.; Karimi, N.; Samavi, S.; Najarian, K. Left ventricle segmentation in cardiac MR images using fully convolutional network. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Honolulu, HI, USA, 17–21 July 2018; pp. 1275–1278. [Google Scholar]
- Avendi, M.R.; Kheradvar, A.; Jafarkhani, H. A combined deep-learning and deformable-model approach to fully automatic segmentation of the left ventricle in cardiac MRI. Med. Image Anal. 2016, 30, 108–119. [Google Scholar] [CrossRef] [Green Version]
- Ngo, T.A.; Lu, Z.; Carneiro, G. Combining deep learning and level set for the automated segmentation of the left ventricle of the heart from cardiac cine magnetic resonance. Med. Image Anal. 2017, 35, 159–171. [Google Scholar] [CrossRef]
- Rupprecht, C.; Huaroc, E.; Baust, M.; Navab, N. Deep Active Contours. Available online: https://arxiv.org/abs/1607.05074 (accessed on 18 July 2016).
- Shokri, M.; Tizhoosh, H.R. Using reinforcement learning for image thresholding. In Proceedings of the CCECE 2003-Canadian Conference on Electrical and Computer Engineering, Toward a Caring and Humane Technology, Montreal, QC, Canada, 4–7 May 2003; pp. 1231–1234. [Google Scholar]
- Song, G.; Myeong, H.; Lee, K.M. Seednet: Automatic seed generation with deep reinforcement learning for robust interactive segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1760–1768. [Google Scholar]
- Grady, L. Random walks for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Yang, L.; Zhang, D.; Chang, X.; Liang, X. Reinforcement cutting-agent learning for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9080–9089. [Google Scholar]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- Castrejon, L.; Kundu, K.; Urtasun, R.; Fidler, S. Annotating object instances with a polygon-rnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5230–5238. [Google Scholar]
- Acuna, D.; Ling, H.; Kar, A.; Fidler, S. Efficient interactive annotation of segmentation datasets with polygon-rnn++. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 859–868. [Google Scholar]
- Chitsaz, M.; Seng, W.C. Medical image segmentation by using reinforcement learning agent. In Proceedings of the 2009 International Conference on Digital Image Processing, Bangkok, Thailand, 7–9 March 2009; pp. 216–219. [Google Scholar]
- Chitsaz, M.; Woo, C.S. Software agent with reinforcement learning approach for medical image segmentation. J. Comput. Sci. Technol. 2011, 26, 247–255. [Google Scholar] [CrossRef]
- Tian, Z.; Si, X.; Zheng, Y.; Chen, Z.; Li, X. Multi-step medical image segmentation based on reinforcement learning. J. Ambient. Intell. Humaniz. Comput. 2020, 1–12. [Google Scholar] [CrossRef]
- Dong, N.; Kampffmeyer, M.; Liang, X.; Wang, Z.; Dai, W.; Xing, E. Reinforced auto-zoom net: Towards accurate and fast breast cancer segmentation in whole-slide images. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 20 September 2018; pp. 317–325. [Google Scholar]
- Sahba, F.; Tizhoosh, H.R.; Salama, M.M. A reinforcement learning framework for medical image segmentation. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; pp. 511–517. [Google Scholar]
- Sahba, F.; Tizhoosh, H.R.; Salama, M.M. Application of reinforcement learning for segmentation of transrectal ultrasound images. BMC Med. Imaging 2008, 8, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, X.; Li, W.; Xu, Q.; Wang, X.; Jin, B.; Zhang, X.; Zhang, Y.; Wang, Y. Iteratively-Refined Interactive 3D Medical Image Segmentation with Multi-Agent Reinforcement Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9394–9402. [Google Scholar]
- Wang, L.; Merrifield, R.; Yang, G.Z. Reinforcement learning for context aware segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Toronto, ON, Canada, 18–22 September 2011; pp. 627–634. [Google Scholar]
- Wang, L.; Lekadir, K.; Lee, S.L.; Merrifield, R.; Yang, G.Z. A general framework for context-specific image segmentation using reinforcement learning. IEEE Trans. Med. Imaging 2013, 32, 943–956. [Google Scholar] [CrossRef]
- Mortazi, A.; Bagci, U. Automatically designing CNN architectures for medical image segmentation. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Granada, Spain, 16 September 2018; pp. 98–106. [Google Scholar]
- Mahmud, M.; Kaiser, M.S.; Hussain, A.; Vassanelli, S. Applications of deep learning and reinforcement learning to biological data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2063–2079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Bernard, O.; Lale, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Jodoin, P.M. Deep Learning Techniques for Automatic MRI Cardiac Multi-structures Segmentation and Diagnosis: Is the Problem Solved? IEEE Trans. Med. Imag. 2018, 37, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Radau, P.; Lu, Y.; Connelly, K.; Paul, G.; Dick, A.; Wright, G. Evaluation framework for algorithms segmenting short axis cardiac MRI. Midas J. Card. Left Ventricle Segm. Chall. Available online: http://hdl.handle.net/10380/3070 (accessed on 7 September 2009).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
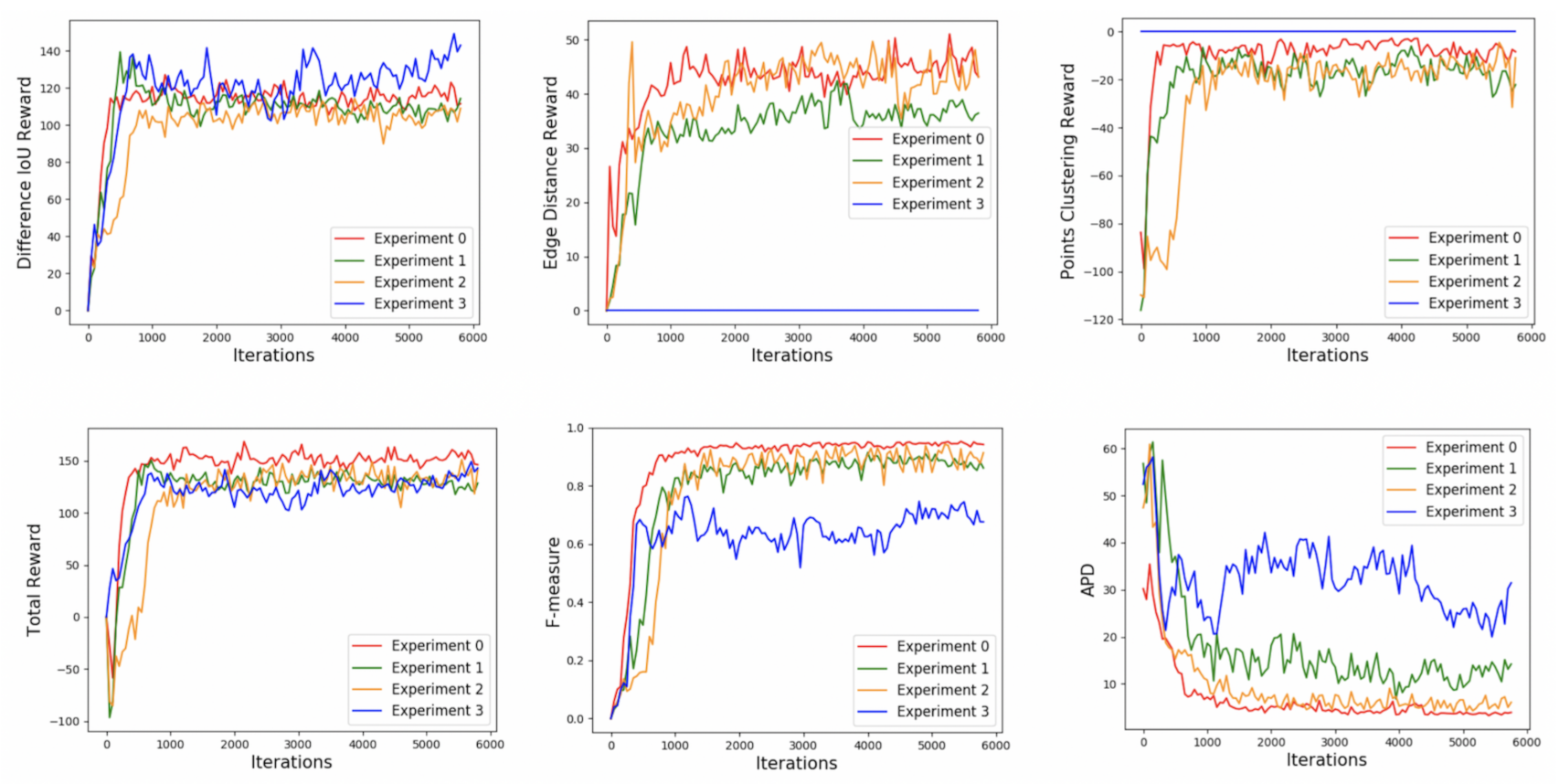
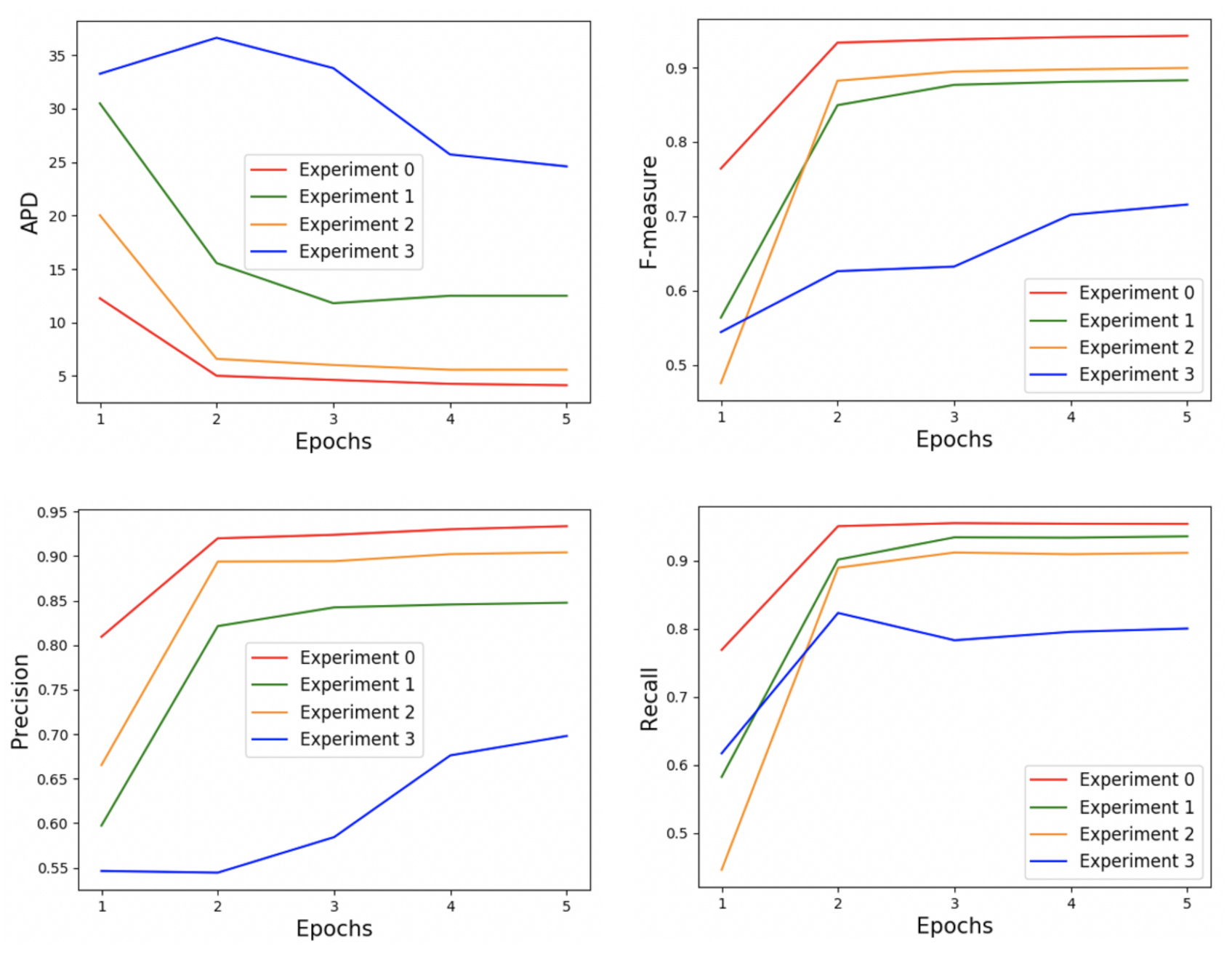
| Exp | State | Reward | Difference IoU Reward | Edge Distance Reward | Points Clusting Reward | Total Reward | APD | Precision | Recall | F-Measure |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | SCGP | RdReRp | 110.9860 | 44.8845 | −3.9499 | 149.9206 | 4.1757 | 0.9383 | 0.9500 | 0.9428 |
| 1 | SP | RdReRp | 98.6766 | 35.1291 | −4.9411 | 128.8646 | 11.6372 | 0.8580 | 0.9181 | 0.8808 |
| 2 | SCG | RdReRp | 96.2734 | 38.4739 | −13.5838 | 121.1635 | 6.1673 | 0.8824 | 0.9004 | 0.8825 |
| 3 | SCGP | Rd | 124.3672 | 0 | 0 | 124.3672 | 24.4755 | 0.6723 | 0.8043 | 0.6997 |
| Dataset | Model | Method | APD | Precision | Recall | F-Measure | |
|---|---|---|---|---|---|---|---|
| DL | RL | ||||||
| FCN-8s [26] | ✓ | 4.8724 | 0.9340 | 0.9329 | 0.9326 | ||
| U-Net [2] | ✓ | 4.3779 | 0.9395 | 0.9401 | 0.9388 | ||
| UNet++ [21] | ✓ | 4.0660 | 0.9429 | 0.9420 | 0.9418 | ||
| ACDC | AttenU-Net [22] | ✓ | 3.8900 | 0.9357 | 0.9589 | 0.9465 | |
| 2017 [62] | FCN2 [27] | ✓ | 6.865 | - | - | 0.94 | |
| DeepLab+U-Net [31] | ✓ | - | - | - | 0.9502 | ||
| Policy Gradient [57] | ✓ | 8.9 | - | - | 0.928 | ||
| The proposed | ✓ | 4.1757 | 0.9383 | 0.9500 | 0.9428 | ||
| FCN-8s [26] | ✓ | 5.4146 | 0.9418 | 0.9193 | 0.9292 | ||
| U-Net [2] | ✓ | 5.4541 | 0.9475 | 0.9141 | 0.9295 | ||
| Sunnybrook | UNet++ [21] | ✓ | 5.2907 | 0.9242 | 0.9409 | 0.9317 | |
| 2009 [63] | AttenU-Net [22] | ✓ | 5.1936 | 0.9490 | 0.9238 | 0.9351 | |
| The proposed | ✓ | 5.7185 | 0.9155 | 0.9431 | 0.9270 | ||
| Train Set | Test Set | Model | APD | Precision | Recall | F-Measure |
|---|---|---|---|---|---|---|
| FCN-8s [26] | 8.5395 | 0.9147 | 0.8513 | 0.8796 | ||
| U-Net [2] | 7.0136 | 0.8707 | 0.8979 | 0.8828 | ||
| 1 + 2 | 3 | UNet++ [21] | 8.4232 | 0.8217 | 0.8839 | 0.8504 |
| AttenU-Net [22] | 7.4199 | 0.8348 | 0.9085 | 0.8689 | ||
| The proposed | 8.9178 | 0.8770 | 0.9281 | 0.8983 | ||
| FCN-8s [26] | 6.5695 | 0.9307 | 0.8846 | 0.9055 | ||
| U-Net [2] | 5.3193 | 0.9059 | 0.9402 | 0.9216 | ||
| 1 + 3 | 2 | UNet++ [21] | 5.8975 | 0.9153 | 0.9266 | 0.9197 |
| AttenU-Net [22] | 5.1295 | 0.9094 | 0.9284 | 0.9175 | ||
| The proposed | 4.8773 | 0.9334 | 0.9416 | 0.9357 | ||
| FCN-8s [26] | 6.1855 | 0.9421 | 0.8717 | 0.9047 | ||
| U-Net [2] | 5.4322 | 0.9287 | 0.9079 | 0.9167 | ||
| 2 + 3 | 1 | UNet++ [21] | 6.5104 | 0.9053 | 0.8846 | 0.8931 |
| AttenU-Net [22] | 5.5275 | 0.9171 | 0.9111 | 0.9126 | ||
| The proposed | 6.4510 | 0.9041 | 0.9385 | 0.9181 | ||
| FCN-8s [26] | 7.0982 | 0.9292 | 0.8692 | 0.8966 | ||
| U-Net [2] | 5.9217 | 0.9018 | 0.9153 | 0.9070 | ||
| average result | UNet++ [21] | 6.9437 | 0.8808 | 0.8984 | 0.8877 | |
| AttenU-Net [22] | 6.0256 | 0.8871 | 0.9160 | 0.8997 | ||
| The proposed | 6.7481 | 0.9048 | 0.9360 | 0.9173 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, J.; Po, L.-M.; Cheung, K.W.; Xian, P.; Zhao, Y.; Rehman, Y.A.U.; Zhang, Y. Edge-Sensitive Left Ventricle Segmentation Using Deep Reinforcement Learning. Sensors 2021, 21, 2375. https://doi.org/10.3390/s21072375
Xiong J, Po L-M, Cheung KW, Xian P, Zhao Y, Rehman YAU, Zhang Y. Edge-Sensitive Left Ventricle Segmentation Using Deep Reinforcement Learning. Sensors. 2021; 21(7):2375. https://doi.org/10.3390/s21072375
Chicago/Turabian StyleXiong, Jingjing, Lai-Man Po, Kwok Wai Cheung, Pengfei Xian, Yuzhi Zhao, Yasar Abbas Ur Rehman, and Yujia Zhang. 2021. "Edge-Sensitive Left Ventricle Segmentation Using Deep Reinforcement Learning" Sensors 21, no. 7: 2375. https://doi.org/10.3390/s21072375
APA StyleXiong, J., Po, L. -M., Cheung, K. W., Xian, P., Zhao, Y., Rehman, Y. A. U., & Zhang, Y. (2021). Edge-Sensitive Left Ventricle Segmentation Using Deep Reinforcement Learning. Sensors, 21(7), 2375. https://doi.org/10.3390/s21072375