
SEMPANet: A Modified Path Aggregation Network with Squeeze-Excitation for Scene Text Detection


Abstract
:1. Introduction
2. Related Work
2.1. Anchor-Based and Anchor-Free
2.2. One-Stage and Two-Stage Algorithms
2.3. ResNet and FPN
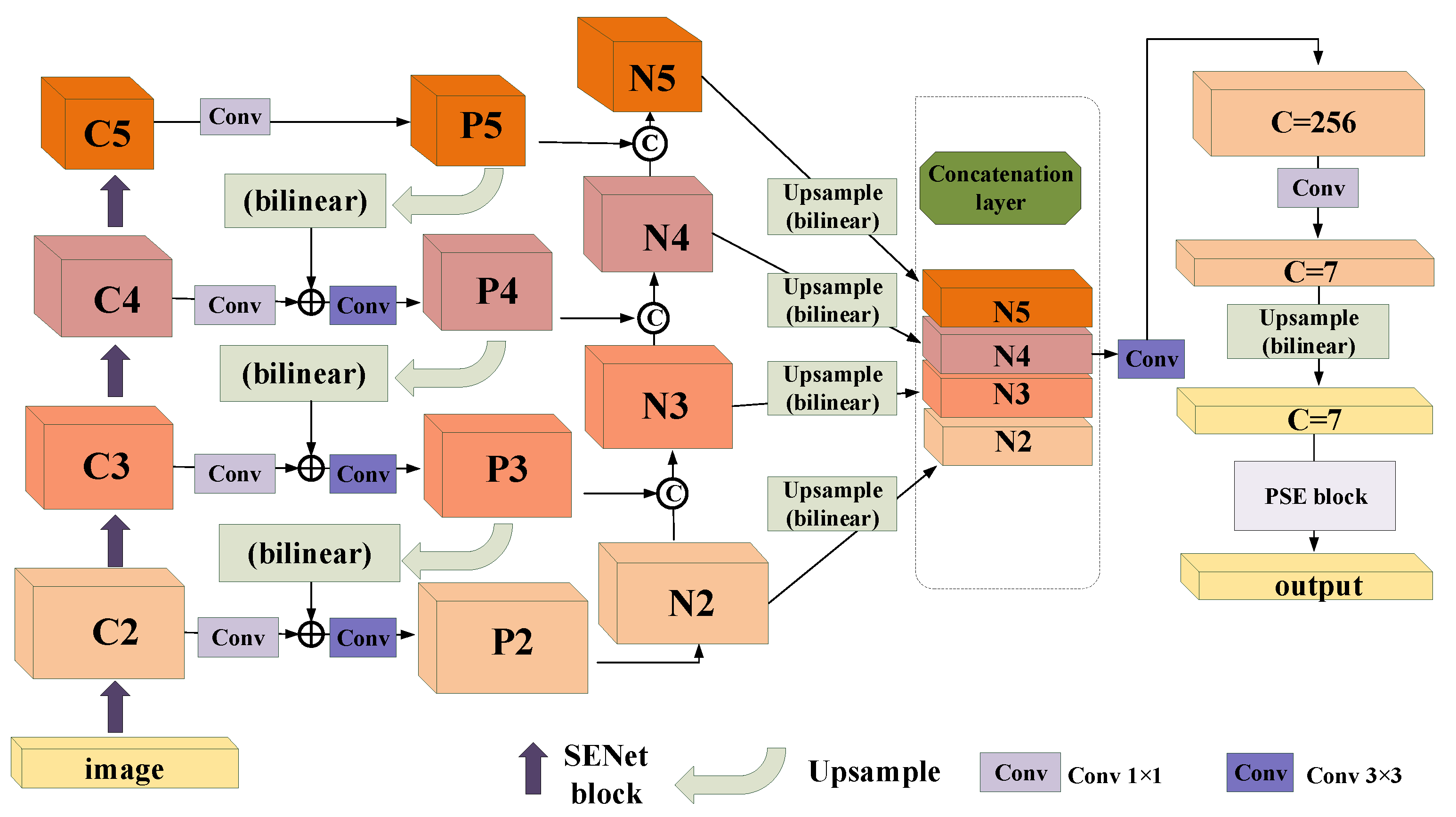
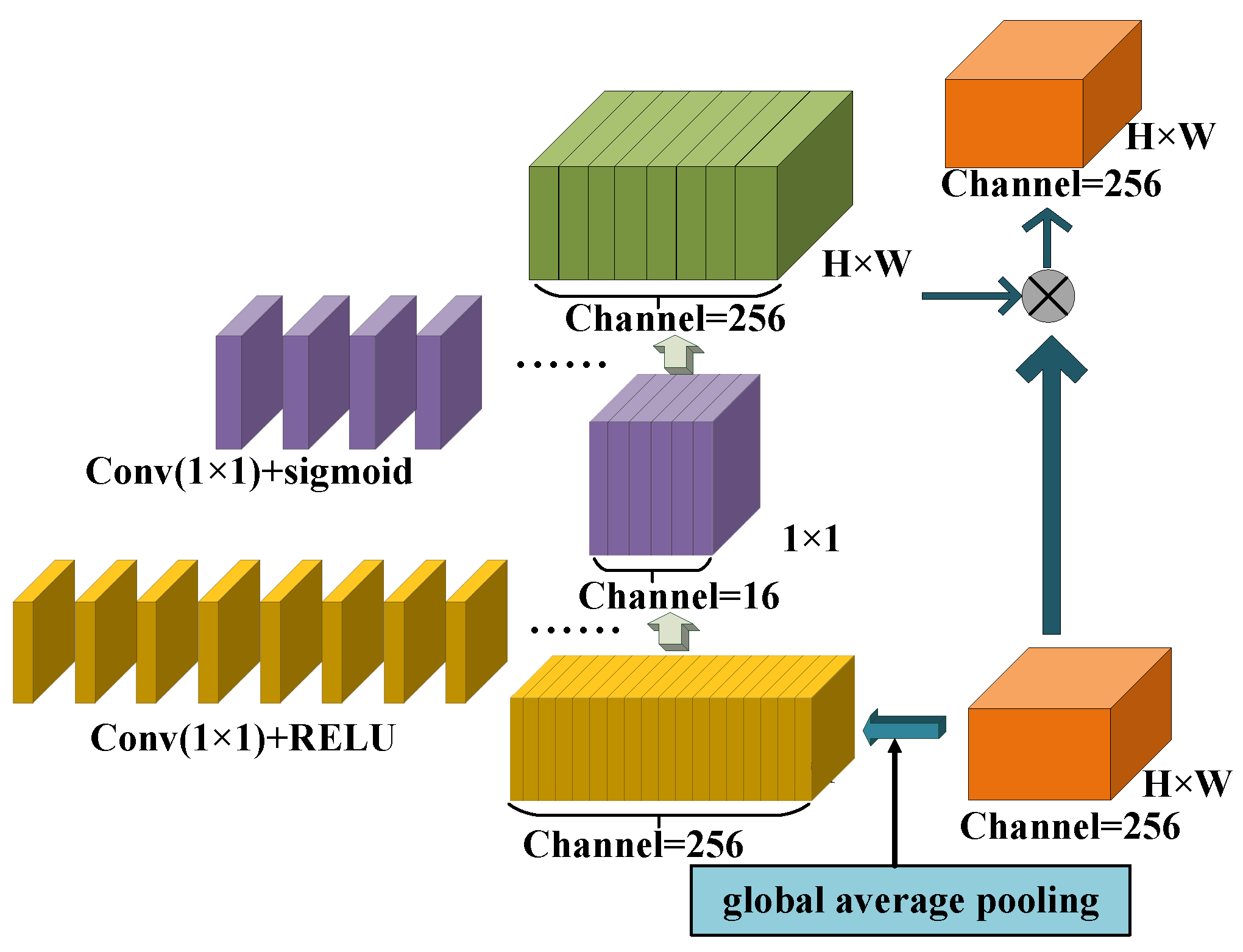
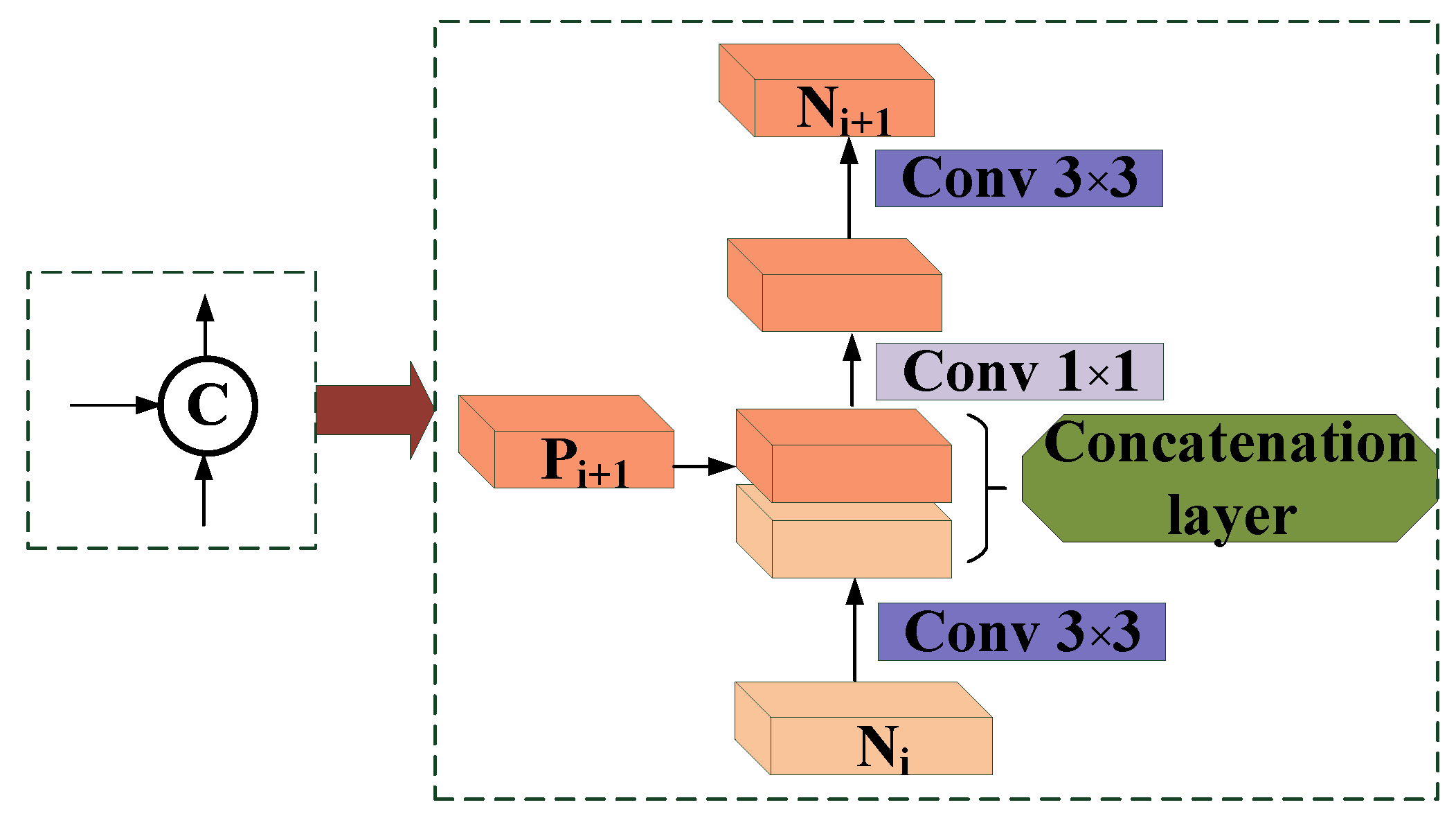
3. Principle of the Method
3.1. SENet Block
3.2. Architecture of MPANet
4. Experiments
4.1. Experiment Configuration
4.2. Benchmark Datasets
4.2.1. ICDAR2015
4.2.2. CTW1500
4.3. Performance Evaluation Criteria
4.3.1. Recall
4.3.2. Precision
4.3.3. F-measure
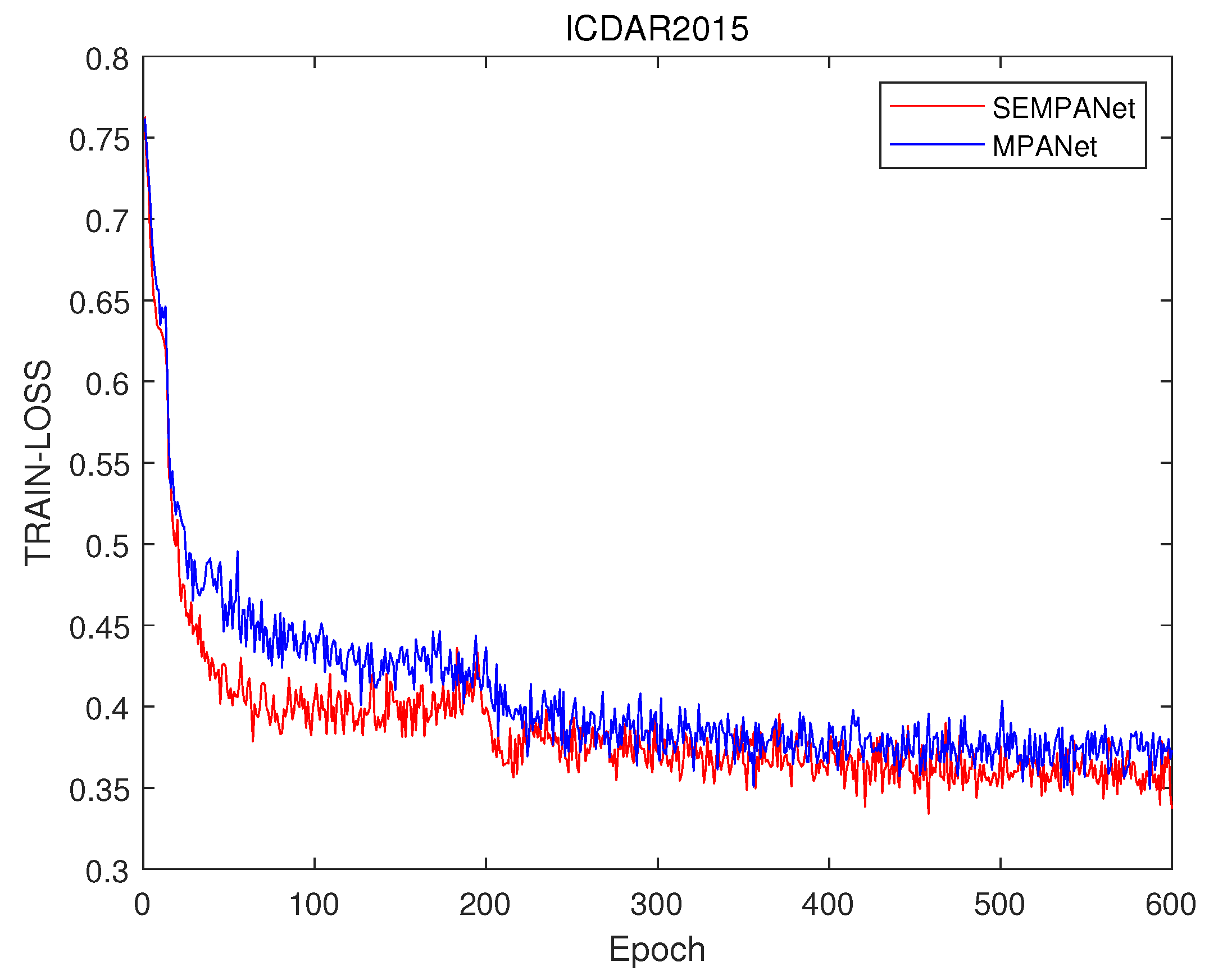
4.4. Ablation Study
4.4.1. Effects of MPANet
4.4.2. Effects of the Threshold in the Testing Phase
4.5. Experimental Results
4.5.1. Evaluation on Oriented Text Benchmark
4.5.2. Evaluation on Curve Text Benchmark
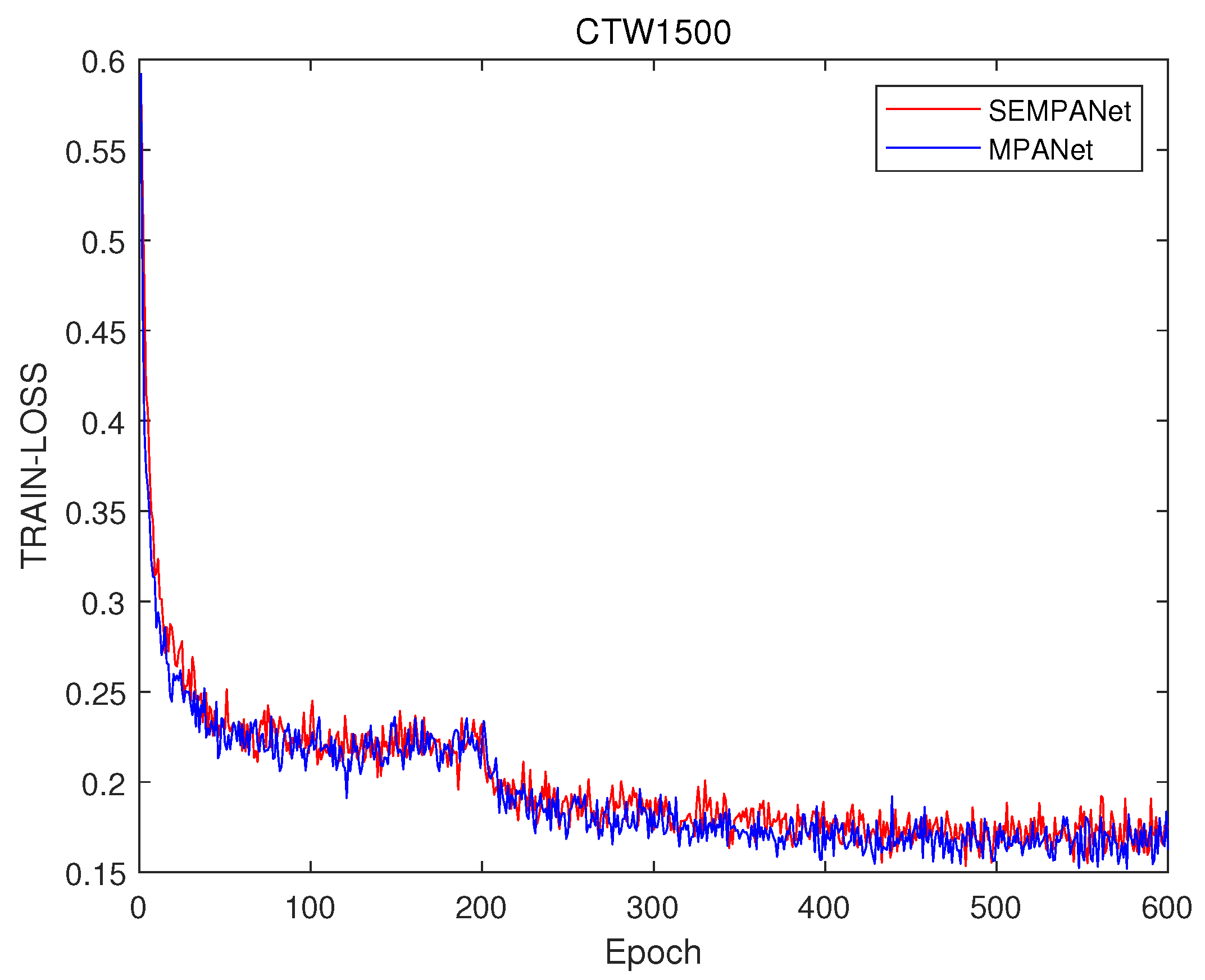
4.6. Discussion of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aljuaid, H.; Iftikhar, R.; Ahmad, S.; Asif, M.; Afzal, M.T. Important citation identification using sentiment analysis of in-text citations. Telemat. Inform. 2021, 56, 101492. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogate, M.; Li, J.; Jiang, F.; Kong, B.; Hussain, A. A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing 2020, 380, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Cao, W.; Liu, Q.; He, Z. Review of pavement defect detection methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Shi, B.; Bai, X.; Belongie, S. Detecting oriented text in natural images by linking segments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2550–2558. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting text in natural image with connectionist text proposal network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: New York, NY, USA, 2016; pp. 56–72. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: New York, NY, USA, 2016; pp. 630–645. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. Textboxes: A fast text detector with a single deep neural network. arXiv 2016, arXiv:1611.06779. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Process. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Jin, L. Deep matching prior network: Toward tighter multi-oriented text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1962–1969. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, South Korea, 27 October–3 November 2019; pp. 9627–9636. [Google Scholar]
- Zhong, Z.; Sun, L.; Huo, Q. An anchor-free region proposal network for faster r-cnn-based text detection approaches. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 315–327. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 9336–9345. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2315–2324. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An efficient and accurate scene text detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5551–5560. [Google Scholar]
- Wang, X.; Zheng, S.; Zhang, C.; Li, R.; Gui, L. R-YOLO: A Real-Time Text Detector for Natural Scenes with Arbitrary Rotation. Sensors 2021, 21, 888. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lyu, P.; Liao, M.; Yao, C.; Wu, W.; Bai, X. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 67–83. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ye, J.; Chen, Z.; Liu, J.; Du, B. TextFuseNet: Scene Text Detection with Richer Fused Features. In Proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Yang, Q.; Cheng, M.; Zhou, W.; Chen, Y.; Qiu, M.; Lin, W.; Chu, W. Inceptext: A new inception-text module with deformable psroi pooling for multi-oriented scene text detection. arXiv 2018, arXiv:1805.01167. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Valveny, E. Icdar 2015 competition on robust reading. In Proceedings of the International Conference on Document Analysis & Recognition, Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Yuliang, L.; Lianwen, J.; Shuaitao, Z.; Sheng, Z. Detecting curve text in the wild: New dataset and new solution. arXiv 2017, arXiv:1712.02170. [Google Scholar]
- Nayef, N.; Fei, Y.; Bizid, I.; Choi, H.; Ogier, J.M. Icdar2017 robust reading challenge on multi-lingual scene text detection and script identification—Rrc-mlt. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Heras, L.P.D.L. Icdar 2013 robust reading competition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013. [Google Scholar]
- Jiang, X.; Xu, S.; Zhang, S.; Cao, S. Arbitrary-Shaped Text Detection with Adaptive Text Region Representation. IEEE Access 2020, 8, 102106–102118. [Google Scholar] [CrossRef]
- Córdova, M.; Pinto, A.; Pedrini, H.; Torres, R.D.S. Pelee-Text++: A Tiny Neural Network for Scene Text Detection. IEEE Access 2020, 8, 223172–223188. [Google Scholar] [CrossRef]
- Qin, X.; Jiang, J.; Yuan, C.A.; Qiao, S.; Fan, W. Arbitrary shape natural scene text detection method based on soft attention mechanism and dilated convolution. IEEE Access 2020, 8, 122685–122694. [Google Scholar] [CrossRef]
- He, P.; Huang, W.; He, T.; Zhu, Q.; Li, X. Single shot text detector with regional attention. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Hu, H.; Zhang, C.; Luo, Y.; Wang, Y.; Han, J.; Ding, E. Wordsup: Exploiting word annotations for character based text detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4940–4949. [Google Scholar]
- He, W.; Zhang, X.Y.; Yin, F.; Liu, C.L. Deep direct regression for multi-oriented scene text detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-oriented scene text detection via corner localization and region segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7553–7563. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. Textsnake: A flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Liu, Z.; Lin, G.; Yang, S.; Liu, F.; Lin, W.; Goh, W.L. Towards robust curve text detection with conditional spatial expansion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Wang, R.; Shen, M.; Wang, X.; Cao, W. RGA-CNNs: Convolutional neural networks based on reduced geometric algebra. Sci. China Inf. Sci. 2021, 64, 1–3. [Google Scholar] [CrossRef]
- Wang, R.; Shen, M.; Wang, T.; Cao, W. L1-norm minimization for multi-dimensional signals based on geometric algebra. Adv. Appl. Clifford Algebr. 2019, 29, 1–18. [Google Scholar] [CrossRef]
- Lin, Q.; Cao, W.; He, Z.; He, Z. Mask Cross-Modal Hashing Networks. IEEE Trans. Multimed. 2021, 23, 550–558. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software Platform | System | Code Edit | Framework |
|---|---|---|---|
| Ubuntu 16.04 LTS | Python2.7 | PyTorch1.2 | |
| Hardware Platform | Memory | GPU | CPU |
| 25 GB | GeForce RTX 2080Ti 11G memory | 28 core |
| Method | Recall | Precision | F-Measure |
|---|---|---|---|
| FPN * | 79.68 | 81.49 | 80.57 |
| MPANet * | 79.97 | 83.26 | 81.58 |
| Gain * | 0.29 | 1.77 | 1.01 |
| FPN † | 75.55 | 80.57 | 78.00 |
| MPANet † | 75.52 | 83.29 | 79.21 |
| Gain † | −0.03 | 2.72 | 1.21 |
| in MPANet | Recall | Precision | F-Measure |
|---|---|---|---|
| 0.93 | 78.77 | 85.92 | 82.19 |
| 0.91 | 79.82 | 84.25 | 81.98 |
| 0.89 | 79.97 | 83.26 | 81.58 |
| in SEMPANet | Recall | Precision | F-Measure |
| 0.93 | 78.57 | 84.74 | 81.54 |
| 0.91 | 79.83 | 83.57 | 81.65 |
| 0.89 | 80.45 | 82.80 | 81.61 |
| Method | Year | Ext | Recall | Precision | F-Measure |
|---|---|---|---|---|---|
| CTPN [8] | 2016 | - | 51.6 | 74.2 | 60.9 |
| Seglink [6] | 2017 | √ | 73.1 | 76.8 | 75.0 |
| SSTD [41] | 2017 | √ | 73.9 | 80.2 | 76.9 |
| EAST [24] | 2017 | - | 73.5 | 83.6 | 78.2 |
| WordSup [42] | 2017 | √ | 77.0 | 79.3 | 78.2 |
| DeepReg [43] | 2017 | - | 80.0 | 82.0 | 81.0 |
| RRPN [9] | 2018 | - | 73.0 | 82.0 | 77.0 |
| Lyu et al. [44] | 2018 | √ | 70.7 | 94.1 | 80.7 |
| PAN [45] | 2019 | - | 77.8 | 82.9 | 80.3 |
| PSENet-1s [21] | 2019 | - | 79.7 | 81.5 | 80.6 |
| Pelee-Text++ [39] | 2020 | √ | 76.7 | 87.5 | 81.7 |
| Qin et al. [40] | 2020 | - | 80.20 | 82.86 | 81.56 |
| Jiang et al. [38] | 2020 | - | 79.68 | 85.79 | 82.62 |
| MPANet | - | 79.97 | 83.26 | 81.58 | |
| SEMPANet | - | 80.45 | 82.80 | 81.61 |
| Method | Year | Ext | Recall | Precision | F-Measure |
|---|---|---|---|---|---|
| CTPN * [8] | 2016 | - | 53.8 | 60.4 | 56.9 |
| Seglink * [6] | 2017 | - | 40.0 | 42.3 | 40.8 |
| EAST * [24] | 2017 | - | 49.1 | 78.7 | 60.4 |
| CTD+TLOC [35] | 2017 | - | 69.8 | 77.4 | 73.4 |
| TextSnake [46] | 2018 | √ | 85.3 | 67.9 | 75.6 |
| CSE [47] | 2019 | √ | 76.0 | 81.1 | 78.4 |
| PSENet-1s [21] | 2019 | - | 75.6 | 80.6 | 78.0 |
| Jiang et al. [38] | 2020 | - | 75.9 | 80.6 | 78.2 |
| Qin et al. [40] | 2020 | - | 76.8 | 81.8 | 79.4 |
| MPANet | - | 75.52 | 83.29 | 79.21 | |
| SEMPANet | - | 72.82 | 84.08 | 78.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Cao, W. SEMPANet: A Modified Path Aggregation Network with Squeeze-Excitation for Scene Text Detection. Sensors 2021, 21, 2657. https://doi.org/10.3390/s21082657
Li S, Cao W. SEMPANet: A Modified Path Aggregation Network with Squeeze-Excitation for Scene Text Detection. Sensors. 2021; 21(8):2657. https://doi.org/10.3390/s21082657
Chicago/Turabian StyleLi, Shuangshuang, and Wenming Cao. 2021. "SEMPANet: A Modified Path Aggregation Network with Squeeze-Excitation for Scene Text Detection" Sensors 21, no. 8: 2657. https://doi.org/10.3390/s21082657
APA StyleLi, S., & Cao, W. (2021). SEMPANet: A Modified Path Aggregation Network with Squeeze-Excitation for Scene Text Detection. Sensors, 21(8), 2657. https://doi.org/10.3390/s21082657