
An Efficient Anomaly Recognition Framework Using an Attention Residual LSTM in Surveillance Videos





Abstract
:1. Introduction
- We propose a light-weight model for anomaly detection, functional for a real-world surveillance network. We adopted a pretrained model and extracted frame-wise features, followed by a sequential learning mechanism for the precise recognition of anomalous activity.
- We employed the residual attention-based long short-term memory (LSTM) concept, which can effectively learn temporal context information and precisely recognize anomalous activity. Moreover, using a residual attention-based LSTM saves more than 10% of learnable parameters as compared to the usual LSTM network size.
- Our proposed model is tested using the challenging University of Central Florida UCF-Crime dataset, outperforming the baseline methods in terms of accuracy with reduced number of model parameters and size compared to existing anomaly activity recognition models.
2. Related Work
2.1. Traditional Feature-Based Techniques
2.2. Deep Feature-Based Techniques
3. Materials and Methods
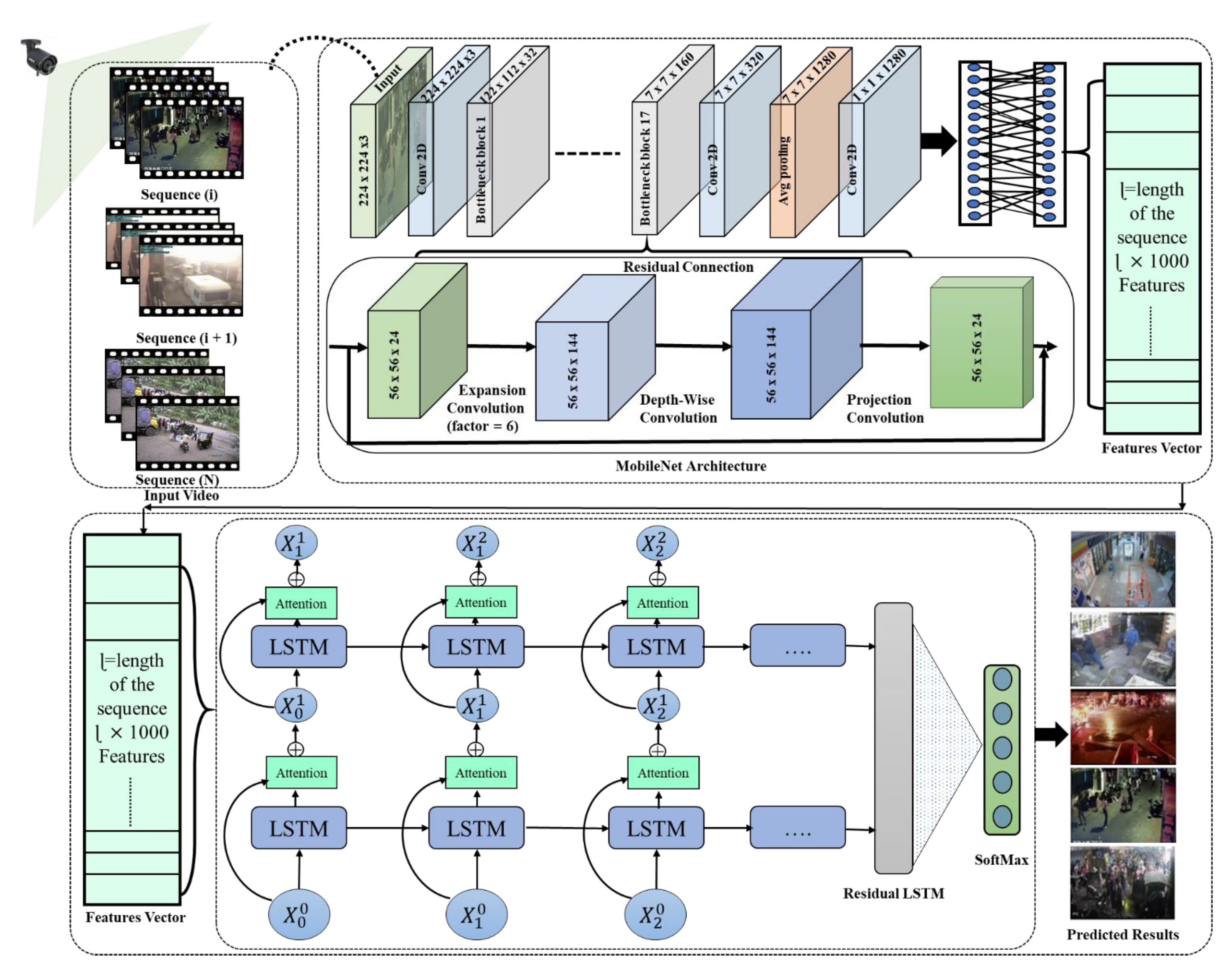
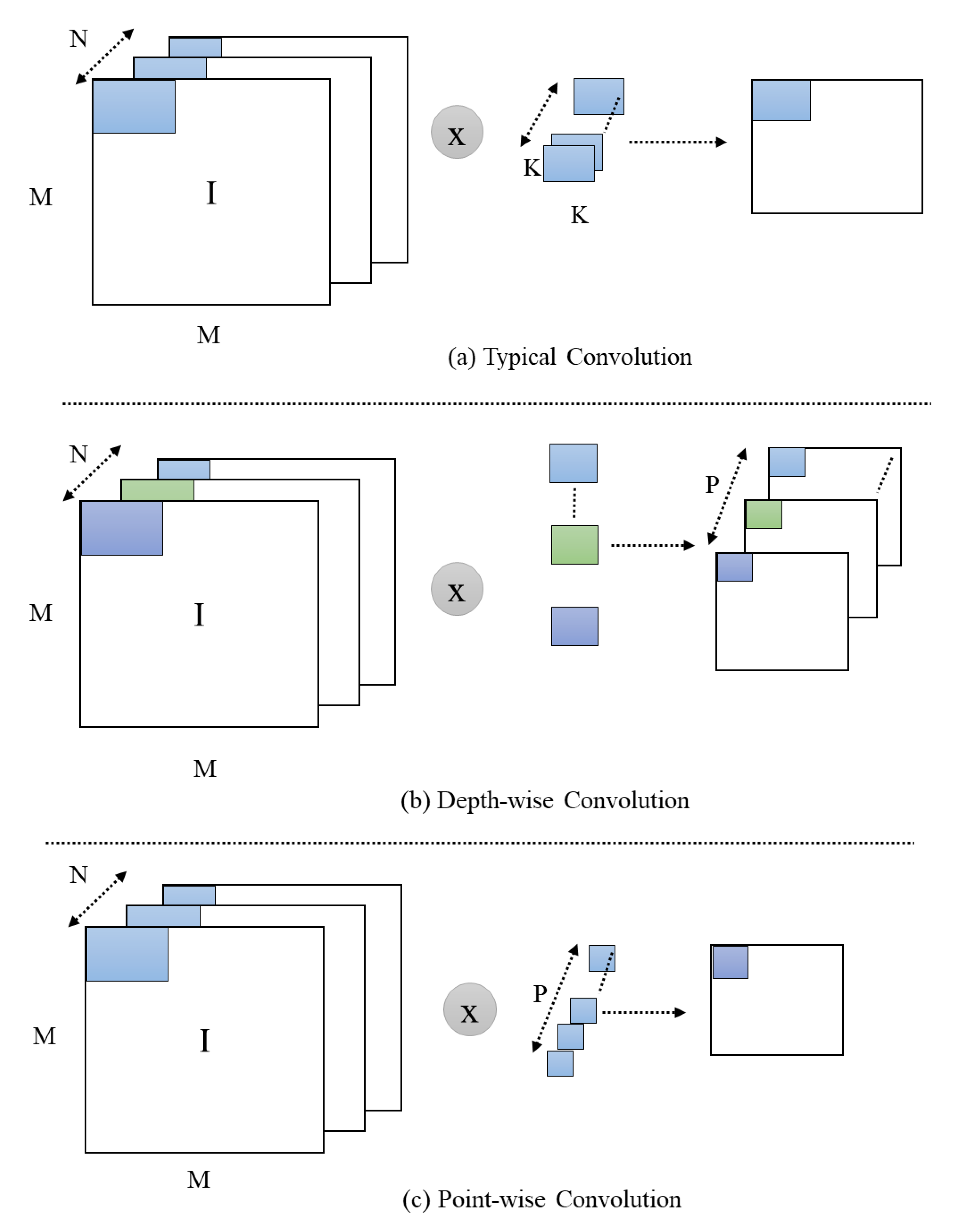
3.1. Feature Extraction Using Light-Weight CNN
3.2. Sequential Learning Techniques
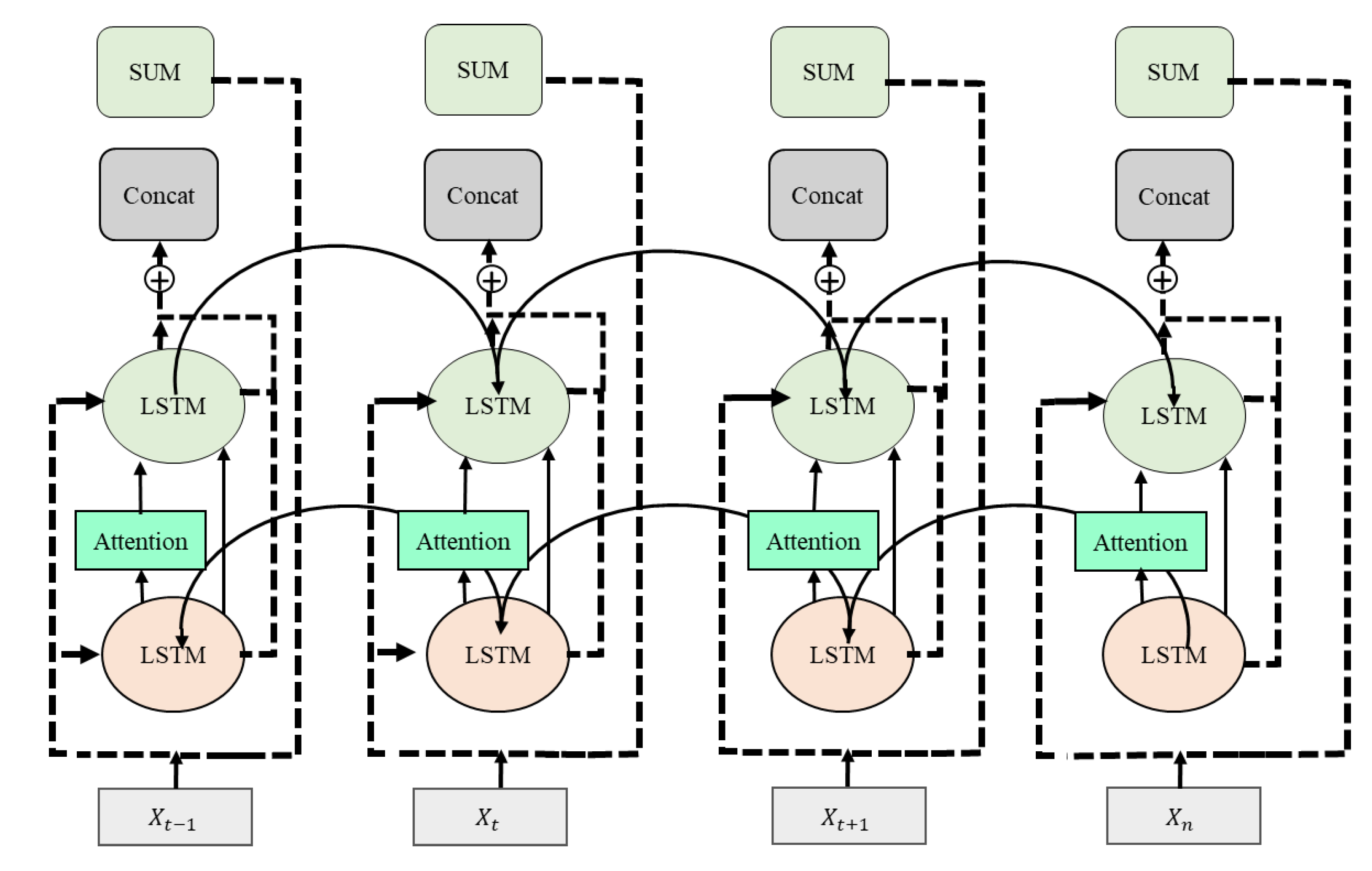
3.3. Residual Attention-Based LSTM
4. Results
4.1. Datasets
4.2. Evaluation Methods
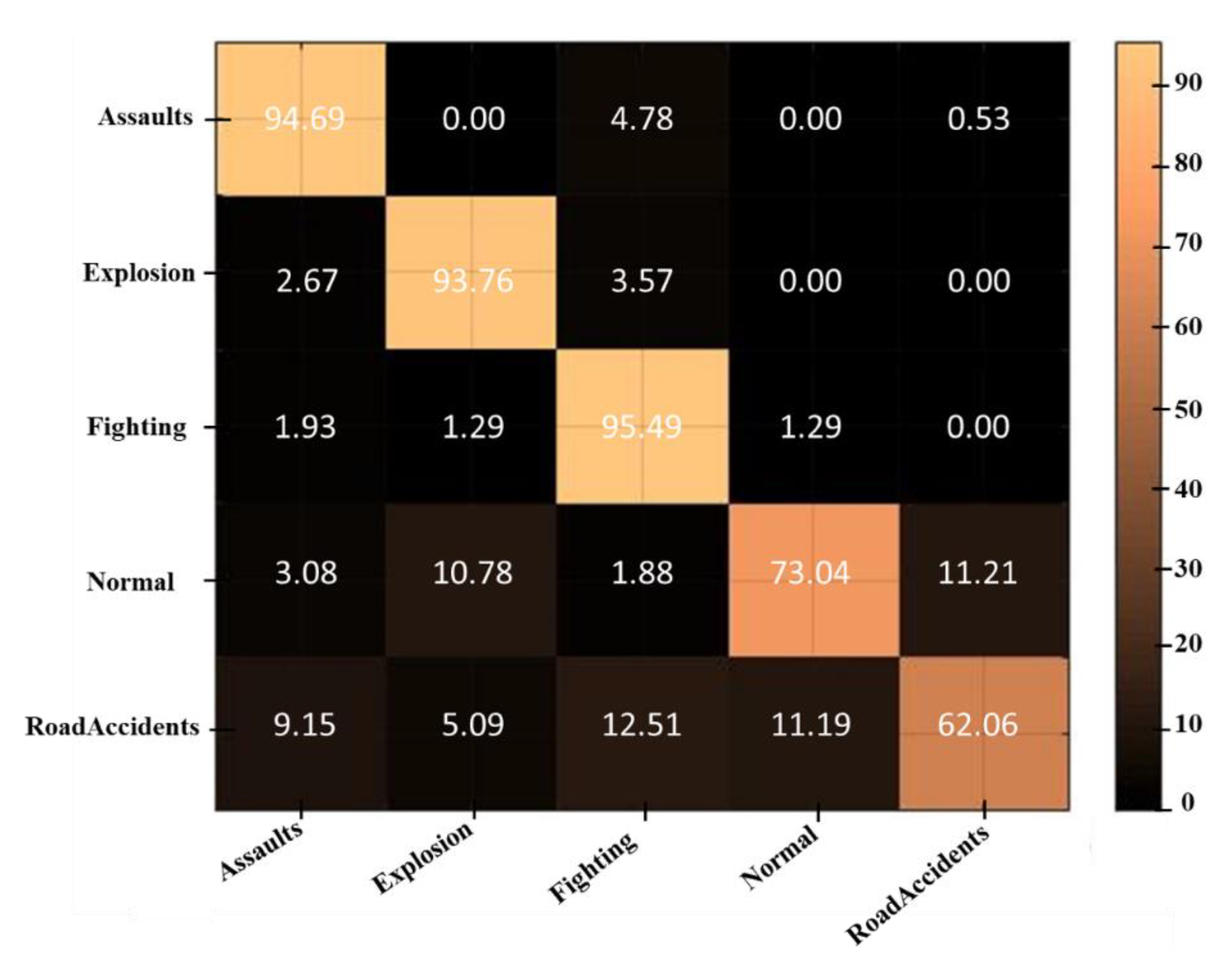
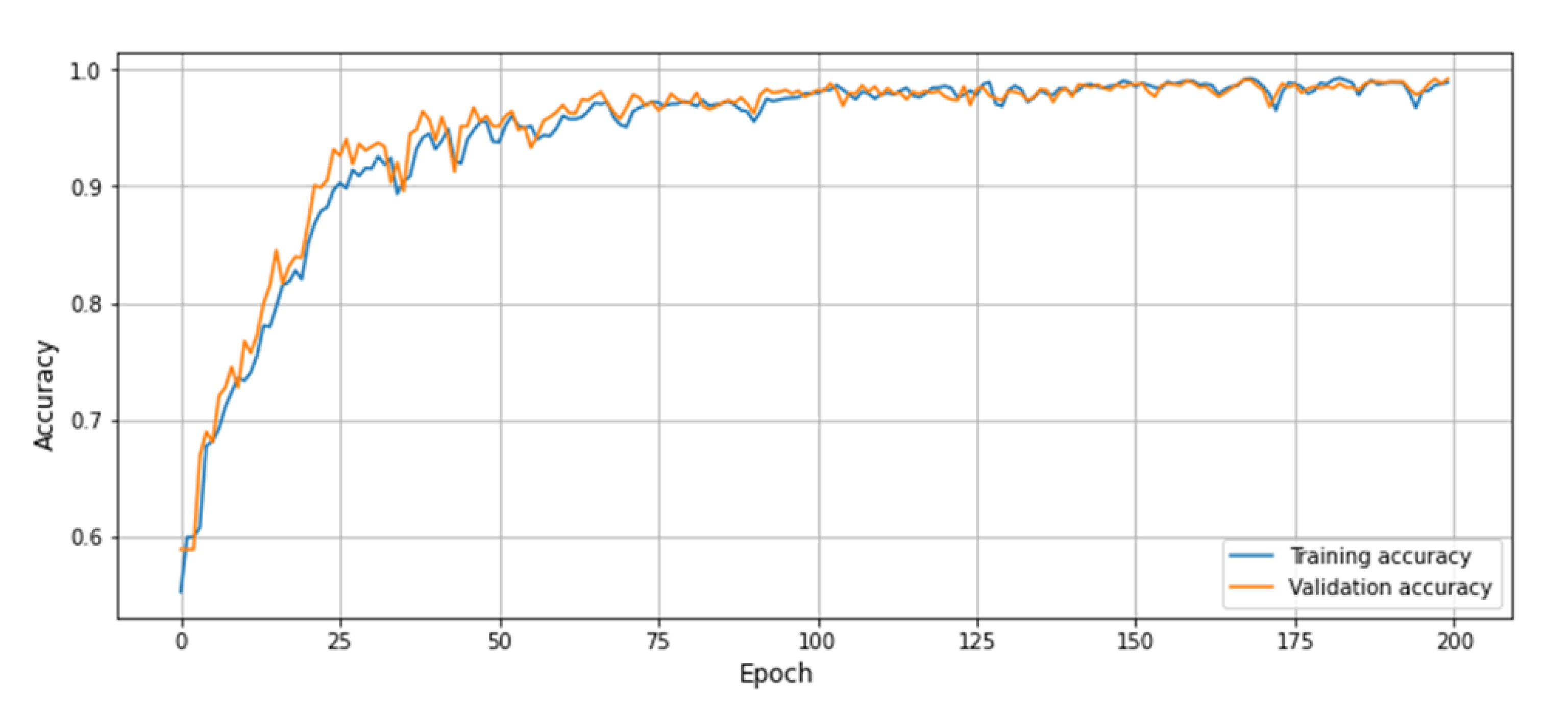
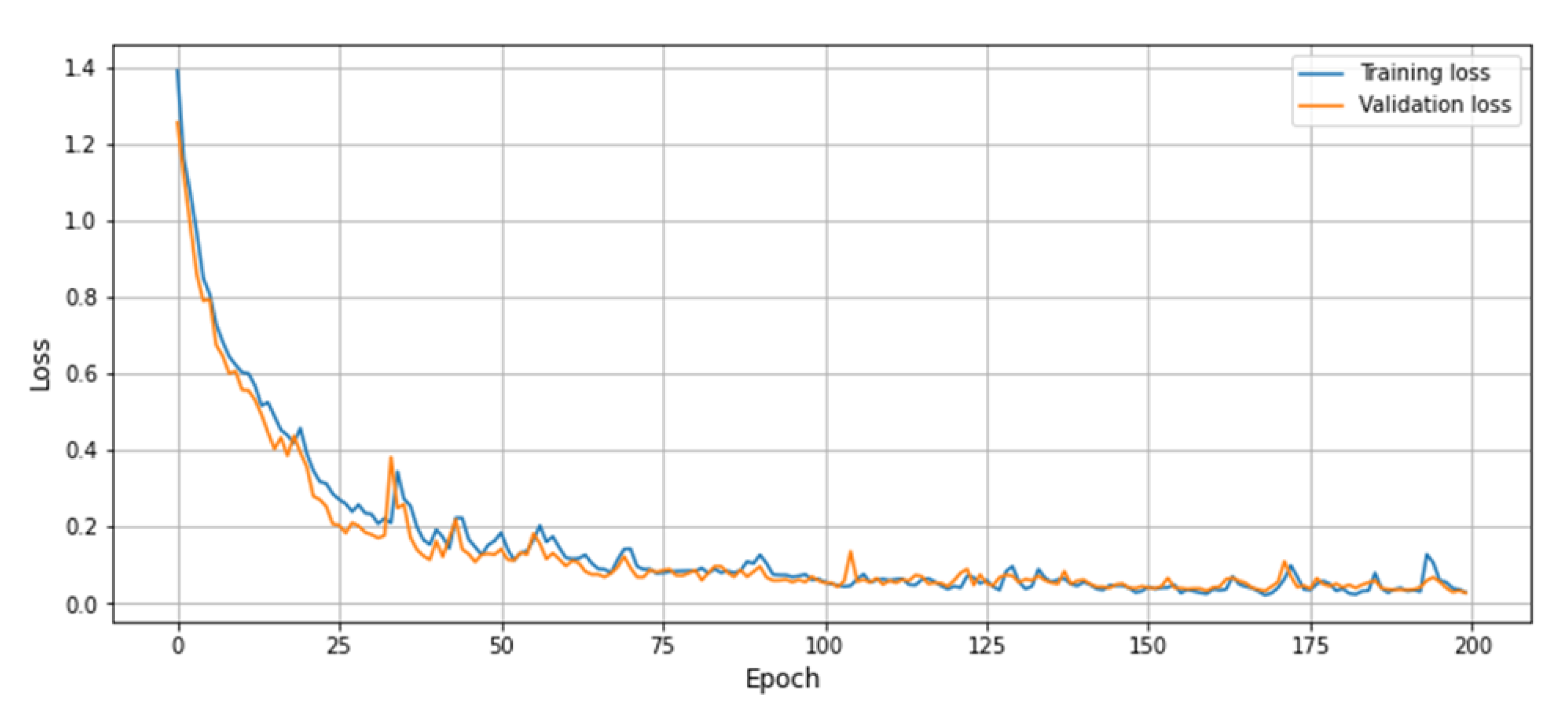
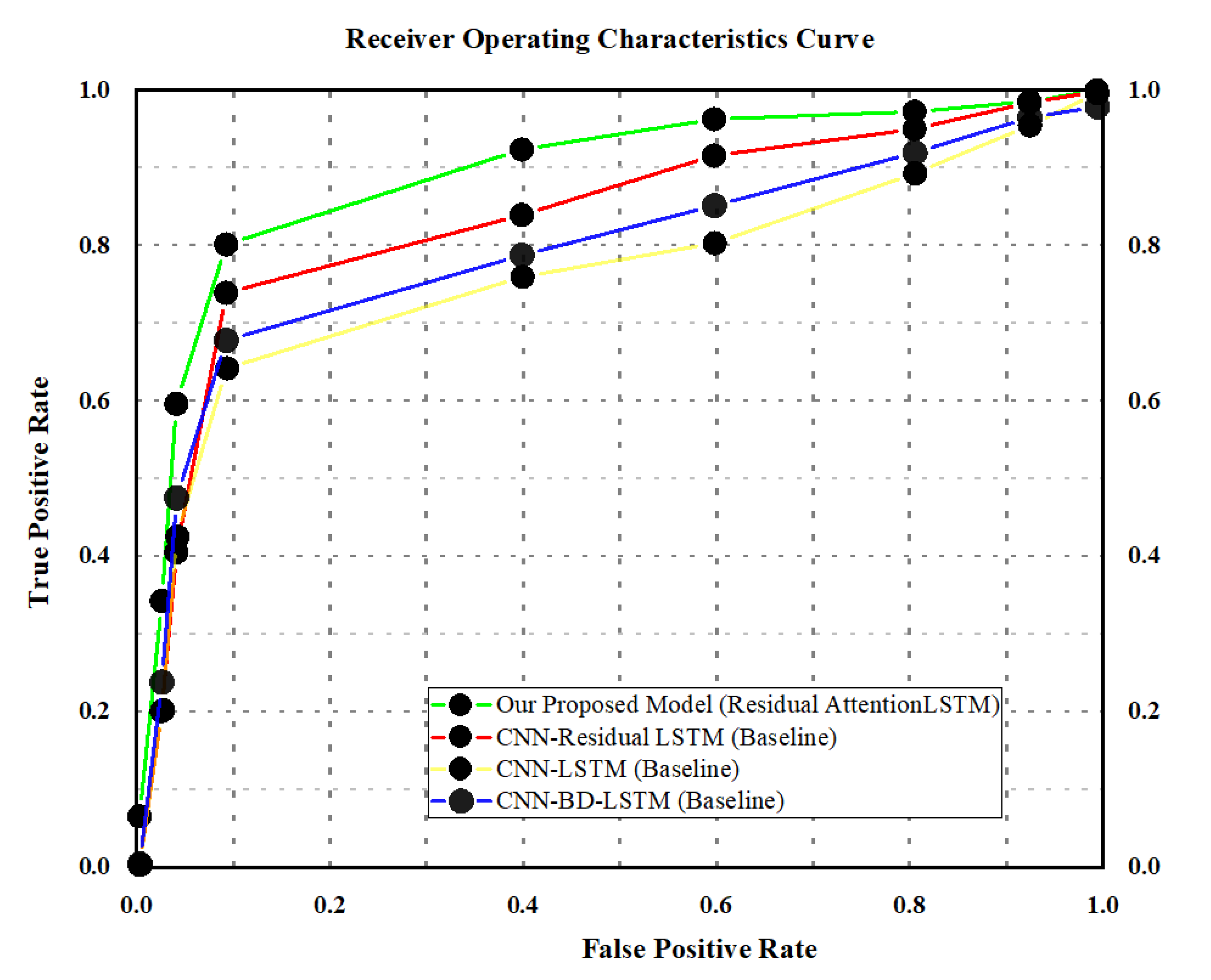
4.3. Results
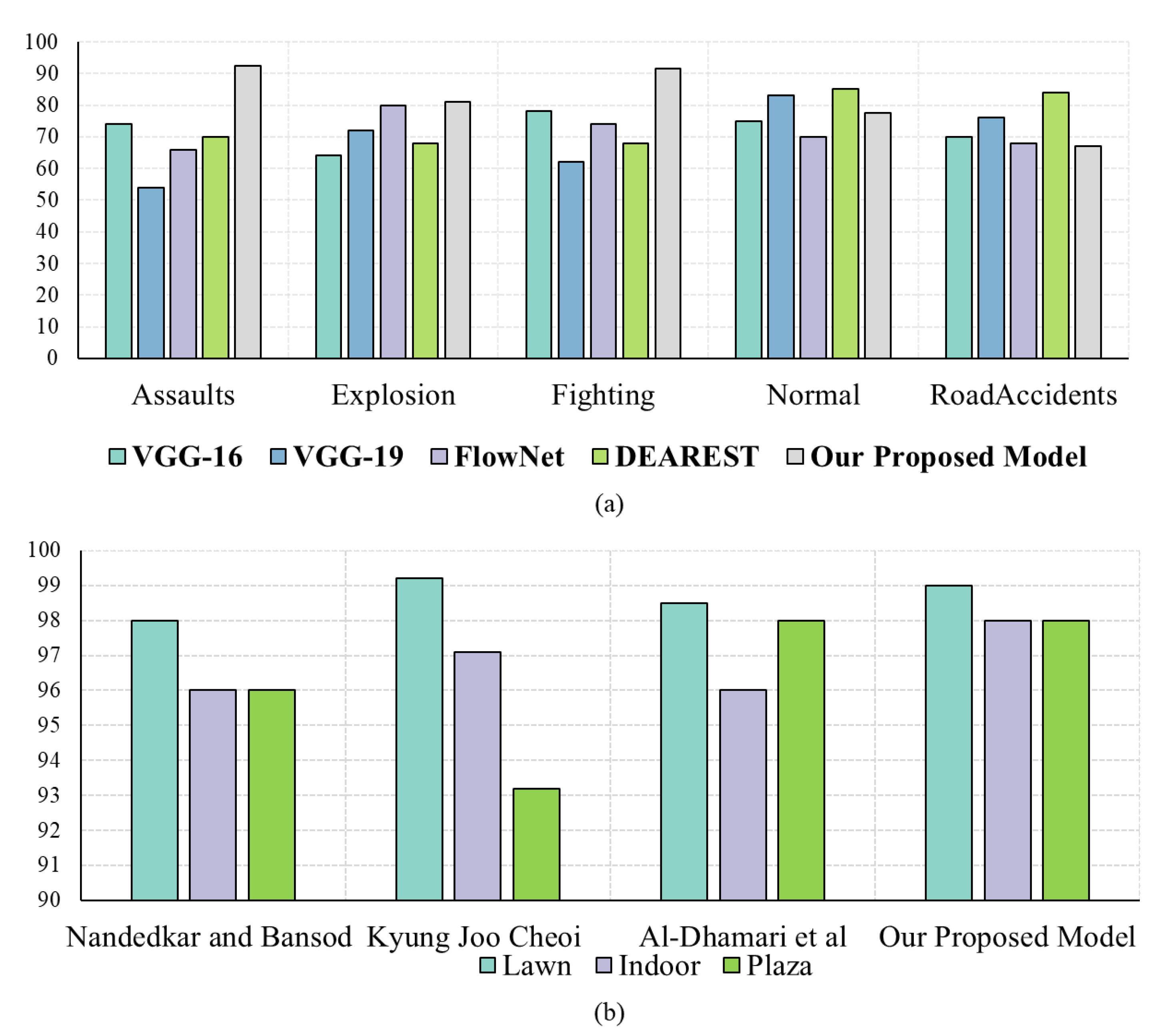
4.4. Comparison with the State-of-the-Art Techniques
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Piza, E.L.; Welsh, B.C.; Farrington, D.P.; Thomas, A.L. CCTV surveillance for crime prevention: A 40-year systematic review with meta-analysis. Criminol. Public Policy 2019, 18, 135–159. [Google Scholar] [CrossRef] [Green Version]
- Suarez, J.J.P.; Naval, P.C., Jr. A Survey on Deep Learning Techniques for Video Anomaly Detection. arXiv 2020, arXiv:2009.14146. [Google Scholar]
- Morais, R.; Le, V.; Tran, T.; Saha, B.; Mansour, M.; Venkatesh, S. Learning regularity in skeleton trajectories for anomaly detection in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 11996–12004. [Google Scholar]
- Dos Santos, F.P.; Ribeiro, L.S.; Ponti, M.A. Generalization of feature embeddings transferred from different video anomaly detection domains. J. Vis. Commun. Image Represent. 2019, 60, 407–416. [Google Scholar] [CrossRef] [Green Version]
- Fan, Y.; Wen, G.; Li, D.; Qiu, S.; Levine, M.D.; Xiao, F. Video anomaly detection and localization via Gaussian mixture fully convolutional variational autoencoder. Comput. Vis. Image Underst. 2020, 195, 102920. [Google Scholar] [CrossRef] [Green Version]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Ionescu, R.T.; Khan, F.S.; Georgescu, M.-I.; Shao, L. Object-centric auto-encoders and dummy anomalies for abnormal event detection in video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7842–7851. [Google Scholar]
- Hinami, R.; Mei, T.; Satoh, S.I. Joint detection and recounting of abnormal events by learning deep generic knowledge. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3619–3627. [Google Scholar]
- Yan, S.; Smith, J.S.; Lu, W.; Zhang, B. Abnormal event detection from videos using a two-stream recurrent variational autoencoder. IEEE Trans. Cogn. Dev. Syst. 2018, 12. [Google Scholar] [CrossRef]
- Zhong, J.-X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1237–1246. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. "Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar]
- Zhu, Y.; Newsam, S. Motion-aware feature for improved video anomaly detection. arXiv 2019, arXiv:1907.10211. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6536–6545. [Google Scholar]
- Sun, J.; Wang, X.; Xiong, N.; Shao, J. Learning sparse representation with variational auto-encoder for anomaly detection. IEEE Access 2018, 6, 33353–33361. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Violence detection using spatiotemporal features with 3D convolutional neural network. Sensors 2019, 19, 2472. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.U.; Haq, I.U.; Rho, S.; Baik, S.W.; Lee, M.Y. Cover the violence: A novel Deep-Learning-Based approach towards violence-detection in movies. Appl. Sci. 2019, 9, 4963. [Google Scholar] [CrossRef] [Green Version]
- Luo, W.; Liu, W.; Gao, S. Remembering history with convolutional lstm for anomaly detection. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo. (ICME), Hong Kong, China, 10–14 July 2017; pp. 439–444. [Google Scholar]
- Luo, W.; Liu, W.; Gao, S. A revisit of sparse coding based anomaly detection in stacked rnn framework. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 341–349. [Google Scholar]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly detection and localization in crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 18–32. [Google Scholar]
- Wu, S.; Moore, B.E.; Shah, M. Chaotic invariants of lagrangian particle trajectories for anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2054–2060. [Google Scholar]
- Tung, F.; Zelek, J.S.; Clausi, D.A. Goal-based trajectory analysis for unusual behaviour detection in intelligent surveillance. Image Vis. Comput. 2011, 29, 230–240. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 428–441. [Google Scholar]
- Zhang, D.; Gatica-Perez, D.; Bengio, S.; McCowan, I. Semi-supervised adapted hmms for unusual event detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 611–618. [Google Scholar]
- Kim, J.; Grauman, K. Observe locally, infer globally: A space-time MRF for detecting abnormal activities with incremental updates. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2921–2928. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 555–560. [Google Scholar] [CrossRef]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar]
- Cong, Y.; Yuan, J.; Liu, J. Sparse reconstruction cost for abnormal event detection. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3449–3456. [Google Scholar]
- Zhao, B.; Fei-Fei, L.; Xing, E.P. Online detection of unusual events in videos via dynamic sparse coding. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3313–3320. [Google Scholar]
- Hussain, T.; Muhammad, K.; Ullah, A.; Del Ser, J.; Gandomi, A.H.; Sajjad, M.; Baik, S.W.; de Albuquerque, V.H.C. Multi-View Summarization and Activity Recognition Meet Edge Computing in IoT Environments. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Ul Haq, I.; Ullah, A.; Muhammad, K.; Lee, M.Y.; Baik, S.W. Personalized movie summarization using deep cnn-assisted facial expression recognition. Complexity 2019, 2019, doi. [Google Scholar] [CrossRef] [Green Version]
- Kwon, S. A CNN-assisted enhanced audio signal processing for speech emotion recognition. Sensors 2020, 20, 183. [Google Scholar]
- Khan, N.; Ullah, F.U.M.; Ullah, A.; Lee, M.Y.; Baik, S.W. Batteries State of Health Estimation via Efficient Neural Networks with Multiple Channel Charging Profiles. IEEE Access 2020. [Google Scholar] [CrossRef]
- Parab, A.; Nikam, A.; Mogaveera, P.; Save, A. A New Approach to Detect Anomalous Behaviour in ATMs. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 774–777. [Google Scholar]
- Ullah, W.; Ullah, A.; Haq, I.U.; Muhammad, K.; Sajjad, M.; Baik, S.W. CNN features with bi-directional LSTM for real-time anomaly detection in surveillance networks. Multimed. Tools Appl. 2020, 1–17. [Google Scholar] [CrossRef]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Sabokrou, M.; Khalooei, M.; Fathy, M.; Adeli, E. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3379–3388. [Google Scholar]
- Zhao, Y.; Deng, B.; Shen, C.; Liu, Y.; Lu, H.; Hua, X.-S. Spatio-temporal autoencoder for video anomaly detection. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1933–1941. [Google Scholar]
- Chang, Y.; Tu, Z.; Xie, W.; Yuan, J. Clustering Driven Deep Autoencoder for Video Anomaly Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 329–345. [Google Scholar]
- Ullah, A.; Muhammad, K.; Haydarov, K.; Haq, I.U.; Lee, M.; Baik, S.W. One-Shot Learning for Surveillance Anomaly Recognition using Siamese 3D CNN. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Babenko, B. Multiple instance learning: Algorithms and applications. View Artic. PubMed NCBI Google Scholar 2018, 1–19. [Google Scholar]
- Tomar, D.; Agarwal, S. Multiple Instance Learning Based on Twin Support Vector Machine. In Advances in Computer and Computational Sciences; Springer: Berlin/Heidelberg, Germany, 2017; pp. 497–507. [Google Scholar]
- Tan, K.; Hou, Z.; Ma, D.; Chen, Y.; Du, Q. Anomaly detection in hyperspectral imagery based on low-rank representation incorporating a spatial constraint. Remote Sens. 2019, 11, 1578. [Google Scholar] [CrossRef] [Green Version]
- He, C.; Shao, J.; Sun, J. An anomaly-introduced learning method for abnormal event detection. Multimed. Tools Appl. 2018, 77, 29573–29588. [Google Scholar] [CrossRef]
- Biradar, K.; Dube, S.; Vipparthi, S.K. DEARESt: Deep Convolutional Aberrant Behavior Detection in Real-world Scenarios. In Proceedings of the 2018 IEEE 13th International Conference on Industrial and Information Systems (ICIIS), Rupnagar, India, 1–2 December 2018; pp. 163–167. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Hartwig, A. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arxiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Kim, J.; El-Khamy, M.; Lee, J. Residual LSTM: Design of a deep recurrent architecture for distant speech recognition. arXiv 2017, arXiv:1701.03360. [Google Scholar]
- Ma, J.; Tang, H.; Zheng, W.-L.; Lu, B.-L. Emotion recognition using multimodal residual LSTM network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 176–183. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Li, X.; Zhou, Z.; Chen, L.; Gao, L. Residual attention-based LSTM for video captioning. World Wide Web 2019, 22, 621–636. [Google Scholar] [CrossRef]
- UCF-Crime Dataset. 12 January 2018. Available online: https://www.crcv.ucf.edu/projects/real-world/, (accessed on 25 February 2021).
- Raghavendra, R.; Bue, A.; Cristani, M. Unusual Crowd Activity Dataset of University of Minnesota; 2006. Available online: http://mha.cs.umn.edu/proj_events.shtml (accessed on 28 February 2021).
- Avenue Dataset for Abnormal Event Detection. 2013. Available online: http://www.cse.cuhk.edu.hk/leojia/projects/detectabnormal/dataset.html (accessed on 25 February 2021).
- Dubey, S.; Boragule, A.; Jeon, M. 3D ResNet with Ranking Loss Function for Abnormal Activity Detection in Videos. In Proceedings of the 2019 International Conference on Control, Automation and Information Sciences (ICCAIS), Chengdu, China, 23–26 October 2019; pp. 1–6. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 2462–2470. [Google Scholar]
- Bansod, S.; Nandedkar, A. Transfer learning for video anomaly detection. J. Intell. Fuzzy Syst. 2019, 36, 1967–1975. [Google Scholar] [CrossRef]
- Al-Dhamari, A.; Sudirman, R.; Mahmood, N.H. Transfer deep learning along with binary support vector machine for abnormal behavior detection. IEEE Access 2020, 8, 61085–61095. [Google Scholar] [CrossRef]
- Cheoi, K.J. Temporal Saliency-Based Suspicious Behavior Pattern Detection. Appl. Sci. 2020, 10, 1020. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Recall (%) | Precision (%) | F1 Score (%) | AUC (%) |
|---|---|---|---|---|---|
| Mobile Net V2 +LSTM | UCF-Crime dataset | 86 | 74 | 77 | 88 |
| Mobile Net V2 +BD-LSTM | 79 | 84 | 76 | 87 | |
| Mobile Net V2 + residual LSTM | 91 | 78 | 82 | 95 | |
| Our Proposed Model | 78 | 87 | 81 | 96 | |
| Mobile Net V2 +LSTM | UMN | 87 | 77 | 81 | 86 |
| Mobile Net V2 +BD-LSTM | 88 | 81 | 84 | 88 | |
| Mobile Net V2 + residual LSTM | 94 | 95 | 94 | 96 | |
| Our Proposed Model | 98 | 98 | 98 | 98 | |
| Mobile Net V2 +LSTM | Avenue | 91 | 93 | 92 | 91 |
| Mobile Net V2 +BD-LSTM | 94 | 95 | 94 | 94 | |
| Mobile Net V2 + residual LSTM | 93 | 94 | 94 | 94 | |
| Our Proposed Model | 98 | 99 | 99 | 98 |
| Model | Time Complexity (Seconds) | Model Size (MB) | Parameters (Millions) | FLOPs (Mega) |
|---|---|---|---|---|
| VGG-16 (2014) [60] | - | 528 | 138 | |
| VGG-19 (2014) [60] | - | 549 | 143 | |
| FlowNet (2017) [61] | - | 638.5 | 162.49 | |
| DEARESt (2018) [47] | - | 1187.5 | 305.49 | |
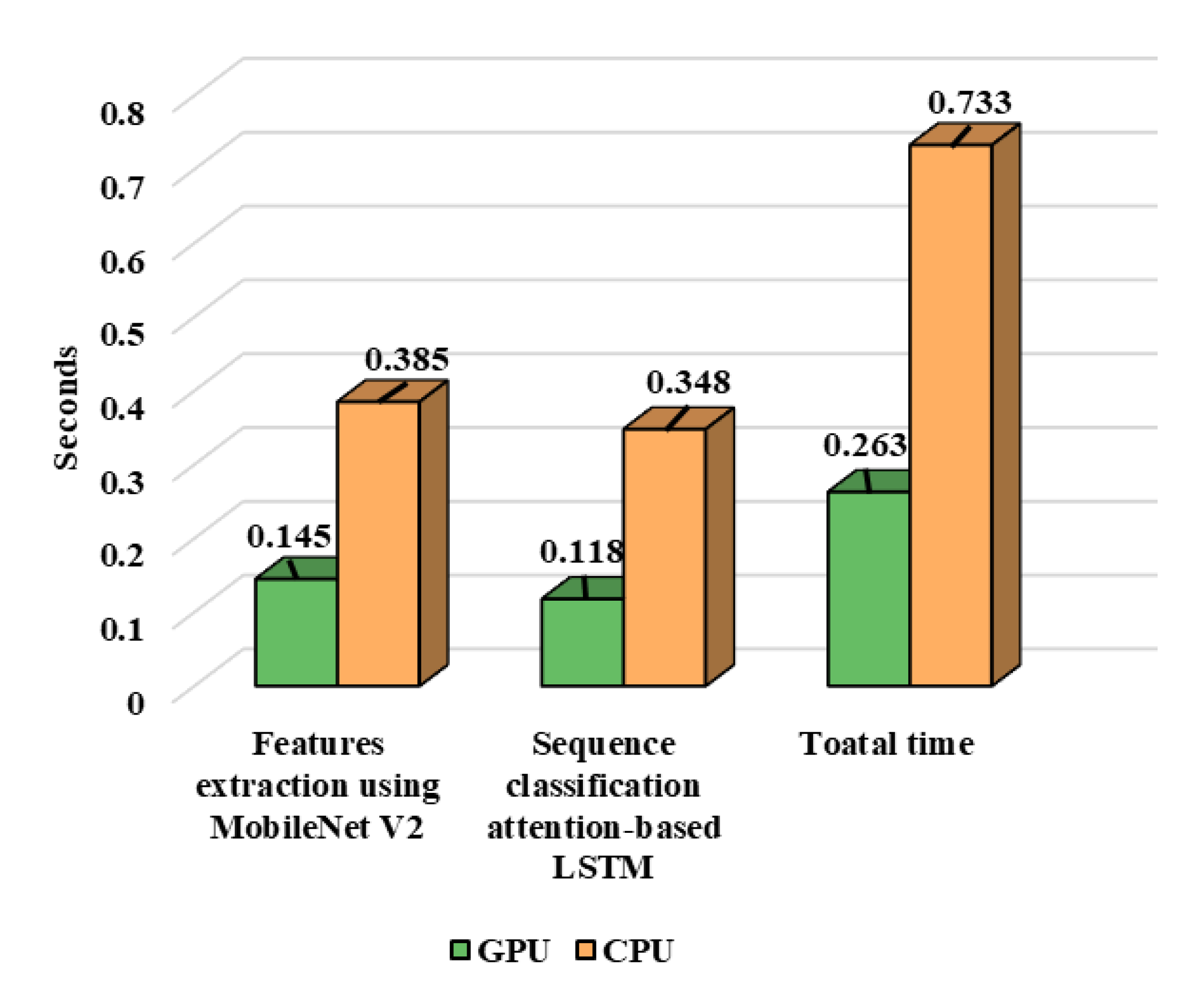
| Our Proposed Model | 0.263 | 12.8 | 3.3 | 618.3 |
| Model | Accuracy (%) | ||
|---|---|---|---|
| UCF-Crime [56] | UMN [57] | Avenue [58] | |
| VGG-16 (2014)[60] | 72.66 | - | - |
| VGG-19 (2014)[60] | 71.66 | - | - |
| FlowNet (2017)[61] | 71.33 | - | - |
| DEARESt (2018)[47] | 76.66 | - | - |
| Nandedkar and Bansod (2019)[62] | - | 96.99 | - |
| Kyung Joo Cheoi (2020)[64] | - | 96.50 | 90.18 |
| Al-Dhamari et al. (2020) [63] | - | 97.44 | - |
| Our Proposed Model | 78.43 | 98.20 | 98.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, W.; Ullah, A.; Hussain, T.; Khan, Z.A.; Baik, S.W. An Efficient Anomaly Recognition Framework Using an Attention Residual LSTM in Surveillance Videos. Sensors 2021, 21, 2811. https://doi.org/10.3390/s21082811
Ullah W, Ullah A, Hussain T, Khan ZA, Baik SW. An Efficient Anomaly Recognition Framework Using an Attention Residual LSTM in Surveillance Videos. Sensors. 2021; 21(8):2811. https://doi.org/10.3390/s21082811
Chicago/Turabian StyleUllah, Waseem, Amin Ullah, Tanveer Hussain, Zulfiqar Ahmad Khan, and Sung Wook Baik. 2021. "An Efficient Anomaly Recognition Framework Using an Attention Residual LSTM in Surveillance Videos" Sensors 21, no. 8: 2811. https://doi.org/10.3390/s21082811
APA StyleUllah, W., Ullah, A., Hussain, T., Khan, Z. A., & Baik, S. W. (2021). An Efficient Anomaly Recognition Framework Using an Attention Residual LSTM in Surveillance Videos. Sensors, 21(8), 2811. https://doi.org/10.3390/s21082811