
FASDQ: Fault-Tolerant Adaptive Scheduling with Dynamic QoS-Awareness in Edge Containers for Delay-Sensitive Tasks

Abstract
:1. Introduction
- For latency-sensitive tasks, we propose a dynamic QoS-aware fault-tolerant task scheduling mechanism, which extends the traditional PB model by introducing different reliability requirements for tasks; i.e., when scheduling task copies, their QoS levels are dynamically adjusted according to their reliability requirements and latency constraints.
- After the primary succeeds, the resources and time interval occupied by the backup are released. In order to make full use of the released resources, the start time of task copies that are waiting in the queue will be reselected to improve resource utilization at the container level.
- To reduce the resource pressure exerted by the PB model at the edge, we propose a container resource-adaptive adjustment mechanism for the resource quota of each edge container, which replenishes resources according to their usage by the assigned task copies, as well as the latency constraints and reliable service requirements of unexecuted task copies.
2. Related Work
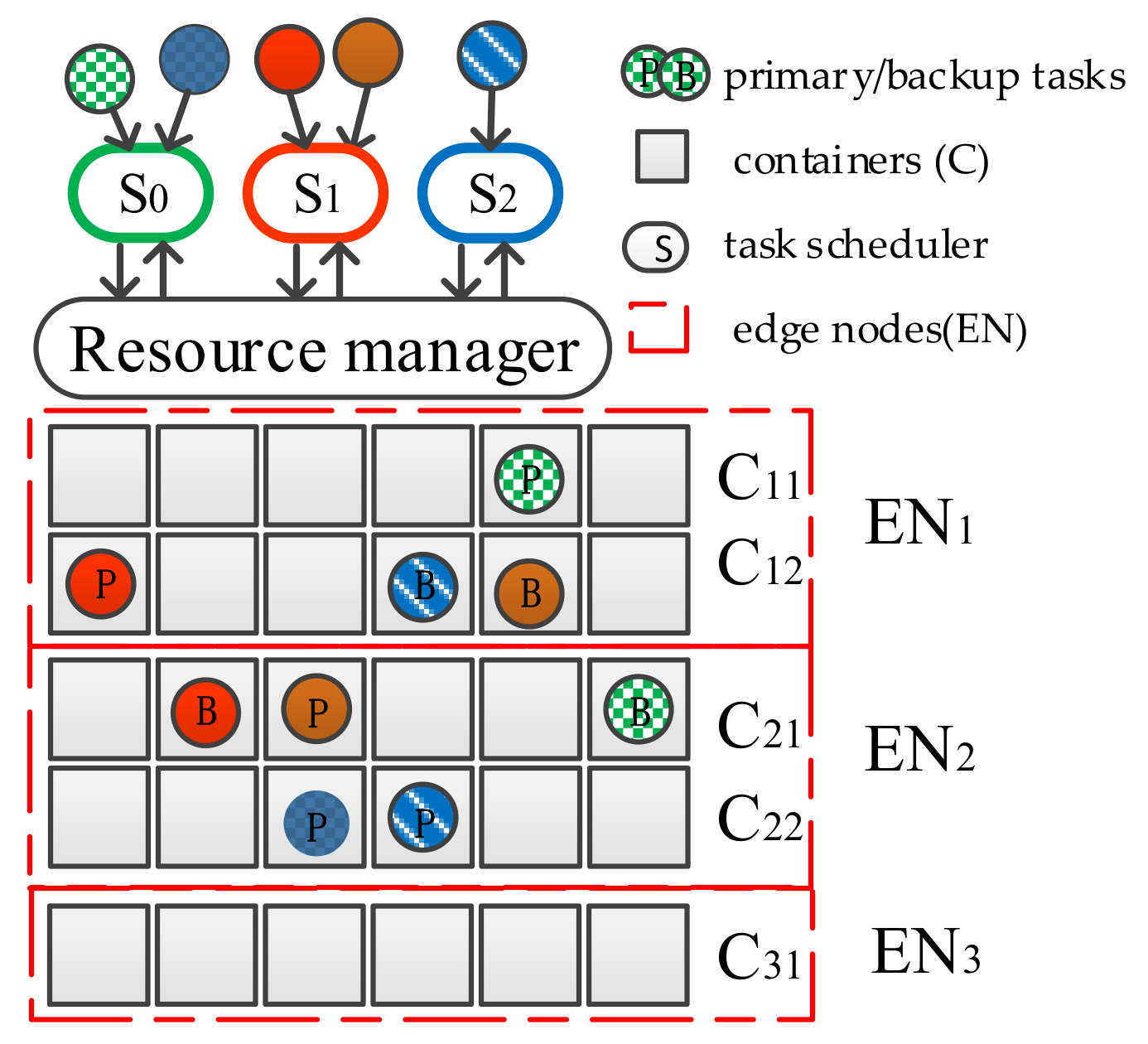
3. Problem Analysis and System Model
3.1. Problem Analysis
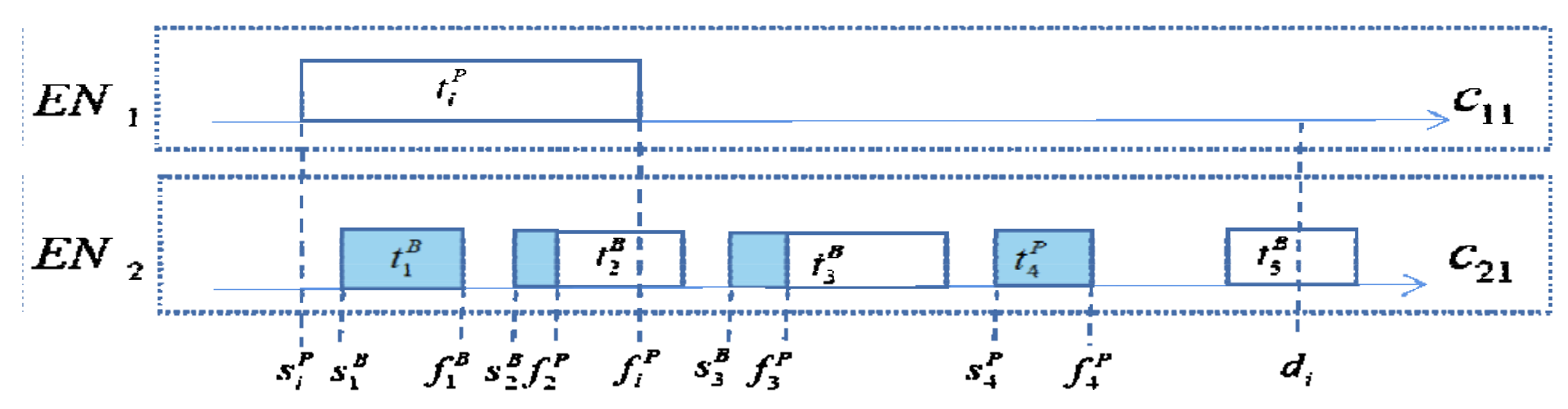
3.2. System Model
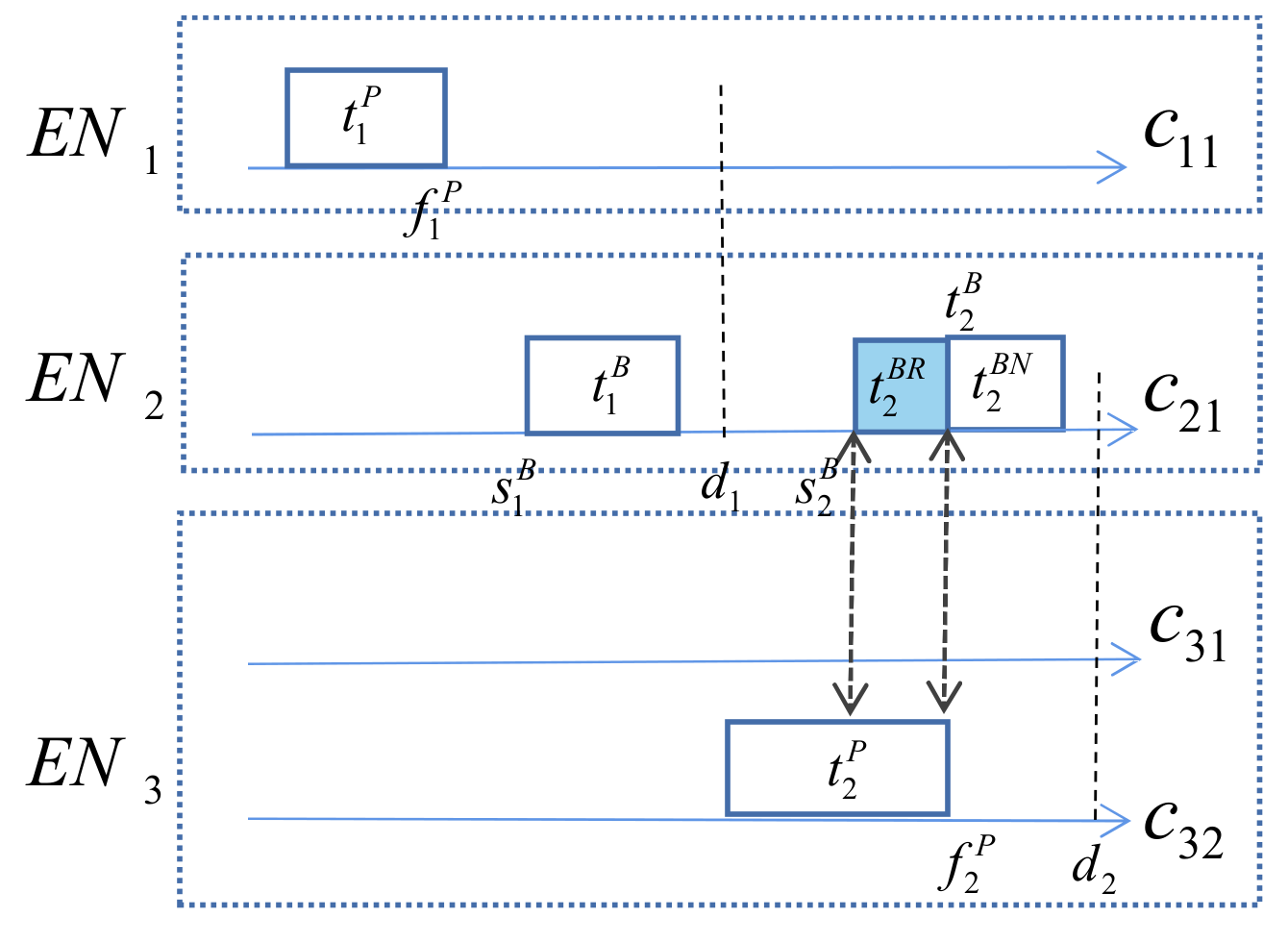
- If succeeds and , then is not executed;
- If succeeds and , then the execution time of is ;
- If fails, then the execution time of is .
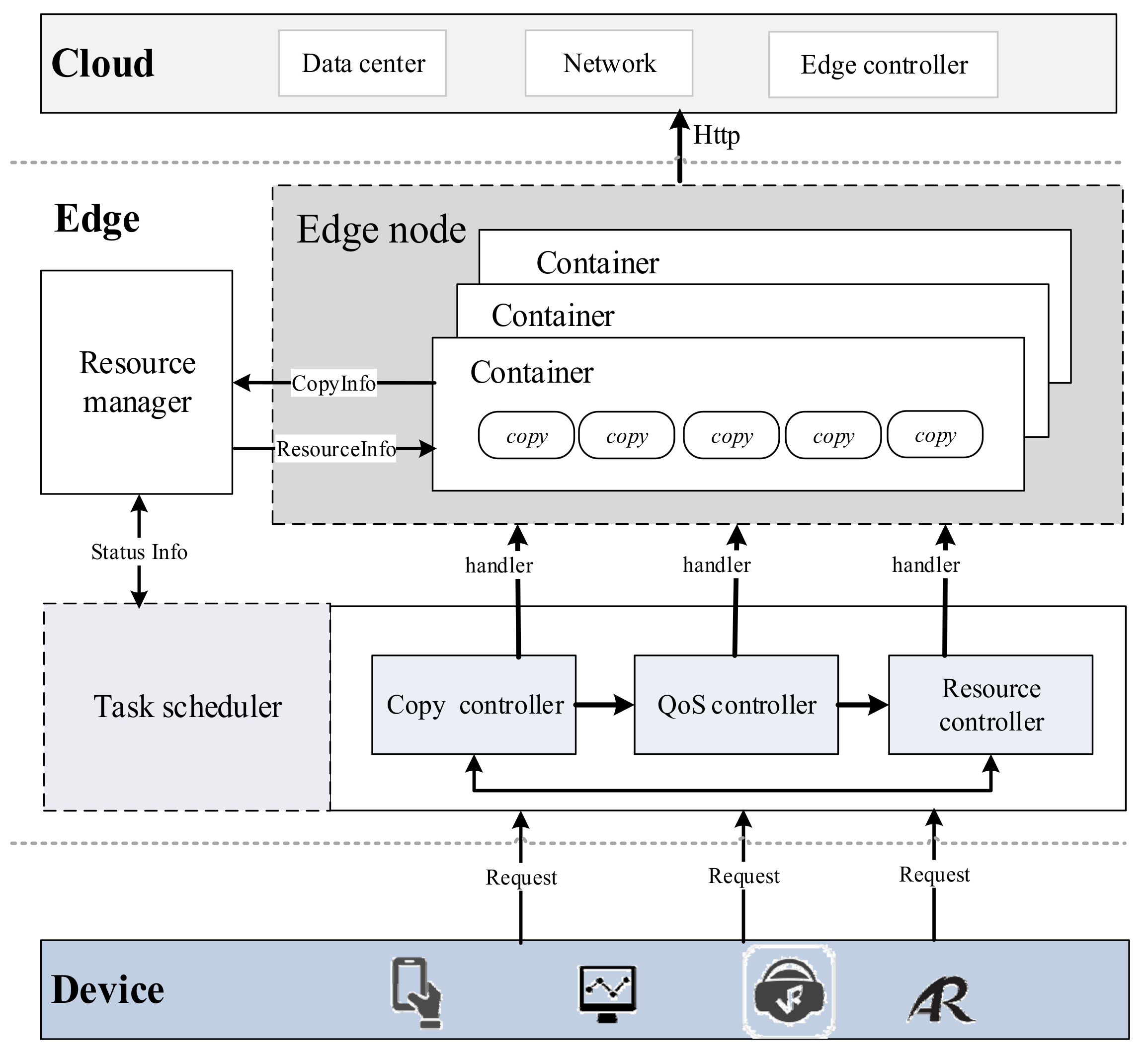
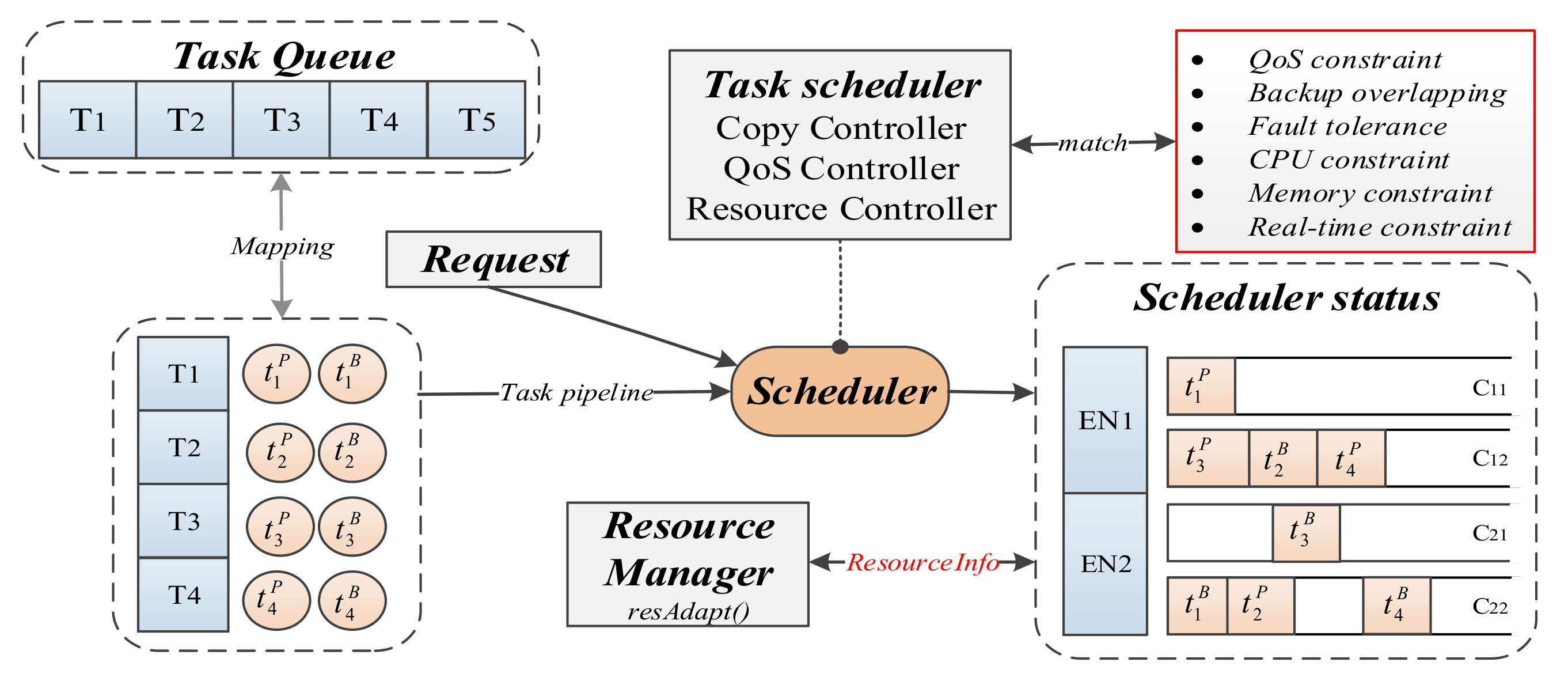
4. Solution: FASDQ Framework and Key Algorithms
4.1. Dynamic QoS-Aware Primary/Backup Scheduling Mechanism
| Algorithm 1. Primary Scheduling in FASDQ | |
| Input: The set of tasks: T; QoS level: ; the set of ENs: . | |
| Output: // The container that can be scheduled for with the earliest start time. | |
| Begin: | |
| 1 | for each new task , do |
| 2 | ;;;; |
| 3 | Sort in descending order of processing capability; |
| 4 | while , do // The QoS level of is initialized to the maximum value within time constraints. |
| 5 | for each , do |
| 6 | Set the processing capability ; |
| 7 | ; |
| 8 | ; |
| 9 | if and , then |
| 10 | //Select the container with the earliest completion time of the primary. |
| 11 | ; ; ; |
| 12 | Calculate the remaining processing capability of and ; |
| 13 | end if |
| 14 | end for |
| 15 | if , then ; // The QoS level is degraded. |
| 16 | end while |
| 17 | if, then //The existing container resources cannot meet the scheduling requirements. |
| 18 | ; |
| 19 | if , then |
| 20 | ; // Create a new container. |
| 21 | return ; |
| 22 | end if |
| 23 | else Reject ; |
| 24 | end for |
| END | |
| Algorithm 2. Backup Scheduling in FASDQ | |
| Input: The set of tasks whose primary copy is successfully assigned to a container, ; ; the neighboring edge nodes of task : . | |
| Output: //After the primary is successfully scheduled in a container, output the container for which the backup is scheduled. | |
| Begin: | |
| 1 | for each backup task , do |
| 2 | ; ; ; ; |
| 3 | Sort in descending order of the remaining processing capability; |
| 4 | while , do //The QoS level of is initialized to the maximum value within time constraints. |
| 5 | for each , do |
| 6 | for each , do |
| 7 | Set the processing capability ; |
| 8 | Calculate using Equation (5); |
| 9 | ; |
| 10 | if and , then |
| 11 | //Select the container for the backup copy with the latest start time. |
| 12 | ; ; ; |
| 13 | Calculate the remaining processing capability of and ; |
| 14 | if , then ; //Mark the backup state. |
| 15 | else ; |
| 16 | end if |
| 17 | end for |
| 18 | end for |
| 19 | if , then ; // The QoS level is degraded. |
| 20 | end while |
| 21 | if , then ; //The existing container resources cannot meet the scheduling requirements. |
| 22 | if , then |
| 23 | ; // Create a new container. |
| 24 | return ; |
| 25 | end if |
| 26 | else reject ; |
| 27 | end for |
| END | |
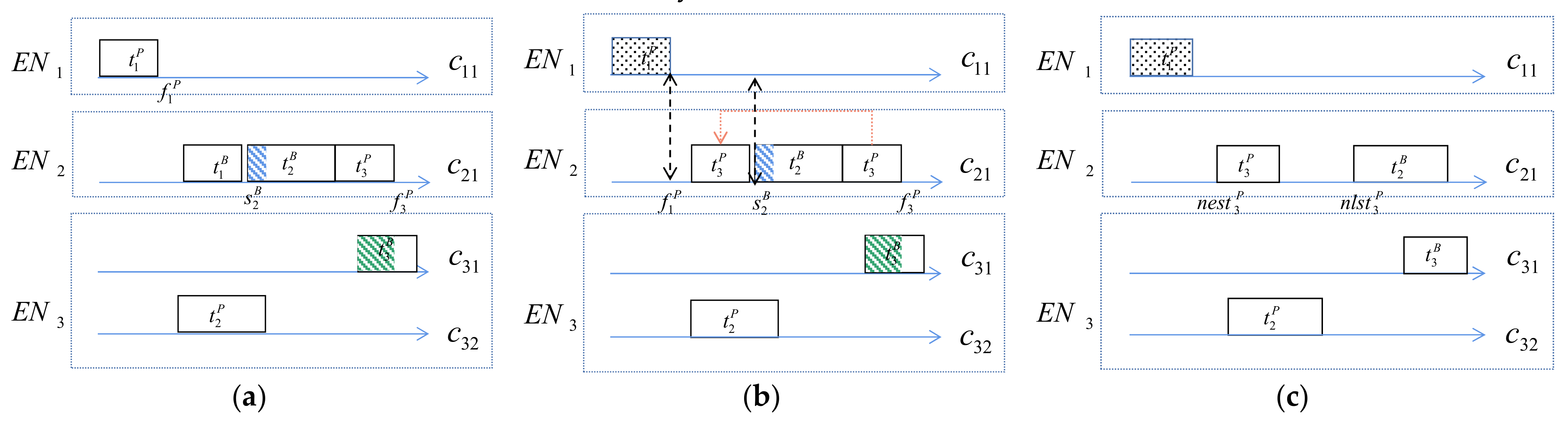
4.2. Container Resource-Adaptive Adjustment Mechanism
- (1)
- cannot be migrated to the edge node of , nor can be migrated to the same edge node of . Otherwise, two copies of the task are in the same edge node and it cannot be fault-tolerant.
- (2)
- If there is overlap between and , cannot be migrated to .
- The set of running edge nodes near the user is sorted in ascending order of remaining processing capability , and these nodes are traversed in turn and judged to be able to create new containers (processing capacity is denoted by ) to accommodate the task copy (lines 1–7). If there is no suitable running node, some containers are migrated to a nearby running node to make space to create a new container (lines 8–11).
- If the creation of containers in the running node still cannot meet the scheduling demand of task copies, an unpowered node near the task copy (processing capacity is indicated by ) starts up, and a new suitable container in this node is created (lines 13–18).
| Algorithm 3. Container resource-adaptive adjustment algorithm | |
| Begin: | |
| 1 | for each, do //Create a new container in the running neighboring node. |
| 2 | Sort active nodes in ascending order by the remaining processing power; |
| 3 | Select a new container satisfying Equation (10); |
| 4 | if , then //Determine whether the remaining processing power of can accommodate the new container. |
| 5 | Create in ; |
| 6 | return ; |
| 7 | else |
| 8 | Migrate in to other nearby nodes with migration constraints; //Migrate the container with the least processing power in the target node to another neighboring node to accommodate the new container. |
| 9 | if can accommodate , then |
| 10 | Create on ; |
| 11 | return ; |
| 12 | end if |
| 13 | end if |
| 14 | end for |
| 15 | for each in nearby nodes, do //Enable a neighboring node in shutdown mode. |
| 16 | If &&, then |
| 17 | Create in ; |
| 18 | return; |
| 19 | else return ; |
| 20 | end for |
| END | |
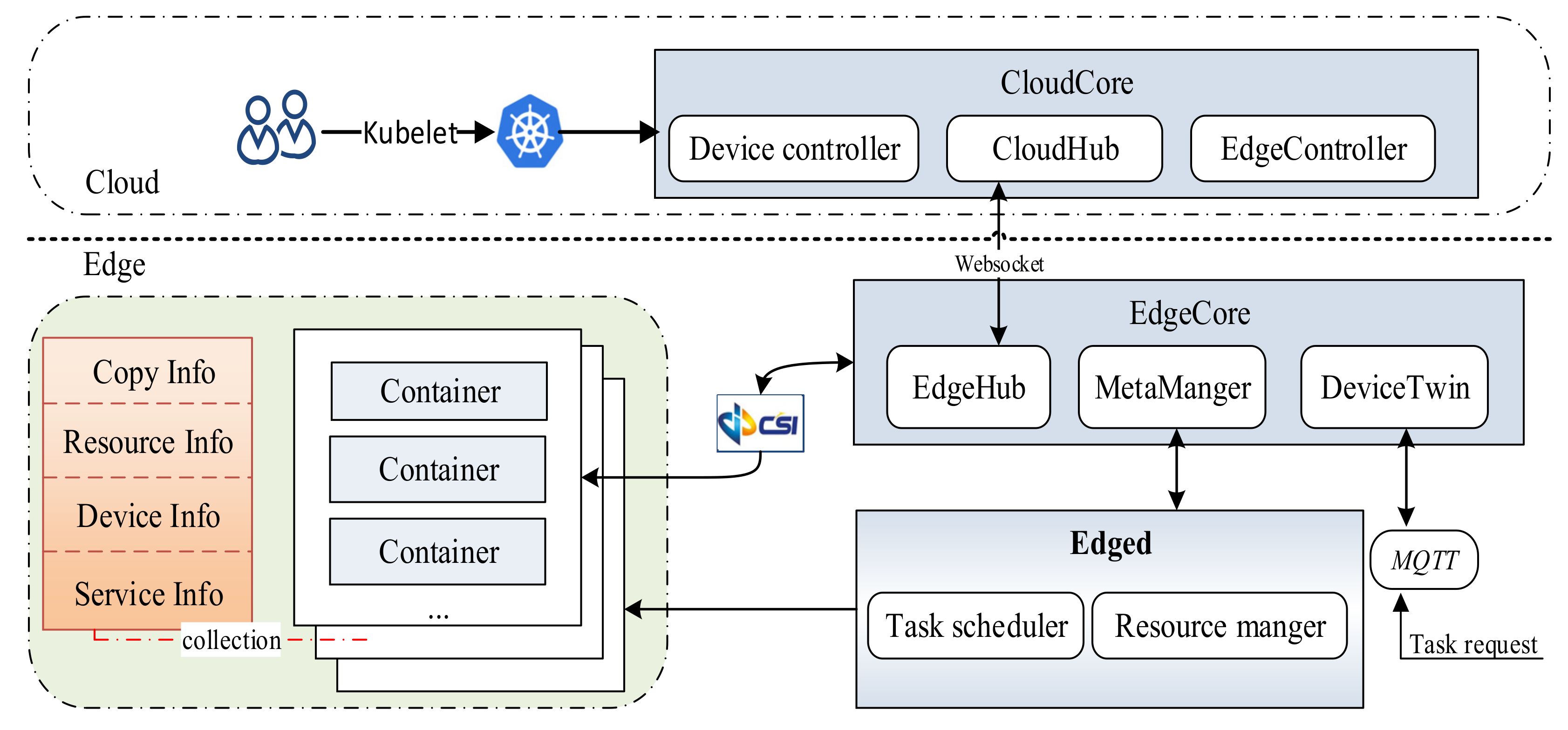
5. Experiments
5.1. Formatting of Mathematical Components
- (1)
- Fault-tolerant elastic scheduling algorithm (FESTAL) [17]: it can be added or removed certain virtual machines depending on the load state to optimize resource utilization while supporting fault tolerance in the cloud. In terms of using virtualization technology, the approach in this paper uses the more lightweight container virtualization technology. This experiment applied FESTAL to the edge side for comparative experiments to verify the effectiveness of FASDQ in terms of latency and resource utilization.
- (2)
- Fault-tolerance based QoS-aware scheduling algorithm (FTBQA)[19]: adjusts the QoS level of tasks and has an adjustment mechanism, which is invoked when the backup copy of a task in a compute node is deleted after the corresponding primary copy succeeds.
- (3)
- Non-Resource Adjustment (NONRAD): a variant of FASDQ that does not use the resource-adaptive adjustment mechanism.
- (4)
- Non-Backup Overlapping (NONBOL): a variant of FASDQ that lacks backup overlapping techniques to verify the impact of backup overlapping techniques on system reliability and QoS levels.
5.2. Analysis of Experimental Results
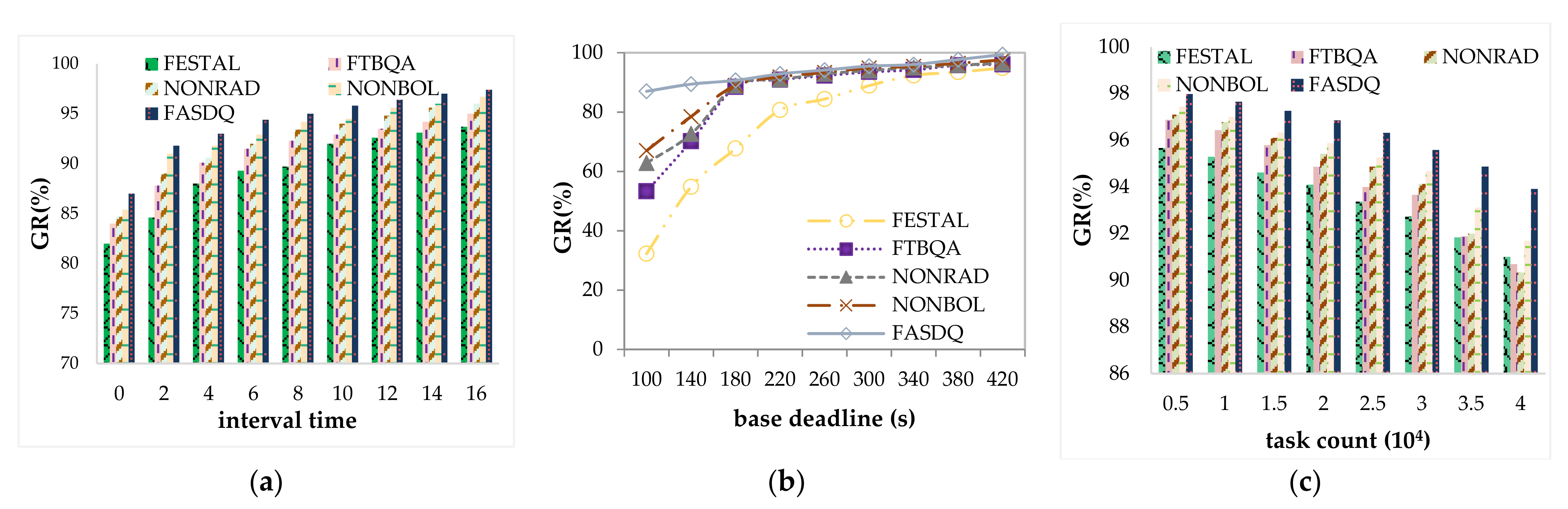
5.2.1. Evaluation of the Effectiveness of Fault-Tolerant Scheduling
- (1)
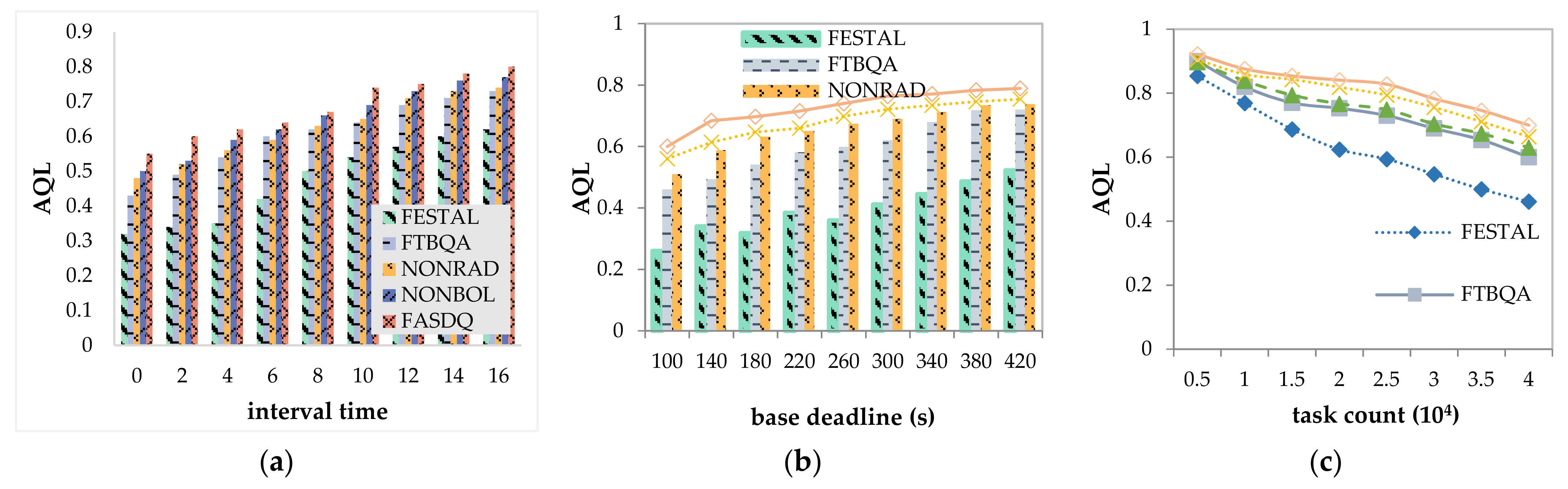
- The task arrival interval value range is from 0 to 16 with a step of 2 s. The value is inversely proportional to the workload per unit time. Other parameters remain unchanged.
- (2)
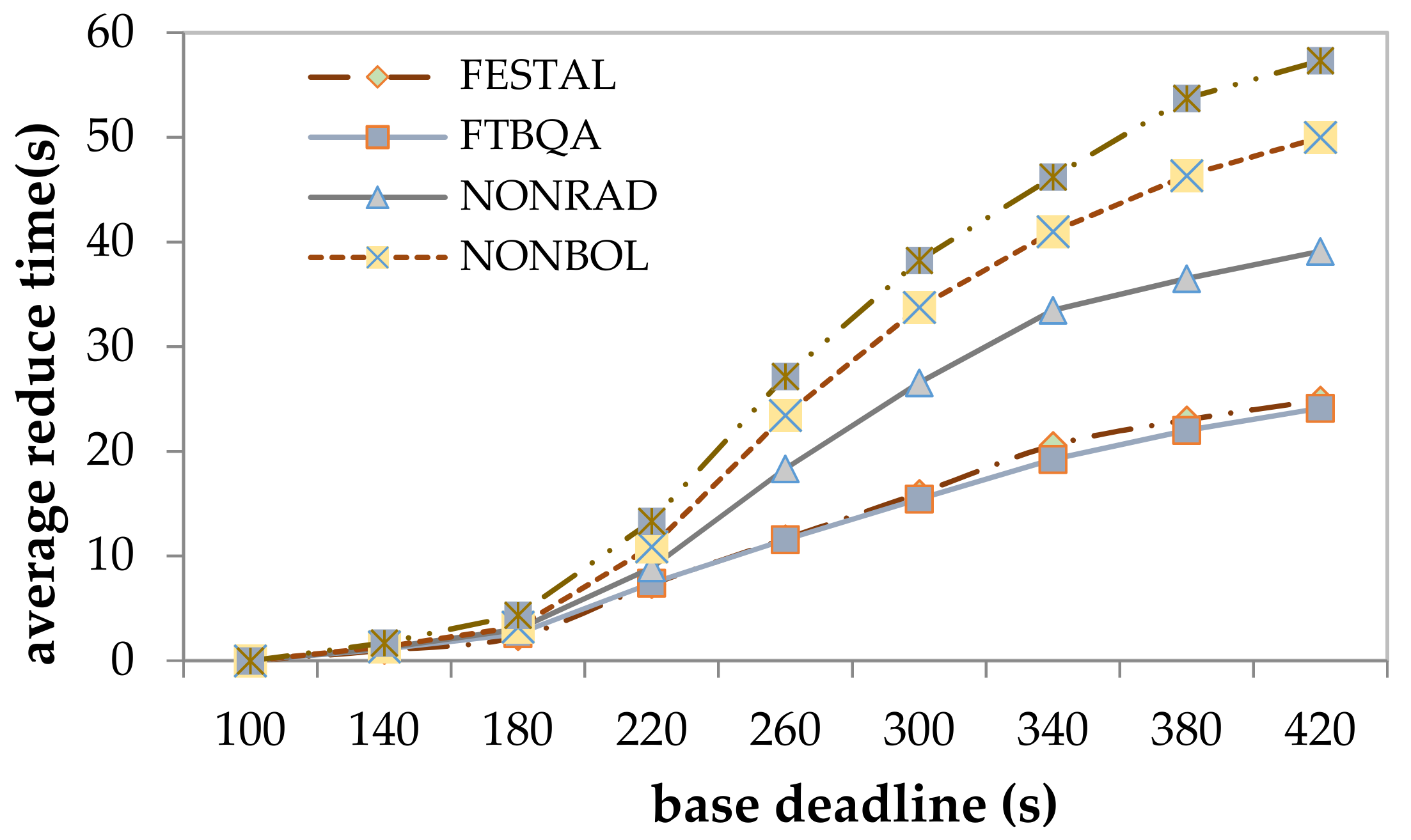
- Base deadline is set from 100 to 420 with a step of 40 s. The higher the value of the base deadline, the more relaxed the task deadline constraint. The other parameters remain unchanged.
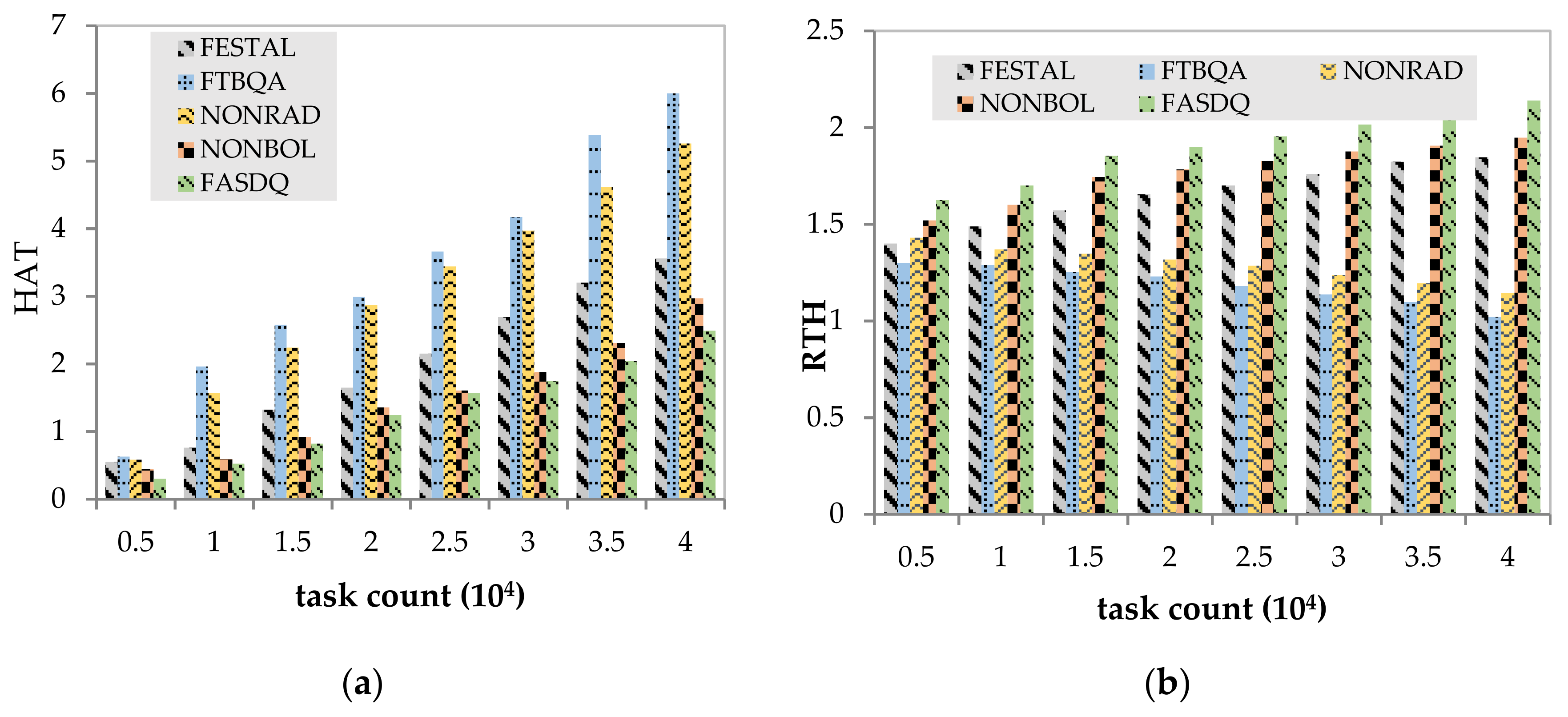
5.2.2. Resource Consumption Evaluation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Yao, G.; Ding, Y.; Hao, K. Using Imbalance Characteristic for Fault-Tolerant Workflow Scheduling in Cloud Systems. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 3671–3683. [Google Scholar] [CrossRef]
- Awada, U.; Zhang, J. Edge Federation: A Dependency-Aware Multi-Task Dispatching and Co-location in Federated Edge Container-Instances. In Proceedings of the 2020 IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 18–20 September 2020; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2020; pp. 91–98. [Google Scholar]
- An In-Depth Analysis of Google’s 5G Mobile Edge Cloud Strategy. Available online: http://www.qianjia.com/html/2020-03/10_362269.html (accessed on 10 March 2020).
- Flynn. Available online: https://flynn.io/ (accessed on 31 January 2018).
- Deis. Available online: https://github.com/deis/deis (accessed on 20 May 2017).
- Edge Container Service. Available online: https://cloud.tencent.com/document/product/457/42876 (accessed on 20 November 2020).
- Introduction to Edge Containers (ACK Edge Kubernetes). Available online: https://developer.aliyun.com/article/703032 (accessed on 20 May 2019).
- Aguilera, X.M.; Otero, C.; Ridley, M.; Elliott, D. Managed Containers: A Framework for Resilient Containerized Mission Critical Systems. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–7 July 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscatawy, NJ, USA, 2018; pp. 946–949. [Google Scholar]
- Ghosh, S.; Melhem, R.; Mosse, D. Fault-tolerance through scheduling of aperiodic tasks in hard real-time multiprocessor systems. IEEE Trans. Parallel Distrib. Syst. 1997, 8, 272–284. [Google Scholar] [CrossRef] [Green Version]
- Ramamurthy, C.; Chellappa, S.; Clark, L.T.; Chandarasekaran, R.; Srivatsan, C. Physical Design Methodologies for Soft Error Mitigation Using Redundancy. In Proceedings of the 2015 15th European Conference on Radiation and Its Effects on Components and Systems (RADECS), Moscow, Russia, 14–18 September 2015; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2015; pp. 1–5. [Google Scholar]
- Zhu, X.; Wang, J.; Qin, X.; Wang, J.; Liu, Z.; Demeulemeester, E. Fault-Tolerant Scheduling for Real-Time Tasks on Multiple Earth-Observation Satellites. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 3012–3026. [Google Scholar] [CrossRef]
- Ding, W.; Guo, R.; Qin, C. A Fault-Tolerant Scheduling Algorithm with Software Fault Tolerance in Hard Real-Time Systems. Comput. Res. Dev. 2011, 48, 691–698. [Google Scholar]
- Liu, J.; Wei, M.; Hu, W.; Xu, X.; Ouyang, A. Task scheduling with fault-tolerance in real-time heterogeneous systems. J. Syst. Arch. 2018, 90, 23–33. [Google Scholar] [CrossRef]
- Guo, Y.; Zhu, D.; Aydin, H.; Han, J.-J.; Yang, L.T. Exploiting primary/backup mechanism for energy efficiency in dependable real-time systems. J. Syst. Arch. 2017, 78, 68–80. [Google Scholar] [CrossRef]
- Al-Omari, R.; Somani, A.K.; Manimaran, G. Efficient overloading techniques for primary-backup scheduling in real-time systems. J. Parallel Distrib. Comput. 2004, 64, 629–648. [Google Scholar] [CrossRef]
- Wang, J.; Bao, W.; Zhu, X.; Yang, L.T.; Xiang, Y. FESTAL: Fault-Tolerant Elastic Scheduling Algorithm for Real-Time Tasks in Virtualized Clouds. IEEE Trans. Comput. 2014, 64, 2545–2558. [Google Scholar] [CrossRef]
- Xing, L.; Tannous, M.; Vokkarane, V.M.; Wang, H.; Guo, J. Reliability Modeling of Mesh Storage Area Networks for Internet of Things. IEEE Internet Things J. 2017, 4, 2047–2057. [Google Scholar] [CrossRef]
- Sun, H.; Yu, H.; Fan, G.; Chen, L. QoS-Aware Task Placement with Fault-Tolerance in the Edge-Cloud. IEEE Access 2020, 8, 77987–78003. [Google Scholar] [CrossRef]
- Balasubramanian, J.; Gokhale, A.; Dubey, A.; Wolf, F.; Lu, C.; Gill, C.; Schmidt, D. Middleware for Resource-Aware Deployment and Configuration of Fault-Tolerant Real-time Systems. In Proceedings of the 2010 16th IEEE Real-Time and Embedded Technology and Applications Symposium, Stockholm, Sweden, 12–15 April 2010; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2010; pp. 69–78. [Google Scholar]
- Grover, J.; Garimella, R.M. Reliable and Fault-Tolerant IoT-Edge Architecture. In Proceedings of the 2018 IEEE Sensors Applications Symposium (SAS), Seoul, Korea, 12–14 March 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Wang, C.; Gill, C.; Lu, C. Adaptive Data Replication in Real-Time Reliable Edge Computing for Internet of Things. In Proceedings of the 2020 IEEE/ACM Fifth International Conference on Internet-of-Things Design and Implementation (IoTDI), Montreal, QC, Canada, 21–24 April 2020; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2020; pp. 128–134. [Google Scholar]
- Wang, C.; Chen, X.; Jia, W. PLOVER: Fast, Multi-core Scalable Virtual Machine Fault-tolerance. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’18), Renton, WA, USA, 9–11 April 2018. [Google Scholar]
- Zhou, D.; Tamir, Y. Fault-Tolerant Containers Using NiLiCon. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), New Orleans, LA, USA, 18–22 May 2020; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2020; pp. 1082–1091. [Google Scholar]
- Mao, Y.; Zhang, J.; Song, S.H.; Letaief, K.B. Stochastic Joint Radio and Computational Resource Management for Multi-User Mobile-Edge Computing Systems. IEEE Trans. Wirel. Commun. 2017, 16, 5994–6009. [Google Scholar] [CrossRef] [Green Version]
- Yin, L.; Luo, J.; Luo, H. Tasks Scheduling and Resource Allocation in Fog Computing Based on Containers for Smart Manufacturing. IEEE Trans. Ind. Inform. 2018, 14, 4712–4721. [Google Scholar] [CrossRef]
- Are You Still Figuring out Cloud-Native? Edge Containers Are Already Here. Available online: https://new.qq.com/omn/20200927/20200927A04VLZ00.html (accessed on 27 September 2019).
- Tsai, M.-Y.; Chiang, P.-F.; Chang, Y.-J.; Wang, W.-J. Heuristic Scheduling Strategies for Linear-Dependent and Independent Jobs on Heterogeneous Grids. In Programmieren für Ingenieure und Naturwissenschaftler; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2011; Volume 261, pp. 496–505. [Google Scholar]
- Wang, W.-J.; Chang, Y.-S.; Lo, W.-T.; Lee, Y.-K. Adaptive scheduling for parallel tasks with QoS satisfaction for hybrid cloud environments. J. Supercomput. 2013, 66, 783–811. [Google Scholar] [CrossRef]
- Guo, P.; Liu, M.; Wu, J.; Xue, Z.; He, X. Energy-Efficient Fault-Tolerant Scheduling Algorithm for Real-Time Tasks in Cloud-Based 5G Networks. IEEE Access 2018, 6, 53671–53683. [Google Scholar] [CrossRef]
- Sonmez, C.; Ozgovde, A.; Ersoy, C. EdgeCloudSim: An environment for performance evaluation of Edge Computing systems. In Proceedings of the 2017 Second International Conference on Fog and Mobile Edge Computing (FMEC), New York, NY, USA, 2–4 October 2020; IEEE: Piscataway, NJ, USA, 2017; pp. 39–44. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.-J. YFCC100M. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Zhou, P.; Wang, K.; Xu, J.; Wu, D.; Wang, K. Differentially-Private and Trustworthy Online Social Multimedia Big Data Retrieval in Edge Computing. IEEE Trans. Multimed. 2018, 21, 539–554. [Google Scholar] [CrossRef]
- Urgaonkar, R.; Wang, S.; He, T.; Zafer, M.; Chan, K.; Leung, K.K. Dynamic service migration and workload scheduling in edge-clouds. Perform. Eval. 2015, 91, 205–228. [Google Scholar] [CrossRef]
- Sarkar, S.; Chatterjee, S.; Misra, S. Assessment of the Suitability of Fog Computing in the Context of Internet of Things. IEEE Trans. Cloud Comput. 2018, 6, 46–59. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, M.; Yang, L.T.; Chen, Z.; Li, P. Energy-Efficient Scheduling for Real-Time Systems Based on Deep Q-Learning Model. IEEE Trans. Sustain. Comput. 2017, 4, 132–141. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters and Symbols | Description |
|---|---|
| , | Edge node i and container j of edge node i. |
| Primary copy and backup copy . | |
| , | Arrival time and deadline of and their units are second. |
| Task size (unit: MI, millions of instructions). | |
| , | Start time and finish time of |
| , | Start time and finish time of |
| , | The earliest start time of and the latest start time of |
| State of | |
| QoS level of | |
| The execution time of and and the unit is second. | |
| , | The processing capability and the remaining processing capability of (unit: MIPS). |
| , | The processing capability and the remaining processing capability of (unit: MIPS). |
| The processing capability provided to with of (unit: MIPS). | |
| Indicates whether succeeds in : if it succeeds, ; otherwise, | |
| AQL | Average QoS level denoting the reliable demand of |
| Indicates whether is assigned to the container successfully. |
| Parameter | (Fixed)-(Min, Max, Step) |
|---|---|
| Task size (×105 MI) | () |
| Task count (×104) | (1)-(0.5, 4, 0.5) |
| Interval time () | (4)-(0, 16, 2) |
| Base deadline (×102 s) | (3)-(1, 4.2, 0.4) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Chen, N.; Yao, X.; Hu, L. FASDQ: Fault-Tolerant Adaptive Scheduling with Dynamic QoS-Awareness in Edge Containers for Delay-Sensitive Tasks. Sensors 2021, 21, 2973. https://doi.org/10.3390/s21092973
Wang R, Chen N, Yao X, Hu L. FASDQ: Fault-Tolerant Adaptive Scheduling with Dynamic QoS-Awareness in Edge Containers for Delay-Sensitive Tasks. Sensors. 2021; 21(9):2973. https://doi.org/10.3390/s21092973
Chicago/Turabian StyleWang, Ruifeng, Ningjiang Chen, Xuyi Yao, and Liangqing Hu. 2021. "FASDQ: Fault-Tolerant Adaptive Scheduling with Dynamic QoS-Awareness in Edge Containers for Delay-Sensitive Tasks" Sensors 21, no. 9: 2973. https://doi.org/10.3390/s21092973
APA StyleWang, R., Chen, N., Yao, X., & Hu, L. (2021). FASDQ: Fault-Tolerant Adaptive Scheduling with Dynamic QoS-Awareness in Edge Containers for Delay-Sensitive Tasks. Sensors, 21(9), 2973. https://doi.org/10.3390/s21092973