
3D MRI Reconstruction Based on 2D Generative Adversarial Network Super-Resolution


Abstract
:1. Introduction
- (1)
- A new noise-based enhanced super-resolution generative adversarial network (nESRGAN) with the addition of noise and interpolated sampling is proposed. The noise part of the network can provide specific high-frequency information and details without affecting the overall feature recovery. Simultaneously, interpolation sampling solves artifacts and color changes caused by the checkerboard effect [21].
- (2)
- Our proposed method is better than the super-resolution method based on 3D neural networks in respect of the reconstruction effect. The high-resolution MRI images can assist doctors in obtaining more detailed brain information, which is of particular significance for diagnosing and predicting brain diseases by using a 1.5 T MRI scanner.
2. Main Method of Reconstruction
2.1. Main Idea and Processes
2.2. MRI Slice Reconstruction Based on RFB-ESRGAN
2.3. MRI Slice Reconstruction Based on nESRGAN
2.4. Related Loss Function
2.5. Image Quality Evaluation Indicators
3. Comparisons and Configuration
3.1. Experimental Configuration
3.1.1. Dataset
3.1.2. Experimental Environment
3.1.3. Experimental Configuration
3.2. Comparison
3.2.1. RFB-ESRGAN
3.2.2. nESRGAN
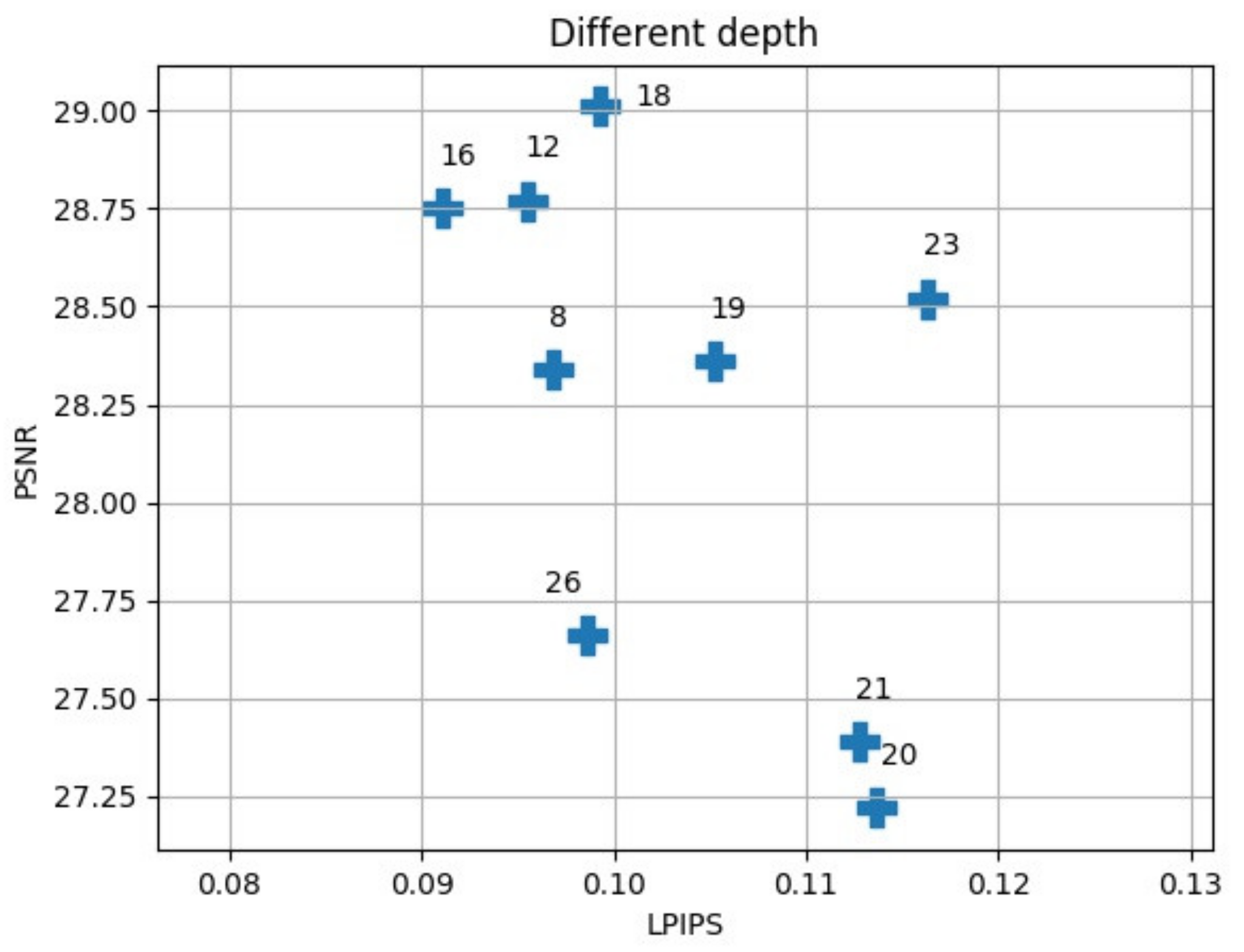
4. Results
4.1. First Super-Resolution Reconstruction
4.2. MRI Reconstruction Comparison
4.3. Comparison of 2D and 3D
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Duyn, J.H. The future of ultra-high field MRI and fMRI for study of the human brain. NeuroImage 2012, 62, 1241–1248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pruessner, J.; Li, L.; Serles, W.; Pruessner, M.; Collins, D.; Kabani, N.; Lupien, S.; Evans, A. Volumetry of Hippocampus and Amygdala with High-resolution MRI and Three-dimensional Analysis Software: Minimizing the Discrepancies between Laboratories. Cereb. Cortex 2000, 10, 433–442. [Google Scholar] [CrossRef] [PubMed]
- Soher, B.J.; Dale, B.M.; Merkle, E.M. A Review of MR Physics: 3T versus 1.5T. Magn. Reson. Imaging Clin. N. Am. 2006, 15, 277–290. [Google Scholar] [CrossRef] [PubMed]
- Willinek, W.A.; Schild, H.H. Clinical advantages of 3.0T MRI over 1.5T. Eur. J. Radiol. 2008, 65, 2–14. [Google Scholar] [CrossRef] [PubMed]
- Greenspan, H.; Oz, G.; Kiryati, N.; Peled, S. MRI inter-slice reconstruction using super-resolution. Magn. Reson. Imaging 2002, 20, 437–446. [Google Scholar] [CrossRef]
- Elad, M.; Feuer, A. Super-resolution reconstruction of image sequences. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 817–834. [Google Scholar] [CrossRef]
- Plenge, E.; Poot, D.H.; Bernsen, M.; Kotek, G.; Houston, G.; Wielopolski, P.; van der Weerd, L.; Niessen, W.J.; Meijering, E. February. Super-resolution reconstruction in MRI: Better images faster? In Medical Imaging 2012: Image Processing; International Society for Optics and Photonics: San Diego, CA, USA, 2012; Volume 8314, p. 83143V. [Google Scholar]
- Plenge, E.; Poot, D.H.J.; Bernsen, M.; Kotek, G.; Houston, G.; Wielopolski, P.; Van Der Weerd, L.; Niessen, W.J.; Meijering, E. Super-resolution methods in MRI: Can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time? Magn. Reson. Med. 2012, 68, 1983–1993. [Google Scholar] [CrossRef] [PubMed]
- Shi, F.; Cheng, J.; Wang, L.; Yap, P.-T.; Shen, D. LRTV: MR Image Super-Resolution with Low-Rank and Total Variation Regularizations. IEEE Trans. Med Imaging 2015, 34, 2459–2466. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.-H.; Liao, Q. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef] [Green Version]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 349–356. [Google Scholar]
- Protter, M.; Elad, M.; Takeda, H.; Milanfar, P. Generalizing the Nonlocal-Means to Super-Resolution Reconstruction. IEEE Trans. Image Process. 2009, 18, 36–51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5892–5900. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Shang, T.; Dai, Q.; Zhu, S.; Yang, T.; Guo, Y. Perceptual extreme super-resolution network with receptive field block. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 14–19 June 2020; pp. 440–441. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Wang, Y.; Teng, Q.; He, X.; Feng, J.; Zhang, T. CT-image of rock samples super resolution using 3D convolutional neural network. Comput. Geosci. 2019, 133, 104314. [Google Scholar] [CrossRef] [Green Version]
- Sánchez, I.; Vilaplana, V. Brain MRI super-resolution using 3D generative adversarial networks. arXiv 2018, arXiv:1812.11440. [Google Scholar]
- Chen, Y.; Xie, Y.; Zhou, Z.; Shi, F.; Christodoulou, A.G.; Li, D. Brain MRI super resolution using 3D deep densely connected neural networks. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 739–742. [Google Scholar]
- Srinivasan, K.; Ankur, A.; Sharma, A. Super-resolution of magnetic resonance images using deep convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taipei, Taiwan, 12–14 June 2017; pp. 41–42. [Google Scholar]
- Lyu, Q.; Chenyu, Y.; Hongming, S.; Ge, W. Super-resolution MRI through deep learning. arXiv 2018, arXiv:1810.06776. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In European Conference on Computer Vision, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Karras, T.; Samuli, L.; Timo, A. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Horé, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Rakotonirina, N.C.; Rasoanaivo, A. ESRGAN+: Further improving enhanced super-resolution generative adversarial network. In Proceedings of the ICASSP 2020—International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3637–3641. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In European Conference on Computer Vision, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Hongtao, Z.; Shinomiya, Y.; Yoshida, S. 3D Brain MRI Reconstruction based on 2D Super-Resolution Technology. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 18–23. [Google Scholar]
- Hwang, J.W.; Lee, H.S. Adaptive Image Interpolation Based on Local Gradient Features. IEEE Signal Process. Lett. 2004, 11, 359–362. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LR | CNN | Deep Network | GAN | |||||
|---|---|---|---|---|---|---|---|---|
| Plane/ Method | Evaluation | Bicubic | SRCNN | FSRCNN | EDSR | SRGAN | ESRGAN | RFB-ESRGAN |
| Sagittal | PSNR ↑ | 25.13 | 14.40 ± 0.22 | 25.77 ± 0.56 | 25.62 ± 0.31 | 26.45 ± 0.64 | 25.37 ± 0.45 | 26.20 ± 0.59 |
| SSIM ↑ | 0.8106 | 0.3196 ± 0.0095 | 0.8337 ± 0.0041 | 0.8963 ± 0.0035 | 0.8959 ± 0.0057 | 0.8856 ± 0.0054 | 0.9201 ± 0.0041 | |
| LPIPS ↓ | 0.1996 | 0.3228 ± 0.0127 | 0.2140 ± 0.0044 | 0.1501 ± 0.0043 | 0.1522 ± 0.0064 | 0.1525 ± 0.0054 | 0.1411 ± 0.0043 | |
| Coronal | PSNR ↑ | 26.95 | 14.10 ± 0.37 | 29.25 ± 0.64 | 27.70 ± 0.80 | 29.16 ± 0.79 | 29.15 ± 0.86 | 29.94 ± 0.83 |
| SSIM ↑ | 0.7491 | 0.4175 ± 0.0516 | 0.7732 ± 0.0124 | 0.9430 ± 0.0047 | 0.9372 ± 0.0067 | 0.9366 ± 0.0049 | 0.9641 ± 0.0032 | |
| LPIPS ↓ | 0.149 | 0.2411± 0.0127 | 0.1884 ± 0.0095 | 0.1006 ± 0.0087 | 0.1077 ± 0.0064 | 0.0807 ± 0.0092 | 0.0750 ± 0.0075 | |
| Axial | PSNR ↑ | 29.19 | 16.46 ± 0.44 | 28.42 ± 1.12 | 28.85 ± 1.09 | 27.69 ± 0.92 | 27.12 ± 0.88 | 30.69 ± 0.83 |
| SSIM ↑ | 0.8115 | 0.3682 ± 0.0301 | 0.8224 ± 0.0452 | 0.9417 ± 0.0056 | 0.9027 ± 0.0157 | 0.9083 ± 0.0089 | 0.9600 ± 0.0031 | |
| LPIPS ↓ | 0.131 | 0.2519 ± 0120 | 0.2035 ± 0.0174 | 0.1005 ± 0.0088 | 0.1148 ± 0.0088 | 0.1104 ± 0.0079 | 0.0839 ± 0.0074 | |
| Depth of Residual in Residual Dense Block | Configuration | Original | ||||
|---|---|---|---|---|---|---|
| Plane/Network | Evaluation | 23 Blocks Noise/Bilinear | 16 Blocks Noise/Bilinear | 23 Blocks Noise | 23 Blocks Bilinear | 23 Blocks |
| sagittal | PSNR↑ SSIM ↑ LPIPS↓ | 26.36 ± 1.01 0.9289 ± 0130 0.1255 ± 0.0138 | 29.63 ± 0.83 0.9478 ± 0.0070 0.0955 ± 0.0124 | 29.58 ± 1.09 0.9441 ± 0.0052 0.1034 ± 0.0083 | 29.83 ± 1.08 0.9450 ± 0.0056 0.1063 ± 0.0077 | 29.28 ± 1.38 0.9452 ± 0.0064 0.1116 ± 0.0080 |
| coronal | PSNR↑ SSIM ↑ LPIPS↓ | 29.42 ± 1.84 0.9353 ± 0.0033 0.0714 ± 0.0054 | 32.12 ± 1.23 0.9728 ± 0.0025 0.0586 ± 0.0056 | 33.36 ± 1.37 0.9510 ± 0.0056 0.0582 ± 0.0047 | 32.17 ± 1.34 0.9584 ± 0.0018 0.0543 ± 0.0044 | 33.18 ± 1.45 0.9596 ± 0.0020 0.0533 ± 0.0048 |
| transverse | PSNR↑ SSIM ↑ LPIPS↓ | 29.16 ± 0.69 0.9222 ± 0.0016 0.0896 ± 0.0055 | 31.33 ± 0.34 0.9626 ± 0.0018 0.0731 ± 0.0040 | 31.32 ± 0.46 0.9406 ± 0.0020 0.0799 ± 0.0040 | 31.04 ± 0.51 0.9435 ± 0.0018 0.0802 ± 0.0039 | 31.17 ± 0.70 0.9438 ± 0.0024 0.0877 ± 0.0052 |
| Plane/Network | Evaluation | Bicubic | 3DSRCNN | 3DSRGAN | Ours |
|---|---|---|---|---|---|
| Sagittal | PSNR ↑ | 25.77 ± 1.32 | 19.93 ± 0.9728 | 23.74 ± 1.13 | 30.28 ± 0.59 |
| SSIM ↑ | 0.8170 ± 0.0191 | 0.7240 ± 0.0346 | 0.7288 ± 0.0145 | 0.9497 ± 0.0020 | |
| LPIPS ↓ | 0.1321 ± 0.0103 | 0.3288 ± 0.0150 | 0.2236 ± 0.0102 | 0.0806 ± 0.0039 | |
| Coronal | PSNR ↑ | 19.44 ± 2.12 | 24.02 ± 0.72 | 24.74 ± 1.34 | 34.25 ± 1.34 |
| SSIM ↑ | 0.6318 ± 0.0315 | 0.8838 ± 0.0183 | 0.6422 ± 0.0287 | 0.9710 ± 0.0022 | |
| LPIPS ↓ | 0.1550 ± 0.0265 | 0.2300 ± 0.0127 | 0.1723 ± 0.0149 | 0.0498 ± 0.0059 | |
| Axial | PSNR ↑ | 23.71 ± 1.69 | 25.08 ± 1.73 | 27.43 ± 1.84 | 30.93 ± 0.90 |
| SSIM ↑ | 0.6901 ± 0.0299 | 0.8634 ± 0.0642 | 0.7065 ± 0.0549 | 0.9596 ± 0.0053 | |
| LPIPS ↓ | 0.1236 ± 0.0233 | 0.2471 ± 0.0234 | 0.1486 ± 0.0272 | 0.0731 ± 0.0121 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Shinomiya, Y.; Yoshida, S. 3D MRI Reconstruction Based on 2D Generative Adversarial Network Super-Resolution. Sensors 2021, 21, 2978. https://doi.org/10.3390/s21092978
Zhang H, Shinomiya Y, Yoshida S. 3D MRI Reconstruction Based on 2D Generative Adversarial Network Super-Resolution. Sensors. 2021; 21(9):2978. https://doi.org/10.3390/s21092978
Chicago/Turabian StyleZhang, Hongtao, Yuki Shinomiya, and Shinichi Yoshida. 2021. "3D MRI Reconstruction Based on 2D Generative Adversarial Network Super-Resolution" Sensors 21, no. 9: 2978. https://doi.org/10.3390/s21092978
APA StyleZhang, H., Shinomiya, Y., & Yoshida, S. (2021). 3D MRI Reconstruction Based on 2D Generative Adversarial Network Super-Resolution. Sensors, 21(9), 2978. https://doi.org/10.3390/s21092978