
Infrequent Pattern Detection for Reliable Network Traffic Analysis Using Robust Evolutionary Computation




Abstract
:1. Introduction
1.1. Research Questions
- How can a feature selection process be applied to the cybersecurity datasets that can select a suitable subset of features and can improve the unsupervised pattern/anomaly detection techniques’ performance?
- –
- How can the unsupervised pattern/anomaly detection techniques be applied to the original dataset and the dataset with fewer features?
- –
- Can the infrequent pattern/anomaly detection techniques perform well on a dataset with feature selection as on the original dataset?
1.2. Paper Roadmap
2. Infrequent Pattern Mining
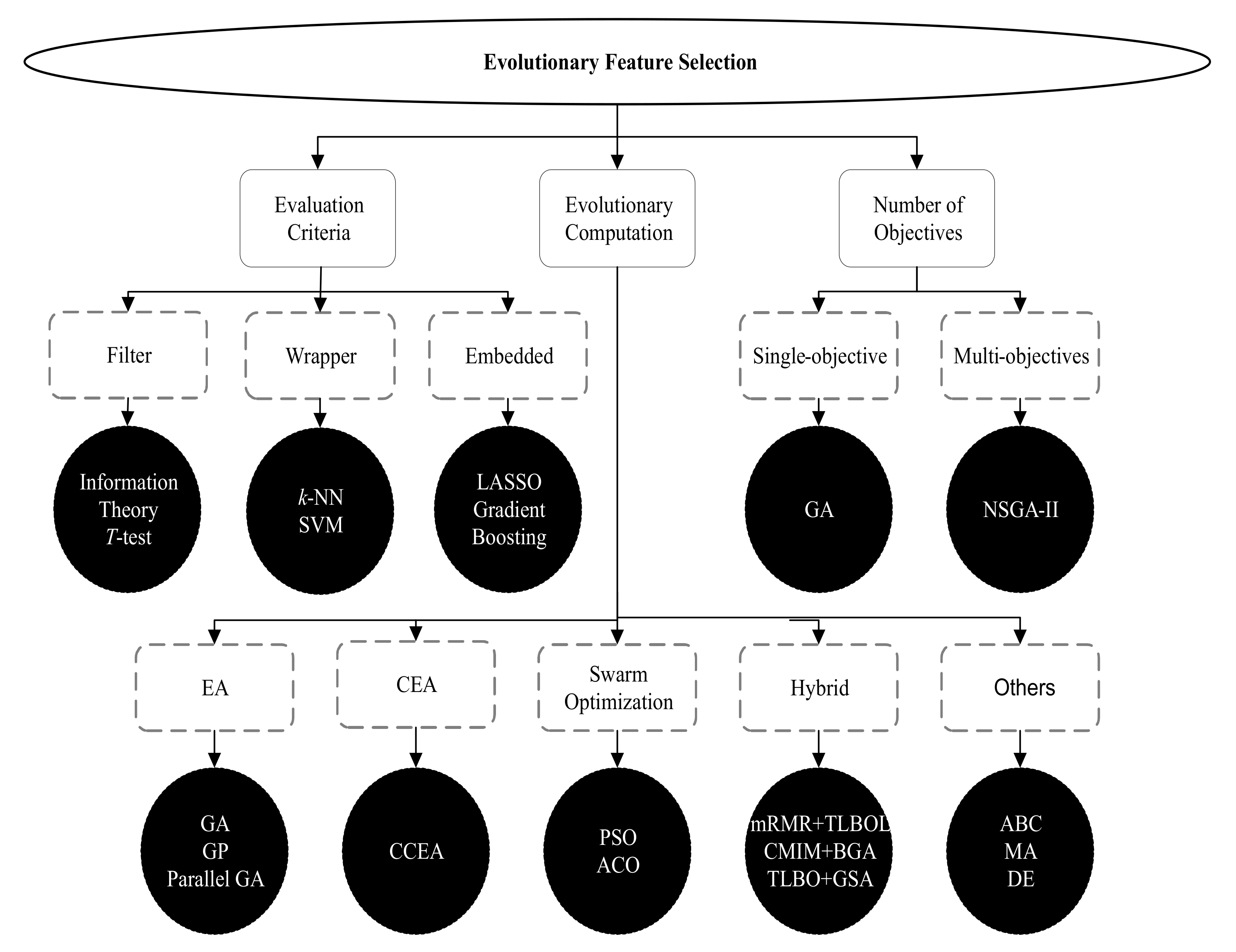
3. Feature Engineering Using Evolutionary Computation
3.1. Cooperative Co-Evolution
3.2. Cooperative Co-Evolution-Based Feature Selection with Random Feature Grouping
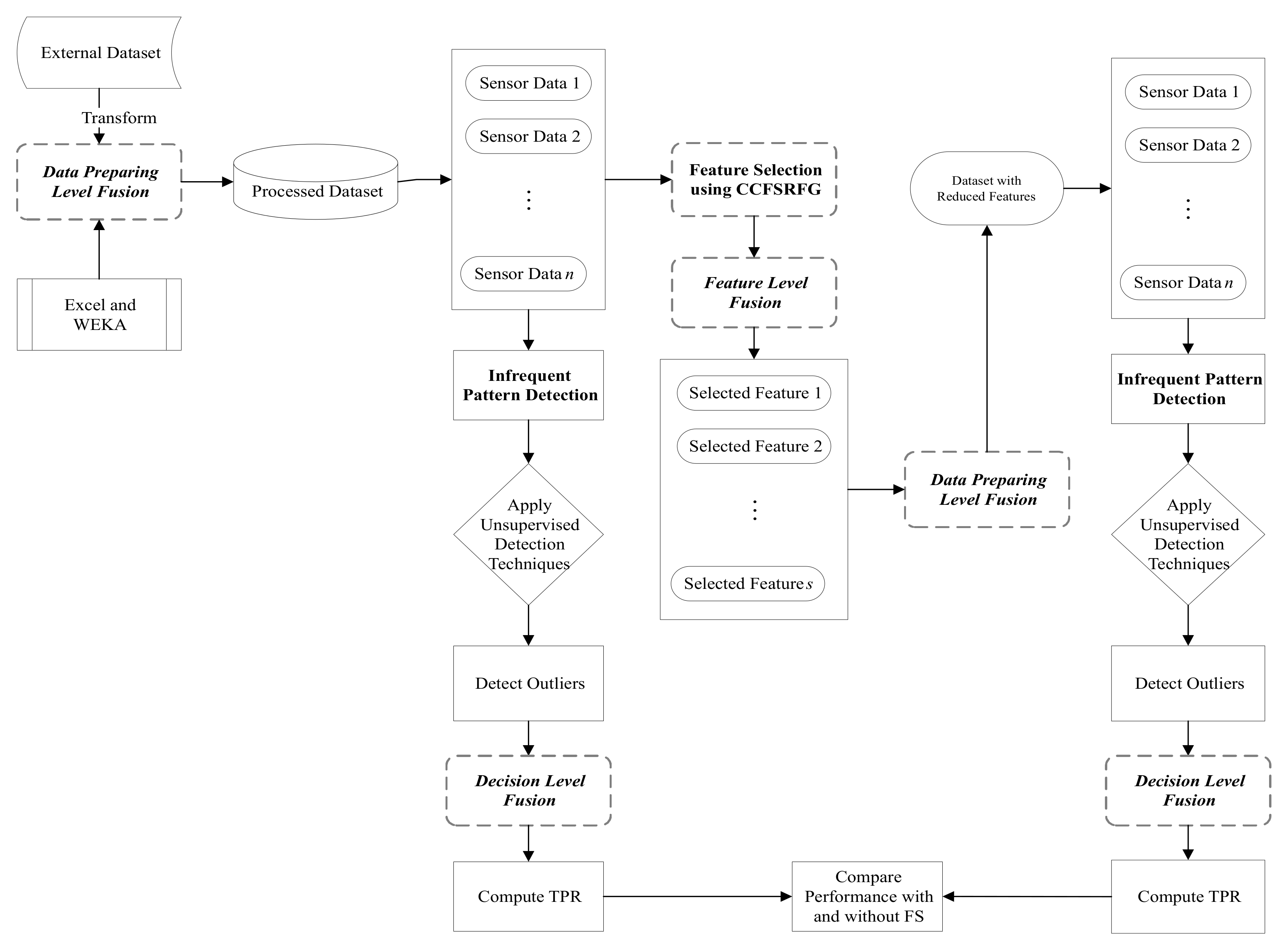
4. Proposed Methodology
| Algorithm 1 UIPD |
| Input: *.CSV formatted dataset files; |
| Output: TPR and ET; |
| 1: Using RapidMiner to compute the anomaly scores; |
| 2: Sort the anomaly scores in descending order; |
| 3: Separate the top instances based on the actual anomalies in the ground truth and store in a CSV file; |
| 4: while Read the CSV files of actual anomalies and anomalies obtained in previous step until end do |
| 5: Split the read lines into columns and store the first column’s values into and ; |
| 6: Increase the value of x by 1; |
| 7: end while |
| 8: Compute the number of anomaly instances from both CSV files and store into and , respectively; |
| 9: Store the value of into array; |
| 10: for to do |
| 11: for to length of do |
| 12: if then |
| 13: Increase the value of by 1; |
| 14: Remove index y from the array; |
| 15: Jump the execution to the inner loop to continue checking with other index values; |
| 16: end if |
| 17: end for |
| 18: end for |
| 19: Assign the size of into ; |
| 20: Compute ; |
| 21: Display TPR and ET. |
5. Experimental Results and Analysis
5.1. Benchmark Dataset
5.2. Parameters and Evaluation Measures
5.3. Results and Discussions
5.4. Meaningful Insights
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rashid, A.N.M.B. Access methods for Big Data: Current status and future directions. EAI Endor. Trans. Scal. Inf. Syst. 2018, 4. [Google Scholar] [CrossRef] [Green Version]
- Rashid, A.N.M.B.; Choudhury, T. Knowledge management overview of feature selection problem in high-dimensional financial data: Cooperative co-evolution and MapReduce perspectives. Probl. Perspect. Manag. 2019, 17, 340. [Google Scholar] [CrossRef] [Green Version]
- Rashid, A.N.M.B.; Choudhury, T. Cooperative co-evolution and MapReduce: A review and new insights for large-scale optimization. Int. J. Inf. Technol. Project Manag. (IJITPM) 2021, 12, 29–62. [Google Scholar] [CrossRef]
- Rashid, A.N.M.B.; Ahmed, M.; Sikos, L.F.; Haskell-Dowland, P. A novel penalty-based wrapper objective function for feature selection in Big Data using cooperative co-evolution. IEEE Access 2020, 8, 150113–150129. [Google Scholar] [CrossRef]
- Ahmed, M.; Anwar, A.; Mahmood, A.N.; Shah, Z.; Maher, M.J. An investigation of performance analysis of anomaly detection techniques for Big Data in scada systems. EAI Endor. Trans. Indust. Netw. Intellig. Syst. 2015, 2, e5. [Google Scholar] [CrossRef] [Green Version]
- Rashid, A.N.M.B.; Ahmed, M.; Sikos, L.F.; Haskell-Dowland, P. Cooperative co-evolution for feature selection in Big Data with random feature grouping. J. Big Data 2020, 7, 1–42. [Google Scholar] [CrossRef]
- Ahmed, M. Intelligent Big Data summarization for rare anomaly detection. IEEE Access 2019, 7, 68669–68677. [Google Scholar] [CrossRef]
- De Juan, A.; Tauler, R. Chapter 8—Data Fusion by Multivariate Curve Resolution. In Data Fusion Methodology and Applications; Data Handling in Science and, Technology; Cocchi, M., Ed.; Elsevier: Amsterdam, The Netherlands, 2019; Volume 31, pp. 205–233. [Google Scholar] [CrossRef]
- Li, N.; Gebraeel, N.; Lei, Y.; Fang, X.; Cai, X.; Yan, T. Remaining useful life prediction based on a multi-sensor data fusion model. Reliabil. Eng. Syst. Saf. 2021, 208, 107249. [Google Scholar] [CrossRef]
- Borah, A.; Nath, B. Rare pattern mining: Challenges and future perspectives. Compl. Intell. Syst. 2019, 5, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Islam, M.R. A survey of anomaly detection techniques in financial domain. Future Gener. Comput. Syst. 2016, 55, 278–288. [Google Scholar] [CrossRef]
- Karie, N.M.; Sahri, N.M.; Haskell-Dowland, P. IoT threat detection advances, challenges and future directions. In Proceedings of the 2020 Workshop on Emerging Technologies for Security in IoT, Sydney, NSW, Australia, 21 April 2020; pp. 22–29. [Google Scholar] [CrossRef]
- Chakraborty, B.; Kawamura, A. A new penalty-based wrapper fitness function for feature subset selection with evolutionary algorithms. J. Inf. Telecommun. 2018, 2, 163–180. [Google Scholar] [CrossRef]
- Potter, M.A.; De Jong, K.A. A cooperative coevolutionary approach to function optimization. In International Conference on Parallel Problem Solving from Nature; Springer: Berlin, Germany, 1994; pp. 249–257. [Google Scholar] [CrossRef] [Green Version]
- Van den Bergh, F.; Engelbrecht, A.P. A cooperative approach to particle swarm optimization. IEEE Trans. Evolut. Comput. 2004, 8, 225–239. [Google Scholar] [CrossRef]
- Shi, M.; Gao, S. Reference sharing: A new collaboration model for cooperative coevolution. J. Heurist. 2017, 23, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Omidvar, M.N.; Li, X.; Mei, Y.; Yao, X. Cooperative co-evolution with differential grouping for large scale optimization. IEEE Trans. Evolut. Comput. 2013, 18, 378–393. [Google Scholar] [CrossRef] [Green Version]
- Potter, M.A. The Design and Analysis of a Computational Model of Cooperative Coevolution. Ph.D. Thesis, George Mason University, Fairfax, VA, USA, 1997. [Google Scholar]
- Yang, Z.; Tang, K.; Yao, X. Large scale evolutionary optimization using cooperative coevolution. Inf. Sci. 2008, 178, 2985–2999. [Google Scholar] [CrossRef] [Green Version]
- Omidvar, M.N.; Yang, M.; Mei, Y.; Li, X.; Yao, X. DG2: A faster and more accurate differential grouping for large-scale black-box optimization. IEEE Trans. Evolut. Comput. 2017, 21, 929–942. [Google Scholar] [CrossRef] [Green Version]
- Storn, R.; Price, K. Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Opt. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Potter, M.A.; Jong, K.A.D. Cooperative coevolution: An architecture for evolving coadapted subcomponents. Evolut. Comput. 2000, 8, 1–29. [Google Scholar] [CrossRef]
- Ambusaidi, M.A.; He, X.; Nanda, P.; Tan, Z. Building an intrusion detection system using a filter-based feature selection algorithm. IEEE Trans. Comput. 2016, 65, 2986–2998. [Google Scholar] [CrossRef] [Green Version]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Cheng, D. Learning k for KNN Classification. ACM Trans. Intell. Syst. Technol. 2017, 8. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Normal (%) | Anomalous (%) | No. of Instances | No. of Features |
|---|---|---|---|---|
| UNSW_NB15 | 44.94 | 55.06 | 82,332 | 42 |
| Anomaly | Weight (%) | Anomalous (%) | No. of Instances |
|---|---|---|---|
| Analysis | 00.82 | 01.49 | 677 |
| Backdoor | 00.71 | 01.29 | 583 |
| DoS | 04.97 | 09.02 | 4,089 |
| Exploits | 13.52 | 24.56 | 11,132 |
| Fuzzers | 07.36 | 13.37 | 6,062 |
| Generic | 22.92 | 41.63 | 18,871 |
| Reconnaissance | 04.25 | 07.71 | 3,496 |
| Shellcode | 00.46 | 00.83 | 378 |
| Worms | 00.05 | 00.10 | 44 |
| Without FS | With FS | ||||
|---|---|---|---|---|---|
| Dataset | Accuracy (%) | No. of Features | Accuracy (%) | No. of Features | Execution Time (hour) |
| UNSW_NB15 | 45.91 | 42 | 72.78 | 3 | 09.72 |
| Infrequent Pattern | With or Without FS | Outlier | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| k-NN | LOF | COF | aLOCI | LoOP | INFLO | CBLOF | LDCOF | CMGOS | HBOS | ||
| Analysis | Ori | 15.51 | 68.83 | 42.98 | 72.38 | 93.94 | 67.65 | 23.63 | 25.11 | 27.92 | 13.88 |
| FS | 76.22 | 40.77 | 62.19 | 26.44 | 56.28 | 79.91 | 100 | 100 | 100 | 08.57 | |
| Backdoor | Ori | 15.44 | 54.72 | 42.54 | 66.55 | 74.27 | 66.38 | 20.58 | 27.79 | 25.56 | 11.84 |
| FS | 79.76 | 50.77 | 60.03 | 40.99 | 61.06 | 63.12 | 100 | 100 | 100 | 10.46 | |
| DoS | Ori | 33.04 | 59.18 | 52.16 | 68.11 | 52.31 | 49.38 | 41.21 | 48.28 | 52.53 | 25.83 |
| FS | 83.10 | 68.87 | 55.91 | 58.38 | 49.79 | 52.09 | 100 | 100 | 100 | 28.78 | |
| Exploits | Ori | 72.83 | 50.93 | 67.58 | 68.03 | 65.11 | 62.95 | 74.24 | 70.76 | 72.87 | 64.46 |
| FS | 86.52 | 72.70 | 57.72 | 41.16 | 46.53 | 44.98 | 91.18 | 91.19 | 98.94 | 71.50 | |
| Fuzzers | Ori | 72.83 | 63.38 | 74.02 | 70.37 | 74.07 | 74.83 | 72.29 | 68.87 | 64.05 | 54.57 |
| FS | 80.30 | 75.42 | 57.34 | 45.61 | 43.29 | 48.19 | 00.00 | 00.00 | 94.37 | 91.96 | |
| Generic | Ori | 04.54 | 53.48 | 51.14 | 36.02 | 51.70 | 51.47 | 09.31 | 09.80 | 07.29 | 42.48 |
| FS | 04.39 | 17.44 | 58.28 | 49.61 | 91.91 | 91.39 | 39.29 | 39.29 | 09.87 | 00.61 | |
| Reconnaissance | Ori | 62.67 | 67.88 | 74.57 | 70.42 | 72.03 | 76.74 | 56.78 | 56.26 | 49.34 | 19.45 |
| FS | 99.31 | 83.70 | 56.64 | 100 | 36.87 | 47.08 | 100 | 100 | 100 | 04.92 | |
| Shellcode | Ori | 79.10 | 71.43 | 84.92 | 71.43 | 80.95 | 80.69 | 67.46 | 62.43 | 42.59 | 12.43 |
| FS | 98.94 | 84.92 | 49.21 | 100 | 34.66 | 29.89 | 100 | 100 | 100 | 32.54 | |
| Worms | Ori | 95.45 | 56.82 | 81.82 | 65.91 | 68.18 | 65.91 | 95.45 | 88.64 | 72.73 | 72.73 |
| FS | 100 | 100 | 00.00 | 100 | 100 | 100 | 100 | 100 | 100 | 86.36 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashid, A.N.M.B.; Ahmed, M.; Pathan, A.-S.K. Infrequent Pattern Detection for Reliable Network Traffic Analysis Using Robust Evolutionary Computation. Sensors 2021, 21, 3005. https://doi.org/10.3390/s21093005
Rashid ANMB, Ahmed M, Pathan A-SK. Infrequent Pattern Detection for Reliable Network Traffic Analysis Using Robust Evolutionary Computation. Sensors. 2021; 21(9):3005. https://doi.org/10.3390/s21093005
Chicago/Turabian StyleRashid, A. N. M. Bazlur, Mohiuddin Ahmed, and Al-Sakib Khan Pathan. 2021. "Infrequent Pattern Detection for Reliable Network Traffic Analysis Using Robust Evolutionary Computation" Sensors 21, no. 9: 3005. https://doi.org/10.3390/s21093005
APA StyleRashid, A. N. M. B., Ahmed, M., & Pathan, A. -S. K. (2021). Infrequent Pattern Detection for Reliable Network Traffic Analysis Using Robust Evolutionary Computation. Sensors, 21(9), 3005. https://doi.org/10.3390/s21093005