1. Introduction
Supervised deep learning enables accurate computer vision models. Key for this success is the access to raw sensor data (i.e., images) with ground truth (GT) for the visual task at hand (e.g., image classification [
1], object detection [
2] and recognition [
3], pixel-wise instance/semantic segmentation [
4,
5], monocular depth estimation [
6], 3D reconstruction [
7], etc.). The supervised training of such computer vision models, which are based on convolutional neural networks (CNNs), is known to required very large amounts of images with GT [
8]. While, until one decade ago, acquiring representative images was not easy for many computer vision applications (e.g., for onboard perception), nowadays, the bottleneck has shifted to the acquisition of the GT. The reason is that this GT is mainly obtained through human labeling, whose difficulty depends on the visual task. In increasing order of labeling time, we see that image classification requires image-level tags, object detection requires object bounding boxes (BBs), instance/semantic segmentation requires pixel-level instance/class silhouettes, and depth GT cannot be manually provided. Therefore, manually collecting such GT is time-consuming and does not scale as we wish. Moreover, this data labeling bottleneck may be intensified due to domain shifts among different image sensors, which could drive to per-sensor data labeling.
To address the curse of labeling, different meta-learning paradigms are being explored. In self-supervised learning (SfSL) the idea is to train the desired models with the help of auxiliary tasks related to the main task. For instance, solving automatically generated jigsaw puzzles helps to obtain more accurate image recognition models [
9], while stereo and structure-from-motion (SfM) principles can provide self-supervision to train monocular depth estimation models [
10]. In active learning (AL) [
11,
12], there is a human—model collaborative loop, where the model proposes data labels, known as pseudo-labels, and the human corrects them so that the model learns from the corrected labels too; thus, aiming at a progressive improvement of the model accuracy. In contrast to AL, semi-supervised learning (SSL) [
13,
14] does not require human intervention. Instead, it is assumed the availability of a small set of off-the-shelf labeled data and a large set of unlabeled data, and both datasets must be used to obtain a more accurate model than if only the labeled data were used. In SfSL, the model trained with the help of the auxiliary tasks is intended to be the final model of interest. In AL and SSL, it is possible to use any model with the only purpose of self-labeling the data, i.e., producing the pseudo-labels, and then use labels and pseudo-labels for training the final model of interest.
In this paper we focus on co-training [
15,
16], a type of SSL algorithm. Co-training self-labels data through the mutual improvement of two models. These models analyze the unlabeled data according to their different views of these data. Our work focuses on onboard vision-based perception for driver assistance and autonomous driving. In this context, vehicle and pedestrian detection are key functionalities. Accordingly, we apply co-training to significantly reduce human intervention when labeling these objects (in computer vision terminology) for training the corresponding deep object detector. Therefore, the labels are BBs locating the mentioned traffic participants in the onboard images. More specifically, we consider two settings. On the one hand, as is usual in SSL, we assume the availability of a small set of human-labeled images (i.e., with BBs for the objects of interests), and a significantly larger set of unlabeled images. On the other hand, we do not assume human labeling at all, but we have a set of virtual-world images with automatically generated BBs.
This paper is the natural continuation of the work presented by Villalonga & López [
17]. In this previous work, a co-training algorithm for deep object detection is presented, addressing the two above-mentioned settings too. In [
17], the two views of an image consist of the original RGB representation and its horizontal mirror; thus, it is a single-modal co-training based on appearance. However, a priori, the higher difference among data views the more accurate pseudo-labels can be expected from co-training. Therefore, as a major novelty of this paper, we explore the use of two image modalities in the role of co-training views. In particular, one view is the appearance (i.e., the original RGB), while the other view is the corresponding depth (D) as estimated by a state-of-the-art monocular depth estimation model [
18]. Thus, we term this approach as multi-modal co-training; however, it can still be considered a single-sensor because still relies only on RGB images.
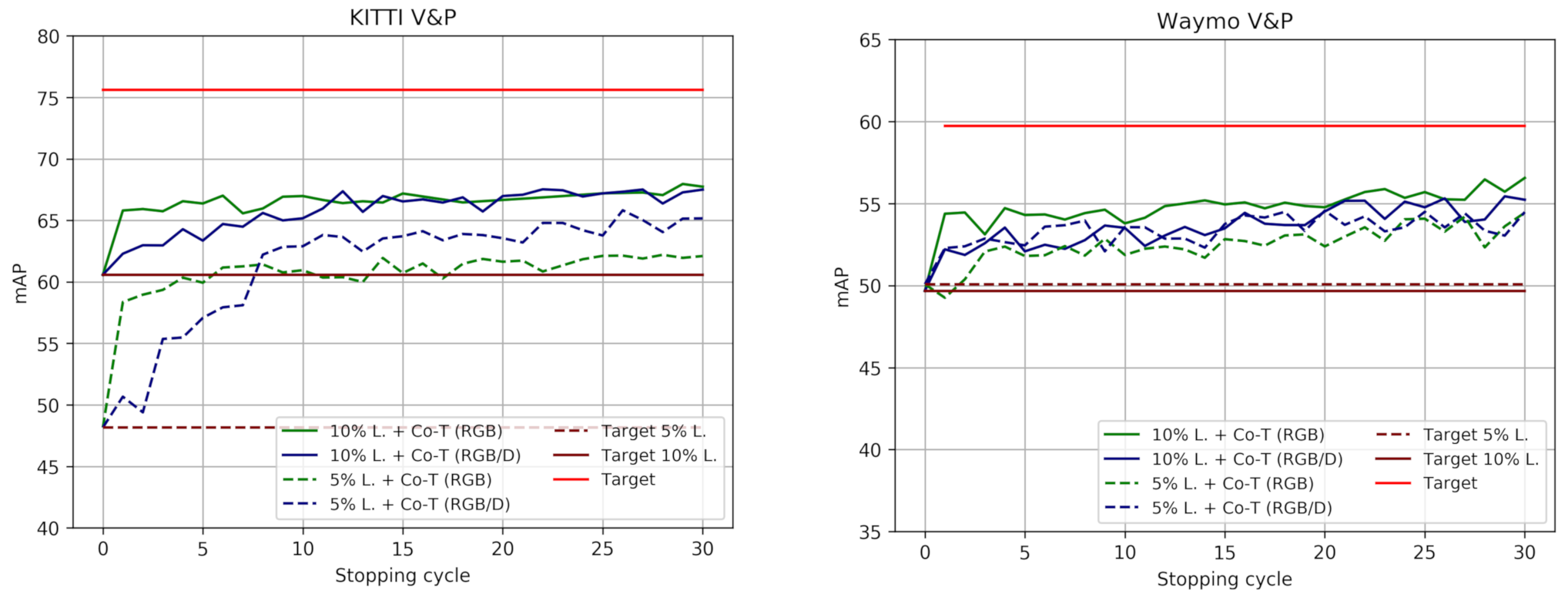
Figure 1 illustrates these different views for images that we use in our experiments.
In this setting, the research questions that we address are two: (Q1) Is multi-modal (RGB/D) co-training effective on the task of providing pseudo-labeled object BBs?; (Q2) How does perform multi-modal (RGB/D) co-training compared to single-modal (RGB)?. After adapting the method presented in [
17] to work with both, the single and the multi-modal data views, we ran a comprehensive set of experiments for answering these two questions. Regarding (Q1), we conclude that, indeed, multi-modal co-training is rather effective. Regarding (Q2), we conclude that in a standard SSL setting (no domain shift, a few human-labeled data) and under virtual-to-real domain shift (many virtual-world labeled data, no human-labeled data) multi-modal co-training outperforms single-modal. In the latter case, when GAN-based virtual-to-real image translation is performed [
19] (i.e., as image-level domain adaptation) both co-training modalities are on par; at least, by using an off-the-shelf monocular depth estimation model not specifically trained on the translated images.
We organize the rest of the paper as follows.
Section 2 reviews related works.
Section 3 draws the co-training algorithm.
Section 4 details our experimental setting, discussing the obtained results in terms of (Q1) and (Q2).
Section 5 summarizes the presented work, suggesting lines of continuation.
2. Related Work
As we have mentioned before, co-training falls in the realm of SSL. Thus, here we summarize previous related works applying SSL methods. The input to these methods consists of a labeled dataset, , and an unlabeled one, , with and , where is the cardinality of the set and refers to the domain from which has been drawn. Note that, when the latter requirement does not hold, we are under a domain shift setting. The goal of a SSL method is to use both and to allow the training of a predictive model, , so that its accuracy is higher than if only is used for its training. In other words, the goal is to leverage unlabeled data.
A classical SSL approach is the so-called self-training, introduced by Yarowsky [
20] in the context of language processing. Self-training is an incremental process that starts by training
on
; then,
runs on
, and its predictions are used to form a pseudo-labeled set
, further used together with
to retrain
. This is repeated until convergence, and the accuracy of
, as well as the quality of
, are supposed to become higher as the cycles progress. Jeong et al. [
21] used self-training for deep object detection (on PASCAL VOC and MS-COCO datasets). To collect
, a consistency loss is added while training
, which is a CNN for object detection in this case, together with a mechanism for removing predominant backgrounds. The consistency loss is based on the idea that
, where
is an unlabeled image, and “
” refers to performing horizontal mirroring. Lokhande et al. [
22] used self-training for deep image classification. In this case, the original activation functions of
, a CNN for image classification, must be changed to Hermite polynomials. Note that these two examples of self-training involve modifications either in the architecture of
[
22] or in its training framework [
21]. However, we aim at using a given
together with its training framework as a black box, so performing SSL only at the data level. In this way, we can always benefit from state-of-the-art models and training frameworks, i.e., avoiding changing the SSL approach if those change. In this way, we can also decouple the model used to produce pseudo-labels from the model that would be trained with them for deploying the application of interest.
A major challenge when using self-training is to avoid drifting to erroneous pseudo-labels. Note that, if
is biased to some erroneous pseudo-labels, when using this set to retrain
incrementally, a point can be reached where
cannot compensate the errors in
, and
may end learning wrong data patterns and so producing more erroneous pseudo-labels. Thus, as alternative to the self-training of Yarowsky [
20], Blum and Mitchell proposed co-training [
15]. Briefly, co-training is based on two models,
and
, each one incrementally trained on different data features, termed as views. In each training cycle,
and
collaborate to form
. Where,
and
are used to retrain
. This is repeated until convergence. It is assumed that each view,
, is discriminant enough as to train an accurate
. Different implementations of co-training, may differ in the collaboration policy. Our approach follows the disagreement idea introduced by Guz et al. [
16] in the context of sentence segmentation, later refined by Tur [
23] to address domain shifts in the context of natural language processing. In short, only pseudo-labels of high confidence for
but of low confidence for
,
, are considered as part of
in each training cycle. Soon, disagreement-based SSL attracted much interest [
24].
In general,
and
can be based on different data views by either training on different data samples (
) or being different models (e.g.,
and
can be based on two different CNN architectures). The disagreement-based co-training falls in the former case. In this line, Qiao et al. [
25] used co-training for deep image classification, where the two different views are achieved by training on mutually adversarial samples. However, this implies linking the training of the
’s at the level of the loss function, while, as we have mentioned before, we want to use these models as black boxes.
The most similar work to this paper is the co-training framework that we introduced in [
17] since we work on top of it. In [
17], two single-modal views are considered. These consist of using
to process the original images from
while using
to process their horizontally mirrored counterparts, and analogously for
. A disagreement-based collaboration is applied to form
and
. Moreover, not only the setting where
is based on human labels is considered, but also when it is based on virtual-world data. In the latter case, a GAN-based virtual-to-real image translation [
19] is used as pre-processing for the virtual-world images, i.e., before taking them for running the co-training procedure. Very recently, Díaz et al. [
26] presented co-training for visual object recognition. In other words, the paper addresses a classification problem, while we address both localization and classification to perform object detection. While the different views proposed in [
26] rely on self-supervision (e.g., forcing image rotations), here, these rely on data multi-modality. In fact, in our previous work [
17], we used mirroring to force different data views, which can be considered as a kind of self-supervision too. Here, after adapting and improving the framework used in [
17], we confront this previous setting to a new multi-modal single-sensor version (Algorithms 1 and
Figure 2). We focus on the case where
works with the original images while
works with their estimated depth. Analyzing this setting is quite interesting because appearance and depth are different views of the same data.
To estimate depth, we need an out-of-the-shelf monocular depth estimation (MDE) model, so that we can keep the co-training as a single-sensor even being multi-modal. MDE can be based on either LiDAR supervision, or stereo/SfM self-supervision, or combinations; where, both LiDAR and stereo data, and SfM computations, are only required at training time, but not at testing time. We refer to [
6] for a review on MDE state-of-the-art. In this paper, to isolate the multi-modal co-training performance assessment as much as possible from the MDE performance, we have chosen the top-performing supervised method proposed by Yin et al. [
18].
Finally, we would like to mention that there are methods in the literature that may be confused with co-training, so it is worth introducing a clarification note. This is the case of the co-teaching proposed by Han et al. [
27] and the co-teaching+ of Yu et al. [
28]. These methods have been applied to deep image classification to handle noisy labels on
. However, citing Han et al. [
27],
co-training is designed for SSL, and co-teaching is for learning with noisy (ground truth) labels (LNL); as LNL is not a special case of SSL, we cannot simply translate co-training from one problem setting to another problem setting.
| Algorithm 1: Self-labeling of object BBs by co-training. |
![Sensors 21 03185 i001]() |
3. Method
In this section, we explain our co-training procedure with the support of
Figure 2 and Algorithms 1. Up to a large extent, we follow the same terminology as in [
17].
Input: The specific sets of labeled (
) and unlabeled (
) input data in Algorithms 1 determine if we are running on either a single or multi-modal setting. Also, if we are supported or not by virtual-world images or their virtual-to-real translated counterparts.
Table 1, clarifies the different co-training settings depending on these datasets. In Algorithms 1, view-paired sets means that each image of one set has a counterpart in the other, i.e., following
Table 1, its horizontal mirror or its estimated depth. Since the co-training is agnostic to the specific object detector in use, we explicitly consider its corresponding CNN architecture,
, and training hyper-parameter,
, as inputs. Finally,
consists of the co-training hyper-parameters, which we will introduce while explaining the part of the algorithm in which each of them is required.
Output: It consists in a set of images (
) from
, for which co-training is providing pseudo-labels, i.e., object BBs in this paper. In our experiments, according to
Table 1,
always corresponds to the unlabeled set of original real-world images. Since we consider as output a set of self-labeled images, which complement the input set of labeled images, they can be later used to train a model based on
or any other CNN architecture performing the same task (i.e., requiring the same type of BBs).
Initialize: First, the initial object detection models () are trained using the respective views of the labeled data (). After their training, these models are applied to the respective views of the unlabeled data (). Detections (i.e., object BBs) with a confidence over a threshold are considered pseudo-labels. Since we address a multi-class problem, per-class thresholds are contained in the set T, a hyper-parameter in . The temporary self-labeled sets generated by and are and , respectively. At this point no collaboration is produced between and . In fact, while co-training loops (repeat body), the self-labeled sets resulting from the collaboration are and , which are initialized as empty. In the training function, , we use BB labels (in ) and BB pseudo-labels (in ) indistinctly. However, we only consider background samples from , since, as co-training progresses, may be instantiated with a set of self-labeled images containing false negatives (i.e., undetected objects) which could be erroneously taken as hard negatives (i.e., background quite similar to objects) when training .
Collaboration: The two object detection models collaborate by exchanging pseudo-labeled images (
Figure 2-right). This exchange is inspired in disagreement-based SSL [
24]. Our specific approach is controlled by the co-training hyper-parameters
, and, in case of working with image sequences instead of with sets of isolated images, also by
. This approach consists of the following three steps.
(First step) Each model selects the set of its top-m most confident self-labeled images (); where, the confidence of an image is defined as the average over the confidences of the pseudo-labels of the image, i.e., in our case, over the object detections. Thus, . However, for creating , we do not consider all the self-labeled images in . Instead, to minimize bias and favor speed, we only consider N randomly selected images from . In the case of working with image sequences, to favor variability in the pseudo-labels, the random choice is constrained to avoid using consecutive frames. This is controlled by thresholds and ; where controls the minimum frame distance between frames selected at the current co-training cycle (k), and among frames at current cycle with respect to frames selected in previous cycles (). We apply first, then , and then the random selection among the frames passing these constraints.
(Second step) Model processes , keeping the set of the n less confident self-labeled images for it. Thus, we obtain the new sets and . Therefore, considering the first and second steps, we see that one model shares with the other those images that it has self-labeled with more confidence, and, of these, each model retains for retraining those that it self-labels with less confidence. Therefore, this step implements the actual collaboration between models and .
(Third step) The self-labeled sets obtained in previous step () are fused with those accumulated from previous co-training cycles (). This is done by properly calling the function for each view. The returned set of self-labeled images, , contains , and, from , only those self-labeled images in are added to .
Retrain and update: At this point we have new sets of self-labeled images (), which, together with the corresponding input labeled sets (), are used to retrain the models and . Afterwards, these new models are used to obtain new temporary self-labeled set () through their application to the corresponding unlabeled sets (). Then, co-training can start a new cycle.
Stop: The function
determines if a new co-training cycle is executed. This is controlled by the co-training hyper-parameters
. Co-training will execute a minimum of
cycles and a maximum of
, being
k the current number. The parameters
and
are supposed to be instantiated with the sets of self-labeled images in previous and current co-training cycles, respectively. The similarity of these sets is monitored in each cycle, so that if its stable for more than
consecutive cycles, convergence is assumed and co-trained stopped. This constrain could already be satisfied at
provided
. The metric used to compute the similarity between these self-labeled sets is mAP (mean average precision) [
29], where
plays the role of GT and
the role of results under evaluation. Then, mAP is considered stable between two consecutive cycles if its magnitude variation is below the threshold
.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}