1. Introduction
With the development of artificial intelligence and automation technology, utilizing video cameras to monitor the health and welfare of pigs has become more important in the modern pig industry. In group-housed environments, instance segmentation of pigs includes detection, which automatically obtains the positions of all pigs, and segmentation, which distinguishes each pig in the images [
1]. Many high-level and intelligent pig farming applications, such as pig weight estimation [
2], pig tracking [
3], and behavior recognition [
4,
5,
6,
7], require accurate detection and segmentation of pig objects in complex backgrounds. The premise and foundation of pig behavior analysis involves the accurate detection and segmentation of group pig images [
8]. Therefore, detecting and segmenting group-housed pigs can help improve the efficiency of instance segmentation, complete high-level applications, and improve the welfare of pigs in pig farms.
Digital image processing combined with pattern recognition studies use automatic detection and segmentation techniques to group-housed pigs [
9]. Pig detection and segmentation methods include two categories based on non-deep learning and deep learning algorithms. These non-deep learning approaches have more mature technologies and have been widely applied in video surveillance of pigs [
1,
10,
11,
12]. Guo et al. [
10] proposed a pig’s foreground detection method based on the combination of a mixture of Gaussians and threshold segmentation. This approach achieved an average pig object detection rate with approximately 92% in complex scenes. Guo et al. [
11] also proposed an effective method for identifying individual group-housed pigs from a feeder and a drinker using a multilevel threshold segmentation. The method achieved a 92.5% average detection rate on test video data. An approach [
5] was proposed to detect mounting events amongst pigs for pig video files. The method used the Euclidean distances of the different parts of pigs to automatically recognize a mounting event. This approach can obtain the results of sensitivity, specificity, and accuracy, with 94.5%, 88.6%, and 92.7%, respectively, for identifying mounting events. The algorithm [
12] for the group-housed pig detection was developed, and it used Gabor and LBP features for feature extraction and classified each pig by SVM. A recognition rate with 91.86% was obtained by this algorithm. Li et al. [
1] combined appearance features and the template matching framework to detect each pig under a group-housed environment. From these related studies, we found that these non-deep learning methods have some disadvantages, and that feature extraction and recognition of the pigs are separated. Meanwhile, feature extractions of these methods obtain features with handed-design features and cannot automatically learn features from the amount of data, which causes these methods to lack robustness.
The studies on pig detection and segmentation methods, based on deep learning models, have increased in recent years, since Girshick et al. [
13] proposed the R-CNN method. These algorithms can automatically extract the pig’s target features in an image and avoid the process of extracting the target features by artificial observation, so the obtained model has strong universality. Faster R-CNN [
14] was used to detect pig targets and classify lactating sow postures, including standing, sitting, sternal recumbency, ventral recumbency, and lateral recumbency, using depth images [
15]. Yang et al. [
16] first used faster R-CNN to detect individual pigs and their heads. Then, a behavior identification algorithm was implemented for feeding behavior recognition from a group-housed pen. Finally, the results of a precision rate with 0.99 and recall rate with 0.8693 can be obtained for feeding behavior recognition of pigs. Xue et al. [
17] proposed an approach based on a fully convolutional network (FCN) [
18] and Otsu’s thresholding to segment the lactating sow images. The approach achieved a 96.6% mean accuracy rate. He et al. [
19] proposed an end-to-end framework named mask R-CNN for object detection and segmentation. The mask R-CNN achieved good results for the challenging instance segmentation dataset COCO [
13], and was used in cattle segmentation [
20]. These recent research results show that pig detection and segmentation approaches, based on deep learning models, were effective and widely used under complex scene environments. However, when pigs are under heavy overlap and adhesion, pig instance segmentation methods, based on non-deep learning and deep learning algorithms, have some difficulty accurately detecting individual pigs with a low miss rate.
Segmenting the adhesive pig images is important to the next extraction of pig herd behavioral characteristic parameters. The adhesion segmentation methods mainly include ellipse fitting, watershed transformation, and concave point analysis. In [
4,
9], the least square method was used to conduct ellipse fitting for pigs, and then it separated the adhered pig bodies according to the length of the major and minor axis, and the position of the center point, but this method did not evaluate the performance of the ellipse fitting method when several pigs adhered. Xiong et al. [
21] divided piglet adhesion into four cases, as follows: no adhesion, slight, mild, and severe adhesion. Firstly, the contour line of the adhered part was extracted. Then, the contour line, according to the concave point, was segmented. The ellipse fitting for the contour lines was carried out after segmentation. Finally, five ellipse-screening rules were developed. The ellipses, which did not comply with the rules, were integrated. The recognition accuracy of this method for pigs was over 86%. A Kinect-based segmentation of touching-pigs was used for segmentation of touching-pigs, by applying YOLO and CPs [
8], and this method was effective at separating touching-pigs with an accuracy of 91.96%. Mask scoring R-CNN (MS R-CNN) [
22] was explored for instance segmentation of standing posture images of group-housed pigs, from the top view and front view pig video sequences, which achieved a best F1 score with 0.9405 on pig test datasets in our previous work [
23]. However, severe adhesion was not analyzed, but is further researched in these studies.
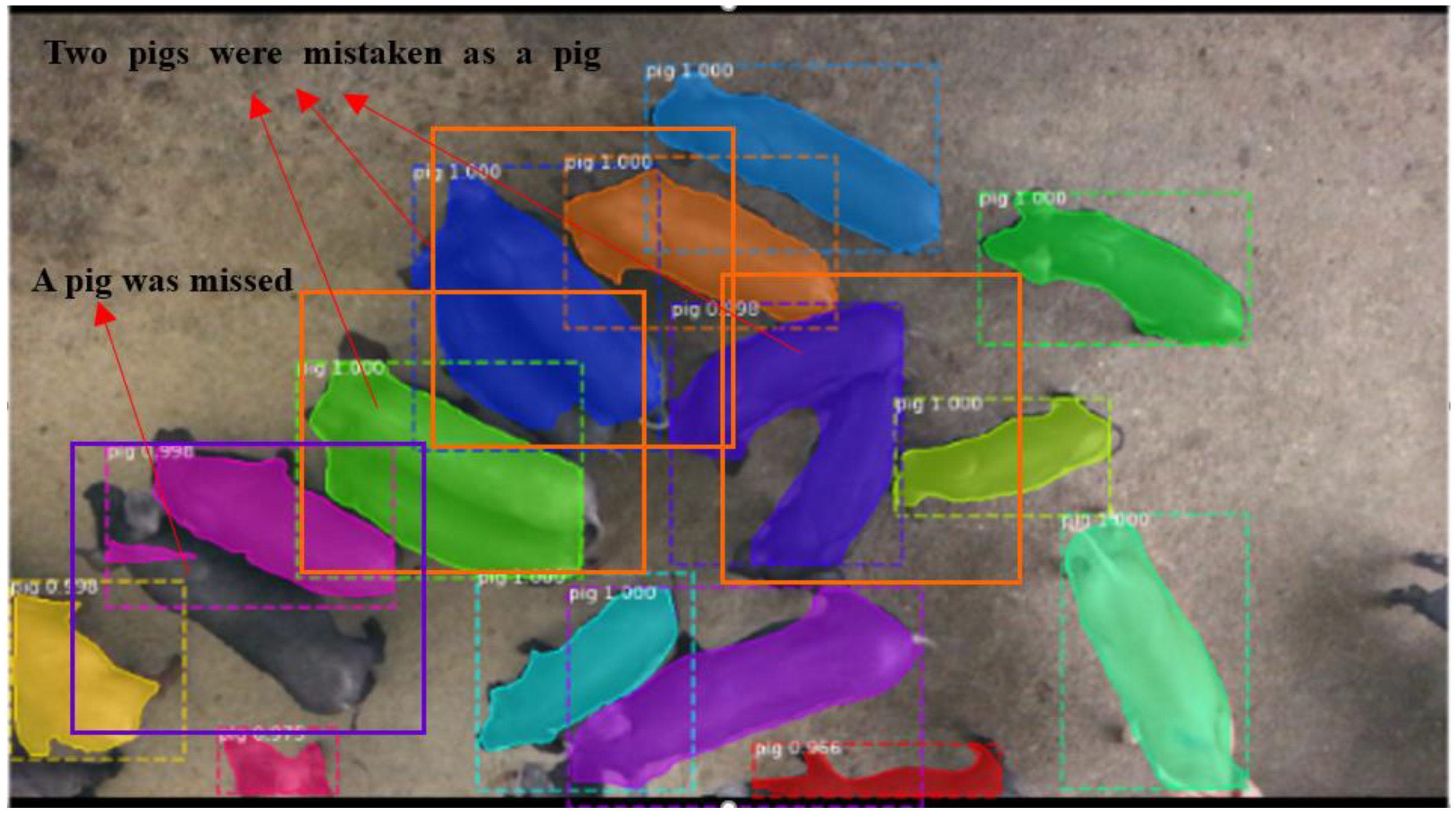
Although these works have been performed effectively on pig detection and segmentation, most approaches are designed under fewer pigs/one pig environments or top view images; it is difficult for these algorithms to detect each pig in a group-housed condition when the pigs are closely grouped. Based on the previous work of our team [
23], we propose a PigMS R-CNN model, which can efficiently obtain the instance segmentation mask for each pig, while simultaneously decrease the faulty detection results for group-housed pigs. To reduce the missed rate of pigs in group-housed environments, soft-NMS [
24] was used in the PigMS R-CNN model. The algorithm gains improvements in precision measured over multiple overlap thresholds, which are especially suitable for group-housed pig detection. The PigMS R-CNN model, combining the MS R-CNN and soft-NMS network, is simple to implement and does not need extra resources. We can easily use the improved approach for a pig instance segmentation application.
3. The Proposed Approach
3.1. The PigMS R-CNN Model
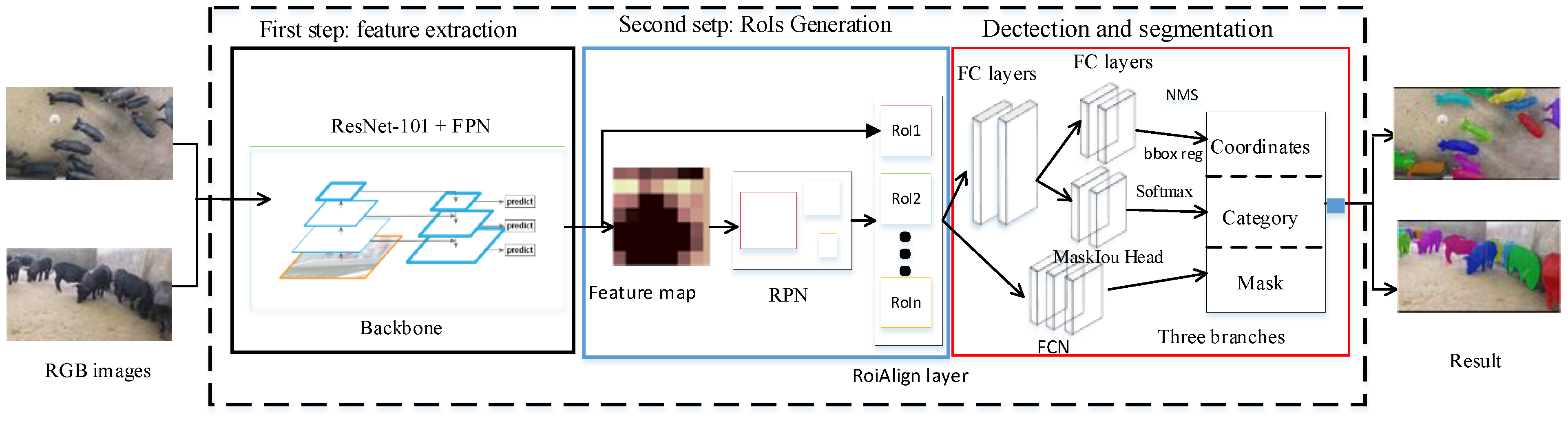
The PigMS R-CNN model (as shown in
Figure 2) based on MS R-CNN [
22] included three stages. In the first stage, a residual network of 101 (or 50) layers, combining the feature pyramid network (FPN), was used as a feature extraction network to obtain feature maps for input images. FPN can obtain different levels of the feature maps according to three scales. In the second stage, the region proposal network (RPN) extracted the regions of interest (RoIs), according to the feature maps. In the third stage, for each RoI, we can get the location, classification, and segmentation results of detected pig targets in the group-housed scenes through the category, and regression, and mask three branches in the PigMS R-CNN head network. In the segmentation branch, the Maskiou head in FCN was used to regress between the predicted mask and the true ground mask to improve the segmentation accuracy.
In addition, the third stage extracted features using RoIAlign from each candidate RoI, and performed BB regression, classification with softmax, and a binary mask prediction for each potentially detected pig by FCN. During the process of BB regression, NMS was applied to these potentially detected pigs to remove highly overlapping BB and obtain the ultimate locations of the pigs. The steps are detailed in the following sections.
3.2. The Feature Extraction
The feature extraction uses backbone architecture to extract different levels of features over an entire image. The backbone architecture includes two parts, named ResNet [
25] and FPN [
26]. The deep ResNets are easy to optimize for training and obtain high accuracy from greatly increased depth compared with other networks. ResNets with 50-layer, 101-layer, and 152-layer depths are the most commonly used residual structures on detection and segmentation. In this paper, with comprehensive consideration of accuracy and operation time, the ResNet-101 network of a depth of 101 layers was used in the implementation of the mask R-CNN, and primarily extracted features from the three convolutional layers of the third, fourth, and fifth stages, as shown in
Figure 3, left, which fed to the next multiscale backbone architecture.
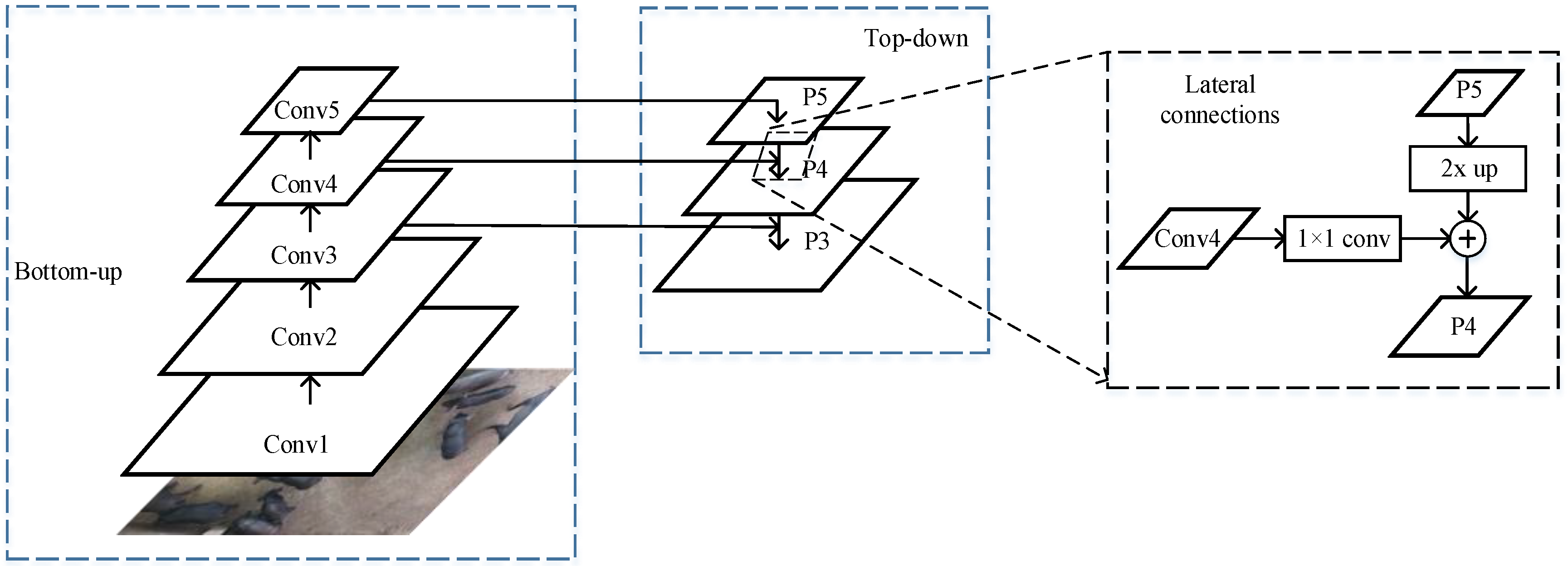
Another part of effective backbone architecture was FPN, proposed by Tsung Yi Lin [
26]. FPN can construct a multi-output feature pyramid from a single-scale input by using top-down architecture and lateral connections, as shown in
Figure 3, middle and right. The detailed process of
Figure 3 is described in the following.
The conv1, conv2, conv3, conv4, and conv5 outputs are obtained from the last residual blocks in the ResNet101 network. First, the top-layer feature map (P5) can be achieved by performing a 1 × 1 convolutional layer on conv5. Then, the upsampled feature map was generated by a factor of 2 on P
5, and the feature map P
4 (
Figure 3, right lateral connections) can be obtained by element-wise addition operation for the upsampled feature map, and the result, which is obtained by performing a 1 × 1 convolutional operation on
. Finally, according to
, this final set of feature maps is
.
The backbone architecture of PigMS R-CNN in this study uses ResNe-101+FPN. The feature maps of backbone architecture for a housed-pig image are shown in
Figure 4.
Figure 4a shows source image,
Figure 4b–d extract low-level features, including texture and edge contour information.
Figure 4e represents high-level abstract features.
3.3. RoIs Generation Based on RPN
The candidate RoIs will be produced by RPN using the feature maps from the first stage. The convolution layers of a pre-trained network are followed by a 3 × 3 convolutional layer in the RPN. The function of this operation is to map a large spatial window or receptive field in the input image to a low-dimensional feature vector at a window location. Then two 1 × 1 convolutional layers are used for classification and regression operations of all spatial windows [
14].
In the RPN, the algorithm introduces anchors to manage different scales and aspect ratios of objects. An anchor is located at each sliding location of the convolutional maps, and lies at the center of each spatial window, which is associated with a scale and an aspect ratio. Following the default setting of [
26], five scales (32
2, 64
2, 128
2, 256
2, and 512
2 pixels) and three aspect ratios (1:1, 1:2, and 2:1) are used, and k = 15 anchors at each location are created and used for each sliding window. These anchors go through a classification layer (cls) and a regression layer (reg). The RPN then completes the following two tasks: (1) determining whether the anchors are targets or non-targets (2k); (2) performing coordinate correction on the target anchors (4k). In the classification layer branch, two scores (target and non-target) are generated for each anchor; in the regression layer branch, the parameterizations of the four coordinates are corrected, and shown as Equation (1). For each target anchor:
where
denote the two coordinates of the box center,
is the width and height of the box. The
and
variables denote the predicted box, anchor box, and ground-truth box respectively (likewise for
). Finally, after sorting scores of the target anchors in descending order, the first n anchors are selected for the next stage of detection.
The loss function of training RPN is as follows:
where
is the index of an anchor and
is the predicted probability of anchor
, which is taken as a positive object. If the anchor is positive sample, the ground-truth label
is 1, otherwise it is 0. The
vector includes the 4 parameterized coordinates of the predicted bounding box, and
is a vector of the ground-truth box associated with a positive anchor.
is the classification loss to express log loss for two classes (object vs. not object).
is the regression loss, where
R is the robust loss function (smooth L1). The term
denotes the regression loss which is activated only for positive anchors (
= 1) and is disabled otherwise (
= 0). The outputs of the
cls and
reg layers consist of
and
, respectively. The two terms are normalized with
,
, and a balancing weight
.
Some RPN proposals highly overlap with each other. To reduce redundancy, NMS, on the proposal regions based on their cls scores, is adopted. The IoU threshold for NMS is set 0.7, which leaves us about 2k proposal regions per image. NMS does not harm the ultimate detection accuracy, but substantially reduces the number of proposals. After NMS, the top-N ranked proposal regions are used for further detection and segmentation.
The process of bounding box generation based on RPN is shown in
Figure 5.
Figure 5a shows the source image,
Figure 5b shows the results that the anchors are targets or non-targets;
Figure 5c shows the results of the coordinate corrections on the target anchors.
3.4. The Three Branches of Detection and Segmentation
The MS R-CNN outputs the three branches, including performing the proposal classification, regression, and a binary mask for each RoI in parallel. The first two branch structures use two fully connected (FC) layers for the region of interest (RoI) performing classification prediction and BB regression. The last branch is instance segmentation, which uses a fully convolutional network (FCN) [
18] for predicting a mask from each BB.
Formally, during training, a multi-task loss (
) on each BB is defined:
where
and
are the bounding-box and classification loss,
was defined as the average binary cross-entropy loss. For a BB associated with ground-truth class
k,
is only defined on the
k-th mask in MS R-CNN model,
,
and
are identical as those defined in [
23].
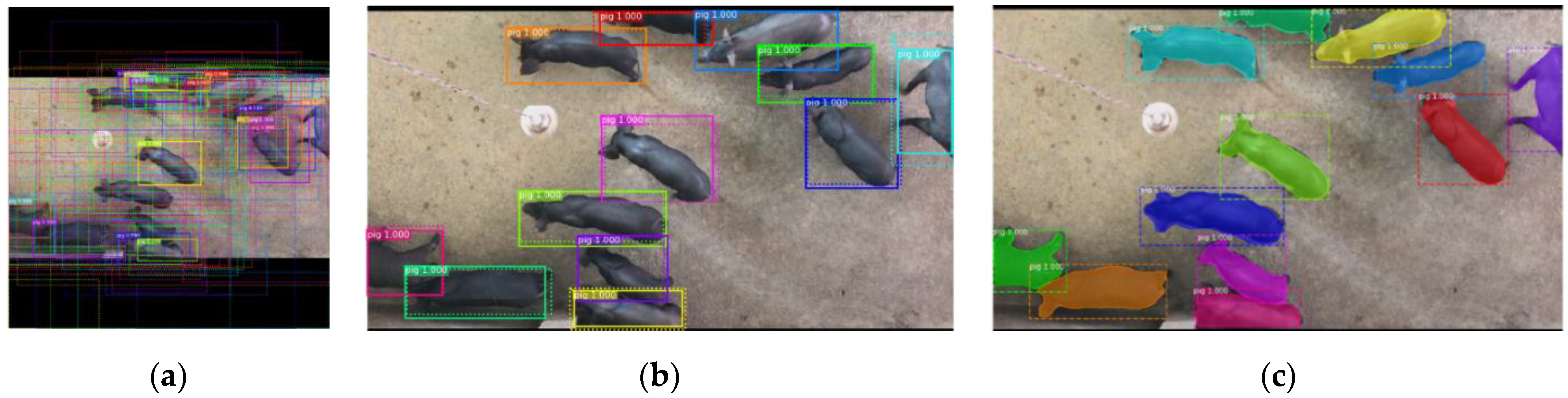
The output of the three branches is shown in
Figure 6.
Figure 6a shows the BB’s positions can be adjusted using a regression network.
Figure 6b shows the BBs that are assigned a score for each class label using a classification network after NMS.
Figure 6c shows the detection and segmentation final results of group-housed pigs.
3.5. Improving Non-Maximum Suppression
For detection tasks, NMS is a necessary component after BB regression, which is a post-processing algorithm for redundancy removal of detection results. It is a handcrafted algorithm, to greedily select high-scoring detections, and remove their overlapping, low confidence neighbors. The NMS algorithm first sorts the proposal boxes according to the classification scores from high to low, then the detection box m with the highest score(
) is selected, and the other boxes with obvious overlap (Intersection over Union (IoU) > threshold used
Nt) are suppressed. This process is recursive until all proposal boxes are traversed. Traditional NMS processing methods can be expressed by the following fraction resetting function:
where
,
,
and
denote the detection box with the maximum score, the
i-th of detection box, the score of the
i-th detection box, and threshold value. NMS sets a hard threshold
while deciding what should be kept or removed from the neighborhood of
.
NMS performs well in generic object detection, adopting different thresholds; however, due to local maximum suppression, there is missing detection for the easily overlapped target objects. In the group-housed pig-breeding environment, there are serious adhesions and high overlaps in group pigs. To improve the detection performance of group-housed pigs, an improved NMS algorithm named soft-NMS [
24] is used.
The soft-NMS algorithm process is as follows in
Figure 7:
where
is the overlap based weighting function with a Gaussian penalty function in soft-NMS as follows,
This rule is applied in the algorithm for each iteration and scores of all remaining detection boxes are updated. In the soft-NMS algorithm, the computational complexity of each step is , where N is the number of detection boxes. Moreover, the algorithm updates the scores for all detection boxes that overlap with . Therefore, for N detection boxes, the computational complexity of soft-NMS is , and it is the same as traditional NMS. Soft-NMS hence does not require any additional training and uses the same running time with NMS’s detectors.
3.6. Experiment Detail
The experimental environment is described below as follows:
PC: CPU, Intel® Xeon(R) CPU E5-2620 v4 @ 2.10 GHz × 8; Memory, 64 GB; Graphics, Tesla K40c.
OS: Ubuntu 16.04, CUDA10.1, Python3, Pytorch1.0, PyCharm, Jupyter Notebook.
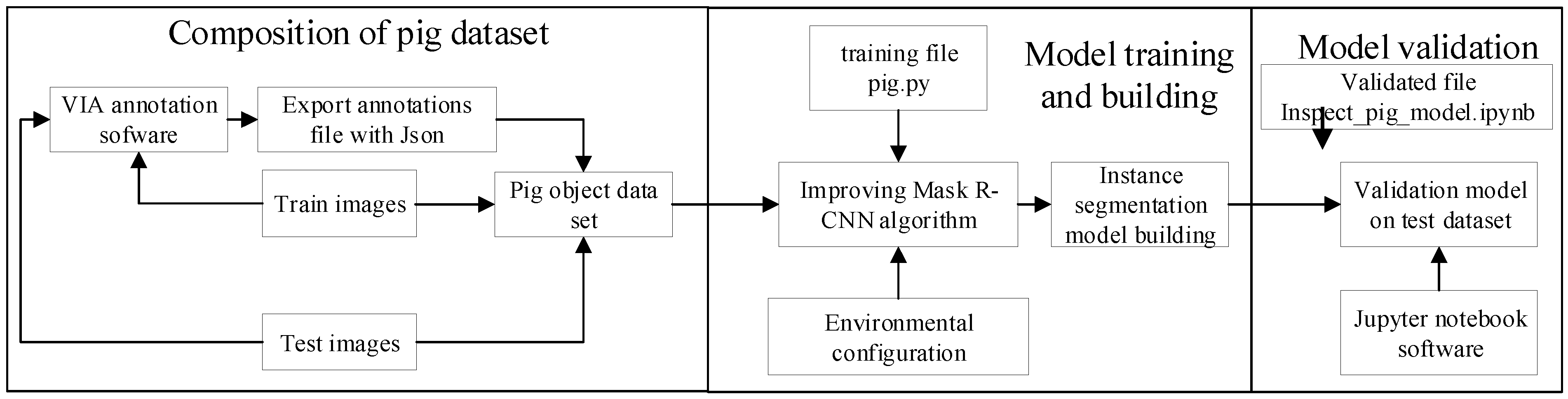
The procedure of the PigMS R-CNN model mainly involves three steps: image data annotation, model training, and verification, as shown in
Figure 8. Firstly, the training set and test set are labeled via the annotation tool, and the corresponding annotation files with JSON format are obtained. The train images, test images, and the corresponding annotation JSON files form the pig object dataset for training. Then, the pig.py of the training file adopts the PigMS R-CNN algorithm to set up an instance segmentation model using python3.6 on the pig object dataset, which includes 290 training and 130 test images. Finally, the validated pig file inspect_pig_model.ipynb written in jupyter notebook software is used to test set and get the pig object detection and segmentation result by calling the built model file of pig.py.
Back-propagation and stochastic gradient descent (SGD) are used to train the PigMS R-CNN model. For RPN networks, each mini batch comes from a single image containing many positive and negative example anchors. The input image is resized to 800 pixels on its shorter side. Synchronized SGD is used to train the model on eight GPUs. Each mini batch includes two images per GPU and 512 anchors in each image with a weight decay of 0.001 and a momentum of 0.9. The learning rate is 0.01 for the first 6000 mini-batches and 0.001 for the next 1000, and 0.0001 for the next 1000. NMS is performed over the proposals with an IoU threshold of 0.7.
and
in soft-NMS are set to 0.7 and 0.5, respectively. The pre-trained model of ResNet-101 was available at
https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/MSRA/R-101.pkl (accessed on 7 May 2021). The experimental results, models, and images are obtained by the Baidu network disk’s address (
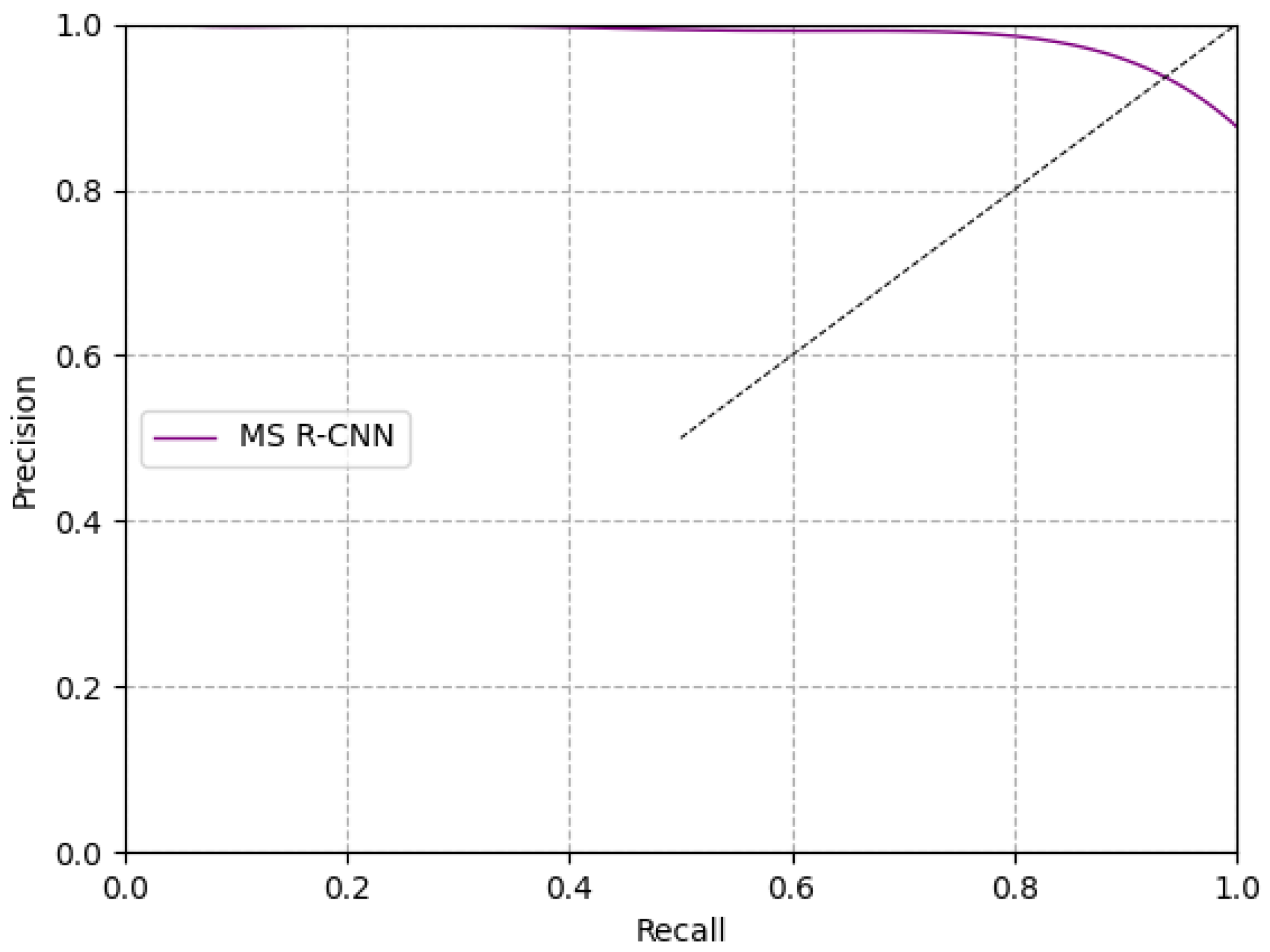
https://pan.baidu.com/s/1_BOpAJ8trdjhBZO1fe4hWA, accessed on 23 April 2021), where the extracted code is a5h6. The precision–recall curve with the corresponding F1 score is used as the evaluation metric for pig detection [
23]. The F1 score is computed as:
5. Conclusions and Future Work
The group-housed instance segmentation of pigs in a natural environment is a significant operation to efficiently manage pig farms. However, using a traditional method, group-housed pigs cannot be separated accurately in real-time for heavily overlapped pigs in complex backgrounds.
In this paper, an improved MS R-CNN framework with soft-NMS was proposed to obtain the locations and segmentation of each pig in group-housed pig images. To prevent the missed and wrong detection of target pigs, caused by overlapping, adhesion, and other complex environmental issues in a crowded room, this paper employs the soft-NMS method instead of the traditional NMS in the MS R-CNN model, without adding extra times. All boxes, which have an overlap greater than a threshold in traditional NMS, are given a zero score. Compared with NMS, soft-NMS rescores neighboring boxes instead of suppressing them altogether, which obtains improvement in precision and recall values.
Based on the pig detection and segmentation results for 130 images, with 1147 for top view and front view, the basic MS R-CNN framework obtained results with an F1 of 0.9228, while the target pigs using PigMS R-CNN had an F1 of 0.9374 in complex scenes. This algorithm can achieve good performance in terms of F1 without adding extra time. Our work on pig instance segmentation supports the foundation for pig behavior monitoring, posture recognition, and other related applications, such as body size and weight measurement estimations of pigs. Furthermore, it provides a deep learning framework for detecting and segmenting animals using overhead and front view cameras in a natural environment. In the future, we will develop pig behavior applications, such as pig monitoring of drinking water and fighting behavior under group-housed pigs’ scenes.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}