
Feature-Based Sentimental Analysis on Public Attention towards COVID-19 Using CUDA-SADBM Classification Model




Abstract
:1. Introduction
2. Literature Survey
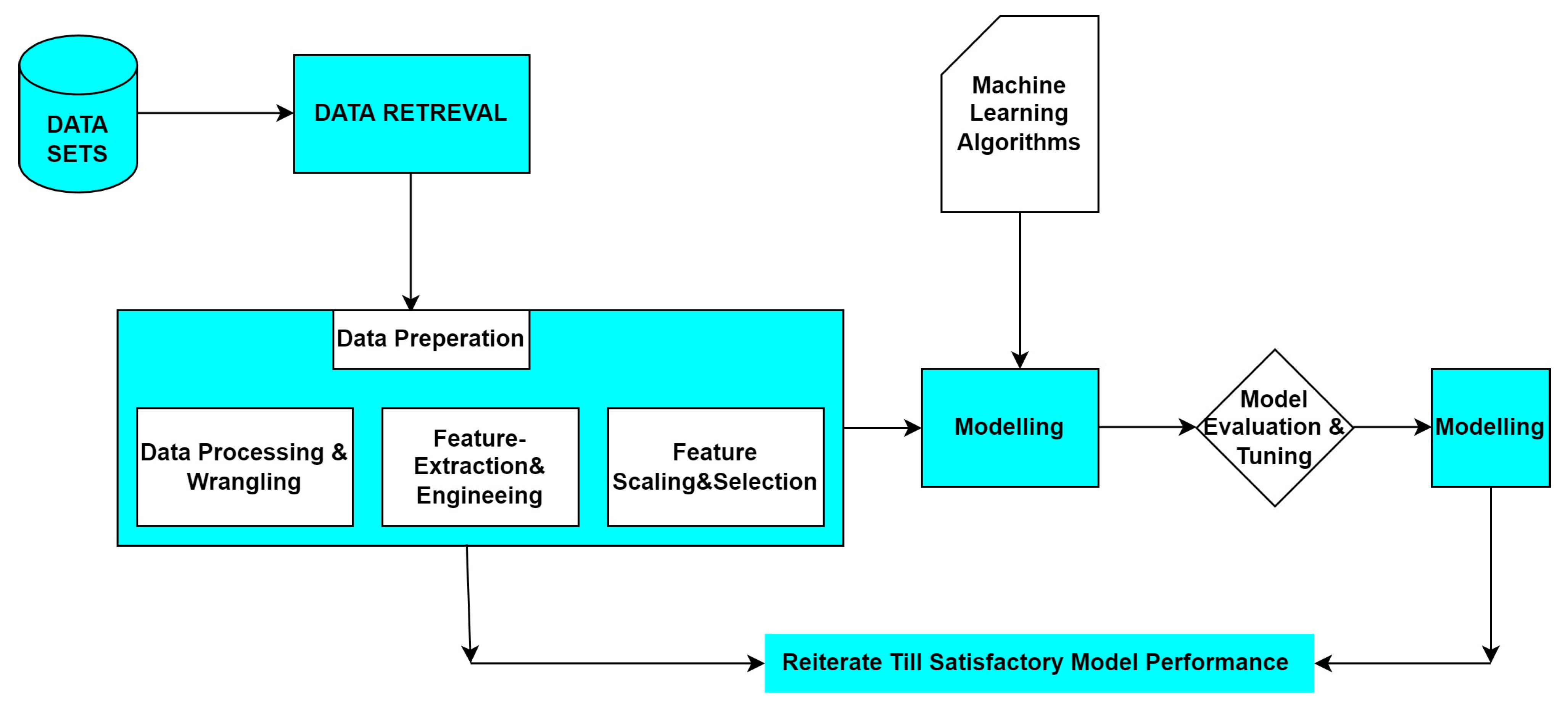
3. Methodology
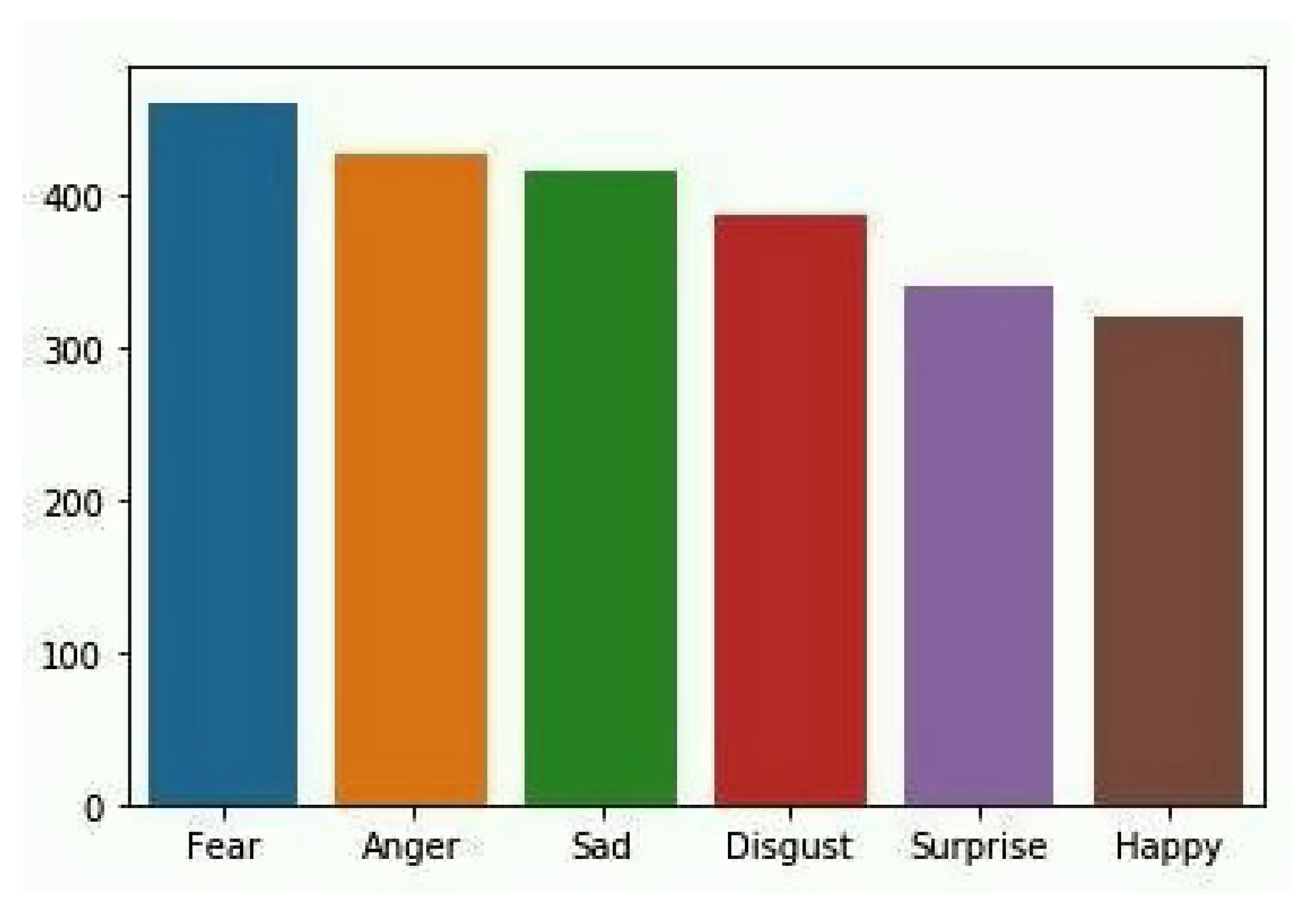
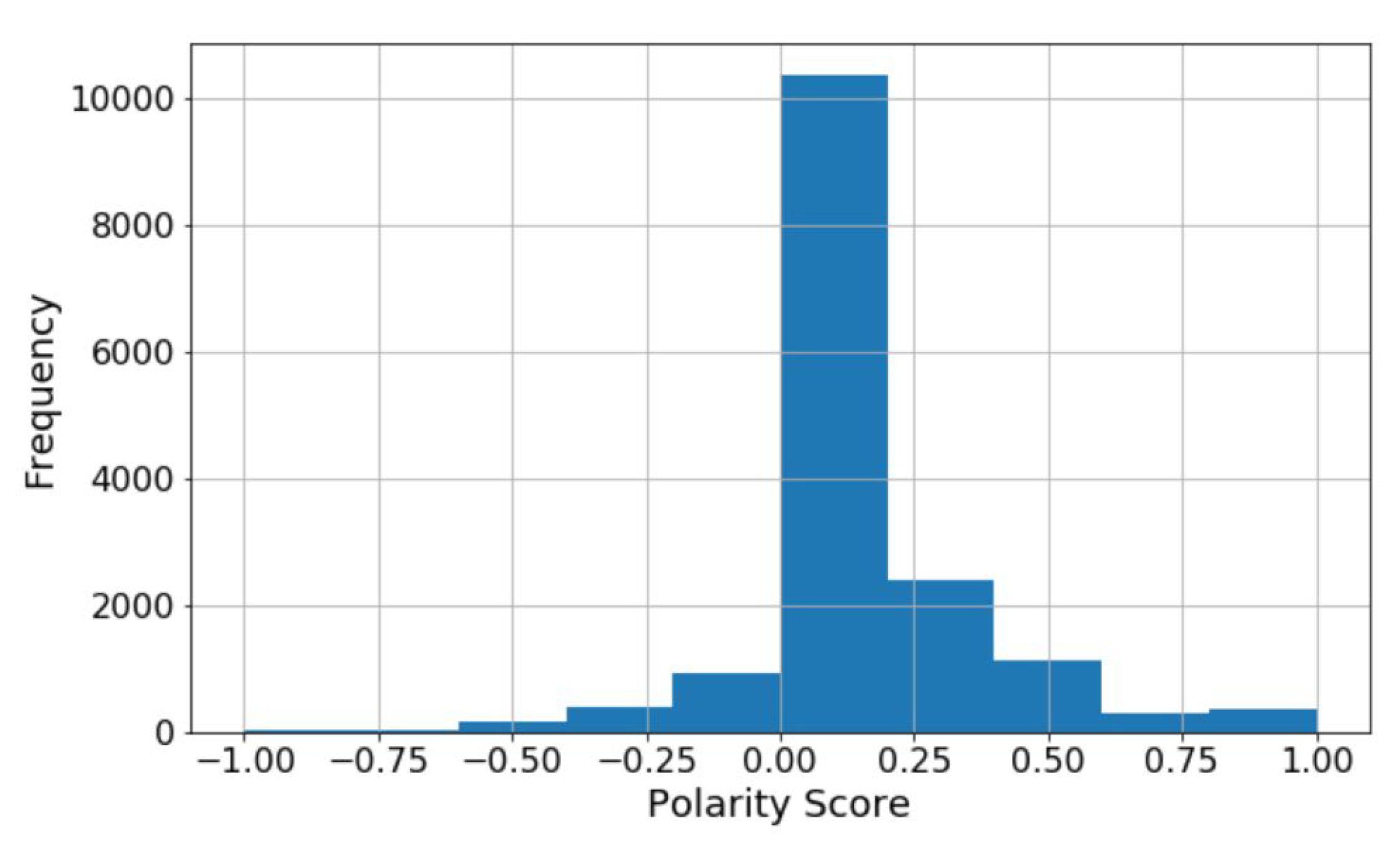
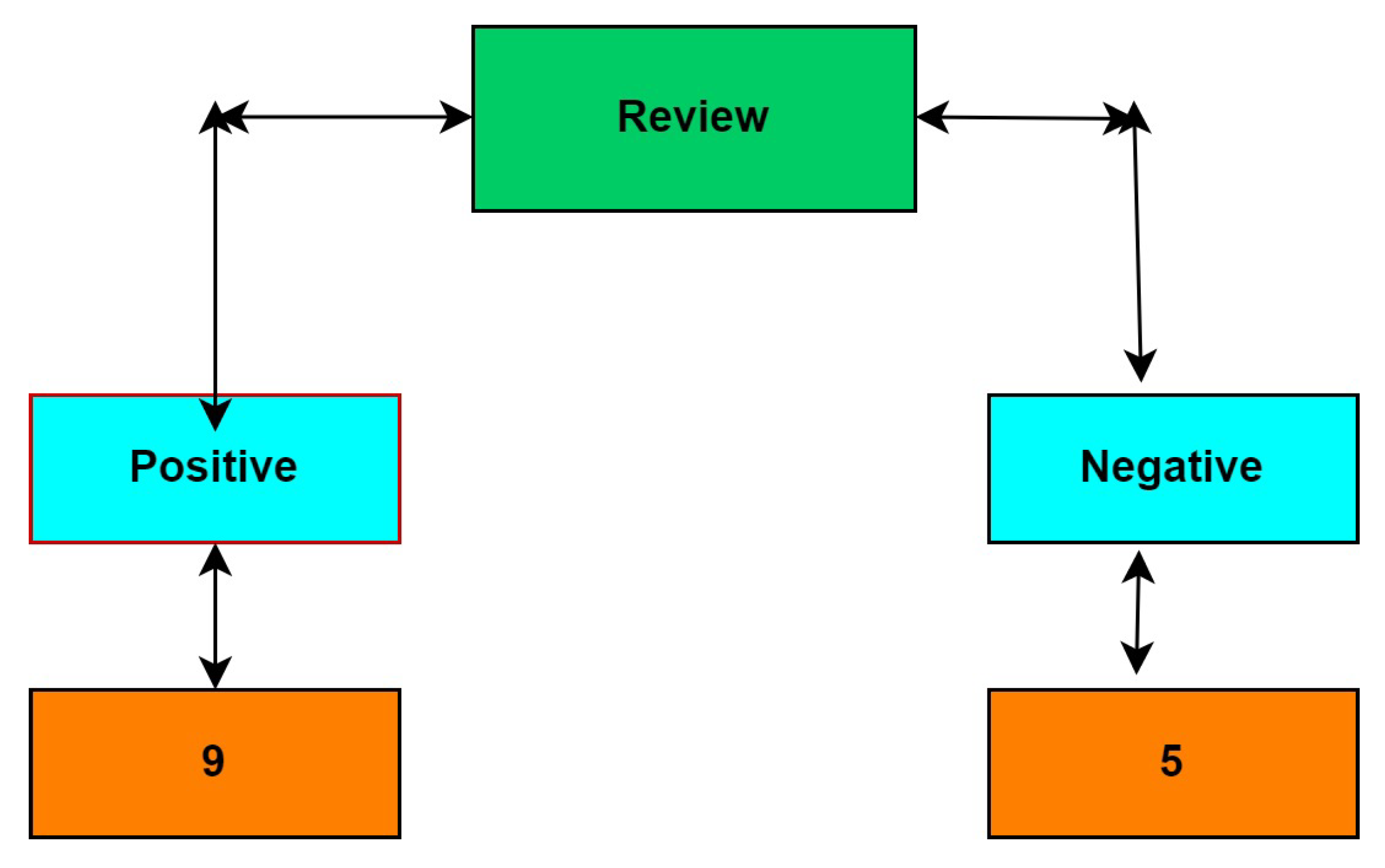
Dataset
4. Compute Unified Device Architecture (CUDA) and Programming
GF108 Architecture
5. Proposed Method
5.1. Making Predictions with Logistic Regression
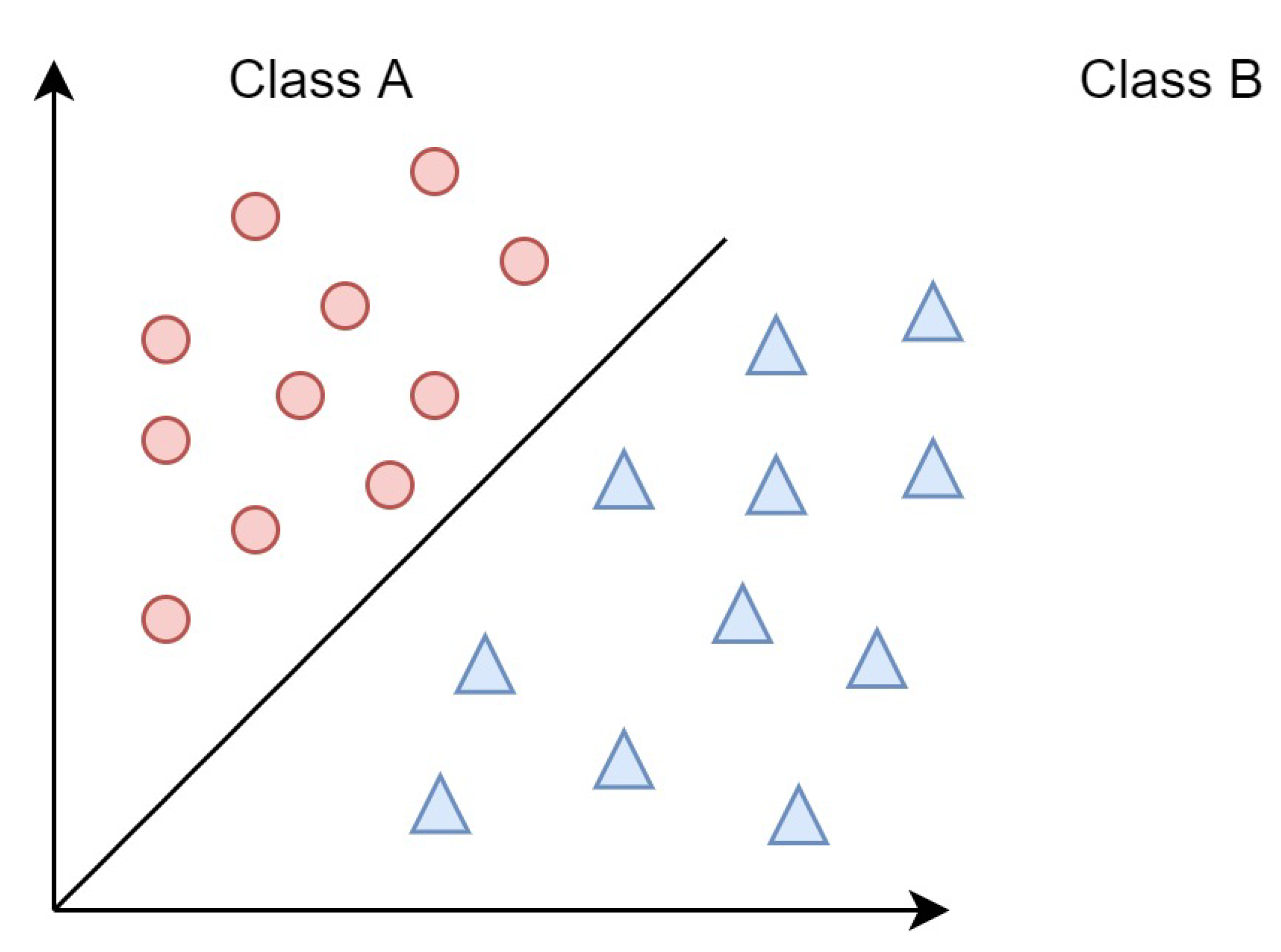
5.2. Decision Tree
5.2.1. Entropy
5.2.2. Information Gain
- Find the entropy of the target attribute.
- Entropy of every branch is calculated to find the best split.
- Select attribute with high info gain and recursively repeat the same for all the remaining branches.
- If entropy is zero, then consider all of them as a leaf node; else, continue splitting.
- Repeat all the above steps until data is classified.
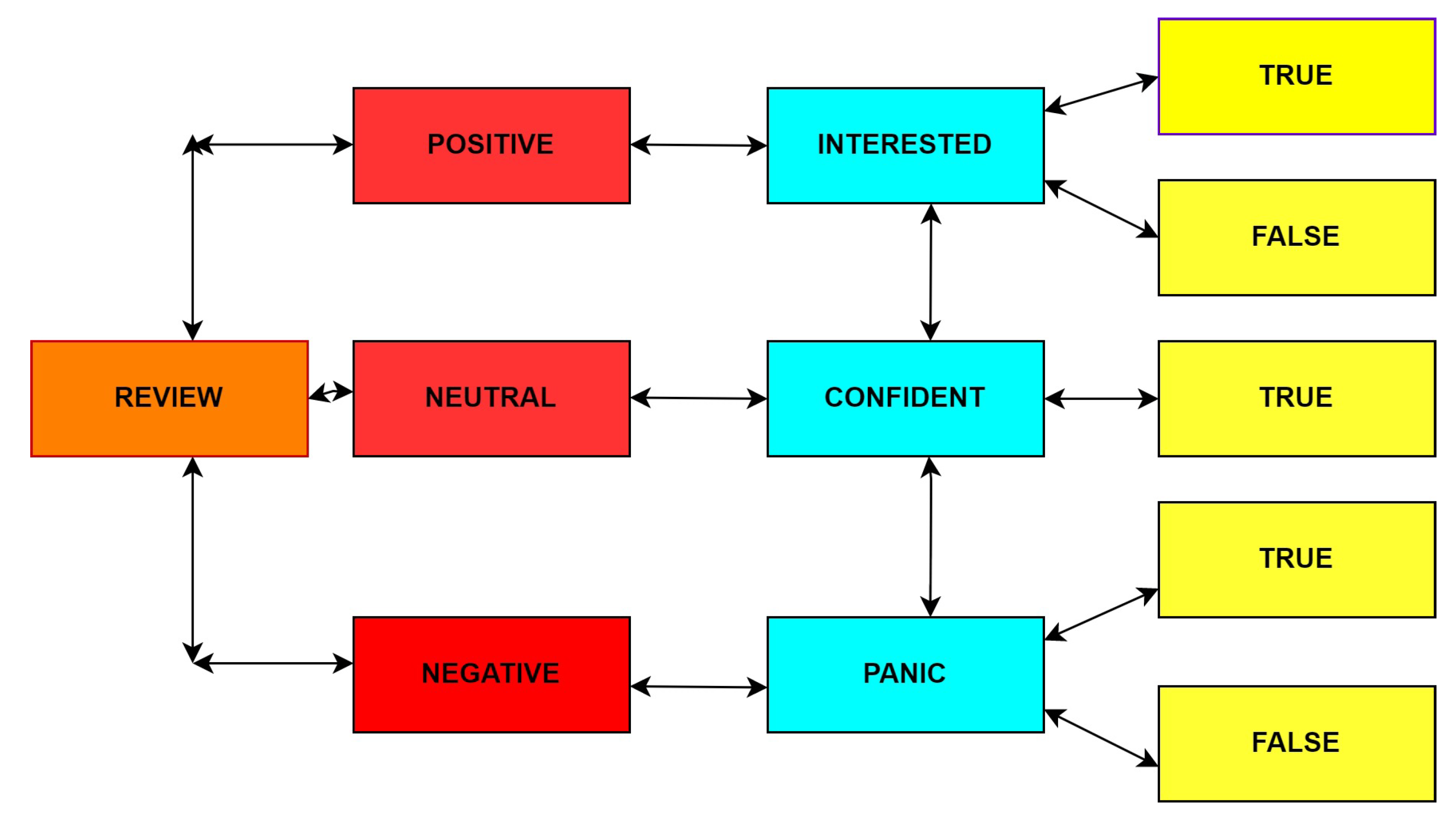
5.3. Proposed Compute Unified Device Architecture (CUDA) Sentimental Analysis Database Miner Classifier
| Algorithm 1: Decision Tree Building Algorithm |
 |
|---|
| Algorithm 2: Accuracy Prediction Algorithm |
Call: xgboost() M= x.xgbClassifier() m.fit(X_train,Y_train) Call: ConstructTree() c= confusion_matrix (Y_test,Y_pred) Calculate: Accuracy = Number of correct predictions/total predictions Return accuracy Stop |
6. Implementation and Results
6.1. Acceleration Ratio
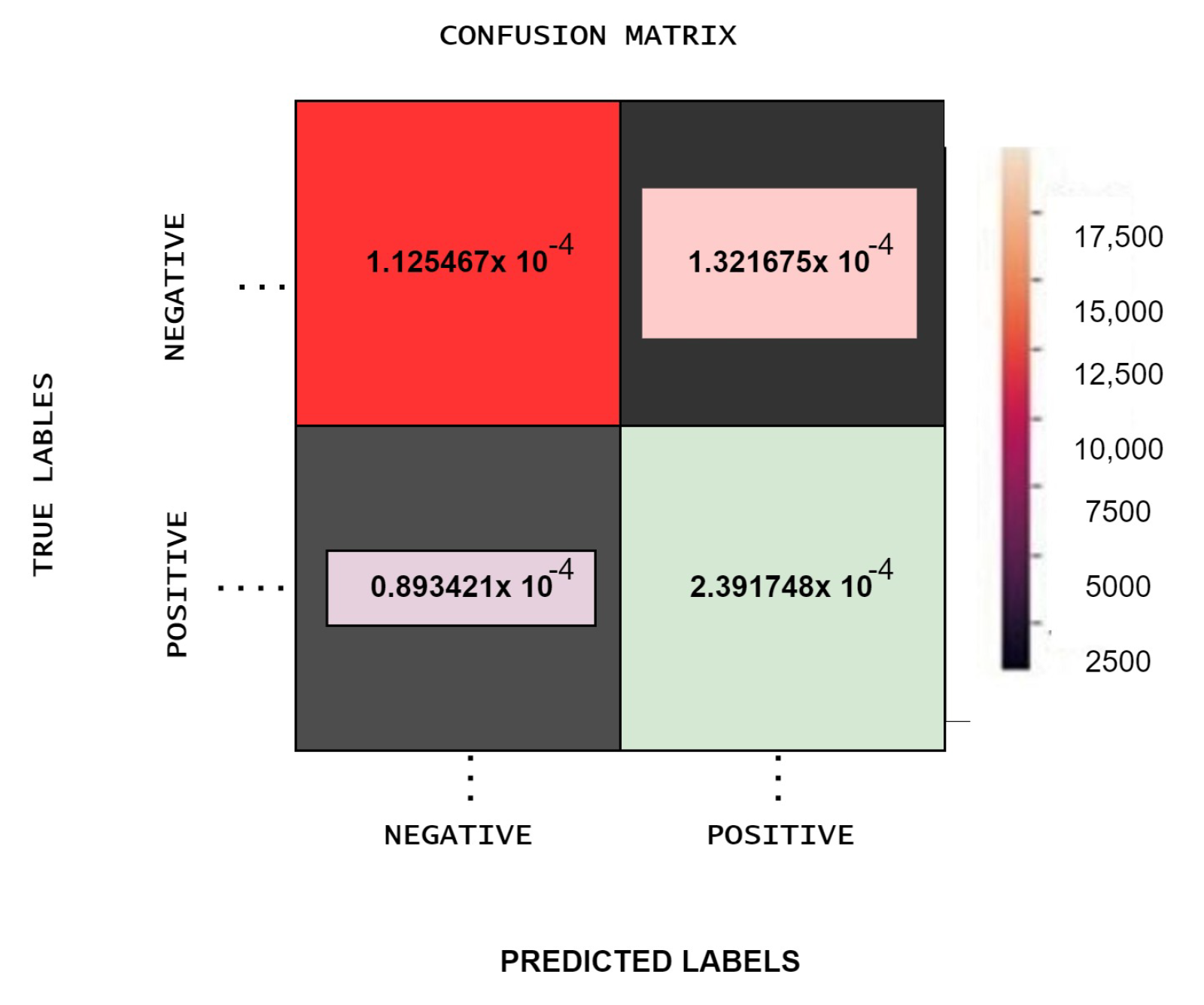
6.2. Performance Evaluation Measures
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Picard, R.W.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: Analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef] [Green Version]
- Pathuri, S.K.; Anbazhagan, N. Basic Review of Different Strategies for Sentiment Analysis in Online Social Networks. Int. J. Recent Technol. Eng. 2019, 8, 3392–3396. [Google Scholar]
- Shiva, T.; Kavya, T.; Reddy, N.A.; Bano, S. Calculating The Impact Of Event Using Emotion Detection. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 183–189. [Google Scholar]
- Ortigosa, A.; Martín, J.M.; Carro, R.M. Sentiment analysis in Face book and its application to E-Learning. J. Comput. Hum. Behav. 2014, 31, 527–541. [Google Scholar] [CrossRef]
- Singh, A.J. Sentiment Analysis: A Comparative Study of Supervised Machine Learning Algorithms Using Rapid miner. IJRASET 2017, 5, 80–89. [Google Scholar]
- Sreedevi, E.; Premalatha, V.; Sivakumar, S.; Nayak, S.R. A comparative study on new classification algorithm using NASA MDP datasets for software defect detection. In Proceedings of the 2019 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 21–22 February 2019; pp. 312–317. [Google Scholar]
- Atmakur, V.K.; Siva Kumar, P. A prototype analysis of machine learning methodologies for sentiment analysis of social networks. Int. J. Eng. Technol. 2018, 7, 963–967. [Google Scholar] [CrossRef] [Green Version]
- Chandra, R.; Krishna, A. COVID-19 sentiment analysis via deep learning during the rise of novel cases. PLoS ONE 2021, 16, e0255615. [Google Scholar] [CrossRef]
- Videla, L.S.; Ashok Kumar, P.M. Fatigue Monitoring for Drivers in Advanced Driver-Assistance System. Examining Fractal Image Process. Anal. IGI Glob. 2020, 170–187. [Google Scholar] [CrossRef]
- Sivakumar, S.; Nayak, S.R.; Vidyanandini, S.; Kumar, J.A.; Palai, G. An empirical study of supervised learning methods for breast cancer diseases. Opt.-Int. J. Light Electron Opt. 2018, 175, 105–114. [Google Scholar]
- Mazzonello, V.; Gaglio, S.; Augello, A.; Pilato, G. A Study on Classification Methods Applied to Sentiment Analysis. In Proceedings of the 2013 IEEE Seventh International Conference on Semantic Computing, Irvine, CA, USA, 16–18 September 2013; pp. 16–18. [Google Scholar]
- Razia, S.K.; Narasingarao, M.R. A Neuro computing frame work for thyroid disease diagnosis using machine learning technique. J. Theor. Appl. Inf. Technol. 2017, 95, 1996–2005. [Google Scholar]
- Devi, S.A.; Kumar, S.S. A hybrid document features extraction with clustering based classification framework on large document sets. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 364–374. [Google Scholar] [CrossRef]
- Videla, L.S.; Rao, M.N.; Anand, D.; Vankayalapati, H.D.; Razia, S. Deformable facial fitting using active appearance model for emotion recognition. Smart Intell. Comput. Appl. 2019, 104, 135–144. [Google Scholar]
- Guo, X.; Li, J. A novel twitter sentiment analysis model with baseline correlation for financial market prediction with improved efficiency. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 472–477. [Google Scholar]
- Güven, Z.A.; Diri, B.; Çakaloğlu, T. Comparison of n-stage Latent Dirichlet Allocation versus other topic modeling methods for emotion analysis. J. Fac. Eng. Archit. Gazi Univ. 2021, 35, 2135–2145. [Google Scholar] [CrossRef]
- Kaur, C.; Sharma, A. COVID-19 Sentimental Analysis Using Machine Learning Techniques. Prog. Adv. Comput. Intell. Eng. 2021, 1299, 153–162. [Google Scholar]
- Anila, M.; Pradeepini, G. Least square regression for prediction problems in machine learning using R. Int. J. Eng. Technol. 2018, 7, 960–962. [Google Scholar]
- Baig, M.M.; Sivakumar, S.; Nayak, S.R. Optimizing Performance of Text Searching Using CPU and GPUs. Adv. Intell. Syst. Comput. 2020, 141–150. [Google Scholar] [CrossRef]
- Golbeck, J.; Robles, C.; Edmondson, M.; Turner, K. Predicting personality from twitter. In Proceedings of the IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 149–156. [Google Scholar]
- PremaLatha, V.; Sreedevi, E.; Sivakumar, S. Contemplate on internet of things transforming as medical devices- The internet of medical things (IOMT). In Proceedings of the International Conference on Intelligent Sustainable Systems ICISS, Palladam, India, 21–22 February 2019; pp. 276–281. [Google Scholar]
- Bruce, R.F.; Wiebe, J.M. Wiebe. Recognizing Subjectivity: A Case Study in Manual Tagging. Nat. Lang. Eng. 1999, 5, 187–205. [Google Scholar] [CrossRef] [Green Version]
- Sivakumar, S.; Periyanagounder, G.; Sundar, S. A MMDBM classifier with CPU and CUDA GPU computing in various sorting procedures. Int. Arab. J. Inf. Technol. 2017, 14, 897–906. [Google Scholar]
- Nguyen, H. GPU Gems 3; Addison-Wesley Professional: Boston, MA, USA, 2007. [Google Scholar]
- CUDA Best Practices Guide; NVIDIA Corporation, 2010. Available online: https://www.classes.cs.uchicago.edu/archive/2011/winter/32102-1/reading/CUDA_C_Best_Practices_Guide.pdf (accessed on 10 October 2021).
- CUDA C Programming Guide; NVIDIA Corporation, 2014. Available online: https://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf (accessed on 10 October 2021).
- Nickolls, J.; Buck, I.; Garland, M. Scalable Parallel Programming with CUDA. ACM Queue 2008, 6, 40–53. [Google Scholar] [CrossRef] [Green Version]
- Razia, S.K.; Narasingarao, M.R. Development and Analysis of Support Vector Machine Techniques for Early Prediction of Breast Cancer and Thyroid. J. Adv. Res. Dyn. Control Syst. 2017, 9, 869–878. [Google Scholar]
- Razia, S.; Prathyusha, P.S.; Krishna, N.V.; Sumana, N.S. A Comparative study of machine learning algorithms on thyroid disease prediction. Int. J. Eng. Technol. 2018, 7, 315–319. [Google Scholar] [CrossRef]
- Kumar, P.; Pradeepini, G.; Kamakshi, P. Feature Selection Effects on Gradient Descent Logistic Regression for Medical Data Classification. Int. J. Intell. Eng. Syst. 2019, 12, 278–286. [Google Scholar] [CrossRef]
- Videla, S.; Kumar, P.M.A. Modified Feature Extraction Using Viola Jones Algorithm. J. Adv. Res. Dyn. Control Syst. 2018, 10, 528–538. [Google Scholar]
- Banker, S.; Patel, R. A brief review of sentiment analysis methods. Int. J. Inf. Sci. Tech. (IJIST) 2016, 6, 89–95. [Google Scholar] [CrossRef]
- Pathuri, S.K.; Anbazhagan, N.; Narayana, N.S.; Sridhar, W. A Novel classification model for feature-based sentimental analysis on public attention towards COVID-19. J. Cardiovasc. Dis. Res. 2021, 12, 176–187. [Google Scholar]
- Pathuri, S.K.; Anbazhagan, N. Feature-Based Sentimental Analysis on Product Review System Using CUDA-BB Algorithm. Int. J. Emerg. Trends Eng. Res. 2018, 8, 6380–6386. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Algorithms Used | Feature-Selection | Data Source | Accuracy |
|---|---|---|---|---|
| Gualtiero Bcolombo (2015) | Graph mining | TF-IDF | Web forums(Twitter Data) | 84% |
| Dmytro Karamshuk (2017) | Glove word vector, Conventional classification, DT | Consistency Label | Public Twitter | 85% |
| Tong Liu (2017) | Support vector Machine (SVM) | TF-IDF, N-Grams | Historical Twitters posts | 88% |
| Bridianne O’Dea (2015) | SVM, Logistic regression | TF-IDF wih filter and without filter and no filter, Data points | CSIRO | 80% |
| Pete Burnap (2015) | SVM, Naïve Bayes (NB), Decision Tree (DT), Rotation forest | Lexical, Structural, Emotive, Psychological TF-IDF, N-Grams, | Web forums (Twitter Data) | 75% |
| Benjamin. L (2016) | Logistic regression | N-Grams, Linguistic context | Kaggle | 82% |
| Mia Johnson Vioules (2017) | NB, Sequential minimal optimization (SMO), Decision tree (J48), | NBB, Multinomial L-R, RF | 80% | |
| Scott R Braithwaite (2016) | Decision Tree (DT) | Linguistic, word count | Amazon Mechanical Turk (AMT) | 76% |
| Munmum De Choudhury (2013) | SVM with a radial-basis function (RBF) kernel | Depression set | Crowdsourcing | 86% |
| Ramit Sawhney (2018) | Ensemble, Linear classification | Twitter streaming API | 81% | |
| Bart Desmet (2018) | Parallel Computing | Bag of words, polarity lexicon | KAGGLE | 92% |
| Shaoxiong Ji (2018) | SVM, random forest, gradient boost classification, XGboost | TF-IDF, semantics and syntactic, statistics, Linguistic features | Reddit and Twitter blogs | 89% |
| Jingcheng Du (2018) | CNN binary classification | Linguistic features | Twitter streaming API | 74% |
| No of Threads | Time Taken |
|---|---|
| 128 | 5.12 |
| 256 | 4.14 |
| 512 | 3.12 |
| 1024 | 2.69 |
| SADBM GPU Time | No of | No of | No of | No of | No of |
|---|---|---|---|---|---|
| Records | Records | Records | Records | Records | |
| s/12,000 | s/32,000 | s/52,000 | s/72,000 | s/92,000 | |
| Classification Time | 0.552 | 1.020 | 1.705 | 2.052 | 2.742 |
| CPU-Time | 0.710 | 1.130 | 1.740 | 2.3500 | 2.900 |
| GPU-Time | 0.550 | 1.010 | 1.640 | 2.230 | 2.490 |
| Acceleration Ratio | 1.296 | 1.118 | 1.064 | 1.054 | 1.1649 |
| Polarity | Precision | Recall | F-Score | Support |
|---|---|---|---|---|
| 0 | 0.79 | 0.82 | 0.77 | 2467 |
| 1 | 0.884 | 0.81 | 0.84 | 5765 |
| Accuracy | 0.81 | 8232 | ||
| MacroAvg | 0.81 | 0.82 | 0.81 | 8232 |
| WeightedAvg | 0.81 | 0.81 | 0.81 | 8232 |
| Polarity | Precision | Recall | F-Score | Support |
|---|---|---|---|---|
| 0 | 0.89 | 0.84 | 0.88 | 2899 |
| 1 | 0.884 | 0.91 | 0.89 | 5333 |
| Accuracy | 0.89 | 8232 | ||
| MacroAvg | 0.87 | 0.88 | 0.87 | 8232 |
| WeightedAvg | 0.89 | 0.89 | 0.89 | 8232 |
| Polarity | Precision | Recall | F-Score | Support |
|---|---|---|---|---|
| 0 | 0.953 | 0.943 | 0.924 | 2882 |
| 1 | 0.950 | 0.948 | 0.946 | 5350 |
| Accuracy | 0.96 | 8232 | ||
| MacroAvg | 0.96 | 0.96 | 0.956 | 8232 |
| WeightedAvg | 0.955 | 0.961 | 0.959 | 8232 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pathuri, S.K.; Anbazhagan, N.; Joshi, G.P.; You, J. Feature-Based Sentimental Analysis on Public Attention towards COVID-19 Using CUDA-SADBM Classification Model. Sensors 2022, 22, 80. https://doi.org/10.3390/s22010080
Pathuri SK, Anbazhagan N, Joshi GP, You J. Feature-Based Sentimental Analysis on Public Attention towards COVID-19 Using CUDA-SADBM Classification Model. Sensors. 2022; 22(1):80. https://doi.org/10.3390/s22010080
Chicago/Turabian StylePathuri, Siva Kumar, N. Anbazhagan, Gyanendra Prasad Joshi, and Jinsang You. 2022. "Feature-Based Sentimental Analysis on Public Attention towards COVID-19 Using CUDA-SADBM Classification Model" Sensors 22, no. 1: 80. https://doi.org/10.3390/s22010080
APA StylePathuri, S. K., Anbazhagan, N., Joshi, G. P., & You, J. (2022). Feature-Based Sentimental Analysis on Public Attention towards COVID-19 Using CUDA-SADBM Classification Model. Sensors, 22(1), 80. https://doi.org/10.3390/s22010080