
Unsupervised Clustering of Heartbeat Dynamics Allows for Real Time and Personalized Improvement in Cardiovascular Fitness


 ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition
2.2. Data Cleaning
2.3. Model
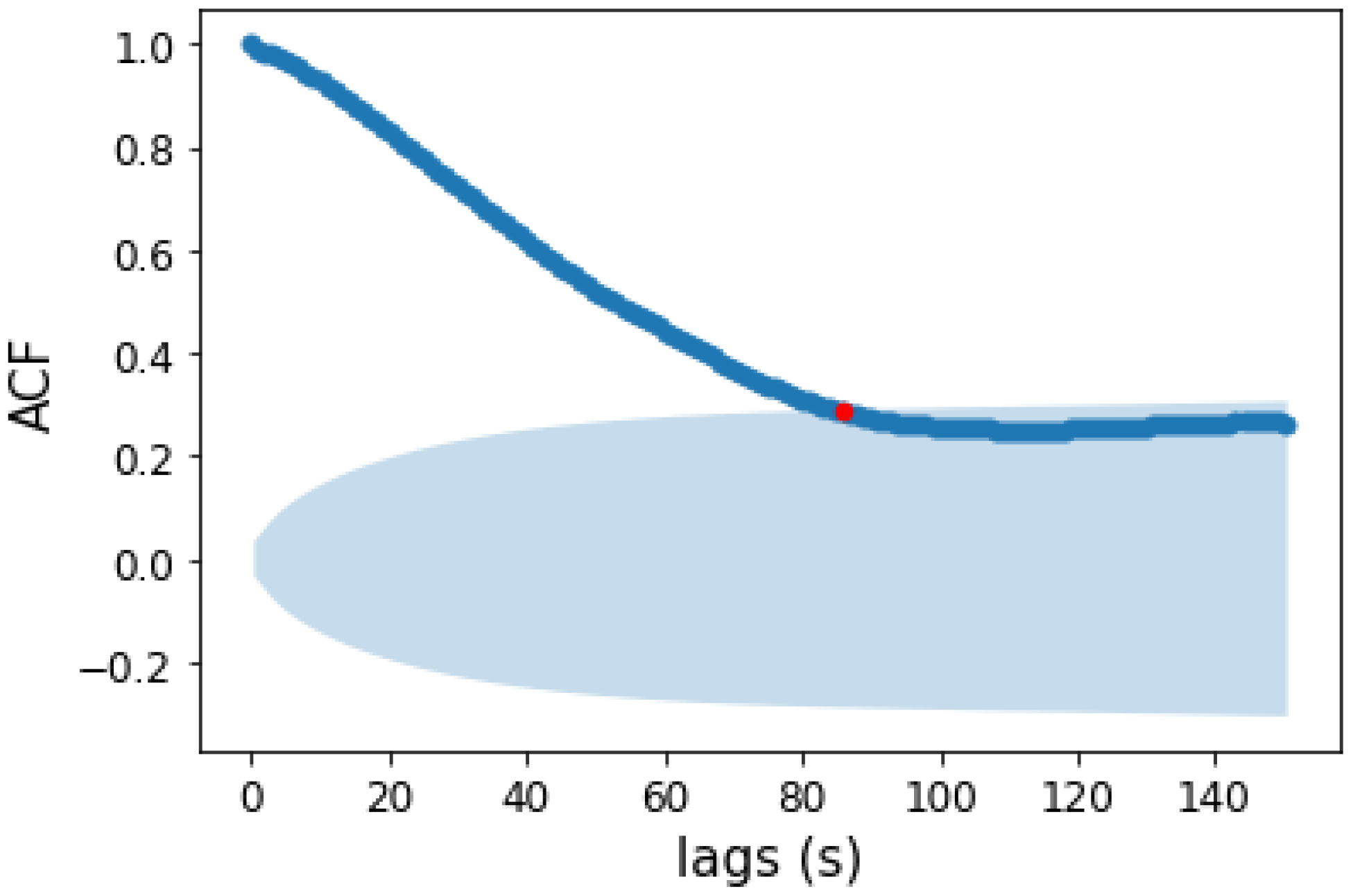
2.3.1. Time Interval as Statistical Unit
2.3.2. Feature Selection for the Clustering Algorithm
2.3.3. Clustering Analysis Algorithm
- Specify the number of clusters k and initialize centroids by randomly selecting K data points for the centroids without replacement;
- For each , set the cluster Cj to be the set of points in X that are closer to cj than they are to cj for all i ≠ j;
- For each, set ci to be the center of mass of all points in Cj: ;
- Repeat steps 2 and 3 until a stopping criterion is achieved (no reassignments with tolerance < 10−5).
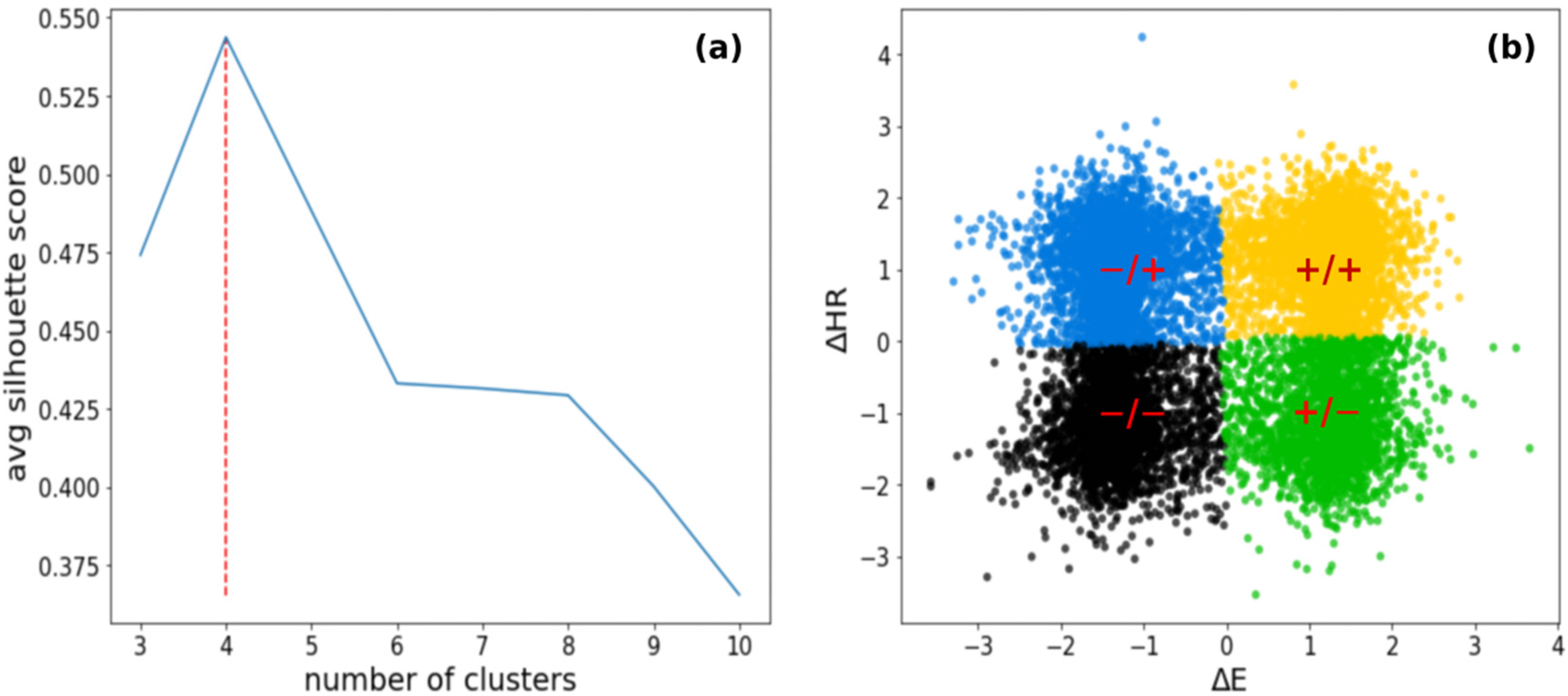
2.3.4. Choosing the Best k Number
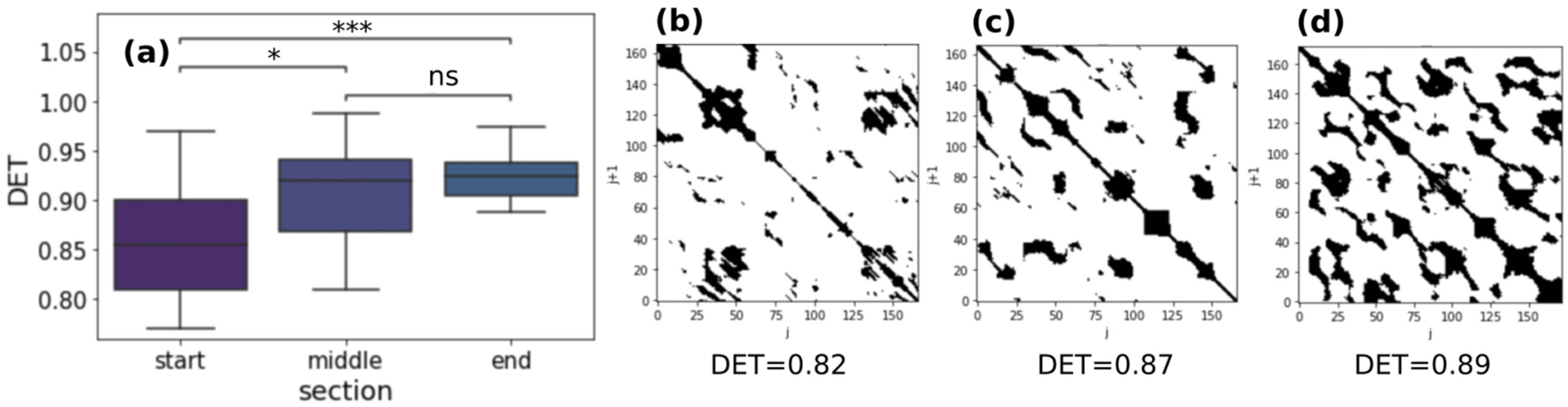
2.4. Recurrence Quantification Analysis (RQA)
2.5. Statistics
3. Results
3.1. K-Means Clustering Reveals Four Dynamic Clusters
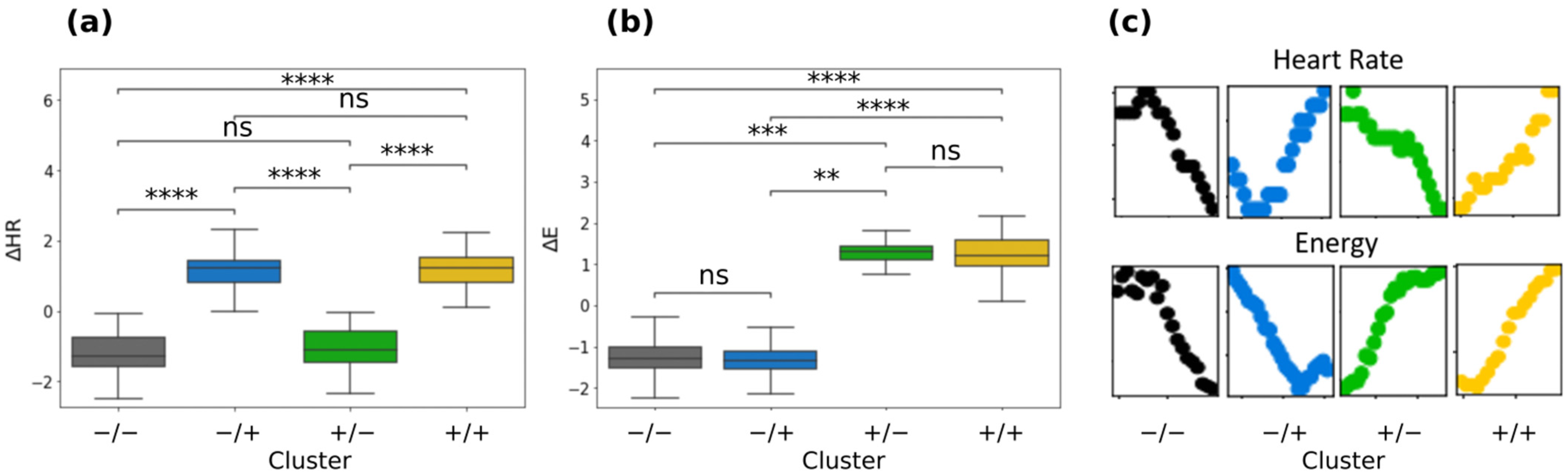
3.2. Descriptions of the Dynamic Clusters
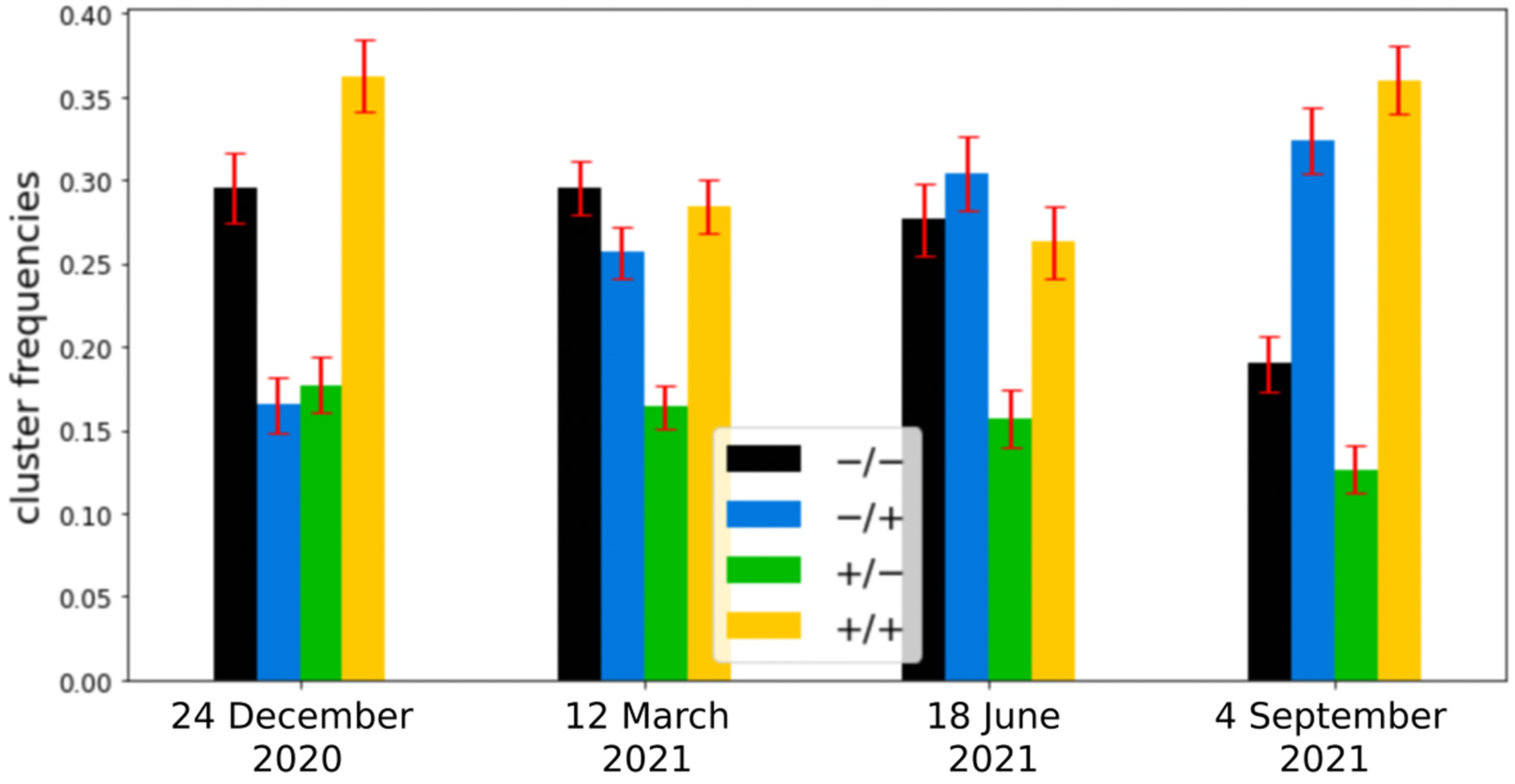
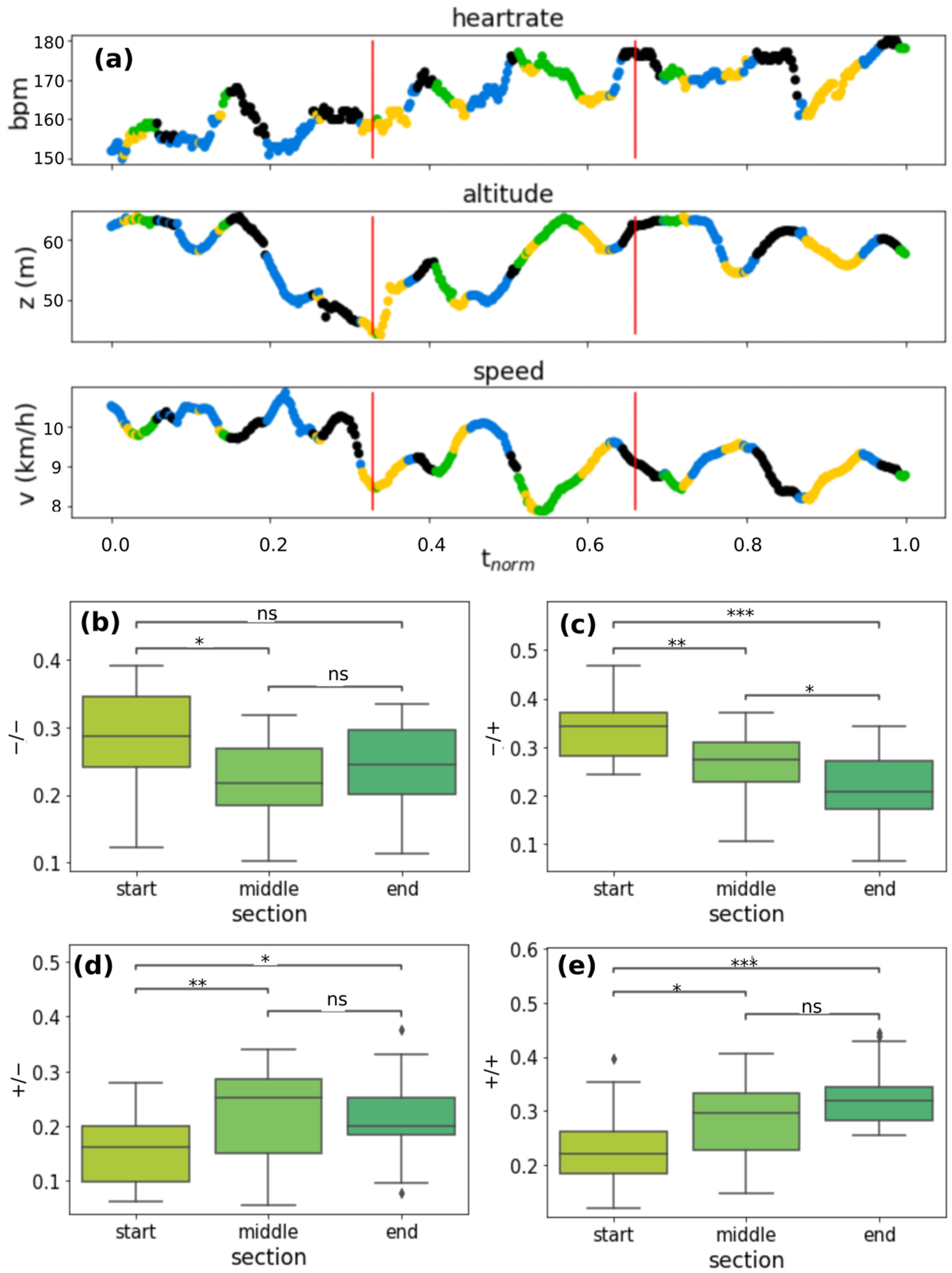
3.3. Temporal Mapping of Clusters on Running Sessions
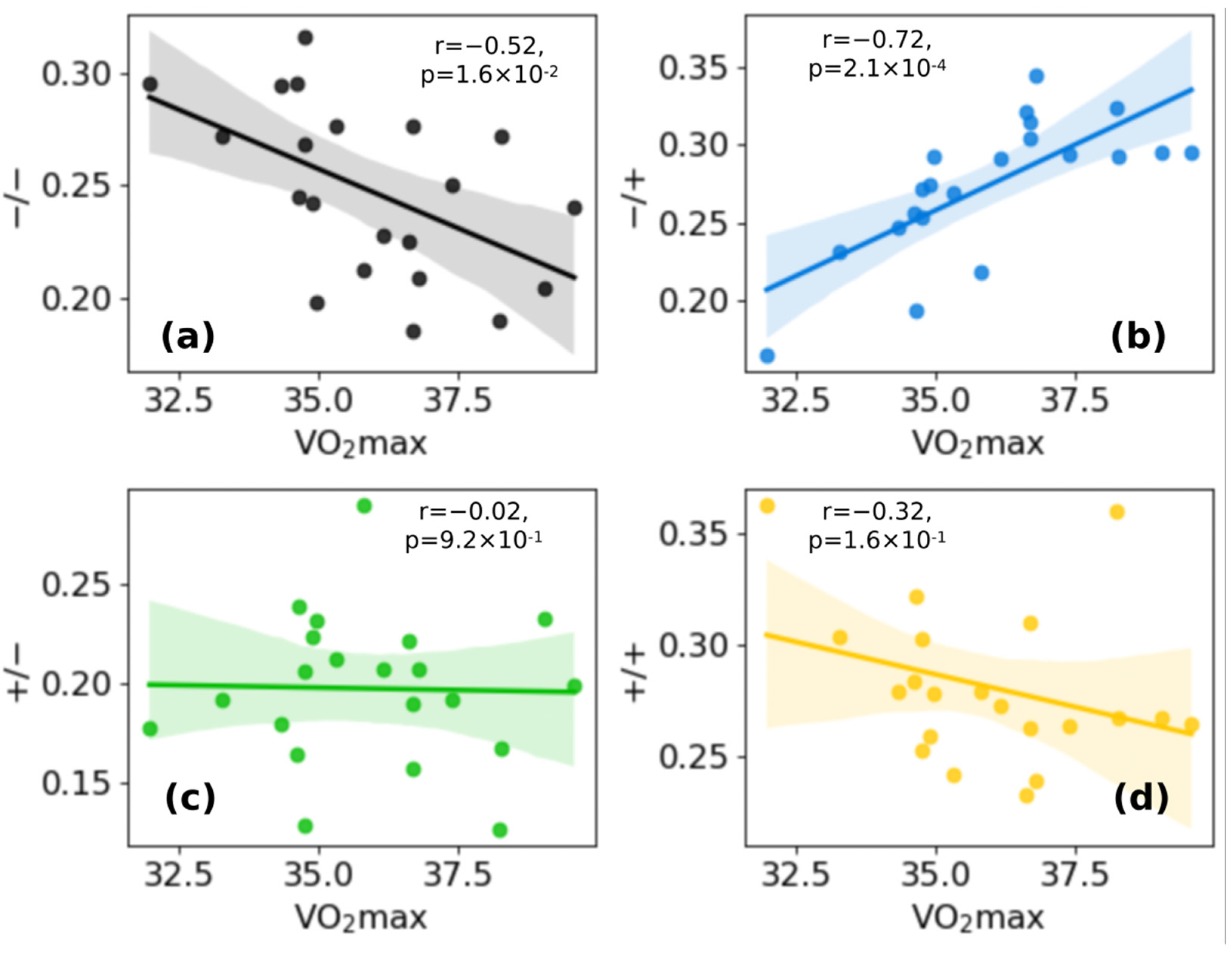
3.4. Fraction of Cluster −/+ Is Positively Correlated with VO2max, While Fraction of Cluster −/− Is Negatively Correlated
3.5. Temporal Distribution of the Heartbeat Dynamics and Correlation with Neuromuscular Fatigue
4. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shephard, R.J.; Allen, C.; Benade, A.J.S.; Davies, C.T.M.; di Prampero, P.E.; Hedman, R.; Merriman, J.E.; Myhre, K.; Simmons, R. The Maximum Oxygen Intake. Bull. World Health Organ. 1968, 38, 757–764. [Google Scholar] [PubMed]
- Hill, A.V.; Lupton, H. Muscular Exercise, Lactic Acid, and the Supply and Utilization of Oxygen. QJM Int. J. Med. 1923, 62, 135–171. [Google Scholar] [CrossRef]
- Ferrar, K.; Evans, H.; Smith, A.; Parfitt, G.; Eston, R. A Systematic Review and Meta-Analysis of Submaximal Exercise-Based Equations to Predict Maximal Oxygen Uptake in Young People. Pediatr. Exerc. Sci. 2014, 26, 342–357. [Google Scholar] [CrossRef] [PubMed]
- Salin, K.; Auer, S.K.; Rey, B.; Selman, C.; Metcalfe, N.B. Variation in the Link between Oxygen Consumption and ATP Production, and Its Relevance for Animal Performance. Proc. R. Soc. B Biol. Sci. 2015, 282, 20151028. [Google Scholar] [CrossRef] [Green Version]
- Ross, R.; Blair, S.N.; Arena, R.; Church, T.S.; Després, J.-P.; Franklin, B.A.; Haskell, W.L.; Kaminsky, L.A.; Levine, B.D.; Lavie, C.J.; et al. Importance of Assessing Cardiorespiratory Fitness in Clinical Practice: A Case for Fitness as a Clinical Vital Sign: A Scientific Statement From the American Heart Association. Circulation 2016, 134, e653–e699. [Google Scholar] [CrossRef]
- Kodama, S.; Saito, K.; Tanaka, S.; Maki, M.; Yachi, Y.; Asumi, M.; Sugawara, A.; Totsuka, K.; Shimano, H.; Ohashi, Y.; et al. Cardiorespiratory Fitness as a Quantitative Predictor of All-Cause Mortality and Cardiovascular Events in Healthy Men and Women: A Meta-Analysis. JAMA 2009, 301, 2024–2035. [Google Scholar] [CrossRef] [Green Version]
- Salier Eriksson, J.; Ekblom, B.; Andersson, G.; Wallin, P.; Ekblom-Bak, E. Scaling VO2max to Body Size Differences to Evaluate Associations to CVD Incidence and All-Cause Mortality Risk. BMJ Open Sport Exerc. Med. 2021, 7, e000854. [Google Scholar] [CrossRef]
- Bianchetti, G.; Abeltino, A.; Serantoni, C.; Ardito, F.; Malta, D.; De Spirito, M.; Maulucci, G. Personalized Self-Monitoring of Energy Balance through Integration in a Web-Application of Dietary, Anthropometric, and Physical Activity Data. J. Pers. Med. 2022, 12, 568. [Google Scholar] [CrossRef]
- Grant, J.A.; Joseph, A.N.; Campagna, P.D. The Prediction of Vo2max: A Comparison of 7 Indirect Tests of Aerobic Power. J. Strength Cond. Res. 1999, 13, 346–352. [Google Scholar] [CrossRef]
- Dourado, V.Z.; Banov, M.C.; Marino, M.C.; de Souza, V.L.; Antunes, L.D.O.; McBurnie, M.A. A Simple Approach to Assess VT during a Field Walk Test. Int. J. Sports Med. 2010, 31, 698–703. [Google Scholar] [CrossRef]
- Mankowski, R.T.; Michael, S.; Rozenberg, R.; Stokla, S.; Stam, H.J.; Praet, S.F.E. Heart-Rate Variability Threshold as an Alternative for Spiro-Ergometry Testing: A Validation Study. J. Strength Cond. Res. 2017, 31, 474–479. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Zhang, J.; Xie, Y.; Gao, F.; Xu, S.; Wu, X.; Ye, Z. Wearable Health Devices in Health Care: Narrative Systematic Review. JMIR MHealth UHealth 2020, 8, e18907. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, M.H.; Aydin, A.; Brunckhorst, O.; Dasgupta, P.; Ahmed, K. A Review of Wearable Technology in Medicine. J. R. Soc. Med. 2016, 109, 372–380. [Google Scholar] [CrossRef] [PubMed]
- Adesida, Y.; Papi, E.; McGregor, A.H. Exploring the Role of Wearable Technology in Sport Kinematics and Kinetics: A Systematic Review. Sensors 2019, 19, 1597. [Google Scholar] [CrossRef] [Green Version]
- Aroganam, G.; Manivannan, N.; Harrison, D. Review on Wearable Technology Sensors Used in Consumer Sport Applications. Sensors 2019, 19, 1983. [Google Scholar] [CrossRef] [Green Version]
- POLAR. Polar-Fitness-Test-White-Paper.Pdf. Available online: https://www.polar.com/sites/default/files/static/science/white-papers/polar-fitness-test-white-paper.pdf (accessed on 21 April 2022).
- FIRSTBEAT. White_paper_VO2max_30.6.2017.Pdf. Available online: https://assets.firstbeat.com/firstbeat/uploads/2017/06/white_paper_VO2max_30.6.2017.pdf (accessed on 6 April 2022).
- Passler, S.; Bohrer, J.; Blöchinger, L.; Senner, V. Validity of Wrist-Worn Activity Trackers for Estimating VO2max and Energy Expenditure. Int. J. Environ. Res. Public. Health 2019, 16, 3037. [Google Scholar] [CrossRef] [Green Version]
- Kraft, G.L.; Roberts, R.A. Validation of the Garmin Forerunner 920XT Fitness Watch VO2peak Test. Int. J. Innov. Educ. Res. 2017, 5, 63–69. [Google Scholar] [CrossRef]
- APPLE. Using Apple Watch to Estimate Cardio Fitness with VO2Max. 2021, pp. 1–13. Available online: https://www.apple.com/healthcare/docs/site/Using_Apple_Watch_to_Estimate_Cardio_Fitness_with_VO2_max.pdf (accessed on 21 April 2022).
- Bacon, A.P.; Carter, R.E.; Ogle, E.A.; Joyner, M.J. VO2max Trainability and High Intensity Interval Training in Humans: A Meta-Analysis. PLoS ONE 2013, 8, e73182. [Google Scholar] [CrossRef]
- Moore, S.C.; Patel, A.V.; Matthews, C.E.; Berrington de Gonzalez, A.; Park, Y.; Katki, H.A.; Linet, M.S.; Weiderpass, E.; Visvanathan, K.; Helzlsouer, K.J.; et al. Leisure Time Physical Activity of Moderate to Vigorous Intensity and Mortality: A Large Pooled Cohort Analysis. PLoS Med. 2012, 9, e1001335. [Google Scholar] [CrossRef] [Green Version]
- Blair, S.N.; Morris, J.N. Healthy Hearts–and the Universal Benefits of Being Physically Active: Physical Activity and Health. Ann. Epidemiol. 2009, 19, 253–256. [Google Scholar] [CrossRef]
- Joyner, M.J.; Green, D.J. Exercise Protects the Cardiovascular System: Effects beyond Traditional Risk Factors: Exercise Protects the Cardiovascular System. J. Physiol. 2009, 587, 5551–5558. [Google Scholar] [CrossRef] [PubMed]
- Gibala, M.J.; Hawley, J.A. Sprinting Toward Fitness. Cell Metab. 2017, 25, 988–990. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, H.; Monahan, K.D.; Seals, D.R. Age-Predicted Maximal Heart Rate Revisited. J. Am. Coll. Cardiol. 2001, 37, 153–156. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis: Forecasting and Control; Prentice Hall: Englewood Cliff, NJ, USA, 1994; ISBN 978-0-13-060774-4. [Google Scholar]
- Lazzeri, F. Machine Learning for Time Series Forecasting with Python|Wiley. Available online: https://www.wiley.com/en-us/Machine+Learning+for+Time+Series+Forecasting+with+Python-p-9781119682387 (accessed on 10 May 2022).
- Francq, C.; Zakoïan, J.M. Bartlett’s Formula for a General Class of Nonlinear Processes. J. Time Ser. Anal. 2009, 30, 449–465. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array Programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Dickey, D.A.; Bell, W.R.; Miller, R.B. Unit Roots in Time Series Models: Tests and Implications. Am. Stat. 1986, 40, 12–26. [Google Scholar] [CrossRef] [Green Version]
- Punj, G.; Steward, D. Cluster analysis in marketing research: Review and suggestions for application. J. Mark. Res. 1983, 20, 134–148. [Google Scholar] [CrossRef]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition; Elsevier: Boston, MA, USA, 2009; ISBN 978-1-59749-272-0. [Google Scholar]
- Zaïane, O.R.; Foss, A.; Lee, C.-H.; Wang, W. On Data Clustering Analysis: Scalability, Constraints, and Validation. In Advances in Knowledge Discovery and Data Mining; Goos, G., Hartmanis, J., van Leeuwen, J., Chen, M.-S., Yu, P.S., Liu, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2336, pp. 28–39. ISBN 978-3-540-43704-8. [Google Scholar]
- Bianchetti, G.; Ciccarone, F.; Ciriolo, M.R.; De Spirito, M.; Pani, G.; Maulucci, G. Label-Free Metabolic Clustering through Unsupervised Pixel Classification of Multiparametric Fluorescent Images. Anal. Chim. Acta 2021, 1148, 238173. [Google Scholar] [CrossRef]
- Bianchetti, G.; Spirito, M.D.; Maulucci, G. Unsupervised Clustering of Multiparametric Fluorescent Images Extends the Spectrum of Detectable Cell Membrane Phases with Sub-Micrometric Resolution. Biomed. Opt. Express 2020, 11, 5728–5744. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Grouping Multidimensional Data; Kogan, J.; Nicholas, C.; Teboulle, M. (Eds.) Springer: Berlin/Heidelberg, Germany, 2006; ISBN 978-3-540-28348-5. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. How Slow Is the k-Means Method? In Proceedings of the Twenty-Second Annual Symposium on Computational Geometry-SCG’06, Sedona, AZ, USA, 5–7 June 2006; ACM Press: New York, NY, USA, 2006; p. 144. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing Partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009; ISBN 978-1-4414-1269-0. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. Mach. Learn. 2011, 12, 2825–2830. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Recurrence Quantification Analysis: Theory and Best Practices; Webber, C.L.; Marwan, N. (Eds.) Understanding Complex Systems; Springer International Publishing: Cham, Switzerland, 2015; ISBN 978-3-319-07154-1. [Google Scholar]
- Marwan, N.; Carmen Romano, M.; Thiel, M.; Kurths, J. Recurrence Plots for the Analysis of Complex Systems. Phys. Rep. 2007, 438, 237–329. [Google Scholar] [CrossRef]
- Zbilut, J.P.; Thomasson, N.; Webber, C.L. Recurrence Quantification Analysis as a Tool for Nonlinear Exploration of Nonstationary Cardiac Signals. Med. Eng. Phys. 2002, 24, 53–60. [Google Scholar] [CrossRef]
- Zimatore, G.; Cavagnaro, M. Recurrences Analysis of Otoacoustic Emissions. In Recurrence Quantification Analysis; Chapter 8: Theory and Best Practices; Webber, C., Marwan, N., Eds.; Springer: Cham, Switzerland, 2015; pp. 253–278. [Google Scholar]
- Zimatore, G.; Cavagnaro, M.; Skarzynski, P.H.; Fetoni, A.R.; Hatzopoulos, S. Detection of Age-Related Hearing Losses (ARHL) via Transient-Evoked Otoacoustic Emissions. Clin. Interv. Aging 2020, 15, 927–935. [Google Scholar] [CrossRef]
- Zimatore, G.; Gallotta, M.C.; Innocenti, L.; Bonavolontà, V.; Ciasca, G.; De Spirito, M.; Guidetti, L.; Baldari, C. Recurrence Quantification Analysis of Heart Rate Variability during Continuous Incremental Exercise Test in Obese Subjects. Chaos Woodbury N 2020, 30, 033135. [Google Scholar] [CrossRef]
- Zimatore, G.; Falcioni, L.; Gallotta, M.C.; Bonavolontà, V.; Campanella, M.; De Spirito, M.; Guidetti, L.; Baldari, C. Recurrence Quantification Analysis of Heart Rate Variability to Detect Both Ventilatory Thresholds. PLoS ONE 2021, 16, e0249504. [Google Scholar] [CrossRef]
- Marwan, N.; Zou, Y.; Wessel, N.; Riedl, M.; Kurths, J. Estimating Coupling Directions in the Cardiorespiratory System Using Recurrence Properties. Philos. Transact. A Math. Phys. Eng. Sci. 2013, 371, 20110624. [Google Scholar] [CrossRef] [Green Version]
- Marwan, N.; Donges, J.F.; Zou, Y.; Donner, R.V.; Kurths, J. Complex Network Approach for Recurrence Analysis of Time Series. Phys. Lett. A 2009, 373, 4246–4254. [Google Scholar] [CrossRef] [Green Version]
- Zolotova, N.V.; Ponyavin, D.I. Synchronization in Sunspot Indices in the Two Hemispheres. Sol. Phys. 2007, 243, 193–203. [Google Scholar] [CrossRef]
- Zimatore, G.; Garilli, G.; Poscolieri, M.; Rafanelli, C.; Gizzi, F.T.; Lazzari, M. The Remarkable Coherence between Two Italian Far Away Recording Stations Points to a Role of Acoustic Emissions from Crustal Rocks for Earthquake Analysis. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 043101. [Google Scholar] [CrossRef] [PubMed]
- Orlando, G.; Zimatore, G. Recurrence Quantification Analysis on a Kaldorian Business Cycle Model. Nonlinear Dyn. 2020, 100, 785–801. [Google Scholar] [CrossRef]
- Orlando, G.; Zimatore, G. Business Cycle Modeling between Financial Crises and Black Swans: Ornstein-Uhlenbeck Stochastic Process vs Kaldor Deterministic Chaotic Model. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 083129. [Google Scholar] [CrossRef]
- Crowley, P.M.; Schultz, A. Measuring the intermittent synchronicity of macroeconomic growth in Europe. Int. J. Bifurc. Chaos 2011, 21, 1215–1231. [Google Scholar] [CrossRef]
- Rawald, T.; Sips, M.; Marwan, N. PyRQA—Conducting Recurrence Quantification Analysis on Very Long Time Series Efficiently. Comput. Geosci. 2017, 104, 101–108. [Google Scholar] [CrossRef]
- Hawley, J.A.; Lundby, C.; Cotter, J.D.; Burke, L.M. Maximizing Cellular Adaptation to Endurance Exercise in Skeletal Muscle. Cell Metab. 2018, 27, 962–976. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clusters | Post-Hoc Comparison | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Features | Black +/+ (n = 172) 1 | Blue −/+ (n = 179) 1 | Green +/− (n = 131) 1 | Yellow −/− (n = 149) 1 | p-Value2 (Kruskall) | +/+ vs. | −/+ vs. | +/− vs. | |||
| −/+ | +/− | −/− | +/− | −/− | −/− | ||||||
| HR mean (bpm) | 162.44 ± 8.33 | 163.33 ± 8.64 | 163.97 ± 8.89 | 161.95 ± 9.89 | 0.47 | ||||||
| V mean (km/h) | 9.24 ± 0.81 | 9.21 ± 0.77 | 9.01 ± 0.68 | 9.05 ± 0.79 | 0.21 | ||||||
| HR St. Dev. (bpm) | 1.83 ± 1.05 | 1.99 ± 1.30 | 1.54 ± 0.72 | 2.14 ± 1.30 | 0.06 | ||||||
| V St. Dev. (km/h) | 0.17 ± 0.18 | 0.21 ± 0.14 | 0.19 ± 0.15 | 0.16 ± 0.12 | 0.16 | ||||||
| Z St. Dev. (m) | 1.22 ± 0.85 | 1.10 ± 0.79 | 1.26 ± 0.97 | 1.32 ± 0.88 | 0.43 | ||||||
| ∆E | 1.24 ± 0.46 | −1.29 ± 0.40 | 1.30 ± 0.32 | −1.25 ± 0.52 | <0.0001 (****) | <0.0001 (****) | ns | <0.0001 (****) | 0.004 (**) | ns | <0.001 (***) |
| ΔHR | 1.16 ± 0.52 | 1.13 ± 0.55 | −1.06 ± 0.60 | −1.20 ± 0.58 | <0.0001 (****) | ns | <0.0001 (****) | <0.0001 (****) | <0.0001 (****) | <0.0001 (****) | ns |
| Date | 24 December 2020 | 12 March 2021 | 18 June 2021 | 4 September 2021 |
|---|---|---|---|---|
| VO2max (mL/kg·min) | 31.96 | 34.59 | 36.7 | 38.23 |
| % Cluster −/+ (blue) | 0.16 ± 0.02 | 0.26 ± 0.02 | 0.30 ± 0.02 | 0.32 ± 0.02 |
| % Cluster −/− (black) | 0.29 ± 0.02 | 0.29 ± 0.02 | 0.27 ± 0.02 | 0.19 ± 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serantoni, C.; Zimatore, G.; Bianchetti, G.; Abeltino, A.; De Spirito, M.; Maulucci, G. Unsupervised Clustering of Heartbeat Dynamics Allows for Real Time and Personalized Improvement in Cardiovascular Fitness. Sensors 2022, 22, 3974. https://doi.org/10.3390/s22113974
Serantoni C, Zimatore G, Bianchetti G, Abeltino A, De Spirito M, Maulucci G. Unsupervised Clustering of Heartbeat Dynamics Allows for Real Time and Personalized Improvement in Cardiovascular Fitness. Sensors. 2022; 22(11):3974. https://doi.org/10.3390/s22113974
Chicago/Turabian StyleSerantoni, Cassandra, Giovanna Zimatore, Giada Bianchetti, Alessio Abeltino, Marco De Spirito, and Giuseppe Maulucci. 2022. "Unsupervised Clustering of Heartbeat Dynamics Allows for Real Time and Personalized Improvement in Cardiovascular Fitness" Sensors 22, no. 11: 3974. https://doi.org/10.3390/s22113974
APA StyleSerantoni, C., Zimatore, G., Bianchetti, G., Abeltino, A., De Spirito, M., & Maulucci, G. (2022). Unsupervised Clustering of Heartbeat Dynamics Allows for Real Time and Personalized Improvement in Cardiovascular Fitness. Sensors, 22(11), 3974. https://doi.org/10.3390/s22113974