
A New Multi-Sensor Stream Data Augmentation Method for Imbalanced Learning in Complex Manufacturing Process


Abstract
:1. Introduction
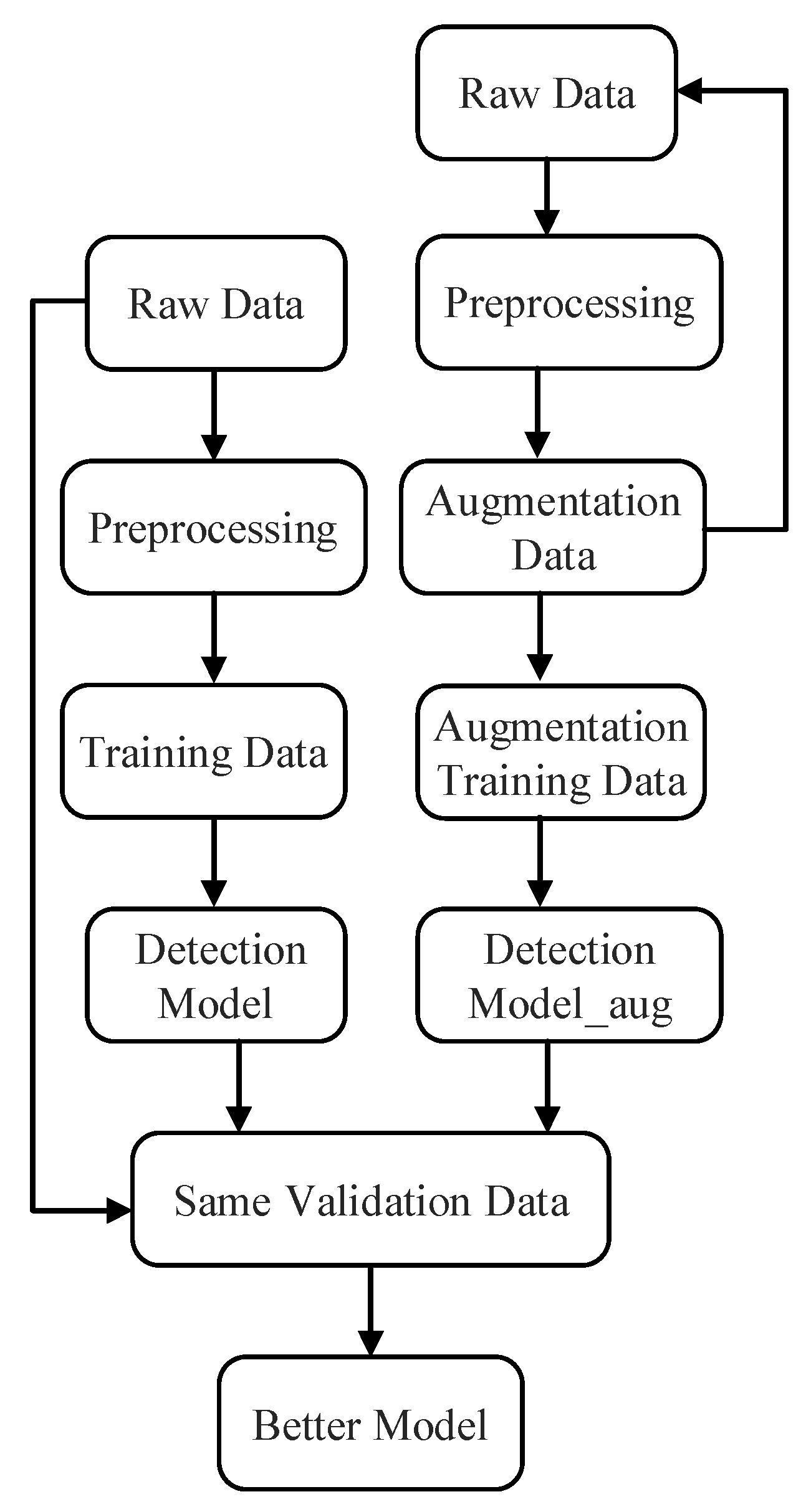
2. The Proposed Data Augmentation Method for Multi-Sensor Stream Data
2.1. The Basics of Method
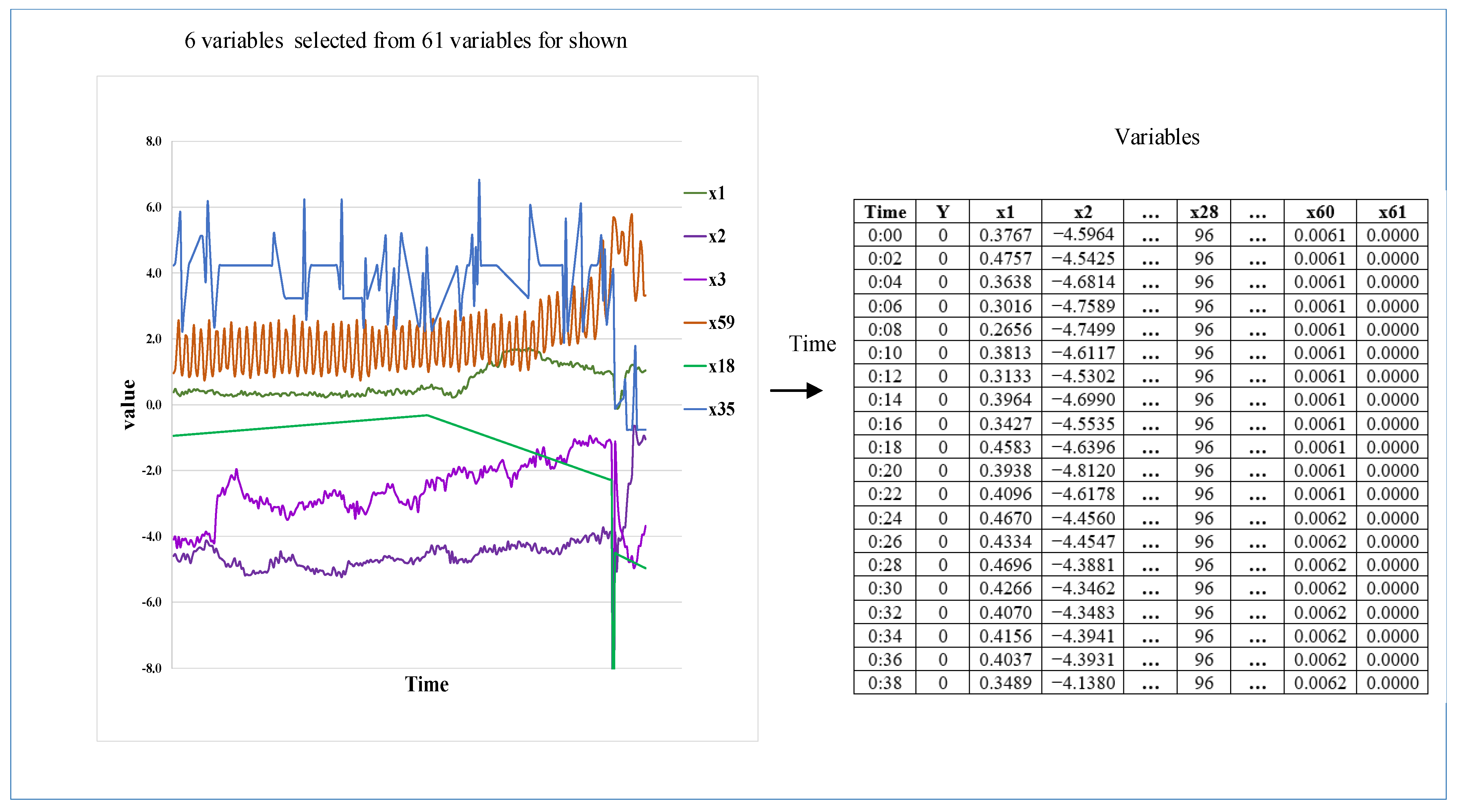
2.1.1. The Matrix Representation of Imbalanced Stream Data
2.1.2. Singular Value Decomposition of Multivariate Stream Data Matrix
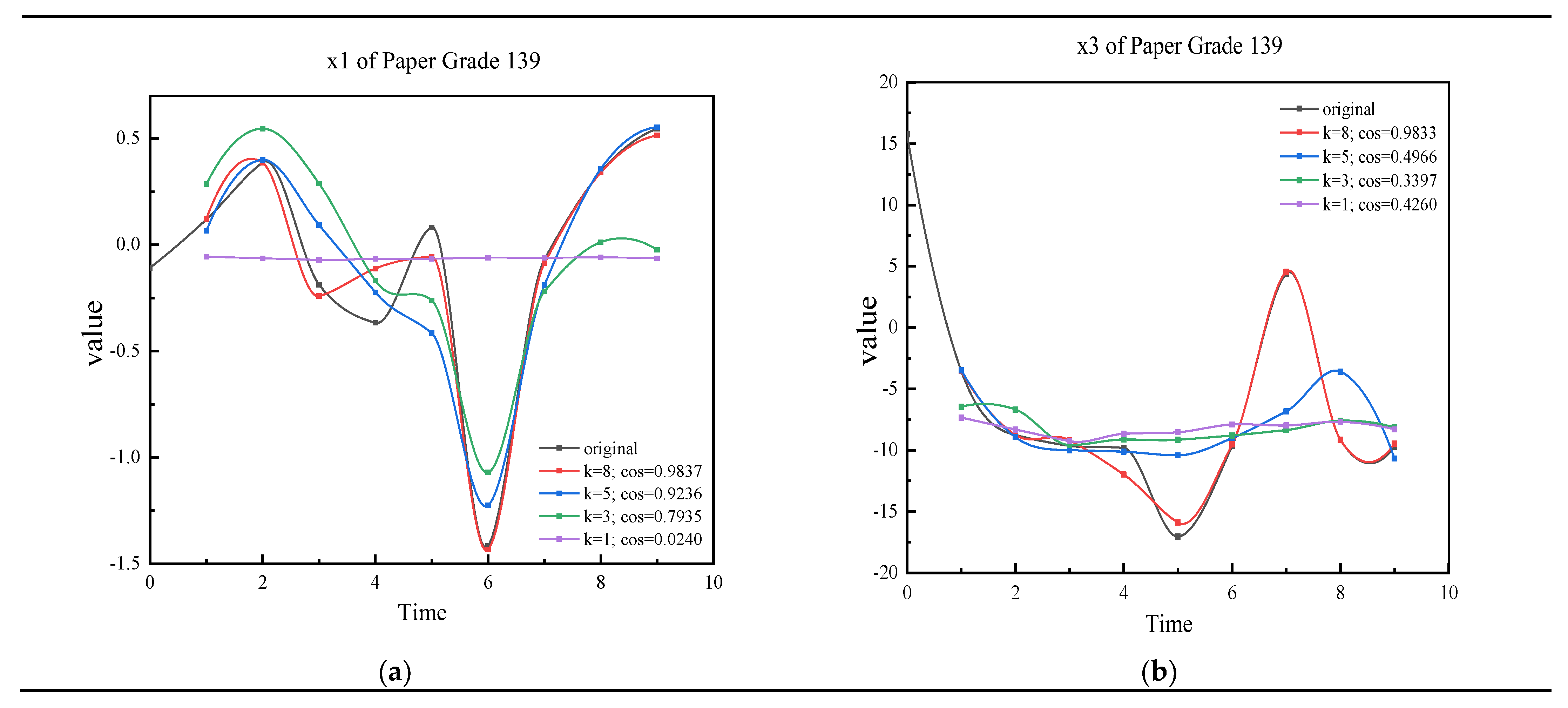
2.1.3. Cosine Similarity of Vectors
2.2. The IMSDA Method
| Algorithm 1: The method of IMSDA |
| Input: Raw imbalanced multi-sensor stream data labeled by failure (y = 1) or normal (y = 0). The variables (sensors) are is the number of variables (sensors). Output: Augmented data for the minority class (y = 1). Step 1: Perform raw dataset preprocessing like normalization and delete some categorical variables which cannot be modeled. Store the processed data into a matrix, denoted as , which has m samples and n variables. The variables can be represented by . Step 2: The failure data and normal data can be treated as two classes. Calculate the degree of class imbalance. Step 3: If d < , where is the preset threshold for the maximum tolerated degree of class imbalance, then: a. calculate the number of augmented data samples that needed to be generated from the minority class (failure class): b. If , that means that the number of failure samples is bigger than the number of variables, then: divide it into several smaller parts , where . If or , that means that the number of failure samples is smaller than the number of variables, then: perform singular value decomposition of the multi-sensor stream data matrix. c. Calculate cosine similarity matrix. The element of the matrix is calculated by: d. Check the value of cos, and we can define a threshold costhreshold according to that. In practice, the value of cosine similarity is close to the correlation. We can also plot the data to check the difference between the curves of augmented data and original data intuitively. Thus, the size of k is decided. These data are treated as the augmented data. Step 4. Calculate the imbalance degree: Step 5: Add the augmented data to the original data for supervised learning algorithm training. |
3. Real Manufacturing Process Case Study
3.1. The Description of the Case
3.2. Results of Data Augmentation Method IMSDA
3.3. The Results of Supervised Failure Detection
3.3.1. The Performance Metrics in Imbalanced Learning
3.3.2. The Supervised Failure Detection Models Trained by Augmentation Data
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Andrew, N. Available online: https://www.youtube.com/watch?v=06-AZXmwHjo (accessed on 30 March 2021).
- Wang, J.; Xu, C.; Zhang, J.; Zhong, R. Big data analytics for intelligent manufacturing systems: A review. J. Manuf. Syst. 2021, 62, 738–752. [Google Scholar] [CrossRef]
- Gontijo-Lopes, R.; Smullin, S.J.; Cubuk, E.D.; Dyer, E. Affinity and Diversity: Quantifying Mechanisms of Data Augmentation. arXiv 2020, arXiv:2002.08973v2. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time Series Data Augmentation for Deep Learning: A Survey. Int. Jt. Conf. Artif. Intell. Organ. 2021, 5, 4653–4660. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.-F. Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images. Symmetry 2020, 12, 1822. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.-F. Environmental sound classification using a regularized deep convolutional neural network with data augmentation. Appl. Acoust. 2020, 167, 107389. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wei, J.; Huang, H.; Yao, L.; Hu, Y.; Fan, Q.; Huang, D. New imbalanced fault diagnosis framework based on Cluster-MWMOTE and MFO-optimized LS-SVM using limited and complex bearing data. Eng. Appl. Artif. Intell. 2020, 96, 103966. [Google Scholar] [CrossRef]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Knowledge Discovery in Databases: PKDD 2003; Lavrač, N., Gamberger, D., Todorovski, L., Blockeel, H., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2838, pp. 107–119. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.; Viktor, H.L. Learning from imbalanced data sets with boosting and data generation. ACM Sigkdd Explor. Newsl. 2004, 6, 30–39. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Li, T.; Li, B.; Lan, X. SP-SMOTE: A novel space partitioning based synthetic minority oversampling technique. Knowl.-Based Syst. 2021, 228, 107269. [Google Scholar] [CrossRef]
- Liang, X.; Jiang, A.; Li, T.; Xue, Y.; Wang, G. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl.-Based Syst. 2020, 196, 105845. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. SMOTE based class-specific extreme learning machine for imbalanced learning. Knowl.-Based Syst. 2020, 187, 104814. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef] [Green Version]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal-trend decomposition procedure based on loess. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Wen, Q.; Gao, J.; Song, X.; Sun, L.; Xu, H.; Zhu, S. RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series. Proc. Conf. AAAI Artif. Intell. 2019, 33, 5409–5416. [Google Scholar] [CrossRef] [Green Version]
- Bergmeir, C.; Hyndman, R.; Benitez, J.M. Bagging exponential smoothing methods using STL decomposition and Box–Cox transformation. Int. J. Forecast. 2016, 32, 303–312. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Song, X.; Wen, Q.; Wang, P.; Sun, L.; Xu, H. RobustTAD: Robust time series anomaly detection via decomposition and convolutional neural networks. arXiv 2020, arXiv:2002.09545v1. [Google Scholar]
- Wang, X.; Jing, L.; Lyu, Y.; Guo, M.; Zeng, T. Smooth Soft-Balance Discriminative Analysis for imbalanced data. Knowl.-Based Syst. 2020, 228, 106604. [Google Scholar] [CrossRef]
- Zhang, C.; Bi, J.; Xu, S.; Ramentol, E.; Fan, G.; Qiao, B.; Fujita, H. Multi-Imbalance: An open-source software for multi-class imbalance learning. Knowl.-Based Syst. 2019, 174, 137–143. [Google Scholar] [CrossRef]
- Oh, C.; Han, S.; Jeong, J. Time-Series Data Augmentation based on Interpolation. Procedia Comput. Sci. 2020, 175, 64–71. [Google Scholar] [CrossRef]
- Conlin, A.; Martin, E.; Morris, A. Data augmentation: An alternative approach to the analysis of spectroscopic data. Chemom. Intell. Lab. Syst. 1998, 44, 161–173. [Google Scholar] [CrossRef]
- Chen, Y.; Kempton, D.J.; Ahmadzadeh, A.; Angryk, R.A. Towards Synthetic Multivariate Time Series Generation for Flare Forecasting. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Virtual, 21–23 June 2021; Volume 12584, pp. 296–307. [Google Scholar] [CrossRef]
- Fons, E.; Dawson, P.; Zeng, X.; Keane, H.; Losifidis, A. Adaptive Weighting Scheme for Automatic Time-Series Data Augmentation. arXiv 2021, arXiv:2102.08310v1. [Google Scholar]
- Saeed, A.; Li, Y.; Ozcelebi, T.; Lukkien, J. Multi-sensor data augmentation for robust sensing. In Proceedings of the 2020 International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; pp. 1–7. [Google Scholar]
- Lu, H.; Du, M.; Qian, K.; He, X.; Wang, K. GAN-based Data Augmentation Strategy for Sensor Anomaly Detection in Industrial Robots. IEEE Sens. J. 2021, 1. [Google Scholar] [CrossRef]
- Safaeipour, H.; Forouzanfar, M.; Casavola, A. A survey and classification of incipient fault diagnosis approaches. J. Process Control 2021, 97, 1–16. [Google Scholar] [CrossRef]
- Gangsar, P.; Tiwari, R. Signal based condition monitoring techniques for fault detection and diagnosis of induction motors: A state-of-the-art review. Mech. Syst. Signal Process. 2020, 144, 106908. [Google Scholar] [CrossRef]
- Guo, Y.; Zhou, Y.; Zhang, Z. Fault diagnosis of multi-channel data by the CNN with the multilinear principal component analysis. Measurement 2021, 171, 108513. [Google Scholar] [CrossRef]
- Jian, C.; Yang, K.; Ao, Y. Industrial fault diagnosis based on active learning and semi-supervised learning using small training set. Eng. Appl. Artif. Intell. 2021, 104, 104365. [Google Scholar] [CrossRef]
- Uraikul, V.; Chan, C.W.; Tontiwachwuthikul, P. Artificial intelligence for monitoring and supervisory control of process systems. Eng. Appl. Artif. Intell. 2007, 20, 115–131. [Google Scholar] [CrossRef]
- Ranjan, C. Understanding Deep Learning: Application in Rare Event Prediction, 1st ed.; Connaissance Publishing: Atlanta, GA, USA, 2020. [Google Scholar]
- Park, P.; Di Marco, P.; Shin, H.; Bang, J. Fault Detection and Diagnosis Using Combined Autoencoder and Long Short-Term Memory Network. Sensors 2019, 19, 4612. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Yu, K.-M.; Chen, Y.-C.; Hsu, H.-P. A Hybrid Feature Selection Method RFSTL for Manufacturing Quality Prediction Based on a High Dimensional Imbalanced Dataset. IEEE Access 2021, 9, 29719–29735. [Google Scholar] [CrossRef]
- Lee, W.; Seo, K. Early failure detection of paper manufacturing machinery using nearest neighbor-based feature extraction. Eng. Rep. 2020, 3, e12291. [Google Scholar] [CrossRef]
- Zhang, D.; Xu, B.; Wood, J. Predict failures in production lines: A two-stage approach with clustering and supervised learning. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 2070–2074. [Google Scholar] [CrossRef]
- Zhang, C.; Yan, H.; Lee, S.; Shi, J. Multiple profiles sensor-based monitoring and anomaly detection. J. Qual. Technol. 2018, 50, 344–362. [Google Scholar] [CrossRef]
- Strang, G. Introduction to Linear Algebra, 4th ed.; Wellesley–Cambride Press: Wellesley, MA, USA, 2009. [Google Scholar]
- Xu, D.; Zhang, Z.; Shi, J. Training Data Selection by Categorical Variables for Better Rare Event Prediction in Multiple Products Production Line. Electronics 2022, 11, 1056. [Google Scholar] [CrossRef]
- Ranjan, C.; Reddy, M.; Mustonen, M.; Paynabar, K.; Pourak, K. Data Challenge: Data Augmentation for Rare Events in Multivariate Time series. arXiv 2019, arXiv:1809.10717v4. [Google Scholar]
- Mercangoz, M.; Doyle, F. Model-based control in the pulp and paper industry. IEEE Control Syst. 2006, 26, 30–39. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The field of real numbers | |
| Multivariate time series | |
| Matrix (multivariate time series for special time) | |
| Matrix | |
| Diagonal matrix | |
| Matrix | |
| Left-singular vectors | |
| Singular value | |
| Right-singular vectors | |
| Cosine similarity (threshold) | |
| The degree of class imbalance | |
| The desired balance level | |
| The size of augmented data | |
| The rows of the matrix | |
| The columns of the matrix (the number of variables) |
| Paper Grade | Normal | Failure | The Degree of Class Imbalance |
|---|---|---|---|
| 96 * | 6502 | 72 | 0.0111 |
| 82 | 4360 | 18 | 0.0041 |
| 118 | 2631 | 15 | 0.0057 |
| 139 | 1797 | 10 | 0.0056 |
| 112 | 1230 | 5 | 0.0041 |
| Paper Grade | Normal | Abnormal | The Degree of Class Imbalance | ||
|---|---|---|---|---|---|
| 96 * | 0.5 | 18–35 | 6502 | 1332 | 0.2049 |
| 82 | 0.5 | 14–17 | 4360 | 86 | 0.0197 |
| 118 | 0.5 | 10–14 | 2631 | 85 | 0.0323 |
| 139 | 0.5 | 6–9 | 1797 | 46 | 0.0256 |
| 112 | 0.5 | 4 | 1230 | 9 | 0.0073 |
| k = 9 | k = 8 | k = 7 | k = 6 | k = 5 | k = 4 | k = 3 | k = 2 | k = 1 | |
|---|---|---|---|---|---|---|---|---|---|
| x1 | 1.0000 | 0.9837 | 0.9522 | 0.9521 | 0.9236 | 0.9020 | 0.7935 | 0.6554 | 0.0240 |
| x2 | 1.0000 | 0.9979 | 0.9915 | 0.5518 | 0.3680 | 0.3487 | 0.3567 | 0.2287 | 0.2072 |
| x3 | 1.0000 | 0.9883 | 0.8937 | 0.5886 | 0.4966 | 0.3556 | 0.3397 | 0.4897 | 0.4260 |
| ⁝ | ⁝ | ⁝ | ⁝ | ⁝ | ⁝ | ⁝ | ⁝ | ⁝ | ⁝ |
| x60 | 1.0000 | 0.9860 | 0.9800 | 0.9114 | 0.8948 | 0.8915 | 0.5730 | 0.3125 | 0.5484 |
| Notation | Description |
|---|---|
| Accuracy | (TP + TN)/(TP + FP + TN + FN) |
| Recall | TP/(TP + FN) |
| Precision | TP/(TP + FP) |
| F1 score | 2 × Precision × Recall/(Precision + Recall) |
| Rank | Parameters | Values |
|---|---|---|
| 1 | cv(cross-validation) | 5 |
| 2 | * Random-state | 0 |
| 3 | Max_iter | 10,000 |
| 4 | Train dataset | 0.6 |
| 5 | Test dataset | 0.2 |
| 6 | Validation dataset | 0.2 |
| Paper Grade | Model | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|
| 82 | Original data trained model clf82 | 0.997 | 0.666 | 0.558 | 0.666 |
| Augmentation data trained model clf82_aug | 0.998 | 0.857 | 0.638 | 1 | |
| 96 | Original data trained model clf96 | 0.993 | 0.400 | 0.340 | 0.330 |
| Augmentation data trained model clf96_aug | 0.995 | 0.530 | 0.542 | 0.444 | |
| 112 | Original data trained model clf112 | 0.996 | 0.004 | 0 | 0 |
| Augmentation data trained clf112_aug | 1 | 1 | 1 | 1 | |
| 118 | Original data trained model clf118 | 0.991 | 0 | 0.035 | 0 |
| Augmentation data trained model clf118_aug | 0.998 | 0.909 | 0.998 | 1 | |
| 139 | Original data trained model clf139 | 0.994 | 0 | 0.02 | 0 |
| Augmentation data trained model clf139_aug | 1 | 1 | 1 | 1 |
| Rank | Parameters | Values |
|---|---|---|
| 1 | Random-state | 0 |
| 2 | Train dataset | 0.8 |
| 3 | Test dataset | 0.2 |
| Paper Grade | Model | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|
| 82 | Original data trained model rf82 | 0.997 | 0.571 | 0.667 | 0.500 |
| Augmentation data trained model rf82_aug | 0.995 | 1.000 | 0.500 | 1.000 | |
| 96 | Original data trained model rf96 | 0.995 | 0.769 | 0.833 | 0.714 |
| Augmentation data trained model rf96_aug | 0.101 | 1.000 | 0.012 | 1.000 | |
| 112 | Original data trained model rf112 | 0.996 | 1.000 | 0.000 | 0.000 |
| Augmentation data trained model rf112_aug | 0.996 | 1.000 | 0.000 | 0.000 | |
| 118 | Original data trained model rf118 | 0.994 | 0.400 | 1.000 | 0.250 |
| Augmentation data trained model rf118_aug | 0.998 | 1.000 | 1.000 | 0.750 | |
| 139 | Original data trained model crf139 | 1.000 | 1.000 | 1.000 | 1.000 |
| Augmentation data trained rf139_aug | 0.980 | 1.000 | 0.430 | 1.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, D.; Zhang, Z.; Shi, J. A New Multi-Sensor Stream Data Augmentation Method for Imbalanced Learning in Complex Manufacturing Process. Sensors 2022, 22, 4042. https://doi.org/10.3390/s22114042
Xu D, Zhang Z, Shi J. A New Multi-Sensor Stream Data Augmentation Method for Imbalanced Learning in Complex Manufacturing Process. Sensors. 2022; 22(11):4042. https://doi.org/10.3390/s22114042
Chicago/Turabian StyleXu, Dongting, Zhisheng Zhang, and Jinfei Shi. 2022. "A New Multi-Sensor Stream Data Augmentation Method for Imbalanced Learning in Complex Manufacturing Process" Sensors 22, no. 11: 4042. https://doi.org/10.3390/s22114042
APA StyleXu, D., Zhang, Z., & Shi, J. (2022). A New Multi-Sensor Stream Data Augmentation Method for Imbalanced Learning in Complex Manufacturing Process. Sensors, 22(11), 4042. https://doi.org/10.3390/s22114042