1. Introduction
The use of the human face as a biometric means of identification—commonly called “face recognition” [
1]—is currently widely used at the commercial scale, in devices ranging from cellphones to residential gateways [
2], to the point that its use without people’s awareness has been called a threat to personal privacy [
3]. Another potentially very helpful sub-area of face analysis is emotion recognition using facial expressions [
4,
5]. Of course, facial expressions are not direct indicators of subjective emotions for several reasons, starting with faked smiles or other expressions; current pre-trained facial expression recognition systems are unreliable when exposed to different individuals. The latter is why attributing emotions to specific individuals has been signaled as an unethical use of AI in the workplace [
6]. Though many emotion recognition works have explored several cues beyond visual ones (such as speech [
7], body gestures [
8] and others), visual-related facial emotion recognition will remain one of the primary emotion recognition approaches for a long time. Facial expression recognition through visual analysis is certainly poised to make significant strides in the following years, mainly because of its great potential in real-world applications, even when used anonymously, from stores’ shop windows seeing customer reactions to engagement assessment in public events; the area’s financial value is expected to grow to over 40 billion dollars in the next five years.
This paper addresses the problem of automatic facial expression recognition and proposes a method based on information fusion and ML techniques. Our work builds on the previous work of Freitas et al. [
9], which used a variant of visual expression recognition, namely, a set of facial points delivered by a Microsoft Kinect device [
10]. We obtained even better results by applying the information fusion methods described below. The specific application of the dataset we used [
9] was the recognition of facial expressions as a complement to hand and body gestures in sign language—specifically, the “Libra” Brazilian sign language. We will describe below in detail the specific settings and methods of this work to promote reproducibility.
Our proposed method consists of using subsets of the feature vectors mentioned above as independent feature vectors (which we call “perspectives”), from which several instances (one for each subset) of some classifier can learn to predict a facial expression (in terms of class probabilities). The predictions of such cases are processed by using soft voting [
11] for the final decision. This approach has not been proposed previously for facial expression classification. As far as we know, the feature vector elements (coming from the same source) have not been treated as independent feature vectors (as if they came from different sources).
Like many other recent works on facial expression recognition [
12,
13,
14], we leverage machine learning (ML) methods [
15]. Instead of relying on human-defined rules, ML systems are entirely data-driven and can adjust their behavior mainly by training with a different dataset. Nevertheless, most ML works use dataset features as a flat vector (we call this approach “aggregation”), which could be sub-optimal for classification performance. In our previous works [
16,
17], we have explored the use of structured information combination architectures, such as separating the features (columns of the dataset) into groups and then applying hard or soft voting [
11] and other methods for combining the predictions of instances of ML classifiers, one for each feature group. Though it could not be intuitively evident, the use of fusion, as mentioned earlier, gives in some cases substantially better results, in terms of accuracy and other quality indicators, than simple aggregation.
The contributions of this work are twofold: (1) a novel and efficient approach based on information fusion architectures and soft voting for the visual recognition of facial expressions, and (2) this approach improves the indicators of critical performance, such as accuracy and F1-score, compared to other state-of-the-art works, which studied the same dataset as us, as a result of exploiting information fusion architectures and soft voting with subsets of features.
This document is organized as follows: After this introduction,
Section 2 establishes some definitions, and
Section 3 reviews the main related works; then,
Section 4 shows the proposed method; then,
Section 5 presents the experimental methodology, and
Section 6 discusses the results. Finally,
Section 7, draws conclusions and suggests possible future work.
2. Background
This work lies in the intersection of two areas: one is the application area, which is facial expression recognition, and the other one is information fusion architectures for machine learning, which refers to the way input information is structured to get classification performance that is as high as possible. As far as the latter is concerned, we have previously done some work applying fusion architectures to domains such as activity recognition [
17]. However, we were interested in testing our methods in a domain radically different from the activity recognition one, so facial expression recognition was a good candidate. Then, as we mentioned in the introduction, for the facial expression recognition task, we restricted our attention to facial expressions used intended to complement the gestures in sign languages, giving a prosodic component to the sentences [
18,
19]; this is why they have been called “grammatical facial expressions” (GFE). In recent years, GFE has gained importance in automated recognition tasks for sign languages, as they help eliminate confusion among signs [
20]. GFE help with the construction of the meaning and cohesion of what is signed [
9]; for example, they help to construct different types of phrases: questions, relative, affirmative, negative, and conditional.
GFE has been used in data-driven machine learning approaches for various sign languages, such as American (ASL) [
21,
22,
23], German [
24], Czech [
25], and Turkish [
26], among others. In the literature, it has been proposed that a classifier should learn to recognize syntactic-type GFE in “Libras” sign language (Brazilian sign language) using a vector of features composed of distance, angles and deep points, extracted from the points of the contour of the face (which were captured by a deep camera) [
9]. In this paper, we are using the dataset proposed in Freitas’ work.
In addition, GFE has begun to be processed by taking advantage of data fusion techniques [
27], such as, in the context of GFE recognition, combining the outputs of Hidden Markov Models (HMM) [
28] (the probabilities of movements of facial features and movements head) and using them as input to a Support Vector Machine (SVM) [
29], proposed by [
30]. Kumar et al. [
31], for their part, followed a similar approach to the previous one, where they used two HMMs as temporal classifiers to combine their decisions (facial gesture and hand gesture) through the Independent Bayesian Classification Combination (IBCC) method [
32]. In addition, da Silva et al. [
33] presented a model composed of a convolutional neural network [
34] (to obtain the static features of two regions of the face image) and two long-short term memory networks [
35] (to add the temporal features to the features of each face region), which ultimately merge their outputs for a final decision. Additionally, Neidle [
36] described a majority voting strategy [
11] that combines the SVM classifier trained with the eye and eyebrow region features and the angle of 100 inclination of the head. However, although these fusion techniques have shown promising results in GFE recognition, the use of information fusion techniques has been ad hoc and not systematic. We found no works that use such techniques in the particular case of Libras GFE recognition. In the context of GFE recognition, although the knowledge acquired in one sign language can be considered in others, it is necessary to study each of them separately, as they have their particularities [
9]. The GFE facial expression set is specific for each signal language.
The GFEs we are considering in this paper aim to identify different types of sentences [
37], which are the nine following ones used in the sign language of Libra [
37,
38,
39]:
WH question—phrases (such as who, when, why, how, and where) expressed by a slight elevation of the head, accompanied by lines drawn on the forehead.
Yes/No question—interrogative sentences (in which there is a Yes or No answer) expressed with the head down and the eyebrows raised.
Doubt question—sentences (showing distrust) expressed by compressing the lips, closing the eyes more, drawing lines on the forehead, and tilting the shoulders to one side or back.
Negation—sentences (constructed with elements no, nothing, never) are drawn by lowering the corners of the mouth, accompanied by lowering of the eyebrows and lowering of the head, or a side-to-side movement of the head.
Affirmative—phrases (that transmit ideas or affirmative actions) are expressed by moving the head up and down.
Conditional—clauses (indicating that a condition must be met to do something) characterized by tilting the head and raising the eyebrows, followed by a set of markers that can express a negative or affirmative GFE.
Relative—clauses (that add phrases either to explain something, add information, or insert another relative, interrogative sentence) are presented by raising eyebrows.
Topics—serve to structure speech differently, such as moving an element (topic) of the sentence to the beginning. One way to express these sentences is by raising the eyebrows, moving the head down and to the side, and keeping the eyes wide open.
Focus—Sentences that insert new information into speech, such as contrasting ideas, giving information about something, or highlighting something. These sentences are expressed in the same way as a topic sentence.
2.1. Data Fusion Architectures
The fusion of data from various sources (sensors) emerges from the observation that one data source can compensate for other data sources’ weaknesses, so with the combination of several sensors, it is possible to achieve better reliability, accuracy, flexibility, or combinations of the above; that is why the fusion of information from several sensors is currently used in many systems spanning many domains [
40].
There are many ways to implement the general idea of data fusion. First of all, three different “levels” of fusion have been distinguished [
41,
42]:
Fusion at the “data level” consists of gathering compatible data from sensors that could be different, but the incoming data are of the same type so they can be put together; this form of fusion is aimed at coverage, redundancy reliability, and increasing the amount of data.
In the fusion at the “feature level”, the characteristics (“features”) extracted from different data sources, and usually of various types, are used to complement the other available ones, generally aiming at improving the accuracy or similar prediction quality metrics.
At the “decision level” fusion, several independent predictions are obtained using some of the data or features, and then the partial decisions are combined by an algorithm like voting.
In practical systems, two or all of these fusion levels are often used, being combined in structures called “fusion architectures.” Aguileta [
16] compared, in tasks such as activity recognition, the performance of several fusion architectures, including the following ones:
Raw feature aggregation, which is a kind of baseline with almost no structure: It is simply concatenating the columns of several datasets with compatible rows (there could be some issues to sort out, such as if the clocks of sensors in a time series are not perfectly aligned, if there are missing data from one of the sensors, etc.). Raw feature aggregation is one of the simplest, “no structure” options.
Voting with groups of features by sensor and homogeneous classifier. This architecture takes the features from each sensor and uses them to train a respective ML classifier (in this case, the classifiers are the same, such as random forest, for all sensors); then, we combine the classifier predictions using voting.
Stacking with shuffled features: We shuffle the features randomly, and then we partition them into equal parts, which group the columns of the dataset, and then we train independent (usually similar) classifiers with each group. Then the predictions of each classifier become a feature in a new dataset, for which we train a classifier that we use to make the actual prediction.
The last two architectures are just examples from our previous work [
16]. However, it should be clear that the number of possible architectures is staggering because they are combinations of structural elements, such how we group the features, which classifier are we going to use for each one (and whether or not it should be the same one), how to combine the classifiers’ decisions, and so on.
In this paper, we do not explore the problem of choosing the best architecture for a given dataset, which has been done elsewhere [
16]. However, we do establish that the result, using a non-trivial architecture in the domain we are considering, is better than simple aggregation in terms of performance measures to a statistically significant extent.
2.2. Soft Voting
In the previous subsection, we have mentioned voting inside of fusion architectures, but we must further distinguish between two voting variants: hard and soft voting.
Hard voting, also called simply “voting” or “plurality voting”, is what we usually call “voting”: the choice receiving more votes is the one chosen. However, in “soft voting” there are weights for each vote that are taken into account. A weighted linear average is calculated and compared to a predefined threshold, giving the final result [
43].
In the case of ML systems, the weights usually are taken from the certainty given as a percentage by the classifier about a given decision. Though roughly the certainty is supposed to correspond to a probability, most of the implemented methods in commonly used software packages are not strictly probabilities, so they should be used cautiously.
Section 4 will explain how we use soft voting to achieve better performance than with hard voting.
3. State of the Art
In works addressing GFE recognition related to Libra sign language (using a dataset for Brazilian sign language [
37]), Bhuvan et al. [
44] explored various machine learning algorithms (such as the multi-Layer perceptron (MLP) [
15], the random forest classifier (RFC) [
45], and AdaBoost [
46], among others) to recognize nine GFEs. They performed experiments (with the 100 coordinates
corresponding to facial points stored in the aforementioned dataset) under the user-dependent model (when training and prediction of a classifier are performed with the same subjects) to choose the best algorithm for each GFE. The primary metrics on which they based these choices were the area under the curve (AUC) of the receiver operating characteristic (ROC) [
47] and the F1 score [
48].
Acevedo [
49] applied morphological associative memories (MAMS) [
50] to recognize nine GFE. They performed experiments with the 100 coordinates
corresponding to the facial points stored in the aforementioned dataset for both subjects (one and two). MAMS performance was measured with the % error and its complement (% recognition).
Gafar [
51] proposed a framework to recognize nine GFE. It relies on two algorithms to reduce features and the fuzzy rough nearest neighbor (FRNN) [
52,
53] algorithm (which is based on the k-nearest neighbor [
54] algorithm) for the classification task. These two algorithms (called FRFS-ACO [
55,
56], when used together) are the fuzzy rough feature selection (FRFS) [
57,
58] algorithm and the ant colony optimization (ACO) [
59,
60] algorithm. He performed experiments with the 100 coordinates
corresponding to the facial points stored in the previous dataset for subject one. The framework’s performance, which was compared with others (such as FRFS-ACO with MLP, FRFS-ACO with C4.5 [
61], and FRFS-ACO with fuzzy nearest neighbor (FNN) [
62]), was measured with the accuracy metric [
15].
Uddin [
20] presented an approach based on two methods (AdaBoost and RFC) to recognize nine GFE. The AdaBoost feature selection algorithm was used to reduce features and RFC for the classification task. He performed experiments with the 100 coordinates
corresponding to the facial points stored in the previous dataset for subject one and subject two. The approach performance was measured with the AUC-ROC metric.
Freitas et al. [
9] used MLP to recognize nine GFEs. They performed experiments with the 100 coordinates
corresponding to the facial points stored in the previous dataset for both subjects (one and two). These experiments mainly involved creating a feature vector (composed of the distances, angles, and coordinates, extracted from said points), different sliding window [
63] sizes to add the time feature to said feature vector, and various training and testing strategies. Based on the user-dependent model and the user-independent model (when training and predictions of a classifier are carried out with the different subjects), some examples of these strategies are (1) training and validation with subject one or two and testing with subject one or two, and (2) training and validation with subjects one and two and testing with the same two subjects. MLP was measured with the F1 score.
Cardoso et al. [
64] classified six GFEs using MLP. They used eight points
of the face, which together with the distances between them, formed the characteristics of the GFE. For the experiment, they used the user-dependent model and the user-independent mode. The results of the experiments were presented as accuracy.
Our work differs from previous work, as we consider different subsets of the feature vector (extracted from the Libra sign dataset) as independent feature vectors to take advantage of fusion techniques (such as soft voting). As we have shown, such a strategy has not been explored in previous works. Additionally, in user-dependent experiments (see
Section 5), we used the same sliding window size for all GFE studied here, unlike previous works.
4. Method and Materials
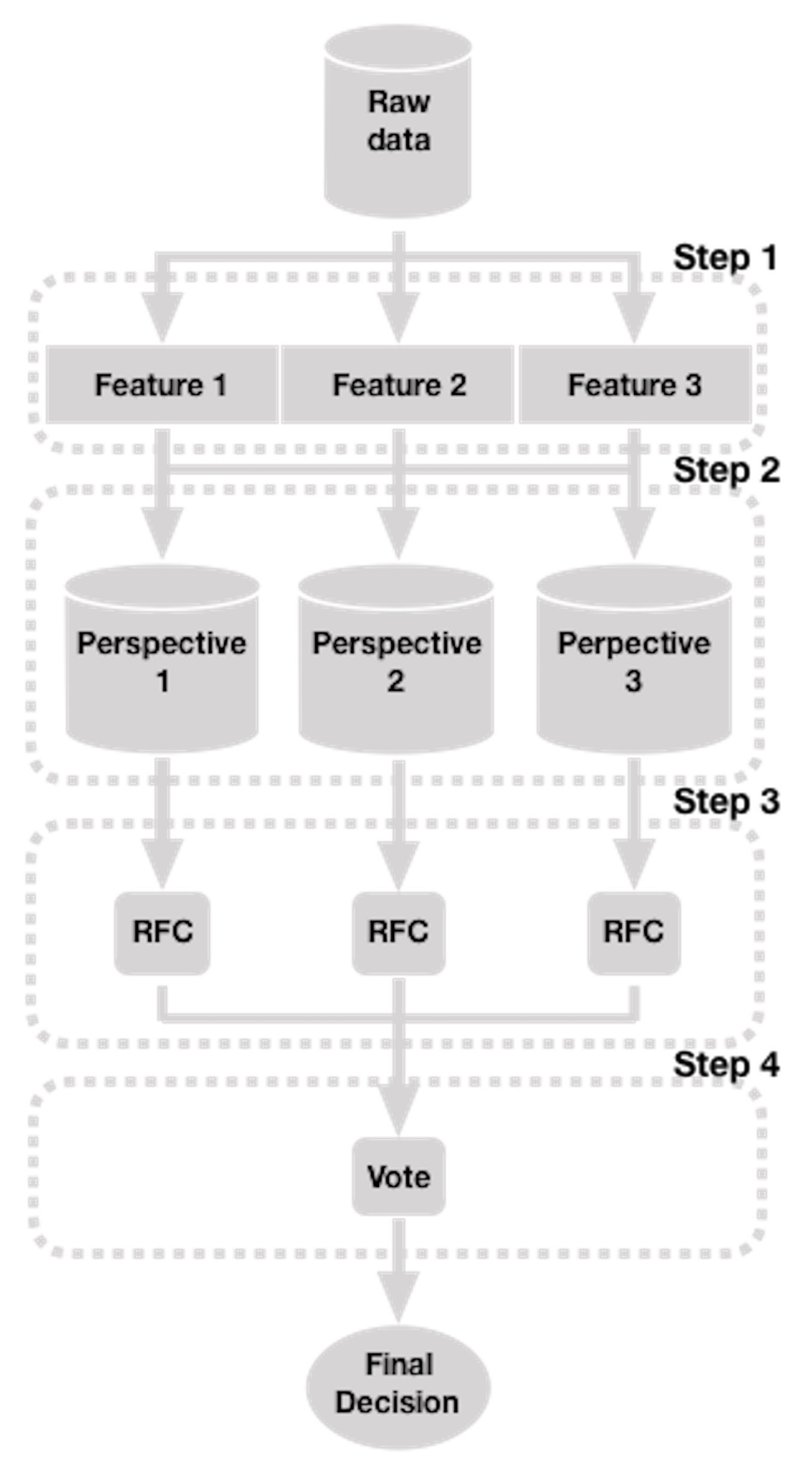
The approach we propose is illustrated in
Figure 1. It takes advantage of the data fusion strategy in a context where a sequence of data over time maintains a meaning for a given period, such as GFE. This approach consists of four steps that we describe below:
In step 1, we extract from the raw data (for example, the
X,
Y, and
Z coordinates that represent the human face in each unit of time, for a given period of time) three features (such as distances, angles, and
Zs, which have been used with good results in this task [
37]). Formally, let
be a set of
n points that represent a facial expression with
for
. Then, taking the
X and
Y of some
points, we define a set of pairs of points (from which we calculate the Euclidean distances) as
for a given
l, where
for
. Therefore, the Euclidean distance feature is defined as the set
where the Euclidian distance
(see Equation (
1)).
Additionally, taking the
X and
Y of the
points, we define a set, whose elements are formed by three points, from which we calculate angles. This set is
for
, where
for
. Therefore, the angle feature is defined as the set
, where
(see Equation (
2)).
Taking as reference the non-repeated PP points, we take their corresponding Zs located in the FE set and define the set , which corresponds to the third feature, where .
In step 2, by adding the temporal characteristic to the features we defined above, we create three sets of features or “perspectives” (as we call them). The temporal characteristic is added to these features by observing a series of consecutive facial expressions in time, which slide one expression at a time (“sliding window” procedure [
37]), where a GFE is supposed to occur. Formally, let
be the size of the window of the facial expressions (the number consecutive facial expressions included in a window) and
the number of facial expressions. Then, the first “perpective” is defined by
with the set
defined in Equation (
3),
The second “perspective” is defined by
with the set
defined in Equation (
4),
The third “perspective” is defined by
with the set
defined in Equation (
5),
In the set, set, and set, the set is the set calculated with the points extracted from in the time . Additionally, the set is the set calculated with the points extracted from in the time . The set is the set referenced by the points extracted from in the time .
In step 3, we learn to predict a GFE from three classifiers (such as RFC), one for each “perspective” (, , and ). Here, the set, together with its corresponding labels , are the input for a RFC instance, which predicts the probability of a GFE label. Similarly, the and sets, and their corresponding set of labels and , respectively, are the inputs of independent RFC instances, which predict the probability of the tag of the same previous expression. Here, is the probability of the class (for a binary classification) predicted by the classifier (for the three classifiers).
Finally, in step 4, the final decision,
, is taken by soft voting of the predictions of the classifiers of the previous step using Equation (
6) [
11]:
where
is the weight of the
jth RFC instance. In this case the weights are taken uniformly because we use the same classification algorithm (RFC) instances.
7. Conclusions
This paper proposed an improved method for recognizing facial expressions, among a collection of nine GFEs of the Brazilian sign language (Libras), from the visual face information composed of points delivered by a Kinect sensor. Our method is based on an information fusion approach which groups in a multi-view fashion the features (extracted from diverse points of the face) and then applies a decision-making architecture based on soft-voting to the outputs of various RFC instances. Thus, each view (one subset of the feature set) is used to train a classifier instance, and the prediction outputs of several instances are voted for the final decision of the GFE.
The results we presented in this paper show that our method is efficient and has better performance (considering three metrics: F1-score, accuracy, and ROC-AUC) than other state-of-the-art methods for the dataset considered.
Based on the results of the user-independent experiments and the user-dependent experiments’ results, we can make the claim of superior performance and hence an advance in recognizing facial expressions, at least for the dataset we considered (using Libras sign language), by using the multi-view architecture that we have also used in other domains, in combination with soft voting. We view this as an original contribution.
Our future work will address a more general problem of emotion recognition from the recognition of facial expressions, which of course, would have a greater commercial and social impact than the case of sign language, and some privacy implications that are better to consider from the initial design of the technology rather than making them an afterthought.


 ,
, 



{kind=link}