
A Novel Auto-Synthesis Dataset Approach for Fitting Recognition Using Prior Series Data


Abstract
:1. Introduction
- Formulating the data synthesis rules based on prior series data. The prior series data are derived from complex working conditions; therefore, the synthesis rule possesses the characteristics of these working conditions.
- Integrating advanced virtual 3D technology to render 2D images. Synthetic images would not be subject to topographic restrictions such as real images, reducing the difficulty of acquiring image.
- Proposing a novel auto-synthesis dataset approach for fitting recognition using prior series data. The synthetic dataset with space–time properties generated by this approach is used to train the DL model, making the network easier to learn important features. The training results are biased toward identifying the fittings at the source of the prior information, improving the accuracy rate of target recognition.
2. Proposed Approach
2.1. Prior Series Data
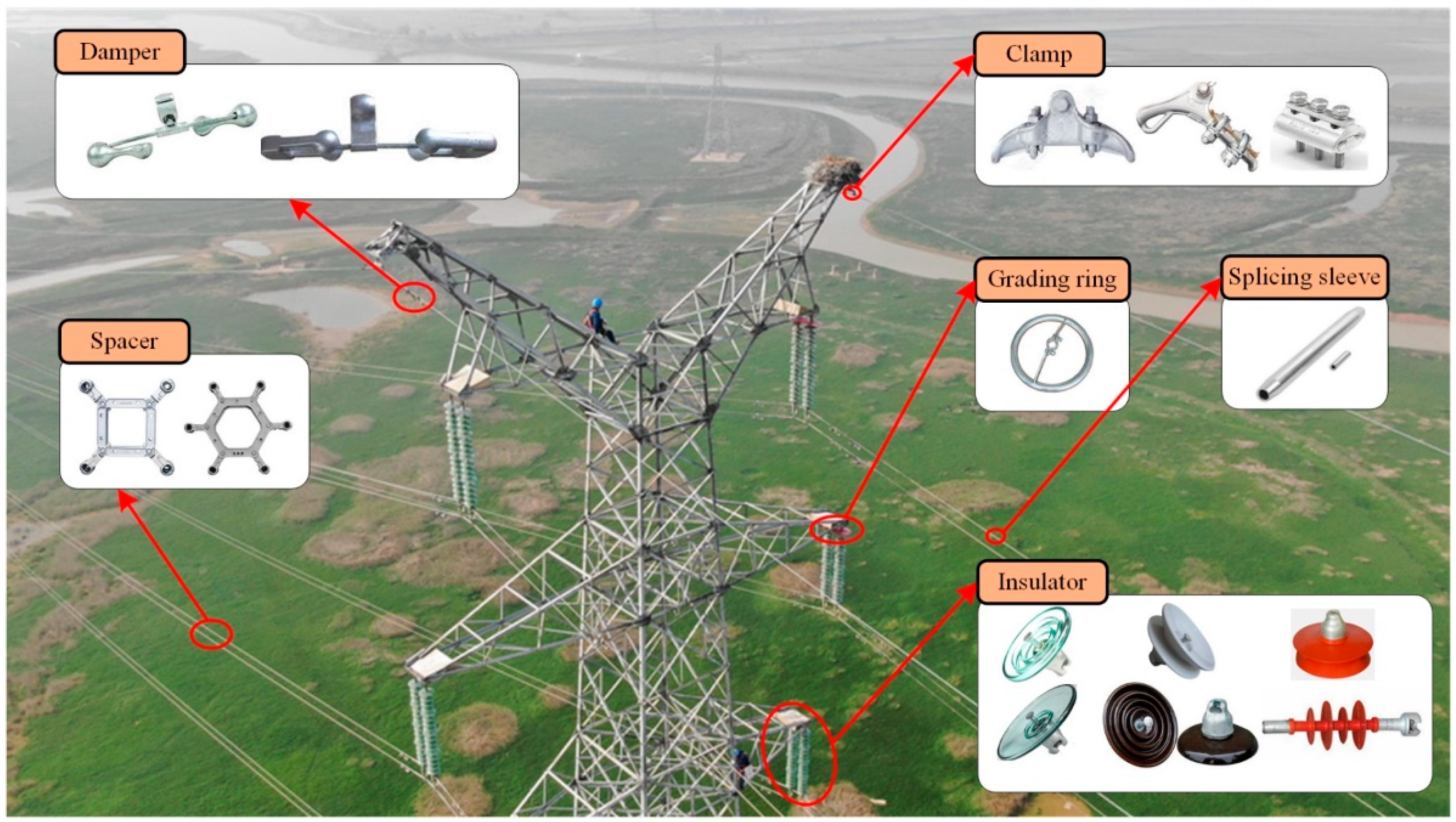
2.1.1. Prior Fitting Series
2.1.2. Prior Inspection-View Series
2.1.3. Prior Topography Series
2.1.4. Prior Time Series
2.2. Auto-Synthesis Dataset
- The 3D model of the insulator pieces with the material information is imported into Blender and the insulator pieces are assembled into insulator strings;
- A camera is created so that the coordinate system of the camera viewpoint coincides with the world coordinate system. The position and the angle of the insulator strings are corrected by the prior inspection-view series and the prior fitting series, and the view angle of the camera is also adjusted;
- Background-free images are outputted, then the high dynamic range images (HDRIs) are imported and adjusted to render images based on the prior time series and the prior topography series;
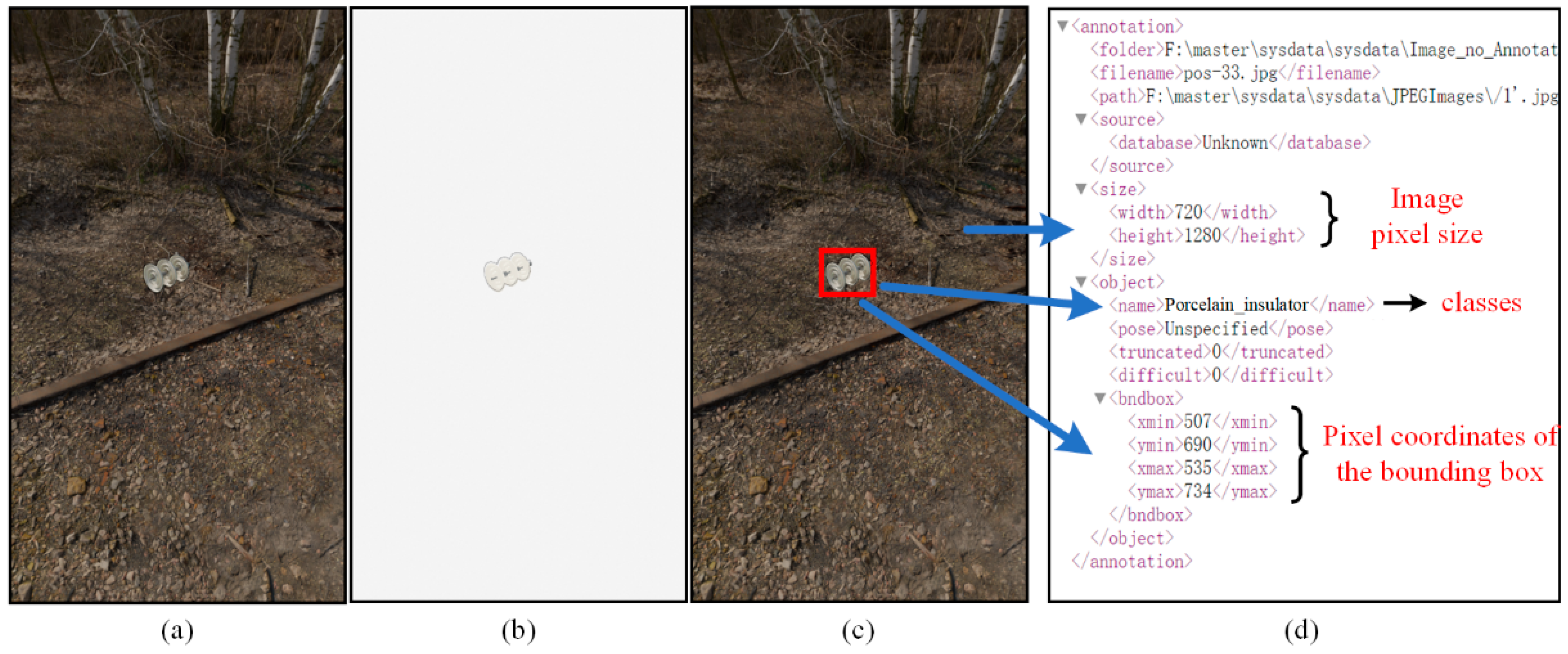
- The background-free image is processed using standard image processing techniques (Python OpenCV library) to generate object bounding boxes and annotate files with basic parameters (position/dimensions);
- A synthetic dataset is generated with images and annotations. The synthetic dataset is divided into a training set and a validation set.
- Ry Rz represents the four-dimensional rotation matrix of insulators,
- β, γ is the rotation angle of each additional generated view.
- Txyz represents the four-dimensional translation matrix of the insulators,
- tx, ty, tz is the translation distance of each additional generated view.
- TF-xyz represents the four-dimensional translation matrix of the insulator in the flying mode.
- t′x, t′y, t′z is the translation distance of each additional generated view relative to the walking mode.
| Algorithm 1. Auto-synthesis dataset algorithm |
| def main(): # Parameter initialization _init_() # Read hdri files hdri_folder = bpy.path.abspath("//hdri") hdri_file = [os.path.join(hdri_folder, f) for f in os.listdir(hdri_folder) if f.endswith(".exr")] # Synthetic dataset for num_insulators in range(starnum_insulators, endnum_insulators): # Assemble insulators according to the number of insulator strings zoom(num_insulators) for hdris in hdri_file: for k in range(1, num_hdri): # Counting num_image += 1 # Loading environment node_environment, node_background, link1 = hdri(hdris) # Adjustment of environmental parameters hdri_adjust() # Mobile insulator move() # Adjusting ambient light light() # Switching the CYCLES rendering engine bpy.context.scene.render.engine = ‘CYCLES’ bpy.context.scene.cycles.device = ‘GPU’ save(Fi0 + str(num_image) + ".png") # Output background-free image bpy.context.scene.render.engine = ‘BLENDER_EEVEE’ bpy.data.worlds["World"].node_tree.nodes["Background"].inputs[1].default_value = 1 clear(node_environment, node_background, link1) save(Fi2 + str(num_image) + ".png") # Clear nodes and cache images, unload hdri bpy.context.scene.world.node_tree.nodes.clear() img_remove() hdri_reload() #Automatic generation of annotation files cv_label() |
2.3. Dataset Evaluation
3. Experiments
3.1. Experiment Description
- (1)
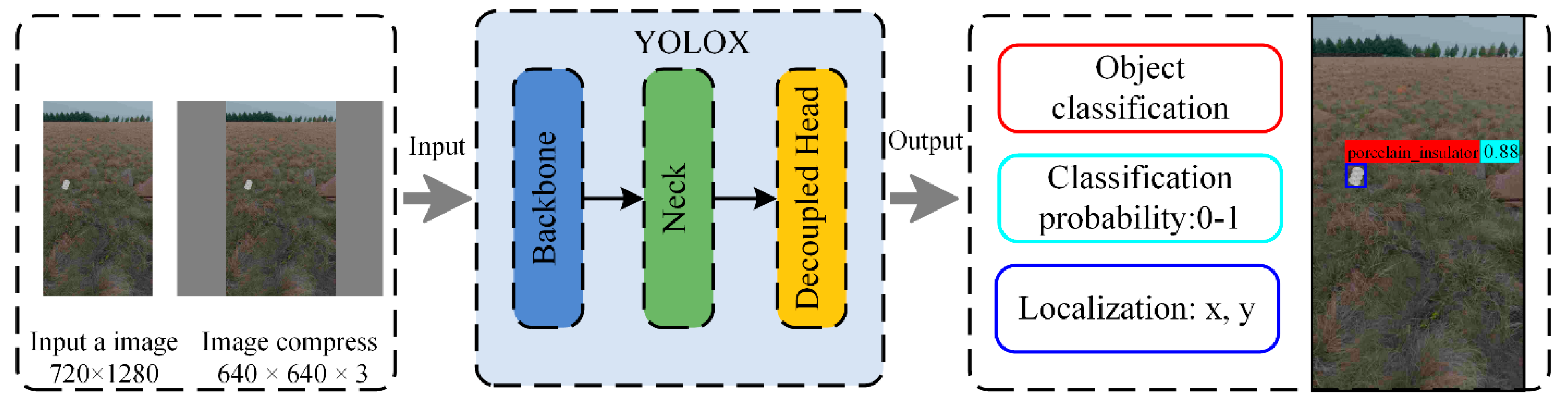
- Dataset: A synthetic dataset of 10,800 images with 720 × 1280 pixels is divided into a training set and a validation set to train a DL model. A dataset of 1200 real images with 2160 × 3840 pixels is used to test the trained DL model. The ratio of the training set, validation set, and test set is 8:1:1. The format of these datasets is COCO2017. Note that the format of our generated synthetic dataset is VOC format and needs to be converted for the COCO format. The object classification is a porcelain insulator.
- (2)
- Experimental configuration: The experiments are conducted based on the DL framework YOLOX. The computer configuration is AMD R7 3700X CPU, NVIDIA GTX-1660 with 8 GB of video memory, and 16 GB RAM. The operating system is ubuntu 18.04.
- (3)
- Defect detection criteria (evaluation criteria): Three widely used indexes are used to quantitatively assess the performance of defect detection methods: precision (P), recall (R), and achieved mean average precision (mAP). P is the percentage of true samples among all the samples that the system determines to be “true”. R is the percentage of “true” samples found among all true samples. AP represents the detection accuracy of a single category, and mAP is the average of AP for each category.
3.2. Training Results with YOLOX
3.3. Comprehensive Performance Analysis
4. Discussions
4.1. Synthetic Dataset vs. Real Dataset
4.2. Potential for the Synthetic Dataset Based on the Prior Series Data
4.3. False Detections and Omissions
4.4. Comparison with Other Dataset Expanding Methods
5. Conclusions
- The synthetic dataset is generated by the Blender script using the prior series data. Per 720 × 1280 pixel image and its annotation are generated in only 11.6 s. The efficiency of synthesizing the dataset is substantially improved compared with humans collecting images and annotating.
- The formulation of synthesis rules based on prior series data can control the properties of the dataset. The synthesis dataset has strong scalability, operability, and tunability.
- Training the YOLOX model using a synthesis dataset without real samples can obtain good models. The trained model achieves an mAP of 0.98 on the test set of real samples, indicating that the trained model on the synthetic dataset has a great generalization to recognize real samples. The research results suggest that training the DL model using a synthesis dataset is promising.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Surya, A.S.; Harsono, B.B.S.D.A.; Tambunan, H.B.; Mangunkusumo, K.G.H. Review of Aerial Vehicle Technology for Transmission Line Inspection in Indonesia. In Proceedings of the Electrical Power Electronics, Malang, Indonesia, 26–28 August 2020. [Google Scholar] [CrossRef]
- Zhang, W.; Ning, Y.; Suo, C. A Method Based on Multi-Sensor Data Fusion for UAV Safety Distance Diagnosis. Electronics 2019, 8, 1467. [Google Scholar] [CrossRef] [Green Version]
- Qin, X.; Wu, G.; Lei, J.; Fan, F.; Ye, X.; Mei, Q. A Novel Method of Autonomous Inspection for Transmission Line based on Cable Inspection Robot LiDAR Data. Sensors 2018, 18, 596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, L.; Xu, D.; Zhai, D. Research and Design of Space-Sky-Ground Integrated Transmission Line Inspection Platform Based on Artificial Intelligence. In Proceedings of the 2018 2nd IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 20–22 October 2018. [Google Scholar] [CrossRef]
- Alhassan, A.B.; Zhang, X.; Shen, H.; Xu, H. Power transmission line inspection robots: A review, trends and challenges for future research. Int. J. Electr. Power 2020, 118, 105862. [Google Scholar] [CrossRef]
- Bian, J.; Hui, X.; Zhao, X.; Tan, M. A Novel Monocular-Based Navigation Approach for UAV Autonomous Transmission-Line Inspection. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018. [Google Scholar] [CrossRef]
- Hui, X.; Bian, J.; Zhao, X.; Tan, M. Vision-based autonomous navigation approach for unmanned aerial vehicle transmission-line inspection. Int. J. Adv. Robot. Syst. 2018, 15, 1729881417752821. [Google Scholar] [CrossRef]
- Côté-Allard, U.; Campbell, E.; Phinyomark, A.; Laviolette, F.; Gosselin, B.; Scheme, E. Interpreting Deep Learning Features for Myoelectric Control: A Comparison with Handcrafted Features. Front. Bioeng. Biotechnol. 2020, 8, 158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Titov, E.; Limanovskaya, O.; Lemekh, A.; Volkova, D. The Deep Learning Based Power Line Defect Detection System Built on Data Collected by the Cablewalker Drone. In Proceedings of the 2019 International Multi-Conference on Engineering, Computer and Information Sciences (SIBIRCON), Novosibirsk, Russia, 21–27 October 2019. [Google Scholar] [CrossRef]
- Yao, N.; Zhu, L. A Novel Foreign Object Detection Algorithm Based on GMM and K-Means for Power Transmission Line Inspection. J. Phys. Conf. Ser. 2020, 1607, 012014. [Google Scholar] [CrossRef]
- Mukherjee, A.; Kundu, P.K.; Das, A. Transmission Line Faults in Power System and the Different Algorithms for Identification, Classification and Localization: A Brief Review of Methods. J. Inst. Eng. Ser. B 2021, 102, 855–877. [Google Scholar] [CrossRef]
- Miao, X.; Liu, X.; Chen, J.; Zhuang, S.; Fan, J.; Jiang, H. Insulator Detection in Aerial Images for Transmission Line Inspection Using Single Shot Multibox Detector. IEEE Access 2019, 7, 9945–9956. [Google Scholar] [CrossRef]
- Wen, Q.; Luo, Z.; Chen, R.; Yang, Y.; Li, G. Deep Learning Approaches on Defect Detection in High Resolution Aerial Images of Insulators. Sensors 2021, 21, 1033. [Google Scholar] [CrossRef] [PubMed]
- Rahman, E.U.; Zhang, Y.; Ahmad, S.; Ahmad, H.I.; Jobaer, S. Autonomous Vision-Based Primary Distribution Systems Porcelain Insulators Inspection Using UAVs. Sensors 2021, 21, 974. [Google Scholar] [CrossRef] [PubMed]
- Mill, L.; Wolff, D.; Gerrits, N.; Philipp, P.; Kling, L.; Vollnhals, F.; Ignatenko, A.; Jaremenko, C.; Huang, Y.; De Castro, O.; et al. Synthetic Image Rendering Solves Annotation Problem in Deep Learning Nanoparticle Segmentation. Small Methods 2021, 5, 2100223. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Xu, W.; Wang, Z.; Yu, S.; Zeng, P.; Ju, Z. Analysis on the Impact of Data Augmentation on Target Recognition for UAV-Based Transmission Line Inspection. Complexity 2020, 2020, 3107450. [Google Scholar] [CrossRef]
- Chang, W.; Yang, G.; Wu, Z.; Liang, Z. Learning Insulators Segmentation from Synthetic Samples. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Židek, K.; Lazorík, P.; Piteľ, J.; Hošovský, A. An Automated Training of Deep Learning Networks by 3D Virtual Models for Object Recognition. Symmetry 2019, 11, 496. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.; Chen, R.; Wang, J.; Liu, X.; Zhang, M.; Zhai, Y. Study on insulator recognition method based on simulated samples expansion. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018. [Google Scholar] [CrossRef]
- Madaan, R.; Maturana, D.; Scherer, S. Wire detection using synthetic data and dilated convolutional networks for unmanned aerial vehicles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar] [CrossRef]
- Barth, R.; Ijsselmuiden, J.; Hemming, J.; Henten, E.J.V. Data synthesis methods for semantic segmentation in agriculture: A Capsicum annuum dataset. Comput. Electron. Agric. 2018, 144, 284–296. [Google Scholar] [CrossRef]
- Boikov, A.; Payor, V.; Savelev, R.; Kolesnikov, A. Synthetic Data Generation for Steel Defect Detection and Classification Using Deep Learning. Symmetry 2021, 13, 1176. [Google Scholar] [CrossRef]
- Cheng, K.; Tahir, R.; Eric, L.K.; Li, M. An analysis of generative adversarial networks and variants for image synthesis on MNIST dataset. Multimed. Tools Appl. 2020, 79, 13725–13752. [Google Scholar] [CrossRef]
- Benitez-Garcia, G.; Yanai, K. Ketchup GAN: A New Dataset for Realistic Synthesis of Letters on Food. In Proceedings of the International Joint Workshop on Multimedia Artworks Analysis and Attractiveness Computing in Multimedia, Taipei, Taiwan, 16–19 November 2021; pp. 8–12. [Google Scholar] [CrossRef]
- Tian, Y.; Li, X.; Wang, K.; Wang, F. Training and testing object detectors with virtual images. IEEE/CAA J. Autom. Sin. 2018, 5, 539–546. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Core Idea | Method | Pros and Cons |
|---|---|---|---|
| Expanding a real dataset | Data augmentation [16] | Histogram equalization, gaussian blur, random translation, scaling, cutout, and rotation | Histogram equalization, random translation, and cutout have a low impact on network accuracy. Faster RCNN cannot deal with the issue of target rotation well. |
| Random splicing [17] | — | The trained model used synthetic samples have a good generalization for the real images, the transparent samples made the networks difficult to converge. | |
| Image processing [14] | A deep Laplacian pyramid-based super-resolution network and a low-light image enhancement technique | The quality and volume of the training dataset are improved, but the images need to be collected. | |
| Generating a synthesis dataset | Generating dataset using virtual 3D models [18,21,22] | Blender script | Dataset generation is easy and fast in a single background working condition for standard parts. |
| Generating dataset based on images [19,23,24] | Mixing real and synthetic data, Generative Adversarial Networks (GANs) | The appropriate ratio is favorable for neural network learning; however, it is difficult to collect real images. | |
| Overlaying synthetic data on videos [20] | A ray tracing engine | Semantic segmentation datasets can be quickly generated, but the background changes are not flexible. |
| Tower Number | Date | Time | Set of Prior Series Data |
|---|---|---|---|
| 1# | 2 January | 10:00 | S1-P1 1/P2 1/P3 1/P4 1 |
| 15:00 | S1-P1 1/P2 1/P3 1/P4 2 | ||
| 3 March | 13:00 | S1-P1 1/P2 1/P3 1/P4 3 | |
| 18:00 | S1-P1 1/P2 1/P3 1/P4 4 | ||
| 2# | 4 June | 9:00 | S2-P1 2/P2 1/P3 2/P4 5 |
| 11:00 | S2-P1 2/P2 1/P3 2/P4 6 |
| Description | Symbol | Unit | Value |
|---|---|---|---|
| xi axis conversion distance of insulator | tx | m | [0.3, 30] |
| yi axis conversion distance of insulator | ty | m | {1.9, 2.2, 2.3} |
| zi axis conversion distance of insulator | tz | m | [0, 4.6] |
| Translation distance xr axis increase in flight | t′x | m | [−30, 30] |
| Translation distance yr axis increase in flight | t′y | m | [−10, 10] |
| Translation distance zr axis increase in flight | t′z | m | [−10, 10] |
| yi axis rotation angle of insulator | β | ° | [−90, 90] |
| zi axis rotation angle of insulator | γ | ° | [−60, 60] |
| Irradiance | E | W/m2 | [0, 1032] |
| HDRI environmental horizontal rotation angle | θl | ° | [0, 360] |
| HDRI environmental vertical rotation angle | θv | ° | [−45, 45] |
| xi axis conversion distance of insulator | tx | m | [0.3, 30] |
| Core Idea | Method | Recognition Target | Data Volume | Sensor Type | Vehicle Type | Performance Metrics |
|---|---|---|---|---|---|---|
| Data augmentation [16] | Faster RCNN | Insulator | — | RGB Camera | NVIDIA RTX2080ti | Highest accuracy: 90.2% |
| Random splicing [17] | cGAN | Insulator | 8 K | Infrared camera and RGB camera | NVIDIA GTX1080 | Highest accuracy: 85% |
| Image processing [14] | YOLO v4 | Insulator | 15 K | RGB Camera | NVIDIA GTX1060 | AP: 82.9% |
| Generating dataset using virtual 3D models [18] | CNN | Screw, nut, and washer | — | RGB Camera | Samsung S7, Epson Moverio M350 | Accuracy: 91% to 99% |
| Mixing real and simulated samples [19] | CNN | Insulator | 18 K | RGB Camera | Omnisky SCW4750 workstation | Best mixing ratio: 2.0 Accuracy: 97.9% |
| Overlaying synthetic wires on flight videos [20] | CNN | Wire | 68 K | RGB Camera | NVIDIA Jetson TX2 | AP: 73% |
| Generating dataset base prior series data | YOLOX | Insulator | 10.8 K | D 435i | NVIDIA GTX1660 | AP: 98% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Qin, X.; Lei, J.; Jia, B.; Li, B.; Li, Z.; Li, H.; Zeng, Y.; Song, J. A Novel Auto-Synthesis Dataset Approach for Fitting Recognition Using Prior Series Data. Sensors 2022, 22, 4364. https://doi.org/10.3390/s22124364
Zhang J, Qin X, Lei J, Jia B, Li B, Li Z, Li H, Zeng Y, Song J. A Novel Auto-Synthesis Dataset Approach for Fitting Recognition Using Prior Series Data. Sensors. 2022; 22(12):4364. https://doi.org/10.3390/s22124364
Chicago/Turabian StyleZhang, Jie, Xinyan Qin, Jin Lei, Bo Jia, Bo Li, Zhaojun Li, Huidong Li, Yujie Zeng, and Jie Song. 2022. "A Novel Auto-Synthesis Dataset Approach for Fitting Recognition Using Prior Series Data" Sensors 22, no. 12: 4364. https://doi.org/10.3390/s22124364
APA StyleZhang, J., Qin, X., Lei, J., Jia, B., Li, B., Li, Z., Li, H., Zeng, Y., & Song, J. (2022). A Novel Auto-Synthesis Dataset Approach for Fitting Recognition Using Prior Series Data. Sensors, 22(12), 4364. https://doi.org/10.3390/s22124364