
An Unsupervised Transfer Learning Framework for Visible-Thermal Pedestrian Detection


Abstract
:1. Introduction
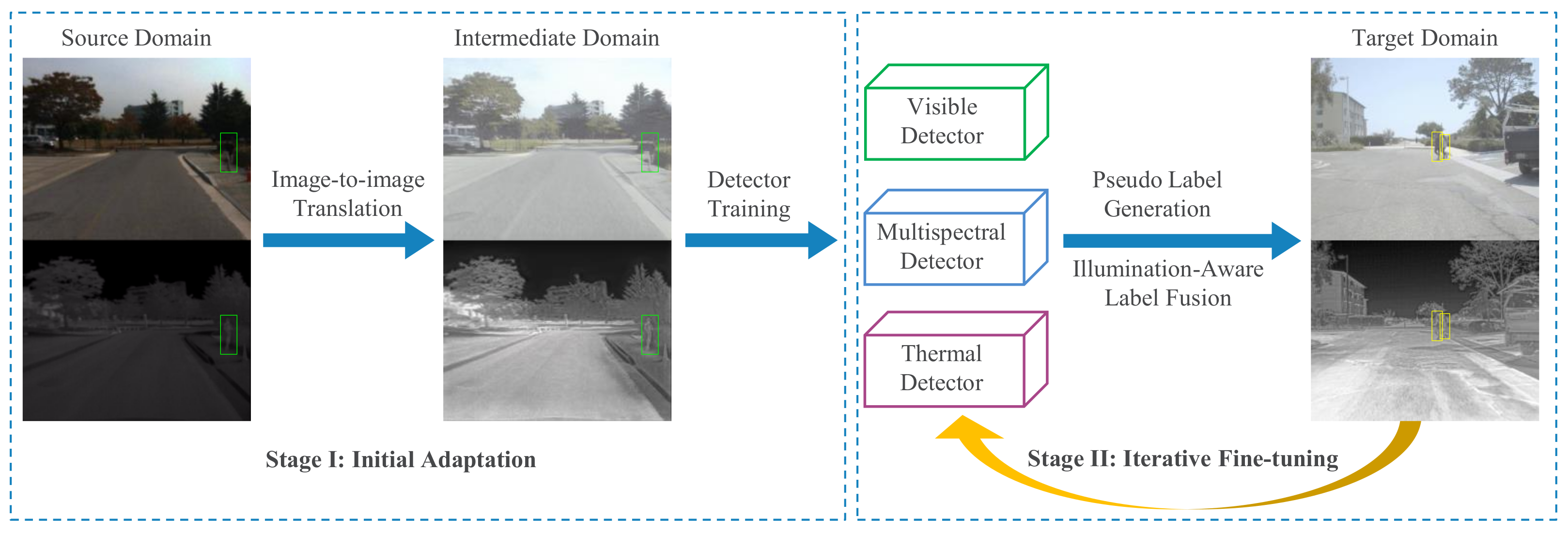
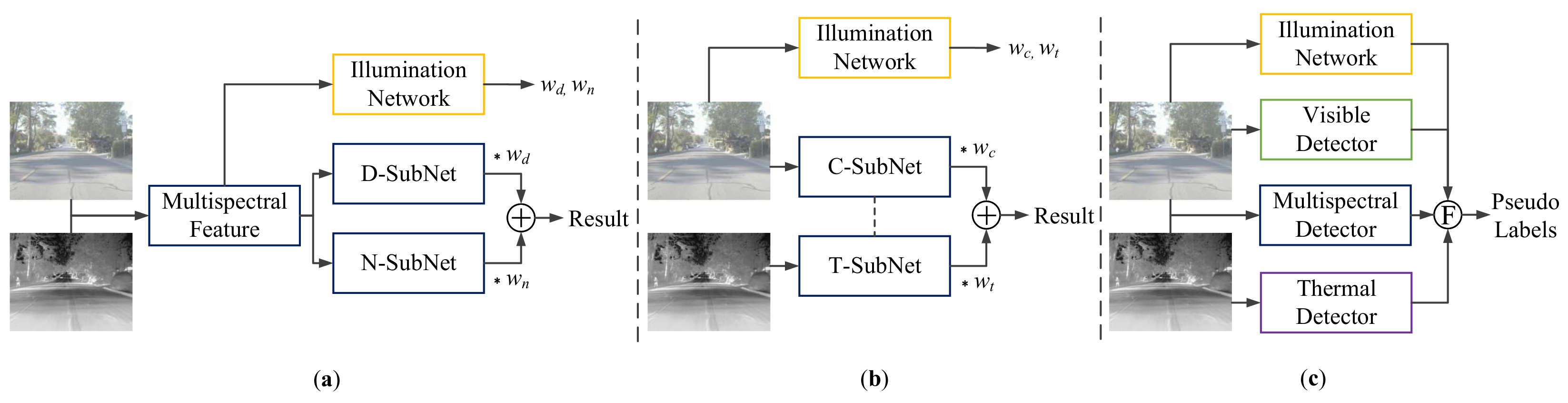
- A novel and unified unsupervised transfer learning framework for multispectral pedestrian detection is proposed. The adaptation of a multispectral detector using pseudo training labels, leveraging auxiliary detectors specializing in single modalities;
- The idea of using an intermediate domain representation is introduced to reduce the domain gap between the source and target domains. The high-quality initial pseudo labels are generated based on the this intermediate domain;
- An illumination-aware label fusion strategy is proposed to select the best pseudo labels from different modalities, where the environmental illumination level is accessed by an independent illumination estimation network;
2. Related Work
2.1. Visible Pedestrian Detection
2.2. Thermal Pedestrian Detection
2.3. Multispectral Pedestrian Detection
2.4. Unsupervised Transfer Learning
3. Methodology
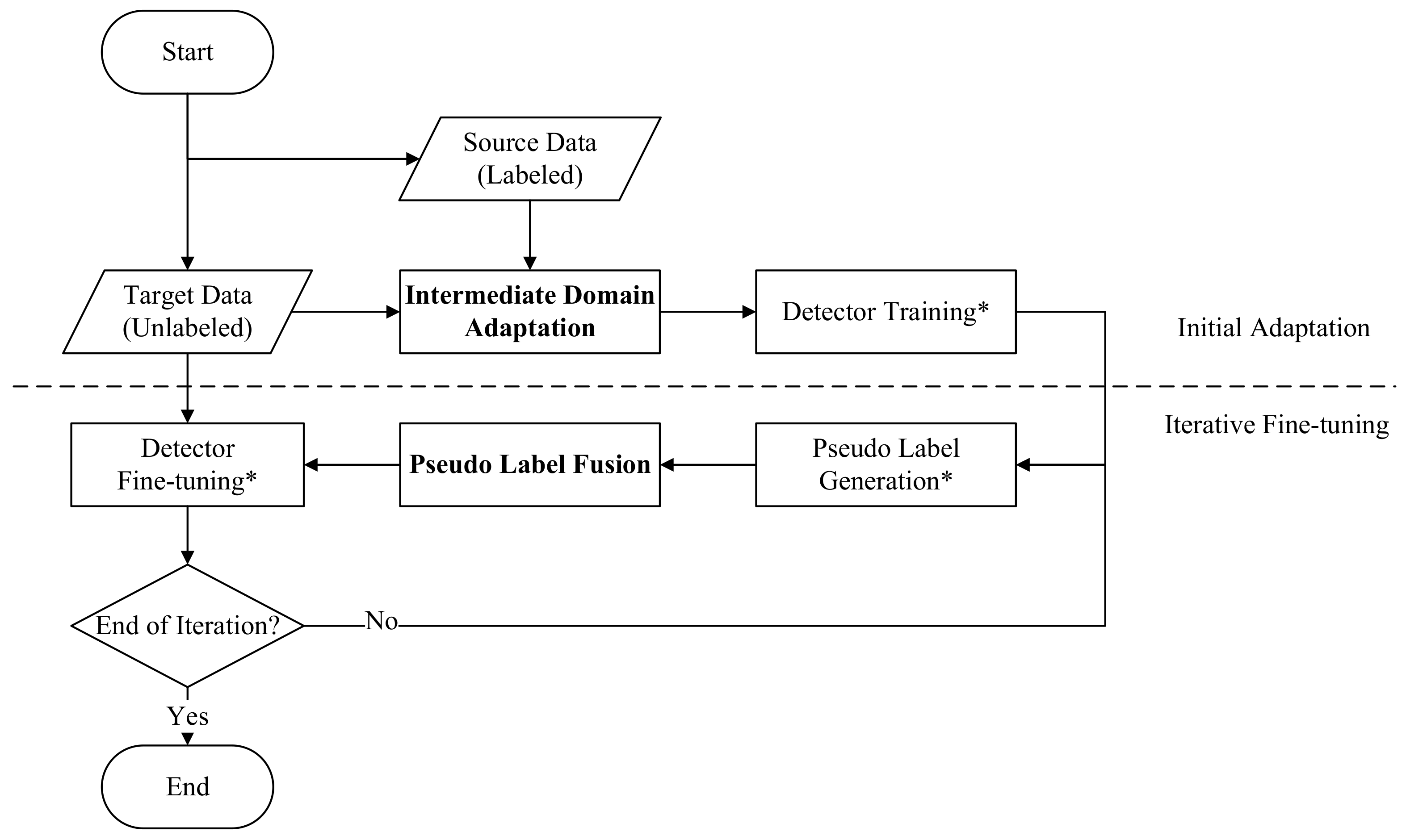
3.1. Framework Overview
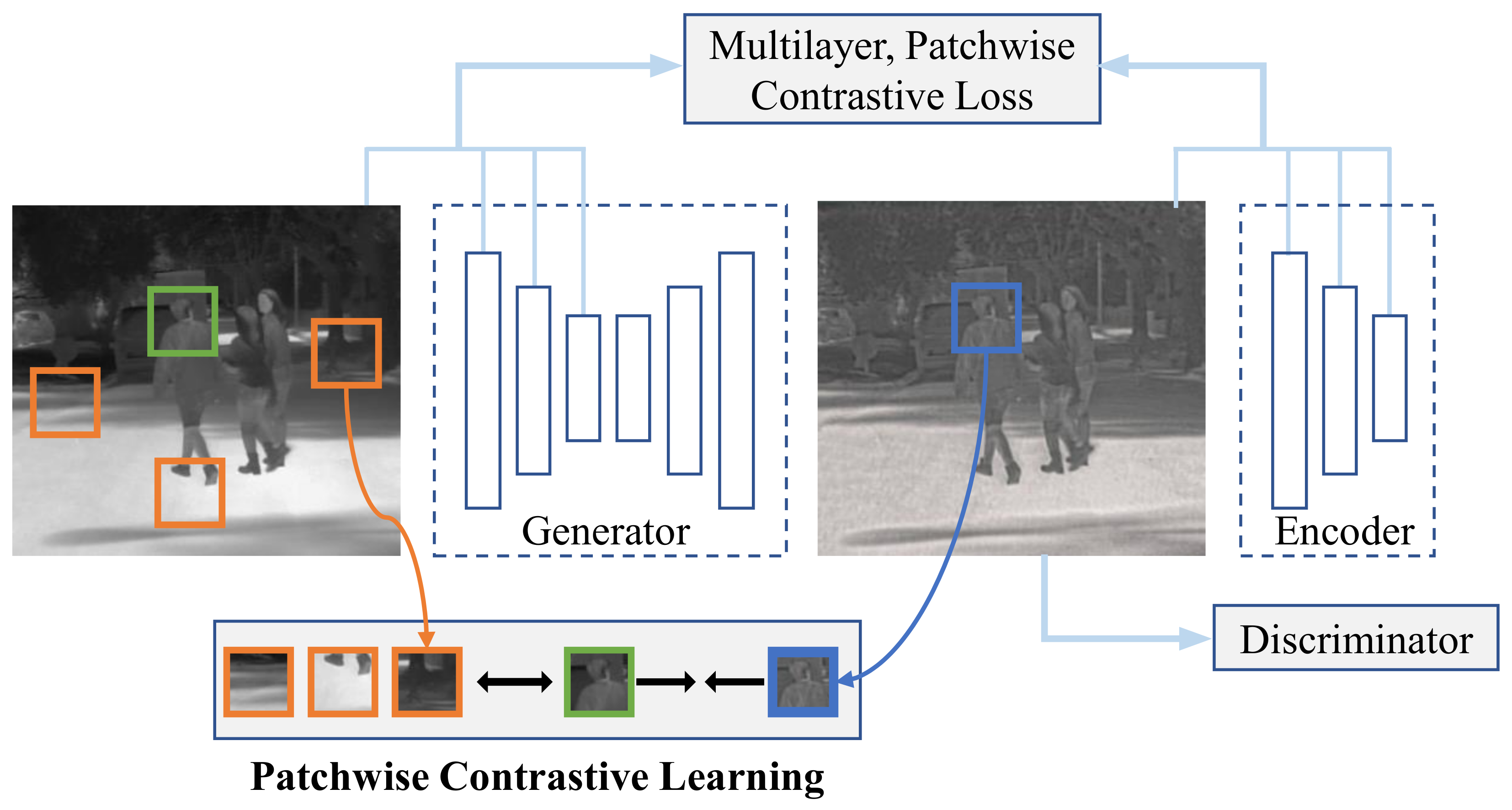
3.2. Intermediate Domain Adaptation
3.3. Illumination-Aware Label Fusion
4. Experiments and Results
4.1. Datasets and Metrics
4.2. Experimental Setup
4.3. Main Results
4.4. Ablation Study
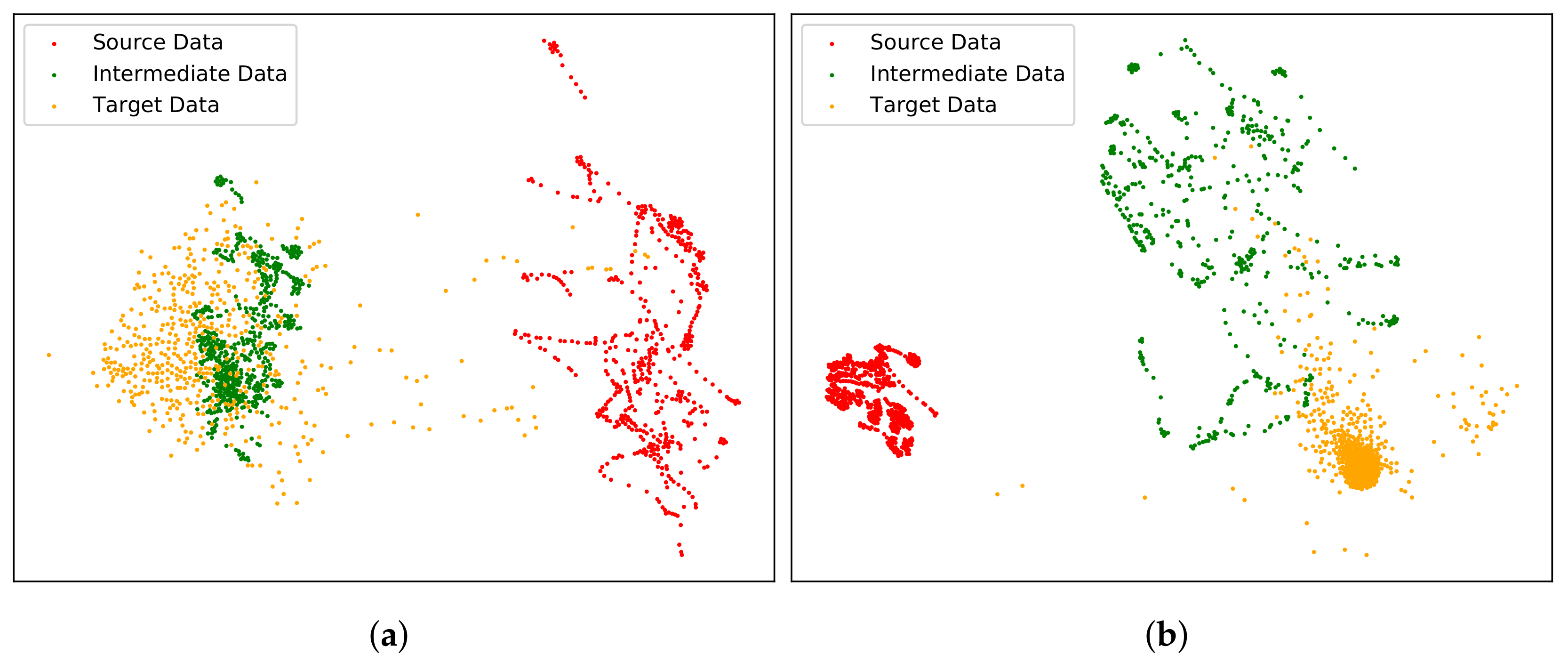
4.4.1. Effects of Intermediate Domain Adaptation
4.4.2. Effects of Illumination-Aware Label Fusion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Navarro, P.J.; Fernandez, C.; Borraz, R.; Alonso, D. A Machine Learning Approach to Pedestrian Detection for Autonomous Vehicles Using High-Definition 3D Range Data. Sensors 2017, 17, 18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, Z.; Li, J.; Li, H. Real-time Pedestrian and Vehicle Detection for Autonomous Driving. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 179–184. [Google Scholar]
- Wang, X.; Wang, M.; Li, W. Scene-Specific Pedestrian Detection for Static Video Surveillance. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 361–374. [Google Scholar] [CrossRef] [PubMed]
- Bilal, M.; Khan, A.; Khan, M.U.K.; Kyung, C.M. A Low-complexity Pedestrian Detection Framework for Smart Video Surveillance Systems. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2260–2273. [Google Scholar] [CrossRef]
- Solbach, M.D.; Tsotsos, J.K. Vision-Based Fallen Person Detection for the Elderly. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 1433–1442. [Google Scholar]
- Guo, L.; Ge, P.S.; Zhang, M.H.; Li, L.H.; Zhao, Y.B. Pedestrian Detection for Intelligent Transportation Systems Combining Adaboost Algorithm and Support Vector Machine. Expert Syst. Appl. 2012, 39, 4274–4286. [Google Scholar] [CrossRef]
- Khalifa, A.B.; Alouani, I.; Mahjoub, M.A.; Rivenq, A. A Novel Multi-view Pedestrian Detection Database for Collaborative Intelligent Transportation Systems. Future Gener. Comput. Syst. 2020, 113, 506–527. [Google Scholar] [CrossRef]
- Retief, S.P.; Willers, C.; Wheeler, M. Prediction of Thermal Crossover Based on Imaging Measurements Over the Diurnal Cycle. In Proceedings of the Geo-Spatial and Temporal Image and Data Exploitation III, Orlando, FL, USA, 21 April 2003; Volume 5097, pp. 58–69. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D. Multispectral Deep Neural Networks for Pedestrian Detection. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016; pp. 73.1–73.13. [Google Scholar]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully Convolutional Region Proposal Networks for Multispectral Person Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 49–56. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Multispectral Fusion for Object Detection with Cyclic Fuse-and-Refine Blocks. In Proceedings of the IEEE International Conference on Image Processing, Virtual, 25–28 October 2020; pp. 276–280. [Google Scholar]
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Generalizable Pedestrian Detection: The Elephant in the Room. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11328–11337. [Google Scholar]
- Fritz, K.; König, D.; Klauck, U.; Teutsch, M. Generalization Ability of Region Proposal Networks for Multispectral Person Detection. In Proceedings of the Automatic Target Recognition XXIX, Baltimore, MD, USA, 15–18 April 2019; Volume 10988, pp. 222–235. [Google Scholar]
- Cao, Y.; Guan, D.; Huang, W.; Yang, J.; Cao, Y.; Qiao, Y. Pedestrian Detection with Unsupervised Multispectral Feature Learning Using Deep Neural Networks. Inf. Fusion 2019, 46, 206–217. [Google Scholar] [CrossRef]
- Guan, D.; Luo, X.; Cao, Y.; Yang, J.; Cao, Y.; Vosselman, G.; Yang, M.Y. Unsupervised Domain Adaptation for Multispectral Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 434–443. [Google Scholar]
- Lyu, C.; Heyer, P.; Munir, A.; Platisa, L.; Micheloni, C.; Goossens, B.; Philips, W. Visible-Thermal Pedestrian Detection via Unsupervised Transfer Learning. In Proceedings of the International Conference on Innovation in Artificial Intelligence, Xiamen, China, 5–8 March 2021; pp. 158–163. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-Aware Faster R-CNN for Robust Multispectral Pedestrian Detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A Discriminatively Trained, Multiscale, Deformable Part Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S. Integral Channel Features. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Brazil, G.; Yin, X.; Liu, X. Illuminating Pedestrians via Simultaneous Detection & Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4950–4959. [Google Scholar]
- Kim, J.U.; Park, S.; Ro, Y.M. Robust Small-Scale Pedestrian Detection with Cued Recall Via Memory Learning. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3050–3059. [Google Scholar]
- Luo, Y.; Zhang, C.; Lin, W.; Yang, X.; Sun, J. Sequential Attention-Based Distinct Part Modeling for Balanced Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Chang, S.L.; Yang, F.T.; Wu, W.P.; Cho, Y.A.; Chen, S.W. Nighttime Pedestrian Detection Using Thermal Imaging Based on HOG Feature. In Proceedings of the International Conference on System Science and Engineering, Macau, China, 8–10 June 2011; pp. 694–698. [Google Scholar]
- Brehar, R.; Nedevschi, S. Pedestrian Detection in Infrared Images Using HOG, LBP, Gradient Magnitude and Intensity Feature Channels. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1669–1674. [Google Scholar]
- Ghose, D.; Desai, S.M.; Bhattacharya, S.; Chakraborty, D.; Fiterau, M.; Rahman, T. Pedestrian Detection in Thermal Images Using Saliency Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Devaguptapu, C.; Akolekar, N.; Sharma, M.M.; N Balasubramanian, V. Borrow from Anywhere: Pseudo Multi-Modal Object Detection in Thermal Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Marnissi, M.A.; Fradi, H.; Sahbani, A.; Amara, N.E.B. Thermal Image Enhancement using Generative Adversarial Network for Pedestrian Detection. In Proceedings of the International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6509–6516. [Google Scholar]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef] [Green Version]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian Detection at Day/Night Time with Visible and FIR Cameras: A Comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Multispectral Pedestrian Detection via Simultaneous Detection and Segmentation. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; p. 225. [Google Scholar]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Tisse, C.L. Exploiting Fusion Architectures for Multispectral Pedestrian Detection and Segmentation. Appl. Opt. 2018, 57, D108–D116. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-Modality Interactive Attention Network for Multispectral Pedestrian Detection. Inf. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Guided Attentive Feature Fusion for Multispectral Pedestrian Detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 72–80. [Google Scholar]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Fusion of Multispectral Data Through Illumination-Aware Deep Neural Networks for Pedestrian Detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef] [Green Version]
- Vandersteegen, M.; Beeck, K.V.; Goedemé, T. Real-time Multispectral Pedestrian Detection with a Single-Pass Deep Neural Network. In Proceedings of the International Conference Image Analysis and Recognition, Póvoa de Varzim, Portugal, 24–26 June 2018; pp. 419–426. [Google Scholar]
- Roszyk, K.; Nowicki, M.R.; Skrzypczyński, P. Adopting the YOLOv4 Architecture for Low-Latency Multispectral Pedestrian Detection in Autonomous Driving. Sensors 2022, 22, 1082. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, C.; Hu, Q.; Fu, H.; Zhu, P. Confidence-aware Fusion using Dempster-Shafer Theory for Multispectral Pedestrian Detection. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised Visual Domain Adaptation Using Subspace Alignment. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–3 December 2013; pp. 2960–2967. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Wang, Y.; Ngo, C.W.; Mei, T. Transferrable Prototypical Networks for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2239–2247. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain Adaptive Faster R-CNN for Object Detection in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-Weak Distribution Alignment for Adaptive Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6956–6965. [Google Scholar]
- Hsu, H.K.; Yao, C.H.; Tsai, Y.H.; Hung, W.C.; Tseng, H.Y.; Singh, M.; Yang, M.H. Progressive Domain Adaptation for Object Detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 749–757. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhang, H.; Luo, G.; Li, J.; Wang, F.Y. C2FDA: Coarse-to-Fine Domain Adaptation for Traffic Object Detection. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive Learning for Unpaired Image-to-Image Translation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 319–345. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing Data Using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-Training with Noisy Student Improves Imagenet Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Teledyne FLIR. FLIR Thermal Dataset for Algorithm Training; FLIR Systems: Wilsonville, OR, USA, 2021. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | LAMR (Lower, Better) | ||
|---|---|---|---|
| All | Daytime | Nighttime | |
| Supervised training | |||
| ACF + T + THOG [9] | 47.25% | 42.44% | 56.17% |
| Halfway Fusion [10] | 26.14% | 24.08% | 29.01% |
| Feature-Map Fusion | 21.27% | 18.63% | 26.17% |
| Source only: | |||
| Feature-Map Fusion (CVC-14) | 51.94% | 53.83% | 44.76% |
| Unsupervised transfer learning: | |||
| U-TS-RPN [15] | 30.07% | 31.59% | 26.78% |
| Ours (CVC-14 → KAIST) | 19.98% | 22.17% | 15.78% |
| Methods | LAMR (Lower, Better) |
|---|---|
| Supervised training | |
| Halfway Fusion [10] | 40.43% |
| Feature-Map Fusion | 31.41% |
| Source only: | |
| Feature-Map Fusion (KAIST) | 64.64% |
| Feature-Map Fusion (CVC-14) | 43.92% |
| Unsupervised transfer learning: | |
| Ours (KAIST → FLIR ADAS) | 44.19% |
| Ours (CVC-14 → FLIR ADAS) | 33.16% |
| Source → Target | Methods | LAMR (Lower, Better) | ||
|---|---|---|---|---|
| All | Daytime | Nighttime | ||
| CVC-14 → KAIST | Detector Trained on CVC-14 | 51.94% | 53.83% | 44.76% |
| Initial Adaptation (w/HM) | 43.28% | 46.83% | 33.79% | |
| Initial Adaptation (w/ID) | 41.07% | 45.11% | 29.20% | |
| KAIST → FLIR ADAS | Detector Trained on KAIST | 64.64% | - | - |
| Initial Adaptation (w/HM) | 60.13% | - | - | |
| Initial Adaptation (w/ID) | 52.41% | - | - | |
| CVC-14 → FLIR ADAS | Detector Trained on CVC-14 | 43.92% | - | - |
| Initial Adaptation (w/HM) | 40.51% | - | - | |
| Initial Adaptation (w/ID) | 39.16% | - | - | |
| Methods | LAMR (Lower, Better) | ||
|---|---|---|---|
| All | Daytime | Nighttime | |
| Without illumination info | 34.50% | 39.21% | 24.49% |
| With daytime/nighttime info | 23.09% | 24.55% | 17.74% |
| With estimated illumination | 21.09% | 23.32% | 17.14% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, C.; Heyer, P.; Goossens, B.; Philips, W. An Unsupervised Transfer Learning Framework for Visible-Thermal Pedestrian Detection. Sensors 2022, 22, 4416. https://doi.org/10.3390/s22124416
Lyu C, Heyer P, Goossens B, Philips W. An Unsupervised Transfer Learning Framework for Visible-Thermal Pedestrian Detection. Sensors. 2022; 22(12):4416. https://doi.org/10.3390/s22124416
Chicago/Turabian StyleLyu, Chengjin, Patrick Heyer, Bart Goossens, and Wilfried Philips. 2022. "An Unsupervised Transfer Learning Framework for Visible-Thermal Pedestrian Detection" Sensors 22, no. 12: 4416. https://doi.org/10.3390/s22124416
APA StyleLyu, C., Heyer, P., Goossens, B., & Philips, W. (2022). An Unsupervised Transfer Learning Framework for Visible-Thermal Pedestrian Detection. Sensors, 22(12), 4416. https://doi.org/10.3390/s22124416