
GPU-Accelerated PD-IPM for Real-Time Model Predictive Control in Integrated Missile Guidance and Control Systems



Abstract
:1. Introduction
- This is the first approach to accelerate missile MPC on GPU.
- The problem of considerable computation time in the KKT condition construction part of PD-IPM is firstly addressed and analyzed.
- A new parallelization method is developed for the KKT condition construction part of PD-IPM.
- The computation time for PD-IPM is significantly reduced, even considering the overhead time for the CUDA (Compute Unified Device Architecture) initialization on a widely-used embedded system.
2. Problem Description
2.1. Augmented Model for Integrated Guidance and Control
2.2. The Problem of PD-IPM for Real-Time MPC
| Algorithm 1. Primal-Dual Interior Point Method [24]. | ||
| Choose K: maximum iteration, | ||
| while or | ||
| // Find update direction by solving Newton Step | ||
| // Backtracking Line Search to find θ | ||
| // Primal-Dual Update | ||
3. Proposed Method
3.1. Overview of the Proposed Method
3.2. Computation-Time Profiling
3.3. Parallelization Based on CSR and CSC
| Algorithm 2. Parallel Sparse-Matrix Multiplication | |
| Input | * CSR format matrix A(data: , col index: , row ptr: ) * CSC format matrix B(data: , row index: , col ptr: ) * Sparse matrices A, B must be sorted. |
| Output | Dense matrix D() |
| 1. | all do, in parallel: |
| 2. | sum |
| 3. | for to do: |
| 4. | for to do: |
| 5. | if then: |
| 6. | break |
| 7. | else if then: |
| 8. | sumsum |
| 9. | end if |
| 10. | end for |
| 11. | end for |
| 12. | |
| 13. | end |
| Algorithm 3. Parallel Construct Modified KKT Matrix (top-left sub-matrix) | |
| Input | Dense matrix P(), dense matrix D() |
| Output | dense matrix M() |
| 1. | all do in parallel: |
| 2. | |
| 3. | end |
4. Results
4.1. Simulation Results
4.2. Results of Algorithm Acceleration with GPU
4.3. Analysis
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manchester, I.R.; Savkin, A.V. Circular navigation missile guidance with incomplete information and uncertain autopilot model. J. Guid. Control. Dyn. 2004, 27, 1078–1083. [Google Scholar] [CrossRef] [Green Version]
- Menon, P.K.; Ohlmeyer, E.J. Integrated design of agile missile guidance and autopilot systems. Control. Eng. Pract. 2001, 9, 1095–1106. [Google Scholar] [CrossRef]
- Shima, T.; Idan, M.; Golan, O.M. Sliding-mode control for integrated missile autopilot guidance. J. Guid. Control. Dyn. 2006, 29, 250–260. [Google Scholar] [CrossRef]
- Shtessel, Y.B.; Tournes, C.H. Integrated higher-order sliding mode guidance and autopilot for dual control missiles. J. Guid. Control. Dyn. 2009, 32, 79–94. [Google Scholar] [CrossRef]
- He, S.; Song, T.; Lin, D. Impact Angle Constrained Integrated Guidance and Control for Maneuvering Target Interception. J. Guid. Control. Dyn. 2017, 40, 2652–2660. [Google Scholar] [CrossRef]
- Hou, M.; Duan, G. Adaptive block dynamic surface control for integrated missile guidance and autopilot. Chin. J. Aeron. 2013, 26, 741–750. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Hou, M.; Duan, G. Adaptive dynamic surface control for integrated missile guidance and autopilot in the presence of input saturation. J. Aerosp. Eng. 2015, 28, 04014121. [Google Scholar] [CrossRef]
- Liu, W.; Wei, Y.; Duan, G. Barrier Lyapunov Function-based Integrated Guidance and Control with Input Saturation and State Constraints. Aerosp. Sci. Technol. 2019, 84, 845–855. [Google Scholar] [CrossRef]
- Kim, J.H.; Whang, I.H.; Kim, B.M. Finite horizon integrated guidance and control for terminal homing in vertical plane. J. Guid. Control. Dyn. 2016, 39, 1103–1111. [Google Scholar] [CrossRef]
- Bachtiar, V.; Manzie, C.; Kerrigan, E.C. Nonlinear model predictive integrated missile control and its multi-objective tuning. J. Guid. Control. Dyn. 2017, 40, 2958–2967. [Google Scholar] [CrossRef]
- Chai, R.; Savvaris, A.; Chai, S. Integrated Missile Guidance and Control Using Optimization-based Predictive Control. Nonlinear Dyn. 2019, 96, 997–1015. [Google Scholar] [CrossRef]
- Park, J.H.; Kim, Y.I.; Kim, J.H. Integrated Guidance and Control Using Model Predictive Control with Flight Path Angle Prediction against Pull-Up Maneuvering Target. Sensors 2020, 20, 3143. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.H.; Park, J.H.; Kim, J.H. Computational Issues in Sparse and Dense Formulations of Integrated Guidance and Control with Constraints. Int. J. Aeronaut Space Sci. 2020, 21, 826–835. [Google Scholar] [CrossRef]
- Ma, L.; Shan, J.; Liu, J.; Ding, Y. Missile IGC Based on Improved Model Predictive Control and Sliding Mode Observer. Int. J. Aerosp. Eng. 2021, 2021. [Google Scholar] [CrossRef]
- Shamaghdari, S.; Nikravesh, S.K.Y.; Haeri, M. Integrated guidance and control of elastic flight vehicle based on robust MPC. Int. J. Robust Nonlinear Control 2015, 25, 2608–2630. [Google Scholar] [CrossRef]
- Mohsen, H.; Amin, R.; Wenjun, Z. An interpolation-based model predictive controller for input–output linear parameter varying systems. Int. J. Dyn. Control. 2022, 1–14. [Google Scholar] [CrossRef]
- Gabay, D.; Mercier, B. A dual algorithm for the solution of nonlinear variational problems in finite-element approximations. Comput. Math. Appl. 1976, 2, 17–40. [Google Scholar] [CrossRef] [Green Version]
- East, S.; Cannon, M. ADMM for MPC with state and input constraints, and input nonlinearity. In Proceedings of the 2018 annual American control conference (ACC), Milwaukee, WI, USA, 27–29 June 2018. [Google Scholar]
- Danielson, C. An alternating direction method of multipliers algorithm for symmetric MPC. IFAC-PapersOnLine 2018, 51, 319–324. [Google Scholar] [CrossRef]
- Brand, M.; Shilpiekandula, V.; Yao, C.; Bortoff, S.A. A Parallel Quadratic Programming Algorithm for Model Predictive Control. IFAC Proc. 2011, 44, 1031–1039. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Goldsmith, A.M.; Di Cairano, S. Efficient Convex Optimization on GPUs for Embedded Model Predictive Control. In Proceedings of the 10th General Purpose GPUs, Austin, TX, USA, 4–8 February 2017. [Google Scholar]
- Glad, T.; Jonson, H. A method for state and control constrained linear quadratic control problems. IFAC Proc. 1984, 17, 1583–1587. [Google Scholar] [CrossRef]
- Richter, S.; Jones, C.N.; Morari, M. Real-time input-constrained MPC using fast gradient methods. In Proceedings of the 48h IEEE Conference on Decision and Control (CDC) Held Jointly with 2009 28th Chinese Control Conference, Shanghai, China, 16–18 December 2009. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004; pp. 324–615. [Google Scholar]
- Lustig, I.J.; Marsten, R.E.; Shanno, D.F. Computational experience with a primal-dual interior point method for linear programming. Linear Algebra Its Appl. 1991, 152, 191–222. [Google Scholar] [CrossRef] [Green Version]
- Lau, M.S.; Yue, S.P.; Ling, K.V.; Maciejowski, J.M. A comparison of interior point and active set methods for FPGA implementation of model predictive control. In Proceedings of the 2009 European Control Conference (ECC), Budapest, Hungary, 23–29 August 2009. [Google Scholar]
- Abughalieh, K.M.; Alawneh, S.G. A survey of parallel implementations for model predictive control. IEEE Access 2019, 7, 34348–34360. [Google Scholar] [CrossRef]
- Zarchan, P. Tactical and Strategic Missile Guidance, 6th ed.; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2012; pp. 473–527. [Google Scholar]
- Nicolai, F.; Gade, N. Interior Point Methods on GPU with Application to Model Predictive Control. Available online: https://backend.orbit.dtu.dk/ws/portalfiles/portal/103047513/phd338_Gade_Nielsen_NF.pdf. (accessed on 8 June 2022).
- Smith, E.; Gondzio, J.; Hall, J. GPU Acceleration of the Matrix-Free Interior Point Method. Lect. Notes Comput. Sci. 2012, 7203, 681–689. [Google Scholar]
- Jin, H.J.; O’leary, D. Implementing an interior point method for linear programs on a CPU-GPU system. Electron. Trans. Numer. Anal. 2008, 28, 174–189. [Google Scholar]
- Jing, J.; Xianggao, C.; Xiaola, L. Efficient SVM Training Using Parallel Primal-Dual Interior Point Method on GPU. In Proceedings of the 2013 International Conference on Parallel and Distributed Computing, Applications and Technologies, London, UK, 3–5 July 2013. [Google Scholar]
- Maggioni, M. Sparse Convex Optimization on GPUs. Ph.D. Thesis, University of Illinois at Chicago, Chicago, IL, USA, 2016. Available online: https://hdl.handle.net/10027/20173 (accessed on 8 June 2022).
- Shah, U.A.; Yousaf, S.; Ahmad, M.O. On the Efficiency of Supernodal Factorization in Interior-Point Method Using CPU-GPU Collaboration. IEEE Access 2020, 8, 120892–120904. [Google Scholar] [CrossRef]
- Legendre, M.; Moussaoui, S.; Idier, J.; Schmidt, F. Parallel implementation of a primal-dual interior-point optimization method for fast abundance maps estimation. In Proceedings of the 2013 5th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Gainesville, FL, USA, 26–28 June 2013. [Google Scholar]
- Liu, J.; Peyrl, H.; Burg, A.; George, A. FPGA implementation of an interior point method for high-speed model predictive control. In Proceedings of the 24th International Conference of Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014. [Google Scholar]
- Chen, Z.; Li, J.; Wang, S.; Wang, J.; Ma, L. Flexible gait transition for six wheel-legged robot with unstructured ter-rains. Robot. Auton. Syst. 2022, 150, 1–18. [Google Scholar]
- Pipatpaibul, P.; Ouyang, P.R. Application of Online Iterative Learning Tracking Control for Quadrotor UAVs. Int. Sch. Res. Not. 2013, 2013, 476153. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Qian, Z.; Yan, Z.; Yuan, C.; Zhanga, W. Novel Resilient Robot: Kinematic Analysis and Experimentation. IEEE Access 2019, 8, 2885–2892. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related works | Target Device | MPC | Parallelization Part | IGC Application |
|---|---|---|---|---|
| [29] | GPU | ○ | Linear equation solver | × |
| [30,31,32,33,34] | GPU | × | Linear equation solver | × |
| [35] | GPU | × | None | × |
| [36] | FPGA | ○ | Linear equation solver | × |
| Part | Computation Time (ms) |
|---|---|
| Calculate residue | 287.285 |
| Construct modified KKT condition | 1202.956 |
| Calculate search direction | 1612.328 |
| Backtracking line search | 352.767 |
| Part | Computation Time (ms) |
|---|---|
| Convert dense matrix to sparse matrix | 78.513 |
| Sparse matrix multiplication | 695.494 |
| Construct modified KKT matrix | 321.575 |
| etc. | 108.922 |
| Part | Computation Time (ms) |
|---|---|
| Convert dense matrix to sparse matrix | 187.086 |
| Solve linear equation | 1425.109 |
| Part | Computation Time(ms) | |||
|---|---|---|---|---|
| CPU Only | CUDA Dense | CUDA SpMM | Ours | |
| CUDA initialization delay | - | 106.152 | 1409.594 | 92.593 |
| Construct modified KKT condition | 1202.956 | 1120.698 | 479.706 | 298.689 |
| Total | 1202.956 | 1226.85 | 1889.3 | 391.282 |
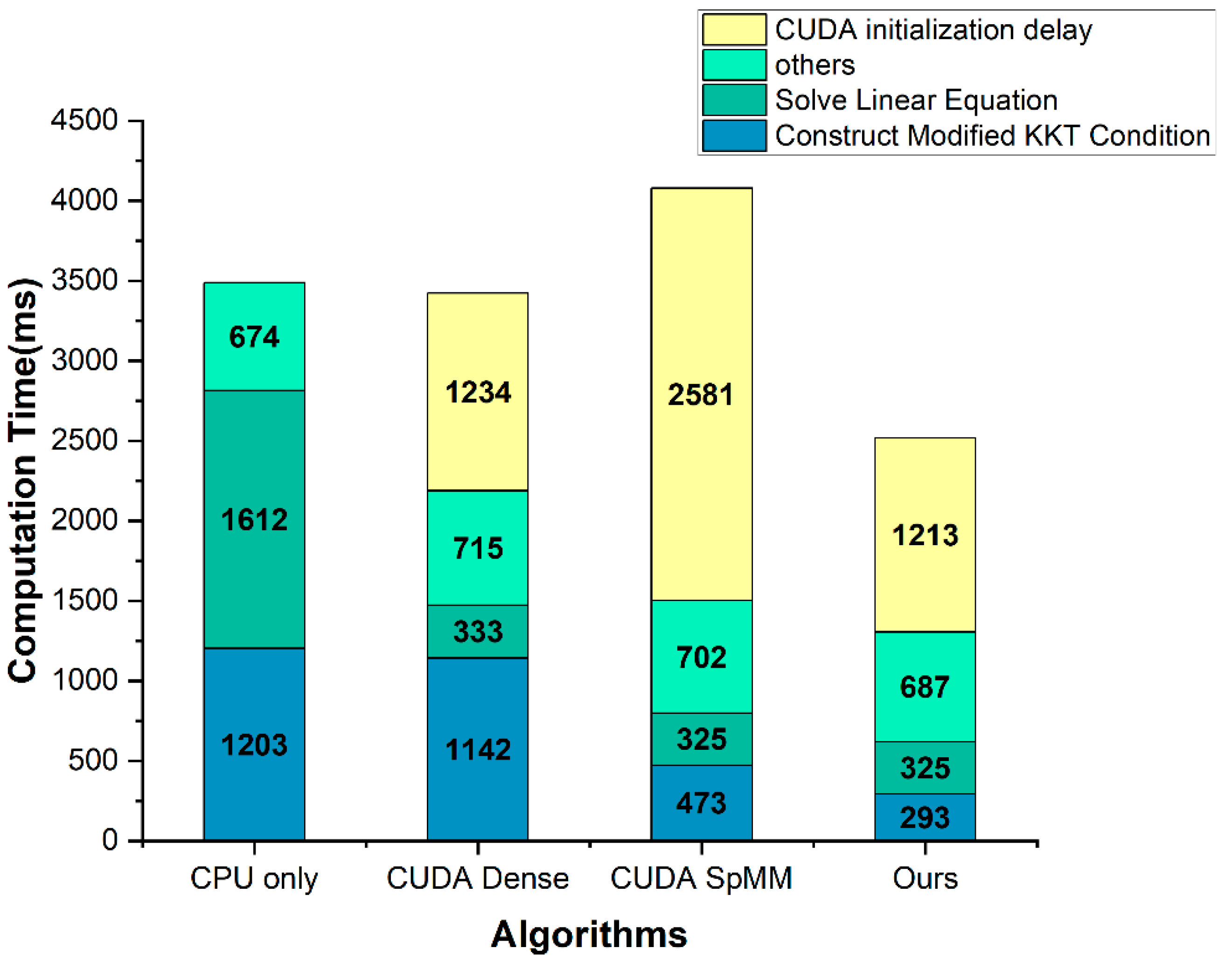
| Part | Computation Time (ms) | |||
|---|---|---|---|---|
| CPU only | CUDA Dense | CUDA SpMM | Ours | |
| CUDA initialization delay | - | 1234.11 | 2580.534 | 1213.339 |
| Others | 673.505 | 714.613 | 701.644 | 687.447 |
| Solve linear equation | 1612.328 | 332.588 | 325.038 | 325.44 |
| Construct modified KKT condition | 1202.956 | 1141.699 | 473.369 | 293.119 |
| Total | 3488.789 | 3423.01 | 4080.585 | 2519.345 |
| without CUDA initialization delay | 3488.789 | 2188.9 | 1500.051 | 1306.006 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Lee, H.; Kim, Y.; Kim, J.; Choi, W. GPU-Accelerated PD-IPM for Real-Time Model Predictive Control in Integrated Missile Guidance and Control Systems. Sensors 2022, 22, 4512. https://doi.org/10.3390/s22124512
Lee S, Lee H, Kim Y, Kim J, Choi W. GPU-Accelerated PD-IPM for Real-Time Model Predictive Control in Integrated Missile Guidance and Control Systems. Sensors. 2022; 22(12):4512. https://doi.org/10.3390/s22124512
Chicago/Turabian StyleLee, Sanghyeon, Heoncheol Lee, Yunyoung Kim, Jaehyun Kim, and Wonseok Choi. 2022. "GPU-Accelerated PD-IPM for Real-Time Model Predictive Control in Integrated Missile Guidance and Control Systems" Sensors 22, no. 12: 4512. https://doi.org/10.3390/s22124512
APA StyleLee, S., Lee, H., Kim, Y., Kim, J., & Choi, W. (2022). GPU-Accelerated PD-IPM for Real-Time Model Predictive Control in Integrated Missile Guidance and Control Systems. Sensors, 22(12), 4512. https://doi.org/10.3390/s22124512